基于多度量融合的无监督领域自适应行人重识别算法
2023-01-16姜冠正
姜冠正,唐 俊
(安徽大学 电子信息工程学院,安徽 合肥 230601)
行人重识别任务旨在跨相机下检索出特定的行人图像,这是一项极具挑战性的任务.由于行人的姿态、摄像机拍摄角度和光照的变化,使得同一个行人的图像之间出现较大差异.受益于人工标注数据集的出现,行人重识别任务得到快速发展,在检索精度上得到了很大提升.然而,在实际应用中,即使使用人工标注的数据集训练好模型,如果直接部署在一个新的应用场景上,由于领域间的显著差异会导致模型精度的显著下降.在每个监控系统上都重新进行数据采集和人工标注是一项费时费力的工作,同时也不具备在现实中部署的意义.为此,无监督领域自适应任务被提出用以解决上述问题.无监督领域自适应任务指的是在有标注的源域上训练好模型,使其适应于无标注的目标域并在目标域上得到检索精度的提升.和一般的无监督领域自适应任务不同的是,在行人重识别任务中目标域的类别数未知,且通常和源域之间没有交叉,因此该任务较一般意义上的无监督领域自适应任务而言更为实际,也更具挑战性.
无监督领域自适应在行人重识别上现有的方法主要分为基于生成对抗网络的方法和基于聚类的方法.基于生成对抗网络的方法利用对抗性学习、通过减少像素级别上的差异来学习域不变特征,利用图像风格转移来缩小像素空间的域差异[1].基于聚类的方法也是解决无监督领域自适应问题的重要范式,Lin等[2]设计了一种自底向上的聚类框架,利用不同身份之间的多样性和每个身份内的相似性来学习判别特征.Fu等[3]关注到行人自身的相似性,提出将行人分成整体、上半身、下半身,分别对不同部分进行分组聚类获得伪标签,并将分组训练后的特征拼接后作为最终的行人特征.Zhai等[4]通过在源域上训练具有不同偏向和特定知识的模型,再在目标域上通过不同预训练的模型进行聚类和相互学习来提炼出更高质量的伪标签.
虽然这些方法的实验效果已经取得了显著提升,但是其性能仍不能令人满意.无监督领域自适应在行人重识别任务中面临的问题主要来自:①源域上预训练的模型在目标域上泛化能力有限;②聚类算法本身的局限性使得很难获得目标域上准确的伪标签,从而难以在目标域上得到可靠的聚类结果.这些因素限制着模型领域自适应能力.
论文提出了一种基于多度量融合(multi-metric fusion,简称MMF)的无监督领域自适应行人重识别算法,以解决无监督领域自适应任务中由于聚类算法的局限性而导致伪标签出现噪声的问题.它具有以下优点:①相较于传统的特征相似度度量方式,多度量融合算法以一种柔性的方式计算特征相似度,通过线性加权的形式、利用不同特征相似度度量函数产生不同聚类结果来进一步优化聚类结果;②在不使用目标域上任何信息的情况下,通过优化聚类时特征相似度计算方式,有效减少了伪标签噪声的产生,使得目标域上的伪标签更加可靠.
1 基于多度量融合的无监督领域自适应行人重识别算法
1.1 问题描述
在无监督领域自适应行人重识别任务中,目标域上伪标签的质量对模型的领域自适应性能有着很大影响.由于源域预训练模型在目标域上泛化能力有限,以及聚类算法本身存在的局限性而出现伪标签噪声的问题,现有的方法并没有很好地解决上述问题.
如图1所示,在目标域上对行人的特征进行聚类时:使用欧式距离度量行人特征之间的相似性,行人图像A1和B之间的欧式距离小于行人图像A1和A2的欧式距离;计算行人特征之间的相关距离时,行人图像A1和B的相关距离大于行人图像A1和A2的相关距离.实际上,行人图像A1和B属于不同的行人图像,行人图像A1和A2属于同一个行人图像.此时如果在DBSCAN(density-based spatial clustering of applications with noise)聚类阶段使用欧式距离计算行人特征之间的相似性时,就会错误地将行人图像A1和B划分到同一个簇内,从而引入伪标签噪声,得到不可靠的聚类结果.

