基于双鉴别器生成对抗网络的单目深度估计方法
2022-09-15阮晓钢颜文静郭佩远
阮晓钢, 颜文静, 黄 静, 郭佩远
(1.北京工业大学信息学部, 北京 100124; 2.计算智能与智能系统北京市重点实验室,北京 100124)
准确的深度估计对于计算视觉任务有着重要的作用. 目前,自动驾驶汽车通常采用昂贵的激光系统来获得深度数据,而使用相对便宜的摄像头来获得深度信息可有效地降低成本,这使得基于视觉的深度估计有着突出的应用价值.
目前,大多数深度估计的方法通过从不同视角获取的多幅图像来推断深度[1-4],这些基于几何的方法能够相当准确地估计深度信息. 然而,基于几何的算法只考虑几何差异,忽略了单目线索. 单目线索是单个相机(眼睛)用于判断视觉信息的方式. 人类使用多个不同的单目线索来推断3D位置,比如纹理(例如:当近距离观看草地时与在远处观看时,草地具有非常不同的纹理)和颜色(例如:绿色斑块更可能是地面上的草地;蓝色斑块更可能是天空)等. 另一方面,计算时间和内存需求也是其面临的一个重要挑战.
单目深度估计方法克服了这些限制. 最近这一领域的工作利用基于深度学习的方法极大地提高了单目深度估计的性能. 早期的工作通过对带有地面真实深度的图像进行训练,以有监督的方法[5-7]解决了深度估计问题. Saxena等[5]使用线性回归和马尔可夫随机场预测一组图像特征的深度,并将其扩展到Make3D系统用于3D模型生成. 然而,该系统依赖于水平对齐的图像,并且容易在较少控制的设置下受到影响. Eigen等[6]首先开发了一个多尺度卷积神经网络来学习3种不同的任务,任务之一是从一幅图像中预测深度,该网络从输入的RGB图像中回归深度值. 有监督方法虽然取得了巨大的成功,但收集大量带有标签的数据是十分昂贵的. 基于自监督学习的方法[8-10]通过将深度估计作为图像重建来克服这一问题. 该方法不仅不需要难以获取的标记数据,效果上也超过了一些有监督方法. 立体图像对是基于自监督方法的一种输入形式. 文献[8]针对新视图合成问题,提出了一种深度离散化的模型. 文献[9]通过预测连续的视差值对该方法进行了扩展. 文献[10]通过引入左右深度一致性项产生了良好的结果. 目前,基于立体的方法已经扩展出生成对抗网络[11-12]、半监督数据[13-14],并用于嵌入式系统[15-16]等.
生成对抗网络(generative adversarial networks,GAN)是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的方法之一[17]. 该模型在博弈中不断提高其建模能力,最终实现以假乱真的图像生成,在许多图像生成任务中都有较好的应用,包括文本到图像合成[18]、超分辨率[19]和图像到图像翻译[20]等.
最近,受GAN在图像重建和生成任务上取得的良好结果的启发,一些工作将GAN应用到了单目深度估计任务中[21-24]. Aleotti等[12]提出在GAN范式下进行无监督单目深度估计,其中,生成器网络学习从参考图像推断深度以生成扭曲的目标图像,在训练时,鉴别器网络学习区分由生成器生成的假图像和用立体装置获取的目标帧,成功用GAN范式解决了单目深度估计问题. Almalioglu等[11]提出了一个生成性无监督学习框架,该框架利用深度卷积GAN从未标记的RGB图像序列中预测六自由度相机位姿和场景的单目深度图,在位姿估计和深度恢复方面都有更好的效果. 此外,基于GAN的单目深度估计方法还探索了条件随机场[21]及GAN的变体Vanilla GAN、WGAN[25]、Conditional GAN[23]等的应用.
上述方法使用的是最原始的GAN,其中包括1个生成器和1个鉴别器. 在一些具体的问题中,一些人将GAN扩展为2个鉴别器或多个鉴别器,获得了良好的效果. Li等[26]提出基于深度生成模型的人脸补全算法, 该模型由1个编解码生成器和2个对抗性鉴别器组成,用于从随机噪声中合成丢失的内容,能够处理任意形状的大面积缺失像素,并生成逼真的人脸补齐结果. Ma等[27]提出了双鉴别器条件GAN,用于融合不同分辨率的红外和可见光图像. 该方法建立了1个生成器和2个鉴别器之间的对抗性博弈,在视觉效果和定量度量方面都优于最先进的图像融合算法. Yang等[28]引入对抗性学习机制来同时训练单个生成器和多个并行鉴别器,从而得到平滑的连续人脸老化序列. 该模型生成的老化序列在视觉上更可信,老化趋势更稳定.
受上述工作启发,为了进一步提高基于自监督学习单目深度估计的精度,本文提出了一种基于双鉴别器GAN的自监督单目深度估计方法. GAN在合成视觉上可信的图像方面具有优势,本文方法利用了GAN的这个特点,其中,双鉴别器结构使生成器得到更充分的训练以满足更严格的要求,并避免由于只在左图像或右图像上引入鉴别器而造成的信息损失. 同时,为了保持训练的稳定性,使用GAN变体WGAN-GP的损失函数. WGAN-GP即Wasserstein GAN + Gradient Penalty,它使用 Wasserstein 损失公式加上梯度范数惩罚来实现利普希茨连续性,增强了训练稳定性,具有更好的图像质量和收敛性. 具体地说,该模型包含1个生成器和2个鉴别器. 其中,生成器用来生成视差图,视差图与真实图像合成重建图像. 重建的左右图像与真实左右图像分别作为鉴别器的输入,由鉴别器来辨别输入是真实图像还是重建图像. 交替训练生成器和2个鉴别器,直到鉴别器无法辨别真实图像还是重建图像. 此时,说明生成器生成了相当准确的视差,也就能得到相当准确的深度.
1 模型设计
本文提出了一种基于双鉴别器GAN的自监督单目深度估计方法,其网络包括1个生成器和2个鉴别器,框架如图1所示. 该框架以Godard等[10]的方法为基线. 其中,生成器G生成了2个视差,获得了2个重建图像,这2个重建图像在地位上是相同的. 因此,根据单目深度估计网络有2个输出的特点,使用2个鉴别器D1和D2,可以便于利用重建后的左图像和右图像. 同时,针对此模型的结构,设计了相应的损失函数.

