基于置信熵差的冲突证据融合方法
2023-02-08许石君邓新蒲陈沛铂周石琳
许石君,侯 毅,邓新蒲,陈沛铂,周石琳
(国防科技大学 电子科学学院,长沙410000 )
0 引言
Dempster -Shafer(D -S)证据理论是由Dempster[1]和他的学生Shafer[2]共同提出的理论,能够在无先验知识的条件下,有效处理由随机性和模糊性带来的不确定性,已被广泛应用于目标识别、故障诊断、智能决策和风险评估等领域。
在D-S 证据理论的应用发展中,Zadeh[3]于1986 年指出:Dempster 组合规则的使用在证据高度冲突时会失效。针对以上问题,研究者给出了许多改进的方法,其中使用加权平均的方法对原始证据进行修正后再使用Dempster 组合规则进行融合,能够较好地保留Dempster 组合规则的良好数学性能—交换律和结合律。
然而,如何合理地确定证据的权重是一个值得研究的问题。Liu[4]提出了一种新的权重因子估计方法,利用基于概率变换的距离和冲突系数来表征相异性,距离代表证据之间的差异,而冲突系数则揭示了两个基本概率赋值函数强烈支持某假设的分歧程度。相异性的两个方面在某种意义上是互补的,两个方面的结合被用作相异性的度量,此度量值便是各个证据的权重值;Xiao[5]将Jousselme 距离推广到复杂的证据距离,以度量复杂的证据冲突,并将其作为加权因子对原始证据进行修正,以获得最后的融合结果;Mi[6]提出了基于非冲突元素集的证据冲突处理方法,先利用证据间的相关系数获得加权平均值,加权平均得到新证据,再通过非冲突元素集判断后进行折扣计算,以获得最终的融合结果;Xiao[7]提出了一种基于相似度和置信熵的方法,首先根据基本概率赋值的修正余弦相似性,计算证据的可信度及其相应的全局可信度;其次,根据证据的全局可信度,将原始证据分为可靠证据和不可靠证据两类;最后,为了加强可靠证据的积极效应