图卷积增强多路解码的实体关系联合抽取模型
2023-01-30乔勇鹏于亚新刘树越王子腾夏子芳乔佳琪
乔勇鹏 于亚新 刘树越 王子腾 夏子芳 乔佳琪
(东北大学计算机科学与工程学院 沈阳 110169)
(医学影像智能计算教育部重点实验室(东北大学) 沈阳 110169)(1901770@stu.neu.edu.cn)
目前为了构建大型结构化的知识图谱,大量研究致力于从无结构化文本中抽取出实体关系三元组,这样的三元组通常由一对实体和实体之间的语义关系组成[1],如〈China, capital, Beijing〉,表示“中国的首都是北京”.迄今为止,现有模型主要致力于实现一对实体间语义关系识别的关系抽取或关系抽取任务.Zeng等人[2]和Xu等人[3]提出在识别出实体的基础上进行关系抽取,但该方法忽略了对实体抽取的研究.为了对文本中的实体和相应关系实现同时抽取,Chan等人[4]提出了一种流水线处理方法,首先对无结构化文本进行命名实体识别,而后在实体被识别的基础上再进行关系抽取,由于这类方法以命名实体识别和关系抽取的先后顺序进行,因此忽略了这2个子任务间的关联.Li等人[5]和Miwa等人[6]考虑到上述子任务之间存在相关性,提出预先设计并筛选有利于模型训练的特征,实现将2个子任务联系在一起的目标,但这2个子任务严重依赖现有自然语言处理工具和复杂特征工程.随着深度学习技术[7]在一些自然语言处理任务上的成功应用,实体关系抽取也渐渐与深度学习相结合.Xu等人[3]将循环神经网络和卷积神经网络用于关系抽取;Zhang等人[8-9]将关系抽取任务视为一种端到端表格填充问题;Zheng等人[10]则提出一种以循环神经网络为基础的序列标注模型并将其应用到实体关系联合抽取中.
实体关系抽取在近些年虽然得到长足发展,但是当前大量研究忽略了句中三元组存在很多关系重叠的现象,在这种情况下,现阶段大量以深度学习为基础的模型和以传统特征工程为基础的实体关系抽取模型,并不能完全抽取到目标文本所含的全部实体关系三元组.Zeng等人[11]根据句中实体关系三元组的重叠程度,将关系重叠大致分为3类,即无重叠(normal)、实体对重叠(entity pair overlap,EPO)以及单一实体重叠(single entity overlap,SEO).图1 给出了3类实体关系重叠样例,其中无重叠类型表示句中含有的三元组中没有重复出现的实体;实体对重叠类型表示句中包含1个或多个重复出现的实体对,即同一实体对之间存在着多种关系;单一实体重叠表示句子中有部分三元组包含同一实体,不同于实体对重叠.当前研究的模型大都致力于解决无关系重叠的文本[10],由于这些模型建立在“句中每个词至多只有一个标签”这一假设之上,导致原文本序列中每个词在关系抽取时最多只能出现在一个三元组中,因此这些模型在处理含有关系重叠的文本时通常召回率比较低.例如图1中“单一实体重叠”样例存在2个三元组,即〈Barack Obama,presidentOf,America〉和〈Barack Obama,liveIn,White House〉 , 其 中 〈 Barack Obama,liveIn,White House〉表示“巴拉克·奥巴马居住于白宫”, 〈Barack Obama,presidentOf,America〉表示“巴拉克·奥巴马是美国的总统”.实体“Barack Obama”出现在上述2个三元组中,但目前大多数实体抽取模型只允许文本中的词在抽取三元组时最多出现一次,所以该类模型只能抽取到其中一个实体关系三元组,造成实体关系三元组丢失的问题.
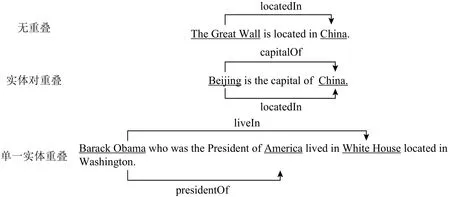
Fig.1 Types of entity relationship overlapping图1 实体关系重叠类型
抽取大量含有重叠实体关系语句的方法,其技术难点在于实体分布密度高以及实体关系交叉互联,主要表现为单个句子包含多个实体,实体间存在多种关系,同一实体会因交叉出现于1个或多个三元组内,因此,抽取模型需要更为关注局部特征和非局部特征的捕捉和融合.Peng等人[12]通过自然语言工具解析文本以构建原语句中的词间依赖关系图,以便根据词与词之间的不同依赖关系赋予不同权重进行特征融合,其中词间关系主要是指通过工具解析生成的句中单词之间的依存关系,依存关系表达了句中各成分之间的语义关系,目标语句中的依存关系构成一棵句法树,树的根节点通常是句子的核心谓词,用来表达句子的核心内容.Sahu等人[13]在文献[12]研究基础上通过文本中存在的共指关系进一步捕捉词与词的依赖关系.其中,共指关系包含实体(entity)和指称(mention)这 2 个概念,指称是实体在自然语言文本中存在的别名或者另一种指代形式.例如,实体“奥巴马”存在“美国总统”“第44任美国总统”“他”等指称,如果在文本或句子中存在上述指称并指代同一个实体“奥巴马”,则它们之间存在共指关系.Dai等人[14]从文本序列先后顺序角度出发,通过位置注意力机制捕捉词与词之间的相对位置关系以实现特征融合.不同于文献[12-14]模型对不同依赖关系的相应赋值操作,本文提出了基于图卷积增强多路解码的实体关系联合抽取模型 (graph convolution-enhanced multi-channel decoding joint entity and relation extraction model, GMCD-JERE),其特征融合是基于双线性变换计算句中词之间的依赖权重,并通过图卷积网络的不断迭代进行特征融合.主流实体关系抽取模型中使用长短期记忆神经网络(long short-term memory network, LSTM), 本 文 引 入 LSTM编码文本序列的上下文特征,同时在解码器中融入标注框架[15],定位实体起始、结束位置.
