基于深度学习的肝脏CT-MR 图像无监督配准
2023-01-27王帅坤周志勇胡冀苏钱旭升耿辰陈光强纪建松戴亚康
王帅坤,周志勇,胡冀苏,钱旭升,耿辰,陈光强,纪建松,戴亚康,5
(1.中国科学技术大学(苏州)生物医学工程学院生命科学与医学部,江苏苏州 215163;2.中国科学院苏州生物医学工程技术研究所,江苏 苏州 215163;3.苏州大学附属第二医院,江苏 苏州 215000;4.丽水市中心医院,浙江 丽水 323000;5.济南国科医工科技发展有限公司,济南 250000)
0 概述
肝癌是最危险的致死癌之一[1]。常规的肝癌诊断、放疗规划、图像引导的介入治疗等技术都需根据医学图像的分析,其中多模态配准是关键环节。通过多模态图像如电子计算机断层扫描(Computed Tomography,CT)和核磁共振图 像(Magnetic Resonance,MR)的配准和融合能够利用不同模态的互补信息,从不同侧面分析疾病。由于配准速度和配准结果的好坏都会严重影响后续的定量分析,因此实现快速、精准的多模态配准具有重要的临床意义。
配准的根本目的是寻找一组最优转换参数,使不同图像变换后在整体和结构上均对齐。多模态配准相较于单模态配准的主要难点在于不同模态图像的灰度、纹理差异较大,转换参数的寻优困难。以肝脏为例,CT 与MR 图像的灰度值相差巨大,CT 图像的灰度值为[-1 024,1 024],而MR 仅为[0,500],因此度量两者的相似性十分困难。另外,肝脏器官体积较大,与周围组织存在滑动,导致不同模态图像上的非线性形变巨大,这也是限制配准精度的关键因素。传统的迭代式肝脏多模态配准方法主要利用相似测度的迭代最大值来寻找图像对的最优转换参数,其中,有效的相似测度至关重要,常用的多模态相似测度有互信 息[2]、熵图[3]、模态无关邻域描述符[4]等。虽然上述方法在解决图像对齐的优化问题上已经取得了不错的效果,但是迭代优化的计算量巨大、配准时间长、容易陷入局部最优的缺点限制了其临床应用范围。随着深度学习在医学图像处理领域的应用,基于深度学习的配准算法被陆续提出,并且取得了相当高的配准性能[5]。
测度估计式配准是指通过卷积神经网络学习到一种通用的相似测度用于指导多模态配准。基于此思想,SIMONOVSKY 等[6]采用一种Siamese 网络来显式地学习多模态脑图像对的相似测度表达。他们将测度估计问题建模为分类任务,通过判断不同模态的图像块是否对齐来估计相似测度,然后用估计到的相似测度指导配准。后来,GRANT 等[7]使用类似的理论学习MR-TRUS 配准的相似测度,并且提出一种复合优化策略来提高训练速度。上述方法从设计测度角度看待多模态问题,存在一个巨大的缺点—伪分类任务需要预先设计两类图像块(对齐和不对齐)来监督训练相似测度网络,导致相似测度网络和配准网络不能同时训练,整体网络权重训练不能端对端进行。
对抗训练式配准受益于生成对抗式[8]思想,通过使用鉴别网络代替损失函数,实现对抗式训练。YAN 等[9]率先提出多模态图像对抗训练式配准框架,他们将生成器设计为配准网络,直接估计形变场,并用鉴别器评估生成图像和参考图像的相似性,总体网络采用对抗式训练,直到达到平衡状态。尽管文章中的配准精度还有待提高,但至少证明了算法的可行性。MAHAPATRA 等[10]拓展 了对抗训练式配准框架,使用多种对抗网络实现多模态眼底图像的配准。FAN 等[11]通过精心设计参考图像,同时实现了单模态和多模态的对抗训练配准。
深度学习的数据驱动能力具备直接优化转换参数的能力,例如形变参数估计式配准方法被应用于单模态配准,产生出如DIRNet[12]、SVF-Net[13]、VoxelMorph[14]等配准性能良好的图像配准框架,但由于单模态相似测度不适用于多模态,导致其在多模态配准中应用受限。后来,HU 等[15]提出采用前列腺不同区域的分割标签来监督训练形变参数估计网络,实现了前列腺MR 图像和超声(Ultrasound,US)图像的多模态配准。然而,标签驱动的弱监督配准需要手动分割解剖标签,耗时耗力。ZHOU 等[16]提出采用深度学习的方式自动分割肝脏CT 和MR 标签,然后使用分割标签辅助配准,提高了配准精度。从本质上说,形变参数估计配准是一个利用深度学习网络实现图像特征表征的过程,其中从差异性较大的区域中提取合适的特征是难点。衍生出的标签驱动配准能够从损失函数的角度进行全局约束,但是本身标签的获取困难,约束也比较微弱,容易使网络陷入局部最优。
