基于Transformer的电网企业文件密级分类系统
2023-01-17杨振宇
董 添, 李 广, 杨振宇, 张 博, 于 波, 王 巍
(国网吉林省电力有限公司 党委办公室, 长春 130021)
0 引 言
作为企业的无形资产, 企业秘密包含巨大的经济利益, 它不仅是一个企业安全运营的根本, 更代表了企业的核心竞争力。只有抓好定密工作, 才能抓住保密工作的源头, 扼住保密管理过程的“咽喉”, 最大限度地确保企业秘密的安全[1], 进而保障电网运行安全, 确保企业利益不受损害。电子文档的定密本质上是根据一定的规则, 将电子文档划分到不同的类别里。不同类别的电子文档, 根据所含不同程度的领域信息, 对企业重要程度也不尽相同。比如电网企业将文档划分为核心商密、 普通商密和非秘密3种不同的类别。因此, 对企业文件密级分类即是对电子文档进行的文本分类[2]。
2014年Kim[3]运用卷积神经网络(CNN: Convolutional Neural Network)设计出针对文本的Text-CNN模型, 首次全面超越支持向量机(SVM: Support Vector Machine)。2015年Zhang等[4]在此基础上给出了关于参数调节的经验, 并强调了过滤器大小和数量是两个最重要参数。Henaff等[5]在ICLR2017上基于记忆网络(Memory Network)在问答模型成功经验基础上提出了循环独立网络(Recurrent Entity Network), Yang等[6]提出了多层注意力网络(Hierachical Attention Networks), 通过两层将字、 句和段联系, 证明了循环神经网络在文本领域的可行性。Joulin等[7]在EACL2017上提出FastText, 开启高效基于词嵌入的分类模型。目前国内在基于机器学习的文本定密方法上已有很多研究, 其经典方法主要包括: 决策树算法[8]、 朴素贝叶斯算法[9]、K近邻算法[10]、 SVM[11-12]和神经网络[13]等。近几年, 也有许多学者利用深度学习方法对文本分类进行研究, 如多层异构注意力机制[14]、 图卷积[15]、 混合注意力Seq2seq模型[16]、 半监督学习算法[17]和卷积神经网络[18]等。
目前, 国网吉林省电力有限公司均依靠保密人员对文件的密级进行标注, 标注的准确性依赖相关人员的业务素质。随着人工智能理论与技术的发展, 利用先进的机器学习方法对公司文件进行自动定密, 能减少人为因素造成的标密不准的问题, 实现文件秘密信息的智能化管理, 是未来电网公司保密管理重要的发展方向。为此, 笔者构建一种基于Transformer模型的企业文件密级分类系统, 该系统能自动提取文本密级信息的特征表达, 对企业秘密文件进行智能辅助定密的决策。
1 系统整体结构
基于Transformer的电网企业文件密级分类系统依托Word2Vec[19]的CBOW(Continuous Bag-of-Word Model)模型对涉密文件信息关键词进行词嵌入向量训练, 利用基于长短期记忆网络(LSTM: Long Short-Term Memory)[20]和条件随机场(CRF: Conditional Random Field)[21]的中文分词技术, 实现文本词句的划分, 再利用Transformer神经网络模型[22]对文本密级信息的特征进行学习, 最后利用训练好的模型进行密级信息的自动分类, 整体流程如图1所示。