本文的主要工作及贡献为:
1)提出图卷积神经网络聚合词间依赖信息.当前基于编码器−解码器的联合抽取模型并未充分考虑句中词间的依赖关系,本文基于语句上下文[16]、依存句法[17]等关系,借助图卷积神经网络聚合句中具有依赖关系的词之间的特征信息,提高关系抽取的准确性.
2)提出多路解码实体关系三元组机制.针对语句因多个三元组共享同一实体而产生关系重叠的现象,同时为解决传统解码器解码三元组序列过长造成的误差累积、传播的问题,本文改进为多路生成含有同一实体的多个三元组,有效解决了关系重叠的问题,提高了模型对重叠实体关系的抽取能力,提升了模型的召回率.
1 相关工作
1.1 实体关系抽取相关技术研究
从实体关系抽取所依赖的底层原理来看,实体关系抽取从基于统计学方法演变到基于深度学习模型.现有的实体关系抽取研究大多致力于显式关系抽取,从显式关系抽取所依赖的技术上来看,方法可以分为2类:基于特征工程的方法和基于机器学习的方法.
1)基于特征工程的实体关系抽取方法
早期的实体关系抽取模型大多基于特征工程和传统统计学习方法,其中以构建有效核函数[18-19]为基础的支持向量机模型较为成熟,但是纵观这一类型的方法虽然理论基础较为完善,但是前期需要进行大量的特征工程以抽取有效的特征集,如词性、最短依赖路径,甚至是设计具体的核函数,具体表现为实际的抽取过程中需要依赖大量的人力去筛选适合当前模型学习的特征,可以说人工特征抽取的质量将决定模型性能的上限.
2)基于机器学习的实体关系抽取方法
由于传统特征工程实体关系抽取模型严重依赖于人工筛选大量适合相应模型训练的特征,所以为减少对人工和自然语言处理工具的依赖,一些基于神经网络的模型逐渐成为研究主流方向,其中包括常见的卷积神经网络和循环神经网络.
对于已经标注出实体的文本语句,Hendrickx等人[20]将关系抽取视为关系抽取任务,其中Zeng等人[2]将卷积神经网络引入关系抽取任务,Xu等人[21]通过卷积神经网络和循环神经网络学习到最短依存路径间的关系特征.尽管在关系抽取方面已有大量研究成果,但这些模型仅仅建立在实体已经被识别的基础上,并不能从无任何标注的文本中抽取完整的实体关系三元组.
1.2 实体关系抽取相关流程研究
从实体关系抽取具体流程来看,实体关系抽取经历了从传统的流水线模型到端到端联合抽取模型的演变.传统模型将实体关系抽取这一任务分为命名实体识别和关系抽取两个子任务,以流水线方式先后进行.其中命名实体识别是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等;关系抽取则是探究句中相关实体之间的关系,但该类方法容易造成误差在2个子任务之间累计和传播,影响抽取的准确率.由此,端到端实体关系联合抽取的方法应运而生.
1)基于流水线的实体关系抽取
命名实体识别[22-23]和关系抽取[24-25]是信息抽取中的2个基本任务[26-27],二者的目的都是为了从无结构化的文本中抽取有结构的信息.在联合抽取方法尚未成熟之前,Chan等人[4]基于流水线的方式识别出输入语句中所有实体,并在此基础上组合其中任意2个实体并进行关系抽取.除此之外,大部分现有基于神经网络的方法也是以流水线方式实现,其中包括全监督关系抽取[20]和远程关系抽取[28].虽然Cai等人[29]对Christopoulou等人[30]提出的基于神经网络的方法[31]不断地更新优化,但是不可否认的是,命名实体识别和关系抽取以流水线先后顺序的方式展开所造成的误差累积和传播不可避免地降低了此类实体关系抽取模型的准确率和召回率.
2)基于联合学习的实体关系抽取
由于联合抽取模型将命名实体识别和关系抽取2个子任务紧密结合降低了流水线方法中误差传播造成的影响,近些年研究人员大都致力于联合抽取模型的研究.
传统的联合抽取模型[32]主要以特征工程[33]为主,这类方法[34]严重依赖人工去筛选适合模型训练的特征.为了减少人工操作,研究人员将重心转移到以神经网络为基础的模型上来且这些深度学习模型展现出不俗的性能,但是大量现有的神经网络模型[35]是基于参数共享进行联合学习抽取实体和相应的关系,并没有实现真正的联合解码,也就是说在抽取实体和关系的过程中以流水线方式先进行实体识别而后对实体进行关系抽取,这样分离的解码过程可以看作是2个单独的训练目标,在命名实体识别和关系抽取性能指标上表现较好,但在三元组这一整体上并不能得到较高的准确率和召回率.与这些工作不同是,Zheng等人[10]通过引入统一的标注框架将实体关系三元组抽取转化为端到端序列标注问题,从而在不依赖命名实体识别和关系抽取的基础上实现联合解码同时抽取实体和关系.该方法将实体和关系的信息集成到统一的标注框架中,可以直接在实体关系三元组层面进行建模.
虽然此类联合解码或者非联合解码模型得到了大量关注和研究,但是当前大多数工作忽略了重叠关系三元组的问题,Zeng等人[11]引入了3种重叠三元组的模式,试图通过带有复制机制的序列到序列模型来解决忽略了重叠关系三元组的问题,Fu等人[36]也对该问题进行了研究,提出了一种基于图卷积神经网络的方法.尽管文献[11, 36]这2种方法都取得了初步成功,但是他们仍然将关系视为实体对的离散标签,使得模型很难学习具有重叠关系的实体三元组.