为有效提高肝脏多模态图像的特征表达能力,解决导致肝脏配准精度低的大形变问题,本文提出一种基于多尺度形变融合和双输入空间注意力的无监督图像配准算法(Ms-RNet)。采用一种全新的多尺度形变融合框架分解肝脏的大形变问题,通过提取不同分辨率的图像特征实现肝脏的逐阶配准,提高配准精度。此外,提出一种双输入空间注意力模块,通过融合编解码阶段中不同水平的空间和文本信息来提取图像间的差异特征,从而增强配准网络的特征表达,获得更加精确的形变场。为实现无监督配准,将传统多模态配准中常用的模态无关邻域特征向量化,构建可以用于深度学习网络的相似测度,并通过在结构信息损失项的基础上添加雅可比负值罚项来惩罚折叠体素,保证形变的稳定性。
1 本文方法
1.1 整体框架
定义3D 空间Ω∈R3上的一组图像,固定图像F和浮动图像M。图像配准的目的是寻找一组最优的空间变换参数ϕ,使配准后的图像M(ϕ)与图像F在形态和解剖结构上对齐。与传统配准迭代优化的思路不同,本文基于深度学习思想构建了一个卷积神经网络模型,直接估计图像F和M之间的形变场,即:

其中:f表示卷积神经网络要学习的映射函数;θ是网络参数;ϕ是估计得到的形变场。一般通过最大化相似测度函数来训练网络,学习最优的网络参数,构建配准模型。其图像配准过程可表示为式(2)所示:

其中:S(F,M(ϕ))表示固定图像F和配准后图像M(ϕ)之间的损失项;R(ϕ)是为了保证形变的平滑性而添加的正则项。
整体配准框架如图1 所示,包含形变场估计、空间变换和相似性度量3 个部分。具体来说,首先把浮动图像和固定图像合并为双通道图像,并将其输入到本文提出的Ms-RNet 网络(具体网络的结构见1.2 节),经过特征提取和解耦,得到三通道的形变场。然后经过空间变换对浮动图像进行重采样,得到最终的配准图像。最后,将配准图像与固定图像间的结构特征相似性指标作为网络的损失项来引导网络参数的优化。在使用正则项保证整体形变平滑性的同时,引入雅可比负值罚项来进一步惩罚折叠体素,保证配准图像的拓扑特性。在测试阶段中,给定未知的图像对,直接通过配准网络即可得到配准后的图像,无需重复训练,配准速度快。
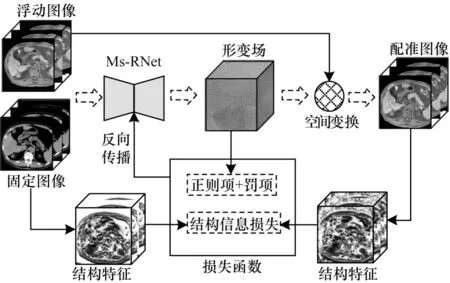
图1 肝脏多模态配准流程Fig.1 Procedure of liver multimodal registration
尽管本文Ms-RNet 网络属于多阶配准框架,但是整个网络训练过程是端对端的,可以直接输出最终配准结果,而且训练阶段不需要任何标签信息,属于无监督式配准。
1.2 具体网络结构
本文提出的Ms-RNet 是在多尺度形变融合框架下的配准网络,其中的基础全卷积配准网络RNet 融合了双输入空间注意力模块来增强特征表达,具体细节见2.2.1 节~2.2.3 节。
1.2.1 多尺度形变融合框架
肝脏多模态图像非线性形变明显,结构差异性较大。深度学习网络中常用的3×3、5×5 的卷积核感受野较小,难以提取图像中差异性较大的特征,不利于大形变的配准[17-18]。同时由于网络参数较多且具有较大自由度,在没有良好的初始化参数的情况下,直接优化较为困难,容易陷入局部最优。受传统配准方法中的多分辨率思想和文献[17]启发,本文设计了一种多尺度形变融合框架,将大形变配准问题简化为从粗到细的逐阶配准问题。通过逐层精细化配准,网络在每个尺度估计的形变可以作为后续配准的初始值,避免了网络陷入局部最优,提高配准精度。
图2 是多尺度形变融合框架的示意图(本文采用三阶的结构),采用倒金字塔式形态,各阶输入为不同分辨率的图像对。其中,每一阶的基础配准网络RNet 是本文提出的融合了双输入空间注意力模块的全卷积配准网络,他们具有一样的网络架构,但是输入的图像尺寸不同。

图2 多尺度形变融合框架Fig.2 Multi-scale deformation fusion framework
多尺度形变融合框架的基本流程如下:
1)将原始图像分别下采样为原图像大小的1/2和1/4,即F=F0=2F1=4F2,M=M0=2M1=4M2,其中F为原固定图像,M为原浮动图像。
