结合眼动信息和序列指纹的亚暴事件识别方法
2023-01-17韩怡园高新波
韩怡园,韩 冰+,高新波
1.西安电子科技大学电子工程学院,西安710071
2.重庆邮电大学重庆市图像认知重点实验室,重庆400065
极光亚暴[1-2]也称作地磁亚暴,是地球磁层产生强烈扰动时的一种现象,它也是地球磁层中能量输入、耦合和释放的过程。据有关研究显示,其发生时释放的能量大约相当于一次中等地震的能量。巨大的能量释放会对高纬度地区的通讯、飞行器、全球定位系统(global positioning system,GPS)等产生强烈的干扰和影响。而现代人类的生活非常依赖于这些设施,假如极光亚暴的发生对这些设备造成了破坏和干扰,则在一定程度上也会影响到现代人类社会的生活。因此,自动且高效地对极光亚暴进行识别、研究其发生机制、对其进行预测不仅具有非常重要的科学意义同时也对保障人类生活、避免不必要的损失起到了至关重要的作用。
随着科技的发展,许多卫星携带的成像仪可以全方位地对高空极光现象进行有效捕捉。在众多类型的极光图像中,有研究表明,Polar 卫星[3]携带的紫外成像仪[4-5]获取到的紫外极光(ultraviolet imager,UVI)图像则是研究亚暴发生机制最有效的数据[6]。Polar 卫星在其运行过程中每一年可以采集到上千万张UVI 图像。准确地识别亚暴事件是后续对其发生机制等研究的前提,但由人工在海量的图像中挑选出亚暴发生的序列是非常耗时且费精力的。因此,如何自动且准确地从海量的紫外极光图像中识别出亚暴事件是当下该领域亟需解决的关键问题。
在对亚暴事件研究的初始阶段,大多数方法是以人工筛选的方式进行识别的。这些方法[7-8]主要根据亚暴发生的阶段性特点对其初始时刻进行判断和定位,从而根据一般亚暴发生的时长得到亚暴发生的序列。除此之外,有部分学者发现某些空间物理参数的变化与亚暴发生有非常密切的关系。例如极光电集流指数(auroral electrojet,AE)的变化能够反映亚暴发生对磁层的扰动强度[9-10]。通过观测相关物理参数的变化就能够定位和识别亚暴发生和结束的时刻。以上的这些方法虽然可以比较准确地识别亚暴事件,但都是非自动化的识别方法,完全依赖于研究者个人对亚暴发生特性的主观认知,存在识别效率低下的问题。
随着计算机科学和机器学习的迅猛发展,部分研究者则致力于如何利用机器学习领域的算法对亚暴事件进行自动的识别和检测。这些方法[11-12]以人工标注的亚暴事件为基准,将UVI 图像作为机器学习算法的输入,从而实现对亚暴事件的自动化识别。但这些方法仅依赖于UVI 图像在亚暴发生时所呈现的物理特性,因此,其识别结果与人工标注的亚暴事件相比,还具有一定的差距。
区别于一般的视频/序列识别任务,亚暴事件的识别是非常依赖于空间物理科学的专业知识。而空间物理专家们对亚暴序列的视觉认知过程是识别亚暴事件最科学和有效的知识来源。现有能够有效获取人类视觉行为的仪器称为眼动仪,它能够实时跟踪人类的视线[13],获取和记录人类对任何图像或场景的视觉眼动数据。因此,本文提出了一种新的基于眼动信息和序列指纹的极光亚暴事件识别方法。该方法结合了人工标注与机器学习算法两者的优势。首先通过眼动仪获取空间物理领域专家对亚暴序列的视觉认知信息(眼动信息);其次根据极光亚暴发生不同阶段的物理特性对每个亚暴事件中的图像进行标记得到其对应的序列指纹;最终以眼动信息为输入,序列指纹为指导,利用机器学习算法实现对亚暴事件的自动且精确的识别。基于以上表述,本文的贡献可总结如下:
(1)构建了一个新的基于极光亚暴事件的眼动数据库。该数据库包含了15 位不同的空间物理专家在观察不同亚暴序列时的视觉认知信息(眼动信息),也就是每张紫外极光图像对应的眼动注视图。
(2)不同于直接对亚暴事件进行整体标记的方式,本文所提出的方法通过对亚暴事件中的每张图像进行二分类的标记得到每个事件的序列指纹,从而将事件识别问题转化为图像分类问题,在一定程度上减小了该任务的难度。
(3)通过设计对序列指纹的判别策略,结合专家眼动注视图,提出了基于眼动信息和序列指纹的极光亚暴事件识别方法。该方法的性能优于其他亚暴事件自动识别方法。
1 相关工作
本章除了介绍极光亚暴事件的识别相关工作,还主要介绍近年来基于图像分类任务的相关深度学习网络的研究进展。
1.1 极光亚暴事件识别方法
关于极光亚暴事件识别任务的相关研究主要分为三大类:人工筛选识别方法、基于物理参数的识别方法和基于机器学习的识别方法。
人工筛选识别方法主要有两项工作。对于Polar卫星采集的UVI 图像数据,Liou[8]挑选出了其运行期间所有年份的亚暴事件。对于IMAGE 卫星采集的UVI 图像数据,Frey 等人[7]对其进行了人工标记。但人工筛选的工作量非常大,且在一定程度上会受到标记者的主观认知的影响。因此,不适用于在海量的UVI图像中识别亚暴事件。
基于物理参数的识别方法主要是通过寻找特定的亚暴事件,分析在该事件发生时与亚暴相关的空间物理参数的变化规律,利用这些规律对其余的UVI图像数据进行判断,从而实现对亚暴事件的识别。目前已有学者通过研究亚暴发生时Pi2地磁脉动[14-15]、AE[16-17]等参数的变化实现对亚暴事件的识别和检测。例如Sutcliffe 借助Pi2 地磁脉冲的变化实现对亚暴事件的检测[18]。这些方法都依赖于物理参数的变化规律,然而物理参数的获取和UVI 图像的获取分辨率是不一致的,有些情况下会存在缺失的情况,这些问题都影响着该类方法的准确性。
基于机器学习的方法近年来也有许多工作。针对Polar 卫星的UVI 图像,杨秋菊等人提出了一种基于亚暴膨胀相的自动亚暴事件识别方法[11]。Yang 等人也根据亚暴发生时的图像序列特征,提出了一种基于形状约束的稀疏低质矩阵分解的亚暴自动检测方法[12]。连慧芳则基于美国的国防气象卫星(defense meteorological satellite program,DMSP)和全球紫外线成像仪(global ultraviolet imager,GUVI)卫星的低时间、高空间分辨率的紫外极光图像数据,通过检测西行浪涌结构实现对亚暴事件的检测[19]。这些方法均利用亚暴发生过程不同阶段的图像特征对亚暴事件进行识别,但都忽略了空间物理专家在识别极光亚暴事件时的视觉认知信息,其识别准确率与人工筛选的方式还具有一定的差距。
