基于改进EfficientNetv2模型的多品种南药叶片分类方法
2023-01-19孙道宗刘锦源丁郑刘欢彭家骏谢家兴王卫星
孙道宗,刘锦源,丁郑,刘欢,彭家骏,谢家兴,王卫星
1.华南农业大学电子工程学院(人工智能学院),广州 510642;2.广东省农情信息监测工程技术研究中心,广州 510642
南药是指长江以南、南岭以北地区包括湖南、江西、福建、台湾等省区的全部或大部分地区所产的地道药材,是我国传统中药材的重要组成部分。目前广东省种植的药材有60多种,其中具有鲜明地域特色的南药种类有40余种,种植面积共约21万hm2,年产量约115万t,农业产值约160亿元[1]。在实际种植生产过程中,由于叶片的纹理复杂、背景的复杂性及药材叶片与树叶颜色和纹理的高度相似性,给南药材的分类和分拣工作带来一定困难。
对于复杂自然场景下的植物叶片目标检测和识别,近年来已取得一定进展。朱黎辉等[2]将基于形状和纹理特征的中药图像检索方式融合模式识别技术及人机交互技术运用到对中药材图像的检索上,提取BLBP纹理特征和IHOG形状特征并将2种特征进行组合,该方法的平均准确率达到93.56%。杨万里等[3]提取了颜色、形态和纹理等85个表型参数进行归一化处理后,将表型数据与作物的生长质量作线性回归分析,建立最优预测模型。凌秀华等[4]对麦冬药材的几何形状、颜色、纹理、横切面各组织的面积分数等特征进行提取,实现有效鉴别不同产地麦冬药材。陶欧等[5]通过分析18种中药材不同样本图像的26个纹理特征数,采用朴素贝叶斯及BP神经网络2种建模方法和十折交叉验证,建立18种中药材的判别模型,其准确率达到90%。钱丹丹等[6]利用计算机视觉系统提取中药饮片图像的特征并输入到朴素贝叶斯分类器,其综合分类准确率达到94%。药材通过加工制成后的中药饮片也可以利用深度学习进行分类和识别训练,并建立模型[7]。模型提取到足够的特征后,利用卷积神经网络对中药材图像进行识别。
此前手工提取特征的方法容易受图像噪声、背景复杂性等影响,造成提取特征出现偏差。随着深度学习理论的发展,基于学习的方法能够自动化提取数据特征,因此鲁棒性更好[8]。Xu等[9]提出了1种新的用于中药材识别的注意金字塔网络APN(atten‑tional pyramid networks)。APN可以自适应地对不同特征尺度的中草药图像进行建模,将其运用至构建好的中药数据集上开展试验并获得2%的性能提升。除了与图像识别结合,深度学习也能够和电子鼻技术进行结合,在原有的深度卷积神经网络(DCNN)上进行优化,在卷积层和池化层上使用特殊的一维内核,使其适合于电子鼻的数据,实现对多种类型的中药材分类[10]。孙鑫等[11]利用卷积神经网络研究中药饮片图像识别,运用Softmax函数来优化CNN识别模型,在50种中药饮片图像中可实现70%的平均识别精度。Anvarkhah等[12]利用机器视觉技术,针对药用植物种子的形态和颜色2种特征参数的组合,进行识别和检测研究,找出准确率最优的特征组合。基于深度学习的草本植物自动分类识别系统是根据叶片形状来识别植物类型,其方法可以应用至中药材图像信息库,进而建立更高效的、快速的药材信息检索方法[13]。Husin等[14]设计一种便捷高效的草本植物分类系统来提高分类效率,研究的重点在于中药叶片的形状和纹理特征的识别方法,识别准确率达到98.9%。Sladojevic等[15]利用深度卷积网络进行植物病害识别,该模型的试验精度在91%~98%,单独分类测试的平均精度为96.3%。