,减轻不可靠证据的负面影响,利用邓熵函数来衡量不同类型证据的信息量,以得到证据权重并修改证据源;An[8]在相似性度量模型中引入模糊推理机制,通过计算模糊贴进度和相关系数来度量证据之间的冲突程度,在此基础上利用置信熵来计算证据的不确定性,从而得到证据的可信度,并利用量化信息量对每个可信度进行修正,获得最终的证据权重;Tao[9]提出基于置信熵和诱导有序加权平均算子的算法,同时考虑了证据的不确定性和可靠性,首先计算出各个证据的置信熵和可信度;其次,对各个证据的置信熵从高到低进行排序,基于有序加权平均算子产生有序加权平均对,再利用正则递增单调函数计算出顺序权值,加权平均后的新证据通过融合后得到最终结果;Yan[10]提出基于改进置信熵的加权平均方法,利用改进置信熵度量各个证据的不确定值,以此作为证据的支持度,从而获得各个证据的权重,并对原始证据进行加权修正,得到加权平均证据,以实现冲突证据的有效融合。虽然,Yan 方法在大多数情况下,能够较好地处理冲突证据,但该方法是通过改进的置信熵度量整个证据的不确定性值,从全局的角度和不确定性的角度衡量证据之间的差异,并直接将整个证据的置信熵值作为证据支持度,从而确定证据的权重,当冲突证据的置信熵值等于或者大于正常证据时,系统将赋予冲突证据与正常证据相同甚至更大的权重值,导致冲突得不到有效处理。
为此,本文提出基于置信熵差的冲突证据融合方法,利用证据内对应焦元的邓熵值差度量证据之间的差异,从而合理地确定各个证据的权重值;从局部的不确定性的角度度量证据之间的差异,从而有效克服了现有基于置信熵的方法存在的不足,并通过算例证明了该方法的有效性和优越性。
1 理论知识
定义1[11]识别框架。若Θ ={F1,F2,…,FN}是由N个两两互斥元素构成的有限的完备集合,则称Θ为识别框架(Frame Of Discernment,FOD)。Fi称作识别框架的一个元素或事件。由Θ中的所有子集或命题组成的集合称为Θ的幂集,记为2Θ,可表示为
