多专家注释的视杯和视盘不确定性量化
2023-01-27刘丽霞宣士斌刘畅李嘉祥
刘丽霞,宣士斌,刘畅,李嘉祥
(广西民族大学人工智能学院,南宁 530006)
0 概述
医学图像分割在疾病诊断、监测和治疗中起关键作用。在医学图像中注释与在自然图像中注释不同,医学图像通常是由一组专家注释,以减轻特定专家由于专业水平不同等原因产生的主观偏见。由于医学图像存在质量不高、明暗处理、噪声等因素,使在医学图像中描绘精确对象边界成为一项艰巨且繁琐的任务,导致高度不确定的病理区域在专家之间(不同专家对同一图像进行注释)和专家内部(同一专家在不同时间对同一图像进行注释)有很大的差异,几乎没有一个专家的注释能够精确捕捉到所有图像上的目标区域。当前大部分研究成果[1-3]通常需要唯一的标签,而获得唯一标签的做法通常是多数投票、STAPLE[4]或其他融合标签的策略[5],也有研究人员通过标签采样[6]或多头策略[7]探索多专家注释的影响。这些策略虽然易于实施,但是完全忽略了多个专家之间潜在的不确定性信息,使模型过度自信。
为避免神经网络的预测结果过度自信,研究人员[8-9]提出不确定性估计,即对分割预测结果的可靠性程度进行评估,在已有分割模型的预测基础上,增加关于分割网络不确定性估计的研究,结合不确定性的量化指标,优化模型训练过程,提升模型的分割性能。不确定性估计有助于提高深度神经网络决策的可解释性和分割结果的可靠性,能够提供关于系统对给定患者执行给定任务信心的信息,可以用来指示潜在的误分割区域,从而指导医生对不确定性高的部分给予更多的关注,较好地辅助临床医学诊断。
早期利用深度学习网络进行不确定性估计的研究主要集中在图像分类和检测这些粗粒度的预测任务中,此后KENDALL 等[9]将其推广到需要对逐像素预测结果进行不确定性估计的图像分割领域,将不确定性分为认知不确定性(Epistemic uncertainty)和任意不确定 性(Aleatoric uncertainty)。HÜLLERMEIER 等[10]提出神经网络中认知不确定性和随机不确定性的概念,并通过不同方法对其进行建模和量化。不确定性度量除了在医学图像分析领域起重要作用外,在计算机视觉(自动驾驶)、自然语言处理(机器翻译、语音识别)等领域也发挥着重要作用。文献[11]概述了不确定性度量在这些应用领域的研究进展,并提供大量参考文献和对开放性问题进行讨论,目前贝叶斯神经网络、集成模型、概率U-Net、测试时间扩充等方法可用于估计不确定性,但国内相关研究报道相对较少。
本文考虑标签和数据中的人工不确定性,利用专家注释之间的确定(一致认可)和不确定(分歧)区域来反映预测结果的可靠程度,提高模型不确定性量化的性能,并通过网络学习生成最终的校准分割概率图。
1 相关工作