2)每一阶形变估计均采用RNet 来完成,对于低阶配准,输入为最低分辨率图像对(F2,M2),使用RNet 提取输入图像的特征,然后解码得到形变场ϕ2。由于输入的是最低分辨率图像,网络主要提取全局文本信息,生成粗糙形变场。中间阶配准需要先上采样ϕ2,得到与图像对(F1,M1)大小一样的形变场′,然后配准M1得到配准后的图像,所以实际上中间阶网络输入为这样,中间阶配准使用了低阶形变进行初始化操作,可以预测更加精细的形变场,补充更多结构信息。需要注意的是,由于从中间阶开始,浮动图像实际上是配准后的图像,所以配准网络估计的形变是一种残差形变ϕr1,实际形变场ϕ1需要加上低阶形变场,即多尺度的形变融合。高阶配准重复中间阶的过程,即可得到最终的形变场ϕ。中间阶与高阶配准的表达式如式(3)所示:
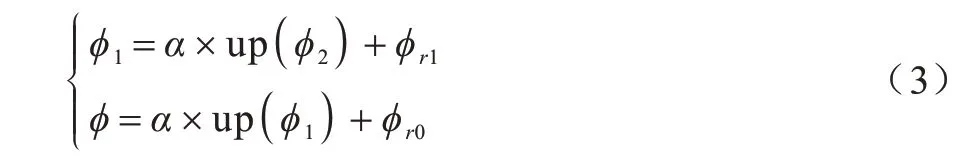
其中:up 代表形变场上采样2 倍,实验中采用三线性插值实现;α代表形变的振幅,可以保证不同阶形变幅值的一致性,一般α=2;ϕ2为低阶形变场;ϕr1为中间阶残差形变;ϕr0为高阶残差形变。
1.2.2 全卷积配准网络
为适应配准本身的特征提取特点,本文设计一种全新的融合了双输入空间注意力的全卷积配准网络RNet,其基础结构类似于U-Net[19],主要由编解码层和注意力层组成,如图3 所示,其中:编码阶段利用级联的卷积层来降低特征图维度,进行特征提取;解码阶段使用反卷积层将特征图恢复至与原始图像大小相同的特征图,然后进行形变估计,得到最终的形变场。具体来说:在提取特征阶段,每次下采样后都会使用2 个3×3×3卷积层提取不同层次的图像特征,并使用参数为0.2 的LeakyReLU 激活层进行激活,同时紧接一个步长为2 的卷积来压缩特征维度,增加网络深度。在解码阶段,每次上采样后的特征图,首先通过跳跃连接层和相同层级编码阶段的浅层特征融合,然后经过2 个3×3×3 的卷积层(每一个卷积层后面依然接一个LeakyReLU 激活层)来进一步解耦特征,同时提高网络的非线性映射能力。最后,经过一个卷积核大小为3,步长为1 的卷积和SoftSign 激活层输出三通道形变场,即位移向量dx、dy和dz。

图3 全卷积配准网络的结构Fig.3 Structure of fully convolution registration network
RNet 与经典U-Net 不同之处在于:
1)由于配准是逐体素配准,需要尽量保留更多特征,因此上下采样层全部使用卷积实现,避免图像特征的丢失。
2)为进一步提高特征表达能力,引入空间注意力机制,将简单的跨越连接替换成了双输入空间注意力模块(细节见1.2.3 节),将来自编解码层的不同水平信息合并到空间特征图上,通过空间权重的重新赋值来突出差异性区域,提高特征表达能力。
1.2.3 双输入空间注意力模块
空间自注意力[20]已被应用于文本的语义分割。后来,自注意力机制被用于消除对于外界门控信息的依赖[21-22],如WANG 等[22]利用非局部自注意力来抓取长程依赖关系。后来也有工作表明,通过将注意力模块集成到标准的U-Net 中,可以捕获最相关的语义上下文信息,且不需要很大的视野域[23]。本文将空间自注意力机制嵌入图像配准网络,利用其优点来更好地提取特征,优化配准。
双输入空间注意力模块的基本结构如图4 所示,通过连接编码和解码阶段不同尺度的特征图,来获取空间维度上的不同权值,进而保留相关区域激活,去除不相关或者噪声响应。在实现上,首先对解码阶段的特征图d进行上采样操作,得到dup∈RC×H×W×D,然后沿着通道轴对e和dup最大池化,并且将结果相加,得到一个融合特征图,其中沿着通道轴应用池化操作可以有效突出信息区域[24]。对融合特征图进行卷积核大小为1,步长为1 的标准卷积操作后,通过Sigmoid 激活来归一化空间权重图α,消除差异性噪声。最后,将α与e进行体素间对位相乘,即可得到具有丰富上下文信息的特征图。将上述过程公式化为式(4)所示:
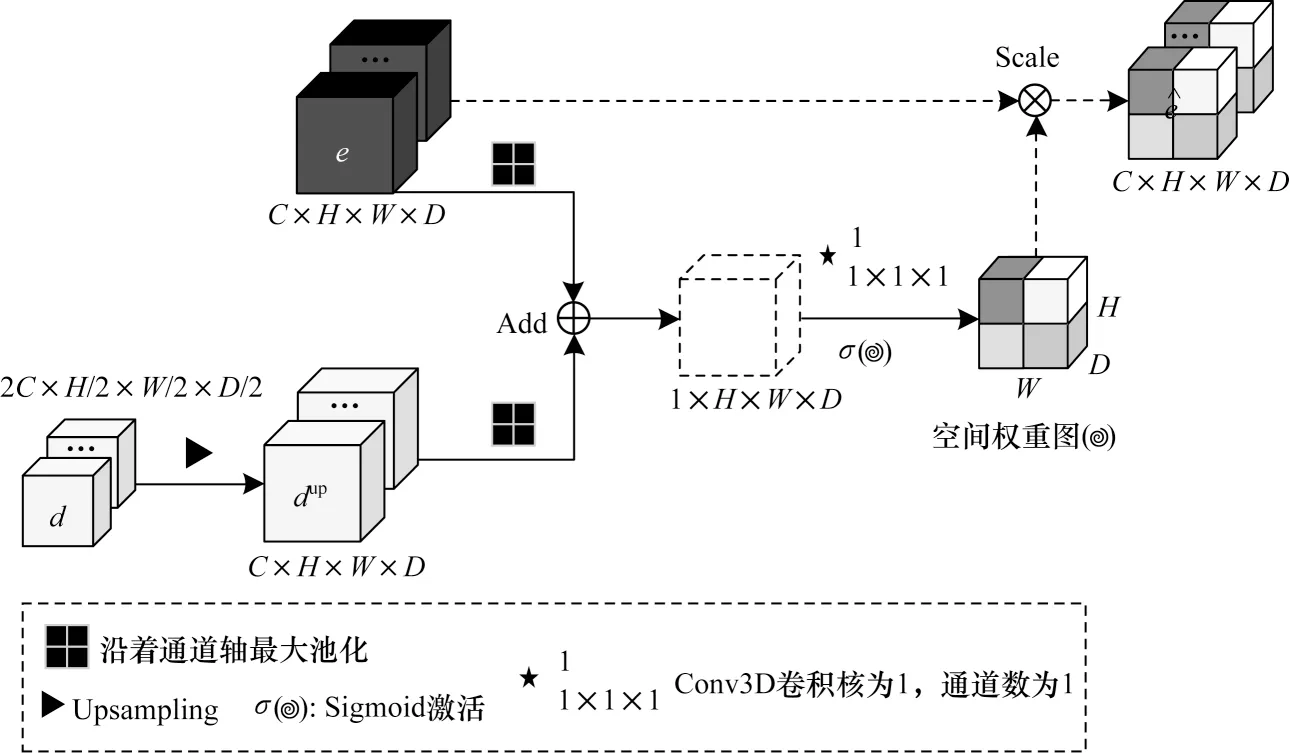
图4 双输入空间注意力模块的结构Fig.4 Structure of the dual-input spatial attention module

本模块与OKTAY 等[23]设计的自注意力门控模块类似,但是由于仅使用池化操作和卷积核为1 的卷积操作,增加的必须优化的参数几乎为0,可以配合更加深层的网络使用,而几乎不增加额外的时间成本。