1.3 实体关系抽取研究进展
Miwa等人[6]在对原序列语句进行句法分析构建句法依赖树的基础上提出树形双向长短期记忆网络(tree-structured LSTM, T-LSTM)来建模句中词与词的依赖关系,模型学习到的特征被序列化实体标注器和最短依存路径关系抽取器共享作为输入,但如果要将共享参数引入实体关系联合抽取模型中,则命名实体识别和关系抽取需以先后顺序依次进行,即以流水线方式抽取,而流水线方式抽取造成误差累积和传播会降低模型抽取的准确率和召回率.
Zheng等人[10]针对文献[6]的问题,为避免以命名实体识别–关系抽取流水线方式进行抽取,将关系抽取视为命名实体识别,通常命名实体识别以序列标注方式处理.命名实体识别中序列标注主要包含人(person, PER)、地点(location, LOC)、组织(organization,ORG)这3类标签,而实体通常由1个或多个单词组成,在实际抽取过程中,标签会加上相应的前缀B(begin),I(inside),E(end)来表示单词在实体中的位置,例如B-LOC,I-LOC,E-LOC.因此在将关系抽取视为命名实体识别后,相应地,实体类标签变为关系类标签,例如 B-BI,I-BI,E-BI,其中 BI表示关系“出生于”(born in).Zheng 等人[10]提出的模型忽视了实体关系重叠的情况,且实验中所使用版本的NYT数据集关系重叠类型数据量较小,因此模型性能有所提升.相比之下,Fu等人[36]提出GraphRel模型,将原序列语句中每个词看作1个节点,则该句子视为1个图,通过2阶段图卷积神经网络进行节点间的特征融合,推断节点之间的关系,而该模型并不能较好地解决图1所示实体对重叠类型的关系重叠问题.
Zeng等人[11]为解决关系重叠问题,系统性地提出了图1所示的3种关系重叠类型,在模型中基于BiLSTM(bi-directional LSTM)对原序列语句进行编码,利用编码器最后的隐层状态初始化解码器起始状态.如图2所示,CopyRE以LSTM为基础的解码器在动态解码生成实体关系三元组时,先解码生成关系,而后从句中复制2个单词作为该关系的头实体、尾实体.但该模型解码有一定的先后顺序关系,后生成的实体关系三元组单方向依赖于先生成的实体关系三元组.根据Fu等人[36]提出GraphRel模型,将原序列语句中每个词看作1个节点,则该句子视为1个图,图上节点通过2阶段图卷积网络进行特征融合并推理节点之间的关系,从而解决了实体关系三元组的生成序列存在单方向依赖性问题.
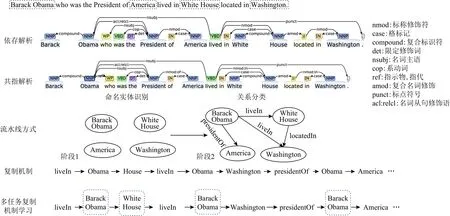
Fig.2 Comparison of related model techniques图2 相关模型技术对比
Zeng等人[37]通过实验分析CopyRE模型并提出2个问题:1)CopyRE对于实体的抽取是不稳定的,需要借助掩码机制遮盖已经生成的头实体,防止在抽取尾实体时又抽取到头实体;2)CopyRE模型仅能抽取出由多个单词组成的实体的最后1个单词.因此,Zeng等人[37]在CopyRE模型基础上提出CopyMTL模型,增加实体标注进行多任务学习,一定程度上解决上述2个问题.
利用图卷积神经网络(graph convolution neural network,GCN)来建模文本中各成分之间的依赖关系越来越多地被应用到自然语言处理中,我们将GCN用于促进跨度较大的文本特征融合.Marcheggiani等人[38]将GCN应用到词序列文本上进行语义属性标注.Liu等人[39]将GCN用于编码长文本和文本匹配等任务,Cetoli等人[40]将循环神经网络和GCN结合进行命名实体识别,Zhang等人[41]和Luan等人[42]则是利用GCN建模词序列之间的依赖关系[43],以此进行关系抽取.
2 变量定义及问题描述
2.1 变量定义
本文中变量定义如表1所示:

Table 1 Variable Definitions for the GMCD-JERE表1 GMCD-JERE模型变量定义
