小样本目标检测研究综述
2023-01-17刘春磊陈天恩姜舒文
刘春磊,陈天恩,王 聪,姜舒文,陈 栋+
1.广西大学计算机与电子信息学院,南宁530004
2.北京市农林科学院信息技术研究中心,北京100097
3.国家农业信息化工程技术研究中心,北京100097
目标检测是计算机视觉方向的热点领域,其任务是将图像中任意数目的感兴趣对象用外接矩形框选出来并识别出对象类别。作为计算机视觉的基本任务之一,目标检测应用广泛,其已经在缺陷检测[1-3]、农业病虫害识别[4]和自动驾驶[5]等领域发挥着重要的作用。
2014 年,Girshick 等[6]提出了用于解决目标检测任务的R-CNN(region-based convolutional neural networks)算法并取得了极大的性能提升,目标检测研究从此进入深度学习时代。Girshick 等[7]又在2016 年提出了经典的Faster R-CNN 两阶段算法,首先在图像上生成大量可能是对象的候选区,然后对这些候选区进行筛选,对筛选得到的候选区进行分类和回归得到想要的结果。由于两阶段算法会基于生成的大量候选区做进一步处理,虽然检测精度较高,但检测速度相对不是很理想。一阶段算法不需要事先通过专门的算法模块生成大量候选区,而只是在图像上预先定义了不同大小和比例的锚框,用这些锚框代替了两阶段算法的候选区,不再需要复杂的候选区操作,只需对图像进行一次卷积处理就可以完成对象的定位和分类,经典的一阶段网络有YOLO(you only look once)系列[8-10]、SSD(single shot multibox detector)[11]、RetinaNet[12]等。近些年,在自然语言处理领域大放异彩的Transformer[13]技术也被成功应用到目标检测中,DETR(detection transformer)[14]是其中的代表之作,其不再需要锚框、候选区和非极大值抑制等人为设计的知识,而是将目标检测看作直接的集合预测问题,真正地实现了端到端检测。
上述的目标检测方法都需要使用大量实例级别的标注信息来实现,这可能会出现以下一些问题:(1)由于现实世界中固有的长尾分布,有些类别本身就很难获得大量的标注信息,比如珍稀动植物、罕见病症等;(2)图像的标注通常需要消耗大量的人力去完成,而且,标注的准确率也不稳定,漏标和误标的情况常有发生,尤其是某些难以标注的对象,比如病虫害、肿瘤等;(3)模型的训练需要消耗大量的资源,如昂贵的GPU 设备和专业的领域知识等。当只有很少的标注信息时,现有主流的目标检测方法很难达到令人满意的效果。然而,现实生活中,即便一个孩童,也能够通过仅仅观察几张图像就完成对新类别的学习。因此,通过很少的样本数量进行目标检测是一个极具现实意义的问题,受到了越来越多的关注。
小样本学习只使用很少的训练样本就能够得到想要的结果。现在,小样本学习在图像分类、语义分割和目标检测这三大计算机视觉任务上都有应用,但迄今为止研究的重点主要集中在图像分类。相比分类,小样本目标检测问题更加复杂,其不仅仅需要分类目标的类别,还需要定位出目标的具体位置。小样本目标检测问题的提出是为了解决实际生产生活中样本数据标注量少的问题,是非常有现实意义的研究方向。目前,已有一些关于小样本目标检测的综述,潘兴甲等[15]将小样本目标检测方法分为基于微调、基于模型结构和基于度量学习三种,并对这些分类方法进行了分析。刘浩宇等[16]将其分成基于数据、模型和算法三个类别,并对每个类别进行了归纳总结,探讨了小样本目标检测的现状和未来趋势。张振伟等[17]也从六方面对小样本目标检测方法进行了分析,比较了不同方法的优缺点。与这些综述[15-17]不同,本文首先将这些方法归纳为两种范式,再按照改进策略的不同,从基于注意力机制、图卷积神经网络、度量学习和数据增强的角度进行归纳总结,对比分析了不同分类的优缺点和适用场景。同时,收录了近两年提出的许多新的小样本目标检测方法,对比分析了这些方法的性能表现。
1 小样本目标检测概述
1.1 小样本目标检测定义和训练过程
小样本目标检测(few-shot object detection,FSOD)相对于通用目标检测最大的不同,是其数据输入的不同,FSOD 将数据集分为基类数据集Db和新类数据集Dn。基类数据集Db由拥有大量标注图像的基类Cb组成,新类数据集Dn由只有少量标注图像的新类Cn组成,其中,基类类别和新类类别不存在交集,即Cb⋂Cn=∅。小样本目标检测方法的目标是通过在基类和新类数据集上训练得到一个模型,期待该模型可以检测出任意给定测试图像中的新类和基类对象,小样本目标检测定义如图1 所示。
小样本目标检测算法的训练过程一般分为两个阶段:第一阶段使用大量的基类数据Dbase进行模型的训练,从初始化模型Minit得到基模型Mbase,称之为基训练阶段;第二阶段使用由少量的基类数据Dbase和新类数据Dnovel组成的平衡数据集Dfinetune对基模型Mbase进行模型微调,得到最终模型Mf,称之为微调阶段。整个训练过程如图2 所示。
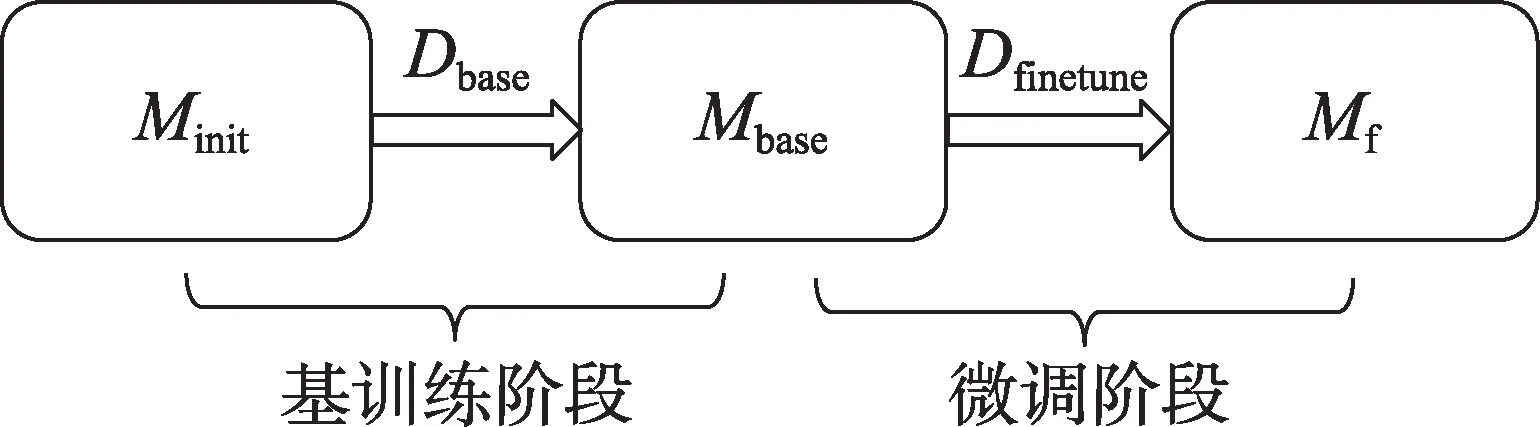
图2 模型训练过程Fig.2 Model training process
1.2 小样本目标检测的相关领域研究
在通用目标检测的基础上,有一些其他新颖的研究方向,这些研究方向与小样本目标检测有相似之处,容易造成混淆,本节对这些研究方向进行简易的区分解释。
零样本目标检测[18]在算法模型的训练阶段只使用可见类别,不可见类别的视觉信息不会被使用到,而用其语义等辅助信息参与训练,这些辅助信息正是零样本目标检测的研究重点。小样本目标检测可以使用少量的新类图像作为视觉方面的信息,同时借鉴零样本中不可见类别中辅助信息的使用;单例目标检测[19]是小样本目标检测的一个特例,其中每个新类只有一个标注对象信息;任意样本目标检测[20]将零样本或者小样本的情况同时考虑,即一个算法模型既可以解决零样本问题又可以处理小样本问题。
还有一些其他的研究在小样本目标检测的基础上,新增加一些新的领域限定条件。为了避免灾难性遗忘,同时可以持续检测不断增加的新类别,提出了类增量小样本目标检测[21];半监督小样本目标检测[22]在不增加新类标注的情况下,将基类数据的来源修改为有标注的图像和没有标注的图像;弱监督小样本目标检测[23]相对于小样本目标检测的区别在于其数据集中新类标注不是实例级的,而是由图像级标注构成的。