近年来,学者对估算深度神经网络中的不确定性进行了研究[12],提出各种方法对其进行量化,主要研究集 中在贝叶 斯推理[9,13-14]、集成方法[16-18]、概率U-Net[20-21]或利用多个标签和专家之间可变性来构建能反映不确定性的分割框架[24-25,30]。通过贝叶斯神经网络(Bayesian Neural Network,BNN)学习权重分布,是目前预测不确定性常用的方法。该方法首先在BNN 参数上指定先验分布[9],然后在给定训练数据的情况下计算参数上的后验分布,从而量化预测认知不确定性。任意不确定性则使网络分割输出均值和方差σ2,其中代表网络的预测结果,方差σ2代表不确定性度量结果。BNN 采用蒙特卡罗(Monte Carlo,MC)dropout[13]来反映与网络参数相关的不确定性,用MC dropout 近似BNN 的后验概率。然而,使用MC dropout 获得的不确定性估计值往往会被错误校准,即该值与模型误差不一致[14]。HUMT 等[15]提出一种新的贝叶斯优化算法,以减轻真实权重后验拟合不足的倾向,并证明拉普拉斯近似的超参数可以有效优化,分割预测结果的校准性能得到提高。此后,研究人员致力于利用集成学习来改进不确定性校准。LAKSHMINARAYANAN等[16]提出一种非贝叶斯神经网络的方法,使用集成学习的优势对与训练数据一致的多个模型进行平均预测,从而对分类和回归任务结果进行更准确的不确定性估计。BELUCH 等[17]和GUSTAFSSON 等[18]在图像分类任务中发现集成方法比MC dropout 在主动学习任务上能提供更准确的校准预测。与MC dropout 不同,使用深度集成不需要修改网络架构,但集成方法需要从头开始训练模型,这对大型数据集和复杂模型来说计算成本很高。STAHL 等[19]通过在MNIST 数据集上对比基于Softmax 输出、网络集成、贝叶斯神经网络、自动编码器等方法的不确定性量化结果,对深度学习中的不确定性量化进行了评估。KOHL 等[20]提出一种概率U-Net 网络,通过将贝叶斯全连接网络(Full Connected Network,FCN)与条件方差自动编码器相结合,为模糊图像提供多个分割假设。BAUMGARTNER 等[21]提出一个多尺度潜在变量的概率层次模型,并将独立的潜在变量用于不同的分辨率,变量自动编码器用于推理。GANTENBEIN 等[22]通过添加可逆块提高内存效率,在保持分割精度不变的前提下节省内存。
上述方法通过使用不同策略进行不确定性估计,但仍然没有充分利用多专家注释工作中丰富的差异信息,浪费了现有多专家注释的人工数据集,无法在多个专家对同一图像的独立注释场景中学习图像分割任务。图1 提供了在眼底图像视杯和视盘注释过程中专家之间存在的明显不确定或争议区域,特别是在视杯边界信息与背景非常相似的位置。目前,多专家间可变性问题开始引起研究人员的关注。HU 等[23]量化了因观察者间的分歧而出现多个注释时的不确定性,使用概率U-Net 网络量化肺异常分割的不确定性。