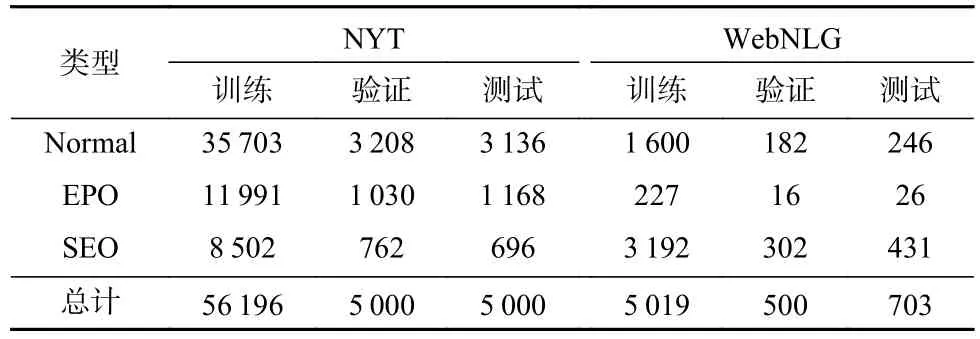
Table 2 Related Information of NYT and WebNLG Datasets表2 NYT和WebNLG数据集相关信息
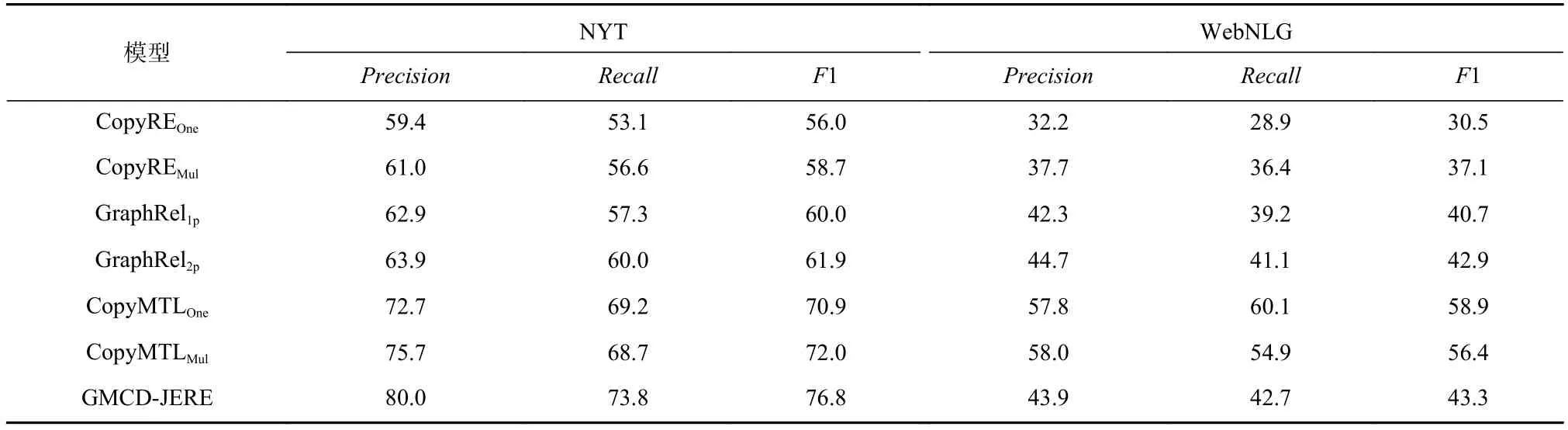
Table 3 Performance Comparison of the Models表3 模型性能对比 %
2.2 问题描述
1)实体关系重叠问题
如图2 所示,例句“Barack Obama who was the President of America lived in White House located in Washington.”中存在2个形式为〈关系,头实体,尾实体〉的三元组,其中〈presidentOf,Barack Obama,America〉表示“巴拉克·奥巴马是美国总统”,〈liveIn,Barack Obama,White House〉表示“巴拉克·奥巴马居住在白宫”,而实体“Barack Obama”出现在上述 2个三元组中.当前模型大都建立在“句中每个词最多仅有一个标签”的假设之上,如图2所示,当前存在的流水线(pipeline)方式按序进行命名实体识别和关系抽取2个过程,当前实体“Barack Obama”和实体“America”被识别存在关系“presidentOf ”后即退出后续关系抽取过程,因此该类模型在实际抽取过程中只能抽取出其中一个三元组,所以存在实体关系重叠的文本无法得到有效地抽取,模型召回率也通常较低.CopyRE[11]通过复制机制在一定程度上解决关系重叠问题,但该模型并不能抽取含有多个词的实体.
2)文本序列词间依赖特征捕捉问题
当前主流模型CopyRE[11]和CopyMTL[37]以编码器−解码器为基础,其中编码器在对原序列语句进行编码后,缺乏对编码特征进行融合以捕捉句级特征并传进解码器进行三元组解码.如图2所示,传统实体关系抽取模型利用句法依存分析工具解构文本中词之间的语义关系,赋予其相应权重进行加权特征统合.而CopyMTL等模型主要依赖自注意力机制,对编码后的序列基于注意力分数加权作为句级特征,但自注意力机制存在一定局限性,主要体现在未充分考虑句中词与词之间的相互依赖关系.
3)长序列解码下误差累积、传播问题
从图2显示的结构来看,CopyRE和CopyMTL是基于Seq2Seq的编码器−解码器模型,解码器解码顺序为〈三元组1,三元组2,…,三元组n〉,其中每个三元组包含关系、头实体和尾实体这3个组成部分,在存在实体关系重叠的情况下,通常存在3个及以上的三元组,而在句中实体较多的情况下,三元组的个数能达到5个以上,而且当前主流模型CopyRE和CopyMTL解码器每次解码仅能生成三元组中的一个元素,造成解码序列过长而带来误差累积和传播,导致模型抽取精确率较低.
3 GMCD-JERE模型
GMCD-JERE模型主要由以LSTM为基础的编码器和解码器构成,如图3所示,其中LSTM作为编码器学习文本序列特征,解码器结合标注框架定位实体首、尾位置,区别于传统解码器〈三元组1,三元组2,…,三元组n〉这样的三元组顺序解码机制,本文采用多路解码实体关系三元组机制,在解码出1个或多个存在于语句中的关系后,在每一种关系下分别抽取符合当前关系的头实体和尾实体,以组合成实体关系三元组.
3.1 模型的编码层
1)基于LSTM的双向编码
本文采用BiLSTM对文本进行编码,如图3所示,在编码器中输入的语句,基于BiLSTM进行编码从而得到语句的上下文特征为如式(1)~(3)所示:
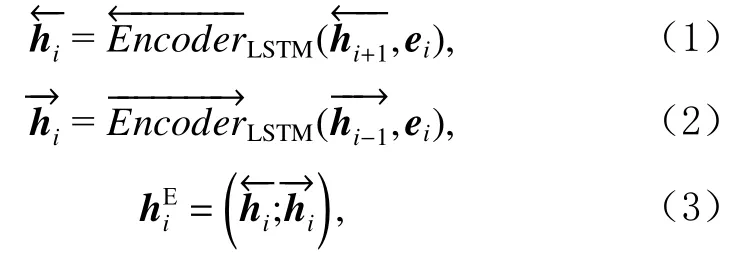
其中ei表 示第i个词的嵌入向量,维度为 1 ×d,为第i个词的双向特征向量,维度为 1 ×2d.式(3)由式(1)(2)中LSTM前向、后向编码输出拼接而得.