图3 从数据流向的角度展示了小样本目标检测及其相似任务之间的区别与联系。这些研究领域的数据集构成都由基类和新类组成,为了避免混淆,更加明确本综述的研究范围,本文对这些相似概念做了简单的区分说明。同时,可以从这些领域寻找问题解决的灵感,将其应用到小样本目标检测方法。
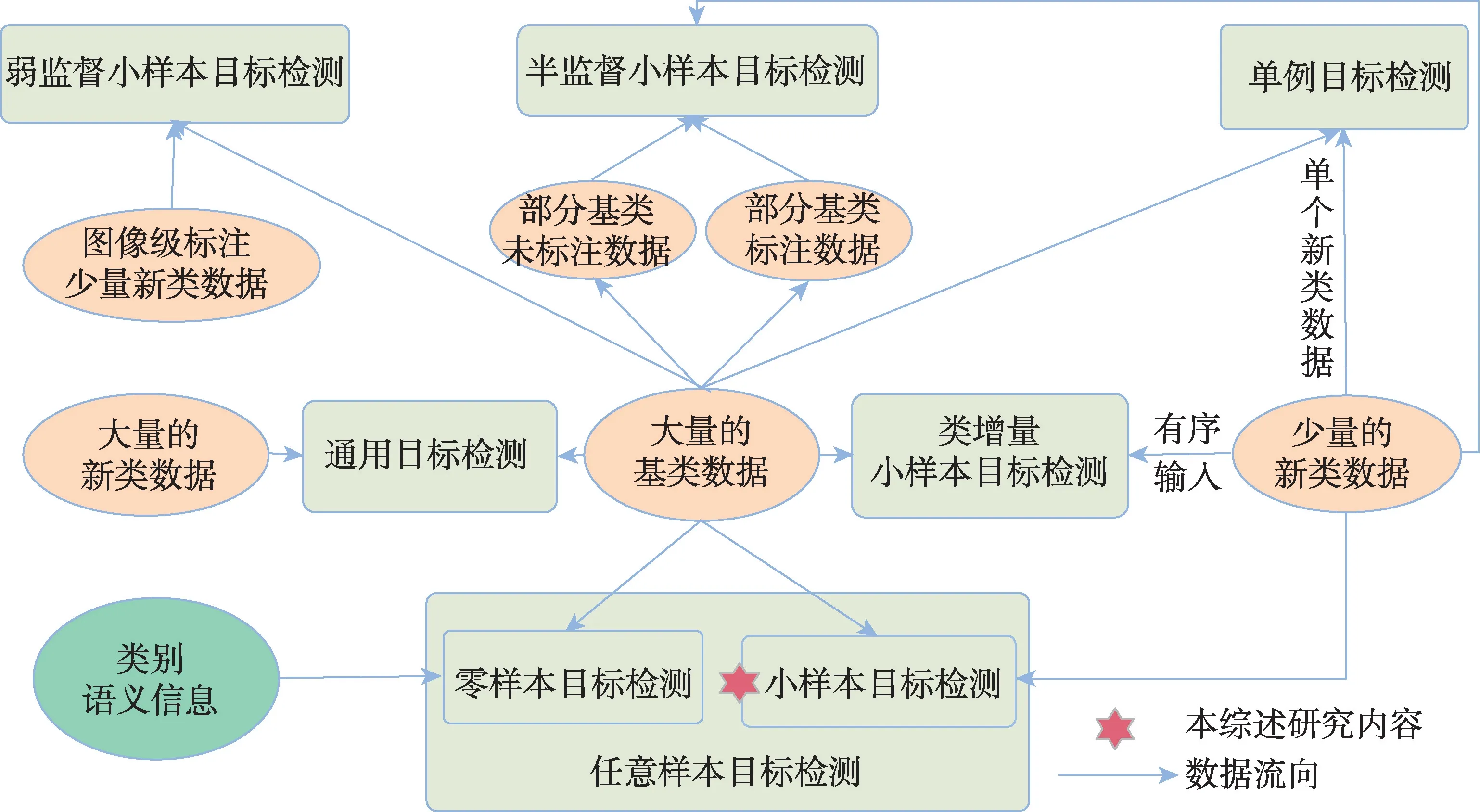
图3 小样本目标检测及其相似任务的区别与联系Fig.3 Differences and connections between few-shot object detection and its similar tasks
2 小样本目标检测的两类经典范式
目前的小样本目标检测方法可以概括为两种范式,基于迁移学习的范式和基于元学习的范式。基于迁移学习的范式是将从已知类中学习到的知识迁移到未知类的检测任务中。基于元学习的范式是利用元学习器从不同的任务中学习元知识,然后对包含有新类的任务通过元知识的调整完成对新类的检测。本章将对这两种范式的典型方法进行简述。
2.1 基于迁移学习的范式
两阶段微调方法(two-stage fine-tuning approach,TFA)[24]是迁移学习范式的基线方法,基于Faster RCNN 算法进行改进。TFA 认为Faster R-CNN 主干网络是类无关的,特征信息可以很自然地从基类迁移到新类上,仅仅只需要微调检测器的最后一层(包含类别分类和边界框回归),就可以达到远远超过之前方法的性能表现。整个方法分为基训练和微调两个阶段,如图4 所示。在基训练阶段,整个模型在有着大量标注的基类上训练;在微调阶段,冻结网络前期的参数权重,由基类和新类组成的平衡子集对顶层的分类器和回归器进行微调。另外,TFA 在微调阶段的分类器上采用余弦相似性测量候选框和真实类别边界框之间的相似性。

图4 迁移学习基线方法TFA 算法架构图Fig.4 Model architecture diagram of transfer learning baseline method TFA
由于小样本中每个新类别的样本量非常少,其高方差可能会导致检测结果的不可靠,TFA 通过抽样多组训练样本进行评估,并且在不同组进行多次实验得到平均值。由于统计上的偏差,之前的评估标准无法完成不同算法的统一比较,TFA 修改了原先的数据基准,在VOC[25]、COCO[26]和LVIS[27]三个数据集上建立了新的基准,检测基类、新类和全部数据集上的性能表现,提出了广义小样本目标检测基准。
2.2 基于元学习的范式


图5 元学习基线方法FSRW 算法架构图Fig.5 Model architecture diagram of meta-learning baseline method FSRW
FSRW[28]整个网络模型是基于一阶段网络YOLOv2[9]进行改进的,在一阶段网络中新增了元特征学习器和元学习器模块,元特征学习器以查询图像为输入,使用YOLOv2 的骨干实现,从有充足样本的基类图像中提取具有泛化性的元特征,用于之后检测新类。元学习器模块以支持集为输入,将新类的某一类别实例转换为一个全局向量,该向量用来检测特定类别的对象实例。网络的训练过程同样分两阶段完成,首先使用基类数据训练连同元学习器模块在内的整个网络模型,然后由少量标注的新类和基类组成的平衡数据集微调模型以适应新类。
2.3 两种范式的对比分析
(1)迁移学习和元学习的相同点:
①两种范式都是为了解决小样本目标检测任务而提出的,都希望通过少量的新类图像就可以完成对新类别的检测。
②两种范式的数据集都分为有大量标注的基类数据和只有少量标注的新类数据。
③两种范式的训练过程都分为两阶段进行,分别是基训练阶段和微调阶段,算法模型在基训练阶段学习到基类数据具有泛化性的知识,然后在新类数据上对模型进行微调,达到检测新类的目的。
④两种范式的评价指标相同,不论是VOC 数据集、COCO 数据集,还是FSOD 数据集[29],两种范式的评价指标都是相同的。
(2)迁移学习和元学习的不同点:
①数据的输入方式不同,元学习范式是以任务(episode)为输入单元,每个任务由支持集图像和查询集图像组成,目的是找到查询集图像中属于支持集类别的目标对象,而迁移学习范式通常不需要分为支持集和查询集两部分。
②元学习范式随着支持集中类别数量的增加,内存利用率会降低,而迁移学习范式不会随着类别数量的增加而使内存利用率降低。
③元学习范式除了通用目标检测模型外,还有一个需要获得类别级元知识的元学习器,而迁移学习范式只需要在通用目标检测模型上改进即可。
3 小样本目标检测算法研究现状
上一章中,将小样本目标检测分为基于元学习和基于迁移学习两种范式,在这两种范式中,存在着一些共性的解决方法,依据这些方法改进策略的不同,将小样本目标检测分类为基于注意力机制、基于图卷积神经网络、基于度量学习和基于数据增强四种实现方式,分类概况如图6 所示。在本章中,将对这些分类方法进行详细分析和总结。

图6 分类图Fig.6 Classification graph
3.1 基于注意力机制
对于小样本目标检测来说,难以从少量的新类样本中准确学习到感兴趣对象的特征信息,而通过注意力机制可以较为准确地找到图像中的感兴趣区域,目前已有一些关于注意力机制的研究[30],注意力机制可以看作一个动态选择的过程,通过输入的重要性对特征进行自适应特征加权。本节将其分为通道注意力、空间注意力和Transformer自注意力方法。
3.1.1 通道注意力
2018 年Hu 等[31]首次提出了使用SENet 的通道注意力,如图7 所示,不同特征图的不同通道可能代表着不同的对象,当需要选择什么对象时,通道注意力使用自适应的方法重新校准每个通道的权重来关注该对象。
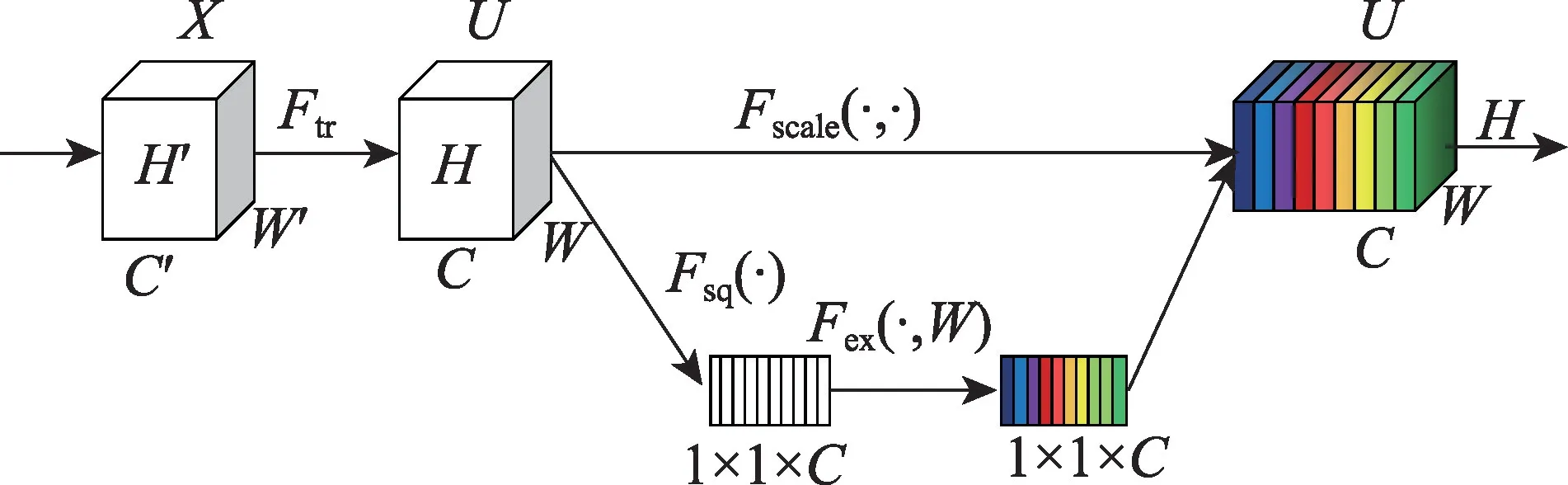
图7 SE 模块Fig.7 SE block
在迁移学习范式上,Zhang 等[32]使用二阶池化和幂正则化计算支持特征和查询特征之间的互相关性,二阶池化提取支持特征数据的二阶统计,形成注意力调制图,通过添加幂正则化可以减少二阶池化带来的可变性。Wu 等[33]提出了FSOD-UP(universalprototype augmentation for few-shot object detection)方法,使用了通用原型的知识,在条件性通用原型和候选框上施加通道注意力机制,提高了候选框的生成质量,以此提高方法对新类的检测性能。
