异质网络中融合多类信息的链路情感倾向预测
2023-02-04蒋希然周丽华王丽珍陈红梅
蒋希然,周丽华,王丽珍,陈红梅,肖 清
(云南大学 信息学院,云南 昆明 650500)
互联网应用如豆瓣、淘宝等逐渐渗入人们的日常生活,成为人们获取信息、表达观点、交流交易的网络活动平台,由此产生的大量网络平台数据被广泛应用于链路预测、推荐系统等研究领域.由于网络平台数据的内容复杂多样且通常蕴含着丰富的语义,如平台用户对平台相关物品的评分、评价等数据不仅能够表示用户与物品间存在关联,还能反映出用户对于物品的喜欢或不满的情感倾向.在利用数据进行分析研究时,相比于将数据建模为同质网络[1],基于多类型对象和多种关系链路共存的异质网络进行研究,能够保留更全面的语义及结构信息,提高研究工作的可解释性和准确率[2].
链路情感倾向预测即是对网络平台上存在关联的两个对象之间情感倾向的预测,如豆瓣用户对于观看过的电影或书籍是否喜欢,淘宝用户对于购买的商品满意与否等.对基于平台数据所构建的异质网络,利用网络链路中的情感倾向信息能够帮助社区网站的用户找到适合的兴趣小组,指导网络零售平台合理调整宣传策略,还有助于社会学、心理学等领域的研究应用.因此,针对异质网络中链路情感倾向的研究具有很强的现实意义.
现有的链路情感倾向预测方法主要分为基于协同过滤的方法、基于矩阵分解的方法及基于网络嵌入的方法.协同过滤的方法[3-5]利用节点间的相似度来进行预测,这类方法通常以余弦相似度、欧式距离等方式来判断节点相似性,未对用户行为进行深度挖掘.此外,该方法对稀疏的评分矩阵及冷启动的问题处理效果欠佳.矩阵分解的方法[6-9]将高维的评分矩阵映射为节点的低维特征矩阵,能处理冷启动问题.但这些方法都忽略了节点本身的属性特征,且模型不具有很好的可解释性.网络嵌入的方法首先学习网络节点的低维潜在特征,再用学到的节点特征来完成预测任务[10-11].很多研究者提出了不同的网络嵌入方法[12-15],这些方法能够捕获网络拓扑、节点属性等信息.由于不同的网络嵌入方式对信息提取的侧重点不同,且仅利用网络嵌入难以精准捕获到预测所需的全部信息,因此网络嵌入的方法常与其他方法结合完成预测任务.
基于以上原因,本文提出一种异质网络中融合多类型信息的链路情感倾向预测模型,简称为HNPS模型.模型首先对节点间链路的情感倾向进行粗略评估,用于设置链路的预测基值,然后分别从节点的相似关系及节点的属性数据中提取信息,最后将所得信息与链路的预测基值结合完成预测任务.模型中预测基值的设置通过分析节点的交互数据完成,是节点间情感倾向差异性的初步体现.对于新加入的节点,模型利用网络链路中情感倾向的总体情况设置预测基值,有效缓解了因节点信息缺失导致的冷启动问题.模型融合的信息包括相似节点的情感倾向信息以及节点的属性信息,多种信息的融合能够全面揭示影响链路预测的因素,从而有效提升预测结果的准确性.其中,在捕获网络中的相似节点时,本文提出了一种基于限制路径类型元路径的遍历游走方法,该方法能通过约束链路类型提取有特定情感联系的节点.
本文主要贡献如下:
(1)提出了一种异质网络中融合多种类型信息预测链路情感倾向的模型,模型利用节点的交互信息设置预测基值,并融合相似节点的情感倾向信息及节点的属性信息完成预测任务;
(2)提出了一种基于限制路径类型的元路径从异质网络中捕获相似节点的方法,该方法对节点关系的利用更加充分,能提取到更精确的信息;
(3)在5个公共数据集上进行了充分的实验,实验结果证实了HNPS模型的有效性及对于稀疏矩阵及冷启动问题的处理能力.
1 相关工作
1.1 基 于 协 同 过 滤 的 预 测传统的协同过滤(Collaborative Filtering, CF)算法根据基于用户或基于项目分为两类[16].基于用户的协同过滤算法[17]通过发现用户群中与目标用户行为相似的邻居用户,并综合这些邻居用户对某一项目的情感倾向,推断目标用户对特定项目的情感倾向.基于项目的协同过滤算法[5]认为,用户对不同项目的情感倾向存在相似性,当需要预测用户对某个项目的情感倾向时,可以通过用户对该项目的若干相似项目的情感倾向进行推测.此外,部分研究工作将基于用户及基于项目的协同过滤结合起来,形成混合的协同过滤模型[18],能有效提升预测效果.基于神经网络的协同过滤通用框架(Neural Collaborative Filtering, NCF)[19],将深度学习引入协同过滤算法中,补充了用于协同过滤的主流浅层模型,为基于深度学习的情感倾向预测方法开辟了新的研究途径.