1.3 损失函数
1.3.1 结构信息损失项
为实现无监督配准,网络的损失项必须不受模态限制,能够真正度量不同模态图像的相似性。模态无关邻域描述符(Modality Independent Neighbourhood Descriptor,MIND)特征是传统配准中经典的多模态测度,它定义在局部图像块(patch)上,描述的是每个体素周围的邻域特性。基于MIND 的相似测度假设是,即使在不同模态图像中,围绕体素的局部模式应该是相似的,与模态无关,通过最小化该相似性,可以促进配准优化。结构信息约束已被用作多模态合成时的损失函数[25],促进合成网络的优化,但是在深度学习配准网络中应用较少。本文将其向量化,实现梯度回传,直接应用于配准网络。下面将具体介绍结构信息损失项的计算方式。
MIND 特征可以用距离向量r和大小为p的图像块参数化。定义Dp为一对图像块的相似距离,其表达式为式(5)所示:
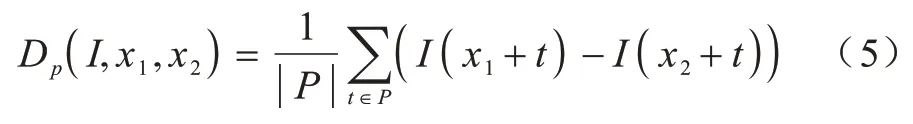
其中:x1和x2是图像I上的两个体素位置;P是以x1和x2为中心,大小为p×p×p的图像块之间的一系列位移量。因此,Dp实际上计算的是2 个图像块的均方差。
MIND 则被定义为Dp的高斯函数:
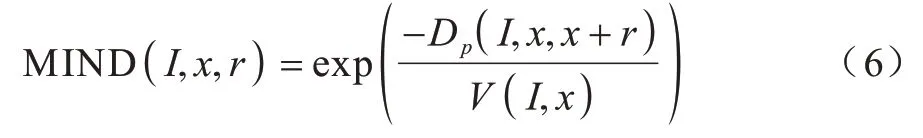
其中:x是图像I上的任一体素;r是距离向量;V(I,x) 是局部方差估计,一般采用6-邻域图像块(如图5 所示)的Dp期望值来估计,其表达式如式(7)所示:
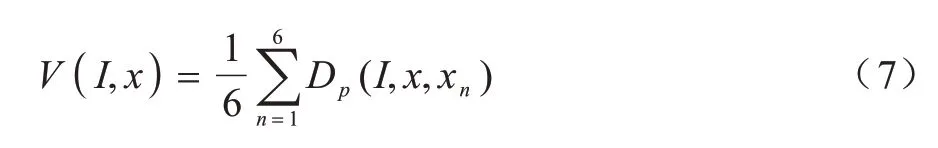
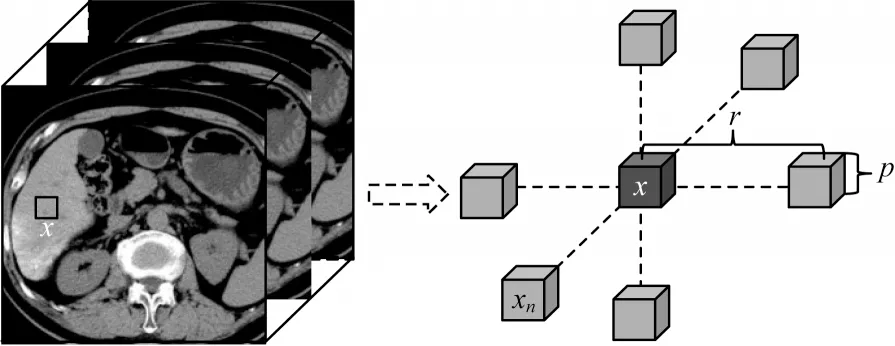
图5 MIND 特征的6-邻域结构示意图Fig.5 Schematic diagram of six-neighborhood structure of MIND feature
由于MIND 特征是Dp的高斯函数,在图像块不相似时表现为低响应,在图像块相似时表现为高响应,可以很好地表征局部特性。
最后,为构建结构信息损失项,采用平均绝对误差来计算配准图像之间的MIND 特征,定义如下:
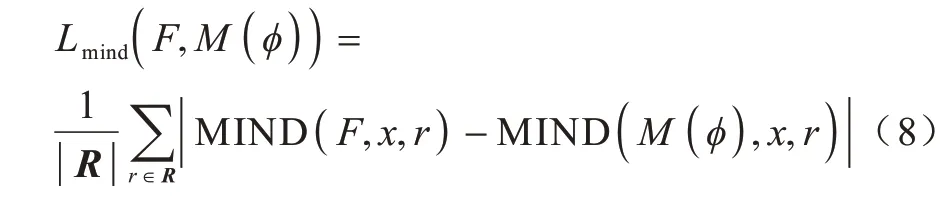
其中:F是固定图像;M(ϕ)是配准后的图像;R是6-邻域的位移向量。
1.3.2 雅可比负值罚项
除了相似性测度函数,一般为了保证形变的平滑性,会在损失函数中添加平滑约束项来约束形变,如:

其中:g表示x,y,z方向的形变位移量。正则项通过对图像在3 个方向上的梯度进行约束来确保平滑变形。
但是在图像配准过程中,所有的体素不一定经历相同的形变量,严重变形的体素会出现折叠或者撕裂现象,不符合真实图像情况。为减少上述情况发生,引入雅可比负值罚项来进一步约束形变。其定义如式(10)所示:
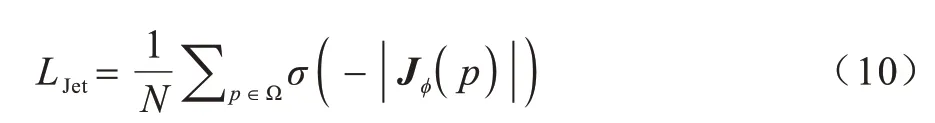
其中:N是中全部元素总数;σ(·)表示一个线性激活函数,对所有正值都是线性的,负值全部为0;实验中,设置线性激活函数为ReLU 函数。Jϕ(p)代表形变ϕ在位置p上的雅可比矩阵,其定义如下:
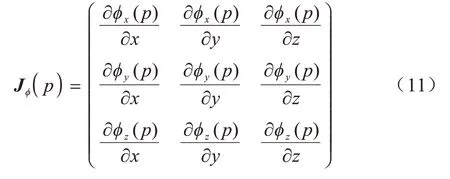
形变场的雅可比矩阵是3 个方向形变导数的二阶张量,其行列式可以用于分析形变场的局部状态。例如:点p∈J(ϕ) 为正值,表示点p在其邻域范围内能够保持方向一致性。相反的,如果点p∈J(ϕ)为负值,表示点p在其邻域范围内存在折叠,导致正常的拓扑性遭到破坏。根据此事实,在雅可比负值体素上添加反折叠罚项,可以抑制负值区域的折叠性,正值区域几乎不受影响。本文联合使用平滑约束项,在反折叠的同时尽量保持整体形变的平滑。
1.3.3 总体损失函数
配准网络的整体损失函数L如下:
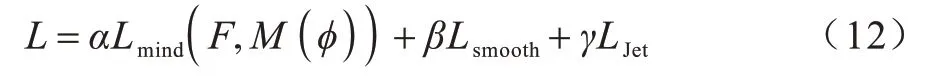
其中:α,β和γ分别是平衡结构信息约束项,平滑约束项和雅可比负值罚项的权值;Lsmooth是保持形变平滑性的约束项;LJet是用来减少体素折叠,保持图像的拓扑特性。经过多次实验调优,最终确定α,β和γ的值分别为10,0.5 和200。