1.2 深度学习图像分类方法
随着深度学习算法的发展,近年来涌现出了许多深度学习网络,这些网络在图像分类任务取得了非常好的效果。从2012 年AlexNet[20]在ImageNet 分类比赛中取得冠军之后,深度学习网络的性能在图像分类任务中逐渐占据了领先地位。针对AlexNet网络的参数量较大的问题,Simonyan 等人通过堆叠3×3 的卷积核加深网络深度,进而提出了VGGNet[21],提高了网络的分类性能。随后,Szegedy 等人提出的GoogLeNet[22]采用多支路并行的方式在保证计算资源使用效率的前提下,进一步地提高了网络的性能。随着深度学习网络层数的增加,在训练过程中出现了梯度爆炸、消失等问题,使得网络难以优化。
为了解决上述问题,He 等人在2016 年利用残差块结构代替原有的卷积结构提出了ResNet[23],该网络不仅进一步地提升了分类效果,同时在网络层数高达152 层时也能够较好地克服梯度消失问题。在此之后,出现了许多基于ResNet 改进的深度学习网络,例如Wide Residual Network[24]、DenseNet[25]、ResNeXt[26]、Res2Net[27]、ResNeSt[28]。这些网络从宽度、模块连接方式、通道分支数、特征提取粒度、增加通道注意力等不同方面对ResNet 进行了改进,并提高了网络的分类精度。这些网络虽然提高了网络的性能,但训练时间长、模型复杂,是非常耗费计算资源的。
在保证网络性能的前提下,是否能够尽可能地减少网络计算量和参数?基于此思想,许多学者开始研究轻量化的深度学习网络。典型的轻量化网络有SqueezeNet[29]、Xception[30]、MobileNet[31]系列和Shuffle-Net[32]系列。这些网络有效提高了内存利用率和网络运行速度,但在分类性能上略低于传统的深度学习网络。上述的网络均是研究者根据经验或者知识人工设计网络的结构。人工设计的网络结构性能是有限的,因此出现了利用神经网络自动设计神经网络结构的方法,称为神经架构搜索(neural architecture search,NAS)。2019 年,Tan 等人基于NAS 搜索设计出了EfficientNets[33]系列模型。该模型平衡了网络的宽度、深度和分辨率,这一系列的部分网络模型不仅具有轻量化的特性,同时在当前的所有深度学习网络中其分类性能是处于优势地位的。
2 极光亚暴事件眼动数据库
该部分主要介绍极光亚暴事件眼动数据库的构建和对眼动数据的分析。
2.1 数据组成
极光亚暴的发生主要有3 个阶段:增长相、膨胀相和恢复相。如图1 所示,在增长相阶段,极光活动较弱,极光椭圆上的亮度较暗。在膨胀相阶段,极光活动最为强烈,可以看到极光椭圆上的亮斑有明显的向两侧扩散的现象。在恢复相阶段,极光椭圆上的亮斑会逐渐消散,也就说明极光活动强度变弱并逐渐恢复平静。