1.2 基于矩阵分解的预测基本矩阵分解(Basic Matrix Factorization,Basic MF)[6]也称为隐语义模型(Latent Factor Model,LFM),是最基础的矩阵分解方式.正则化矩阵分解(Regularized MF)[6]通过加入正则化参数解决基本矩阵分解的过拟合问题.基于概率的矩阵分解(Probabilistic Matrix Factorization,PMF)[8]方法则引入概率模型对矩阵分解进一步优化.Bias SVD模型[6]在基本矩阵分解模型的基础上加入了用户及物品的偏置项,SVD++算法[7]在Bias SVD算法的基础上加入了用户的隐式反馈.BMFDE模型[20]通过引入用户嵌入随时间的偏移规律对PMF模型进行了扩展.除此之外,还有很多不同形式的矩阵分解方法的模型变形,这些方法为解决链路情感倾向预测问题提供了不同的思路.
1.3 基 于 网 络 嵌 入 的 预 测在 网 络 嵌 入 方 法 中,Deepwalk模型[12]是开拓性的研究,它通过深度优先搜索的随机游走方法生成节点序列.Metapath2vec模型[13]将基于元路径的随机游走形式化,构造出节点的异质邻居节点序列,利用异质的跳字模型(Skip-Gram)[21]生成节点的嵌入.HERec模型[10]将Metapath2vec模型的嵌入方法进行改进后,结合矩阵分解的方法完成评分预测及推荐.HopRec模型[22]利用外积对用户与项目节点间的成对关系进行建模,从而对HERec模型进行改进.SHINE模型[11]是针对用户对于公众人物的情感倾向进行的预测,模型利用六层的自编码器分别对情感链路网络、社会关系网络及人物特征网络进行嵌入,再将结果聚合后用于完成预测.这些方法通过不同形式的网络嵌入对数据信息进行挖掘,为准确预测链路情感倾向提供条件.
2 HNPS模型
2.1 相关概念在异质网络[23]G={V,E}中 ,V为节点集合,E为链路集合, φ:V→A以 及 φ:E→R为节点类型及链路类型的映射函数,A和R分别代表节点和链路的类型集合.
元路径[24]P是在网络模式[23]Q=(A,R)上定义的路径,若两节点类型间没有多种节点关系,则利用节点类型表示元路径,记为P=A1A2···Al.节点和链路具体化的元路径p称为元路径实例.基于元路径的随机游走是指节点根据给定的元路径在网络中不断转移的过程[13].
限制路径类型的元路径是指对节点之间关系的类型进行了限制的一种扩展的元路径,记为:P(R)=A1(R1)A2(R2)···(Rl-1)Al.当 节 点 类 型Ai与Ai+1间存在多种节点关系时,限制路径类型的元路径P(R)仅 选取节点关系为Ri的路径作为路径实例.
遍历游走是指对于根节点vi,依次访问其邻居节点集Ni中的每个节点.给定一条限制路径类型的元路径P(R)=A1(R1)···At(Rt)At+1···(Rl)Al+1,基于P(R)在 异质信息网络G={V,E}上遍历游走时,要求初始节点vi(1)=vi满足 φ(vi)=A1,此时T1=vi.对于第t步的节点集Tt,遍历其中的节点得到第t+1步的节点集合:At+1,vy∈Nx,rx,y=Rt} ,其中Nx表 示节点vi(t)=vx的邻居节点集,rx,y表 示节点vx与节点vy的节点关系.整个遍历游走的过程根据给定的限制路径类型的元路径P(R)进 行,直至完成节点集Tl的 遍历得到Tl+1,游走过程结束.
2.2 模型框架HNPS模型的整体框架如图1所示.模型引入了预测基值,并融合反馈信息来进行预测.其中,预测基值根据节点的历史评分数据设置,能初步反映不同节点间情感倾向的差异性.反馈信息包括显式及隐式反馈信息.显式反馈指能明确反映用户情感倾向的信息,如评分数据.模型利用基于限制路径类型元路径的遍历游走方法从中找到兴趣相似的用户及内容相似的项目.隐式反馈指不直接表现节点的情感倾向的信息,如节点属性.模型基于元路径的随机游走方法从中学习节点表征.模型将从评分数据及节点属性中提取到的信息与预测基值结合起来,经过不断迭代训练后得到最终的预测结果.
2.3 预测基值的设置现实生活中,用户对即将接触的事物存在一个预期的情感倾向值,通常用户与事物最终所建立链路的情感倾向会基于这个预期值上下波动,即当事物的表现高于用户预期时,用户与事物间链路的情感倾向会高于预期值,反之则低于预期值.模型引入预测基值bu,m作 为节点vu与vm之间链路的预期情感倾向值,计算方式为:

式 中:Nu,Nm分别表示节点vu及vm的邻居节点,分别表示对节点vu及 节点vm的所有评分数值求和,Y分数据集,表示对评分数据集中的所有评分数值求和.

图1 HNPS模型整体框架图Fig.1 The overall framework of HNPS model
2.4 显式反馈的信息提取模型基于评分数据集Y构建出一个异质网络Gr={V,Er},其中V为包含用户及项目的节点集,Er为不同评分转化的节点间不同类型链路的集合.利用限制路径类型元路径的遍历游走方法可以从Gr中找出节点的相似节点,并计算出节点间的相似度.设置用于提取信息的限制路径类型元路径集合:Wr={P(R)|P(R)=Ai(Rk)Aj(Rk)Ai,k=1,···,|RY|},其中Rk表示第k种 评分,|RY|为评分的类型数.节点va的 相似节点集Sa以及节点间相似度值的集合Z由算法1得出.
算法1节点的相似节点集与节点间相似度的算法
输入Gr={V,Er};Wr;va;Z
输出Sa,Z
1 初始化Sa=[];
2 forP(R) inWrdo
3 if φ (va)=Aithen
4 根据P(R)遍 历游走Gr得到节点集Sa;
5 对于Sa中 节点va′,计算va与va′间路径实例的条数sa,a′,将其添加进Z中;
6 end if
7 end for
8 returnSa,Z.
在算法1中,Sa中 包含了与va相 似的节点,Z中保存了节点间相似度值的信息,sa,a′∈Z表示节点va与va′间的相似度.
2.5 隐式反馈的信息提取节点的属性信息能辅助情感倾向的预测.例如,某用户十分欣赏诺兰导演的艺术风格,因此会对诺兰执导的《星际穿越》、《盗梦空间》等电影表示喜欢.从节点属性信息中能够学到节点表征,在预测时用于描述节点属性对链路情感倾向的影响.
模型利用节点属性信息构建异质网络G={V,E},并设置用于提取节点属性信息的元路径P=A1A2···Al.根据metapath2vec++模型[13],节点基于单条元路径的嵌入由算法2得出.
算法2节点基于单条元路径的嵌入算法
输入G={V,E}; 元路径P;路径长度wl;节点嵌入维度d;游走次数wt; 近邻数ns
输出节点基于单条元路径的嵌入
1 初始化
2 forvainVand φ (va)=A1do
3 fori=1→wtdo
4 找到第i条 路径实例pi;
5 基于pi利用跳字模型(SkipGram)[12]迭代更新
6 end for
7 end for
8 return
模型设置了多条元路径来提取节点不同属性的信息,最终的节点表征是对各条元路径所提取到的节点嵌入进行融合后的结果.根据HERec模型[10],采用个性化非线性融合函数对各元路径提取的节点嵌入进行融合,得到节点va的表征:

式中:W为用于提取信息的元路径集合,P为其中的元路径,M(P)∈RD×d及b(P)∈RD分别为对于元路径P的变换矩阵和偏置向量,为节点va对于元路径P的偏好权重,即sigmoid函数,为个性化非线性融合函数.
2.6 链路情感倾向预测HNPS模型结合预测基值及提取到的信息进行预测.节点vu与vm之间链路情感倾向的预测值rˆu,m为:

式中:bu,m为 节点vu与vm间的预测基值,由式(1)计算得出;Xu(vm) 及Xm(vu)为节点的预测偏离值,由式(4)计算.αu及 αm为对节点预测偏离值的调整系数;为节点vu与vm的表征,按式(2)的方式融合节点嵌入后得出; βu及 βm为对节点表征的调整向量.
节点的预测偏离值通过节点的相似节点来计算,节点vx关于节点vy的预测偏离值为:

式中:vx′为 节点vx的相似节点,即vx′∈Sx,rx′,y表示节 点vx′与vy间 实 际 的 评 分 值,bx′,y为 节 点vx′与vy间的预测基值,sx′,y为 节点vx′与vy的相似度.
模型中的参数通过设置损失函数对模型进行不断训练后得出.损失函数为:

式中: 〈vu,vm,ru,m〉为评分数据集Y中的一条数据;ru,m为 用户vu对 项目vm的 实际评分值;rˆu,m为 用户vu对项目vm的 预测评分值,由式(3)计算得到;λ为正则化参数; Θu及 Θm分 别为节点vu与vm嵌入融合时的参数.
使用随机梯度下降(Stochastic Gradient Descent,SGD)的方法来训练模型参数,参数更新方式为:

式中:L为损失函数,即式(5),ωi表示损失函数中的参数包括 α,β,Θ经 过i次 迭代后得到的值,γ为随机梯度下降迭代时的学习率.
整个HNPS模型的算法框架如算法3所示.
算法3HNPS模型
输入评分数据集Y;学习率γ ;正则化参数λ;元路径集W
输出对节点预测偏离值的调整系数集 αV,对节点表征的调整向量集 βV,个性化非线性融合函数中的参数集ΘV
1 初始化参数集中的参数 α ,β,Θ,随机排序评分数据集Y;
2while 结果不收敛 do
3 选取一条评分数据〈vu,vm,ru,m〉;
6 由式(6)迭代更新参数集中的参数α ,β,Θ;
7 end while
8 return αV,βV,ΘV.
3 实验及分析
3.1 数 据 集实验使用的5个数据集分别为:MovieLens(源于https://grouplens.org/datasets/movie lens/);Amazon(源于 http://jmcauley.ucsd.edu/data/ama zon/);Douban Movie(源于http://movie.douban.com);Douban Book(源于http://book.douban.com);Yelp(源于 http://www.yelp.com/dataset-challenge).其 中,MovieLens和Douban Movie属于电影领域,Amazon属于商品领域,Douban Book属于书籍领域,Yelp属于商业领域.数据集中包含了用户对项目的评分以及与用户、项目的属性信息等.各数据集情况见表1.其中,数据集密度指评分矩阵中非零元素比例,即: 数 据集密度=
5个数据集中用户对于项目的评分范围皆为1~5分,统计各数据集评分的分布情况,结果如图2所示.由图2可知,对于所有数据集,评分主要集中在3~5分,1分及2分所占的比例不超过20%.
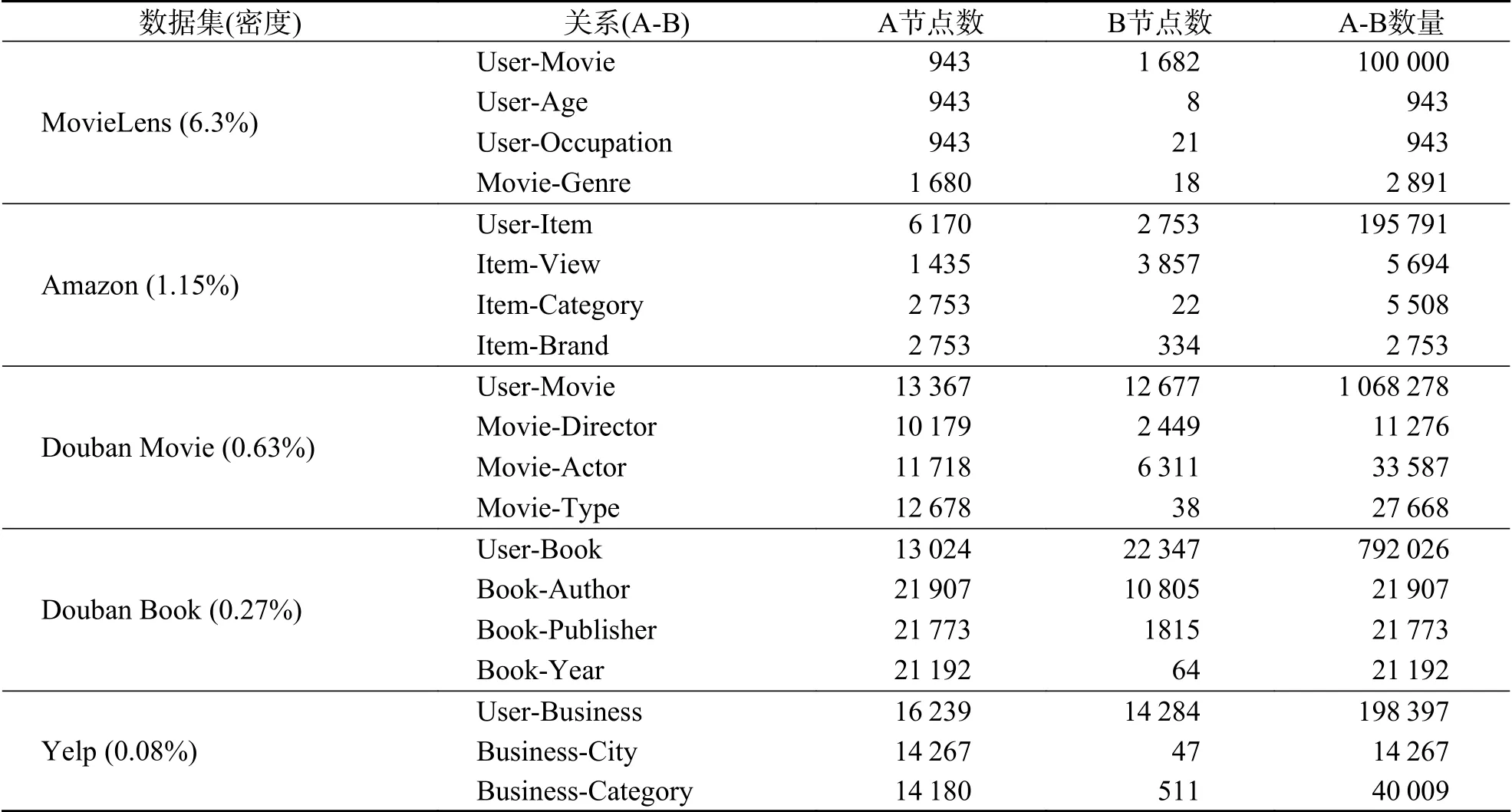
表1 数据集情况统计Tab.1 Statistics of data sets

