面向图像检索的热力特征描述子构造与匹配
2023-01-17刘天宇骆顺利
刘天宇,贾 迪,骆顺利,王 凯
辽宁工程技术大学电子与信息工程学院,辽宁葫芦岛125105
基于内容的图像检索任务(content-based image retrieval,CBIR)长期以来一直是计算机视觉领域重要的研究课题,它充分发挥了计算机长于处理重复任务的优势,将人们从需要耗费大量人力、物力和财力的人工标注中解放出来,已成为海量图像库检索的主要技术手段。
特征匹配是基于内容的图像检索关键环节,早期依赖人工设计特征,如尺度不变特征变换(scaleinvariant feature transform,SIFT)[1],常采用KD 树[1]或词汇树[2]的最近邻搜索算法[1]进行特征匹配。加速鲁棒特征算法(speeded up robust features,SURF)[3]采用积分图来简化高斯函数的二阶偏导数,以此提高了匹配速度。受SURF 启发,Rublee 等人[4]给出一种面向快速旋转变换的描述符构造方法(oriented FAST and rotated BRIEF,ORB),用于加速特征提取环节。Leutenegger 等人[5]引入抗缩放和旋转的二进制描述符BRISK(binary robust invariant scalable keypoints),BRISK 和ORB 都具有较快的特征提取速度。Choi等人[6]对BRISK 描述子进行改进,结合颜色特征给出一种面向图像检索的二进制描述子,与BRISK 算法相比,降低了近一半的配准时间,配准率近84%。Dang等人[7]提出一种几何一致性约束的尺度与旋转不变特征提取方法,并将其应用于文档图片检索的任务中,并与SIFT、SURF、ORB 等方法进行了对比,该方法的检索准确率为90.8%。
近年来,基于深度学习的图像检索正逐步成为研究热点,尽管基于卷积神经网络(convolutional neural networks,CNN)的全局描述符在中小型数据集的检索任务中取得了良好表现,但在大规模数据集条件下(如噪声、遮挡、光照变化)可能会降低其性能。Yi等人[8]提出一种端到端的框架(learned invariant feature transform,LIFT)来检测图像中的关键点、主方向与构造特征描述符。Zagoruyko 等人[9]提出Siamese Network,直接从基于CNN 网络学习普适性相似度函数,以此完成图像的匹配和检索。Gordo 等人[10]提出基于全局描述符的深度图像检索方法(deep image retrieval,DIR),该方法中的特征描述符为2 048 维,采用并行搜索的方式实现特征检索,该方法在检索含有类似场景的数据时易出错。洪睿等人[11]通过深度卷积特征构建匹配核函数,在鼓励相关图像间产生匹配对的同时,抑制不相关图像间的匹配对个数,从而提高检索准确率。周书仁等人[12]提出了一种结合卷积神经网络和哈希算法的深度网络结构,用于大规模图像检索。Noh 等人[13]提出了一种适用于大规模图像检索的深度局部特征描述子(deep local features,DELF),只需在数据集上进行图像级标注训练,同时还给出基于注意力机制的关键点选择方法,解决了从语义上识别对图像检索有用的局部特征,该框架可用于图像匹配,可替代其他关键点检测器和描述符,实现更为精确的匹配。Yang 等人[14]提出一种动态均值模块(dynamic mean with whitening ensemble binarization,DAME WEB),可以使神经网络在池化阶段动态学习图像的特征映射,以生成适合地标检索的全局描述符。Radenović等人[15]的Finetuning CNN 通过利用3D 模型中可用的几何图形和摄像机位姿来选择正负样例,并且提出一种参数可训练的池化层来提高检索性能。Wang 等人[16]提出了一种基于残差模块的残差注意网络,通过深度残差学习产生注意感知特征。Liu 等人[17]提出了一种双注意模型,该模型由两种注意机制生成两段特征向量。Ouyang 等人[18]同时利用了空间注意子网络和时间注意子网络来提取更好的特征表示。此外,一些学者将语义分割方法应用到图像检索的任务中,Zhan 等人[19]提出了语义层次的属性卷积网络,该模型具有三层特征表示,用于区分图像特征表达,并计算损失函数减少属性间的预测误差。Xu 等人[20]提出了一种简单有效的基于语义分割的加权聚合方法用于图像检索,通过选取各语义部分的加权区域生成特征表示。Furuta 等人[21]提出基于全卷积网络的多标签检索方法,通过语义分割图提取区域卷积特征用于多标签检索。
由此可见,现有方法主要结合注意力机制和语义分割方法去克服图像中的局部相似性区域,以此提高检索精度。基于该思路,本文提出一种面向图像检索的热力特征描述子构造与匹配方法。与上述方法不同,将图像中的各部分语义属性与提取到的热力特征相结合,更好地区分图像子类别间细微的局部差异,完成如下工作:(1)对语义分割网络热力特征进行分析,提出采用语义约束减少因相似性局部特征而产生的误匹配结果,给出热力图约束匹配思路,并基于此提出一种新的匹配框架。(2)通过深度学习方法得到图像深度特征描述子,结合语义分割网络得到的类别信息以及热力值信息生成特征描述向量,根据该特征描述向量本文首次提出KD 复合树结构,并利用该结构实现图像特征匹配,从而提高特征检索速度与准确率。
1 本文方法
本章给出算法的基本原理和实现过程。整体处理流程如图1 所示。首先,提取SegNet[22]语义分割网络编码部分最后一层卷积层尺寸为14×14×512 的特征图,利用梯度得分获取特征图每个通道的权重,通过线性融合的方式,在通道维度上加权求和获得尺寸为14×14 的map,将该map归一化并通过双线性插值方式构造对应的热力图。其次,利用DELF 算法提取维度为40 的特征描述子,结合语义分割网络得到类别信息和热力值信息生成42 维特征描述子,基于该描述子构造KD 复合树,最后通过BBF(best bin first)[1]和随机抽样一致算法[23]实现匹配与检索。