在元学习范式上,Yan 等[34]针对一张图像有多个目标的问题提出了Meta R-CNN 方法,该方法不是对整张图像而是在感兴趣区域上使用元学习范式。Meta R-CNN 新增加了预测头重塑网络分支,该分支用有标注的支持图像获取每个类别的注意向量,对模型生成的感兴趣区域特征应用该向量进行通道注意力关注,以检测出查询图像中与这些向量表示的类别相同的对象。Wu 等[35]在Meta-RCNN 中将由支持集得到的类原型与查询集的特征图通过类别注意力结合起来,获得每个特定类的特征图,然后将这些特征图结合起来使用随后的区域候选网络和检测头对查询集进行分类和定位。Fan 等[29]在提出的Attention-RPN 方法前期阶段使用深度互相关注意力区域候选网络,通过通道注意力机制利用支持集和查询集之间的关系提高候选框的生成质量。Liu 等[36]认为检测中分类和定位子任务对特征嵌入的喜好不同,提出了AFD-Net(adaptive fully-dual network)方法,分开处理分类和定位问题,对支持集分支使用注意力机制产生分类和回归两个通道注意力分支,之后将这两个分支与查询集的感兴趣区域的分类和定位特征进行聚合处理,最终得到增强的特征表示。
3.1.2 空间注意力
当人们看到一张图像时,他们总是会将视线聚焦于图像中的某一区域,空间注意力受此启发,对特征图上的每个位置进行注意力调整,可以自适应地关注图像中的某重点区域,这些重点区域往往是人们所感兴趣的对象。
Chen 等[37]基于迁移学习范式提出了AttFDNet 方法,将自底向上的空间注意力和自顶向下的通道注意力结合起来,自底向上注意力由显著性注意(saliency attentive model,SAM)模块实现,由于其类别无关性,能够自然检测图像中的显著区域。Yang等[38]为解决训练集数据多样性少的问题,提出了CTNet方法,使用亲和矩阵在不同尺度、位置和空间关系三方面识别每个候选框上下文字段的重要性,再用上下文聚合将这些关系与候选框聚合起来,利于新类别分类的同时,避免了大量的误分类。Li 等[39]提出了LSCN(low-shot classification correction network)方法,用从基类检测器中得到的误检候选框作为方法校正网络分支的输入,使用空间注意力机制通过跨通道的任意两个位置间的成对关系获得全局感受野,通过捕捉整张图像的信息,解决候选框复杂的对象外观问题。Xu 等[40]在FSSP(few-shot object detection via sample processing)方法中使用了自我注意力模块(self-attention module,SAM),该空间注意力模块可以突出显示目标对象的物理特征而忽略其他的噪声信息,更好地提取复杂样本的特征信息。Agarwal 等[41]提出了AGCM(attention guided cosine margin)方法解决小样本下的灾难性遗忘和类别混淆问题,构建了注意力候选框融合模块,通过空间注意力关注不同候选框之间的相似性,用于减少类内的方差,从而在检测器的分类头中创建类内更加紧密、类间良好分离的特征簇。
基于元学习范式,Chen 等[42]为解决小样本任务中的空间错位和特征表示模糊问题,提出了包含跨图像空间注意的DAnA(dual-awareness attention)方法,通过跨图像空间注意自适应地将支持图像转化为查询位置感知向量,通过测量该感知向量和查询区域的相关性,确定查询区域是否为想要的目标对象。Meta Faster R-CNN[43]将检测头分为基类检测和新类检测两种,基类检测沿用原有的Faster R-CNN部分,新类检测头提出了Meta-Classifier模块,使用注意力机制进行特征对齐,解决空间错位问题,在查询图像的候选框特征和支持集类原型的每个空间位置通过亲和矩阵计算对应关系,基于对应关系,获得想要的前景对象。Quan 等[44]认为在支持集中使用互相关技术会给查询特征引入噪声,提出了CAReD(cross attention redistribution)方法,专注挖掘有助于候选框生成的支持特征,去除有害的支持噪声。不再对支持集特征作平均处理,而是通过空间注意力计算同一类别不同实例之间的相关性,对每个支持特征重加权,从而得到最终的支持特征。彭豪等[45]在由多尺度空间金字塔池算法生成的不同层次上产生注意力图,强化了特定尺度物体的线索,可以提高小目标的检测能力。Zhang 等[46]提出了KFSOD(kernelized few-shot object detector)方法,针对PNSD(power normalizing second-order detector)中核化仍然是线性相关的问题,使用核化自相关单元从支持图像中提取特征形成线性、多项式和RBF(radial basis function)核化表示。然后将这些特征表示与查询图像的特征进行交叉相关以获得注意力权重,并通过注意力区域提议网络生成查询提议区域。
3.1.3 Transformer自注意力机制
Transformer 注意力机制在自然语言处理已经取得了巨大成功[47]。DETR 成功地将其应用到目标检测领域,将检测问题看作集合预测问题。其中的核心内容是多头注意力机制,其将模型分为多个头,形成多个特征子空间,可以让模型关注图像不同方面的信息,通过图像的内在关系来获取图像中重要的信息,如图8 所示。

图8 多头注意力模块Fig.8 Multi-head attention block
Transformer自注意力机制全部遵从元学习的范式,Zhang 等[48]借鉴DETR 的思想,提出了Meta-DETR 方法,去除了在小样本中表现不佳的候选框预测,改为直接的端到端检测。Meta-DETR 由查询编码分支、支持编码分支和解码分支三部分组成。查询编码分支以查询图像为输入,通过特征提取器和Transformer编码器生成其查询特征,支持编码分支从支持图像中提取支持类原型,解码分支将带有支持类原型的查询特征聚合为特定类的特征,然后应用与类别无关的Transformer 解码器预测该支持类的检测结果。Hu 等[49]提出了DCNet 方法,提出稠密关系蒸馏解决外观改变和遮挡问题,稠密关系蒸馏模块通过编码器将支持集和查询集提取出的特征信息编码成原生Transformer 中的Key-Value 特征图对,使用改进的Transformer 注意力机制关注查询集和支持集之间的像素级关系,用以增强查询集的特征表示。