图2 各类型评分的分布情况Fig.2 The distribution of various types of scores
3.2 评 价 指 标本文使用平均绝对误差(Mean Absolute Error, MAE)及 均 方 根 误 差(Root Mean Square Error, RMSE)作为模型质量的评价指标,计算方式分别为:式中,n为 样本的数量,yj为真实评分值,为预测评分值.MAE及RMSE的值越小,表示预测结果的偏离越小,即模型性能越好.
3.3 对比方法本文分别从基于协同过滤、矩阵分解、奇异值分解以及异质网络嵌入的评分预测模型中选取了4个具有代表性的方法来作为对比方法.选取 的方法包括Item-based CF[25]、PMF[8]、SVD++[7]、 HERec[10]及HNPS.在上述5种方法中,PMF、SVD++及HERec方法包含了对评分数据不同形式的矩阵分解,而Item-based CF及HNPS方法则聚焦于从评分数据中获取存在相似行为的节点.在实验过程中,Item-based CF、PMF及SVD++方法仅使用了数据集中的评分信息,HERec及HNPS模型还引入了节点的属性信息.
对于HERec及HNPS模型,在提取节点属性信息时需设置元路径,不同元路径表示的语义不同,提取到的节点属性信息也不相同.例如对于MovieLens数据集,元路径“UMU”包含的语言信息为“看过同一部电影的用户”,“MUM”则表示“同一个用户看过的电影”.HERec[10]的研究表明,较长的元路径所代表的语义相对复杂,且可能在提取信息时引入噪声,因此元路径的设置并非越长越好.本文实验选取的元路径详见表2.

表2 5个数据集中选用的元路径Tab.2 The selected meta-paths for five datasets.
3.4 实验结果设置不同的训练比率将评分记录分为训练集和测试集.对于每个训练比率,随机生成5组包含训练集和测试集的评估集,将选用的模型分别运用于这5组评估集,取5组评估集上实验结果的平均值作为最终的实验结果加以呈现.对于MovieLens、Amazon、豆瓣电影及豆瓣书籍数据集,设置训练比率为80%、60%、40%、20%;对于数据集YELP,由于评分数据十分稀疏,设置训练比率为90%、80%、70%、60%[10].
SVD++、HERec及HNPS模型中都包含了随机梯度下降的方法,实验统一设置学习率为0.93.对于异质网络中节点嵌入的融合,根据HERec模型[10]的表现,对所有数据集的实验都设置融合后的节点表征维数为10,而HNPS模型的实验对5个数据集分别设置融合后的节点表征维度为50、25、15、10、5.实验结果如表3所示.
基于表3,可以得到:
(1)Item-based CF算法无法处理新加入的节点,即,模型无法对训练集中未包含的节点进行预测.随着训练集密度降低,测试集中出现未训练节点的概率增大,而只要测试集中出现未训练的节点,算法将无法正常运行,从而无法得出预测结果,这个问题通常被称为冷启动问题,表3中的 “Null”表示存在冷启动问题.在参与对比的方法中,除了Itembased CF算法以外,其余模型均能正常处理冷启动问题.