现有研究对药材识别的方法多为提取特征后再输入到卷积网络得到分类结果,但是仍然存在识别准确率不高、生成模型存储空间较大的问题,对硬件设备要求较高而难以应用到嵌入式或移动式设备上。Tan等[16]在2019年发布了基于CNN的主干特征提取网络EfficientNetv1,其使用基于强化学习[17-18]的神经架构搜索,将图像输入分辨率r、网络的深度depth以及卷积核个数width 这3个参数进行合理化配置,从而设计一个性能较好的主干网络。相较于AlexNet、VGGNet、GoogleNet等经典网络,EfficientNetv1模型在ImageNet上有更高的精度,并且卷积网络体量更小,速度更快。但EfficientNetv1网络也存在一些不足,比如训练图像要求的尺寸较大时,训练速度会非常慢,训练迭代周期较多时对硬件资源损耗较大;对每个stage的深度和宽度都是统一且同等放大,然而不同的stage在网络的训练速度以及参数量的贡献并不相同,因此,这种同等缩放存在不合理之处。EfficientNetv2[19]针对EfficientNetv1的不足进行改进,提出了改进后的渐进学习方法,该方法根据训练图像的尺寸动态调节正则方法。在模型缩放中采用非均匀的策略来解决同等缩放带来的不合理问题,通过试验获得结果与此前的网络相比,训练速度和参数数量上都有一定的优势。
为进一步提高分类网络的泛用性,优化网络结构,解决在复杂场景下南药材快速、高精度识别问题,本研究选择基于结构复杂但精准度较高的 Effici‑enNetv2 网络模型进行改进,在保持高识别准确率前提进一步下提升网络的性能,旨在进一步提高南药材的分类准确率和分拣效率。
1 材料与方法
1.1 南药图像数据集的制作和预处理
1)试验数据采集 。采样的药材基地包括位于广州市天河区柯木塱的广东省农业技术推广总站以及位于肇庆市高要区的南药省级现代农业产业园,涵盖广藿香(Pogostemon cablin)、沉香(Aquilaria sinen⁃sis(Lour.) Gilg)、巴戟天(Morinda officinalisHow)、何首乌(Fallopia multiflora)、化橘红(Citri Grandis Exocarpium)、广佛手(Citri sarcodactylisFructus),陈皮(Pericarpium Citri Reticulatae)和阳春砂(Amo⁃mum villosumLour)共8种南药,如图1所示。使用 SONY IMX386 1 200万像素带f/2.0光圈的摄像头,距离每种叶片5~10 cm、拍摄时取景角度在−49°~66°,拍摄周期内采集10次以上的数据,涵盖晴天、阴天和雨天3种常见气象情况,并且全部为室外情况,其光照强度范围为50~1×108lx,共采集南药叶片图像2 466 张。图像采集期间包含晴天、多云、阴天及小雨4种天气情况,采集时段集中于09:00-12:00,拍摄方位涵盖顺光、侧光、逆光、侧顺光和侧逆光。

图1 南药叶片图像样本Fig.1 Leaf of southern medicine image samples
2)数据扩增。为了提高训练过程的模型精确率和泛用性,本研究对训练样本进行数据扩增处理,扩增方法包含对比度增强、高斯噪声、仿射变换、镜面翻转4种手段,扩增效果如图2所示。通过对训练样本的扩增处理,将广藿香、沉香、巴戟天、何首乌、化橘红、广佛手、陈皮、阳春砂样本数分别从309、304、308、304、304、297、320、320张扩增至945、1 020、1 040、1 020、1 020、980、1 100、1 100张,整体数据集由原来的2 466张增加至8 225张图片,数量相较于扩增前约提升3倍,防止模型出现过拟合现象,提高模型的泛化能力。