图1 模型框架
1.1 生成器模型
从单幅图像估计深度的问题可以表述为图像重建任务,因此,生成器网络的任务是生成视差.原理如图1所示,用橘色标识.已知一对双目图像,左图像为IL,右图像为IR.左图像IL作为生成器网络的输入,网络输出为每个像素从左到右的视差dR和从右到左的视差dL.真实图像与预测视差合成重建左图像L和右图像R.真实图像与重建图像之间的差距作为网络的约束来评估通过左图像回归出来的左右视差图的效果和质量.因此,该网络可以利用真实图像与重建后的图像对进行训练,监督信号来自数据本身,不需要地面真实深度.根据双目立体视觉原理,给定摄像机之间的基线距离b和摄像机焦距f,就可以从预测的视差恢复每像素深度.它们之间的关系为
=bf/d
(1)
本文的网络只有一个输入,虽然在训练时需要一对匹配好的双目图像,但当网络完成训练之后进行深度估计时,只需要一张图像;因此,该方法也是一种单目深度估计方法.
1.2 鉴别器模型
最原始的GAN包含1个生成器和1个鉴别器,但是,在基于图像重建的自监督单目深度估计方法中,生成器生成了2个重建图像,这2个图像在地位上是相同的.因此,为了充分利用重建图像,本文使用2个并行鉴别器网络来扩展基线模型.如果生成器能同时欺骗2个鉴别器,可以认为生成器的精度有所提高.鉴别器网络的任务是辨别出真实图像与重建图像.原理如图1所示,用绿色标识.事实上,若生成器估计的视差不准确,则图像重建过程将容易再现被鉴别器检测到的失真图像.另一方面,准确的深度预测会导致重新投影的图像更难从真实图像中识别出来.在训练时,先固定生成器,训练鉴别器,目的是使鉴别器能够成功地区分真实图像与重建图像.然后,再固定鉴别器,训练生成器,目的是迫使生成器生成尽可能逼真的图像,从而达到迷惑鉴别器的目的.交替训练鉴别器与生成器,最终达到鉴别器无法分辨真实图像与重建图像的效果.此时,说明生成器生成了相当准确的视差,可以得到相当准确的深度.
1.3 损失函数
1.3.1 图像重建损失
一个好的生成器应该使得重建图像接近原始图像,因此,本文用图像重建损失来衡量这一点,采用文献[10]的损失函数,因为其具有较强的鲁棒性.该图像重建损失函数在每个尺度s上计算损失,最终的损失是每个尺度的总和.每个尺度又包含3个损失项.每个损失项对于整个优化过程具有不同的特点,公式为
(2)
第1个损失项Cap使得重建图像尽可能接近真实图像.该损失函数是单尺度SSIM函数和L1的加权和,L1是逐像素比较差异,SSIM函数考虑了人类的视觉感知.其中权值γ为0.84,使两部分损失的贡献大致相等,公式为

