复合层次融合的多模态情感分析
2023-01-17王旭阳
王旭阳,董 帅,石 杰
兰州理工大学计算机与通信学院,兰州730050
情感分析,又称为意向挖掘或者情感倾向分析,其在人机交互方面发挥着重大的作用[1]。随着工业和互联网的发展,越来越多的用户倾向于在社交媒体(Tik Tok、Facebook、Twitter、YouTube 等)上分享、展示自己的生活状况,并且发表自己对社会各类事物的看法。有关情感分析的研究已经被广泛地应用到了各种领域,比如:通过对网民的情绪分析可以帮助政府掌握社会的舆论走向,优化对消费者的商品推荐,以及对舆情的监测与引导等。
情感分析是传统自然语言处理(natural language processing,NLP)中非常重要的一个研究领域。然而传统的情感分析主要是针对用户在网上的评论、留言等纯文本内容进行分析、处理、归纳和推理的过程。仅使用文本不足以确定说话者的情感状态,而且文本可能会产生误导。随着短视频应用的蓬勃发展,非语言行为(视觉和听觉)被引入来解决上述缺点[2-3]。与纯文本相比,视频中的人物蕴含丰富有关人物情感倾向的模态信息,其中包括文本、视频、音频。
多模态情感分析(multimodal sentiment analysis)是对文本、视频、音频的多模态数据进行综合挖掘,发现其隐藏信息,并最终预测出其情感状态[4]。社交媒体是多模态数据的海量来源,以视频为例,视频中包含了文本、音频和图像这三种信息载体,文本能携带语义信息,音频能携带语气、音调等信息,图像能携带表情、手势等信息。三种模态的关系是相互补充、相互解释的,单从一种模态上来分析其情感色彩是不全面的。如图1 显示为一个视频片段中人物进行对话的时候说的一句话:“what's wrong with you?”,这句对话是个疑问句而且没有明显体现情感取向的词语,因此仅仅依据这句话所传达的信息很难判断出说话人的情感状态,但如果结合说话人的面部表情(皱眉)和语音语调(低声),则可以反映出说话人目前的情感状态是消极的。这种不同模态之间的情感信息相互解释、相互补充称之为模态之间的交互性。

图1 多模态表达实例Fig.1 Example of multimodal data
与单模态情感分析相比,多模态情感分析不仅要充分提取其单独模态的特征,还要考虑不同模态之间的融合和信息的交互,传统的多模态信息融合主要分为早期融合和晚期融合,又称决策层融合。早期融合是在模态信息输入到模型训练之前把各个模态的信息进行拼接,然后进行训练。一般的做法是在信息输入的时候直接将多模态特征向量进行整合,但是这种融合方法并没有关注到不同模态特征之间的语义差异。假设三个模态信息单独表达的情感是不完全相同的,那么就有可能其中的一种或两种模态信息是真正结果情感状态的噪声干扰。晚期融合[5-6]是先把模态信息进行单独训练然后在决策层进行投票最后得出预测结果。这种方法虽然能充分挖掘出各自模态中所蕴含的情感信息,但是明显缺失模态之间的交互性。
为了解决上述问题,本文提出了一种基于时域卷积网络和软注意力机制结合复合层次融合的多模态情感分析的模型。首先,该模型将每个话语的单模态特征信息进行复合层次融合,融合过程中使用TCN(temporal convolutional network)提取其序列特征,最后使用软注意力机制减少噪声和冗余信息的干扰,最终得到一个关于多模态融合的特征向量用于情感分类(详细介绍见第3 章)。实验测试表明,该模型在多模态情感分析上的准确率和F1 值均表现出良好效果。
