面向英语教学的作文主题偏离自动检测算法
2023-01-17叶佩
叶 佩
(西安思源学院 旅游与融媒学院, 西安 710038)
0 引 言
虽然世界各国使用的语言各不相同, 但英语应用最为广泛。人们不仅可使用英语与不同国家的人交流沟通[1], 而且多数前沿技术的参考文献都是英文, 因此, 人类若要了解掌握更多先进的知识与技术, 就要学好英语。
近些年各种技术发展飞快, 其中包括自然语言处理和人工智能[2],运用计算机对试卷自动批改越来越完善, 并已成为教育发展的方向, 在此背景下, 英语自动评分系统应运而生。陈志鹏等[3]针对文章集合发散度的概念展开分析, 并构建了模型, 以发散度和跑题阈值关系为前提奠定了模型的基础, 以此为依据进行检测。孟超颖等[4]针对文章标题与主题关系, 对其进行计算, 检验其关联度, 同时引入聚类方法进行作文主题偏离自动检测。Liu等[5]利用Biterm LDA(Latent Dirichlet Allocation)对作文的主题和语义进行了检验, 并计算不同主题作文的最优阈值, 实现了作文主题是否偏离的判断。
虽然上述3种算法在作文主题偏离检测准确率方面取得了一定程度的提升, 但对单词和特征词两者之间的语义相似度计算需要完善。为此, 笔者提出一种面向大学英语教学的作文主题偏离自动检测算法。相比传统算法, 所提算法的检测结果明显更好。
1 自动检测算法
1.1 语义相似度计算
在计算机面对自然语言时, 不能对其进行直接理解, 所以将全部的语言通过数字化的形式进行描述, 而分布式表示的词向量模型便可解决上述问题[6]。分布式表示的词向量模型基本思想是将多数的文本语料训练保持真实性并应用, 在组词时形成低维稠密的实数向量。根据文本, 将实数向量组成的向量空间统称为分布式语义空间。其中词向量可视为分布式语义空间中的点, 词和词之间的相似性即为点和点在语义空间中的距离。以下对分布式语义空间相关的基础技术和理论进行分析。
1) 统计语言模型。统计语言模型的作用是计算对应句子的概率, 在自然语言处理技术中占有举足轻重的地位。若W是一个句子, 根据n个单词整理顺序后组成, 则句子W的概率可用w1,w2,…,wn的联合概率代表, 具体如下
p(W)=p(w1,w2,…,wn)
(1)
其中p(W)表示句子W的联合概率。
通过贝叶斯公式可将式(1)分解为
(2)
通过式(2)中的全部参数, 可获取句子W的概率p(W)。在机器学习过程中, 为求解统计语言模型的相关参数, 利用对目标函数进行优化使其最大化, 最终获取相关参数。设定C表示语料, Context(w)表示语料中任意单词w的上下文[7], 通过对数最大似然, 在机器学习过程中可将目标函数设为
(3)
其中p(w|Context(w))表示关于w和Context(w)的函数, 即
p(w|Context(w))=F(w,Context(w),θ)
(4)
目标函数可改写为
ι(w|Context(w))=logp(w|Context(w),θ)
(5)