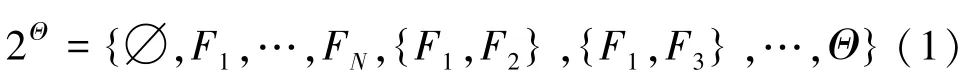
识别框架内的元素是有限可穷举的,且相互之间不相容。直观来说,识别框架就是所识别判断的对象的全体集合,将抽象的逻辑概念转化成直观的集合论概念,进而把各个元素之间的逻辑运算转化为集合论运算。
定义2[1]组合规则。设m1和m2为两组基本概率赋值,对应的焦元分别为A1,A2,…,An和B1,B2,…,Bm,用m表示组合后的证据,则Dempster 组合规则表示为
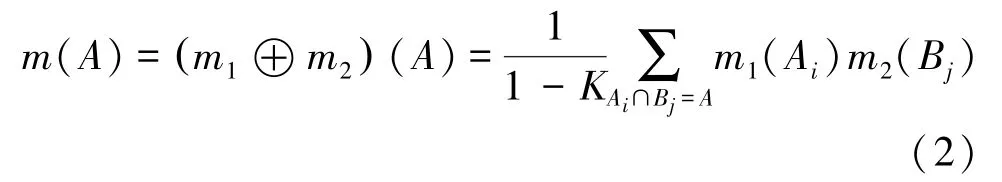
其中,K为冲突系数,表示为(2),式(2),m表示m1和m2的正交和,记为符号⊕。
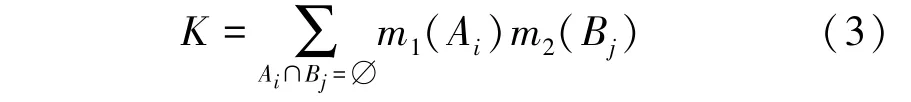
当组合多个证据时,其表达为:

定义3加权平均证据。假设m1,m2,…,mn是从不同的数据源收集到的证据,而w1,w2,…,wn是证据对应的权重,利用权重对原始证据进行修改,得到加权平均证据,表示为(5)
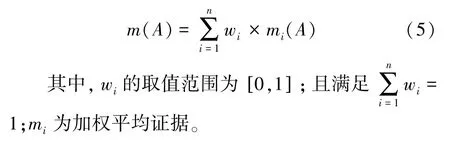
定义4[12]邓熵。邓熵是香农熵的推广,其定义如式(6)

定义5Yan 提出的改进置信熵,通过引入信任函数来扩展不确定性的度量,是在邓熵的基础上的拓展与改进,其定义为
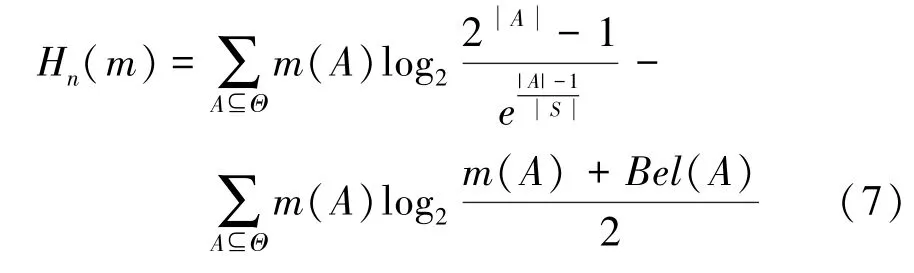
2 基于置信熵差的冲突证据融合方法
2.1 置信熵差
邓熵是一种改进的置信熵,作为香农熵的推广,邓熵是一种有效的测量不确定信息的数学工具。本文在邓熵的基础上,提出利用置信熵差度量证据之间的差异。
定义6假设A1,A2,…,Ak是证据mi和mj的焦元,那么证据mi和mj之间的置信熵差表示为
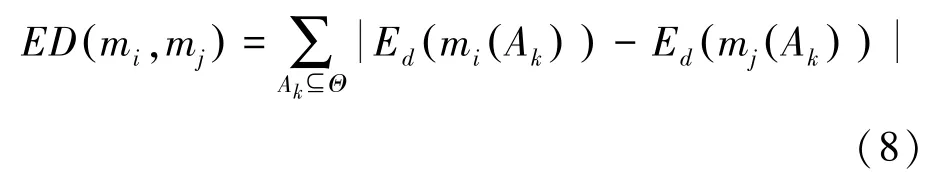