1 相关工作
情感分析作为文本信息挖掘的主要内容,近年来深度学习模型的引入在情感分析领域取得巨大成就。单模态信息提取通常使用的深度学习模型一般有卷积神经网络(convolutional neural networks,CNN)[7]、门控循环单元(gated recurrent unit,GRU)[8]、长短期记忆网络(long short-term memory,LSTM)[9]。
针对不同模态信息之间的相互融合,Cambria 等人[10]提出了一个通用的多模态情感分析框架,该框架由模态内的表示学习和模态间的特征连接组成。基于这个框架,许多研究集中在设计一个新的融合网络来捕获更好的多模态表示并获得更好的性能。对于多模态间融合,Williams 等人[11]提出一种基于EFLSTM(early fusion-long short-term memory)的融合方式,先将三个模态的初始输入连在一起,然后使用LSTM来捕捉序列中的长距离依赖关系。与EF-LSTM相比,后期融合LF-DNN(late fusion-deep neural network)先学习单模态特征,然后在分类前将这些特征进行串联。虽然上述方法在一定程度上能够解决相关问题,但是仍存在不足之处,都忽略了各模态内部信息与模态之间交互作用的结合。如何提高模态之间的交互信息并进行建模是一个值得关注的问题。Zadeh 等人[12]提出了一种记忆融合网络(memory fusion network,MFN),对特定视图和跨视图的交互进行核算,通过特殊的注意力机制对其进行持续建模,并利用多视图门控记忆进行时间总结。MFN 需要在三个模态中进行词级对齐。Zadeh 等人[13]提出一种基于张量融合的特征融合网络(tensor fusion network,TFN),TFN 属于early fusion,是一个典型的通过矩阵运算进行特征融合的多模态网络,同时考虑到模态内部信息以及模态之间的交互作用,但是TFN 通过模态之间的张量外积(outer product)计算不同模态的元素之间的相关性,这会极大地增加特征向量的维度,造成模型过大,难以训练。因此,Liu 等人[14]采用低阶多模态融合方法对权重张量进行分解,降低了基于张量方法的计算复杂性,模型通过与模态特定的低阶因子进行高效的多模态融合来学习模态特定和跨模态的相互作用。Tsai 等人[15]提出一种多模态变换器(multimodal transformer),该模型利用跨模态注意力,实现多模态序列之间跨不同时间步长的交互。Shenoy 等人[16]提出的基于上下文感知的RNN(recurrent neural network)模型能够有效地利用和捕获所有模态对话的上下文用于多模态情绪识别和情感分析。Hazarika等人[17]提出一种MISA(modalityinvariant and-specific representations for multimodal sentiment analysis)的多模态情感分析框架,把每个模态划分为不同的子空间用来学习相关的情感表示,以帮助融合过程。虽然上述方法在精度上有一定提升,但是在多模态数据融合过程中如何有效地利用整合多模态信息进行情感分析依旧是一项艰巨的任务。