图1 整体研究流程框图Fig.1 The workflow of the system
首先将现有的涉密文件库中的每个文件进行人工密级标注, 得到含有核心商密、 普通商密、 非秘密3种密级信息的文本库; 其次通过LSTM结合CRF对涉密文件库中的语料进行中文分词, 并将训练好的词嵌入矩阵集成到这些词句中; 然后将这些数据集中的句子依次输入构建好的Transformer神经网络模型, 学习密级信息的特征, 得到训练好的模型; 最后将词嵌入后的待测文本中的句子送入训练好的Transformer神经网络模型, 判定所输入的句子的密级信息特征, 从而实现对文本密级信息的分类。
2 企业文件的词嵌入向量训练
Word2Vec利用一定的方式将中文词语或句子进行多维向量的表示, 通过训练一个浅层神经网络, 将每个词语或句子都表示为一个事先设定的固定维度的词向量[23], 这些词向量能表示词语或句子之间的关系。使用普通的统计学方法, 依据表示这些词的向量空间构建词与词之间的关系。通过训练CBOW模型对其进行建模获得词与词之间关系向量。CBOW模型的网络结构是只包含一个隐藏层的多输入单输出神经网络, 网络中不包含激活函数, 根据从涉密文件库中获取的句子, 将其上下文词语输入CBOW神经网络中, 并输出对当前词语的预测信息。在训练CBOW模型过程中, 需事先对网络中的权重向量进行随机初始化。通过训练数据的不断输入, 利用随机梯度下降算法对误差不断进行反向传播更新网络中的权重参数。经多次迭代训练后, CBOW神经网络模型中输入层和隐含层之间的参数权重就是训练好的词向量, 流程如图2所示。将这些词向量集成到文件数据库中, 对相应的句子或词语进行向量化表示。

图2 CBOW模型的词嵌入流程框图Fig.2 The workflow of word embedding for CBOW model
3 基于自注意力网络的密级分类模型
经典Transformer结构包含编码器(Encoder)和解码器(Decoder)两部分。其中解码器属于生成式模型, 常用于自然语言的生成, 因此在文本密级分类的任务中只使用编码部分, 不使用解码部分。基于自注意力网络的密级分类模型包含嵌入层、 位置编码、 多头注意力机制、 残差连接以及层归一化等主要部分, 如图3所示。模型根据长度为n的输入序列X=[x1,x2,x3,…,xn]的每个单词创建3个向量, 即查询向量Q=[q1,q2,q3,…,qn]、 键向量K=[k1,k2,k3,…,kn]和值向量V=[v1,v2,v3,…,vn], 则有
利用得到的Q和K并采用相乘的方式计算每两个输入向量之间的相关性, 即计算注意力值

(4)
注意力值矩阵A中的每个元素表示对应的两个输入向量的注意力大小。矩阵A经过softmax操作, 得到归一化的注意力值矩阵A′, 其与V相乘计算每个输入向量X对应的自注意力层的输出向量O=[b1,b2,b3,…,bn], 即
O=VA′
(5)
具体地, 第i个输入对应的输出向量为

(6)
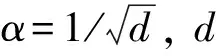

图3 基于Transformer的密点标注模型结构Fig.3 The structure of the Transformer-based secret information annotation model
4 实验结果
4.1 包含不同企业密级文件的数据库
笔者共收集了国网吉林省电力有限公司2017-2020年财务、 发展、 纪检和物资等核心商密文件95个, 发展和审计等普通商密文件67个以及各类非涉密文件60个。随机选取63个核心商密文件、 43个普通商密文件、 40个非涉密文件, 构成训练集。训练集的所有样本用于模型的训练, 将其余的32个核心商密文件、 24个普通商密文件和20个非秘密文件组成测试集, 用于模型的测试与验证。
4.2 CBOW模型和自注意力网络的参数设置
训练CBOW模型时, 将网络的输出单元设为1 000, 即每个词的嵌入向量维度为1 000。网络中所有参数均随机初始化, 学习率设置为0.015, 利用Adam优化算法, 对交叉熵损失函数获得的误差进行反向传播及梯度下降, 经100次的训练迭代, 其损失下降的曲线如图4a所示。
在训练基于自注意力网络的企业文件密级分类模型时, 首先要对所有的词进行词向量嵌入。对网络中的参数进行随机初始化, 学习率为0.022, 构建交叉熵损失函数, 并利用Adam算法优化对网络的参数进行学习训练, 经70次的训练迭代, 其每次训练的损失值如图4b所示。

图4 不同迭代次数下的损失下降曲线Fig.4 The loss reduction with the number of iterations
4.3 对企业文件进行密级分类的结果
首先对测试集中文本的词进行词嵌入编码, 然后按顺序输入到训练好的文本密级分类模型中, 每个测试文本输出3个测试分数, 按分数被判定为属于核心商密、 普通商密或非秘密。根据测试结果, 绘制3分类混淆矩阵, 如表1所示, 并以此计算模型的准确率与召回率, 结果如表2所示。