2)基于GCN的词间依赖特征融合
以注意力机制为核心的神经网络框架成为近些年来自然语言处理领域的研究热点,传统注意力机制通过学习一组权重向量来表示句中各词的重要性,以此来捕捉句中不同成分、句法的特征,但无法推测句中各个词之间的相互关系,因此本节引入基于具有关系推理能力的GCN.
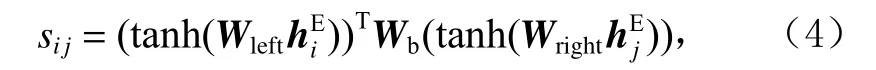
其中Wleft,Wright维度均为d×2d,是2个全连接前向网络的权重参数,Wb维度为d×d,是双线性变换的权重参数.
我们将序列长度为n的语句视为有n个节点的图,M为图中每个节点之间的依赖权重矩阵,如式(5)所示:
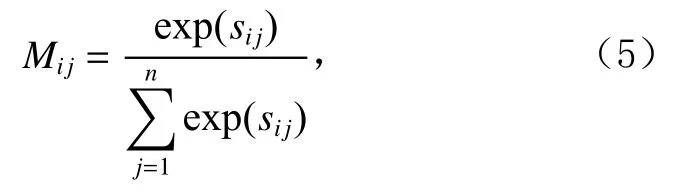
其中Mij表示第i个词与第j个词之间依赖权重.
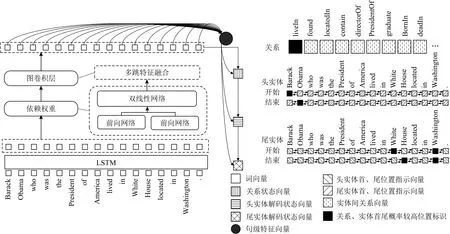
Fig.3 Overall architecture diagram of GMCD-JERE model图3 GMCD-JERE模型整体架构图
根据式(5)得到维度为n×n的邻接关系矩阵M,将第i个节点在第l−1层的隐层向量作为输入,通过式(6)的图卷积操作更新得到该节点在第l层的隐层状态向量.
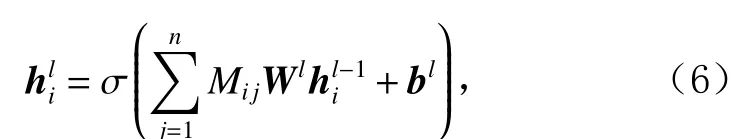
其中Mij是由式(5)计算的图中第i个节点与第j个节点之间的依赖权重,W l和bl分别是GCN的参数矩阵和偏置向量,当l=0时,表示进行图卷积操作前第i个节点的初始隐层向量.图卷积网络主体结构如图3左侧所示,hG为经过图卷积操作后的上下文特征向量.
3.2 模型的解码层
解码器以LSTM为基础,初始输入为hstart,初始化为0.下面将阐述本文模型在〈关系,头实体,尾实体〉顺序下的抽取过程.
1)关系抽取
首先识别句中存在的关系,将编码器的最终隐状态作 为解码器的初始隐状态,与hstart一起输入到解码器进行第1次解码,如式(7)所示;接着通过注意力机制获得融合了卷积层特征的解码器输出o;最后送入关系预测层.具体如式(8)~(10)所示.
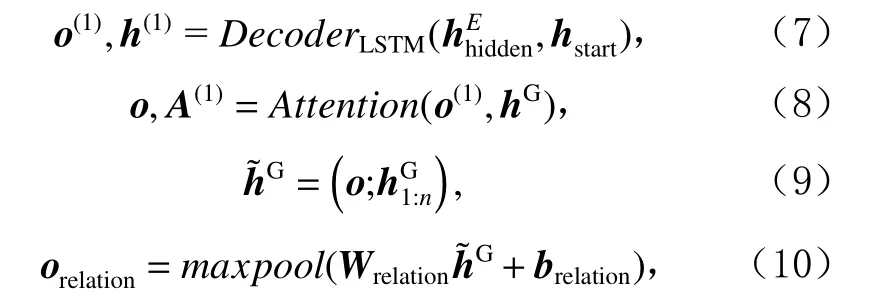
其中,初始输入向量h维度为 1 ×d,o(1)维度为 1 ×d,startWrelation维度为 2d×drelation,drelation为关系集合中关系的种类数.
2)多路分层解码实体三元组机制
假设在上一阶段中抽取出某个关系,其在关系集合中的索引为 λ,通过关系嵌入表示为向量hλ,将其和式(7)中的隐状态h(1)输入到LSTM解码器中,如式(11)所示,通过注意力机制获得融合卷积层特征的解码器输出,最后将其输入头实体首、尾位置的预测层,如式(12)~(15)所示.

其中o(2)的维度为 1 ×d,和的维度均为 1 ×2d.
假设上一步抽取到的头实体的首、尾位置分别为i和j,将对应位置上的卷积输出之和与上一阶段的隐状态输入到解码器中,如式(16)所示,其余过程与头实体抽取类似,如式(17)~(20)所示.
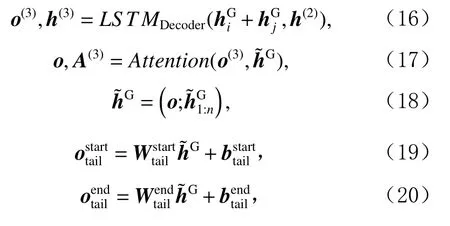
其中o(3)的维度为 1 ×d,和的维度均为 1 ×2d.