综上所述,随着人工智能研究的不断深入,多模态情感分析也得到了巨大的发展。但是如何有效地利用单模态特征和多模态特征之间的交互进行建模依旧是多模态情感分析所面临的主要问题。大多数关于多模态数据融合的工作都使用串联或早期融合作为它们的融合策略。这种简单化方法的问题在于不能过滤从不同模态获得的冲突或冗余信息。本文在早期模态特征信息融合的基础上[11-15]和文献[18]启发下,结合时域卷积网络和软注意力机制设计了一种复合层次融合的多模态情感分析模型(TCN-multimodal sentiment analysis with composite hierarchical fusion,TCN-CHF)。采用复合层次融合方法,能够最大程度地挖掘和保留不同模态内部的情感信息,并且通过复合层次融合不断加强模态之间信息交互的表达。利用TCN 网络和注意力机制更好地提取模态信息中的序列特征,以及文本、视频、音频不同模态信息之间的交互性,并在融合过程中为其分配更合理的权重,减少多模态信息中的噪声以及过滤冗余信息,实现多模态特征信息的有效融合。
2 TCN 和Attention 结合复合层次融合模型
2.1 时域卷积网络
时域卷积网络是一种新型的可以用来解决时间序列的算法。TCN 相比传统的RNN 网络有诸多优点。例如,TCN 网络可以根据层数、卷积核大小、扩张系数灵活控制感受野,同时梯度也更加稳定,并且可以并行处理时序特征信息,所需要的内存要求也更低。
2.1.1 TCN 网络结构
TCN 不同于传统的卷积神经网络CNN,其主要采用两种结构:因果卷积(causal convolution)和膨胀卷积(dilated convolution)。
(1)因果卷积:可以用图2 直观表示,因果卷积不能看到未来的数据,它是单向的结构,不是双向的。也就是说只有有了前面的因才有后面的果,假如要预测当前时刻的信息,只能依靠当前时刻之前的信息进行预测,即只能通过当前的时刻输入xt和之前的输入x1,x2,…,xt-1进行计算,是一种严格的时间约束模型,因此被称为因果卷积。
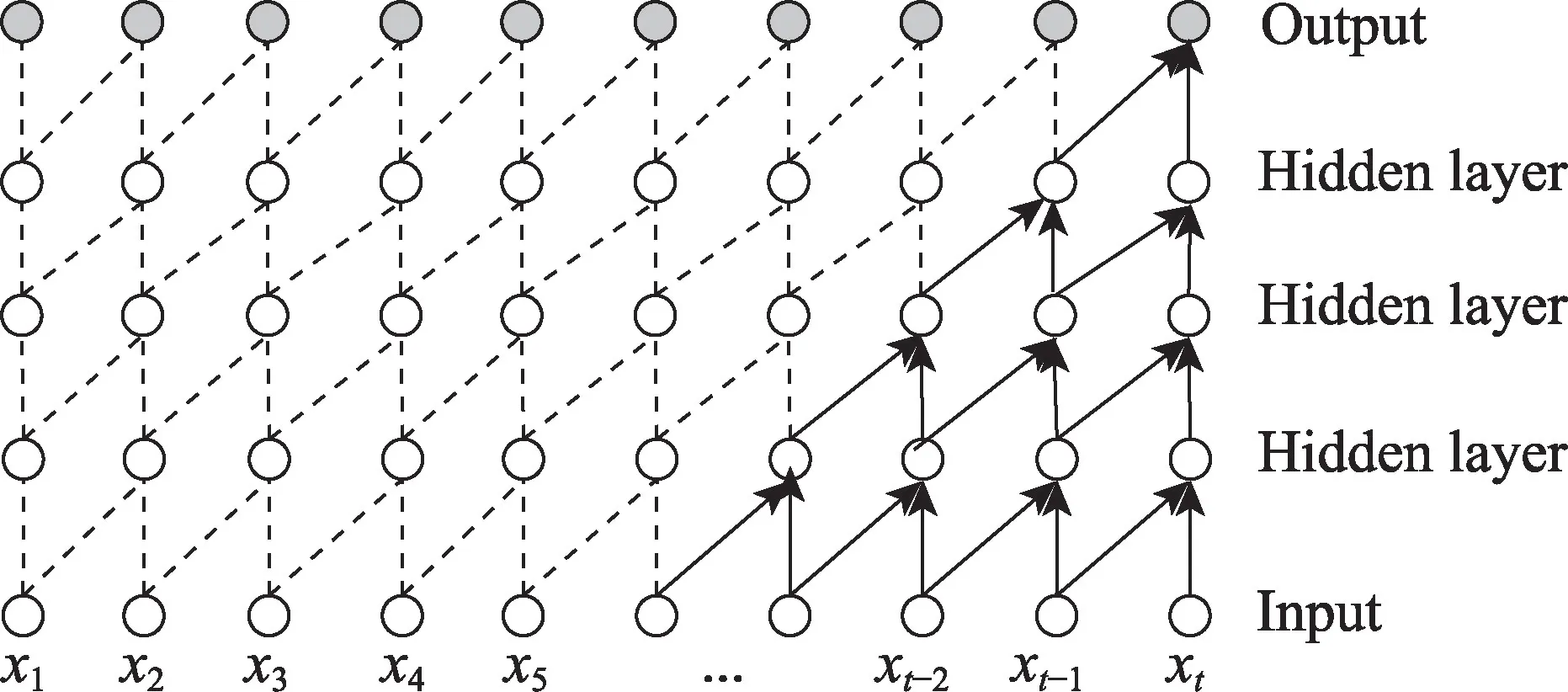
图2 因果卷积Fig.2 Causal convolution
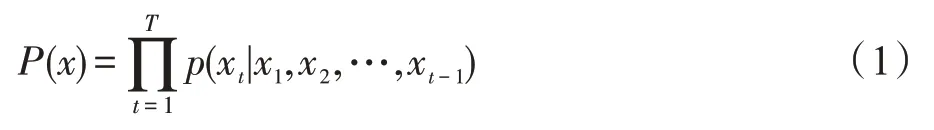
(2)膨胀卷积:单纯的因果卷积存在传统卷积神经网络的问题,即对时间的建模长度受限于卷积核大小,如果要获取更长的依赖关系,就需要堆叠很多线性层。为了解决这个问题,TCN 网络结构采用膨胀卷积,其结构如图3 所示(图中,xt为原始时序的输入,yt为TCN 网络预测值,d为膨胀卷积的空洞大小)。与传统卷积不同的是,膨胀卷积允许卷积时的输入存在间隔采样。其中d控制图中的采样率。最下面一层的d=1,表示输入时每个点都采样,中间层d=2,表示输入时每2 个点采样一个作为输入。越高的层级使用的d的大小越大。膨胀卷积使得有效窗口的大小随着层数呈指数型增长。这样卷积网络用比较少的层,就可以获得很大的感受野。
图3 膨胀卷积Fig.3 Dilated convolution
2.1.2 残差连接
当模型中的网络层数过深时,很容易出现梯度消失或梯度爆炸的现象,TCN 网络结构通过简单的残差连接可以在一定程度上消除这一现象。具体做法是通过对输入x和其经过非线性映射得到的G(x) 求和,避免由于网络层数不断增加而对梯度造成影响。

