基于时序卷积生成对抗网络的单通道音域分离
2023-02-04郁文虎全海燕
郁文虎,全海燕
(昆明理工大学 信息工程与自动化学院,云南 昆明 650500)
对于“鸡尾酒会问题”中提到的人们会在吵闹的环境下获取对自己有用的话语,但是计算机不会主动获取一些音频,只是被动地接受输入的信息.而且随着说话人数增加或者处在一个更嘈杂的环境中,计算机可能会无法辨别出目的语音.为解决该问题,语音分离算法不断革新.语音分离问题的解决主要采用基于信号处理和深度学习的方法.在深度学习未提出之前,研究人员采用信号处理的方法对双通道或者多通道[1]的语音进行研究.常见的有维纳滤波法[2]、谱减法[3]、卡尔曼滤波法[4]等.但上述方法会造成输出信息的丢失,导致分离效果不佳.深度学习兴起于图像领域,伴随图神经网络的不断发展,研究者开始把深度学习逐渐应用于语音和文本,并且取得了一定的成果.经过研究者不断探索,深度学习的模型开始应用于机器翻译[5]、音频合成[6]和语言建模等领域中.
计算机性能的提升,给人们提供了加深神经网络层数的条件,这极大促进了深度学习在语音信号处理上的发展.Xu等[7]将深度神经网络(Deep Neural Nets,DNN)应用于语音分离方面,先将混合语音与目标语音的对数幅度谱相映射,再结合相位信息恢复目标语音波形.Luo等[8]提出了利用双路径递归神经网络(Dual-Path Recurrent Neural Network,DPRNN)在深层结构中组织循环神经网络层对极长语音序列进行重新建模.Wang等[9]专注于使用短时傅里叶变换(Short Time Fourier Transform, STFT)方法进行时频域信号处理,该方法先使用STFT将波形转换为时频表示,然后将结果用于预测每个声源的时频掩模.
在深度学习模型的不断创新下,对抗生成网络(Generative Adversarial Networks, GAN)被 提 出,GAN在图像处理中经常被用来替换一些神经网络.由于GAN中生成器(Generator,G)和判别器(Discriminator,D)可以使用很多模型,因此研究者开始探索对抗生成网络在语音上的应用.Pascual等[10]首次将GAN运用到语音降噪中,提出了语音增强生成对抗网络(Speech Enhanced Generative Adversarial Networks, SEGAN),该方法能完整保存时域信号的相位信息,帮助语音更好地还原.SEGAN将时域波形作为模型的输入,然后结合D训练数据,降噪效果显著.范存航等[11]受SEGAN的启发,提出了一种基于卷积编解码器(Convolutional Encoder Decoder, CED)的端到端语音分离系统.该系统将时域波形作为系统输入,并在损失函数中加入干扰语音信息进行训练,提高了分离性能.王怡斐等[12]提出了一种基于Wasserstein距离的GAN用于语音增强,该方法无需人工提取声学特征便可进一步提升GAN在语音降噪上的效果,同时可以直接看到GAN在直接分析时域波形上的优势.Luo等[13]提出卷积时域音频分离网络Conv-TasNet,该框架是一种端到端的时域语音分离的深度学习框架,能使循环网络更精确、更简单、更清晰.
相比于时域上端到端网络的音域信号分离,大部分频域音域信号的分离需要借助相位信息还原语音,而这种方法会造成目标语音部分信息的丢失.因此受文献[13]启发,本文提出了一种基于时序卷积对抗生成网络的音域分离方法.本文方法首先以经过预处理的时域语音信号作为输入,其次构建联合训练结构,最后利用时序卷积网络(Temporal Convolutional Network,TCN)以及深度特征聚合结构,增加提取目标特征向量之间的“相关性”,从而帮助判别器更好地获取目标语音的高维时域特征信息,使生成器更好地分离出目标语音.此外,在对抗生成网络模型中引入噪声语音,可以弥补目标语音特征信息的不足,提升模型分离的性能.
1 基本原理
1.1 生成对抗网络GAN基本思想是在D和G之间建立一个游戏,让它们相互竞争.在这个游戏中,D学习如何辨别真假数据,而G学习如何欺骗D.D把G生成的样本判为假,把真实数据判为真.GAN的结构框图如图1所示.
GAN旨在训练两个相互竞争的网络,即生成性网络和对抗性网络.标准GAN的损失函数定义如下:
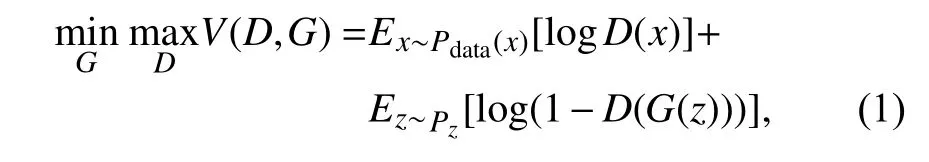
式中:Pdata和Pz表示实际数据和输入先验噪声的概率分布,x表示实际数据,z是生成器G的随机输入,服从概率分布(如高斯分布)Pz.