APSPNet(attending to per-sample-prototype networks)[50]在经典的元学习方法Attention-RPN 和FsDetView(few-shot object detection and viewpoint estimation)基础上,新增了两个使用Transformer技术的注意力模块,一个是支持集数据内部注意(intra-support attention module,ISAM),另一个是查询-支持集间注意(query-support attention module,QSAM),ISAM 在同一个类的支持集内使用注意力机制,去除可能是噪声的信息,QSAM 通过支持集的每个样本原型聚合查询特征和支持特征,达到了远超基线方法的性能。Han 等[51]认为之前在查询和支持分支上进行特征对齐的方法过于简单,提出了FCT(fully cross-transformer)方法,在特征提取器部分使用了多层Cross-Transformer 进行两分支的特征对齐,并提出了非对称分批交叉注意用来聚合两分支的关键信息,用聚合到的关键信息对两分支特征进行增强。在检测头上,提出基于Cross-Transformer 的感兴趣区特征提取器,两分支联合提取查询建议框和支持图像感兴趣区,进行多级交互处理。
综上所述,基于注意力机制的方法在小样本目标检测中应用广泛,注意力机制可以找到图像中的感兴趣区域,抑制其他的无用噪声信息。最近随着Transformer 自注意力的提出,其在小样本目标检测中取得了远超其他注意力的性能表现,目前已有关于这方面的研究[52],基于Transformer 自注意力机制的小样本目标检测有着极大的前景,将会得到进一步的发展。但是,Transformer 的模型训练需要花费较长的时间,且模型参数过大,不利于工程部署,未来的研究方向可以向着轻量化发展。
3.2 基于图卷积神经网络
小样本条件下的新类样本数量少,可以通过深入挖掘不同类别之间的内在关系来实现对新类的检测,卷积神经网络存在平移不变性,即一张图像可以共享卷积算子的参数,图结构则没有这种平移不变性,每一个图节点的周围结构都可能是不同的,因此,图可以处理实体之间的复杂关系。图由节点和边组成,每个节点都有自己的特征,节点与节点之间通过边进行关联,图卷积就是利用节点间的边关系对节点信息进行推理更新,从而增强节点的特征表示。
Kim 等[53]认为图像中各种物体的存在有所关联,比如一张图像中某个对象周围有键盘和显示器,那它更可能是鼠标而不是球,基于此提出了基于迁移学习范式的FSOD-SR(spatial reasoning for few-shot object detection)方法,通过图卷积技术考虑图像中对象间的全局上下文关系,而不仅是通过单个感兴趣区域特征预测新类,将感兴趣区域特征作为图节点,边的构成由感兴趣区域特征表示的视觉信息和几何坐标信息两者结合得到,如图9 所示。Zhu 等[54]提出SRR-FSD(semantic relation reasoning for few-shot object detection)方法,利用基类与新类之间存在的恒定语义关系,由所有的词嵌入特征组成嵌入语义空间,应用图卷积进行显式关系推理,将从大量文本中学习到的语义信息嵌入到每个类概念中,并与分类的视觉特征进行结合。

图9 FSOD-SR 架构图Fig.9 FSOD-SR architecture diagram
在元学习范式上,Kim等[55]提出了FSOD-KT(fewshot object detection via knowledge transfer)方法,其支持集分支使用图卷积技术对查询图像感兴趣区的特征向量进行特征增强。图的顶点为每个类的原型,图的边关系使用类别之间的文本相似性度量(由GloVe[56]计算),通过图卷积神经网络使这些类原型间产生关联,然后通过增强后的原型对查询图像的感兴趣区域特征进行度量,检测出与该原型一致的类别。Liu等[57]提出了基于Meta R-CNN的DRL-for-FSOD(dynamic relevance learning for few-shot object detection)方法,考虑到不同类之间存在着联系,将支持集图像和查询集的感兴趣区域特征放入同一个特征空间,使用皮尔逊相关系数去度量支持集类别和查询集感兴趣区域间的相似性作为图的关系,构造了一个动态图卷积网络,对其进行推理,使得相同类彼此靠近,不同类之间远离,减少了误分类的情况。Han等[58]基于异构图卷积网络提出了QA-FewDet(query adaptive few-shot object detection)方法,存在类间和类内两种子图,前者推理新类和基类的类间的关系,后者推理不同新类的候选框之间的关系以及新类节点与候选框之间的关系。使用类间子图增强新类原型表示,类内子图提供查询自适应类原型和上下文感知原型特征。
综上所述,基于图卷积神经网络的小样本目标检测方法大多选择将候选框作为图的节点,通过图卷积来自动推理不同候选框之间的关系,以此学习到新类同基类间的内在联系,达到对新类对象的检测。但是当图节点过多时,节点之间的边关系也会变得异常复杂,可能会面临模型过拟合的问题。同时,新类的样本量较少也可能导致模型在新类检测上产生过拟合现象。
3.3 基于度量学习
通过度量基类和小样本的新类之间的相似性,使得不同类别彼此远离,相同类别之间靠近,可以很好地区分出新类数据。度量学习又可分为改进度量损失函数、原型学习和对比学习。度量损失函数在不同类别之间设计距离公式;原型学习为每个类别生成线性分类器,衡量类别与原型之间的距离;对比学习是将目标图像与某几个图像对比进行检测。
3.3.1 改进度量损失函数
在迁移学习范式上,Cao 等[59]提出了FADI(fewshot object detection via association and discrimination)方法,将迁移学习的微调阶段分为关联、鉴别两步,关联加强类内相关性,鉴别扩大类间差异。在关联中,使用伪标签显式地将新类转变为最相似的基类特征表示,新类的特征会相对聚集,但可能会与基类特征空间混淆,为了扩大不同类间的距离,在分类分支引入了专门的边际损失,扩大了所有类别的差异性。Wu 等[60]提出了SVD(singular value decomposition)的方法,新引入了对象注意损失和背景注意损失两个损失函数,用于更好地分类正负锚框,将属于同一类的正锚框聚集起来,将背景和负锚框两者尽可能地区分开。