表3 5个数据集的有效性实验结果Tab.3 Results of effectiveness experiments on five datasets
(2)HNPS模型及SVD++模型在两个评价指标上的效果普遍好于其余3个模型,说明相比利用物品间的相似度或对评分数据进行矩阵分解,设置预测基值的方式能有效提升预测准确度及稳定性.
(3)对于MAE指标,HNPS模型在多数情况下表现最好,其次是SVD++模型,而对于RMSE指标则是SVD++模型表现较好,HNPS模型次之,说明将预测基值细化到具体节点并结合多类信息能预测得更加准确,而奇异值分解的方法则能使预测结果更加稳定.
(4)当训练集密度较低时,PMF模型及HERec模型的预测准确度及模型稳定性都不如HNPS模型,说明矩阵分解的方法在训练数据较稀疏时效果并不理想,而SVD++模型在相同情况下却有好的表现,说明预测基值的引入使模型在训练数据较少即矩阵稀疏的情况下仍然适用.
(5)HERec模型的预测准确度及模型稳定性,指标都优于同样使用了矩阵分解方法的PMF模型.随着训练比率增加,HERec模型的预测准确度及稳定性指标提升效果最明显,同样采用了异质网络嵌入方法的HNPS模型相比SVD++模型在后4个数据集上的指标提升速度也更快,说明从异质网络中提取的节点属性信息对于提升模型的预测效果是有用的,且在训练数据丰富时能发挥更大的作用.
3.5 模型及参数分析
3.5.1 冷启动问题 冷启动问题通常发生在数据集较稀疏或数据的训练比率较低时.将冷启动问题按新加入节点的类型细分为仅引入新用户(U)、仅引入新项目(I)及同时引入新用户及新项目(U&I)3种.设置前4个数据集的训练比率为20%,设置Yelp数据集的训练比率为60%,从测试集中筛选出存在冷启动问题的数据用于探究不同模型处理各种冷启动问题的效果,实验结果如表4所示.表中“Null”表示算法未正常运行,“Empty”表示测试集中未找到对应数据.由表4可知,Item-based CF算法不能预测新用户的情感倾向,其余方法对各种类型的冷启动问题都能处理.对比各方法的实验结果,HNPS模型及SVD++模型在遭遇冷启动问题时仍能进行相对准确的预测,而PMF模型及HERec模型的表现则普遍欠佳,这进一步说明了预测基值的设置对于解决冷启动问题是十分有效的.
3.5.2 预测基值的设置 预测基值是对预测结果的粗略估计.通常选取平均值、中位数、众数等描述数据趋势的统计量来设置.由图1可知,评分大多集中在3~5分,即情感倾向的预期值普遍高于评分区间的中位数,但并未特别集中于某个评分值,因此,相比中位数或众数,使用所有评分数据的均值作为预测基值能更加贴近实际的预测结果.在此基础上,HNPS模型将预测基值的设置细化到具体的节点,通过5个数据集来对比采用所有评分数据的均值作为预测基值(Avg)和按HNPS模型的方法设置预测基值(Base)对指标MAE及RMSE的影响,结果如图3所示.由图3可知,HNPS模型的预测基值设置方法能有效提升预测效果.
3.5.3 显式反馈信息及隐式反馈信息对预测基值的调整效果 为了探究两种反馈信息对于模型预测效果的影响程度,本文在5个数据集上进行了4种实验:①直接使用预测基值进行预测(记为Base);②仅使用显式反馈信息对预测基值进行调整(记为BE);③仅使用隐式反馈信息对预测基值进行调整(记为BI);④同时使用显式及隐式反馈信息对预测基值进行调整(记为BEI).4种实验的结果如图4所示.从图4可看出,对于前4个数据集,两种反馈信息都能提升模型的预测效果,但提升程度有限.Yelp数据集的情况较为特殊,反馈信息的引入反而干扰了模型的预测,说明当数据信息匮乏时,预测基值的合理设置变得十分重要.

表4 5个数据集的冷启动问题实验结果Tab.4 Results of cold-start experiments on five datasets

图3 预测基值对于预测效果的影响Fig.3 The influence of basic estimates on the prediction

图4 反馈信息对预测效果的影响Fig.4 The influence of feedback information on the prediction
4 结语
本文提出一种异质网络中融合多种类型的反馈信息预测链路情感倾向的方法,即HNPS模型.模型引入预测基值,并结合显式反馈及隐式反馈中提取的信息进行预测,能有效提升预测结果的准确度.在信息提取过程中,本文设计了一种基于限制路径类型元路径的遍历游走策略用于捕获网络中具有相似情感倾向的节点.将本文模型运用于5个公共数据集,实验结果证明了HNPS模型的有效性及对于稀疏矩阵、冷启动问题的处理能力.在以后的工作中将进一步探索不同种类信息的提取方法,以解决数据量大,数据内容复杂等带来的挑战,同时也将考虑改进信息融合的方式,使得模型的预测效果能更加稳定.