如表1 所示,本研究中构建的极光亚暴事件眼动数据库包括原始极光亚暴序列、每个序列对应的眼动txt 数据(包括每位被试者的每个注视点位置和时长信息)和序列指纹、所有亚暴事件中图像对应的二分类标签及其对应的眼动注视图。如图1 所示,二分类标签为0 和1,0 代表增长相和恢复相中的极光图像,1 代表膨胀相中的极光图像。序列指纹由每个序列中所有图像的分类标签组成,可表示为01110。眼动注视图由各位专家观看亚暴序列时眼动仪记录的注视位置和时长生成,作为专家的眼动信息参与深度学习网络训练,具体实现细节将会在实验部分介绍。

表1 极光亚暴眼动数据库数据组成Table 1 Data composition of auroral substorm eye movement database
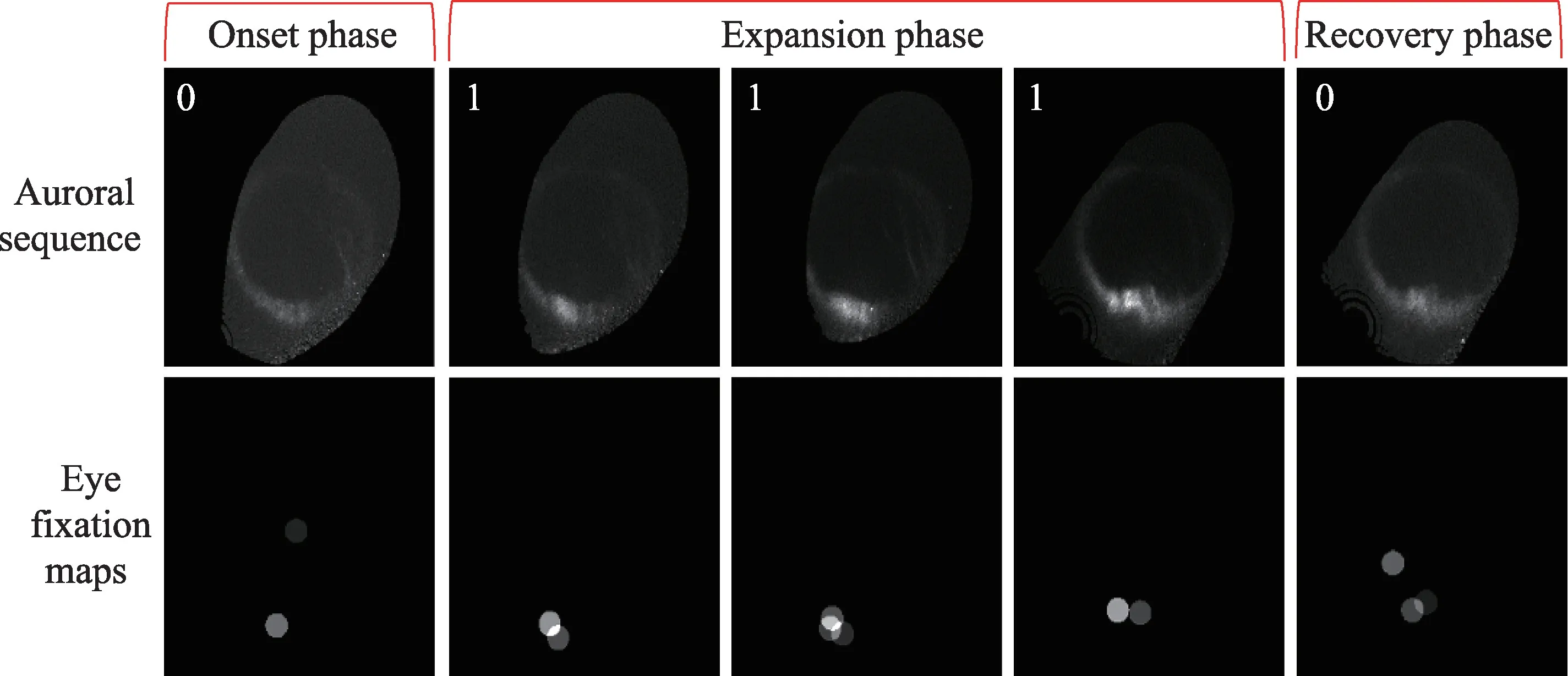
图1 极光亚暴不同阶段图像样例Fig.1 Image samples of different stages of auroral substorms
本文所使用的数据为1996—1997 年冬季的UVI数据,根据Liou[8]所提供的人工标注,共选取197 个亚暴序列与197 个非亚暴序列作为眼动测试数据。实验中采用的亚暴序列基本上包含了大部分类型的亚暴事件,且根据亚暴发生持续的时间,每个序列的长度是不一致的。
2.2 眼动实验设置
极光亚暴事件识别眼动实验共邀请了15 位被试者参与。所有被试者均来自西安电子科技大学,年龄在20~40 岁,裸眼或矫正后视力良好。被试者中有7 位为常年从事极光亚暴研究的学生/老师,其余的为学习过极光亚暴相关知识的学生。使用Eyelink 1000 plus 眼动仪进行眼动数据采集。首先保证实验环境安静,其次每位被试者参与20~30 组的亚暴序列识别实验,期间每5 组休息5~10 min 以保证眼动数据的准确性。
极光亚暴识别眼动实验流程如图2 所示,实验过程中会在屏幕上随机显示一段极光图像序列,要求被试者通过观察判断该序列是否为亚暴序列,若一次观察无法确定该序列是否为亚暴序列,可按键选择进行重复观看直至做出判断。为了使被试了解实验流程,每位被试在正式开始实验前,先进行一次预测试实验,该测试实验设置与极光亚暴事件识别的正式眼动实验一致。为了保证不干扰被试对亚暴序列的判断,仅将极光亚暴序列换成自然图像序列。

图2 眼动实验流程图Fig.2 Flowchart of eye movement experiment
2.3 眼动数据分析
在完成极光亚暴事件的眼动数据采集之后,首先对不同亚暴发生阶段(增长相onset、膨胀相expansion 和恢复相recovery)的眼动注视位置分别在x坐标轴下和y坐标轴下进行了统计分析。所使用的统计指标为平均值、标准差、方差以及偏差数。其中偏差数为平均值与方差的比值,数值区间为[0,1]。
眼动数据的统计结果如图3 和图4 所示。从图中可以看出,无论是在x坐标轴下还是y坐标轴下,眼动注视点位置的平均值和偏差数从增长相到膨胀相呈现增长的趋势,在恢复相又逐渐减小。从方差和标准差上看,膨胀相的数值较小,也就说明在观察膨胀相时,被试者的注视点位置较为集中。膨胀相中极光图像上呈现的亮斑较为明显,被试者的注意大部分会集中在有亮斑的区域。而增长相和恢复相中极光椭圆上的亮度分布较为均匀且亮斑不明显,被试的注视点较为分散,因此增长相和恢复相中极光图像注视点位置的方差和标准差会大于膨胀相中的极光图像注视点位置的方差和标准差。