其中,Ed(mi(Ak)) 是焦元Ak的置信熵值。
2.2 证据权重的确定
假设识别框架中有n个证据。
第一步,利用邓熵式(7)计算焦元置信熵;
第二步,构造置信熵差矩阵,式(9);
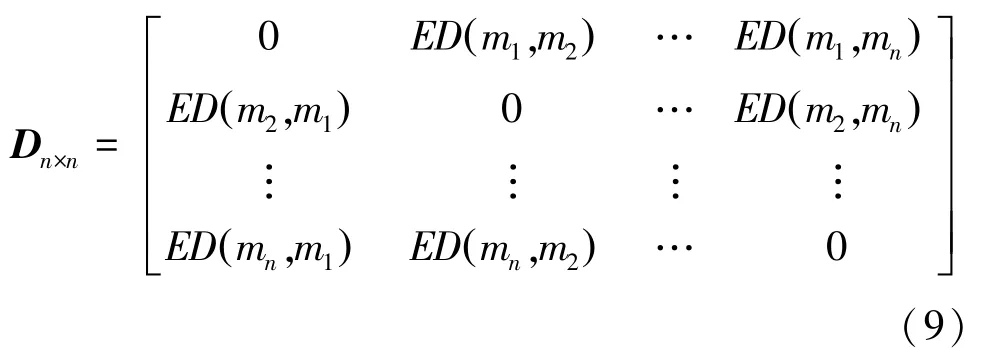
第三步,利用式(10)计算证据体的支持度;
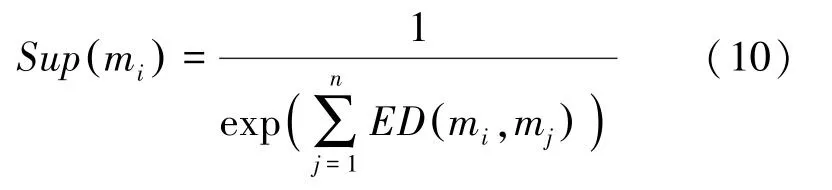
然而,基于置信熵的方法的证据体支持度是由式(11)计算获得,其值等于置信熵本身;
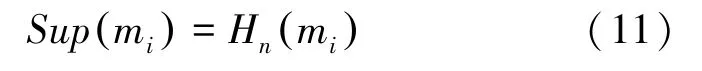
第四步,利用式(12)获得证据权重。
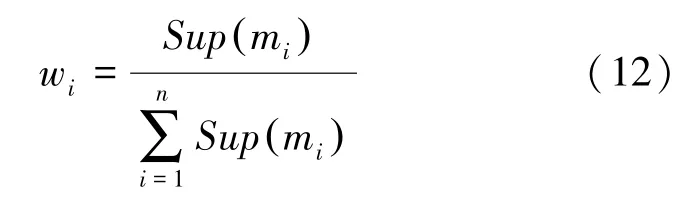
3 数值算例
通过置信熵差度量证据之间的差异以获得证据权重,对原始证据加权平均得到加权平均证据,利用Dempster 组合规则对加权平均证据进行融合。
3.1 反例1
假设辨识框架Θ ={A,B,C},系统收集到5 个证据,各证据的基本概率赋值(basic probability assignment,BPA)如下:
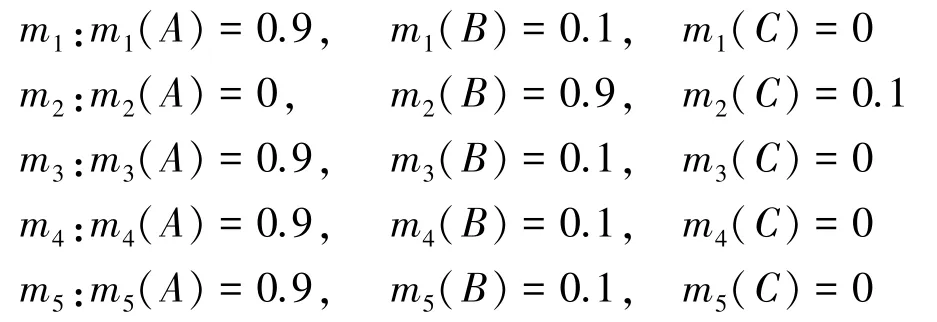
显然,证据m2与其它证据高度冲突,在加权平均过程中应当得到更小的权重。利用基于置信熵的方法计算各个证据的支持度。
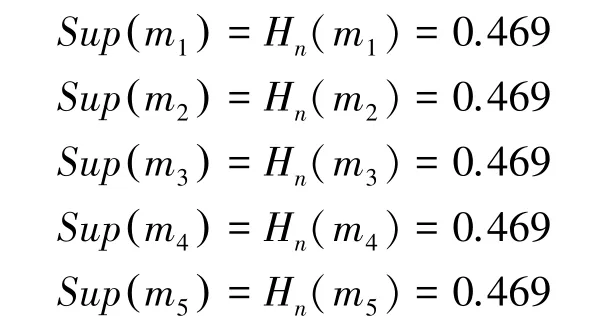
根据式(12)获得各个证据的权重,见表1。
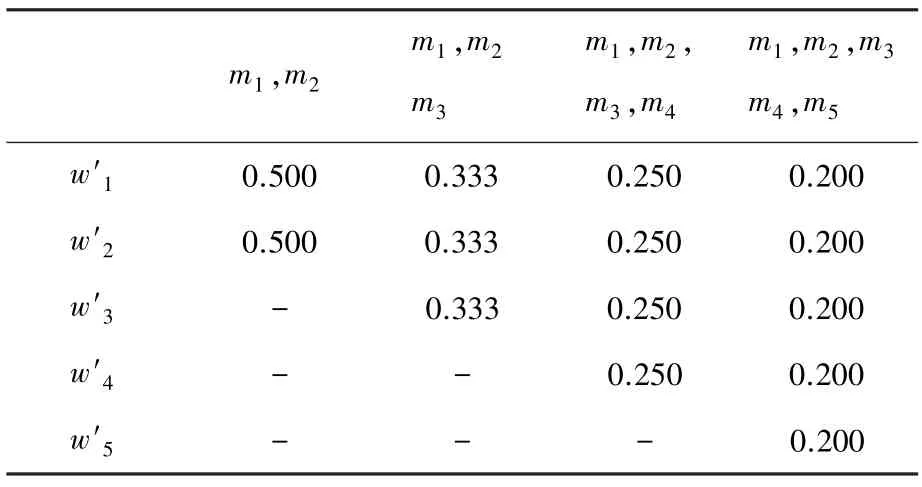
表1 获得各证据权重值Tab.1 Weight of evidences for Yan’s method
计算各个证据的支持度(以融合前3 个证据为例)。
证据内各焦元的邓熵值为:
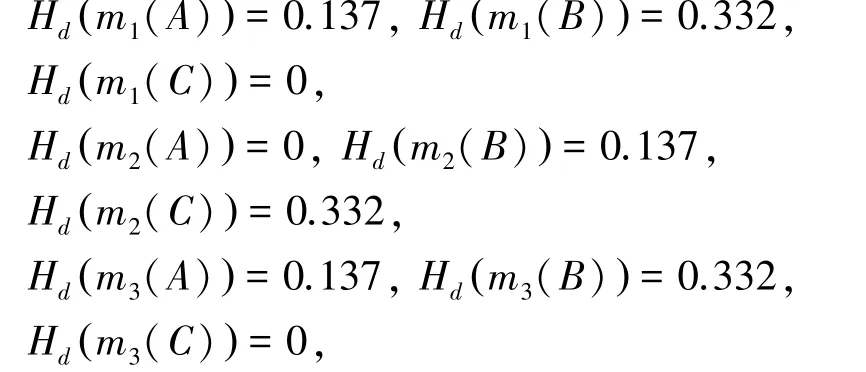
利用式(8)计算各证据之间的置信熵差:(直接给结果)
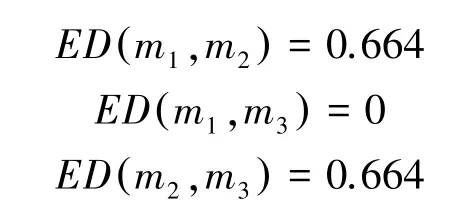
因而,可构建证据置信熵差矩阵D3×3:

利用式(11)计算各证据体的支持度。
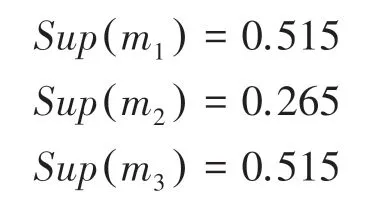
利用式(12)获得证据权重。
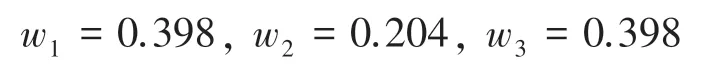
各证据的权重值,见表2,第二个证据权重值的对比如图1 所示。
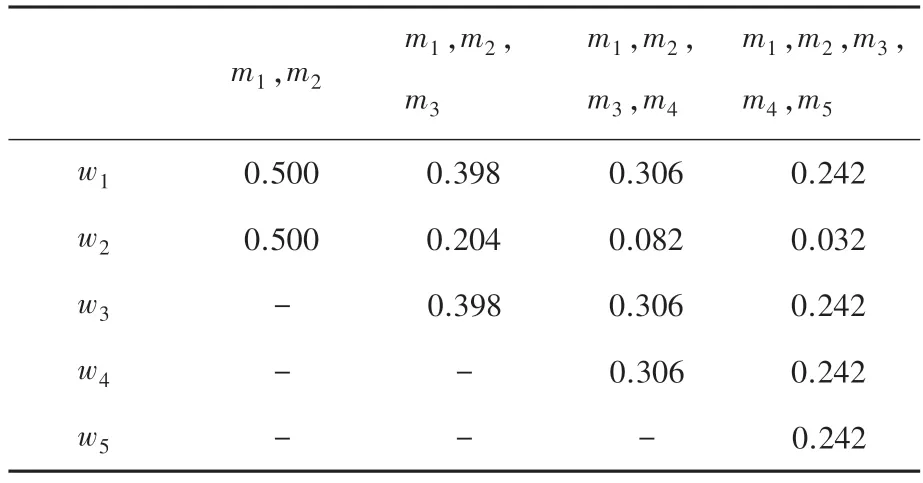
表2 本文方法的各证据权重值Tab.2 Weight of evidences for the proposed method
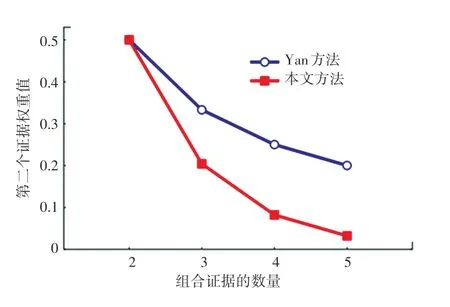
图1 第二个证据权重值对比Fig.1 Comparison of the weights for the second evidence
由表1 可知,5 个证据的置信熵是相等的,将冲突证据和正常证据都赋予了相同的权重,导致后续融合过程中冲突证据无法得到有效处理。根据表2和图1 可知,本文提出的方法赋予冲突证据以更小的权重值,能够很好地区分正常证据与冲突证据。此外,随着正常证据的增加,冲突证据的权重值下降明显,使得正常证据的作用得到了最大程度的发挥,冲突证据受到了最大限度的抑制。
3.2 反例2
假设辨识框架Θ ={A,B,C},系统收集到5 个证据,各证据的BPA为:
m1:m1(A)=0.9,m1(B)=0,m1(C)=0.1
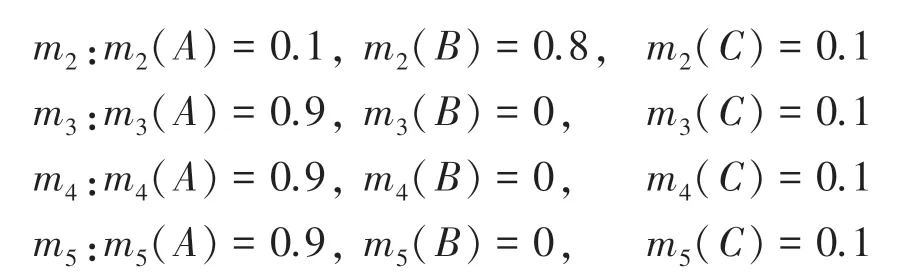