图1 GAN的结构Fig.1 The architecture of GAN
GAN框架的训练过程类似于两人对抗的博弈游戏,其中G被训练为最小化目标函数,其目的是生成接近真实样本的假样本.而D则是被训练为最大化目标函数,其目的是区分真实样本和假样本.式(1)中利用交叉熵函数衡量真样本和假样本之间数据分布的相似度.D是一个二分类网络,其作用是将来自真实样本的数据判为1,来自生成样本的数据判为0.G经过训练会生成接近真实样本数据分布的假样本,使 log(1−D(G(z)))的值最小.在G取最小值的同时使目标函数 logD(x)和 log(1−D(G(z)))两者的和达到最大.
为了加速模型的收敛,可在训练过程中引入一些额外的辅助信息帮助模型达到最优.因此本文在损失函数中引入服从Pdata(xc) 分布的额外信息xc.语音分离中xc一般取目的语音和噪声语音的混合语音,以此约束G生成接近真实样本数据分布的假样本,同时帮助D更好地区分真假数据.G的输入是语音和音乐混合的语音,而D的输入则是xc与将要进行判别的语音拼接后的语音.此时,原始损失函数可改为:

1.2 TCN原理时序卷积网络(Temporal Convolutional Network,TCN)结构利用因果卷积让过去到未来的信息传递没有遗失.因此,对于任意长度的序列信息,TCN可以映射到对应的输出序列,保证了在信息提取过程中信息特征的完整性.此外,TCN融合了膨胀卷积、因果卷积以及残差连接的思想.
因果卷积在网络层数比较少的时候能够较好地映射过去的信息,但当网络层数比较多的时候,其映射过去信息的效果不佳.为解决上述问题,采用扩大卷积涵盖更长历史的映射以达到较大的感受野.对于一维序列x和过滤器f以及序列中元素s的扩张卷积定义的公式如下:

式中:X∈Rn,过滤器f:{0,···,k-1}!R,d为膨胀系数,k为过滤器尺寸,s-d·i解释了过去的方向.膨胀卷积的目的是为了增大输出层的感受野,此时底层的输入相当于正常的卷积,而往上的层则是通过引入的膨胀系数进行类似于采样的卷积.
为了增大TCN的感受野,本文采用增加膨胀系数的办法,其中一层的有效历史为(k-1)d.在使用膨胀卷积时,膨胀系数会随着网络层数的增长而以一定的指数增加.该方法确保了在有效历史记录中过滤器可以涵盖每个输入,同时也允许深度网络生成非常大的有效历史记录.膨胀卷积的原理结构如图2所示.
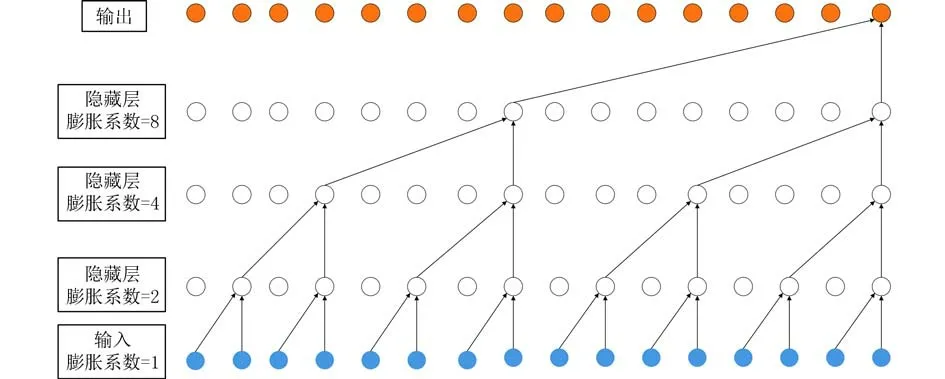
图2 膨胀卷积结构图Fig.2 The architecture of dilated convolution
TCN中的残差连接操作使网络可以跨层传递信息,避免了层数过多导致信息丢失的问题.残差连接最大程度保留了样本原本的特征,从而让神经网络学习到样本更多的信息.
此外,TCN由残差块组成,模型利用残差学习可以充分训练深层网络[14].图3展示了本文中使用的残差块[13].从图3中可以看出,残差块由3个卷积组成:输入1×1卷积、深度卷积和输出1×1卷积.其中,输入卷积用于将输入通道的数量增加一倍.输出卷积用于恢复原始通道数,从而使输入和输出的特征向量相加兼容.深度卷积用于进一步减少参数数量.在深度卷积中,通道数保持不变,每个输入通道仅使用一个滤波器进行输出计算[15].
2 时序卷积生成对抗网络的音域分离方法
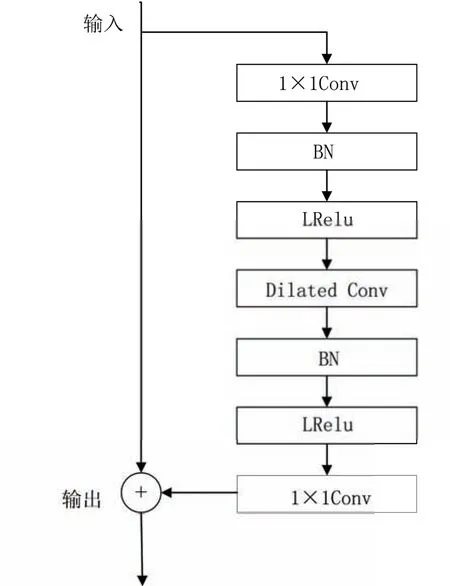
图3 残差单元结构图Fig.3 Unit structure diagram of the residual block
2.1 联合训练与时域卷积生成对抗网络对于音域分离的问题,本文提出了基于时域卷积生成对抗网络的音域分离方法(Temporal Convolutional Network of GAN,T-GAN).该方法不同于SEGAN只关注目标语音,T-GAN中的联合训练结构使GAN能够同时对语音和音乐的特征进行训练.由于神经网络结构只关注当前时刻的目标语音和干扰语音,忽略了特征向量之间的关系,因此本文利用时域卷积网络结构增加特征向量之间的相关性,即特征向量中后一时刻的值由前一时刻或者前面几个时刻的值决定.T-GAN将输入的时域波形通过编码器提取出来的特征向量输入到TCN中增加特征向量的感受野,再输入到解码器上采样进行语音还原.基于T-GAN的音域分离算法模型结构如图4所示.图4中X1表 示分离的目标语音,X2表示分离的噪声语音,Xm表示语音和音乐的混合语音;X3表示纯净的噪声语音;由于输入的是时域信号,所以X2可 以由混合语音Xm减 去分离的目标语音X1得到;z表示潜在的特征向量.
在T-GAN网络结构中,G采用全卷积(Fully Convolutional Networks,FCN) 构成的编码-解码网络,其网络模型如图5所示.全卷积网络分为两个阶段.在编码阶段,G采用正卷积对输入的混合语音信号提取时域特征信息.BN层添加在激活函数前,能够增大模型的学习率,提高模型的训练速度.每层输出采用带泄漏修正线性单元 (LeakyRelu)作为激活函数以加速网络的收敛,预防网络在训练过程中出现梯度消失的问题.将提取的高维时域特征向量c与额外输入的特征向量z连接(z的分布符合正态分布(0,1)).将连接后的特征向量输入到TCN中增大特征向量的感受野,并加深特征之间的关联性以便解码阶段更好的恢复语音.在解码阶段,利用反卷积对经过TCN网络的语音特征向量还原.每个神经网络层设置与编码阶段相似,经过解码阶段还原到和原始语音时长相同的语音.此外,本文引入深度特征聚合结构,将原始输入的特征向量经过最大值池化后和经过卷积、批归一化、激活函数的特征向量拼接作为下一层卷积层的输入,最大程度保留原始时域特征信息的完整性.编码层的特征信息经过跳跃连接[16]传递给对应的解码层,以此得到原始语音信号更多的特征信息,帮助解码器更好地恢复语音.D的结构和编码器的结构相似,使用多层步幅卷积(正卷积)的网络结构对输入的样本进行判别.