MIRIKHARAJI 等[24]提出使用FCN 集成来处理分割注释中的差异,通过有效利用多个专家的意见,并从所有可用注释中学习,捕获了2 种类型的不确定性。ZENG 等[25]提出一个新的扩展Dice 和扩展Dice 损失函数,有效地评估多个可接受注释的分割性能。WANG 等[26]提出一种具有不确定性的分割网络,从每个肺结节的不同注释中学习,预测具有高度不确定性的肺结节区域。VALIUDDIN 等[27]使用规范化流(Normalizing Flows,NFs)来建模单注释数据和多注释数据,允许对任意不确定性进行更复杂的建模。ZHANG 等[28]提出U-Net-and-a-half 网络,并从多个专家对同一组图像执行的注释中学习。YU 等[29]提出一种多分支结构,在不同敏感度设置下生成3 个预测,以利用多评分者共识信息进行青光眼分类。YANG 等[30]提出一种基于U-Net 的多解码器体系结构,并使用交叉损失函数弥补不同分支之间的差距,方法简单易用。

图1 多专家注释的视杯和视盘对比Fig.1 Comparison of optic cup and optic disc annotated by multiple experts
JI 等[31]提出MRNet 医学图像分割框架,考虑多评分员之间的一致和不一致信息,包含由粗到精两级处理管道,第1 级管道使用U-Net获得粗略预测结果,第2 级管道由多评分者重建模块(Multi-rater Reconstruction Module,MRM)和多评分者感知模块(Multi-rater Perception Module,MPM)组成。提出的专业感知推断模块(Expertise-aware Inferring Module,EIM)将评分员的专业知识线索明确整合到高级语义特征中(即两级管道中编解码器的瓶颈处),使用MRM 模块来重建单个评分员的评分,并用MPM 模块细化粗略预测以形成最终校准的分割图。但MRNet 模型存在几点不足:首先模型构建过于复杂,导致模型参数过多,不易于推广使用;其次使用两级处理管道造成编码结构复杂,导致特征提取存在不一致性;最后MRM 模块将第1 级管道中的粗略预测与输入图像相结合,并将其作为特征提取的输入,使生成的特征不是纯粹的输入原图像的特征。在MRM模块中仅在解码器最后一层使用多个1×1 卷积层重构各个评分者的注释,使重构存在一定的局限性。
受文献[30]的启发,本文仅使用单级处理管道,并将多解码器分支作为重构模块,以精简模型结构。本文的改进措施具体如下:
1)在MRNet 模型体系结构的基础上,使用多解码器增强重构的潜在能力,并允许同时学习由多个专家对同一组图像执行的注释。
2)在编码器-解码器的瓶颈处嵌入整合了多专家专业知识的先验信息,提高每个解码分支的泛化性。
3)使用软注意机制增强多解码器中多个预测结果的模糊区域和边界,并在公开的RIGA 视网膜杯盘分割数据集上进行实验。