显然,证据m2与其它证据高度冲突,在加权平均过程中应当得到更小的权重值。利用Han 方法和本文方法得到各个证据的权重值见表3、表4 和图2 所示。
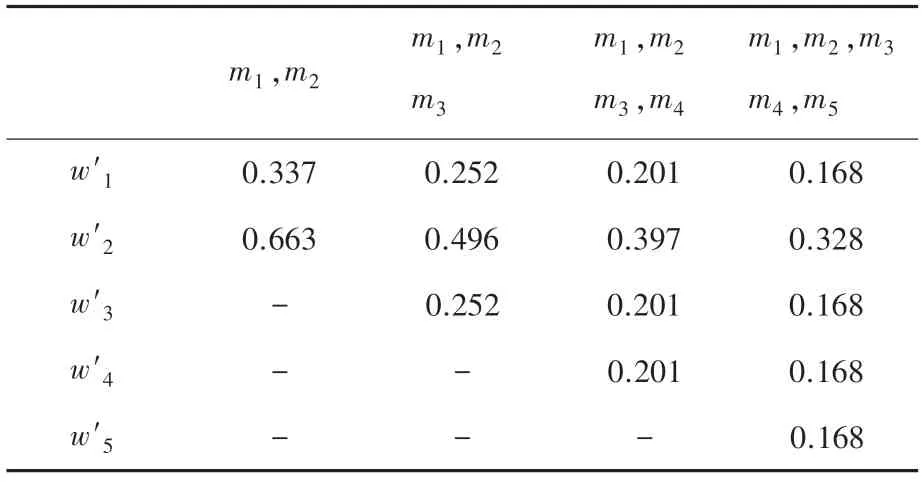
表3 Yan 方法获得各证据权重值Tab.3 Weight of evidences for Yan’s method
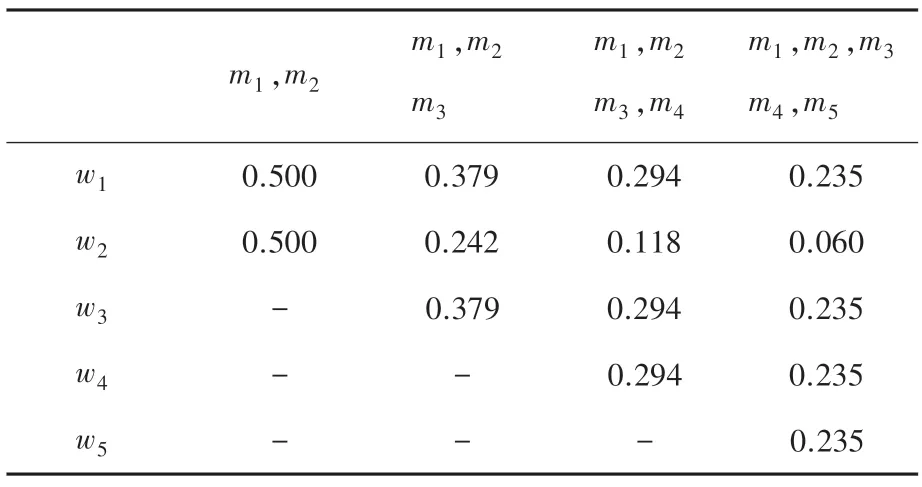
表4 本文方法的各证据权重值Tab.4 Weight of evidences for the proposed method

图2 第二个证据的融合结果对比Fig.2 Comparison of combination result for the second evidence
根据式(7)可得,冲突证据的置信熵值为0.921大于正常证据的置信熵值0.468,见表3,采用Yan方法的冲突证据权重值反而大于正常证据权重值,即使正常证据个数在增加,但冲突证据权重依然大于正常证据,显然与事实相违背。根据表4 和图3可知,本文提出的方法能够合理地处理冲突证据,赋予冲突证据以更小的权重值,并始终比Yan 方法的权重值更小。此外,随着正常证据个数的增加,冲突证据的权重值始终保持下降的趋势,并小于正常证据的权重值,一定程度上减小了冲突证据对后续融合的负面影响。从反例1 和反例2 的对比结果可知,无论冲突证据的置信熵值大于还是等于正常证据,本文方法都能较好地处理冲突证据并赋予一个较为合理的权重值,其有效性得到充分证明。
3.3 识别应用
在多目标识别系统中,A、B和C表示3 种不同的目标,目前共有5 个不同类型的传感器,各传感器数据的基本概率赋值如下。显然,证据m2与其它证据高度冲突,目标A将获得最高的可信度。
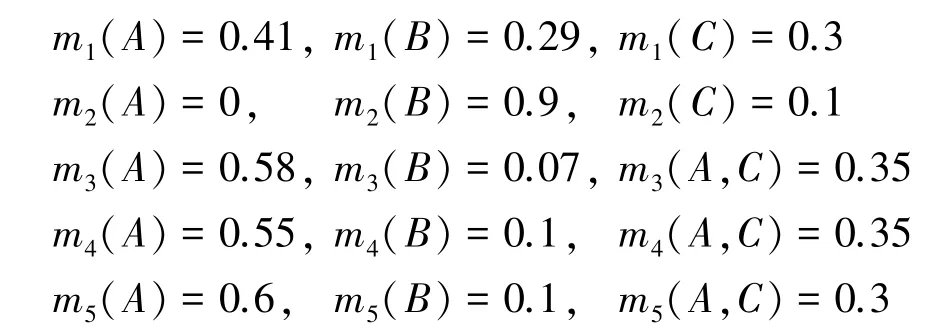
第一步,计算各证据内各焦元的邓熵值;