图1 本文方法流程Fig.1 Method flow chart of this paper
1.1 语义分割网络热力特征分析
选择SegNet 作为本文方法中的语义分割模块,SegNet为对称网络结构,以位于中间的池化层(pooling)和上采样层(upsampling)为分界线,编码器和解码器均由卷积块组成,每个卷积块包括2 或3 个卷积层、BN 层以及ReLU 激活层。编码部分(encoder)通过卷积获得图像高维特征,在提取特征的同时通过池化操作降低图像尺寸,解码部分(decoder)采用反卷积和上采样的方法完成语义分割。反卷积使图像经过分类后的特征得以重现,上采样使图像尺寸增加,最后将输出的值传送给Softmax 层,输出不同分类的最大值,获得最后的语义分割结果。
为了更好地分析图像的热力特征,需要对SegNet 网络进行可视化操作,本文在文献[24]基础上改进,以观察图像在特定卷积层的特征图。将给定图像x进行预处理ε(x),该预处理函数调整输入图像尺寸为224×224,并将RGB 转换成BGR 排列,并对BGR 通道每个像素点减去训练集图片的三通道像素的平均值,将预处理后的图像x输入SegNet 神经网络模型,从起始层号st开始到截止层号sp以步长S选取特定卷积层神经元放入集合O,利用隐藏层神经元特征图可视化方法p层级展示神经元集合O,获取可视化特征图。隐藏层神经元特征图可视化方法p为绘制图像经过神经网络的前向计算在每个卷积层中神经元的激活值。SegNet网络可视化算法如下:

其中Nl表示第l层的神经元,图2 是SegNet 网络编码部分最后一个卷积层的可视化特征图。

图2 SegNet网络编码部分最后一个卷积层可视化特征图Fig.2 Visualized feature map of last convolution layer in coding part of SegNet
通过上述可视化方法发现SegNet 网络编码部分最后一层卷积层所得到的特征图具有最强的空间信息和语义信息。为了获得图像对输出类别贡献度最高的部分,提高图像检索时特征匹配的准确率,本文提出通过特征图获得对应热力图的方法,首先计算特征图对预测类m的权重:

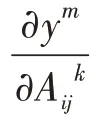

这里得到的map大小为计算公式中Ak的大小(14×14),如图3(a)所示,使用ReLU 激活函数的原因是希望保留对当前类别有正面影响的像素值,将得到的map归一化如图3(b)所示,采用双线性插值的方式放大到原图尺寸以此得到图像对应的热力图,综上提取热力图的步骤如下:
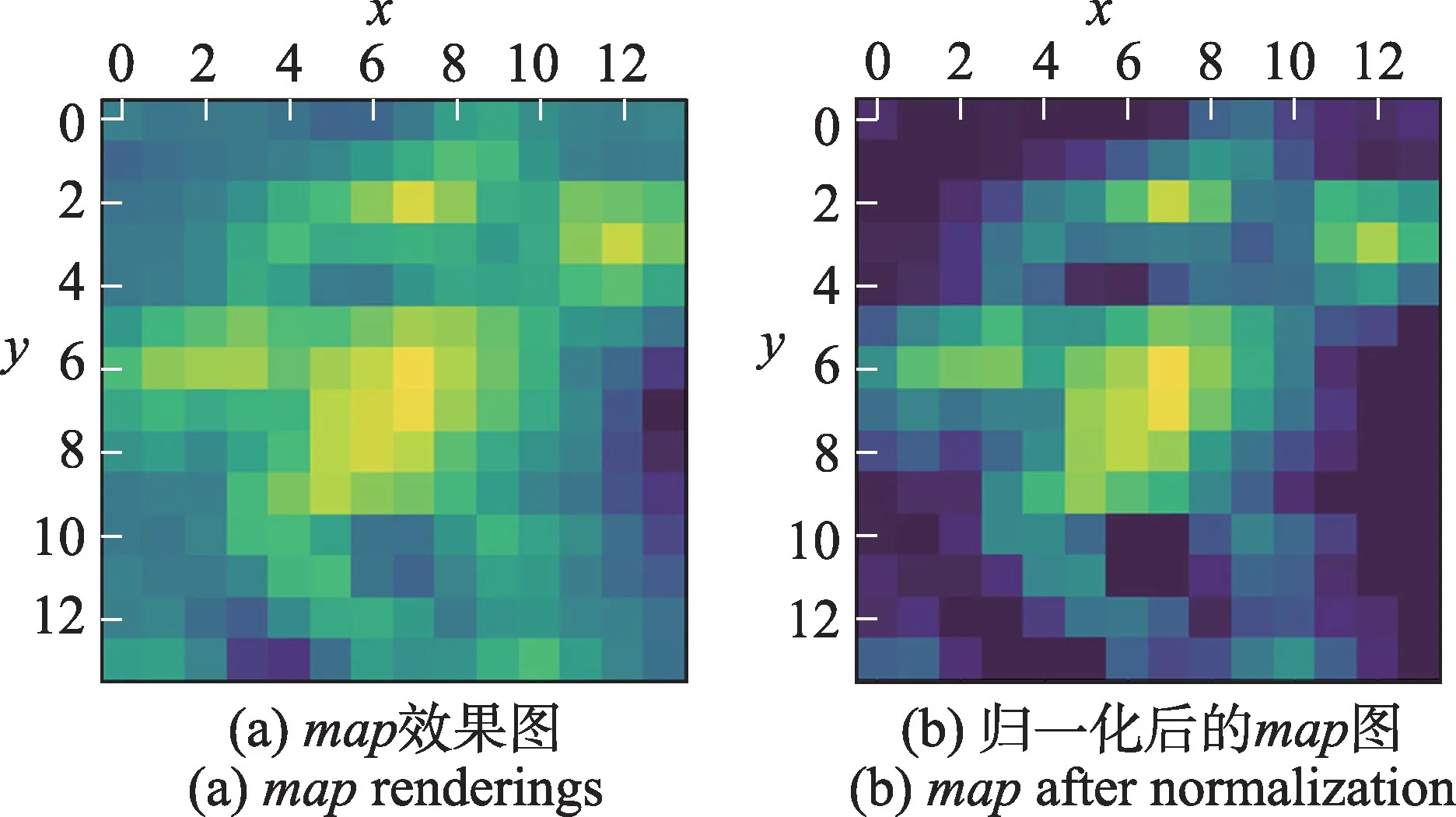
图3 可视化图像Fig.3 Visualization image
输入:SegNet 神经网络模型N,输入图片X,特征图提取方法T。
输出:热力图H。
1.将X输入SegNet 神经网络模型N。
2.提取需要可视化的特征层l,获得特征图。

4.通过线性融合的方式,在特征图的通道维度上加权求和,获得尺寸为14×14 的map。
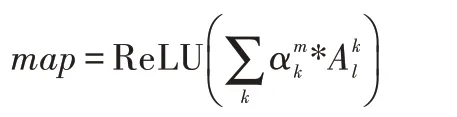
5.对该map归一化,并通过双线性插值的方式放大到原图尺寸。
6.返回热力图H。
如图4 所示,热力图中的不同颜色区域反映了输出类概率的贡献度,其中位于中间部分的三扇窗户是整张图像中最重要的特征区域,其次才是墙壁等一些其他特征。热力特征可以为后续特征描述子匹配起到约束作用,以此减少因局部相似性区域或重复纹理特征产生的误匹配问题,提高图像检索的准确率。

图4 目标图像与热力图Fig.4 Target image and heat map
1.2 KD 复合树构造与匹配
选择DELF 作为本文方法的特征提取模块,DELF 包含两部分:局部密集特征提取和关键点选择。局部密集特征提取DELF 使用深度残差网络ResNet50[25]的conv4_x 层输出14×14 的特征向量,利用加权求和生成1×40 维特征向量,损失函数采用的是标准交叉熵损失;关键点选择是通过训练一个带有注意力的地标分类器来测量局部特征之间的相关性。注意力网络由两层CNN 网络和softplus 激活层组成,利用加权的求和池化对特征进行处理,其中池化的权重由注意力网络获得。
由图1 可知,图像经过DELF 特征提取阶段获得维度为40 的特征描述子,将该描述子进行扩充,增加图像对应的语义信息和热力值信息,因此该特征描述子将增加两个维度达到42 维。
如图5 所示,其中D∈Rn为DELF 提取的40 维特征向量,V2∈Rm为在D∈Rn的基础上将第41 维和第42 维置为0 生成的向量,V1∈Rm的前40 维值为0,V1、V2维度相同,采用向量拼接的方式逐个位相加生成42 维特征向量V3∈Rm。