2 本文模型
将提出的多解码器不确定性感知(Multidecoder Uncertainty Aware)分割模型记为MUA-Net,图2 为MUA-Net 的总体框架,包含一个编码器、多个解码器、EIM模块以及双分支软注意机制。图2 上半部分是编码器-解码器和EIM 模块,从不同专家对同一图像的多个注释中学习,每个注释获得一个解码器分支,解码器的数量与专家注释的数量一致。图2下半部分是双分支软注意机制,利用不确定性映射获得最终的分割概率图。在该模型中,采用U-Net作为主要架构[32],考虑到VGG 架构能保留输入图像的拓扑和敏锐的感知特征,模型选择以VGG16 为主干的DeepLab-V3+作为编码器。所有输入图像通过同一编码器生成图像特征值,构成一个多解码器共享的低维特征空间。每个专家对应一个解码器,每个解码器从对应专家独立生成的注释中学习获得图像掩码。多解码使重构的多专家信息与原始多专家信息更相似,以达到通过训练好的模型来预测多专家注释的目的,提高每个分支的预测能力。本文采用单个编码器和多个解码器结构,这是相对文献[31]的不同之处,既简化了模型,又增强了模型的重构能力。为提高每个分支的泛化能力,在编码器-解码器的瓶颈处引入文献[31]中的EIM 模块,因为仅使用多解码器的每个分支学习相应的注释是不够的,还需通过EIM 模块将多专家注释的先验信息嵌入编码器提取的高层语义特征中,使学习的多个目标暴露于解码器之前,以提高编码器提取特征的动态表示能力。最后,在每个解码分支得到的初始预测估计代表不同区域间专家可变性的像素级不确定性映射,然后利用本文提出的带有双分支软注意机制的不确定性映射进一步细化、捕捉和强调模糊区域,得到最终的分割概率图。
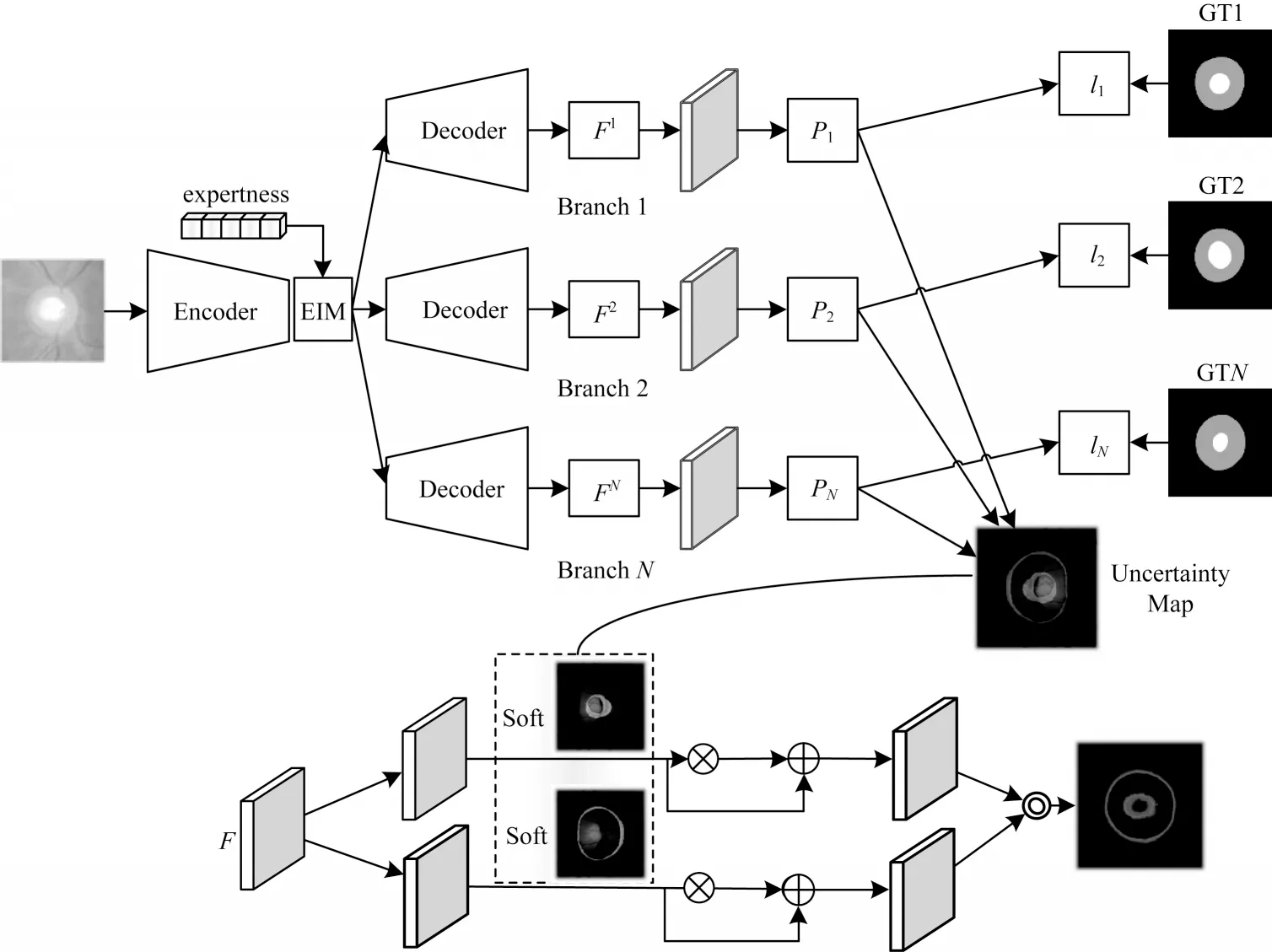
图2 本文模型的整体框架Fig.2 Overall framework of model in this paper
2.1 EIM 模块
EIM 模块利用各专家的专业知识水平作为先验信息,并将其以条件信息的形式嵌入到分割网络中,以提高编码器提取特征的动态表示能力。在EIM 模块中,多个专家的专业知识水平形成归一化的,其中V和N分别代表评分专家相应权重和评分专家总数。expertnessV作为先验知识馈送到网络,在每次训练迭代过程中,考虑到不同专家的临床专业知识水平不同但重要性相同,因此设置为所有专家的权重一致。
为有效将多专家专业知识线索集成到语义特征表示中,将嵌入的expertnessV作为隐藏状态,利用ConvLSTM模块[33]生成增强的特 征,如图3所示。ConvLSTM 是一个功能强大的递归模块,其不仅能捕获特征和不同专业水平(即隐藏状态)之间的相关性,还能感知有区别的动态特征。更具体地说,ConvLSTM 模块将从编码器获取的高级特征图(即f)作为EIM 的输入,并使用归一化expertnessV作为初始隐藏状态h0。为了将V转换为适合ConvLSTM模块的格式,将V扩展到与f相同的维度,该过程可定义为式(1)所示:


图3 EIM 模块Fig.3 EIM module
2.2 多解码器
为同时学习由多个专家对同一组图像给出的注释所获得的图像掩码,并且共享低维的特征空间,提出多解码器结构。每个解码器用于测量和拟合一个注释,尝试捕获多专家注释的专业知识。具体地说,每个解码分支能对编码器提取的图像高级特征逐步恢复近似配对的注释,使重构的多专家信息与原始多专家信息更加相似,以达到通过训练好的模型来预测多专家注释过程的目的,提高每个分支的预测能力。
如图2 的上半部分所示,N个注释专家就有N个解码器分支,它们共享相同的特征提取过程,每个解码分支都有特定的学习目标,学习单个专家专业知识的注释,在逐步上采样后获得最终的解码特征Fi,以及通过1×1 卷积运算处理的初始预测Pi。使用重构损失Lrec衡量重建的多专家注释与各个专家真实注释的相似程度,其定义为表示二进制交叉熵损失,N是专家总数,Pi∈RW×H×C和表示第i个专家相应的重构预测和注释;W、H和C分别表示图像宽度、高度和通道数。每个解码分支包含的二进制交叉熵损失函数能较好地给编码器反馈提取特征的信息,多解码器的重构损失为每个解码器损失的组合取平均值,其表达方式为
通过N个解码器重构N个专家的注释后,专家之间的分歧区域通过粗预测的像素标准偏差进行估计,即不确定性映射,该方法可以从可能导致分割不确定性的区域中学习有价值的视觉特征,从而获得更好的分割结果。使用式(2)获得不确定性映射,并在双分支软注意机制中进一步处理。

2.3 软注意机制
多个专家之间的分歧,即争议区域,反映了医学图像中不同区域的不确定性或难度水平。因此,如何更好地利用这些信息提高分割性能是一个重要的研究问题。本文利用双分支软注意机制能够更好地捕捉和强调模糊区域,其中一个分支对应眼底图像的视杯,另一个分支对应视盘。基于2.1 节获得的不确定映射,使用空间注意策略[34]来强调高度不确定性区域。然而,估计的不确定性映射可能在对象边界附近包含潜在的不确定性或不完整性,如果使用“硬”空间注意,可能会对模型性能产生负面影响。因此,采用“软”注意,以扩大不确定区域的覆盖范围,从而有效地感知和捕捉多个专家之间的不一致线索。软化操作可以表示为式(3)所示:

其中:FGauss表示具有高斯核和零偏差的卷积运算;Ωmax表示一个最大函数,用于保留高斯滤波图和原始不确定性图之间的较高值。在本文中,高斯核的大小和标准偏差可以通过模型训练进行学习,并分别用32 和4 作为高斯核和标准偏差的初始值。