本文所采取的膨胀和因果卷积模块是在每一次进行膨胀卷积计算Conv()之后将参数层级归一化Hinorm(),然后使用ReLU 作为激活函数进行非线性计算,并将其结果与输入进行求和,实现残参连接。计算过程如下:
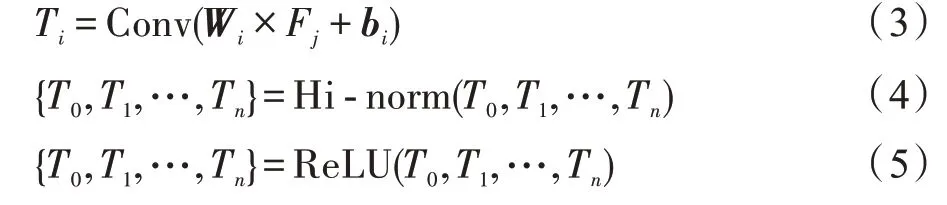
其中,Ti是i时刻卷积计算得到的状态值;Wi为i时刻卷积计算的词的矩阵;Fj为第j层的卷积核;bi为偏置矩阵;{T0,T1,…,Tn}是序列经过一次完整的卷积计算后的编码。
TCN 网络层通过堆叠多个扩张因果卷积层,扩大卷积的感受野。较大的感受野可以获取到更完整的序列特征,使得融合之后的特征提取到更深层次的语义信息。并且在逐步融合提取过程中增强不同模态之间的信息交互性,最终提升模型的整体性能。
2.2 注意力机制
注意力机制类似于人类的视觉注意力,人类的注意力是人类视觉所特有的大脑信号处理机制。深度学习中的注意力机制从本质上来讲,它和人类的选择性视觉注意力机制类似,目的也是从众多信息中选择出对当前任务目标更关键的信息。
注意力机制模型最初应用于机器翻译和文本摘要[19],现在已成为神经网络领域的一个重要概念。本文所采用的是软注意力机制,软注意力机制是指在选择信息的时候,不是从N个信息中只选择1 个,而是计算N个输入信息的加权平均,再输入到神经网络中计算。
2.3 多模态融合方法
对于本文所使用的CMU-MOSI 和CMU-MOSEI数据集的单模态特征提取的方法在文中的3.1 节实验部分有详细介绍。
双模态融合:对于不同模态信息间的融合,首先对单模态信息进行两两融合,过程如图4 所示,对单模态信息进行两两融合以后得到三个双模态信息,即T+V(文本+视频)、T+A(文本+音频)和A+V(音频+视频)。这一步骤在图4 中描述,并在第2.4 节中详细讨论。最后使用图4 的倒数第二层作为双模态特征。
三模态融合:将上一步得到的三个双模态特征向量再进行三融合得到一个三模态特征向量T+V+A,如图5 所示。这一步骤在2.4 节进行详细的描述。
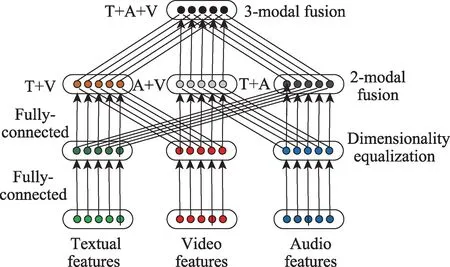
图5 三模态信息融合Fig.5 Trimodal information fusion
复合融合:在融合三模态的基础上,使用类似残差网络的结构做复合层次的融合,其结构如图6 所示,实验表明使用复合层次模型的融合方式最终得到情感分类的结果更佳。
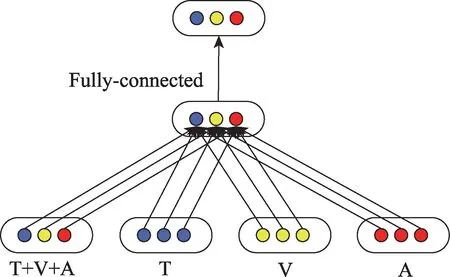
图6 复合模态信息融合Fig.6 Composite modal information fusion
2.4 模型整体结构
本文针对现有多模态情感分析方法中存在情感分类准确率不高、难以有效融合多模态特征等问题,提出了一种时域卷积网络和软注意力机制结合复合层次融合的多模态情感分析模型。
本文提出的多模态数据融合整体结构如图7 所示。使用以下条目代表单模态情感特征向量:
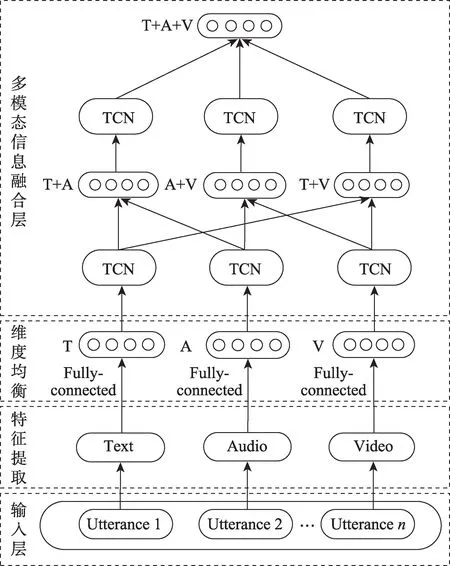
图7 模型整体结构图Fig.7 Overall structure diagram of model

其中,fA、fT、fV分别代表视觉、文本、音频单模态特征信息,N为视频中话语的最大长度。对于较短的视频,使用相应长度的空向量对其进行虚拟话语填充;对于较长的视频,做相应的裁剪操作。本文中N=50。dA、dT、dV分别代表其对应模态的特征维度,具体数值在本文的3.1 节有详细的介绍。