图5 特征向量维度拼接Fig.5 Feature vector dimension splicing
其中第41 维信息为通过SegNet 得到的类别信息,利用Softmax 分类器得到每个像素在所有类别中的概率,如式(3)所示:
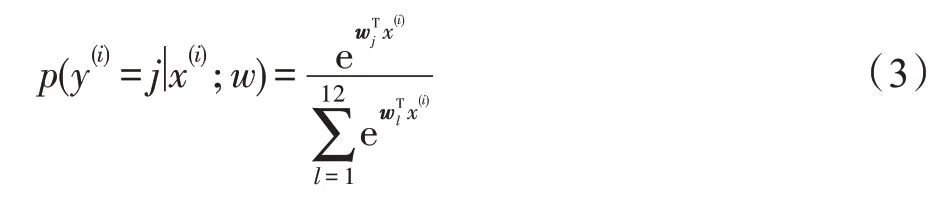
其中,y为类别标签,x为输入的参数,w为模型参数。SegNet 网络训练分类A个类别,类别A为a1,a2,…,an(0 <n≤9),对应的值为1,2,…,9。为了减少局部相似性区域或重复纹理产生的误匹配问题,拟通过热力区域约束匹配范围,提高检索的准确率。如图6 所示为本文通过1.1 节方法中ReLU 激活函数得到的热力区域。由图6(a)可见,主要特征集中在人面部的热力区域上;图6(b)中,特征区域集中在车辆轮胎的热力区域位置上。由此可见,热力区域可以作为同类事物的特征区域,因此采用结合热力信息生成特征描述子可以更好地约束匹配范围,从而提高配准率和检索精度。

图6 热力特征区域Fig.6 Thermal characteristic regions
第42 维信息为通过1.1 节方法获取的热力值,根据图3(b)获得可视化图像的灰度图,如图7 所示。灰度取值范围为(0,255),灰度值越大颜色越亮,则该区域越“热”,采用式(4)以灰度值为索引将其映射至彩色空间中,从而实现热力图,其中,max为灰度最大值,min为灰度最小值。为了更好地突出图像热力部分,本文结合式(4)将热力值信息分为两类,如式(5)所示,其中Gray(x,y)为灰度值信息,mi(i=1,2)为分类结果。将所得热力值信息添加到特征描述符中生成42 维特征描述向量。
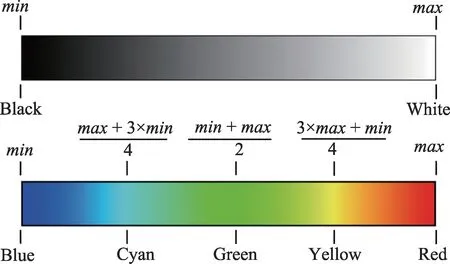
图7 热力值范围Fig.7 Values range of heat map

采用DELF 卷积神经网络提取特征描述子,通过KD 树的最近邻搜索及随机抽样一致算法进行特征匹配。KD-Tree 是k维二叉索引树,主要用于检索多属性数据或多维点的数据。以上述方法为基础,本文提出一种复合树结构,如图8 所示。该结构由一个KD 复合树和三个关键参数构成,根据特征描述向量中第41 维的类别信息C1分为b1个Node1 节点,根据第42 维热力值信息C2分为b2个Node2 节点,深度参数d指定树的深度,KD 复合树的每个Node2 节点都包含一个特征集,该特征集由KD 树组织,因此通过KD 复合树匹配找到Node2 节点时,可将Node2 节点转换为标准的KD 树进行匹配,有效定位匹配特征。

图8 KD 复合树结构图Fig.8 KD compound tree structure diagram

对于Node2 中的特征描述子,首先确定其split域,取前40 维数据计算出40 个方差,挑选方差中最大值对应的维度即为split域值。

Node2 中的数据按其第split维值排序,位于中间的数据点被选为Node-data,将小于Node-data[split]的数据点dleft划归左子空间Left_Range,大于Nodedata[split]的数据点dright划归右子空间Right_Range,以递归的方式对左右子空间重复上述过程,得到下一级子节点,直到数据点集FS为空则完成KD 复合树构造。KD 复合树构建算法如下所示:


将BBF 近邻搜索算法与KD 复合树相结合进一步提高匹配效率,由于在KD 树的基础上加入了最近邻搜索算法所得到的优先队列,在形成搜索队列的同时可以同步形成优先队列,在回溯查找的过程中能够按照优先队列来进行查找,可避免重复路径搜索过程,进一步提高搜索效率。改进的KD 复合树BBF 最近邻搜索算法如下所示:


2 实验结果与分析
2.1 实验数据集
为了验证本文方法的有效性,采用Python 作为开发工具,CPU 主频为2.2 GHz,GPU 为GTX1060,内存8.00 GB,将本文方法与传统方法CONGAS[26],基于深度学习的方法DIR、DELF、Fine-tuning CNN、DAME WEB 和D2-Net[27]进行比较,以验证本文方法的有效性。在Oxford5K[28]与Paris6K[29]数据集上进行测试:
(1)Oxford5K 数据集。该数据集包含5 063 幅图像和17 个关键字,Philbin 等人利用这17 个关键词在Flickr 上检索相关建筑物,共有11 种建筑物被检索到,每种建筑物对应5 幅查询图像,因此共有55 幅查询图像。
(2)Paris6K 数据集。与前面所提到的Oxford5K数据集相同,该数据集由Philbin 等人在Flickr 上检索关键字,检索并获得有关巴黎地标建筑物图像。该数据集共有6 412 幅,但是因为数据损坏等问题,实际可用的图像有6 392 幅。
(3)Google-Landmarks 数据集。本文训练使用Google-Landmarks 数据集,该数据集由Noh 等人基于Zheng 等人[30]给出的算法构建而成,并通过Gordo 等人[10]提出的方法去除与Oxf5K/Par6K 重叠部分,该数据集包含来自586 个地标的140 372 张图像。
同时本文还使用了Oxford105K 和Paris106K 数据集来测试在大规模场景中的检索情况,这两个数据集由Flickr100K 数据集通过10 万张干扰图像扩充Oxford5K 和Paris6K 得到。
此外,以上数据集中,有些数据集图像尺寸过大,因此本文约束图像大小不超过1 024×768 像素,对尺寸过大的图像进行缩小,将其降采样至1 024×768。
2.2 训练
SegNet 语义分割模块训练,输入两幅不同的图像I1和I2,首先将图像调整为480×360 像素并将其输入至前馈网络并从最后一个反卷积层提取特征,然后将提取到的特征输入至Softmax 损失函数,得到具有区分性的视觉属性特征。
DELF 特征提取模块训练类似于文献[13],输入两幅不同的图像I1和I2,首先将图像中心裁剪获得正方形图像并将尺寸缩放到250×250 像素,然后随机裁剪到224×224 像素用于训练,通过ResNet50 输出提取特征,损失函数使用的是标准交叉熵损失:

其中,y*是one-hot 编码后的真实值,1 是一个向量。注意力网络训练损失函数同样采用标准交叉熵损失,训练完成后就可以从中提取相关特征。
2.3 配准结果与分析
为了更好地比较本文方法的匹配效果,选择DELF 和D2-Net 进行对比实验,选择Oxford5K 数据集上三组具有代表性数据进行实验,实验结果如图9~图12 所示。从图9 中可以清晰地看出热力图区域可以直观地反映出目标图像的主要特征。图10(b)为使用DELF 匹配的结果,其中红色线条为误匹配结果,绿色线条为正确匹配结果,可以清楚地看到建筑物下方半圆形通道两侧和玻璃窗附近的误匹配较多,位于建筑物右上方的锥形体的误匹配结果更为明显。该象对共匹配151 对特征点,其中误匹配数量为49 对,匹配准确率为67%。图10(c)为使用D2-Net匹配的结果,可以看出受局部相似性区域的影响,匹配效果并不理想。采用本文方法获得的实验结果如图10(d)所示,受热力图约束较好地避免了上述问题。图11为尺度变化情况下的匹配结果,采用DELF 方法获得的实验结果中,天空和建筑、景物和建筑物之间存在误匹配情况,共获得188 对匹配特征点,其中误匹配特征点37 对,匹配准确率为83%,而采用本文方法的匹配结果不仅稠密度高于DELF 和D2-Net 算法,并且配准率均高于上述方法。图12 为视角变化实验结果,由于摄影角度的变化和光线强度的改变,DELF算法出现了较大面积的误匹配,下方建筑物主体特征并没有获得高分值,匹配准确率仅为26%;D2-Net算法虽然在建筑物主体部分的匹配结果优于DELF,但是受重复纹理特征的影响,产生较多误匹配,而采用本文方法的匹配结果则未出现上述问题。综合对比以上实验结果,本文算法无论在配准密度还是准确率上均有较大提升。