在高度不确定的区域中引入软注意机制,以增强特征图F的高度确定区域,其中F为每个解码器分支最终解码特征Fi的组合,表达式为F=,该表达式充分考虑了多专家的一致性。换言之,初始预测的高度不确定和确定区域都得到了加强。将F发送到2 个平行分支,2 个分支分别代表视杯和视盘分割任务。软空间注意分别从中获得,如图2 所示,在原始特征F和空间增强特征之间采用跳跃连接,以避免传播到网络的注意力图的潜在错误。该过程描述如下:

将细化的特征Fcup、Fdisc进一步连接并输入到一个1×1 卷积层中以获得最终的分割预测M,该过程的表达式如式(5)所示:
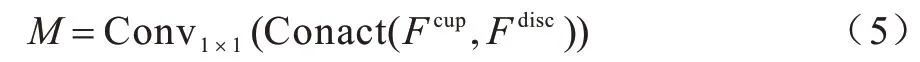
最终将分割预测概率图M和由多个专家对同一图像注释的图像掩码乘以expertnessV中对应的权重获得)进行二进制交叉熵损失,即LM=lBCE(M,GTs)。所以最终的损失组合如下:

3 实验结果与分析
3.1 数据集
RIGA benchmark[35]是一个公开的视网膜杯盘分割数据集,共750 幅彩色眼底图像,包括来自MESSIDOR 的460 幅图像、来 自BinRushed 的195 幅图像和来自Magrabia 的95 幅图像。来自不同组织的6 位眼科专家为该数据手动标记了视杯和视盘轮廓掩模。在模型训练期间,从BinRushed 和MESSIDOR 中分别选择195 个样本和460 个样本作为训练集,选择具有95 个样本的Magrabia 集作为评估模型的测试集,该测试集与训练数据集不同源。
3.2 实现细节和评价指标
在实验中,MUA-Net 采用PyTorch 平台实现,并在具有48 GB 内存的NVIDIA RTX 8000 GPU 上进行训练和测试。所有训练和测试图像都统一调整尺寸为256×256 像素。提出的模型使用Adam 优化器以端到端的方式进行训练,初始学习率设置为1×10-4,批量大小为8,共60 个epoch。
MUA-Net 模型的目标是生成概率图M,该概率图M可以反映潜在的多专家之间的不确定性,即校准预测,用于眼底视杯和视盘图像分割。为更好地评估校准模型预测,使用平均精度(Mean Accuracy,Acc)、文献[31]中的Dice 系数(Dice coefficient,D)、交并比(Intersection over Union,IoU)进行多个阈值级别的度量。本文为公平比较,将阈值参数设置为(0.1,0.3,0.5,0.7,0.9)。在每个阈值级别下,生成预测概率图M和GTs,并与对应阈值进行二值化,然后分别计算Acc、D 和IoU。对在多个阈值处获得的Acc、D 和IoU 取平均值,然后获得软度量,并分别表示为Accs、Ds和IoUs。软分数越高,表示模型性能校准得越好。
3.3 实验结果