3)损失函数
本文使用交叉熵损失函数在训练过程中最小化头实体、尾实体和对应关系的代价之和,如式(21)~(23)所示:
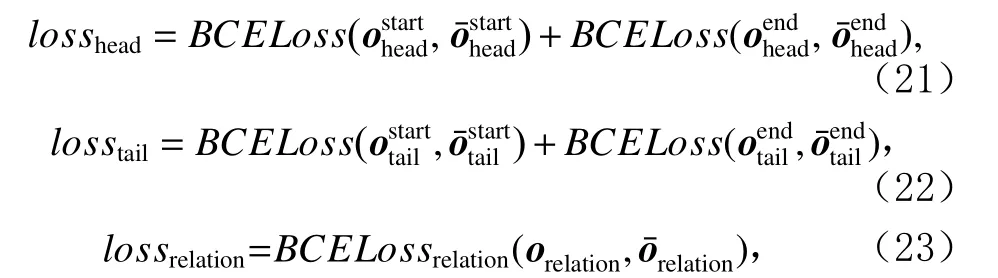
其中losshead,losstail,lossrelation分别为头实体、尾实体以及对应关系与数据集真实值之间的交叉熵代价.
4 性能测试与分析
本节主要在 NYT (New York times)和 WebNLG (Web natural language generation) 这 2 个公开数据集上对所提的GMCD-JERE模型进行性能测试,并将其与目前主流模型进行实验对比.
4.1 数据集与实验配置
NYT数据集是由远程监督生成的英文数据集,包含118万条英文语句和24种预先定义的关系类型.WebNLG数据集最初是由自然语言生成任务产生的数据集,而后由Zeng等人[11]改进用于进行实体关系三元组抽取任务,该数据集包含了246种预先定义的关系类型.这2个数据集中的大部分语句通常包含多个实体关系三元组,所以NYT数据集和WebNLG数据集非常适合用来评价模型在抽取含有关系重叠的三元组语句的性能.本文使用的数据集来源于Zeng等人[11]开源的版本,对于NYT数据集,使用56 196条英文语句来训练、5 000条语句来验证、5 000条语句来测试;对于WebNLG数据集,使用其中5 019条语句来训练、500条语句来验证、703条语句来测试.根据关系重叠类型,将语句划分成Normal,EPO,SEO这3种类型,表2展示了这2个数据集的详细数据.
实验环境及配置为:服务器CPU为Intel Xeon E5-1603,显卡为 Titan Xp,内存为 32 GB,硬盘为 1 TB,操作系统为Ubuntu,开发工具为Pycharm,开发语言为Python,深度学习框架为Pytorch.
4.2 测试指标
与主流模型对比中,使用精确率(Precision)、召回率(Recall)和F1 值作为测试指标,如式(24)~(26)所示.另外,对于抽取的三元组〈关系,头实体,尾实体〉,当且仅当其中每个元素与数据集中的元素相同时视为正确.

其中TP代表抽取三元组中正确的数量,FP代表抽取三元组中不正确的数量,FN代表未抽取出的正确三元组数量.
4.3 基准模型相关技术对比
选用3种类型共6个具体模型作为基准模型来对比验证本文所提出模型的性能,其中包含现有研究中性能较好的CopyMTL模型.基准模型与本文所提出模型在数据集NYT和WebNLG中的整体性能对比结果如表3所示:
1)CopyRE
Zeng等人[11]基于复制机制和Seq2Seq的结构联合抽取关系和实体.其中Seq2Seq结构将目标文本语句作为输入,经一系列处理后输出实体关系三元组序列〈三元组 1, 三元组 2, …, 三元组n〉,从图4 中可以看出,该模型结构简单,通过复制机制在每次解码过程中按三元组组成顺序先抽取关系并在该关系下抽取概率最大的词作为实体.但该模型存在2个缺点:①由于模型采用统一预测分布,其中头实体和尾实体没有本质上的区分,抽取尾实体时如果不对头实体进行掩盖可能会再次抽取到头实体;②只能针对单一词实体,对于包含多个词的实体则无法抽取到完整实体.
2)CopyMTL
CopyMTL模型与CopyRE模型基本一致,主要组成为编码器和解码器.编码器部分使用BiLSTM建模句子上下文信息,解码器部分结合复制机制生成多对三元组,同时解决了CopyRE只能抽取单一词实体,不能抽取多词实体的问题,但解码序列过长带来的误差累积和传播导致模型不易收敛.