2 实验设计
2.1 实验数据和预处理
本文实验数据为采集自丽水市中心医院的肝脏数据集,经过整理共有95 组CT-MR 图像及其对应的分割标签,表1 为图像的具体信息,其中两种模态图像层厚相差2 mm,是本文实验中距离误差的主要来源。分割标签由两位放射科专家标注、校对,用于评价配准精度。采用肿瘤的分割标签和中心点来评估局部配准精度[26],肿瘤的分割标签同样由放射科专家标注得到。

表1 图像及采集设备的具体信息Table 1 Specific information of image and acquisition equipment
本文随机选择20 组数据用作测试集,剩下的75 组数据作为训练集,同时采用5 折交叉验证的方式减少实验误差。为了提高配准精度,提升模型的鲁棒性,训练模型前,本文采用如下的预处理方式对数据进行处理:首先,采用Elastix[27]工具包中的线性变换对CT 和MR 图像进行病人内的对齐操作,减少由于体位变化和FOV 造成的巨大差距。然后,将图像重采样为1 mm×1 mm×1 mm 的各向同性空间分辨率。接着,将所有图像都中心裁剪和零填充为256 mm×256 mm×192 mm 的大小来适应卷积神经网络固定大小输入的要求。注意,裁剪的图像包含全部肝脏图像,足够进行实验。最后,将75 组训练数据中的每一组数据随机沿着x、y、z轴的任一方向进行翻转变换,扩充数据量为原来的2 倍,提升网络在有限数据情况下的训练精度。
2.2 实验细节
配准网络基于PyTorch 深度学习框架完成,并且使用Nvidia RTX 2080Ti GPU 进行加速。训练过程中使用Adam 优化器实现梯度下降,寻找使得损失函数最小的网络参数。网络训练的epoch 数为300;学习率为固定值0.000 4。另外,为适应GPU 内存大小,设置批次batch size 为1,同时下采样输入图像为原始大小的1/2,即128 mm×128 mm×96 mm。但是在推理阶段,会通过上采样获得全图大小的形变场,得到原始大小的配准结果。
当epoch 达到最大次数时停止网络训练,保存对应模型进行测试。本文每次训练需要近10 h,但是在测试阶段,完成一对尺寸为256 mm×256 mm×192 mm 的3D CT-MR 图像的配准仅需要不到0.4 s。
2.3 评价指标
本文采用如下5 个评价指标来评估算法在全局配准以及内部配准的有效性。
1)Dice相似系数(Dice Similarity Coefficient,DSC)和95% 的豪斯多夫距离(95 percentile Hausdorff distance,Hd95)常被用来评估图像的整体配准准确度。其中DSC 指标主要表示结构间的重叠程度,数值越接近1 越好;Hd95主要表示2 个标签边界间的距离程度,数值越低越好。假设图像A和图像B的分割标签分别为Amask和Bmask,则两者的定义分别如下:

2)结构相似性系数(Structural Similarity Index。SSIM)是评估重建图像结构信息相似度的一个指标[29]。其假设是人类在观察图像时主要关注结构信息(如形状、位置等),关注图像的结构性可以更准确评估图像的质量。SSIM 取值范围是[0,1],越接近1 表明配准后图像与固定图像越相似。SSIM 定义如下:
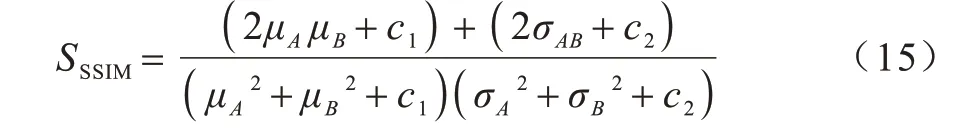
其中:μA,μB分别是图像A和图像B的均值,代表图像亮度估计;σA和σB是图像的标准差;σAB是协方差,用于测量结构相似性。c1和c2是维持稳定度的常量。
3)图像的拓扑特征也是决定图像配准质量的关键,一般使用雅可比值来评价,其中正值代表可逆性和拓扑保持。本文计算雅可比负值(|Jϕ|≤0)的占比来表示形变的拓扑性,数值越小代表拓扑结构越好。
4)目标配准误差(Target Registration Error,TRE)主要用来测量图像内部标记点的配准程度,定义为一组图像全部标记点的距离误差均方根,即:

其中:N是全部标记点的数目;ai和bi是图像的第i组标记点坐标向量。
本文对肝脏配准的全局评估采用DSC、Hd95、SSIM 和|Jϕ|≤0 这4 个指标,内部配准质量的评估采用DSC 和TRE 指标。
3 实验结果与分析