单模态特征fA、fT、fV具有不同的维度特征dA≠dT≠dV,在进行特征信息融合前,需要将它们映射到相同的维度。在该模型中均将其映射到DA=DT=DV=D,DA、DT、DV分别为映射后的视频、文本、音频等单模态特征向量的维度,在经过多次实验后得到当D=350 时模型的性能表现最好。

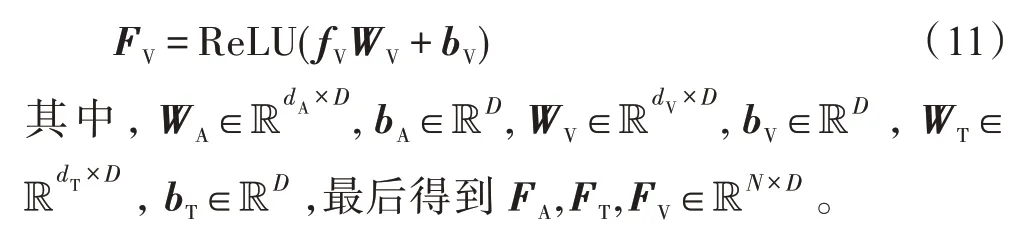
将上述得到的三个单模态特征信息FA、FT、FV作为TCN 网络层的输入进行单模态序列特征的提取,有关TCN 网络层在3.1 节已有详细介绍。

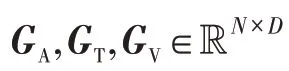

将得到的3 个双模态特征矩阵再次作为输入传入TCN 网络层,进行双模态的序列特征提取:

然后用同样的方法做三模态特征融合,融合过程与双模态融合类似:

最后进行复合层次融合,将得到的三模态情感特征FTAV和单模态情感特征GA、GT、GV进行融合得到多模态情感特征向量:

模型的输出层结构如图8 所示,在该模型中使用软注意力机制,在进行最后的情感分类之前,将得到的多模态情感特征向量传入软注意力机制层,使用Softmax 函数计算注意力分布矩阵,再将得到的注意力分布矩阵和多模态特征融合的矩阵相乘,得到最终加权的多模态特征矩阵用于最后情感分类结果的输出,其具体计算过程如下:
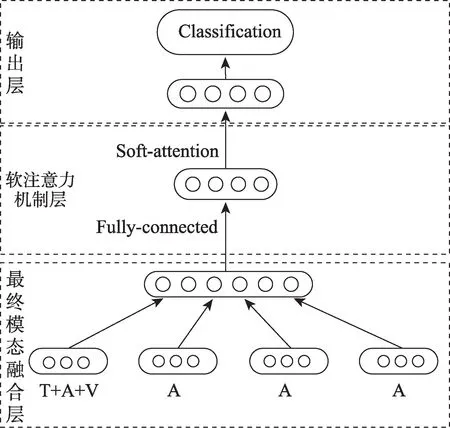
图8 输出层结构图Fig.8 Output layer structure diagram
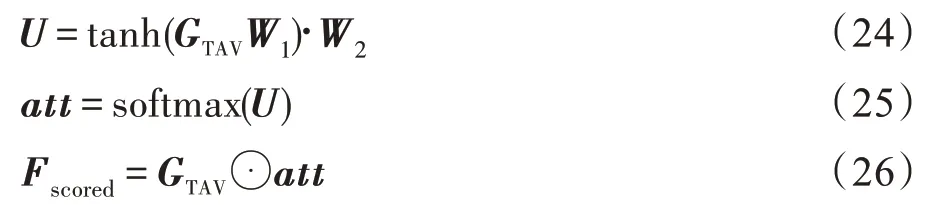
本文提出的模型采用复合融合方法结合TCN以及Soft-attention 机制。从单模态到双模态再到最终的复合模态的融合过程中,经过多次的融合提取,每次融合后经过同一个TCN 网络,使得三个模态信息紧密结合在一起,在这个过程中不断提升不同模态信息之间的交互性。将得到的多模态特征向量全部传入Soft-attention 机制中对其进行最后的过滤冗余以及噪音,注意力机制处理的过程中可以弱化弱相关,强化强相关,从而提升模态信息之间的交互性。
3 实验
3.1 实验设置
(1)数据集
本文的模型实验基于CMU-MOSI[20]数据集和CMU-MOSEI[21]数据集完成。下面对这两个公共的多模态情感分析数据集进行简要介绍。
MOSI:CMU-MOSI 数据集是最受欢迎的多模态情感分析数据集之一。MOSI数据集中包含YouTube电影评论视频的93 个独白片段,被划分为2 199 个标注了情感标签的视频段。其中每个标签情感得分从-3(强消极)到3(强积极)。在本实验中,对于二分类问题,把情感值大于或等于0 的视频段标记为1,即正面情感类,情感值小于0 的视频段标记为0,即负面情感类;对于三分类问题,把情感值等于0 的视频段标记为中性情感,小于0 和大于0 的视频片段分别标记为负面情感和正面情感。
MOSEI:CMU-MOSEI 数据集扩展了数据量,在CMU-MOSI 的基础上增加了话语数量、样本、说话者和话题的多样性。该数据集包含22 856 个带注释的视频片段(话语),来自5 000 个视频、1 000 个不同的说话者和250 个不同的主题,两个数据集的具体统计数据如表1 所示。

表1 两个数据集的统计Table 1 Statistics of two datasets
(2)单模态信息抽取