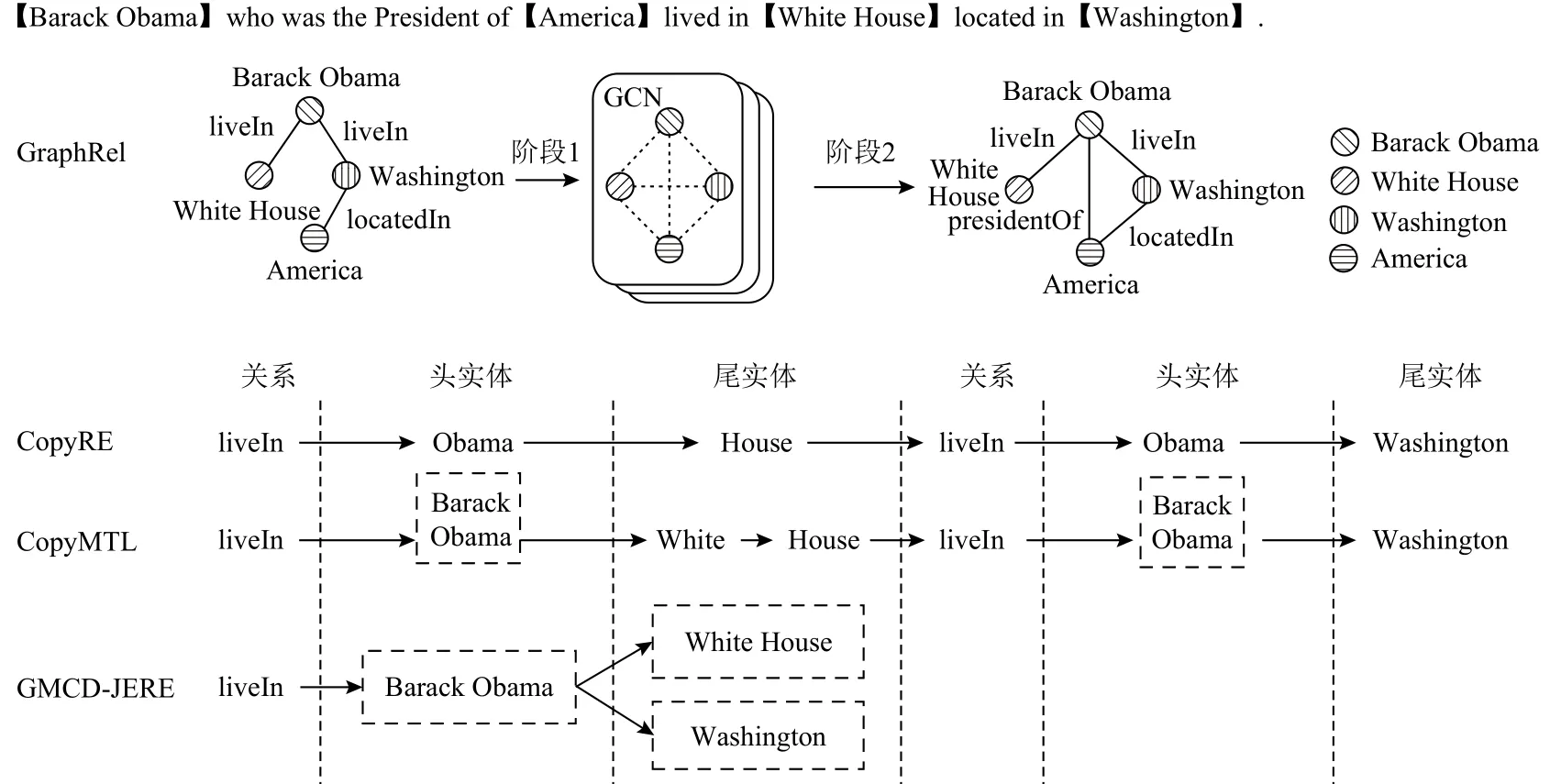
Fig.4 Comparison of baseline model architecture图4 基准模型框架对比
3)GraphRel
GraphRel利用图卷积网络来联合学习命名实体和实体间关系,从图4中可以看出其主要分为2个阶段:①采用BiLSTM和GCN这2种方法分别进行实体标注和关系推理;②基于阶段①的特征融合和关系推理后进行第2轮的实体标注和关系推理,在阶段①的基础上进一步提高模型性能.
4.4 性能测试与分析
如表3所示,从精确率、召回率和F1指标上看出GMCD-JERE在NYT和WebNLG数据集上的表现优于CopyRE模型和GraphRel模型.此外,GMCD-JERE在NYT数据集上相较CopyMTLMul模型,各指标分别实现4.3%,5.1%,4.8%的性能提升.
从模型抽取实体完整性方面看,当前CopyRE模型严格按照〈关系,头实体,尾实体〉先后顺序进行解码,每一步仅能抽取1种关系或1个实体.例如在针对图4例句三元组〈LiveIn,Barack Obama,White House〉的抽取过程中,由于CopyRE模型利用复制机制,即每一步解码仅能选出当前序列中概率最大的一个词,因此对于头实体“Barack Obama”只能抽取其中的“Obama”,对应的尾实体“White House”也同样如此,所以抽取结果可能为〈LiveIn,Obama,House〉,所以该模型不能有效处理含有多个词的实体.针对该问题CopyMTL在CopyRE基础上引入命名实体任务进行多任务学习,虽然在一定程度上缓解该问题,但由于CopyMTL仍属于编码器−解码器模型,解码序列过长带来的误差累积与传播会造成模型抽取精确率的下降.GMCD-JERE模型融合标注框架[15]能定位到实体首、尾位置,有效缩减了解码序列的长度,一定程度上缓解了误差累积、传播的问题,如表3所示,GMCD-JERE在NYT数据集上的精确率上较Copy-MTLMul提升4.3%.
对于关系重叠问题,结合图4来看,虽然CopyRE-和CopyMTL在一定程度上解决了该问题,但解码序列长度会随文本中三元组数量的增加而增加,导致模型抽取精确率随着解码序列长度的增加而降低.GraphRel利用图卷积网络来联合学习命名实体识别和关系抽取.如表3所示,GMCD-JERE对NYT数据集中含有关系重叠问题的样例的抽取较CopyREMul在F1上提升了4.8%.GMCD-JERE模型在解码实体关系三元组过程中,对于原语句序列中词出现的次数没有限制,允许同一实体出现在不同三元组中.如图4例句所示,其中包含2个三元组〈LiveIn,Barack Obama, White House〉 和 〈 LiveIn, Barack Obama,Washington〉,在关系“LiveIn”下 GMCD-JERE解码生成头实体“Barack Obama”,多路解码机制此时基于关系和头实体解码生成“White House”和“Washington”这2个尾实体,由此在一定程度上解决实体关系重叠问题的同时进一步缩短解码序列长度, GMCDJERE在NYT数据集上相较于其他模型各指标均有提升.但在WebNLG上性能并非最佳,通过分析发现,WebNLG数据集的训练样本数量不到NYT的10%,而模型需要学习的参数过多;另一方面,WebNLG数据集中每个实体包含的单词的平均数量比NYT多,所以GMCD-JERE在该数据集上实体抽取的准确性比较低,造成模型整体性能不佳.