图1 神经概率语言模型结构示意图Fig.1 Schematic representation of the neural probabilistic language model structure
其中θ表示待定参数集[8], 利用目标函数使其最大化同时获取最优参数集θ*, 然后通过函数F(w|Context(w),θ*)获取p(w|Context(w))。为组建函数F(w|Context(w),θ), 结合神经概率语言模型进行分析研究, 其中模型的神经网络结构如图1所示。
由图1可知, 模型由4个部分组成, 在模型的输入层, 关键的要素有语料C内包括的任意单词w的前n-1个单词向量, 其中m表示词向量的维度; 映射层xw表示全部词向量按照首尾顺序相连后形成的向量, (n-1)×m则为其维度;W是输出的含义, 是指投影层与隐含层;U是权重矩阵的含义, 是指隐含层与输出层;p是指与输出层相对应的偏置向量。为此, 隐含层的向量zw的计算式为
zw=tanh(Wxw+p)
(6)
输出向量yw的计算式为
yw=Uzw+q
(7)
其中w表示隐含层数量;q是词特征层激活向量;U是隐藏层到输出层的权重;y是对每个输出词的非标准的log概率。通过上述两个计算步骤获取输出层对应的向量yw。若使上下文为Context(w)并采用yw的分量表示时, 则下面的第1个词刚好为词典D中第i个词的概率, 可通过softmax函数对其进行归一化处理[9], 最终p(w|Context(w))的表达式为
(8)
获取目标函数后, 需要将其进行最大化处理, 进而获取最优的参数集, 其中含有大量的词向量, 通过随机梯度上升算法将函数最大化, 获取对应的梯度, 即
(9)
对相关符号进行设定, 设定X表示一个通过语料库共同建立的共现矩阵[10], 同时分析拟合共现矩阵的比率关系, 对应的计算式如下

(10)
其中pik表示变分参数;pjk表示相似度参数。通过上述分析, 组建语义表示模型, 进而得到英语单词和短语之间的语义相似度

(11)
其中J表示英语单词和短语之间的语义相似度。
1.2 面向大学英语教学的作文主题偏离自动检测
LDA模型并非是单一模型, 而是由3层组成的, 为“文本-主题-词”, 从概率隐形语义索引进行扩展, 从而得到3层贝叶斯概率模型, 其中包括3类不同的结构, 为包含词、 主题、 文档, 都属于非监督机器学习算法范畴, 其作用是从大量文章集或语料库内识别隐藏其中的主题信息。根据词袋模型将每个文档当成一个词频向量, 进而转换文本信息为数字信息, 使其方便建模计算。构建LDA模型, 首先以超参数α与β为关键点, 两者都是关于隐含主题,α为强弱程度;β为概率分布。
在组建LDA模型的过程中需要优先进行参数估计, 以下通过Gibbs算法进行主题抽取, 具体操作流程如下。
1) 初始化。将主题zi进行初始化处理, 获取多个随机数以及特定词的数量。
2) 循环采样。经过多次循环迭代后, 直至Markov链接接近目标分布, 此时主题zi可通过