基于上述临床肝脏数据集,本文进行了如下实验:整体算法与其他相关算法的对比实验;结构信息损失项的有效性实验;多尺度形变融合框架和双输入空间注意力的消融实验;网络收敛性分析实验。
3.1 定量分析与可视化
为评估Ms-RNet 的性能,本文将与传统配准算法Elastix[27]以及2 个前沿的深度 学习配准算法Voxelmorph[14]、HU 等[15]进行比较。
Elastix 是一种经典的基于信息论的鲁棒多模态配准算法,常被用于胸腹腔多模态图像配准。本文在配准的准确度和运行时间上进行权衡,其中:相似度设置为最大互信息测度;优化器采用自适应随机梯度下降法;变换方式为B-样条变换;多分辨率是3 阶,每个分辨率的迭代次数为500。Affine 配准也是通过Elastix 实现的,可以用于观察整体形态上的仿射配准情况。Voxelmorph[14]是一种经典的无监督深度学习配准算法,能够直接学习输入图像对的非线性映射。HU 等[15]的半监督深度学习算法在多模态配准中具有优越的性能。为了满足对比需要,对于深度学习算法,本文保留上述原始论文的网络结构,损失项更换为结构信息损失项,对比结果见表2,其中“—”表示在初始状态时无法计算该值。
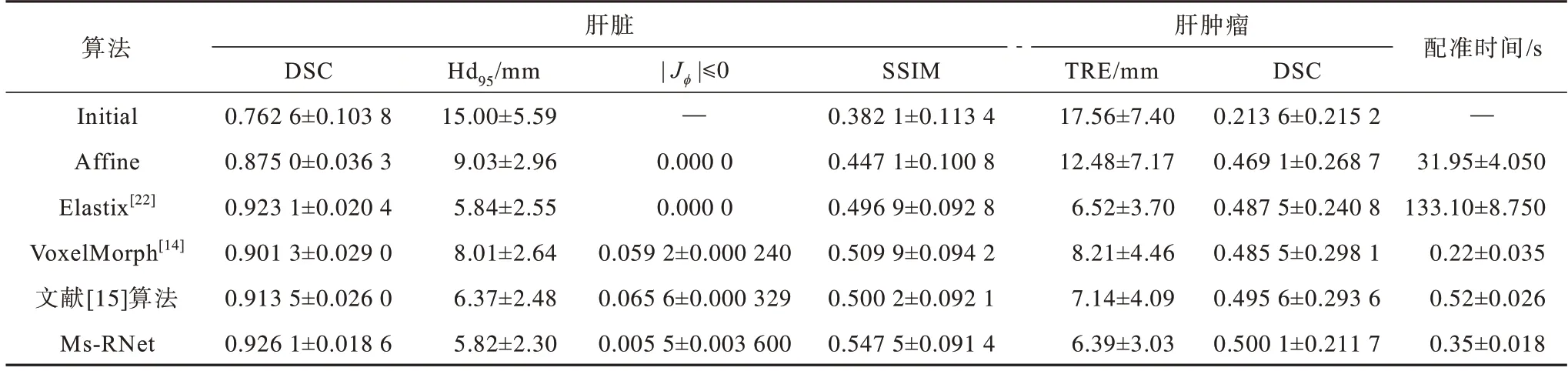
表2 肝脏和肿瘤的定量评估结果Table 2 Quantitative evaluation of the results from liver and tumors
由表2 可知,在肝脏的全局配准上,本文算法Ms-RNet的配准性能显著优于其他深度学习配准算法,达到最高的DSC、最低的Hd95和最优的SSIM值,分别为0.926 1±0.018 6、5.82±2.30 mm和0.547 5±0.091 4。另外,与Elastix 算法相比,Ms-RNet 算法在全局配准结果上略有优势,结构相似性指标提升明显。说明本文算法能够明显提高肝脏多模态配准的准确度。内部配准上,本文主要通过肝肿瘤的配准结果来展示。从表2 可以看出,本文算法在TRE 和局部肿瘤DSC指标上均能达到最优结果,从配准时间上看,本文算法的平均配准速度为0.35 ±0.018 s,明显优于传统Elastix 算法,提升了近380 倍,能够满足临床配准中的时效性需求。
为进一步直观展示本文算法的配准结果,随机选取两组测试数据进行可视化,结果如图6 所示,其中第1 列和最后1 列分别为浮动图像和固定图像,中间5 列分别是5 种不同的配准算法对应的配准结果。为展示肝脏的全局配准效果,将固定图像的分割标签(白色曲线)勾画在配准后的MR 图像上,同时使用箭头标记出配准后明显改进的区域。内部肿瘤的配准结果也进一步放大显示。从图6 可以看出,相比于其他算法,本文算法配准后的结果与固定图像最接近。尤其是箭头标记的大形变区域,Ms-RNet算法的配准效果最好,边界重合程度最高。内部的配准结果可以看图6 中肿瘤区域的放大图,其中白色曲线是“金标准”,黑色曲线是配准后的肿瘤区域。可以看出,本文算法能够较好地配准内部肿瘤区域,配准后的图像相似性最高。说明本文算法采用的注意力机制和多尺度融合策略能够提高特征表达能力,降低肝脏多模态配准的难度。此外,本文使用结构信息作为相似测度,能够有效度量内部纹理和形状特征,进而减少结构性差异,提高配准精度。

图6 不同算法在测试集下的配准结果Fig.6 Registration results of different algorithms under the test dataset
3.2 结构信息损失项的有效性验证
为验证本文模态无关结构信息损失项的有效性,对基于不同损失项的网络进行对比分析,结果如表3 所示。其中,Loss-MI 表示式(12)中使用互信息[28](MI:Mutual Information)损失项,约束项保持不变;Loss-SSIM 表示式(12)中使用结构相似性[29](SSIM)损失项,约束项保持不变;Loss-Ours 为式(12)的损失项。

表3 不同损失项的配准结果Table 3 Registration results with different loss items
由表3 可以看出,Loss-Ours 在多数指标上表现较好。在全局配准中:
1)与基于互信息损失的Loss-MI 对比,全局DSC 和SSIM 指标有明显提升,Hd95指标也有明显降低。但对于|Jϕ| ≤0 指标,Loss-MI 由于采用全局互信息约束,整体形变更加规则,雅可比负值更小,故此指标更有优势。
2)与基于结构相似性损失的Loss-SSIM 对比,除去SSIM 指标,本文损失项均能达到更优的结果。在局部配准中,Loss-Ours 明显优于另外两种损失项,体现出了模态无关结构信息损失项在局部结构配准上的优越性。
图7 所示为不同损失项的配准结果对比。从图7 虚线框可以看到,与另外2 种损失项相比,本文损失项可以更好地指导整体大结构的形变,得到与固定图像更加相近的配准结果。另外,由图7 观察箭头指示的肝脏边缘区域可以看出3 种损失项的配准平滑度有所不同,其中基于Loss-Ours 和Loss-MI得到的边缘更加规则,然而基于Loss-SSIM 的配准结果边缘曲折变化。这说明基于互信息和模态无关结构信息的损失项在保证图像形变的同时,可以在一定程度上减少拓扑折叠。
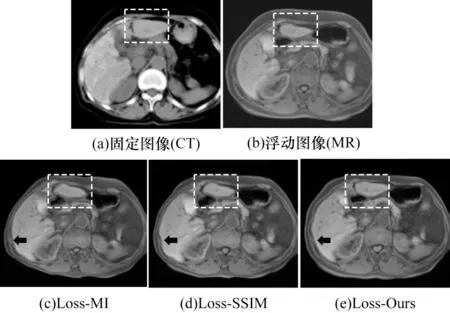
图7 不同损失项的配准结果对比Fig.7 Comparison of registration results with different loss items
3.3 消融实验
本节主要分析双输入空间注意力和多尺度形变融合框架的有效性,及有无雅可比负值罚项对于拓扑结构的影响。
3.3.1 双输入空间注意力的有效性验证
为验证双输入空间注意力的有效性,对有无双输入空间注意力的网络进行对比实验,结果如表4所示。可以看到,添加双输入空间注意力模块后,算法在全局配准以及局部配准上均有明显提升,且TRE 指标降低了16.33%。这表明该模块能够有效提取双流输入的不同水平信息,并通过空间权重的重赋值来突出差异性区域,提高特征表达能力。

表4 有无双输入空间注意力的结果对比Table 4 Results comparision with and without dual-input spatial attention
3.3.2 多尺度形变融合框架的有效性验证
为验证多分辨率残差形变框架的有效性,将配准网络RNet 与多阶Ms-RNet 进行了比较,结果如表5 所示。

表5 有无多尺度形变融合的结果对比Table 5 Results comparision with and without multi-scale deformation architecture
由表5 可知,Ms-RNet 与RNet 相比,配准性能有所提升。其中,在全局配准结果中,Ms-RNet 的DSC均值提升了约1.50%,Hd95均值降低了约16.50%,SSIM 提升了约5.11%。可见使用多尺度形变融合后可以降低配准难度,能更好地配准图像,提高配准的整体精度。由于多分辨率思想存在上下采样操作,导致Ms-RNet 的雅可比负值百分比|Jϕ|≤0 高于RNet,为0.005 5 ±0.003 6,但数值仍然在1%以内,配准后图像仍然能够保持良好的拓扑特性。本文采用的多尺度形变融合框架是一种coarse-to-fine 的理论,适用于解决大形变配准问题。然而,在局部结构的配准上,该理论作用有限。由表5 可知,尽管肿瘤TRE 指标降低了8.97%,但是肿瘤DSC 仅提高1.61%,提升幅度有限。另外,虽然Ms-RNet 算法增加了网络的参数量,但是从测试时间上看,整体的推理时间仅增加0.01 s,仍然可以很快完成配准。
为进一步直观展示多尺度形变融合框架的有效性,本文将Ms-RNet 生成的各阶形变场进行可视化,并且与RNet 网络的结果进行比较,如图8 所示。需要说明的是,本文可视化形变是将任意体素位置的形变向量的标量值()转化为灰度图得到的,其中灰度值表示该位置形变位移量大小,由黑到白逐渐变大。由图8可知,对于Ms-RNet算法,低分辨率图像主要是全局结构上的粗配准,当过渡到高分辨率图像配准时,会逐步精细化内部结构,增加对大形变区域的关注。具体表现为形变的复杂性增加,灰度值分散性增加,较大值主要集中在大形变区域(图中虚线框区域)。这表明,使用多分辨率残差形变可以更好地配准大形变区域,得到的配准结果也更接近固定图像。
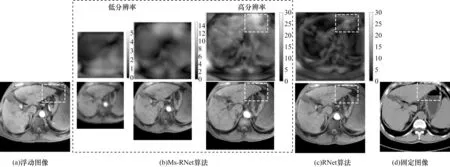