图2 数据扩增处理后的效果图Fig.2 The effect picture after data amplification processing
3)数据预处理。由于扩增后图像样本数量较大,为了进一步提升网络模型的训练速度、收敛性以及准确率,对训练图像数据集进行预处理。本研究采用来自Pytorch官方的算法工具库所提供trans‑forms.Compose组件对南药叶片图像进行张量化处理、归一化处理和正态分布处理,其中transform.To‑Tensor()将输入图像数据原本(W(宽度),H(高度),C(通道数))的形状转换为(C,H,W)形状的Tensor格式,在将所有数据除以255,归一化到[0,1.0];正态分布处理则调用transforms.Normalize方法。将RGB 3个通道上的均值都设为0.5,3个通道的标准差也设置为0.5,参数mean和std均以0.5的形式传递,使图像的灰度归一化在[0,1],处理后的数据符合标准正态分布,模型更容易收敛。
1.2 改进EfficientNetv2网络模型的构建
1) EfficientNetv2相较EfficientNetv1的改进点。EfficientNetv2网络中在原本EfficientNetv1网络的浅层中引入了Fused-MBConv模块,模块结构变化如图3所示。由图3可知,Fused-MBConv是在原来的MBConv结构基础上,用1×1的卷积层替换了原本结构中的1×1的卷积层和深度可分离3×3卷积层,该网络模块替换v1网络浅层的MBConv层后进行训练,能够显著提升训练速度。EfficientNetv2模型将原本EfficientNetv1中卷积核大小为5×5的部分全部用3×3代替、降低输入/输出通道增加倍率值的大小、移除EfficientNetv1中第8个stage,进一步降低内存访问产生的开销并提高训练速度。
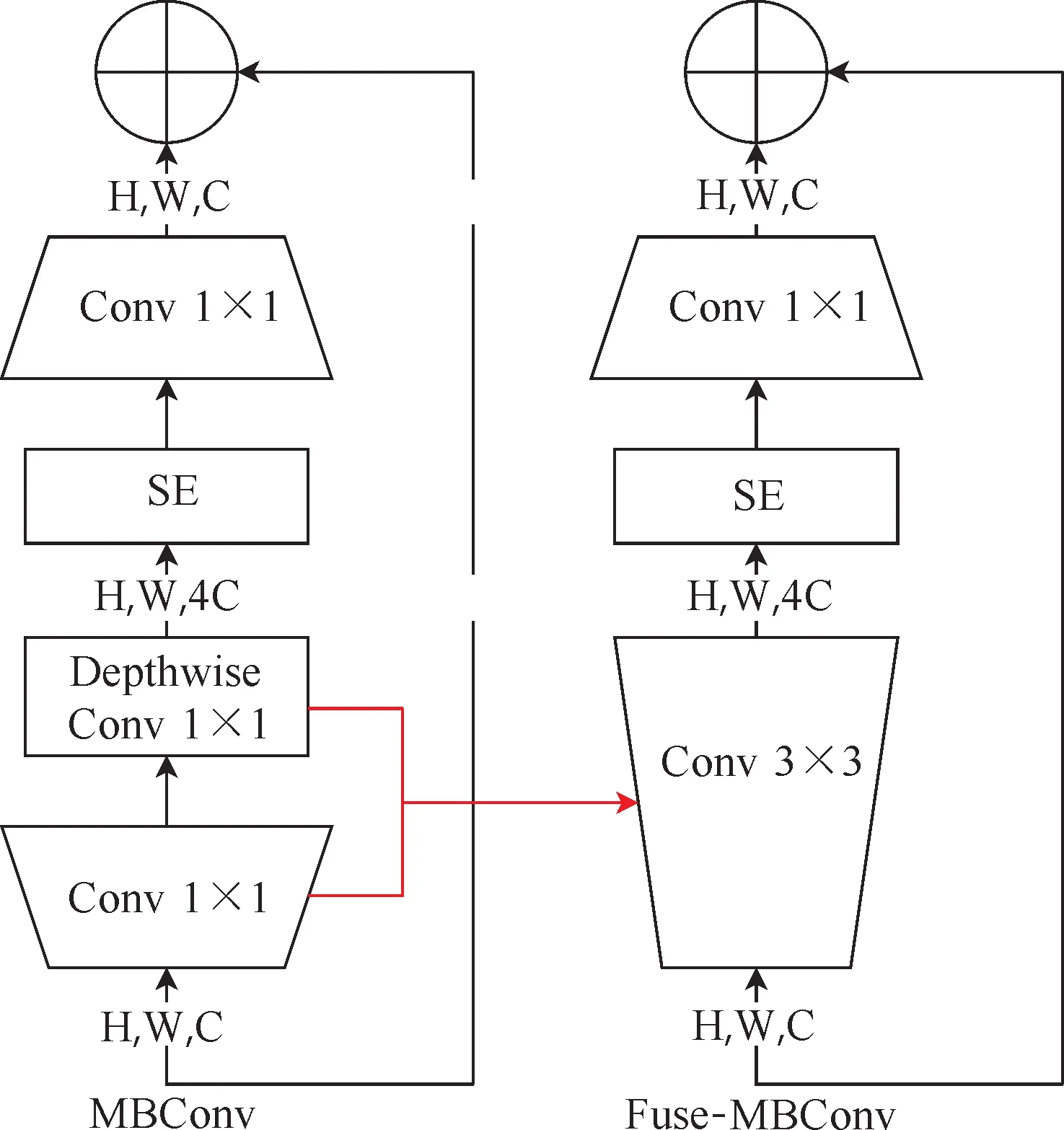
图3 MBConv 和Fused-MBConv的网络结构Fig.3 Structure of MBConv and Fused-MBConv
2) 改进EfficientNetv2网络模型的构建。Effi‑cientNetv2网络提供了S、M以及L 共3种初始模型,本研究选取最轻量的初始模型EfficientNetv2-S作为改进基础,该模型有44层网络结构,共分为7个阶段。初始模型EfficientNetv2-S是原作提供的几个初始模型中最轻量的1个,但是在训练时也存在运算量较大、单次训练时间较长、模型空间占用大的问题,因此对原有的网络结构层实行改进操作。改进后的EfficientNetv2-S模型结构在模型的7个阶段里,第一阶段和最后一阶段与原网络结构保持一致,通道数发生变化,其余的主要针对中间的第2~6阶段部分进行重新设计。网络结构改进前后如图4所示。图4A中,Conv3×3即3×3卷积和 SiLU激活函数; BN即批归一化层,SE=0.25表示使用了SE模块,0.25表示SE模块中首个全连接层的节点个数是输入该MBConv模块特征矩阵通道数 1/4,repeat即重复层数。将原本在前3个调用Fused-MBConv的阶段调整为前2个阶段使用Fused-MBConv,余下3~6这4个阶段使用MBConv模块,该改动的原因是MB‑Conv比Fused-MBConv有更小的扩展比,而更小的扩展比往往具有较少的内存访问开销。因此,调整了Fused-MBConv的使用架构,提高模型的感受野大小,降低模型复杂度和深度,从而进一步提高模型的轻量化。