研究中发现,CopyRE和CopyMTL模型都是以〈关系,头实体,尾实体〉的先后顺序进行三元组抽取,为了探究该类模型为何以这种顺序进行抽取,同时为进一步验证模型解码器的性能,对于〈关系,头实体,尾实体〉这样的三元组,调整三元组内元素抽取的先后顺序,以验证多路解码实体关系三元组机制的有效性,同时确定最佳抽取顺序.实验中以H(head entity)表示头实体,T(tail entity)表示尾实体,R(relation)表示这2个实体之间关系,实验结果如图5和图6所示.
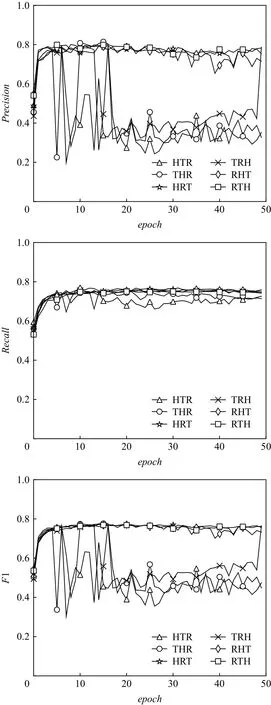
Fig.5 Model performance under different extraction sequences in NYT图5 NYT不同抽取顺序下模型性能
如图5所示,当epoch>5,在RHT和RTH抽取顺序下GMCD-JERE开始收敛,精确率、召回率和F1指标曲线平稳,性能稳定;而在 TRH,THR,HRT,HTR抽取顺序下,模型性能在epoch=5左右虽然能达到上述水平,但在epoch>5后各项性能指标曲线呈现上下振荡.从图5中可以直观地看出在RHT和RTH的抽取顺序下,GMCD-JERE比在其他抽取顺序下性能更稳定,且精确率、召回率和F1这3项数据更优.同样如图6中GMCD-JERE在WebNLG数据集上的性能曲线所示,模型同样在RHT和RTH抽取顺序下精确率、召回率和F1值能达到最高.在WebNLG数据集上,模型在epoch>20后,性能变得平稳,相较于NYT数据集收敛慢,并且根据图5和图6对比可以看出,WebNLG数据集下各模型性能远低于NYT数据集,结合表2从数据集本身来看,原因可能依旧是Web-NLG数据集样本量较少,而NYT数据集中Normal,EPO,SEO这3类语句比例约为4∶1∶2,不含实体关系重叠样本与含有实体关系重叠数据比例则约为4∶3,样本充足且均匀分布,利于模型训练.
经实验发现GMCD-JERE模型在以R为优先抽取的方式下性能较好,如图5所示.在RTH和RHT的抽取顺序下,当epoch>10,模型收敛稳定性能较高,其中精确率维持在80%左右,召回率和F1值最高分别达到73.8%和76.8%,超过当前最优CopyMTLMul模型,而在TRH,THR,HRT,HTR抽取顺序模型收敛性较差,训练后期性能曲线振荡,抽取效果不佳.结合图6中模型在WebNLG数据集下的表现,GMCDJERE仍在以R为优先抽取的方式下性能最优,精确度、召回率和F1值最高实现43.9%,42.7%,43.3%,而在其他4种抽取顺序下精确度、召回率和F1值最高分别为39.3%,38.3%,38.8%,如图5和图6所示,在RHT和RTH抽取顺序下的性能在不同的迭代次数下普遍优于其他抽取顺序,因此以R优先抽取的方式模型性能高于以H或T优先抽取的方式.结合图4各模型结构来看,CopyRE和CopyMTL在抽取过程中都是以R优先抽取的方式进行,并且Zeng等人[11]并没有对此进行详细地阐述.通过模型结构对比和结果分析发现,以R优先的抽取方式较其他方式不易产生冗余实体,如图4中例句,在H或T优先的抽取顺序下,模型可能会抽取到“president”作为实体,而从句子整体来看,句中并没有与之存在关系的另一实体,即不能组成对应的三元组,而在实际抽取过程中模型为了组成三元组可能会强行从句中抽取另一实体并进行关系抽取,由此生成的三元组是存在问题的,因此模型各项性能指标较低,而在以R优先的抽取方式下,模型是从句中找出符合该关系的头实体和尾实体,而前述抽取顺序下,模型目标是为某一实体在某种关系下寻找句中的另一实体,显然以R优先的抽取方式更加合理,因此从一定程度上解释了CopyRE和CopyMTL都是严格以R优先的抽取方式展开进行研究,所以经上述研究与分析,GMCD-JERE模型最优抽取顺序为RHT或RTH.
5 结 论
本文提出并验证了GMCD-JERE在数据集NYT和WebNLG上进行实体关系抽取任务的有效性,其中,将多路解码序列机制融入解码器中,结合标注框架定位实体首、尾位置,同时在编码器中通过具有关系推理能力的GCN进行特征融合.通过实验发现,GMCD-JERE在NYT数据集上表现出良好的性能,在精确率、召回率和F1这3项指标上均取得较好效果,相比于CopyMTL,在精确率、召回率和F1上分别提升4.3%,5.1%,4.8%.在对头实体、关系和尾实体抽取顺序进行变换实验对比后,综合分析并确定了〈关系,头实体,尾实体〉或〈关系,尾实体,头实体〉这样的抽取顺序.相比NYT数据集,GMCD-JERE和其他模型在WebNLG数据集上表现不佳,所以我们将如何在训练样本不足且分布不均的情况下提升模型抽取性能纳入未来的研究工作中,同时我们将进一步探索长句或跨句实体关系抽取解决方案,探索文本序列长度以及解码序列长度对抽取的具体影响,同时文本特征的表征能力也是很有意义的研究方向,对模型性能提升具有一定研究价值.
作者贡献声明:乔勇鹏负责方案设计、模型训练、数据处理和文章撰写;于亚新指导方案设计,对文章修改并校对;刘树越参与模型训练和优化;王子腾参与方案可行性讨论和模型优化;夏子芳参与数据分析;乔佳琪负责文献调研.