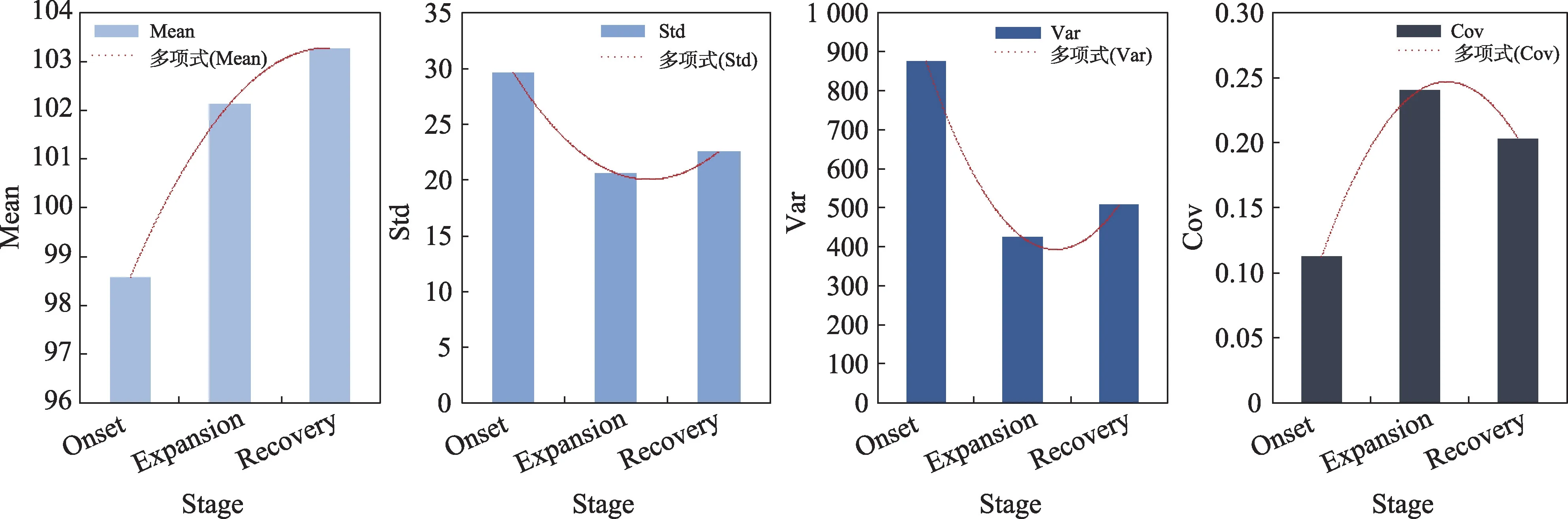
图3 x 坐标轴下的眼动注视位置统计图Fig.3 Statistics results of eye movement fixation position under x coordinate

图4 y 坐标轴下的眼动注视位置统计图Fig.4 Statistics results of eye movement fixation position under y coordinate
该统计结果说明,从整体上看,被试者在观察亚暴序列时,在不同的亚暴发生阶段其视觉认知存在明显的差异。与此同时,发现当不同的被试者在观察同一亚暴序列时,每位被试者的眼动信息在不同的亚暴发生阶段同样存在这种差异。这与原始亚暴序列在图像上所表现出来的特征是一致的。因此,对任何一个亚暴序列,使用单一被试者的眼动信息作为先验加入提出方法中的思想是可行的。
3 基于眼动信息和序列指纹的极光亚暴事件识别方法
本文方法主要分为两部分:第一部分为基于眼动信息的序列指纹获取模块,该模块基于原始UVI图像和其对应的眼动注视图,利用一个深度学习网络对亚暴序列中的图像进行分类预测得到其序列指纹。第二部分为序列指纹识别模块,该模块通过设计合理的序列指纹识别策略实现对亚暴事件的识别。算法框图如图5 所示。
3.1 基于眼动信息的序列指纹获取模块
基于眼动信息的序列指纹获取模块由一个基于分类任务的深度学习网络实现。综合考虑网络模型的速度和精度,本文采用EfficientNets[33]系列网络实现对UVI图像的精确分类。
如图5 所示,在训练阶段,不考虑图像所属的序列,将其与对应的眼动注视图同时打乱输入深度分类网络中进行训练,在训练过程中,使用交叉熵作为Loss函数,如式(1)所示。

图5 本文方法的流程图Fig.5 Flowchart of proposed method

其中,n代表分类的总类别数,本实验中设n=2 。GT代表真实标签,CLS代表分类的结果。
在测试阶段,按照亚暴序列中图像的顺序依次将其输入网络中进行测试,输出的分类预测标签则可组成其序列指纹。
3.2 序列指纹识别模块
根据亚暴事件发生不同阶段的特征可知,相比膨胀相中的图像,增长相与恢复相中的图像特不明显。根据2.1 节对极光图像的标记,任何一个亚暴事件的序列指纹都应该符合0-1-0 这样的规律。因此在利用每个图像的分类预测标签得到每个亚暴事件序列指纹的前提下,本文提出了两种序列指纹识别策略实现对极光亚暴事件的识别。
如图6 以及算法1 所示,策略1 要求序列指纹必须完全服从亚暴发生的规律。也就是说必须出现膨胀相、增长相与恢复相3 个阶段(0-1-0 模式),且增长相与恢复相中全部图像的分类预测标签必须为0,膨胀相中全部图像的分类预测标签必须为1。