为使模型的性能达到最佳,需要使不同模态之间的信息必须严格对齐。
对于本文中的视频文本特征(Text),首先进行转录,在这里只使用中文转录。转录时为每篇转录稿添加两个唯一的标记来表示开始和结束。而后,使用预先训练好的中文BERTbase 词嵌入来从转录本中获得词向量[22]。值得注意的是,由于BERT 的特性,本文并没有使用单词分割工具。最终,每个词都被表示为768 维的词向量dt=768。
对于视频中的声学特征(audio),使用LibROSA[23]语音工具包,以默认参数提取22 050 Hz 的声学特征。在MOSEI 数据集中得到74 维的声学特征da=74。
对于视频中的视觉特征以30 Hz 的频率从视频片段中提取帧。本文使用MTCNN(multi-task convolutional neural network)人脸检测算法[24]来提取对齐的人脸,使用MultiComp OpenFace2.0 工具包[25]提取68个面部地标、17 个面部动作单元、头部姿势、头部方向和眼睛注视的集合。最终在MOSEI 数据集中得到35 维的视觉特征dv=35。
3.2 实验环境
为了全面评估模型性能,实验中使用准确率(Accuracy)和F1 值(F1-score)作为评价指标来对模型进行评估。计算公式如下:

其中,TP是真正例,即实际为正样本,被预测为正样本的数量;FP是假正例,即实际为负样本,被预测为正样本的数量;TN是真负例,即实际为负样本,被预测为负样本的数量;FN假负例,即实际为正样本,被预测为负样本的数量。
3.3 优化策略
在训练过程中,采用交叉熵作为损失函数,公式如下:

本模型基于Pytorch 深度学习框架实现,在Google colab 服务器上进行训练和测试。参数的合理设置对于模型的训练有着至关重要的作用,在大数据集CMU-MOSEI 上进行情感二分类任务测试。实验证明,当模型参数设置如表2 所示时,模型的表现效果最佳。
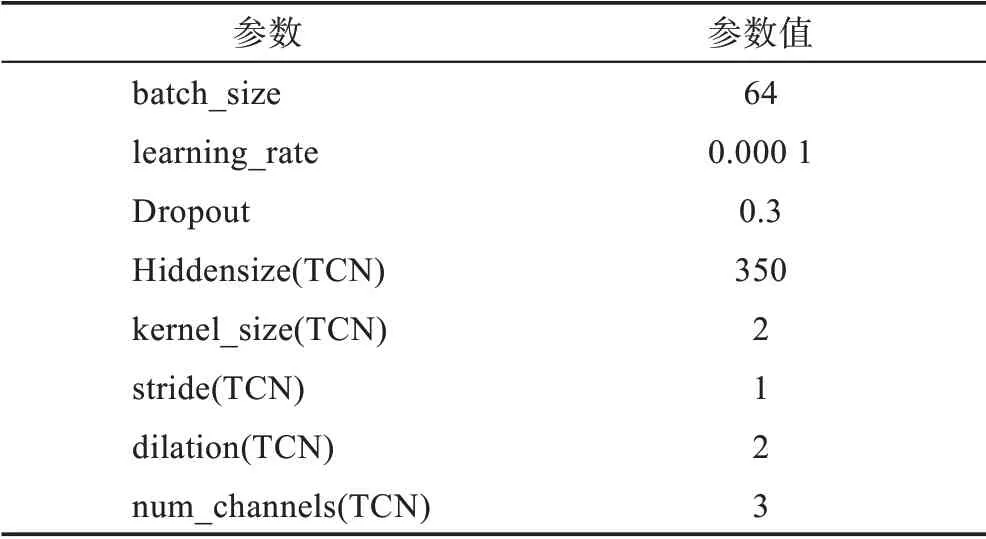
表2 实验参数设置Table 2 Setting of experimental parameters
3.4 对比实验
在本节中,Acc_2、F1_score_2 分别代表模型在情感二分类中准确率和F1 得分,Acc_3、F1_score_3 分别代表三分类情况下的准确率和F1 得分。不同模型的实验对比结果如表3 和表4 所示。
通过表3、表4 的实验结果说明,本文提出的TCN-CHF 模型在MOSEI 数据集上的情感二分类准确率和F1 分数这两个评价指标的表现都要优于其他对比模型,准确率和F1 分数分别提升了6.28 个百分点和6.12 个百分点,尤其是对比现有先进的MISA 模型,准确率提升了1.45 个百分点,F1 提升了2.34 个百分点。这充分地说明TCN-CHF 模型在多模态情感分类任务上的有效性和先进性。此外,根据上述实验结果可以看出,TCN-CHF 模型的F1 值与其他模型相比具有较大提升,这可能是因为不同层次不同组合的模态融合方法以及结合TCN 和注意力构建模型的方法,关注到了模态的内部信息和更高层次的模态交互信息,使得模型的精确率达到84.12%,从而增大了模型的F1 值,提高了模型的分类性能。但是TCN-CHF 模型的参数过多,在面对小的数据集时容易产生过拟合的现象,使得模型的效率降低。而在MOSEI 数据集上三分类的准确率不明显,原因为:一方面,分类数目更多,粒度更细;另一方面,随着数据量的增大,干扰因素也随之上升,导致面对大规模的数据集时其准确率不像小数据集的效果那样突出。