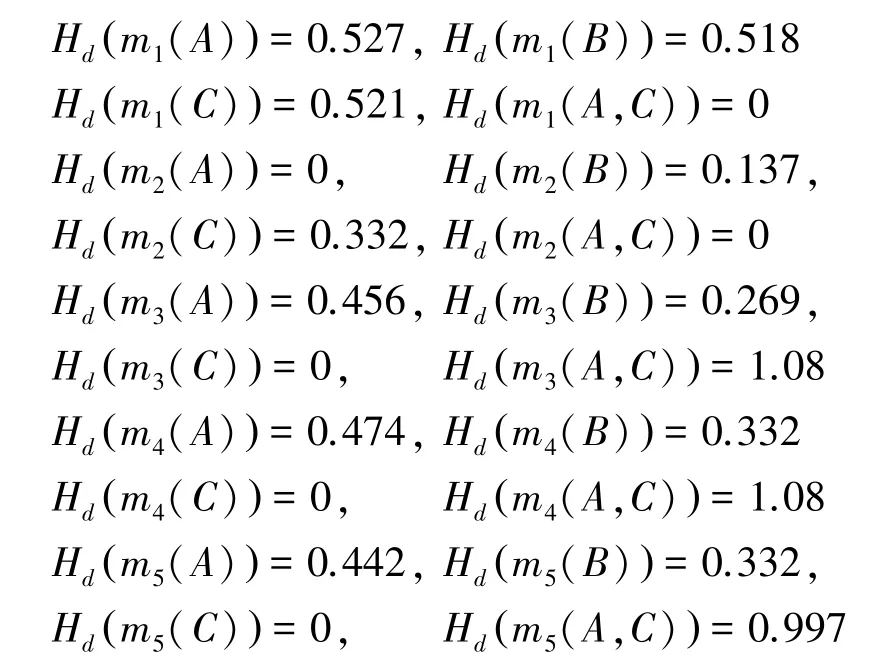
第二步,利用式(10)计算各证据之间的置信熵差;
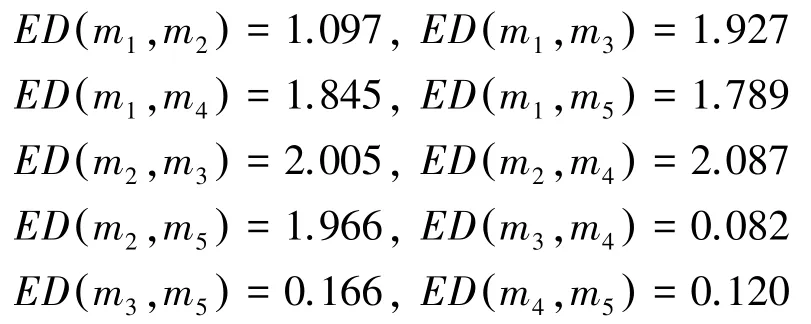
构建证据置信熵差矩阵D5×5;

第三步,利用式(11)计算各证据体的支持度;
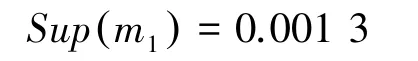
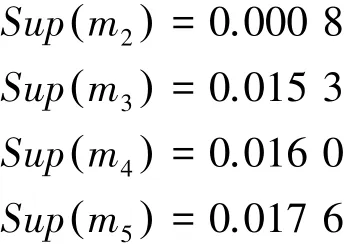
第四步,利用式(13)获得证据权重;
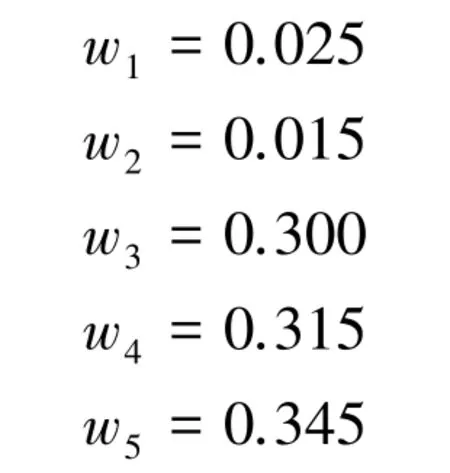
第五步,利用式(14)得到修正后的加权平均证据;
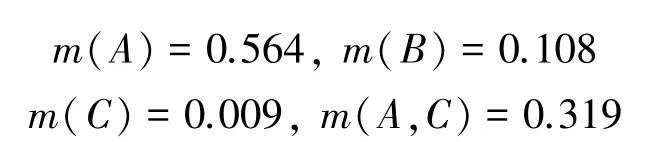
第六步,利用Dempster 组合规则,融合修正后的加权平均证据4 次,得到最终融合结果。
为验证本文所提方法的有效性和合理性,分别应用Dempster 方 法、Murphy 方 法[13]、Deng 方法[14]、Yan 方法对应用实例中的证据进行融合,各方法的融合结果见表5 和图3 所示,m(A) 的融合结果对比如图4 所示。
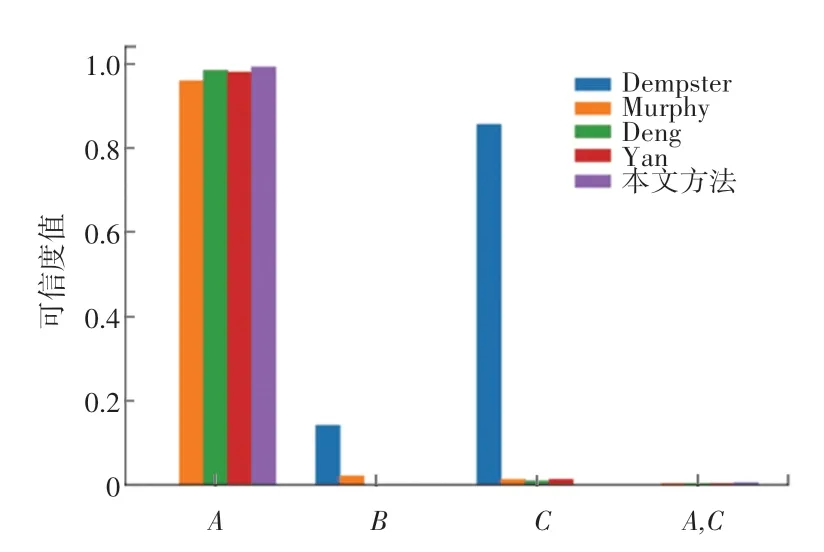
图3 融合5 个证据后的结果对比Fig.3 Comparison of results after combination of five evidences
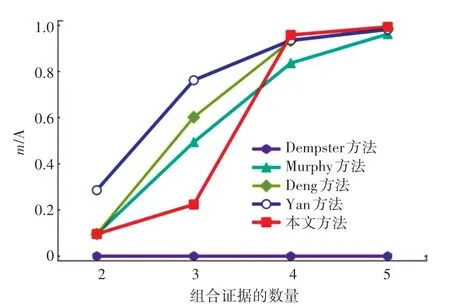
图4 m(A)的融合结果对比Fig.4 Comparison of m(A)′ combination result