图9 目标图像热力图Fig.9 Heat map of target image
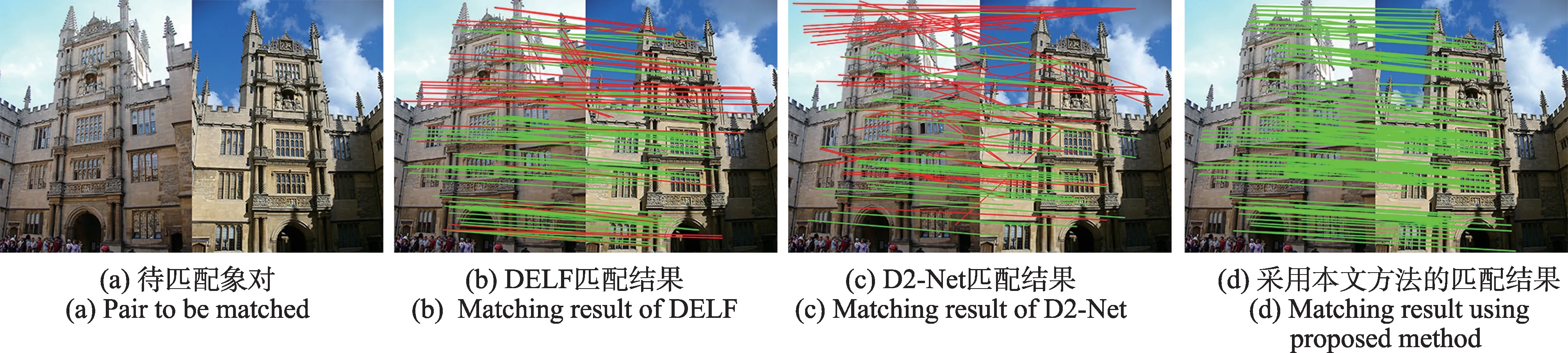
图10 匹配结果对比Fig.10 Comparison of matching results
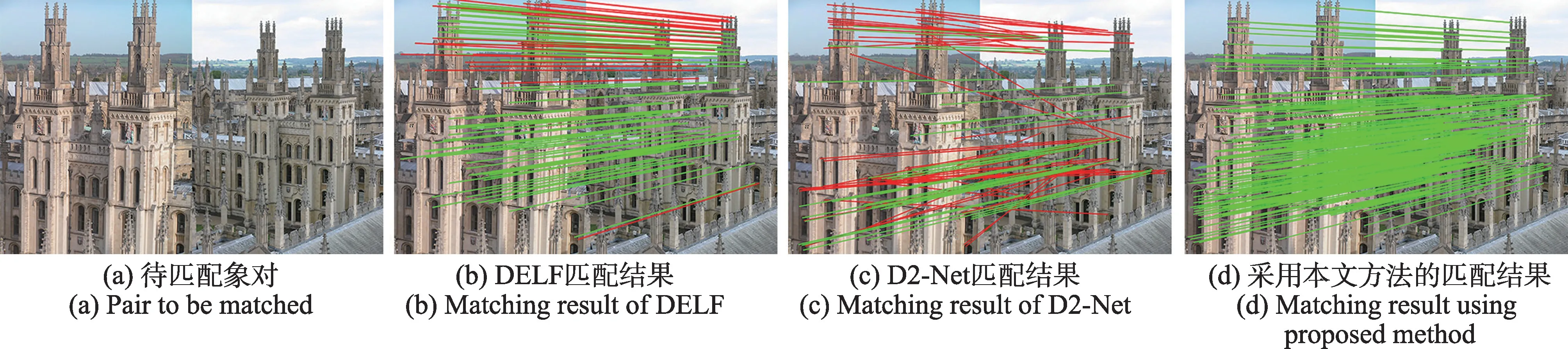
图11 尺度变换匹配结果Fig.11 Matching results of scale transformation

图12 视角变换匹配结果Fig.12 Matching results of viewing angle transformation
将DELF、D2-Net 和本文方法分别应用到5 种不同尺寸的图像上,对这三种方法的执行时间和准确度进行比较,执行时间曲线和配准率曲线如图13 和图14 所示。
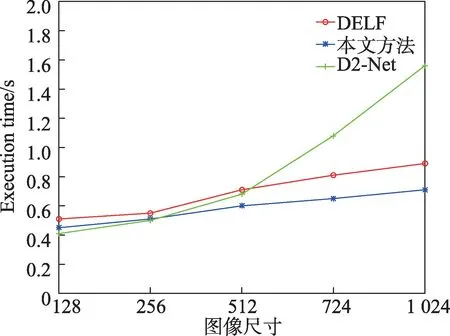
图13 DELF、D2-Net与本文方法的执行时间Fig.13 Execution time of DELF,D2-Net and proposed method
由图13 可见,DELF 方法的运行时间均高于本文方法,D2-Net 方法的运行时间虽然在图像小尺寸时优于本文方法,但随着图像尺寸的增加,本文方法的匹配时间增长缓慢,远低于D2-Net 的处理时间。图像尺寸在128~512 之间时三种方法的运行时间差距不大,而当图像尺寸增加到724~1 024 时,本文方法获得了较为明显的优势,与DELF 相比降低了近10%,D2-Net 算法的时间曲线斜率发生了明显变化,与本文方法的处理时间差距不断增加。图14 中,采用本文方法在尺寸为256~1 024 的图像上获得了较高的配准率,当图像尺寸选择在128~724 时,与DELF、D2-Net 方法相比,配准差距较为稳定。当图像尺寸增大到1 024 时,本文算法的配准率更高,较DELF 和D2-Net 方法分别提高了12%和16%。综上,在Oxford5K 数据集上的配准实验结果表明,本文方法在时间效率和准确率上均优于DELF 和D2-Net 算法,尤其是在处理摄影角度和光线不同的图像时,配准率和配准点密度更高。
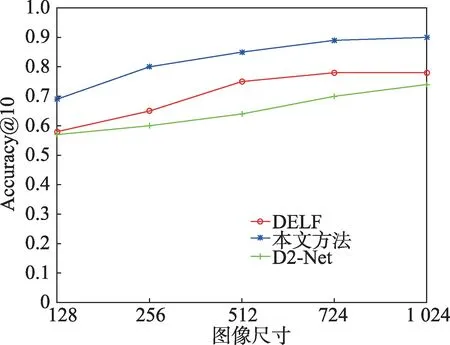
图14 DELF、D2-Net与本文方法的配准率Fig.14 Registration rate of DELF,D2-Net and proposed method
2.4 检索精度对比与分析
(1)检索精度。常采用平均检索精度(mAP)评价图像检索系统性能,定义为:

式中,M为查询集的大小,AP是每幅图像的平均相似度,计算方式为:
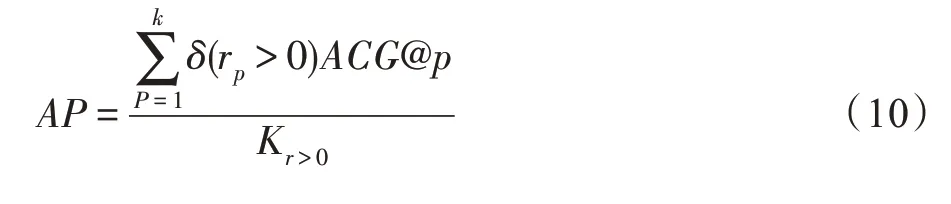
其中,ri为相似度级别,通过两幅图像之间共有的标签数来衡量,最大值为查询图像与数据库中图像的最大相同标签数,最小值为0。δ为指示函数,在相似度级别p所返回图像数量(rp)大于0 时,δ取1,否则取0。ACG@p为返回前p个图像的平均相似度,定义为:

式中,r(i)为第i个返回图像和查询图像之间的共同标签数。
将本文方法与传统方法CONGAS,基于深度学习的方法DIR、DELF、Fine-tuning CNN 和DAME WEB 进行比较。基于平均精度(mAP)评估检索性能,表1 为采用以上方法在4 个公共数据集上进行的检索精度评估结果。
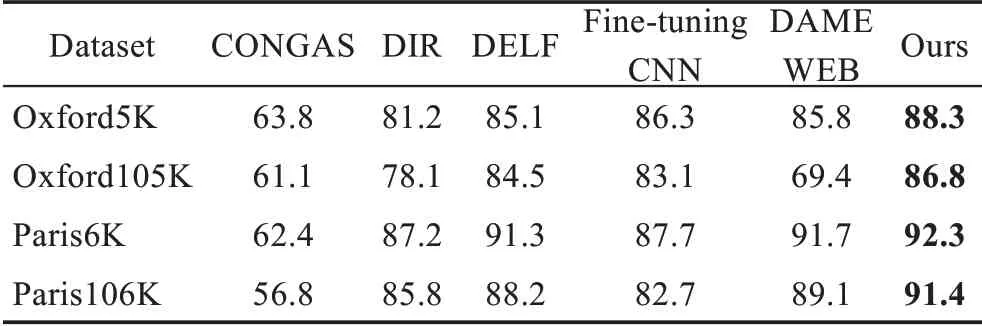
表1 检索精度评估Table 1 Evaluation of retrieval accuracy 单位:%
CONGAS 利用传统手工制作特征进行图像检索,虽然取得了较好的结果,但与基于深度学习的方法相比,存在不小的差距。DIR、DELF、Fine-tuning CNN 和DAME WEB 为基于深度学习的方法,其平均精度优于传统方法,由于本文方法结合了语义网络中的热力值信息,在Oxford5K、Paris6K、Oxford105K和Paris106K 数据集上的平均精度均优于以上方法,验证了本文方法的有效性。
(2)检索效率。为了进一步验证本文方法的有效性,针对本文方法以及对比方法在Oxford5K 数据集上进行检索效率分析。
由表2 可见,与较为传统的CONGAS 相比,本文方法虽然检索速度上降低不多仅8.6%,但mAP 值有明显的提高;相较于DIR、DELF、Fine-tuning CNN 和DAME WEB 方法的检索速度较快,分别降低39.4%、19.9%、28.8%和24.3%检索时间,并且准确率较上述方法有一定的提高,由此可见本文方法更具实用性。

表2 6 种检索方法在Oxford5K 数据集上平均检索时间比较Table 2 Comparison of average retrieval time of 6 retrieval methods on Oxford5K dataset
为了更好地验证本文方法的性能,在Oxford5K数据集上从查全率R、查准率P、P-R和mAP 曲线对各种方法进行分析,查全率如式(12)所示:

其中,tp为被检索到正样本且实际也是正样本(正确识别)数量,fn为未被检索到正样本且实际是正样本(错误识别)数量。图15(a)为不同检索方法的平均查全率,由图可见本文方法明显高于其他方法,当检索样本数为50 幅时,本文方法的查全率达到90%,而其他方法最高仅达到89%,而所有的方法随着检索图像数的增加,会逐渐将与查询图像相似的图像检索出来,因此平均查全率会逐渐上升。