在元学习范式上,Karlinsky 等[61]在RepMet(representative-based metric learning)方法中提出一个距离度量学习(distance metric learning,DML)模块,代替了Faster R-CNN 中的检测头,假定特征嵌入空间中每个类有K个模型,DML 计算感兴趣区域在每个类别中每个模型的概率,新增加了嵌入损失函数,减小嵌入向量E和最接近表征的距离,扩大嵌入向量E和一个错误类的最接近表征的距离。Li 等[62]为了减轻新类的特征表示和分类之间存在的矛盾,提出了CME(class margin equilibrium)方法。为了准确实现新类的类别分类,任意两个基类应该彼此远离,为了准确表示新类特征,基类的分布应该彼此接近。CME 首先通过解耦定位分支将检测转换为分类问题,在特征学习过程中,通过类边际损失为新类保留充足的边界距离,在追求类边界平衡中保证新类的检测性能。Zhang 等[63]提出了PNPDet(plug-and-play detector)方法,将基类和新类检测分开,防止在学习新概念的时候影响基类的检测性能,以CenterNet[64]为基础架构,新增了一个用于新类别检测的热图预测并行分支,将最后一层热图子网络替换为余弦相似对比头和自适应余弦相似对比头,将距离度量学习的损失函数引入类别预测中,极大提升了新类的检测性能。彭豪等[45]在隐藏层的特征空间上应用正交损失函数,使得模型在分类过程中保持不同类别彼此分离,相同类别彼此聚合。
3.3.2 对比学习
对比学习是将目标图像与某几个图像进行对比检测,在最小化类内距离的同时最大化类间距离,提高相同或相似类之间的紧凑性和加大不同类之间的差异性,可以有效提高边界框的分类精度。
在迁移学习范式上,Sun 等[65]在原有分类和定位分支外,新增加一个对比分支,通过对比候选框编码损失函数,利用余弦相似性函数度量感兴趣区域特征和特定类权重的语义相似性。
在元学习范式上,Fan 等[29]在Attention-RPN 方法中采用了三元组对比训练策略,即一张支持集图像与查询集相同类别的一个正例和不同类别的一个负例组成一个三元组。Quan 等[44]在分类对比学习InfoNCE[66]的启发下,将无监督的对比学习转换为有监督的对比学习,对支持和查询两分支的最终特征施加对比学习策略。
3.3.3 原型学习

基于迁移学习范式,Qiao 等[67]提出了一个解耦的Faster R-CNN 方法DeFRCN(decoupled faster R-CNN),通过在分类分支中使用原型校准模块解决多任务的耦合。使用一个离线的原型与感兴趣区特征计算相似度,然后用得到的相似度微调模型进行类别预测,可以分类出与原型相似的感兴趣区域特征。Wu 等[33]提出了通用原型的方法FSOD-UP,通用原型是在所有的对象类别中学习的,而不是某一个特定类。不同类别间存在着内在不变的特征,可以利用这点来增强新类对象特征。
基于元学习范式,Li等[68]提出了基于元学习和度量学习的MM-FSOD(meta and metric integrated fewshot object detection)方法,将元学习训练方法从分类转移到特征重构。新的元表示方法对类内平均原型进行分类,区分不同类别的聚类中心,然后重建低级特征。Han 等[43]针对候选框生成提出了Meta Faster R-CNN 方法,采用基于轻量化度量学习的原型匹配网络。Meta Faster R-CNN 中Meta-RPN 是一个锚框级轻量化粗粒度原型匹配网络,Meta-Classifier 是一个像素级细粒度原型匹配网络,整个检测网络是从粗粒度到细粒度优化的过程,用来产生特定新类的候选框。考虑到FSRW[28]方法只是简单地平均支持样本信息生成每个类别的原型,这样的做法泛化性较差,APSPNet[50]将每个支持样本看作一个原型,称之为逐样本原型,这样可以更好地将不同的支持信息与查询图像结合。
综上所述,度量学习主要通过令相同类别之间彼此靠近、不同类别之间彼此远离来完成。其思路简单好用,被大量应用到小样本目标检测中,但度量学习过于依赖于采样的策略,如果采集的样本过于复杂,可能会发生不收敛、过拟合的问题;如果采集的样本过于简单,又可能不会学习对类别检测有用的信息。
3.4 基于数据增强
小样本的核心问题是其数据量少,最简单直接的想法就是扩充数据样本。郭永坤等[69]就图像在空频域上的图像增强方法作了研究综述,数据增强技术可以通过直接增加训练的图像数量或者间接对特征进行增强,使得网络的输入信息增加,从而最大程度地增加模型能够处理的图像信息,减少模型的过拟合。
3.4.1 多特征融合
在迁移学习范式上,Zhang 等[32]提出了PNSD 方法,使用多特征融合得到细节更丰富的特征图,多特征融合采用双线性插值上采样和1×1 卷积下采样将所有特征映射到相同的尺度,将尺度信息显式混合到特征图中。另外,通过注意力候选区网络生成候选框,经过相似网络的全局、局部和块状关系头三种关系进行分类和定位。Vu 等[70]对通过主干网络得到的特征图使用了多感受野的婴儿学习,使用多感受野可以得到该对象的更多空间信息,通过微调多感受野模块有效地将先验空间知识转移到新域。
基于元学习范式,Xiao 等[71]提出FsDetView 方法,将查询图像的候选框和支持集特征进行三种方式特征融合,三种融合方式分别是通道连接、简单相减和查询特征自身,这样可以更好地利用特征之间的内在关系。Fan 等[29]在提出的Attention-RPN 方法中使用了多关系检测器,通过支持集的候选框和查询集感兴趣区域特征进行全局、局部和块状的关系结合,避免了背景中的错检。Hu 等[49]认为当对象发生遮挡时,局部的细节信息往往起绝对性作用,提出了DCNet 方法,在感兴趣区域上使用三种不同的池化层捕捉上下文信息要远好于单一池化的效果。彭豪等[45]对感兴趣区域分别施加最大池化和平均池化技术,进行多种特征融合,可以提升模型对新类参数的敏感度。
3.4.2 增加样本数量的方法