(12)
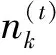

(13)
其中P(zi=k,zi,w)表示后验概率;αt和βk分别表示第t个和第k超参数的取值。在预备LDA建模时, 根据已有文档集合D对每个文档进行预处理, 其具体操作有分词、 去停用词等, 通过空格方式对处理完成的每个词项储存工作, 整理完成后得到相应的语料集, 并将得到的语料集作为下述处理数据。
将完成处理的语料以文档形式展现, 组建文档-词项矩阵, 即
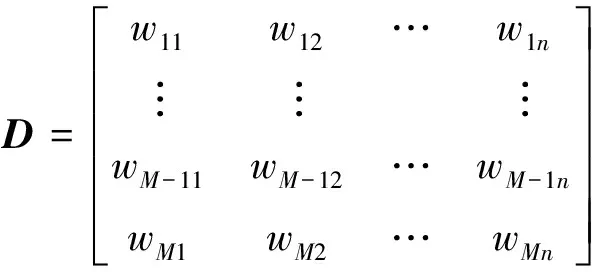
(14)
通过LDA模型对全部文档进行训练, 对文档中每个主题和特征词进行概率加权求和
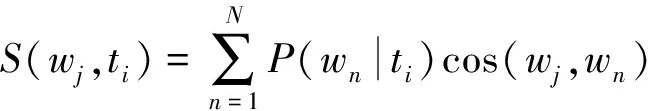
(15)
其中P(wn|ti)表示单词组合方式的数量; cos(wj,wn)表示发散度。在作文主体偏离自动检测时, 第1项任务为预处理, 完成后组建文档-词项矩阵, 然后利用LDA模型进行建模。面向文档集, 对其训练, 然后记录结果得到信息组合, 并利用其对文本设置选取的阈值筛选每篇文档, 进而获取跑题文档, 完成检测。以下给出具体操作流程。
1) 对文档集合进行预处理操作。在面向英文文档预处理时, 要以空格方式优先对文档内容进行分词, 注意转换句首的单词与专有名词等的大写字母, 在小写的同时删除停用词和标点符号。
2) 组建文档-词项矩阵。文档经过向量处理后的表示结果如式(14)所示。
3) 进行LDA建模。分别针对每篇文档进行建模处理, 在主题概率分布方面, 利用相关计算式获得, 第m篇文档亦是如此, 以概率值为基础, 其排列的顺序根据从大到小的规则, 从而得到每个文档的主题和概率分布。
4) 通过word2vec对词向量进行训练。输入以完成预处理的文档集作依据, 根据word2vec进行训练, 将每个词对应的词向量作为输出。以形成的词向量为基础, 根据有关公式计算词与词间的语义相似度。
5) 采用LDA对word2vec对文档进行主题相关度计算。对每篇文档的词均应用word2vec计算其与LDA建模后的第i个主题下不同特征词的余弦相似度, 并计算其概率加权和, 以每个主题的相关度相加之和为总相关度, 最终通过阈值大小检测作文主题是否偏离。
2 仿真实验
为验证所提面向大学英语教学的作文主题偏离自动检测算法的有效性, 实验中征采了8个各不相同主题的英语作文, 每个题目共包含作文200篇, 共计1 600篇。在每篇作文中都有人工标记的打分, 各题目中都存在跑题作文, 以15分为满分, 若一篇作文打分结果为5分以下, 则证明作文跑题。实验的主要目的是将人工标注和所提算法两者进行对比, 主要从查准率、 查全率以及F值3方面进行分析, 具体计算公式如下

(16)

(17)
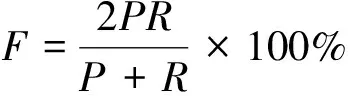
(18)
其中P表示查准率, 表示预测为正例的样本(A)中真正的正样本(T)的比重。R表示查全率, 表示在实际真正的正样本(B)中, 预测为正例的样本(T)的比重。F表示可以兼顾准确率与查全率的综合指标。3项测试指标的取值越高, 说明检测结果越理想, 其实验结果如表1~表3所示。