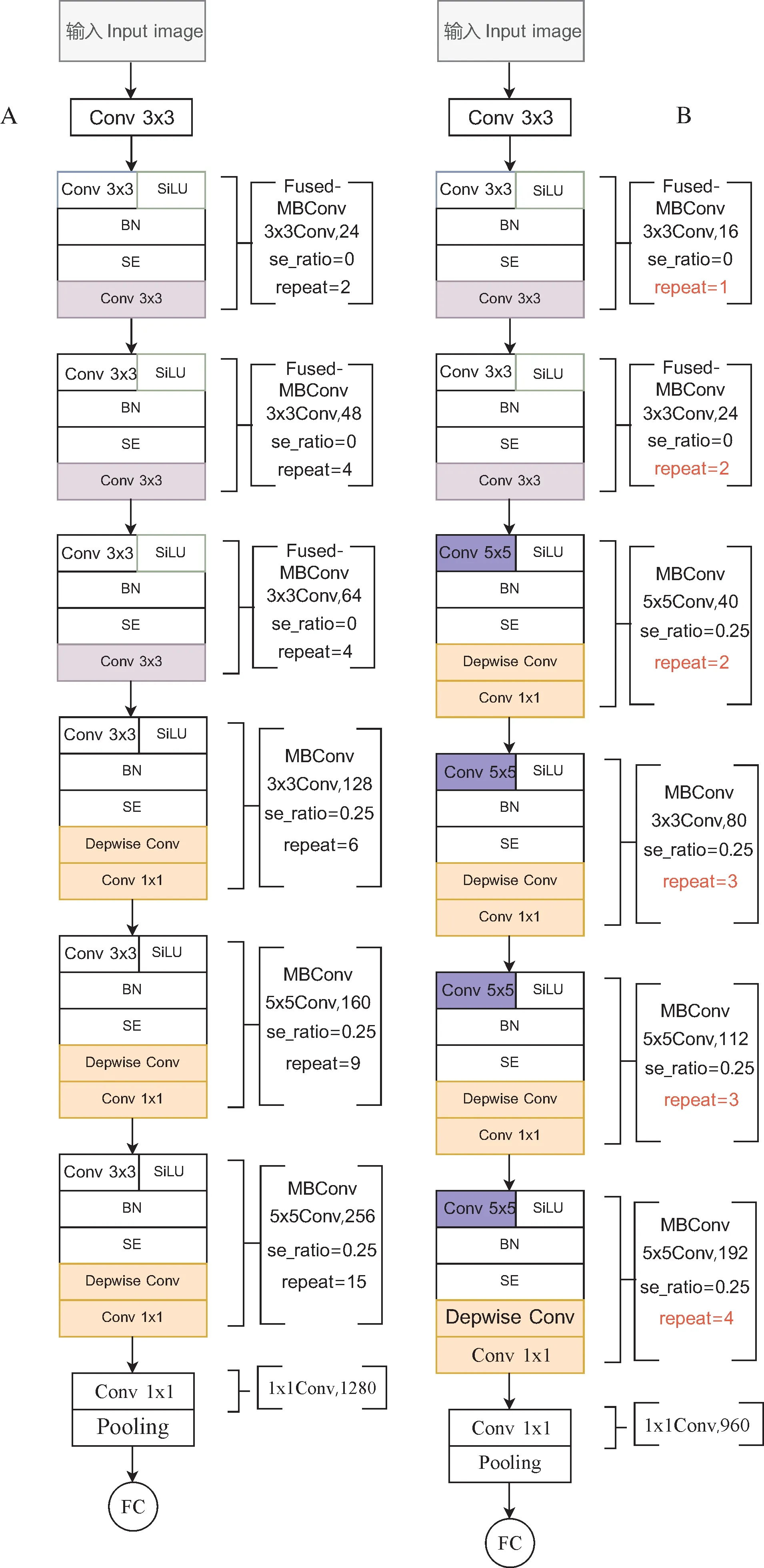
图 4 改进前后的EfficientNetv2-S网络模型结构对比图Fig.4 Comparison of the structure of EfficientNetv2-S network model before and after improvement
第二步是将第5~17层的3×3卷积核替换为5×5卷积核,即图4B中蓝色标记的部分,这一步是结合了EfficientNetv1的思想到改进模型中。在初始的EfficientNetv2-S模型中大量使用3×3卷积核,导致感受野减小,从而迫使整个网络需要增加更多卷积层进行弥补来保证模型精度。将部分3×3卷积层替换为5×5卷积核既可以提高精度,也能减少卷积层数量。
在前两步中,由于调整MBConv模块数量和部分卷积层替换更大的5×5卷积核,使得整个网络的感受野范围得到提升,因此不需要依赖更多的卷积层来维持模型精度。根据初始模型的比例对网络层数进行缩减。按初始模型的比例将第4~6阶段的6、9、15层缩减至3、3、4层,即图4B中红色字体标记的repeat部分,进一步降低模型的复杂度和冗余。经过上述调整,整个网络结构从原来的44层缩减至19层。其中,将1~6阶段共40层的3个Fused-MB‑Conv+3个MBConv的网络结构,优化为17层的2个Fused-MBConv+4个MBConv的网络结构,初始通道数由初始的24调整为16,最后在1×1卷积的全连接层作用下将特征图进行降维处理,降维后特征的分辨率没有发生变化,但是通道数变为960,改进后的网络结构如表1所示。
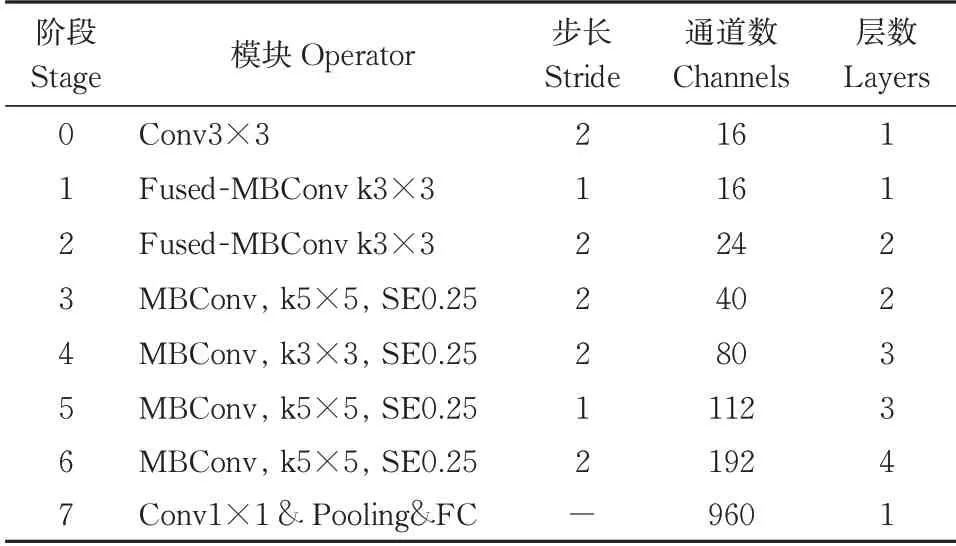
表 1 改进的EfficientNetv2-S的结构Table 1 Improvement of EfficientNetv2-S architecture
3)引入Adam优化算法。在EfficientNetv2-S中,采用的是固定步长随机梯度下降法(stochastic gradient descent, SGD)[20]。虽然该优化算法对梯度要求相对较低,但在随机选择梯度的过程中会增加噪声,导致权值更新比率会出现偏差。因此,引入自适应矩估计(adaptive moment estimation),即Ad‑am[21]优化算法替代原先的SGD优化算法。可以用训练数据的迭代来更新所用神经网络中的各个权重,在计算梯度的一阶矩估计和二阶矩估计时,Ad‑am会为各个参数设置独立的学习率。其算法更新规则如式(1)~(3)所示。
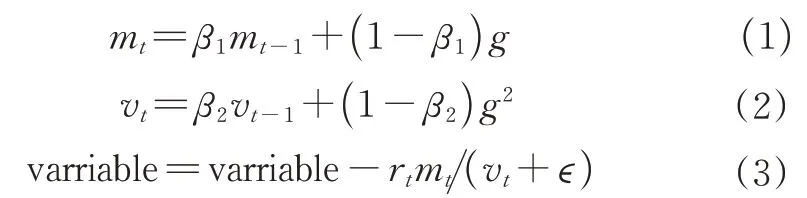
式(1)~(3)中,mt是计算历史梯度的一阶指数平滑值,vt是计算历史梯度平方的一阶指数平滑值,g指的是上一轮刚更新的梯度值,β1、β2是矩估计的指数衰减率,variable是指计算变量的更新值,rt为学习率,ε为除零误差项,目的是避免除数变为0。文中的Adam优化算法里,初始学习率是10-2,指数衰减率β1和β2分别是0.9和0.999,除零误差项ε是10-8。