在迁移学习范式上,Wu 等[72]为解决小样本中的尺度问题,提出了MPSR(multi-scale positive sample refinement)方法,将对象金字塔作为一个辅助分支加入到主体的Faster R-CNN 和特征金字塔网络(feature pyramid networks,FPN),手动地将处理过的不同尺度对象方形框与FPN 的不同级别进行对应,使模型捕捉到不同尺度的对象。为解决训练数据变化的缺乏,Zhang 等[73]在感兴趣区域特征空间上通过幻觉网络(hallucination)产生额外的训练样本,将从基类中学习到的类内样本变化转移到新类上。Kim 等[53]为了不破坏图像中的空间关系,选择在图像中随机调整每个对象的尺寸若干次,这样既增加了感兴趣区域的数量,又适应了不同大小的对象尺度。Sun等[65]认为具有不同交并比(intersection over union,IoU)分数的候选框类似于类内数据增强,在TFA 的基础上提出了更优的FSCE(few-shot object detection via contrastive proposals encoding)方法,即在微调阶段,将NMS(non maximum suppression)处理后的候选框的最大数量翻倍和将感兴趣区域特征中用于损失计算的候选框数量减半。Xu 等[40]认为图像金字塔技术在增加正样本数量的同时也引入了大量的负样本,没有充分发挥正样本数量增强的优势,提出了正样本增强技术,包括背景稀疏化、多尺度复制和随机裁剪技术,通过去除一些负样本实例,大大减少了负样本的占比。Kaul 等[74]提出了Pseudo-Labelling 方法,采用伪标记的方法增加新类别的样本数量,首先在训练集上产生新类的伪标记,通过自监督训练的验证删除标签不正确的大量边界框,之后由类似Cascade R-CNN[75]的逐步优化方法纠正质量差的边界框,大大减少类别不平衡性。Guirguis 等[76]利用连续学习中的重放方法存储以前的任务中的基类样本,以便在学习新任务时进行重放,实现基类和新类之间的知识转移。提出了一个新的梯度更新规则,将基类的梯度添加到新类梯度更新中,它还会自适应地重新加权它们,以防新梯度指向可能导致遗忘的方向。作为一个即插即用的模块,可以很方便地与任意FSOD模型结合。多尺度正样本特征提取如图10所示。
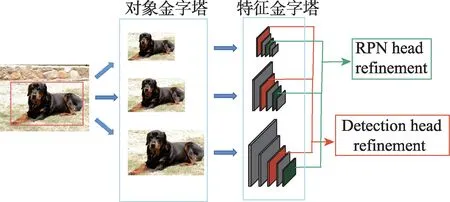
图10 多尺度正样本特征提取Fig.10 Multi-scale positive sample feature extraction
在元学习范式上,Yang 等[77]以RepMet 为基础,提出了NP-RepMet 方法,将其他方法丢弃的负样本纳入模型训练中,可以得到更加鲁棒的嵌入空间。Li等[22]除了使用简单的数据增强技术外,还将变换不变性(transformation invariant principle,TIP)引入到小样本检测中。具体地,在查询分支上,用从查询变换图像中得到的候选框检测原始查询图像对象边界框,在支持分支上,在原始支持图像和支持变换图像间施加一致性损失,最后对两分支结果做聚合处理。Zhang 等[78]认为不应该对支持样本只进行简单的平均操作,提出了SQMG(support-query mutual guidance)方法。在基训练阶段,支持引导的查询增强通过核生成器对查询特征进行增强,通过支持查询相互引导模块生成更多与支持相关的候选框。另外,候选框和聚合支持特征之间进行多种特征比较,得到更高质量的候选框。
3.4.3 增加候选框数量的方法
基于迁移学习范式,Zhang 等[79]提出了同时使用多个区域候选网络结构的CoRPNs 方法,用以解决因为样本少而产生较少的候选框的问题,如果某一个区域候选网络遗漏了具有高IoU 值的候选框,那么其他的区域候选网络能够检出该候选框。在模型训练时,只有最确定的那个区域候选网络模块才能获得梯度,在测试时,也只从最确定的那个区域候选网络中获取候选框。
为了解决模型不遗忘的问题,Fan 等[80]提出了基于元学习范式的Retentive R-CNN 模型,新增了Bias-Balanced RPN 和Re-Detector 模块。区域候选网络不是完全的类无关的,而更偏向于可见类别的检测,因此,基类检测器不能很好检测出新类,产生了很多误报。在Bias-Balanced RPN 中引入了新的分支,同时检测新类和基类对象,原有的检测头只用来检测基类。在Re-Detector 中,原有分支只检测基类,新分支同时检测基类和新类,在两个分支基类检测上施加一致性损失可以更好地完成检测。
综上所述,可以直接或间接的多种方式完成对新类别数据样本的扩充,增加新类别样本数据的方法是最直接有效的解决类别样本数量不足的方法,同时也能带来更加丰富的样本特征,减少模型过拟合的产生,但如果使用了过多的数据增强策略,可能会在增加样本信息的同时,引入一些无关的噪声信息。
4 算法数据集、评估指标和性能分析
小样本目标检测方法中常用的公开数据集有Pascal VOC[25]、MS-COCO[26]和FSOD[29]数据集,在个别方法中使用到的其他数据集有LVIS[27]、iNatureList[81]、ImageNet-Loc[82]等。数据集的概况如表1 所示。

表1 小样本目标检测常用数据集及其划分方式Table 1 Typical datasets for few-shot object detection and their divisions
4.1 小样本目标检测公开数据集介绍
4.1.1 Pascal VOC 数据集
小样本目标检测实验使用的Pascal VOC 数据集由Pascal VOC2007[25]和Pascal VOC2012[83]共同组成,整个VOC 数据集一共有21 503 张图像,其中,VOC07有9 963 张图像,VOC12 有11 540 张图像。VOC07 和VOC12 的train 和val 集合数据用模型训练,VOC07的test 集合数据用于模型测试。VOC 数据集一共有20 个类别,随机选择其中的5 类作为新类,剩余的15类作为基类,为了尽量减少由随机性带来的影响,分成多组不同的数据进行训练,常见的做法是分为3 组进行,即分组1、分组2 和分组3,每个分组中新类的类别均不同,关于3 组划分的具体细节如下:分组1的新类类别为鸟类、公交车、牛、摩托车和沙发;分组2 的新类类别为飞机、瓶子、牛、马和沙发;分组3 的新类类别为船、猫、自行车、羊和沙发。分组中每个新类的对象都应当有K个标注边界框,VOC 数据集中K的取值常为1、2、3、5、10。由于新类的样本数量非常少,其选择会非常影响模型的性能表现,采用多次实验来消除随机性的影响,TFA 提出通过30 次重复实验并取平均值得到公平的实验结果,之后的一些论文提出只进行10 次实验也可以公平比较实验结果。
4.1.2 Microsoft COCO 数据集