为验证本文模型的有效性,以单一专家注释作为标签,使用基线U-Net 训练单个专家,获得6 个不同的模型(Ophthalmologist 1~Ophthalmologist 6),并与对应的标签进行评估。为证明GTs的有效性,使用不同的标签训练相同的MUA-Net,包括单个眼科专家注释的标签(GT1~GT6),Random(在训练过程中,随机从标签池中采样)以及STAPLE[4],结果如表1 所示,其中分别代表视杯的平均精度、Dice 系数、交并比,分别代表视盘的平均精度、Dice 系数、交并比。实验结果表明,在模型Ophthalmologist 1~Ophthalmologist 6中,Ophthalmologist 4 在视杯分割中的各指标均获得了最高值,与其他模型相比,其分别提 高1.15~3.54 个百分点,3.6~8.8 个百分点和4.1~11.5 个百分点,可见不同专家的专业能力差距较大,难以确定唯一的标签。Ophthalmologist 1~Ophthalmologist 6 模型在视盘分割中的最高值与最低值的差值分别为0.86、1.09、3.41 个百分点,对视盘的分割性能比视杯的分割性能差异更小,这是因为在注释过程中视盘相较视杯的边界更加明显。Ophthalmologist 1~Ophthalmologist 6 模型性能的差异体现了评分专家注释图像分割掩码的差异,再次验证了考虑多个专家专业知识并同时学习的必要性。此外,本文模型MUA-Net(GTs)的各指标均取得最优值,MUA-Net(STAPLE)次之。MUA-Net(GTs)模型的比次优的MUA-Net(STAPLE)模型分别高1.06、1.04 和1.9 个百分点。MUA-Net(GTs)模型在视盘分割的比次优的MUA-Net(STAPLE)模型分别高0.25、1.44和0.84 个百分点。这些对比实验证明本文模型MUA-Net 和(GTs)在多个专家注释的情况下获得更好的校准结果。
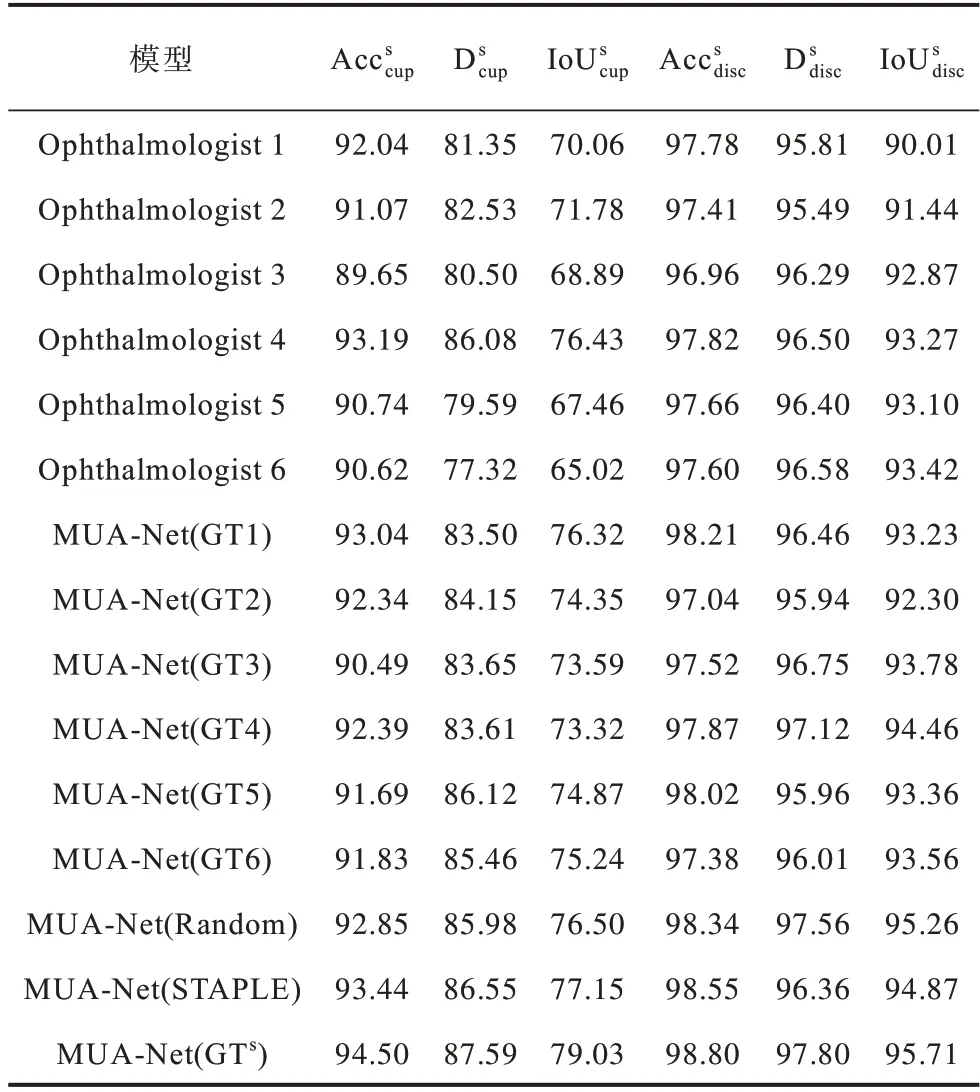
表1 不同模型在RIGA 数据集下的结果对比Table 1 Comparison of results of different models under RIGA dataset %
MUA-Net 模型可视化的结果如图4 所示,由图4可知,MUA-Net 模型生成的概率图具有很好的校准效果,特别是能较好地反映不同专家间的争议区域。
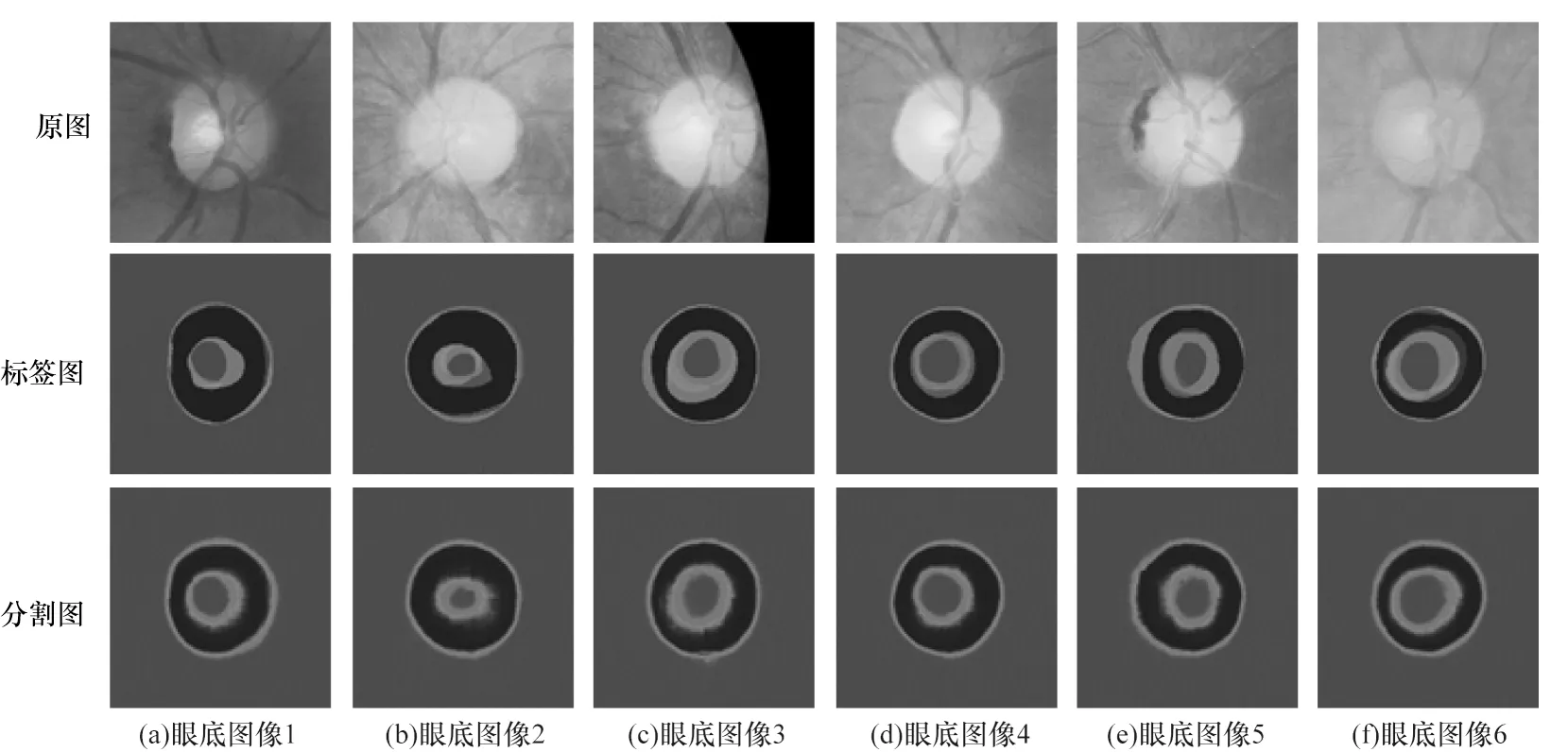
图4 眼底视杯和视盘的分割结果对比Fig.4 Comparison of segmentation results of fundus optic cup and optic disc
为证明本文所提MUA-Net 模型的有效性,将其与最先进的视杯视盘分割模型进行比较,模型包括AGNet[36]、CENet[37]、ResUnet[38]、pOSAL[39]、BEAL[40]和MRNet[31],结果见表2。可以看到,与最先进的眼底视杯视盘分割方法相比,本文MUA-Net 性能优异,在视杯分割时,本文模型的比MRNet 模型分别提升0.75、0.39、0.41 个百分点。在视盘分割时,本文模型的比MRNet模型分别提升了0.25、0.47 个百分点。虽然本文模型在视盘分割时的值没有取得最优值,但仅比最先进的MRNet 模型低0.02 个百分点。综上,本文模型具有更好的校准预测性能。