4)损失函数的选取。MultiMarginLoss函数适用于相似且复杂背景下的多分类任务,在具体训练过程中对网络的收敛性有一定的提升。其表达式如式(4)所示。
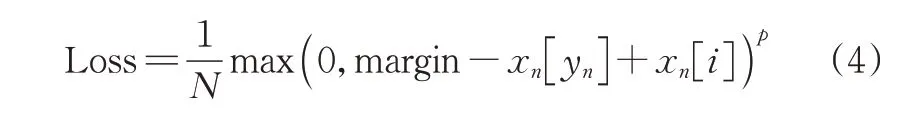
在式(4)中,x为神经网络的输出,y是真实的类别标签,N是类别标签数,yn的取值范围为[0,C-1],p值默认取 1,margin值代表边距,可人为设定阈值,一般取默认值1。
1.3 改进EfficientNetv2-S分类模型的训练与评估
1)模型的训练环境。基于Python3.8编程语言的Pytorch深度学习框架,Ubuntu操作系统, 8核16线程的Intel E5-2620 的CPU,GPU为内存12 GB的GTX TITAN X显卡4张,调用CUDA平台网络训练过程实行加速,集成开发环境为Pycharm。
2)模型评价指标。为了衡量模型的性能,本研究分别与初始提供的3类模型进行参数量(parame‑ters)和浮点运算次数(FLOPs)指标的对比,其中参数量用于衡量模型复杂度,FLOPs用于衡量模型运算性能。除此之外,模型还采用单次验证法进行模型性能的评估。具体操作如下:将数据集按8︰2的比例划分为训练集和测试集,然后使用训练集对模型进行指定迭代周期的训练,接着在测试集上进行客观评价指标的计算。为了对训练出的模型进行客观评价,采用测试准确率(test accuracy)、损失值(loss)、模型存储空间大小(model storage space)和平均训练时间(training time)等评价指标。
3)网络训练过程。初始模型EfficientNetv2-S在大型数据集ImageNet上进行预训练后产生的模型权重文件,选取pre_EfficientNetv2-S.pth进行迁移模型训练,通过迁移学习能够提升神经网络模型的收敛性,进一步提高模型分类的精确度。对于改进Effi‑cientNetv2-S模型在不同种类和不同超参数模型上的对比,采用单次验证法来训练和评估模型的性能。模型的训练流程如图5所示。由图5可知,整个网络的训练过程具体描述为:在扩增后的样本量基础上划分训练集和测试集,并在 Pytorch 深度学习框架中,加载预训练模型,获取与设定的批大小处理量相等数量的图像。利用 Adam 优化算法和学习率衰减机制对每个迭代次数(epoch)的学习率(learning rate)进行相应地调整,使其随着迭代次数逐渐减小。每批次样本在梯度下降时更新1次参数,迭代次数设置为100,批大小为32。在训练集上对改进 Efficient‑Netv2-S进行训练,并且MultiMarginLoss对分类概率值进行优化,在测试集上获得每个迭代次数的模型测试结果。
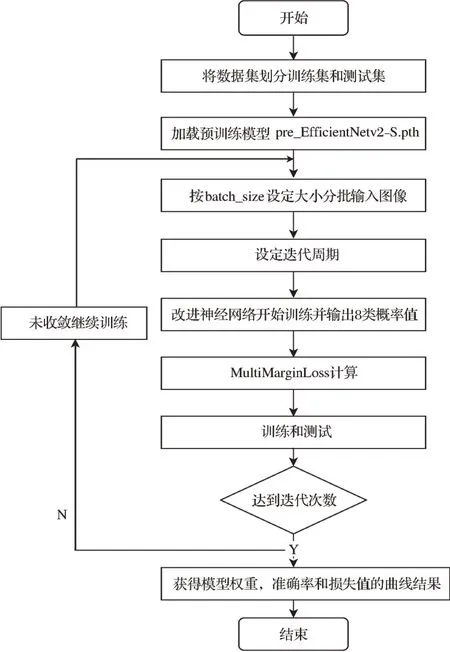
图 5 改进 EfficientNetv2-S模型训练流程图Fig.5 Improved EfficientNetv2-S training flow chart