表1 模型测试的混淆矩阵

表2 模型的测试准确率和召回率
训练好的Transformer模型只有2个文件分类错误, 准确率为97.37%, 表明模型达到了较高的识别效果。召回率为98.67%, 说明模型对涉密文本的识别比较准确, 有效防止了密点信息的泄露。
5 结 语
笔者针对目前企业对文本密级进行智能化分类的需求, 提出了一种基于自注意力网络的电网企业文件密级分类系统。通过涉密文件库的构建、 文本预处理、 中文分词、 词向量构建和密级特征提取与分类等步骤, 在国网吉林省电力有限公司内部核心商密文件、 普通商密文件和非涉密文件构建的数据集上的准确率为97.37%, 召回率为98.67%, 表明模型达到了较高的识别效果, 且模型对秘密文件的识别准确, 有效防止了秘密文件的泄露。
参考文献:
[1]许琦敏. 企业商业秘密保护框架建立初探 [D]. 上海: 上海交通大学法学院, 2016.
[2]章茜, 刘厚丽. 信息时代电网企业保密问题初探 [J]. 办公室业务, 2021(2): 109-110.
ZHANG Qian, LIU Houli. On the Confidentiality of Power Grid Enterprises in the Information Age [J]. Office Operations, 2021(2): 109-110.
[3]KIM Y. Convolutional Neural Networks for Sentence Classification [J/OL]. (2014-08-25)[2021-06-09]. https:∥arxiv.org/abs/1408.5882.
[4]ZHANG Y, WALLACE B. A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification [J/OL]. (2015-10-13)[2021-06-09]. https:∥arxiv.org/abs/1510.03820.
[5]HENAFF M, WESTON J, SZLAM A, et al. Tracking the World State with Recurrent Entity Networks [J/OL]. (2016-12-12)[2021-06-09]. https:∥arxiv.org/abs/1612.03969v1.
[6]YANG Z, YANG D, DYER C, et al. Hierarchical Attention Networks for Document Classification [C]∥Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. [S.l.]: Idiap, 2016: 1480-1489.
[7]JOULIN A, GRAVE E, BOJANOWSKI P, et al. Bag of Tricks for Efficient Text Classification [J/OL]. (2016-07-06)[2021-06-09]. https:∥arxiv.org/abs/1607.01759v3.
[8]LU H, SETIONO R, LIU H. Neurorule: A Connectionist Approach to Data Mining [J/OL]. (2017-01-05)[2021-06-09]. https:∥arxiv.org/abs/1701.01358v1.
“十二五”时期,我国面临着经济发展方式转型、产业结构升级的紧迫任务,经济发达地区应该走在前列.经济发达地区在国内直至国际上具有一定影响力的传统产业将如何发展,是这些地区面临的问题.梳理发展传统产业的理论基础,借鉴国际经验,分析传统产业发展现状,有利于厘清我国特别是经济发达地区传统产业今后的发展趋向.
[9]BIJALWAN V, KUMAR V, KUMARI P, et al. KNN Based Machine Learning Approach for Text and Document Mining [J]. International Journal of Database Theory and Application, 2014, 7(1): 61-70.
[10]吴宗卓. 基于图和K近邻的文本分类算法 [J]. 微型电脑应用, 2021, 37(10): 46-49.
WU Zongzhuo. Text Classification Algorithm Based on Graph andK-Nearest Neighbor [J]. Micorcomputer Applications, 2021, 37(10): 46-49.
[11]FU J H, LEE S L. A Multi-Class SVM Classification System Based on Learning Methods from Indistinguishable Chinese Official Documents [J]. Expert Systems with Applications, 2012, 39(3): 3127-3134.
[12]WANG Z Q, SUN X, ZHANG D X, et al. An Optimal SVM-Based Text Classification Algorithm [C]∥2006 International Conference on Machine Learning and Cybernetics. [S.l.]: IEEE, 2006: 1378-1381.
[13]ZENG D, LIU K, LAI S, et al. Relation Classification via Convolutional Deep Neural Network [J/OL]. (2015-08-05)[2021-06-09]. https:∥arxiv.org/abs/1508.01006.