查准率如式(13)所示,其中fp为被检索到正样本且实际是负样本(错误识别)的数量,由图15(b)的实验对比可见,本文方法优于其他对比方法。当检索样本数为10 幅时,本文方法对查询图像检索的平均查准率为97%,而其他方法的平均查准率都相对较低。随着检索图像数的增加,所有方法都会将与查询图像不相似的图像检索出来,因此平均查准率会有所下降。图15(c)为采用不同检索方法获得的总体P-R曲线,P-R曲线以查全率R为X轴、查准率P为Y轴形成查全率-查准率曲线。P-R曲线与X轴围成的图形面积即为平均检索精度mAP,P-R曲线围成的曲线面积越大,说明图像检索的效果越好,从图15(c)可以看出,本文方法的P-R曲线围成的面积更大。图15(d)是不同检索方法获得的mAP 曲线,可以看出本文方法的mAP 曲线图位置均高于其他对比方法,说明本文方法的检索性能更高。对Oxford5K数据集的11 种类别建筑物的检索精度进行对比,选取5 种检索方法中mAP 值较高的四种方法与本文方法进行比较,表3 为检索图像数为50 时,采用不同检索方法在11 种类别建筑物上的mAP 对比。由表3 可见,本文方法虽然在ashmolean 和radcliffe_camera 类别上的mAP 值低于Fine-tuning CNN,但是在其他9种类别的mAP 值均高于其他方法,并且平均精度和检索效率均优于其他方法,进一步验证了本文方法具有较好的检索性能。

图15 检索精度对比图Fig.15 Comparison chart of retrieval accuracy
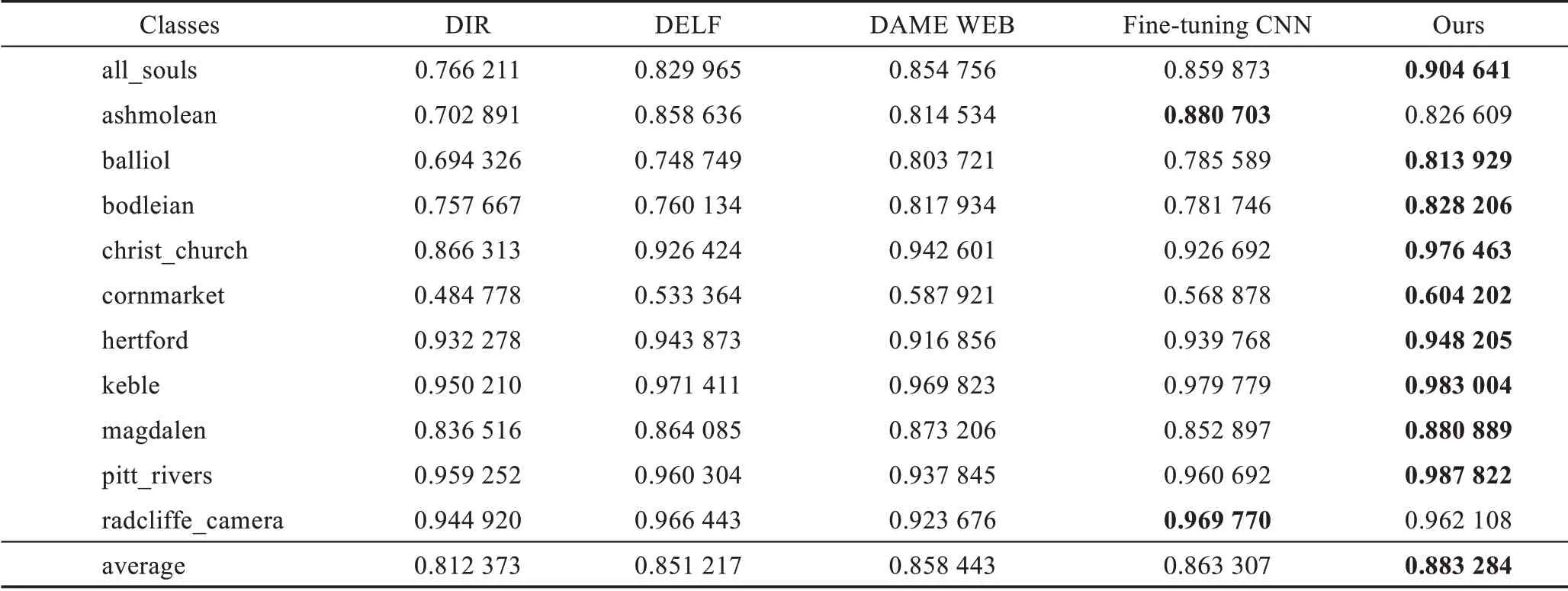
表3 11 种类别建筑物检索精度对比Table 3 Comparison of retrieval accuracy of 11 types of buildings
3 结束语
本文针对图像匹配过程中不同区域高相似性局部描述子易导致误匹配的问题,提出一种面向图像检索的热力特征描述子构造与匹配方法。通过选取语义分割网络对其卷积层进行结构可视化操作,获取图像的热力图,将学习到的特征描述子与语义分割网络得到的类别信息和热力值信息相结合,生成42 维特征描述向量,并利用该特征描述向量建立KD复合树,以此实现基于热力特征描述子的匹配,可以较好地避免不同区域高相似性局部描述子所导致的误匹配问题。实验结果证明,与其他同类方法相比,本文方法检索时间和精度上更具优势,可为后续高级图像处理提供更好的支持。