4)超参数优化。学习率的大小会对模型的收敛速度有较大的影响,在Adam优化算法中,学习率设定过低会使模型收敛速度放慢,甚至降低模型精确率。如果设定太高,梯度有一定概率会在最小值的范围内上下波动,以至于可能出现无法收敛的情况。因此,需要对多个量级的学习率进行试验和比较。试验中初始批大小设置为32[22],尽可能通过较大的批大小处理量来改善收敛不稳定的问题。选取比较的学习率值分别为0.01、0.001、0.000 1和0.000 01,观察这4种学习率在模型训练中产生的损失值和准确率的效果(图6)。由图6可见,当学习率为0.000 01时,模型收敛速度相较其他学习率是最慢的,第100个周期时的准确率为88.6%,均低于另外3种学习率的准确效果。而学习率为0.01和0.000 1时则收敛速度较慢,到第20个周期,2个模型分别是0.422和0.429才开始趋近收敛。相较之下,学习率为0.001时,损失值下降地较快,收敛效果最好,损失值较低,说明学习率为0.001时具有更佳的效果,因此选择学习率为0.001。
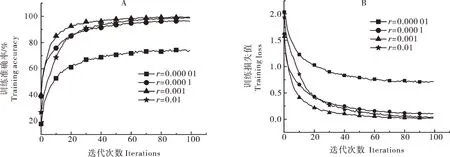
图 6 学习率调节对准确率(A)和损失值(B)的影响Fig.6 Influence of learning rate tuning on accuracy(A)and loss value(B)
2 结果与分析
2.1 不同优化器处理的优化效果
构建复杂背景图像的8种南药叶片图像数据集,通过超参数优化确定了Adam优化器的学习率为0.001后,设定迭代周期为100次,批大小为32,通过训练横向对比Rprop、RMSprop、Adagrad以及SGD等4种优化器的优化效果,观察不同优化器下的训练准确率和损失值结果(图7)。由图7可见,Adam优化器在收敛性方面要好于另外4个优化器,Adam优化器的准确率为99.12%,Adagrad、RMSprop和SGD分别为96.84%、97.40%和97.97%,三者较为接近,Rprop的准确率最低,为41.23%。损失值方面,Adam优化器为 0.002 17,Adagrad、RMSprop、SGD和Rprop分别为0.105 5、0.075 36、0.002 59和1.502,结果表明Adam优化器优化效果均优于其他4个优化器。
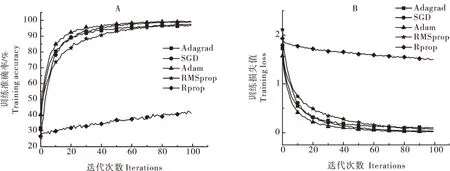
图 7 不同优化器下模型的准确率(A)和损失值(B)Fig.7 Comparison of the results of accuracy(A) and loss values(B) of the model under different optimizers
2.2 网络模型改进后的效果
利用torchstat工具计算每个模型的参数量和浮点运算次数以及训练时所占用内存大小,将改进Ef‑ficientNetv2-S模 型 与EfficientNetv2-S、Efficient‑Netv2-M、EfficientNetv2-L这3个模型进行比较,其结果如表2所示。由表2可知,改进后的Efficient‑Netv2-S模型在参数量、运算次数以及占用内存大小等3个指标都明显优于初始的3个模型,相较初始最轻量的EfficientNetv2-S模型在参数量和运算次数方面都下降了约85%,表明改进模型结构在复杂度上有所下降,模型性能明显提升。除了上述参数量和计算次数,在保持其他超参数、批大小、学习率、迭代周期等变量一致的基础上,还比较了原始模型Effi‑cientNetv2-S和改进后的EfficientNetv2-S网络模型在测试准确率、损失值、模型空间存储大小和训练时间等4个指标的差异,进一步观察改进后的网络模型性能变化情况。本研究将南药叶片图像数据集按照 8︰2比例划分为训练集和测试集,迭代次数为100,学习率和批大小分别取 0.001 和 32,则改进前后模型的种类识别结果如图8所示。