[14]武渊, 徐逸卿. 基于多层异构注意力机制和深度学习的短文本分类方法 [J/OL]. 中北大学学报(自然科学版): 1-9. [2021-06-11]. http:∥kns.cnki.net/kcms/detail/14.1332.TH.20211012.1131.002.html.
WU Yuan, XU Yiqing. Short Text Classification Method Based on Multi-Layer Heterogeneous Attention Mechanism and Deep Learning [J/OL]. Journal of North University of China(Natural Science Edition): 1-9. [2021-06-11]. http:∥kns.cnki.net/kcms/detail/14.1332.TH.20211012.1131.002.html.
[15]张虎, 柏萍. 融入句子中远距离词语依赖的图卷积短文本分类方法 [J/OL]. 计算机科学: 1-11. [2021-06-11]. http:∥kns.cnki.net/kcms/detail/50.1075.TP.20211012.1417.010.html.
ZHANG Hu, BAI Ping. Graph Convolutional Networks with Long-Distance Words Dependency in Sentences for Short Text Classification [J/OL]. Computer Science: 1-11. [2021-06-11]. http:∥kns.cnki.net/kcms/detail/50.1075.TP.20211012.1417.010.html.
[16]陈千, 韩林, 王素格, 等. 基于混合注意力Seq2seq模型的选项多标签分类 [J/OL]. 计算机工程与应用:1-10. [2021-06-11]. http:∥kns.cnki.net/kcms/detail/11.2127.TP.20210927.2339.016.html.
CHEN Qian, HAN Lin, WANG Suge, et al. Multi-Label Classification of Options Based on Seq2seq Model of Hybrid Attention [J/OL]. Computer Engineering and Applications: 1-10. [2021-06-11]. http:∥kns.cnki.net/kcms/detail/11.2127.TP.20210927.2339.016.html.
[17]张晓龙, 支龙, 高剑, 等. 一个半监督学习的金融新闻文本分类算法 [J/OL]. 大数据: 1-12. [2021-06-11]. http:∥kns.cnki.net/kcms/detail/10.1321.G2.20210918.1606.002.html.
ZHANG Xiaolong, ZHI Long, GAO Jian, et al. A Semi-Supervised Learning Financial News Classification Algorithm [J/OL]. Big Data Research: 1-12. [2021-06-11]. http:∥kns.cnki.net/kcms/detail/10.1321.G2.20210918.1606.002.html.
[18]顾凯文. 基于集成算法的密级文本分类系统设计 [D]. 南京: 南京邮电大学计算机学院, 2018.
GU Kaiwen. Design of Security Text Classification System Based on Ensemble Algorithm [D]. Nanjing: School of Computer Science, Nanjing University of Posts and Telecommunications, 2018.
[19]QUOC L E, TOMAS MIKOLOV. Distributed Representations of Sentences and Documents [C]∥Proceedings of the 31st International Conference on International Conference on Machine Learning (ICML). Beijing: ACM, 2014: Ⅱ-1188-Ⅱ-1196.
[20]HOCHREITER S, SCHMIDHUBER J. Long Short-Term Memory [J]. Neural Computation, 1997, 9(8): 1735-1780.
[21]JOHN D LAFFERTY, ANDREW MCCALLUM, FERNANDO C N PEREIRA, et al. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data [C]∥ Proceedings of the 18th International Conference on Machine Learning (ICML). Williamstown: ACM, 2001: 282-289.
[22]VASWANI A, SHAZEER N, PARMAR N, et al. Attention Is All You Need [C]∥ Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS). Long Beach: MIT Press, 2017: 6000-6010.
[23]KOWSARI, MEIMANDI J, HEIDARYSAFA, et al. Text Classification Algorithms: A Survey [J]. Information, 2019, 10(4): 150.