图4 基于T-GAN联合训练的声乐分离算法Fig.4 Vocal music separation algorithm based on T-GAN joint training
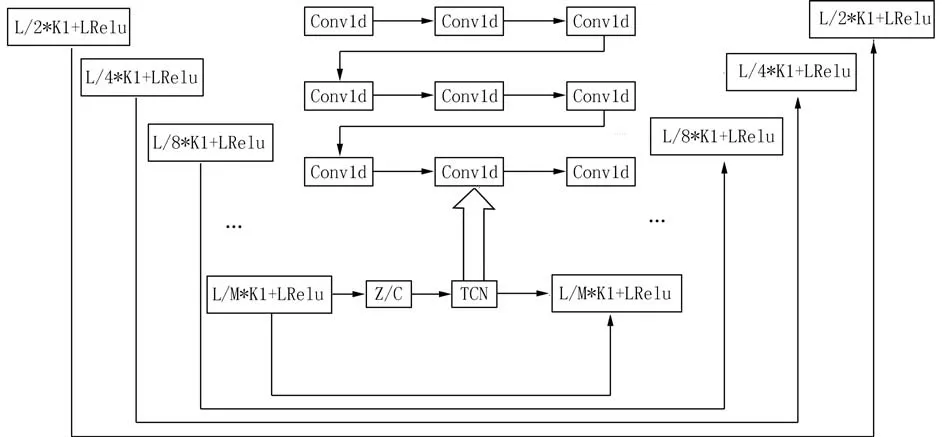
图5 生成器G的模型结构Fig.5 The model structure of generator G
2.2 损失函数在GAN中,损失函数对模型稳定和收敛影响较大,而式(1)和式(2)均使用Sigmoid交叉熵函数作为损失函数.然而Sigmoid交叉熵函数会导致梯度消失情况的出现.为解决上述问题,本文以二进制的最小二乘函数作为模型损失函数,最 小 二 乘GAN (Least Squares GAN,LSGAN)[17]方法可以解决梯度消失的问题.经过实验发现模型会出现过拟合的情形,因此本文引入L1正则项避免模型出现过拟合的现象,同时也可加速模型的收敛.由于本文所提出的T-GAN网络同时对语音和音乐进行训练,所以要在损失函数中引入两个L1正则项,并由参数λ1和λ2控制正则项分别对目标语音和干扰语音进行约束.此外,本文以混合语音信号xm代 替loss函数中的辅助信号xc.最终模型损失函数为:

式中:x˜1=G(z,Xm) ,x˜2=Xm-G(z,Xm)
3 实验及结果
3.1 实验数据以data_thchs30数据集作为实验的语音数据集.该数据集时长30 h,包含40位左右的实验人员和11 000条语音.同时,本文使用MIR-1K数据集作为实验的背景音乐数据集.MIR-1K数据集时长133 min,该数据中每段语音都是双通道语音,其中一个通道是歌声,另一个通道是背景音乐,每段语音时间从4 ~13 s不等.其中音乐由110首卡拉OK歌曲构成,包含混合曲目和音乐伴奏曲目.而卡拉OK歌曲由8位女性和11位男性演唱的5 000首中国流行歌曲中进行自由挑选.本文随机选取350条语音作为实验数据,且相互之间说话内容不同,并从MIR-1K数据集中选取与语音等长时间的音乐作为背景音乐,再随机抽取300条语音作为训练集,剩余的50条语音作为测试集.
3.2 实验设置实验采用16 kHz对训练集和测试集数据进行采样,并提前对所有数据进行分帧加窗预处理,其中帧长设置为64 ms(每帧采样点数为1 024),帧移为32 ms.本文提出的模型结构中G有11个卷积层,每层卷积核大小为31,步长为2.编码阶段每层对应的特征图大小为:1 024×1、512×32、256×64、128×128、64×256、32×512;解码阶段卷积层对应的特征图大小为64×256、128×128、256×64、512×32、1 024×1.由于模型生成器采用跳跃连接结构,因此,反卷积层特征图加倍.D的网络设置与G的编码阶段类似,因为D是将分离的语音和纯净的语音输入到网络中进行判别,所以D有两个1 024×1维的输入通道.模型训练时采用RMSprop优化算法,其训练批次设置为50,学习速率为0.000 1.本文把批次大小设置为16、32、64, 经过多次实验发现设置为32时模型达到最优.为了探究正则项与G的损失函数在数量级上的关系,本文以语音为目标语音在5 dB信噪比下对正则项的系数进行了实验对比,其数据如表1所示.