由图8可知,改进后的EfficientNetv2-S模型在测试训练集的准确率为99.12%,相较于初始网络模型EfficientNetv2-S的97.97%,提升了约1.17%。损失值方面,改进模型和初始模型分别为0.002 17和0.002 59,降低16.21%。从结果上看,改进后的EfficientNetv2-S模型在准确率和损失值两方面比EfficientNetv2-S模型有小幅领先。从图8也可看出,改进后的EfficientNetv2-S模型的准确率和损失值在收敛性上优于初始的Effi‑cientNetv2-S模型。
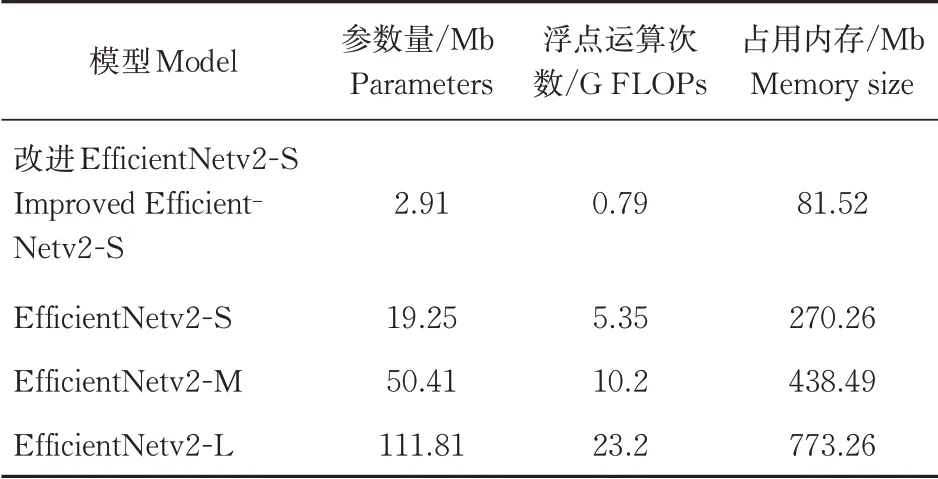
表2 不同模型的性能参数对比Table 2 Comparison of performance parameters of different models
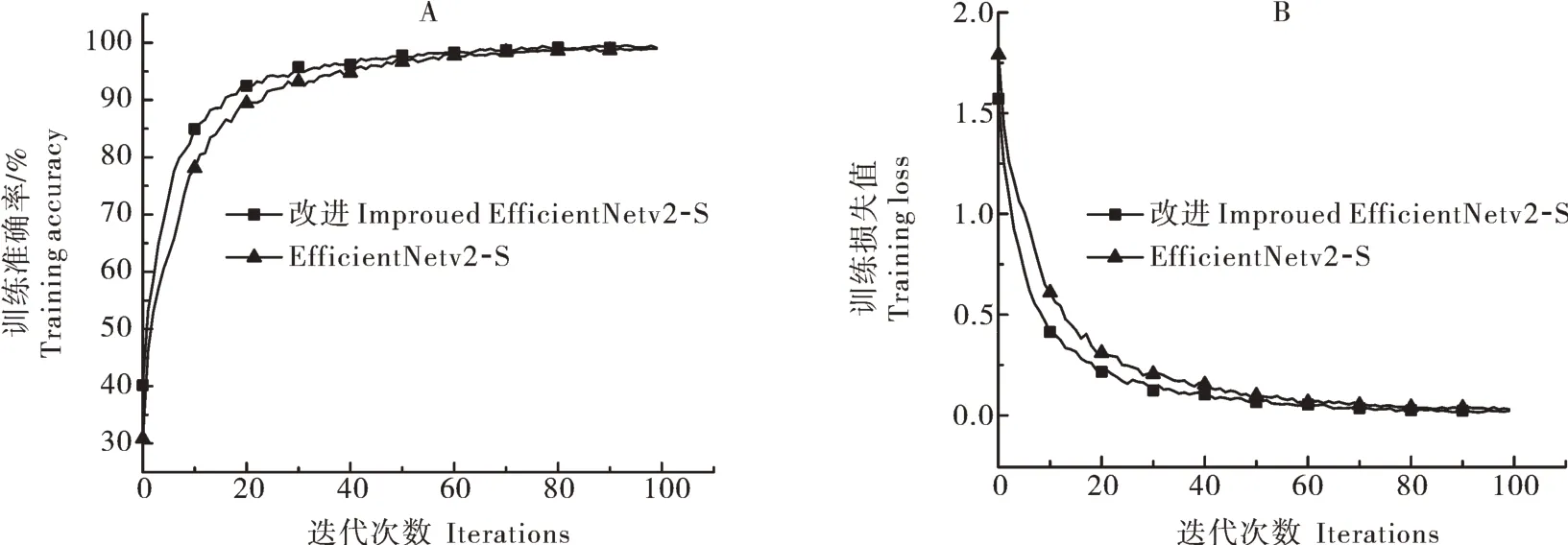
图 8 改进前后模型的准确率(A)和损失值(B)Fig.8 Accuracy rate(A) and loss value(B) of the model were compared before and after improvemt
2.3 不同神经网络模型的对比结果
利用复杂背景图像的8种南药叶片图像数据集对改进的 EfficientNetv2-S模型进行训练,并与其他轻量级的网络模型进行对比。运用迁移学习训练模型,以8︰2比例划分为训练集6 580张和测试集1 645张,不同模型的预处理方式、优化算法等基本设置保持相同,迭代次数100,学习率和批大小分别取0.001 和32,不同模型的种类识别结果对比见表 3。
由表3可知:(1)改进的EfficientNetv2-S模型在单次的平均训练时间上与DenseNet121、ShuffleNet、RegNet 3个轻量级分类网络相比差距在1.29%~5.19%,并且均低于80 s;与EfficientNetv1模型相比,训练时间减少79 s,缩短50.64%。在训练过程中还发现改进后的EfficientNetv2-S模型收敛性和准确性明显高于其他模型,特别是相较RegNet的准确性有明显的优势(图9)。(2)经过改进的EfficientNetv2-S模型在模型存储空间上得到大幅压缩,相比DenseNet121、RegNet和ShuffleNet模型存储空间大小分别降低55.30%、21.26%和19.31%,模型存储空间的轻量程度有一定的明显优势。(3)改进的Effi‑cientNetv2-S模型在模型存储空间和平均训练时间这2个指标保持一致或领先的条件下,相较于Effi‑cientNetv1模型,准确率提高0.69%,损失值降低51.67%。改进后的EfficientNetv2-S模型在模型存储空间上相较于初始模型从79 742 kb下降到12 201 kb,降幅为84.70%,存储空间优化效果明显,单次训练所耗费的平均时间从147 s下降到77 s,模型训练时间下降47.62%,表明改进的EfficientNetv2-S模型在保持高准确率基础上,能够做到对空间存储大小和训练时间的优化,实现复杂分类网络模型的轻量化。说明改进的EfficientNetv2-S模型在保持高准确度的情况下,还能进一步降低模型损失值,并且在此条件下降低训练时间和模型存储空间大小,其模型性能要明显优于EfficientNetv1模型。
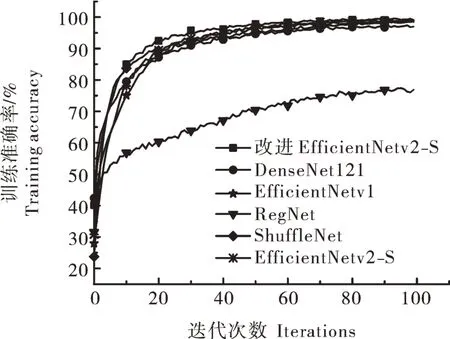