图8 Ms-RNet 算法和RNet 算法的形变场和配准结果的可视化Fig.8 Visualization of deformation fields and registration results for Ms-RNet and RNet algorithm
3.3.3 雅可比负值罚项的有效性验证
为了验证雅可比负值罚项LJet的有效性,本节在其他网络设置参数不变情况下,仅对是否使用雅可比负值罚项进行对比实验,结果如表6 所示。

表6 有无雅可比负值罚项的结果对比Table 6 Results comparison of with and without non-positive Jacobian determinant penalization
由表6 可知,在不添加LJet时,配准结果中的SSIM 值最高,说明在不加约束时,配准的图像在结构上会尽可能通过扭曲来接近固定图像,导致生成的图像存在更严重的体素折叠情况,雅可比负值|Jϕ|≤0 高达0.105 5 ±0.039 2。同时,由于内部肿瘤较小,受体素折叠的影响更大,内部配准性能明显下降,其中肿瘤配准DSC 仅为0.431 8 ±0.246 2,下降了近15.82%。而算法在添加LJet正则项后,不仅在|Jϕ|≤0 值上有显著的下降(降低了近19 倍),在其他配准指标上也均有显著提升。
图9进一步展示了有无LJet罚项的配准结果和形变场的可视化图。可以看出,没有罚项约束的形变场呈现非常明显的体素折叠和撕裂,配准的图像也存在明显的伪影(圈中区域)。而使用了LJet罚项的形变基本不存在拓扑折叠现象,形变平滑且连续。这说明雅可比负值罚项在保证基本形变不变的情况下,有效抑制不规则的形变,保证了算法的准确性和拓扑的一致性。
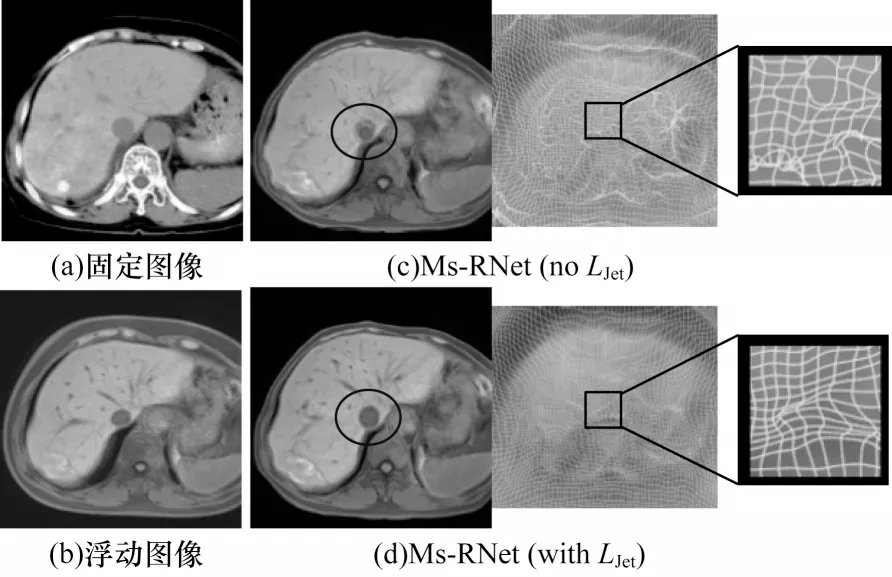
图9 有无雅可比负值罚项的配准结果及形变场可视化Fig.9 Visualization of registration results and deformation fields with and without non-positive Jacobian determinant penalization
3.4 网络收敛性分析
为进一步说明Lmind的有效性以及本文算法的鲁棒性,本节对不同的深度学习配准算法进行收敛性分析,其训练和验证损失曲线如图10 所示。从图10 损失曲线可以看出,前沿深度学习算法VoxelMorph 收敛速度最快,验证损失在接近100 个epoch 时即可收敛,但后续损失值逐渐升高(训练损失仍在下降),网络呈现过拟合现象。对比之下,RNet 和Ms-RNet 算法的损失曲线下降趋势稳定,且不存在过拟合现象。RNet 在接近270 个epoch 时基本收敛。Ms-RNet 由于采用多分辨率策略来降低参数初始化难度,收敛更快,在180个epoch附近即可收敛。
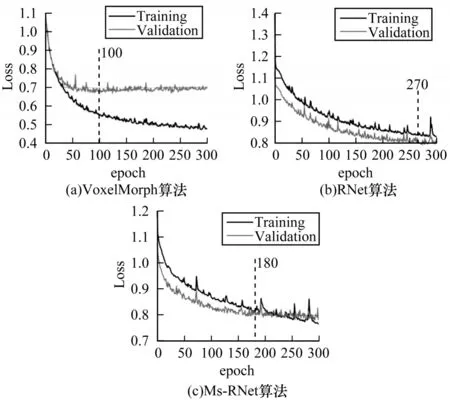
图10 不同深度学习配准算法的训练和验证损失曲线Fig.10 Training loss and validation loss curves of different deep learning registration algorithms
结合表2 和图10 整体损失曲线可知,结构信息损失能够有效促进多模态深度学习配准,即使在数据量较少时,也能够保证稳定收敛,得到良好的配准结果。本文的Ms-RNet使用双输入空间注意力和多分辨残差形变框架,在解决卷积神经网络感受野不足的同时,能很好地促使网络初始化,提高训练速度。
4 结束语
针对肝脏多模态图像差异性大、非线性形变明显、常规迭代式配准耗时长、配准精度低等问题,本文提出一种基于多尺度形变融合与双输入空间注意力的无监督图像配准算法。采用多尺度形变融合框架,以准确提取不同分辨率的图像特征。在设计的全卷积配准网络中添加双输入空间注意力模块,从而提取图像间的差异特征,增强特征表达。通过引入一种结构信息损失项进行网络迭代优化,在不需要任何先验信息的情况下实现精确的无监督配准。在临床肝脏数据集上的实验结果表明,本文所提算法能够准确配准CT 与MR图像,其配准精度高,且配准速度较Elastix 算法提升了近380 倍,能够满足临床需求。下一步将基于图像块进行配准,从而提高内部配准精度及解决数据量不足的问题。