(3)


(4)
第3个损失项Cds表示左右一致损失,理想情况下,dL和dR之间也存在和原图相同的视差关系.因此,当预测深度达到最优时,以下损失函数达到最小值,公式为
(5)
1.3.2 对抗性损失
上述图像重建损失衡量的是每像素之间的误差,在损失公式中没有考虑场景上下文的全局一致性.因此,本文采用对抗性损失来衡量这一点.对抗性损失LGAN表示生成器G和鉴别器D之间的最小- 最大博弈, 为了保持训练的稳定性,使用GAN变体WGAN-GP的损失函数.以左图像为例,公式为
(6)
式中:IL表示真实图像;L表示重建图像.在训练过程中,首先固定生成器,训练鉴别器.当输入是真实图像时,期望鉴别器输出越大越好;当输入是重建图像时,期望鉴别器输出越小越好.整体上,需要最大化该损失函数,说明此时训练的鉴别器能够准确地区分真实图像和重建图像.然后,固定鉴别器,训练生成器.此时,当输入重建图像时,期望鉴别器输出越大越好.整体上,需要最小化该损失函数,说明训练的生成器能够迷惑鉴别器,生成了相当准确的视差.
1.3.3 总损失函数
综上,为了保证像素的真实性与局部-全局内容的一致性,本文采用图像重建损失与2个对抗性损失相结合的方式进行训练.因此,用于训练生成器的总的损失函数为
LG=CS-φG(E[D(L)]+E[D(R)])
(7)
其将重建损失CS与GAN损失的生成器部分相结合,使用φG=0.1进行加权.
用于训练鉴别器D1的损失函数为
LD1=E[D(L)-D(IL)]+λΩGP1
(8)
用于训练鉴别器D2的损失函数为
LD2=E[D(R)-D(IR)]+λΩGP2
(9)
式中ΩGP为来自WGAN-GP的λ=10的梯度惩罚.
2 实验结果
2.1 实验设置
2.1.1 数据集
本文使用KITTI[29]数据集,其中包含一辆汽车在从高速公路到市中心再到乡村道路等各种环境下行驶的图像对.KITTI是针对自动驾驶领域的图像处理技术的数据集,是目前国际上最大的自动驾驶场景下的计算机视觉算法评测数据集.本文遵循Eigen数据拆分方法[7]与现有的工作进行比较.该方法使用22 600个训练图像、888个验证图像和697个测试图像,这些图像的大小被调整到256×512像素.在训练过程中,没有使用深度地面实况,只使用可用的立体图像对.为了进行评估,使用提供的Velodyne激光数据.
2.1.2 实施详情
本文方法在Pytorch中实现.对于所有实验,生成器使用经过调整的VGG30型网络架构,以便与其他方法进行比较.所有模型都用亚当优化器[30]训练50次,每小批8个.初始学习率设置为10-4,并使用常用的学习率调整策略plateau更新学习率.鉴别器采用简单的三层全连接网络.本文模型的训练过程如算法1所示.
--------------------------------------------
算法1本文模型训练过程
--------------------------------------------
参数描述:
wgan_critics_num: WGAN结构的评估次数.
1) 初始化D1的参数θD1,D2的参数θD2,以及G的参数θG;
2) 在一次迭代训练中:
3) 训练鉴别器D1和D2:
4) While wgan_critics_num > 0

③ 生成器数据与真实图像数据合成重建图像
④ 重建图像分别输入2个鉴别器
⑤ 通过随机梯度下降(stochastic gradient descent,SGD)优化器更新鉴别器参数θD1和θD2以最小化式(8)中的LD1和式(9)中的LD2;
⑥ end
5) 训练生成器G:

③ 通过Adam优化器更新生成器参数以最小化式(7)中的LG;
--------------------------------------------
2.1.3 评估
在测试时,视差被转换到深度图中,预测的深度为0~80 m,接近地面实况中的最大深度.与其他方法[9]类似,垂直居中裁剪图像.对于定量评估,使用一组常用于评估单目深度估计模型性能的度量[6-10]:绝对相对距离(absolute relative error, AbsRel)、平方相对距离(square relative error, SqRel)、均方根误差(root mean square error, RMSE)、对数均方误差(root mean square logarithmic error, RMSLE)和阈值内的准确度.
2.2 实验结果与分析
为了与现有工作进行比较,给出了KITTI数据集的结果.首先,对本文方法的不同变体进行比较.其次,与其他单目深度估计方法进行了比较.
2.2.1 模型变体的比较
本文在KITTI数据集上测试了只使用1个鉴别器D1[22]或D2的结果和同时使用2个鉴别器D1+D2的结果,如表1所示.把最佳结果使用黑体突出显示.结果表明,使用2个鉴别器的效果在定量指标中明显优于使用1个鉴别器.其中,仅使用鉴别器D1比仅使用鉴别器D2的结果稍好,因此,认为这是初始化的结果,而不是模型设计和训练的结果,与GAN本身的不稳定性也有一定的关系.使用鉴别器D1+D2与仅使用鉴别器D1在δ<1.25这项指标中没有改善,说明更严格的对抗性约束虽然促进了全局一致性,但牺牲了部分局部像素点的准确性.这在深度图中体现为物体的边界更加平滑,但从范围来看比较模糊.定性的实验结果如图2所示.图中展示了输入图像与从不同模型变体获得的深度图像.图3展示了一些放大的比较,在红框标注的地方可以看到,使用2个鉴别器的模型在处理物体边缘时更加清晰.这与文献[28]得到的结论是一致的.
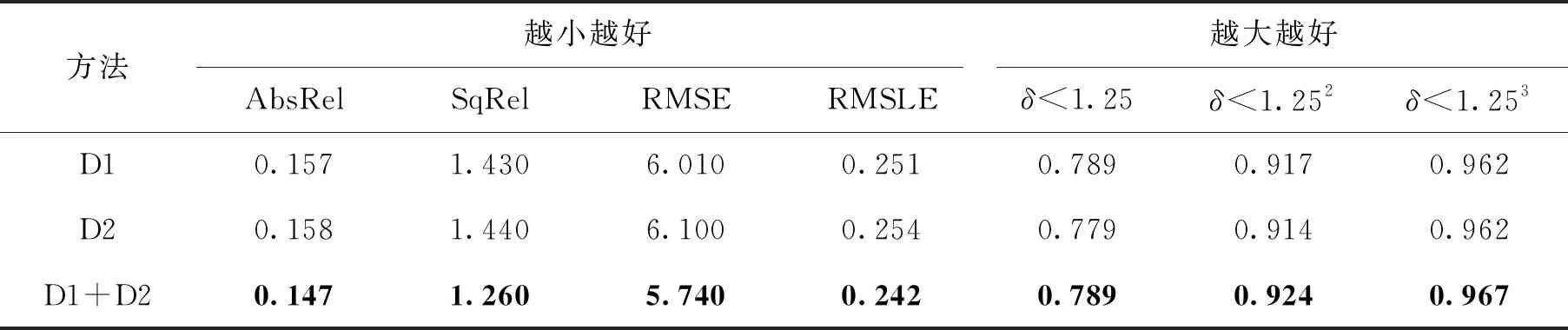
表1 不同模型变体在KITTI数据集上的结果

图2 定性实验结果

图3 细节图
2.2.2 与其他方法的比较
对比了在KITTI数据集上本文方法与其他有监督和无监督单目深度估计方法,如表2所示.由表可知,本文的结果在6个定量指标上优于其他已知的方法,而仅使用单个鉴别器的结果比不使用对抗性训练的结果更差.可以得出结论,只要合理设计基于GAN的单目深度估计模型以及合理利用GAN变体,GAN有助于进行单目深度估计.但是,在δ<1.25这项指标中,本文方法比仅使用基于像素的几何损失的结果[10]稍差.这是由于GAN中的鉴别器是通过神经网络提取后的特征对数据进行判别,更加具有全局性.

表2 与其他单目深度估计方法的比较
3 结 论
1) 本文使用2个鉴别器的方法在定量指标中明显优于使用1个鉴别器,也优于其他不使用对抗性训练的方法,因此,合理设计网络结构及使用合适的GAN变体,有助于提高单目深度估计的精度.
2) 定性实验结果表明,使用双鉴别器模型得到的深度图中的物体边缘更平滑,在视觉上更可信.
3) 仅使用鉴别器D1比仅使用鉴别器D2的结果稍好,因此,这是初始化的结果,而不是模型设计和训练的结果,与GAN本身的不稳定性也有一定的关系.