图9 不同模型的训练准确率结果对比Fig.9 Comparison of the training accuracy of different models for species recognition
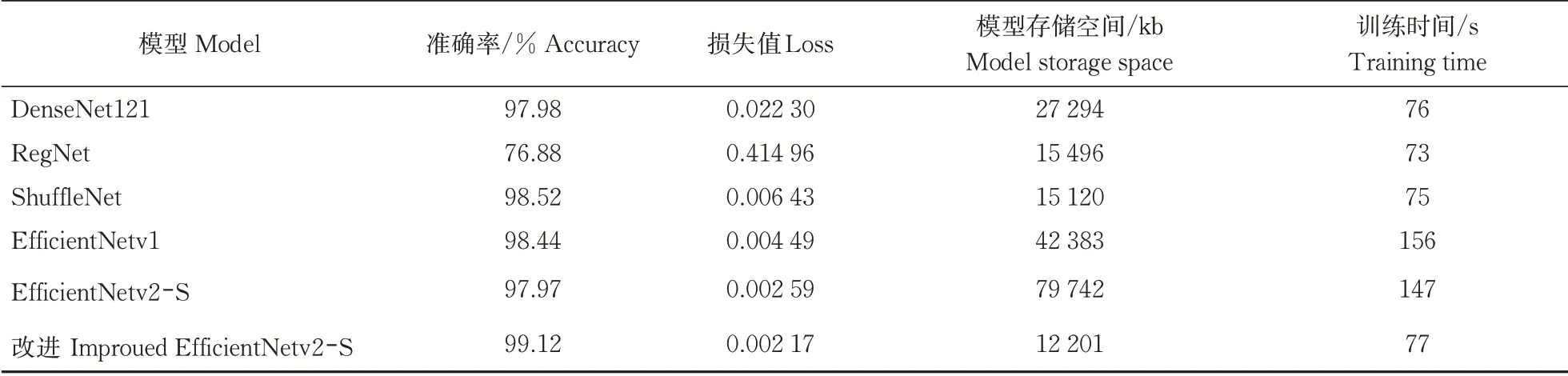
表3 不同模型的种类识别结果比较Table 3 Comparison of the results with different kinds of different mode
3 讨论
本研究在解决目标多分类问题时,原始模型采用交叉熵损失函数进行模型优化,使模型输出逼近理想情况下的输出结果。虽然交叉熵损失的收敛效果良好,但是仍然存在局限性:对于包含复杂背景信息的图像,即叶片像素数量明显小于背景像素数量时,会导致交叉熵损失函数中背景信息成分会占据主导,使网络模型明显偏向背景,导致识别效果有所下降[23]。
Goutham (http://cs230.stanford.edu/projects_fall_2021/reports/103171653.pdf.)分别比较了MultiMar‑gin损失函数和交叉熵损失函数对模型的影响,其结果显示在准确性方面MultiMarginLoss比交叉熵损失函数高0.62%~1.00%,并且,具有复杂背景的图像信息熵较大,容易导致交叉熵不确定性增加,影响模型准确性。而MultiMarginLoss是基于边距的多分类合页损失函数,不容易受到影响,因此采用MultiMar‑ginLoss作为改进EfficieNetv2-S模型的损失函数。在深度学习的卷积神经网络领域中,要获取最优的权值结果,就需要优化算法在网络模型中损失函数,从而得到最小的损失函数值,而求解最优化问题最常用的方法就是梯度下降算法。深度学习中常用的优化算法包括SGD、RMSprop、Adam、Adguard等[24]。本研究提出引入Adam优化器并进行超参数优化,获取精度较高的学习率对模型进行训练。
本研究提出一种基于改进EfficientNetv2-S模型的南药叶片种类识别方法,通过调整MBConv模块结构,替换部分卷积核,加载预训练权重进行迁移学习,对模型的网络结构复杂度和冗余度进行一定精简,实现轻量化目标。将改进后模型对多品种南药叶片数据集进行多组对照试验,结果显示:与初始模型Effi‑cientNetv2-S相比,改进后的EfficientNetv2-S在参数量和计算次数都明显下降,在对南药叶片种类进行识别的过程中,准确率、损失值、训练时间、存储空间大小等指标明显优于初始模型,说明该改进模型的识别准确度较高,并且模型的复杂度和参数量下降,模型性能得到进一步提升。与其他轻量级的分类网络模型进行横向对比,结果表明,在准确率方面,改进Effi‑cientNetv2-S要比另外3个轻量级分类网络模型都有所提升,其中对比DenseNet121提升效果较为显著。改进EfficientNetv2-S分类模型能够保持高精度识别效果的同时减少模型参数量,达到轻量化与高精度之间的平衡。
本研究采用卷积神经网络并对网络模型进行轻量化重构,实现了在保持高精确率的同时进一步降低模型复杂度和存储空间,对于嵌入到移动式设备或单
片机等对存储空间和实时传输条件要求较高的环境而言有较好的适用性。该模型仍有进一步改进的空间,比如测试多种不同学习率衰减机制来确定更适合的更新梯度算法组合。对数据集方面如果能考虑到南药叶片在更多气候条件下的成像效果,再进行训练和测试能够进一步提高模型的泛用性和鲁棒性。