表3 不同模型在MOSI数据集上的结果Table 3 Results of different models on MOSI dataset 单位:%
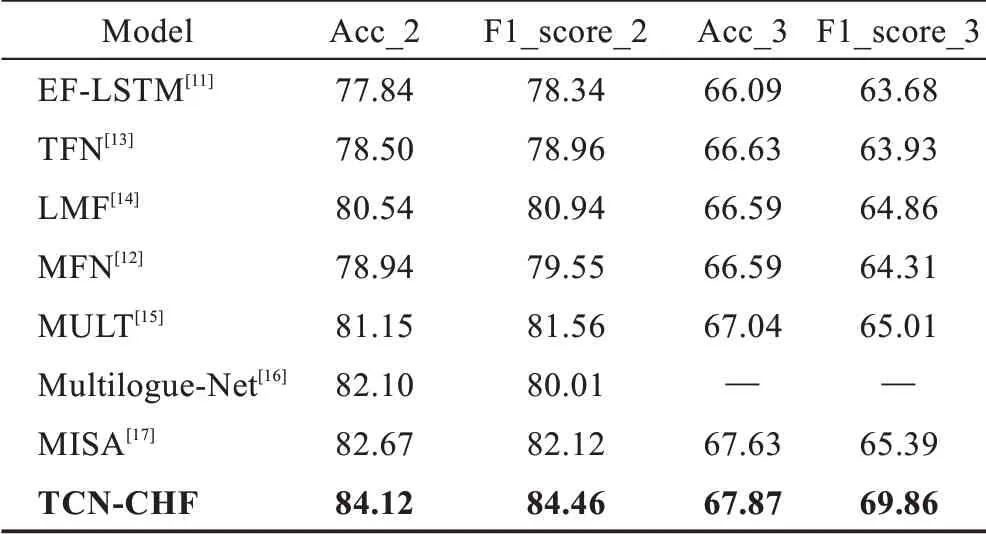
表4 不同模型在MOSEI 数据集上的结果Table 4 Results of different models on MOSEI dataset 单位:%
TCN-CHF 模型所需内存较小,同时因为TCN 网络可以并行处理数据,所以平均训练耗时较短。在Google colab 服务器,显卡为NVIDIA Tesla V100,内存为32 GB 的实验环境下,处理MOSI 数据集中的每个话语的平均预测耗时为2.352 ms,MOSEI 数据集下的每个话语平均处理速度为1.282 ms。综上,模型的时间复杂度和空间复杂度较低。同时利用TCN 网络来构建模型,因为TCN 网络本身的因果卷积是一种单向的结构,并不能依据上下文信息进行分析预测,只能根据当前时刻的信息及之前的信息进行预测分析,但是对于用来进行情感分析的模型而言,上下文信息对情感的预测也尤为重要。
3.5 消融实验
(1)模态信息消融
为了验证多模态信息融合对于情感分析准确性的重要影响,对单模态(T,A,V)、双模态(V+T,T+A,V+A)、三模态(T+V+A)以及复合层次融合(TVA+T+V+A),一共8 种不同组合的模态特征进行输入,分别对其进行情感分析实验并对实验结果进行比较。对于单模态信息特征,只让其经过TCN 层进行处理,然后直接用于情感倾向分析。类似地,对于双模态,先对不同模态信息之间先进行两两融合,再经过相同的处理后用于情感倾向分析。对于三模态信息特征,把得到的双模态特征T+A、T+V、V+T 融合以后得到三模态融合T+A+V,采用相同的处理方法最后用于情感分析。最后采用的是本文所提出来的融合处理方法,将得到的三模态信息再与单模态信息进行融合处理得到最终的三模态特征(TVA+T+V+A)用于最终的情感分析。详细的情感分类结果如表5 和表6 所示。
表5 和表6 所示为模态消融实验结果,通过表中的数据可以发现复合层次的情感分类模型表现最好,三模态特征输入表现次之。证明了多模态信息的必要性,以及复合层次融合的方式可以进一步补充不同模态信息之间的交互信息表达,从而提高了模型的准确率。在单模态的实验中,文本情感分析的准确率及F1 值最高,双模态实验中使用了文本模态信息的模型性能也更优异,表明文本模态特征的情感特性最显著。那是因为在人们表达自身观点的时候文本通常包含更丰富的信息。结合分类结果的两个评价指标,双模态情感分析的效果普遍优于单模态情感分析,利用三模态融合特征进行分类时的效果最好。因此,将文本、语音和图像这三种特征进行有效融合有助于提高情感分类的性能。
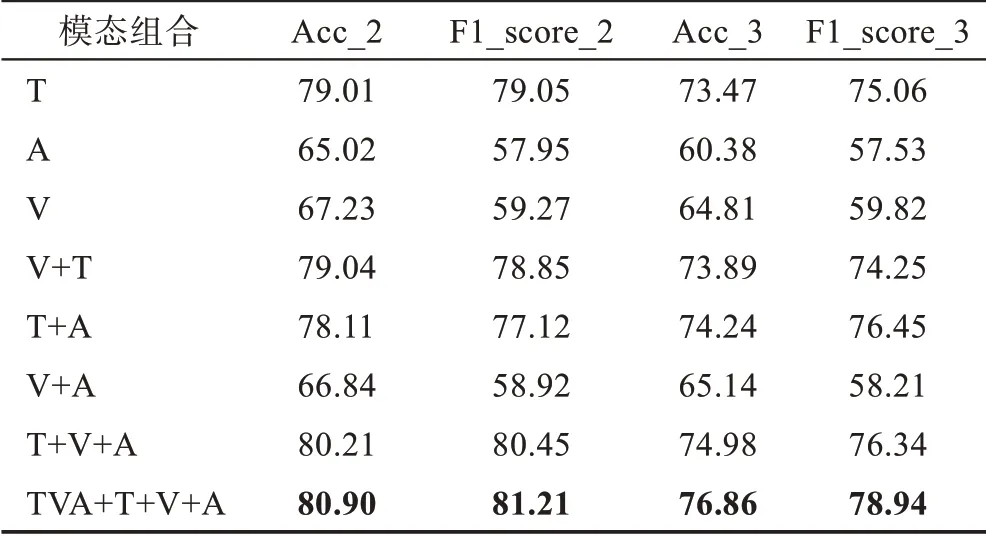
表5 不同模态组合在MOSI数据集上的情感分类结果Table 5 Sentiment classification results of different modal combinations on MOSI dataset 单位:%