表1 查准率

表2 查全率

表3 F值
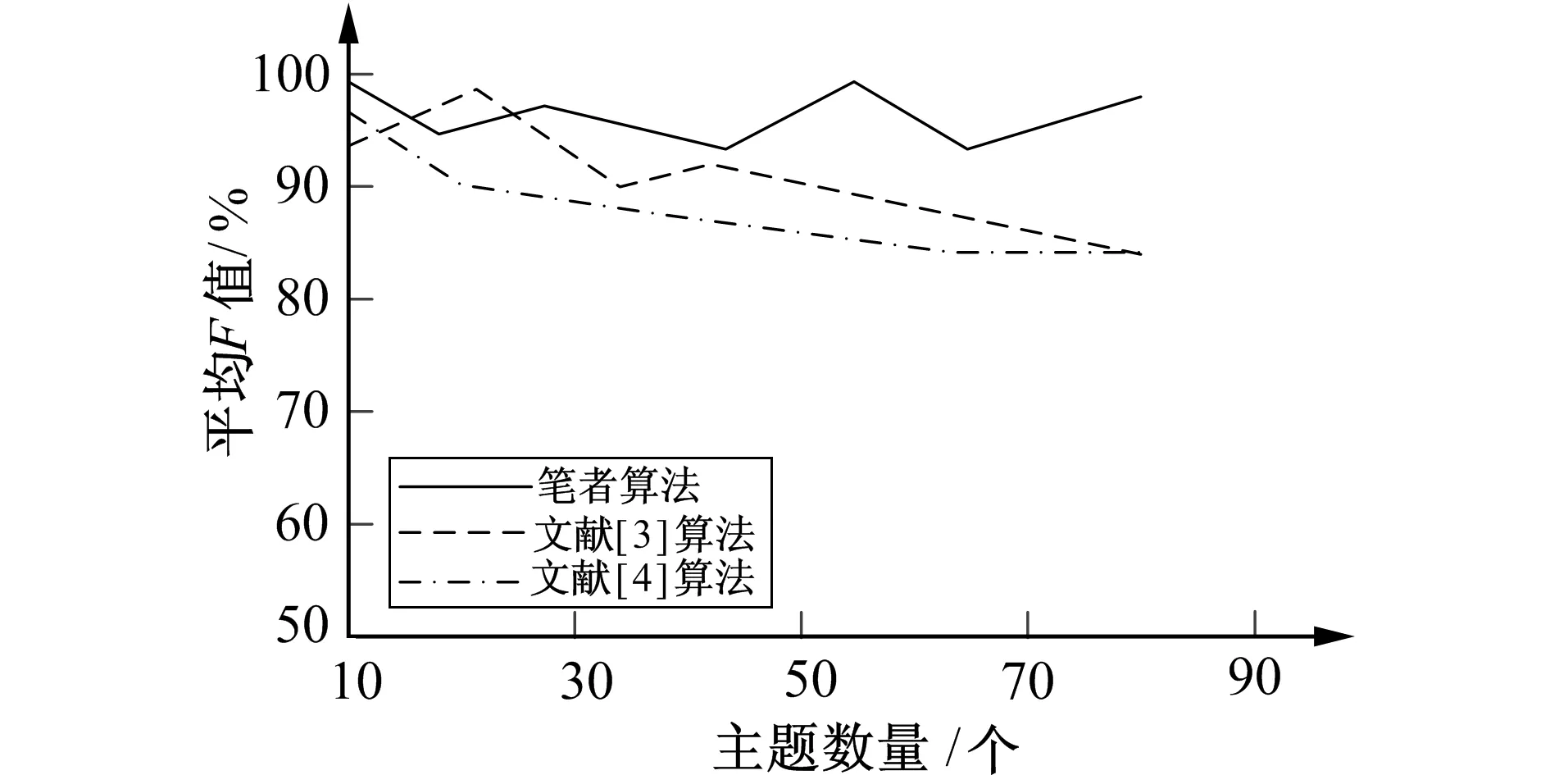
图2 不同算法平均F值对比Fig.2 Comparison of mean F values across different algorithms
分析表1~表3中的实验数据可知, 所提算法的检测结果最佳, 主要是因为其针对英语单词和短语之间的语义相似度进行计算, 将其作为检测依据, 可获取较为理想的检测结果。
由于一篇文档中会包含多个不同的主题, 以下主要通过不同的主题数据进行实验测试, 分别对比所提算法、 文献[3]和文献[4]算法的F值, 实验结果如图2所示。
分析图2的实验数据可知, 即使主题数量持续增加, 但笔者算法的F值取值还是更高一些, 由此证明了所提算法的优越性。因为笔者算法利用LDA模型训练全部文档, 同时对文档中各个主体和特征词进行概率加权求和, 提高了作文离题的检测精度。
3 结 语
针对传统检测算法存在的一系列问题, 笔者设计并提出一种面向大学英语教学的作文主题偏离自动检测算法。仿真实验结果表明, 相比传统算法, 笔者所提算法计算了单词和特征词两者之间的语义相似度, 可获取更加理想的作文偏题检测结果。因此, 该方法可为英语作文主题偏离检测提供一定的科学依据, 并可大大提高人工审阅的效率。但由于时间以及能力等方面的限制, 导致所提算法还存在很多的不足, 后续将针对以下几方面的内容进行研究:
1) 加强语料方面的训练, 同时还需要进一步进行丰富;
2) 后续研究过程中, 针对恶意作文检测方面的内容进行研究, 可有效避免作弊情况的发生。
参考文献:
[1]吕欣, 程雨夏. 基于语义相似度与XGBoost算法的英语作文智能评价框架研究 [J]. 浙江大学学报(理学版), 2020, 47(3): 72-79.

