基于学科主题库的高校图书馆采访模式研究
2023-01-30林丽
林 丽
集美大学图书馆,福建 厦门 361021
高校图书存在学科种类复杂,学科主题更新快问题。图书馆采访人员如何从百万新书中选择适合本校学科发展需要的书籍,是一个迫切解决的问题。当前,采访人员主要根据书目的MARC数据来了解书目信息,而MARC数据中的书名和摘要存在字数多、学科覆盖面广、主题词专业性强等问题,故单纯靠采访人员一条条判断选购,是无法满足高校图书馆的各个学科读者的知识需求及高校的学科建设需要。
随着人工智能技术的发展,运用自然语言处理[1]、数据挖掘技术构建基于高校学科专业知识的学科主题词库,其不仅存储各个学科领域的专业主题词,也能统计各个学科主题词的学科研究热度、馆藏借阅热度等指标数据[2]。基于学科主题库的采访模式中,图书中携带的复杂MARC数据会被抽取转化为若干个学科主题词及主题词指标数据,采访人员不需要学科专业知识,即可以通过主题词及其对应的指标数据直观了解图书的学术价值、需求价值,也可以通过技术手段和统计方法实现机器自动采选,从而大大提高“访”的效率和效果。
一、高校图书馆采访模式及研究现状
国内图书馆界在图书采访模式的理论研究成果丰硕。包括:
1.读者荐购采访模式。楼宇源[3]提出的读者驱动采购模式,结合深圳大学图书馆实行PDA项目的实际情况,提出如何更好地在国内开展纸本书PDA采购模式的建议。
2.定量决策采购模型。钟建法[4]提出的基于德尔菲法和层次分析法构建图书采访决策评价指标体系和基本模型,模型运行所形成的图书评价分值和荐藏、适藏、选藏与不藏四种采选策略,作为新书采选和旧书补藏的重要依据。
3.智能图书采选模式。王红[5]提出采用人工智能技术,基于馆藏数据、采访数据、借阅数据不断训练和学习构建智能采选模型,以取得最优化的图书采访效果。
二、学科主题词库
学科主题词库:指高校按照不同学院不同专业构建学科主题词库。主题词库设计如表1所示,存储的数据包含:学科主题词和学科主题指标。其中,学科主题指标特征包括:
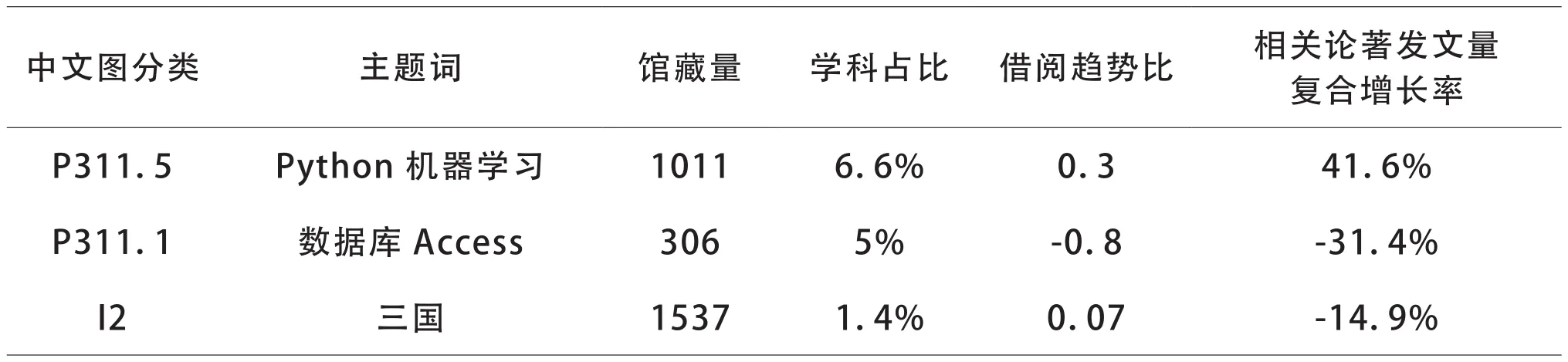
表1 学科主题词库
1.馆藏量,包含该主题词的书目数量,可通过馆藏数量了解重复主题词的书目数量。
2.学科占比,包含该主题词的馆藏量占所属中文图分类的馆藏量的比例,便于馆员采购配比。
3.该主题词近5年的借阅趋势比。统计该主题词的借阅次数年增长率BAGR(式1)。

4.相关论著发文量5年内的复合增长率。计算方法采用在销售系统应用的年复合增长率CAGR(Compound Annual Growth Rate)公式计算(式2)。CAGR值表示某主题词在某个时间段的增长或变迁的潜力和预期。

其中,B表示本年的发文量,A表示往起始年的发文量,n表示统计的年份。
三、基于学科主题库的图书采选系统
基于学科主题库的图书采选体系,主要包括数据采集层、数据处理层、数据存储层、采访业务层、数据分析层。图1所示为基于学科主题词库的图书采访系统架构。
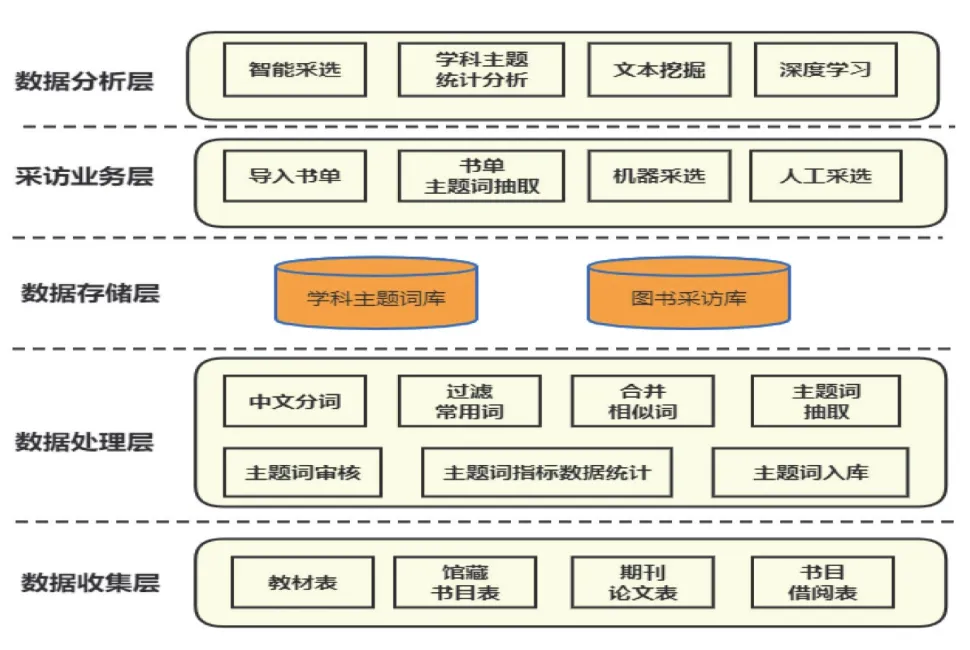
图1 图书采访系统架构
(一)数据采集层
数据采集主要通过不同数据源收集学科主题词。通过教材库、馆藏库、论文期刊库三种方式收集书目名字作为学科主题词库的语料库。
(二)数据处理层
数据处理层的主要工作为:
1.借助自然语言处理的NLP技术实现书目书名的中文分词、词频统计、相似词合并及候选主题词的抽取工作。
2.构建主题词审核平台完成候选主题词的机器核对及人工校对工作。
3.统计学科主题词的指标数据。
4.存入学科主题词库。
(三)数据存储层
1.学科主题词库数据库。存储学科主题词及其指标数据。
2.图书采访数据库。要存储图书采访相关数据。
(四)采访业务层
基于学科主题词的采访模式是基于学科主题词库查找新书对应的学科主题词及学科主题指标。采访工作人员通过学科主题指标可直观了解新书的内容特点、需求价值、学术价值,为采选提供专业的决策辅助。具体的采访流程为:
1.对新到的所有书目的书名和书目摘要分别做中文分词,抽取该书目的学科主题词。书名的关键词作为一级学科主题,摘要的关键词作为二级学科主题。
2.若新书对应的学科主题词在学科主题词库匹配不到,则该新书标记为“待选”,待选的新书可借助人工采选辅助。同时,新书对应的学科主题词,作为候选主题词加入学科主题词库,以便专家人工审核是否新兴学科主题。
3.若新书对应的学科主题词在学科主题词库已存在,则查询其对应的主题词指标数据。按照主题词的各个指标数据,可设置机器自动采选。
表2所示书目智能采购表中可以看到,机器采选根据学科主题的指标,书名为《Python机器学习教程》,满足采购条件,自动加入订单。书名为《Access数据库创建、使用与管理从新手到高手》借阅比和相关论著发文量均下降,说明该书的学术价值、课程学习价值都不高,系统自动不采选。书名《C语言程序设计与应用》的学科主题体现为借阅比为正数,但是论著发文量下降,一般为课程教材或教辅,系统设为“待选”,则需要人工采选,采访人员根据这类书特点、出版社质量等决定是否采选。
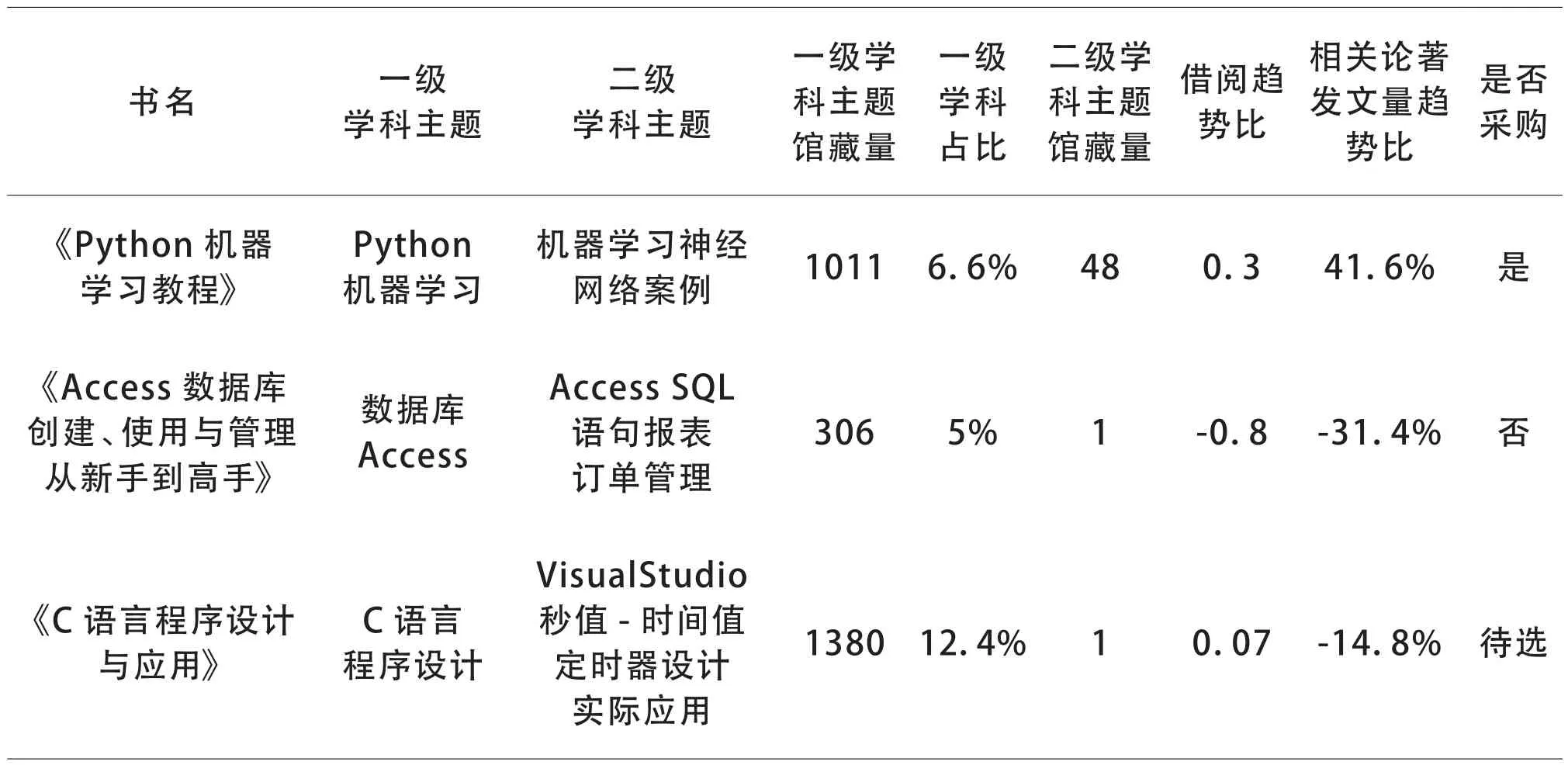
表2 书目智能采购表
(五)数据分析层
数据分析层,主要是基于学科主题词库、书目采访库的大数据,构建学科主题词自动抽取模型、图书智能采访模型、图书检索模型等,高效挖掘馆藏资源。
四、结论
“双一流”高校学科建设背景下,高校图书馆对文献资源的专业性要求更强。基于学科主题词库的高校图书馆的采访模式,应用自然语言处理技术算法、数据分析技术自动抽取图书的学科主题词及学科主题指标构建采访决策模型,不仅能精准提取图书的学术价值、需求热度,而且实时掌握高校的学科研究前沿和热点主题,保障高校图书馆的学科资源建设。但是,本文设计的学科主题词指标数据还不够完善,未来随着更多图书馆数据的融合,主题词指标可将进一步优化,为智能采选提供更多数据支撑。