由于证据m2中类别A的基本概率赋值为0,无论支持类别A的证据有多少个,通过Dempster 组合规则融合后,m(A) 的值始终为0,出现“一票否决”的现象,表明经典的Dempster 组合规则在融合高度冲突证据时会得到违背常理的结果。Murphy 方法能够得到合理的融合结果,但该方法只是对证据进行简单的加权平均,没有考虑影响证据权重的其它因素,因而最终融合结果中,正确类别的可信度不是最高。
虽然Deng 方法和Yan 方法在Murphy 方法的基础上获得了更高的正确类别可信度,并在整体收敛速度上相较本文方法有一定的优势,但从证据不确定性的角度可以得到合理的解释。根据表5 计算结果可知,由于m2置信熵值(0.468)最小,即不确定性程度最低,证据信息的可信度程度高。本文方法在融合m1、m2以及m1、m2、m3时,并没有过早地否定m2,而是当正常证据m4和m5加入后,在已经确认为冲突证据的情况下,开始抑制冲突证据对后续融合的负面影响,赋予证据m2以更低的权重值,因而在融合4 个或5 个证据时,本文方法的收敛速度最快,获得了正确类别A的最高置信度0.993,充分说明了本文方法的优越性。
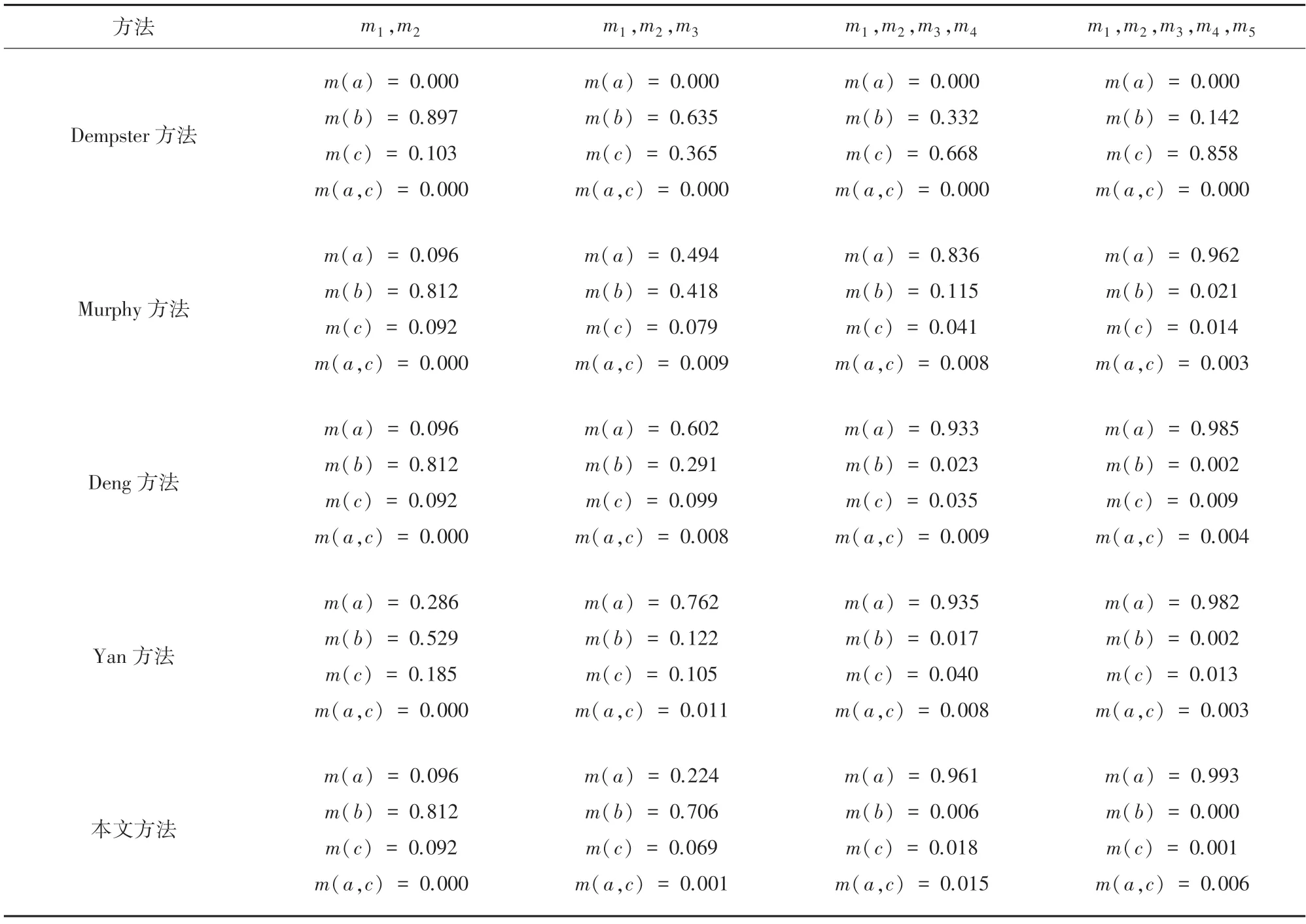
表5 不同冲突证据融合方法的融合结果Tab.5 Combination results of different conflict evidence combination methods
4 结束语
针对现有基于置信熵的加权平均方法,冲突证据置信熵值大于或等于正常证据时,出现的证据权重确定不合理的问题,本文提出了基于置信熵差的冲突证据融合方法。该方法利用证据内对应焦元的邓熵值差度量证据之间的差异,获得各证据的支持度,从而确定各个证据的权重值,相比于只简单地利用整个证据的置信熵值确定证据权重的方法,能够从局部的不确定性的角度衡量各证据可靠性,使得证据权重的确定更加客观、准确和合理。算例结果表明,基于置信熵差的冲突证据融合方法,证据权重确定更加符合人的客观认识,融合结果的正确目标可信度最高。