[2]曲强, 崔荣一, 赵亚慧. 基于LDA和word2vec的英文作文跑题检测 [J]. 计算机应用研究, 2019, 36(2): 415-419.
QU Qiang, CUI Rongyi, ZHAO Yahui. Off-Topic Detection for English Essays Based on LDA and Word2vec [J]. Application Research of Computers, 2019, 36(2): 415-419.
[3]陈志鹏, 陈文亮. 基于文档发散度的作文跑题检测 [J]. 中文信息学报, 2017, 31(1): 23-30.
CHEN Zhipeng, CHEN Wenliang. Off-Topic Essays Detection Based on Document Divergence [J]. Journal of Chinese Information Processing, 2017, 31(1): 23-30.
[4]孟超颖, 宋文爱, 富丽贞. 基于LDA耦合空间模型的作文跑题检测方法研究 [J]. 计算机应用研究, 2019, 36(12): 30-33.
MENG Chaoying, SONG Wenai, FU Lizhen. Off-Topic Essay Detection Based on LDA Coupling Space [J]. Application Research of Computers, 2019, 36(12): 30-33.
[5]LIU P, LIU J, MA X, et al. Off-Topic Detection Model Based on Biterm-LDA and Doc2vec [C]∥Proceedings of the 2019 3rd High Performance Computing and Cluster Technologies Conference. Guangzhou, China: [s.n.], 2019: 157-161.
[6]于建平, 孙亚楠, 孙锐, 等. 共现语境特征对情态动词语义排歧的限制作用 [J]. 江苏科技大学学报(自然科学版), 2019, 33(6): 60-67.
YU Jianping, SUN Yanan, SUN Rui, et al. Restriction of Co-Occurred Contextual Features Upon Word Sense Disambiguation of English Modal Verb [J]. Journal of Jiangsu University of Science and Technology (Natural Science Edition), 2019, 33(6): 60-67.
[7]张小迪, 崔海华, 程筱胜, 等. 一种基于同心圆的环形编码标志设计与检测 [J]. 机械制造与自动化, 2020, 49(2): 133-136,157.
ZHANG Xiaodi, CUI Haihua, CHENG Xiaosheng, et al. Design and Detection of Circular Coded Marker Based on Concentric Circles [J]. Machine Building & Automation, 2020, 49(2): 133-136,157.
[8]于建平, 付继林, 白塔娜, 等. 基于独有属性特征的情态与语境互动关系数据挖掘研究 [J]. 燕山大学学报, 2019, 43(5): 462-470.
YU Jianping, FU Jilin, BAI Tana, et al. Data Mining of Interactive and Restrictive Relations between Modal Senses and Contextual Features by Exclusive Attribute Features [J]. Journal of Yanshan University, 2019, 43(5): 462-470.
[9]雷树杰, 邢富坤, 王闻慧. 融合领域多词特征的英文武器装备名识别研究 [J]. 计算机应用与软件, 2019, 36(6): 177-183,195.
LEI Shujie, XING Fukun, WANG Wenhui. Data Mining of Interactive and Restrictive Relations between Modal Senses and Contextual Features by Exclusive Attribute Features [J]. Journal of Yanshan University, 2019, 36(6): 177-183,195.
[10]王永贵, 郑泽, 李玥. Word2vec-ACV: OOV语境含义的词向量生成模型 [J]. 计算机应用研究, 2019, 36(6): 1623-1628.
WANG Yonggui, ZHENG Ze, LI Yue. Word2vec-ACV: Word Vector Generation Model of OOV Context Meaning [J]. Application Research of Computers, 2019, 36(6): 1623-1628.