COCO2014[26]数据集相比VOC 数据集有更多的类别和更多的图像,包含123 287 张图像,其中,训练集有82 783张图像,验证集有40 504张图像。从COCO数据集的train 和val 集合中选取5 000 张图像用作测试数据集,其余的图像用于训练阶段。选取COCO数据集中与VOC 重叠的20 个类别作为新类,剩余的60 类作为基类数据,同时K的取值通常为10、30,即一个类别选择10 个或者30 个目标样本用来训练。
4.1.3 FSOD 数据集
FSOD 数据集[29]是专门针对小样本目标检测而设计的数据集,对于小样本目标检测任务来说,类别数量越多检测效果越好。FSOD 数据集的类别数很多,总共有1 000 类,每个类别的标注数量较少,超过90%类别的图像数量在22~108 张之间,即使最常见的类别也没有超过208 张图像,总的图像数量也并不多。FSOD 数据集包含大约66 000 张图像和182 000个边界框,其中训练集800 类,测试集200 类,有531类来自ImageNet 数据集,有469 类来自OpenImage 数据集。此外,FSOD 数据集还合并了有相同语义的类别,移除了标注质量差的数据。
4.1.4 其他数据集
ImageNet-Loc数据集[82]在RepMet[61]和Meta-RCNN[35]中使用,固定地使用500 个随机的任务,每个类别的边界框的数量取不同的1、5 和10。
iNatureList 数据集[81]是一个长尾分布的物种数据集,包含2 854 个类别,可以检测在所有类上的AP指标(具体有AP、AP50 和AP75)和AR 指标(AR1 和AR10)。
LVIS 数据集[27]在TFA 中有被使用,其有着天然的长尾分布,整个数据集的类别分布为类别图像数量小于10 个的稀有类、图像数量为10~100 的普通类和图像数量大于100 的频繁类。将频繁类和普通类看作基类,稀有类看作新类进行训练。在模型的微调阶段,手动创建一个平衡的数据子集,其中每个类别拥有10 个实例。
Zhu 等[54]提出了一个更加现实的FSOD 数据集基准,即删除预训练分类模型中有关的新类图像的隐式样本(implicit shot)。在CoRPNs[79]中,也提到了移除预训练数据集中有关的基类和新类数据,包含275类,超过30 万张图像。Huang 等[84]指出,这样的做法可能会使预训练模型得不到最优解。因此,只删除对应VOC 数据集中新类的数据即可,对于COCO 数据集,它的新类类别是很常见的,应该按照长尾分布,选取样本量少的作为新类。
4.2 评估指标
通用目标检测方法常用的评估指标有平均准确率(average precision,AP)[85]和平均召回率(average recall,AR)。
AP 表示检测所得正样本数占所有检测样本的比例,其表达式为:

式中,TP表示被正确检测为正例的实例数,FP表示被错误检测为正例的实例数。AP 表示类别的平均检测精度,mAP(mean average precision)是平均AP值,是多个目标类别的检测精度,即将每个类别的AP值取平均得到mAP 值。
AR 表示检测所得正样本数占所有正样本的比例,其表达式为:

式中,TP表示被正确检测为正例的实例数,FP表示被错误检测为负例的实例数。
小样本目标检测的评估指标和通用目标检测有一些细微的差别,VOC 数据集根据所选新类类别的不同分为3 组实验,在每组中,新类样本数量K的取值均为1、2、3、5 和10。一般地,只需检测新类类别的AP 值(novel AP,nAP)即可,一些算法也会关注模型体现在基类上的不遗忘特性,测试所得模型在基类的性能,指标为bAP(base AP),这里所提到的AP 值都是在交并比值为0.5 的mAP 值。
在COCO 数据集中,新类样本数量K的取值为10 和30,模型会检测在新类数据集上的不同IoU 阈值、不同对象尺度的AP 值以及不同的AR 值。采用COCO 风格的评价指标,具体指标项有mAP、AP50、AP75、APs、APm 和APl。这里的mAP 指的是在10 个IoU 阈值(0.50:0.05:0.95)的指标,AP50、AP75 则是只计算单个IoU 阈值(0.50 和0.75)的指标。APs、APm 和APl 表示在不同的标注边界框面积的指标,APs 是面积小于32 像素×32 像素,APm 是面积在32像素×32 像素到96 像素×96 像素之间,APl 是面积大于96 像素×96 像素。AR 有AR1、AR10 和AR100(AR1 是指每张图片中,在给定1 个检测结果中的指标,其他同理)。
由于随机性的影响,以上检测值都会通过多次实验取平均值当作最后的结果。一般地,VOC 的重复实验次数为10 次或者30 次,COCO 数据集的重复次数为10 次。另外,FSOD 数据集中K的取值常为1、5,具体指标项为AP50 和AP75。
跨数据集问题:从COCO 到VOC,使用VOC 和COCO 重合的20 个类别作为新类,使用COCO 中剩余的60 类作为基类数据,K的取值为10,具体评估指标项为mAP。
4.3 算法性能分析
表2 根据不同的改进策略,对现有方法分类的机制、优势、局限性和适用场景这四方面进行了详细比较。本节使用在4.2 节中提到的数据评估策略在VOC、COCO 和FSOD 数据集上对各个方法进行性能评估,而像iNaturaList、ImageNet-LOC 等数据集由于被使用次数较少,说服力差,不具有可比性,故不做性能对比分析,具体结果可见表3~表7,表中加粗为最优性能结果,下划线为次优性能结果。

表2 小样本目标检测方法优缺点对比Table 2 Comparison of advantages and disadvantages of few-shot object detection methods
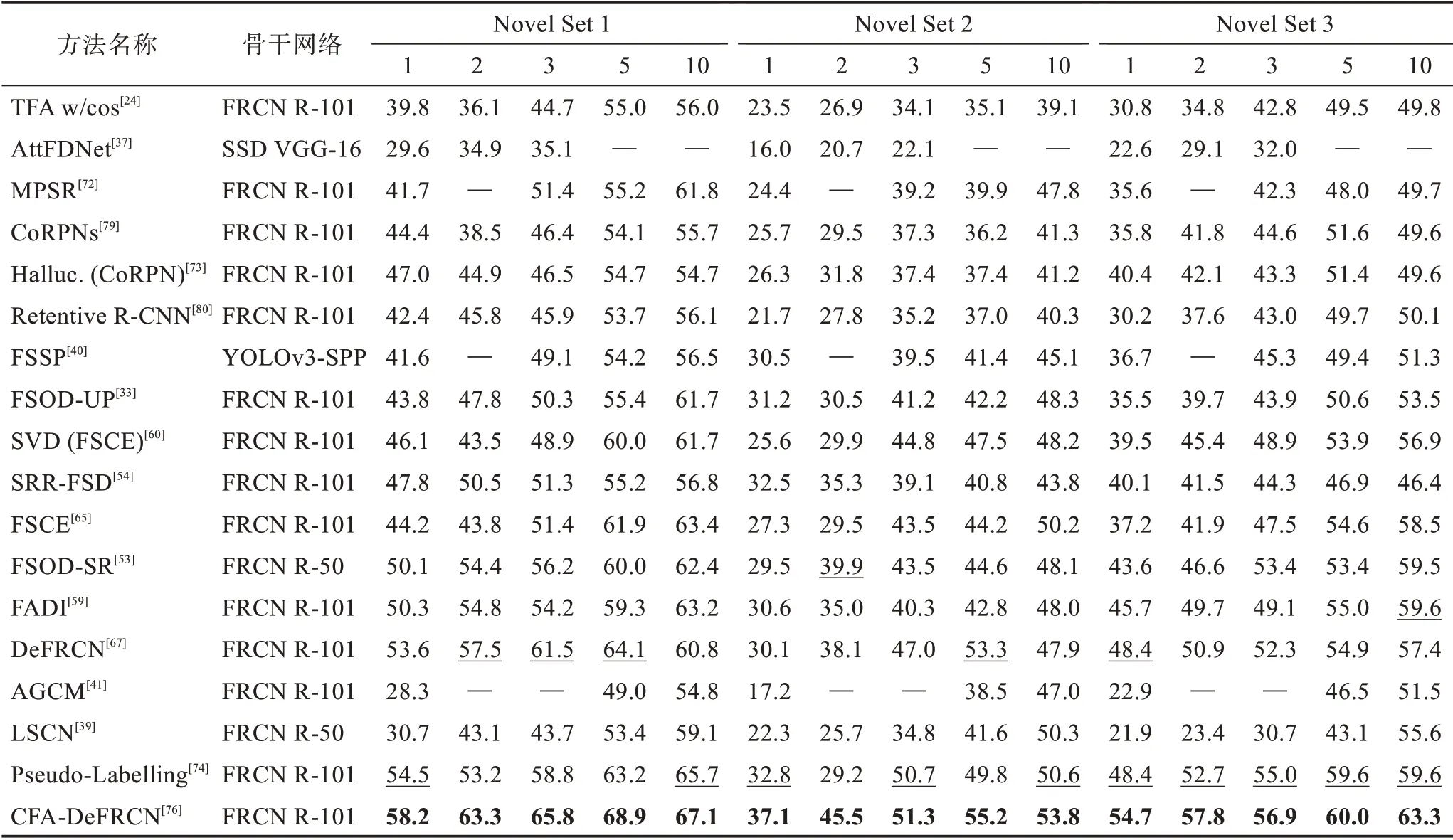
表3 迁移学习方法在VOC 数据集上的mAP 对比Table 3 mAP comparison of transfer learning methods on VOC dataset 单位:%

表4 元学习方法在VOC 数据集上的mAP 对比Table 4 mAP comparison of meta-learning methods on VOC dataset 单位:%

表5 迁移学习方法在COCO 数据集上的AP 对比Table 5 AP comparison of transfer learning methods on COCO dataset 单位:%