表6 不同模态组合在MOSEI数据集上的情感分类结果Table 6 Sentiment classification results of different modal combinations on MOSEI dataset 单位:%
(2)模型消融
为了进一步分析复合层次融合结合TCN 及Softattention 机制对模型性能的贡献,本文设计了三组对比实验,比较不同模块对于模型整体性能的影响。在MOSI 和MOSEI 数据集上的对比实验结果如图9、图10 所示。
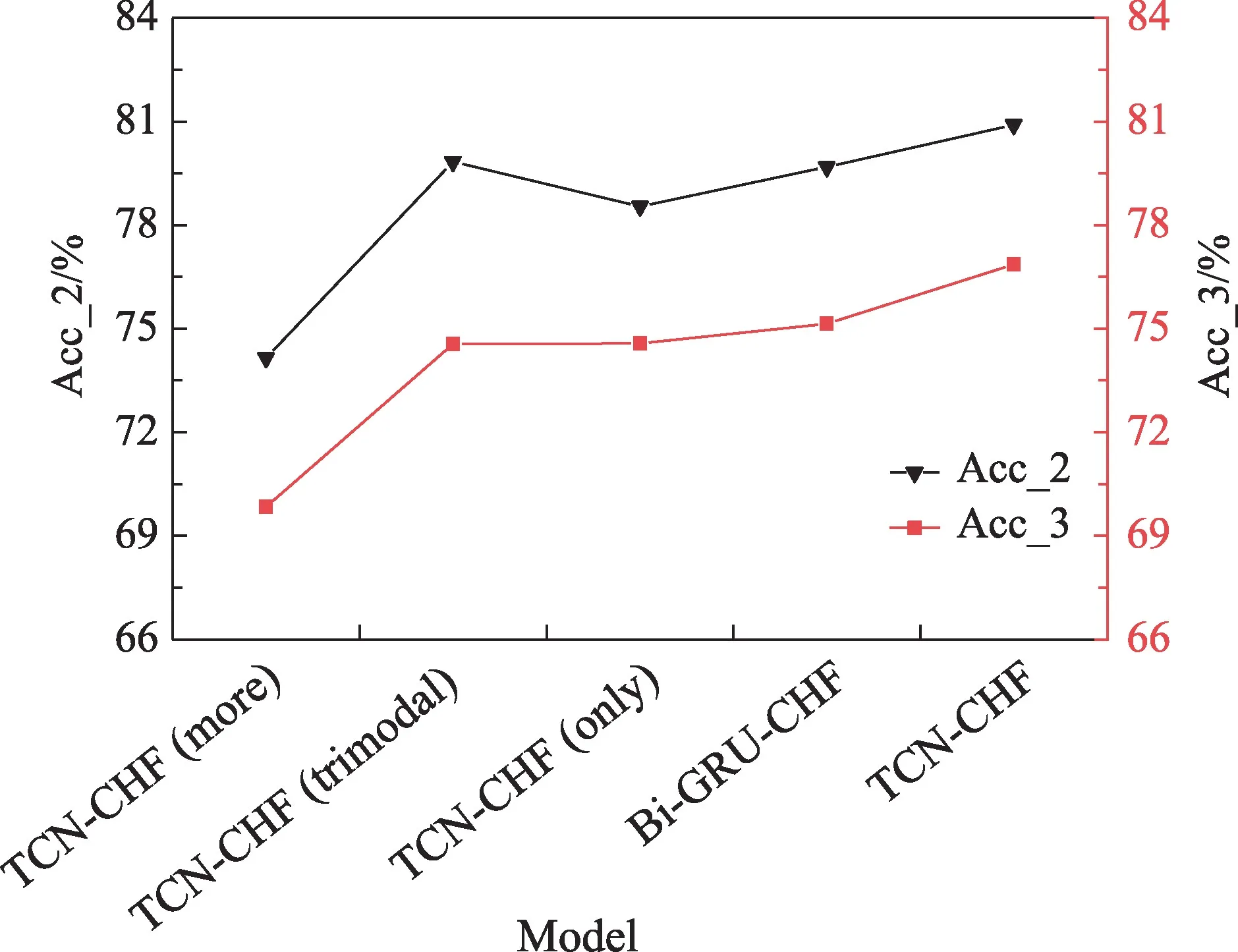
图9 MOSI数据集上的消融实验结果Fig.9 Model ablation results on MOSI dataset
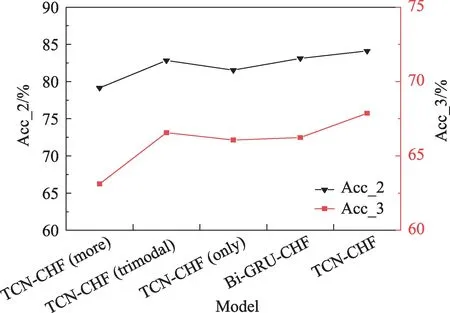
图10 MOSEI数据集上的消融实验结果Fig.10 Model ablation results on MOSEI dataset
①TCN-CHF(more)在使用TCN 网络进行信息处理的时候,分别对其使用单独的TCN 网络,构建多个TCN 网络,不再使用同一个TCN 网络。
②TCN-CHF(trimodal)舍弃最后复合特征信息融合机制,直接使用三模态信息进行输出分类。
③TCN-CHF(only)在最后输出时不再使用软注意力机制,对其直接进行分类输出得到情感分析结果。
④Bi-GRU-CHF 使用Bi-GRU(bidirectional-gated recurrent unit)替换本文提出模型中的TCN 网络。
图9、图10 的实验结果表明,对于MOSI 和MOSEI 数据集,舍弃或者替换TCN-CHF 模型中的任一重要模块,都会使得模型的分类性能下降。首先,相比多个TCN 网络建模,使用单个TCN 网络的模型准确率提升了6 个百分点左右。原因可能是使用多个TCN 网络在训练时内部的参数相互独立,导致不同模态信息之间的交互性减弱,从而使模型的准确率下降。其次,丢弃最后的软注意力机制层或更换TCN 网络结构为Bi-GRU 都会导致模型准确率的下降。软注意力机制层和TCN 网络对情感类的准确率贡献了2%和1.3%(在大数据集二分类中)。这主要是因为舍弃注意力机制层以后,虽然得到的特征融合信息更为丰富,由于不同层次不同组合的模态融合信息存在大量冗余和噪声干扰,对最终分类的结果产生较大的影响。使用Bi-GRU 网络代替TCN,模型的性能有所下降,证明了TCN 相较于传统的RNN网络有更好的处理时间序列特征的能力,两者共同提升模型最终的分类性能。
4 结束语
为了有效地提升视频中的人物情感分析的结果,本文提出了一种基于TCN 与Soft-attention 机制复合层次融合的多模态情感分析方法。先将提取到的模态特征信息进行复合层次融合。在融合过程中使用TCN 网络提取信息中的序列特征,最后通过筛选注意力机制进行信息过滤和特征降维,最终得到情感分类的预测结果。在数据集CMU-MOSI 和CMU-MOSEI 上的实验表明本文方法可以提高多模态情感分类性能。整体上,本文方法在准确率以及F1 值上均优于其他方法。
多模态情感分析主要的研究集中在两方面:一个是单模态信息的提取,另一个是不同模态信息的融合。单模态信息提取需要依靠其他技术,但是模态数据融合有很多种方法。下一阶段将在最新的单模态技术为前提的条件下,尝试各种融合方式,包括早期融合和晚期融合。