图6 两种序列指纹识别策略示意图Fig.6 Diagram of two sequence fingerprint recognition strategies
算法1序列指纹识别策略1

在策略2 中,只要符合以下3 种情况的序列指纹均可被认为符合亚暴发生的规律:
(1)序列指纹的模式保证有从增长相到膨胀相再到恢复相的转换,增长相与恢复相中的全部图像的分类预测标签必须为0,并且膨胀相中全部图像的分类预测标签的容错率为10%。
(2)序列指纹的模式保证有从增长相到膨胀相再到恢复相的转换,但仅保证膨胀相的前一个图像的分类预测标签与膨胀相的后一个图像的分类预测标签必须为0。同时膨胀相中全部图像的分类预测标签的容错率为10%。
(3)序列指纹的模式保证有从增长相到膨胀相的转换,并且在膨胀相中全部图像的分类预测标签的容错率为10%。具体的实现流程如算法2 所示。
算法2序列指纹识别策略2

4 实验结果与分析
4.1 实验数据和环境
本文在相同的实验条件下构建了3 种不同输入条件下实验:第一种输入为UVI 图像。第二种输入为极光卵边界分割结果、UVI 图像和眼动注视图。UVI图像背景具有多变性和干扰性,加入极光卵边界分割结果是为了抑制UVI 图像数据中背景干扰。第三种输入为UVI 图像和眼动注视图,其目的是为了验证眼动信息的加入是否提高了分类网络的性能。
由于UVI 图像为灰度图像,而深度学习网络更加适用于三通道的图像。因此,首先将UVI 图像进行复制,拼接成一个三通道的图像。即每一个通道都是原始的UVI 图像。这样得到的UVI 图像则不会缺失或增加信息。对于另外两种输入数据,同样进行了通道拼接的操作。图7 中的第二行是用UVI 图像、极光卵边界分割结果以及眼动注视图拼接的图像,其中极光卵边界分割结果由目前精度最高的极光卵分割算法[34]得到。第三行是将UVI 图像与眼动注视图2:1 进行通道拼接的图像。

图7 不同输入数据的示例Fig.7 Samples of different input data
本文中所有实验均是在NVIDIA GeForce GTX 1070Ti 显卡上进行,并且实验环境为CUDA 10.0 +CUDNN v7.6.5+Python 3.6+Pytorch 1.2.0、torchvision 0.4.0。本文实验部分所有表格中最好的实验结果显示为加粗且斜体,次好的实验结果显示为加粗。
4.2 基于眼动信息的序列指纹获取模块的消融实验
利用分类准确率对基于眼动信息的序列指纹获取模块中深度学习网络预测的分类结果进行验证。网络的输入分别为图7 所示的3 种不同类型的输入数据。同时,考虑到速度和精度的平衡,仅使用Efficientnets 系列b0~b3 这4 个网络进行实验。由于这4个网络的结构从简单到复杂,网络达到收敛状态时训练的次数是不一致的。因此,实验也同时对比了不同网络在20 次和40 次迭代次数下的实验结果。网络训练采用随机梯度下降(stochastic gradient descent,SGD)优化算法,批处理大小(batch size)设置为4,学习率设置为0.01。
实验结果如表2 所示,从整体上看,在使用b2 网络、迭代次数为40 且UVI 图像和眼动注视图作为输入数据的条件下,网络的性能最佳。