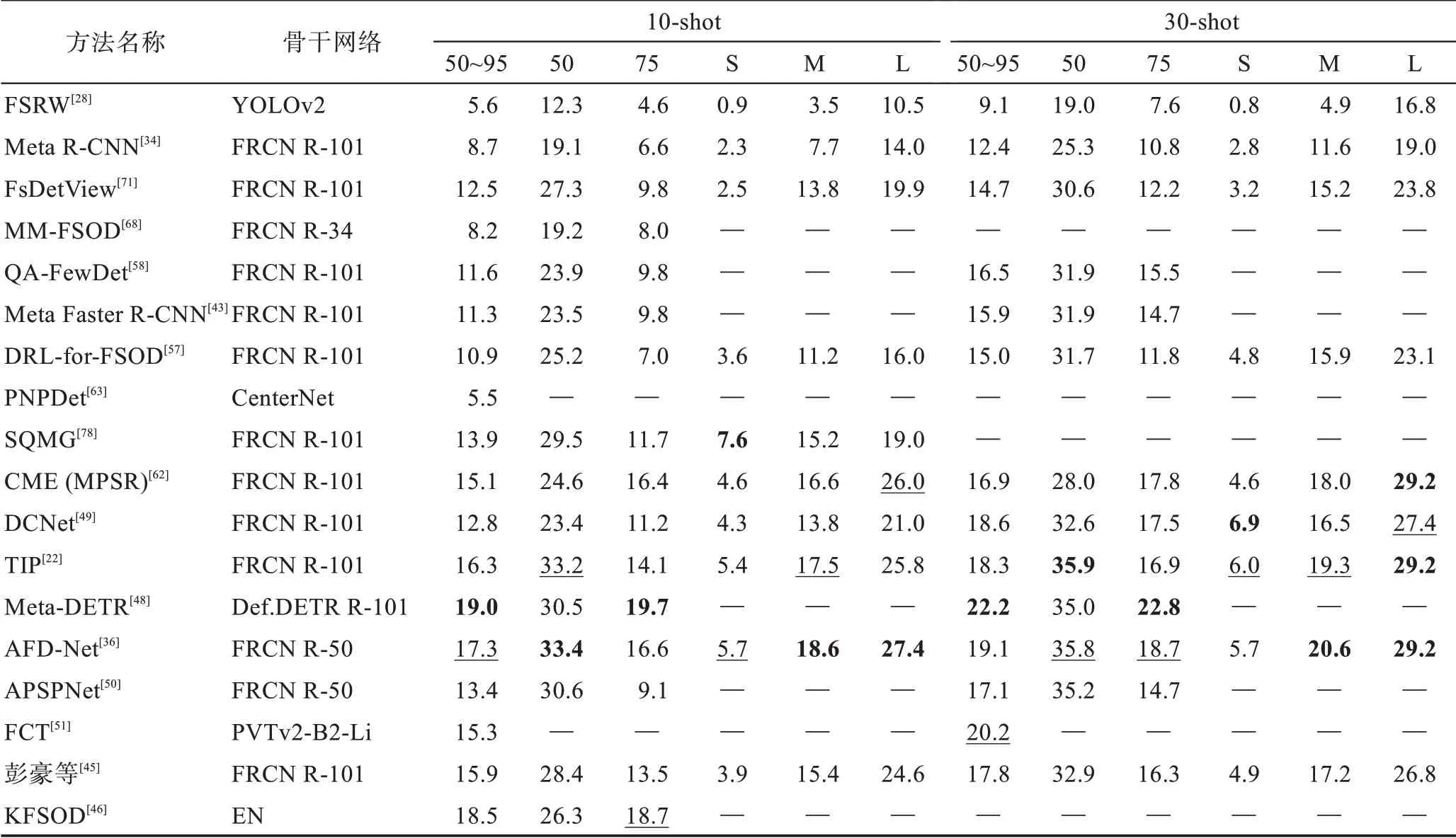
表6 元学习方法在COCO 数据集上的AP 对比Table 6 AP comparison of meta-learning methods on COCO dataset 单位:%
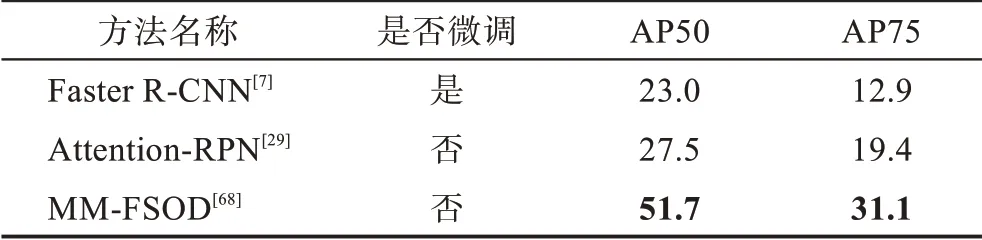
表7 FSOD 数据集上的性能对比Table 7 Performance comparison on FSOD dataset 单位:%
从表中可得:(1)无论是采用迁移学习范式还是元学习范式在检测性能上并没有太大的差异,由前述对两种范式的分析可选择适合的范式进行改进增强。(2)随着shot 数的增多,检测性能有较大的提升,说明图像信息越多,学习到的特征信息越充分,样本数据增强可能是小样本问题解决的关键,最新的方法Pseudo-Labelling[74]和CFA-DeFRCN[76]都在探索数据增强的方法,也说明了数据增强的重要性。(3)在不同的数据集上检测结果也不相同,VOC 的检测结果总体要大于COCO 的检测结果,在VOC 和COCO数据集上表现最好的都是基于迁移学习范式的CFADeFRCN,其除了使用数据增强外,将其结合基于度量学习DeFRCN 方法使用,得到了最优秀的检测结果。可见使用较为简单直接的技术方法可以成功减少模型过拟合的程度,从而达到较优的效果。(4)其他的使用注意力机制方法的Meta-DETR 和AFD-Net以及使用数据增强的SQMG方法也表现出了不错的性能。
5 小样本目标检测在各领域的应用研究
小样本目标检测算法由于只需要少量的新类标注就可以完成对目标类别的检测,目前在自动驾驶、遥感图像检测、农业病虫害检测等领域都有应用。
5.1 自动驾驶
自动驾驶是目前计算机视觉应用较为成功的一个领域,车辆行驶会面临非常多的场景,遇见各种各样的类别,不可能对全部的类别收集到大量标注的图像,自动驾驶需要确保驾驶的绝对安全,在很短的时间里做出反应,这些特性通用目标检测都无法满足。Majee 等[86]新提出了IDD[87]数据集,并验证了TFA 方法和FSRW 方法在该数据集上的性能表现;Agarwal 等[41]提出了AGCM 方法,有助于在检测器的分类头中创建更加紧密且良好分离的特征簇,在IDD自动驾驶数据集上取得了当时的最好效果。
5.2 遥感目标检测
另外一个常见的应用领域是遥感目标检测,遥感图像有助于救援行动援助、灾害预测和城市规划等,对于一些偏远地区或者无人区遥感数据的获取同样非常困难,且其中出现的目标种类众多,这对于通用目标检测是极大的挑战。Xiao 等[88]提出了SAAN(self-adaptive attention network)方法,在目标对象上使用注意力,而不是整张图像,避免一些无用的甚至是有害的特征干扰,在RSOD[89]数据集上取得了最好的效果。另外,李成范等[90]在自建的HSI 遥感图像上应用K 近邻(K-nearest neighbor,KNN)得到了图像局部特征,并与改进的CNN 算法结合,使用TripletLoss 损失令同类更加紧密,不同类别更加分离,得到了良好的检测效果。
5.3 农业病虫害检测
对于农业病虫害检测,需要专业的领域知识才能识别不同作物、不同生长环境下的病虫害,完成标注工作,而要求农业专家进行大量的标注工作是费时费力的,且害虫可以处在不同的发育期,要获取大量这种图像数据同样较为困难,现阶段只有很少的一些工作涉及到小样本病虫害检测。刘凯旋[91]建立了基于不同样本数量的水稻害虫检测算法。在样本数据多的时候,使用Cascade R-CNN[75]模型进行害虫检测,当样本数量进一步减少时,再通过条件判断切换成小样本目标检测算法,为后续农业害虫的智能化检测研究提供了理论支撑。桂江生等[92]针对大豆食心虫虫害进行了小样本检测,通过卷积学习一个非线性度量函数,而不是使用线性度量公式衡量查询集和支持集之间的关系,最终5-shot 的条件下可以达到82%的检测率。
5.4 其他潜在应用领域
另外,还有一些其他可以探索的应用领域,比如,自然界的生物种类众多,对于生物保护来说,辨认物种类别尤为关键,其类别符合长尾分布,大部分的类别都只有很少的数量且不易获取到其图像,可以将其应用到不常见的生物物种检测;零售商品的自动售卖技术很方便地为顾客提供24 h 服务,零售商品的种类成千上万,目标检测所需的标注成本巨大,如果只标注很少图像就可以完成检测的话,可以大大缩减成本;在工业检测领域,缺陷检测的自动化工作可以节约大量的人力且提高效率,比如鸡蛋裂纹检测,可以提高产品质量,但实际的工厂作业很难收集到大量的样本数据,小样本目标检测可以利用少量的样本完成缺陷检测。
6 小样本目标检测的未来研究趋势
小样本目标检测的创建初衷是用来解决实际问题的,可现阶段的效果仍然不太理想。譬如小样本目标检测方法在COCO 数据集10-shot 的条件下最好的mAP 检测效果仅有19.1%,这距离实用性仍有较大的差距。除了需要提高检测精度外,未来小样本目标检测方法在以下方面值得进一步的研究:
(1)自适应领域迁移:从不同领域学习到的通用概念往往并不相同,将从一个领域中学习到的知识迁移到另一个领域的方法,叫作自适应域迁移。小样本目标检测方法也是将从基类学习到的知识迁移到新类中,可以将自适应领域迁移的方法应用到小样本目标检测方法中。
(2)数据增强方面:小样本对于模型过拟合问题尤为敏感,而图像数据增强技术恰恰是最直接简便的用于减少过拟合的方法,比如使用半监督和自监督等方法可以减少模型的过拟合。
(3)图卷积神经网络:现在有一些工作是基于图卷积神经网络完成的,但图卷积神经网络是一个仍在不断探索的领域,研究如何在小样本条件下通过图卷积神经网络更好推理学习是很有前景的方向。
(4)多模态的方向:Transformer 作为注意力机制方法,有着天然的处理多种模态的数据,将文字和图像等结合起来共同考虑,这对于缺乏图像样本数量的小样本检测任务是巨大的增强。
7 总结
本文对小样本目标检测做了详细的分析总结。首先,介绍了小样本目标检测任务的定义及相关概念,叙述了小样本目标检测基于元学习和基于迁移学习的两种经典范式,重点阐述了从注意力机制、图卷积神经网络、度量学习和数据增强方面提升小样本目标检测性能的方法。之后,对常用数据集和评估指标进行了介绍,对各个方法的性能进行了比较和分析。最后,提出了小样本目标检测应用的一些领域并对未来的研究方向进行了展望。