表2 不同视杯和视盘分割模型在RIGA 数据集下的结果比较Table 2 Comparison of the results of different optic cup and optic disc segmentation models under RIGA dataset%
3.4 消融实验
为验证本文MUA-Net 模型中各模块的有效性,进行了消融实验,结果如表3 所示,其中“√”表示使用该模块,“×”表示不使用该模块。所有的实验均使用GTs进行评估。使用基本的U-Net,即单一的编码器-解码器结构作为基线模型。随后在基线模型的基础上逐步加入多解码器、EIM 模块、双分支软注意机制。添加多解码器结构之后,模型的校准预测性能获得了有效提高(表3 中的b 行),尤其是视杯分割时的值比基线模型(表3 中的a 行)分别增加2.40、2.73 个百分点。这有效证明了使用多解码比单解码更能有效重构多专家的信息。通过将EIM模块嵌入到编码器-解码器的瓶颈处值分别增加了1.00,1.82 个百分点(表3 中c 行比图3 中b 行),即具有EIM 模块的模型有更高的校准预测性能。这是因为通过EIM 模块引入多专家专业知识,能够提高模型的动态表示能力,有效利用多专家线索提高校准分割结果。在未加入双分支软注意机制时,本文模型的各项指标均已优于MRNet 模型。为进一步提升本文模型性能,引入双分支软注意机制以更好地强调模糊区域和边界,其性能比表3 中c 行的分别提升了0.27,0.28 个百分点。
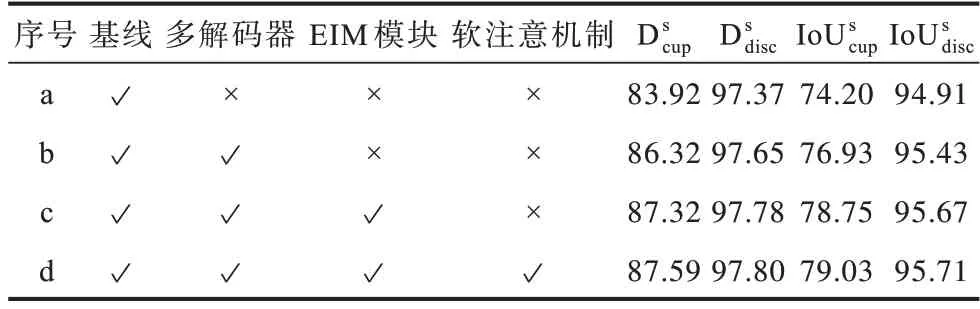
表3 在RIGA 数据集下的消融实验结果Table 3 Results of ablation experiment under RIGA dataset %
4 结束语
针对由多个专家对同一组图像进行注释时无法达成共识的问题,提出一种基于多解码器与不确定性感知体系结构的MUA-Net 模型。以端到端的方式同时学习多个注释,利用多解码器重构多个专家丰富的注释信息,在编解码器的瓶颈处加入EIM 模块,以此作为多专家的先验信息,并使用软注意机制细化模糊区域以更好地反映确定和不确定区域。实验结果表明,本文模型与MRNet 模型相比,能够提高模型的动态表示能力和校准预测性能。在多个专家的注释无法达成共识的临床应用中,预测不确定性至关重要,但由于现有的不确定性量化模型大部分在有监督的环境中提出,而在半监督环境下的研究较少,因此下一步将研究半监督的医学图像分割,并对其不确定性进行量化,从而更好地辅助临床医学诊断。