表1 不同正则项系数评价指标对比Tab.1 Comparison of different regular term coefficient evaluation indicators
表1中λ表示正则项系数,PESQ( Perceptual Evaluation of Speech Quality)表示语音质量感知评估[18].由表1中数据可知,将λ设置为100时模型达到最优.若λ太小则无法缩小分离语音与纯净语音之间的差距,太大则会忽略D对G的反馈作用.
本文采用文献[11]中的CED方法和加入文献[13]中的TCN结构的方法,以及在全卷积网络编码器中加深度特征聚合结构3种方法作为对比实验,展示所提出模型的效果.本文把CED方法记为CED,加特征聚合结构的方法记为CED-1,只加TCN的方法记为T-GAN-0,本实验提出的T-GAN网络结构记为T-GAN.本文构建基于3种对比网络的数据集,并且把训练迭代次数、学习率、批次大小、优化算法等都和本文提出的模型保持一致.
3.3 实验结果与分析实验以语音质量感知评估(Perceptual Evaluation of Speech Quality,PESQ)[18]、短时客观可懂度 ( Short-Time Objective Intelligi[19]、源信号失真比(Source to Distortion Ratio SDR)[20]3种评估方法作为音域分离的评价标准.PESQ用于评估语音分离后的总体质量,STOI用于评估语音客观可懂度,SDR用于评价语音信号分离后整体的失真情况.以语音为目标语音和以音乐为目标语音的实验数据如表2、3所示.

表2 以语音为目标语音4种方法在不同信噪比下的评估值Tab.2 Evaluation values for four methods with different signal-to-noise ratios using speech as the target speech

表3 以音乐为目标语音4种方法在不同信噪比下的评估值Tab.3 Evaluation values for four methods with different signal-to-noise ratios using music as the target speech
由表2、3中数据可以看出,本文提出的T-GAN方法在0 、5 、10 dB 3种信噪比下均优于基线CED、CED-1和T-GAN-0 方法.由表2中数据可以看出,PESQ值平均提高了0.31,STOI值平均提高了0.07.当信噪比为0 dB和10 dB时,CED方法优于CED-1方法,而信噪比为5 dB时则劣于CED-1方法.由于本文模型是基于语音和音乐联合训练,在0 dB时干扰语音太强,目标语音特征不明显,而在10 dB时干扰语音不太突出,所以造成了CED-1会劣于原始CED网络结构.在5 dB时目标语音和干扰语音特征相似,联合训练结构能很好地对语音进行训练,使D对干扰语音的特征也能更好判别,进一步增加干扰语音的分离.而T-GAN-0和TGAN两种方法则在3种信噪比下皆优于CED这种依靠期望信号监督的方法.
由表3中数据可知,PESQ值平均提高了0.15,STOI值平均提高了0.03.在0 dB条件下CED-1方法劣于CED方法.对于音乐为目标语音时,特征比较明显,因此在高信噪比下T-GAN方法优于其他3种方法.在低信噪比下噪声语音特征突出,而目标语音音乐比较杂乱,导致T-GAN网络不能很好地学习目标语音的特征,从而分离效果不明显.表3中以音乐为目标语音相对于表2中以语音为目标语音时整体的分离效果稍差.
图6绘制了以语音为目标语音在5 dB信噪比下本文所提模型和其他基线模型音域分离后的语谱图.由图6中的(b)、(c)两个子图可以看到CED方法和CED-1方法在低频和高频分离效果都不是很好,这是因为CED方法和CED-1方法依据干净的目标语音和经过生成器分离的目标语音之间的误差来进行参数更新,导致获得的分离特征有限,分离效果不佳.而T-GAN-0和T-GAN方法在高频部分分离的效果要比CED方法和CED-1方法好,其中T-GAN方法由于在编码器结构中使用深度特征聚合结构,因此恢复语音时得到的语音信息更加完整,更接近目标语音,同时分离效果也比T-GAN-0方法分离效果好.

图6 5 dB信噪比下语音分离的语谱图Fig.6 Spectrogram of human voice separation under 5 dB signal-to-noise ratio
4 结论
本文提出一种基于时序卷积生成对抗网络的单通道音域分离方法,利用时序卷积网络增加了高维时域特征信息的相关性,提高了生成器的分离性能.同时,对噪声语音和目标语音进行联合训练,并在编码器中使用深度特征聚合的方法帮助解码器对分离的语音进行还原.实验结果表明,在MIR-1K和data_thchs30数据集上与基线方法相比,基线方法在高频部分分离效果不好,而本文所提模型能有效提升音域信号高频部分的分离效果.