表2 序列指纹获取模块的消融实验对比结果Table 2 Ablation experiment results of sequence fingerprint acquisition module
从输入数据上来看,同时使用UVI 图像和眼动注视图数据时,除了b0 网络,其他的网络在不同的迭代次数下均比使用另外两种数据作为网络输入的效果好。由于b0 网络的结构比较简单,使用40 次的迭代次数对其进行训练会产生严重的过拟合现象[35],从而导致其分类准确率大幅下降。另一方面,原始的UVI图像相比其他两种输入图像内容较为单一,对于较为简单的b0 网络而言,其能够较好地学习UVI 图像之间的差异,而对于加入眼动信息和分割信息的这两种内容丰富的图像而言,其学习能力则会下降。同样,虽然分割结果图在一定程度上起到了抑制背景干扰的作用,但由于部分图像的分割结果不精确,使得边界的变化特征较弱,网络可能无法完全学习到其变化模式,从而使得其分类精度不如仅使用UVI图像和眼动注视图数据作为输入时的效果。
对比不同的网络结构,无论在哪一个迭代次数下将UVI 图像和眼动注视图作为输入数据的b2 网络取得了最好的分类准确率并且其在不同的迭代次数下的分类准确率非常接近。这也就说明,相对于其他的网络,该网络更加适合UVI 图像的分类任务,且其稳定性较高。
4.3 序列指纹识别模块的消融实验
本节实验条件与4.2 节实验条件一致,为了验证在不同模型、输入、策略下的序列指纹识别准确率,实验结果如表3 所示。其中,Acc-st1 和Acc-st2 分别代表两种不同的序列指纹判别策略的准确率。从整体上看,除了b0 网络之外,无论是在哪种策略和网络模型下,使用UVI 图像和眼动注视图作为输入均取得了最高的识别准确率。该结果与4.2 节的网络分类准确率是一致的。
从表3 中可以看出,以策略1 为判别准则的亚暴事件识别准确率均低于以策略2 为判别准则的亚暴事件识别准确率。亚暴恢复相的形态多变,很多情况下是难以判定其具体消散时刻的。因此,根据与空间物理学家的讨论,认为只要在某个极光图像序列中出现增长相到膨胀相的转换,并且膨胀相可以持续一段时间,就可认为该序列是亚暴序列。这与策略2 中所提出的3 种情况的判断准则是一致的。因此,策略2 所提出的判别准则是完全符合客观知识的,可以作为亚暴事件识别的客观准则对其进行有效判别,其对应的识别准确率也是可靠的。
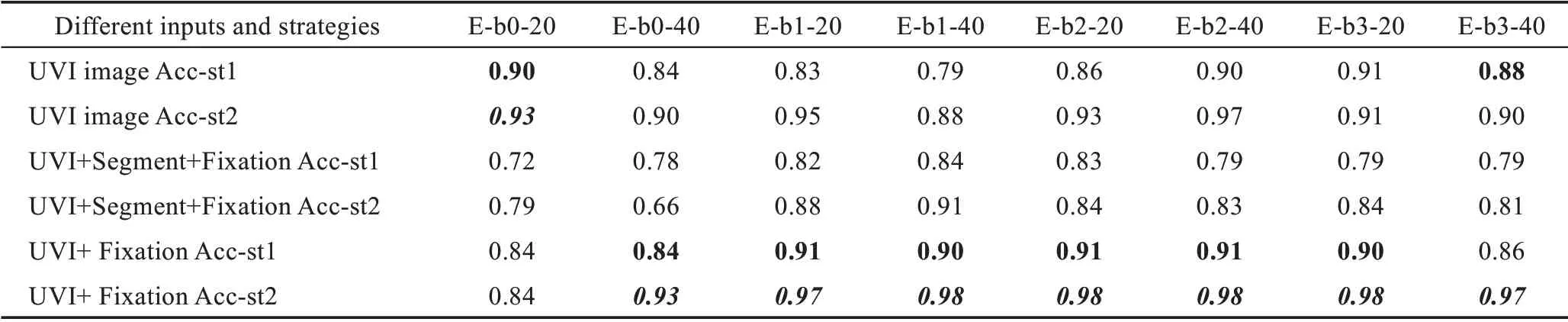
表3 序列指纹识别模块的消融实验对比结果Table 3 Ablation experiment results of sequence fingerprint recognition module
4.4 与不同亚暴序列识别方法的对比实验
为了验证文本方法的有效性,与近年来两个亚暴事件识别方法[11-12]进行对比。这两个对比方法均是基于UVI 图像数据所提出的亚暴序列识别方法且以Liou[8]所标记亚暴事件为真实标签计算识别准确率。杨秋菊等人[11]所提出的方法与文本所使用的数据一致。具体的实验结果如表4 所示。表中Ours-st1 与Ours-st2 分别为b2 网络在不同亚暴序列指纹判别策略下的结果。从表中可以看出,本文方法性能优于其余两种对比方法。

表4 与其他方法的对比实验结果Table 4 Comparative experiment results with other methods
杨秋菊等人[11]所提出的方法识别准确率较低,是因为其方法受限于UVI 图像对极光卵的分割的结果。在分割效果准确率不高的前提下,后续借助物理特征对亚暴序列进行识别的误差较大。SCLSD 方法[12]通过分离亚暴序列的运动特征和背景特征,结合亚暴发生时相关物理指标的变化对1996—2008 年南北极全部的亚暴序列进行了检测。对比杨秋菊等人的方法,该方法大大提高了亚暴序列识别的准确率,但该方法的准确率略低于本文方法,并且其实现过程相较于本文方法也较为繁琐。
4.5 基于不同输入数据的外推实验
在本文方法中,每一个极光亚暴序列都需要其对应的眼动信息(眼动注视图)辅助。这样的设定使得算法有一定的局限性且并不能减轻专家们的负担。基于此,本文设计了基于不同输入数据的外推实验。该实验使用包含眼动信息的数据训练网络,同时仅使用原始的亚暴图像序列进行测试,以此检验所提出方法对数据的鲁棒性。
实验结果如表5 所示。表5 的前两行是基于眼动信息的序列指纹获取模块中UVI 图像的分类准确率,后四行是序列指纹识别模块中根据不同序列指纹策略所得到的亚暴事件识别的准确率。从结果可以看出,当训练与测试数据的类型不一致时,无论其分类结果还是事件识别结果均差于使用同一类型的输入数据进行训练和测试的结果。但当使用原始亚暴序列对使用包含眼动信息的数据训练好的网络进行测试时,其分类准确率在90%左右。

表5 外推实验对比结果Table 5 Extrapolation experiment results
对于亚暴事件识别任务,不同模型准确率降低程度不同。有部分网络的亚暴事件识别准确率在80%以上,并且性能最好的b3 网络得到的事件识别准确率为86%。也就是说,即使在训练和测试时数据信息缺失且差异较大的情况下,本文方法识别效果也与其他亚暴识别算法差距不大,在可接受的范围内。
5 结束语
为了有效利用空间物理专家在识别极光亚暴事件时的视觉认知信息和亚暴发生时的物理特征,本文提出了一种基于眼动信息和序列指纹的极光亚暴事件识别方法。该方法通过对UVI 图像分类标记得到亚暴事件的序列指纹,从而将序列识别任务转化成简单的二分类任务,在一定程度上降低了序列识别任务的难度。同时,充分利用专家的眼动注视图以及设计了合理的序列指纹判别策略提升了现有亚暴事件识别算法的准确率。
但眼动注视图的获取是非常不易且繁琐的,为了减少在采集眼动信息时专家们的劳动,拟设计一个端到端的深度学习网络,将眼动注视图预测与本文算法进行融合,从而进行多任务并行训练。也就是说,对于任何一张UVI 图像而言,网络不仅能够得到预测的眼动注视图,同时还可以得到其序列指纹,从而在不需要额外采集专家眼动信息的条件下提高所提出方法的鲁棒性,实现真正意义上的亚暴序列自动化检测。