图1 伪标签噪声的引入
在聚类算法中,特征相似度的计算对聚类结果有着直接的、决定性的影响,在目前的无监督领域自适应行人重识别任务中,传统的方法在聚类阶段生成伪标签时,仅使用欧式距离作为特征相似度度量函数评估目标域上特征之间的相似度,之后根据该相似度矩阵生成目标域上的伪标签.但是由于数据集之间不同的数据分布特点,传统的特征相似度度量方式并不能合理全面地评估聚类时特征之间的相似性关系,从而导致在目标域上聚类时,会引入噪声样本点,产生伪标签噪声,从而影响到最终聚类结果的可靠性.
1.2 双分支差异化网络
1.2.1 网络结构
信道混洗是通过将同一张图像的RGB信道的图像进行打乱混洗,经过排列组合后,生成同一张图像的RGB混洗的5张增广图像.信道混洗可以有效提升行人重识别模型的检索精度[5].如图2所示,在源域预训练阶段,首先,将源域数据集上带有标签的行人图像通过信道混洗进行数据增广[5],使用Resnet50[6]作为主干网络提取行人特征,经过信道混洗增广后的行人图像,其身份标签采用两种不同的分配策略.模型设计为双分支差异化网络,两个分支分别为标签共享和标签异构分支.整体网络包含主干ResNet50网络的5层卷积层,将其末端的平均最大池化层替换为自适应最大池化层,并在其后面接上全连接层且调整其输出为512维,将这512维的输出作为两个分支分类器的输入,分支一为标签共享分支,分支二为标签异构分支,将两个分支的512维特征输出进行拼接得到最终的1 024维的特征,并将三元组损失与结合LSR(label smoothing strategy)的softmax交叉熵损失作为网络的损失函数用于训练.
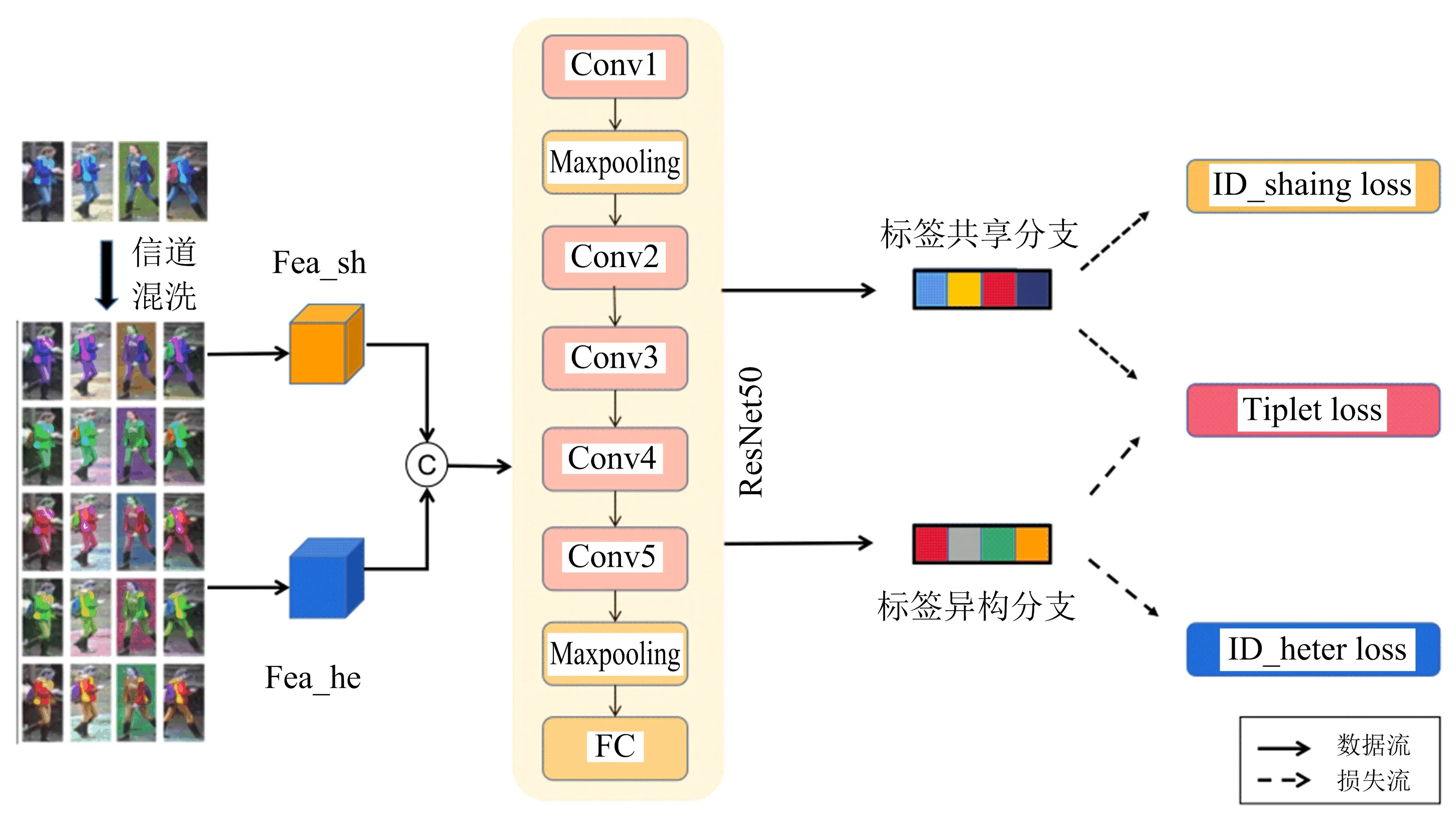
图2 源域预训练阶段
如图3所示,目标域微调阶段,在目标域数据集上无标签的行人图像同样经过信道混洗.经ResNet50网络提取行人特征后,在特征空间上计算两两行人之间的特征相似度,由此得到目标域上行人特征之间的特征相似度矩阵.根据该特征相似度矩阵,由DBSCAN聚类算法对目标域的行人分配伪标签,最后利用所获得的伪标签在目标域上对模型进行微调.

图3 目标域微调阶段
1.2.2 损失函数
在预训练阶段和微调阶段使用相同的损失函数.标签共享分支和标签异构分支分别使用不同的身份分类损失,并同时使用三元组损失作为辅助损失监督模型训练.
对于标签共享分支,认为信道混洗后的增广图像和原始图像共用相同的身份标签,其损失函数的表达式为
(1)
对于标签异构分支,认为信道混洗后的增广图像和原始图像使用不同的身份标签,其损失函数的表达式为
(2)

困难三元组损失的核心思想为难样本挖掘,其损失函数的表达式为
(3)
其中:P为每个批次里不同行人的个数,K为每个行人拥有的样本个数,α为正负样本对间距离阈值的超参数,da,hp为锚点与最难正样本之间的欧式距离,da,hn为锚点与最难负样本之间的欧式距离.
最终的损失函数为
loss_total=αloss_idsharing+βloss_idheter+γloss_triplet,
(4)
其中:α,β,γ为超参数,在实验中设置为α=0.6,β=0.6,γ=0.2.
1.2.3 多度量融合算法
在无监督领域自适应行人重识别任务中,聚类阶段的伪标签质量直接影响到行人重识别模型的领域自适应性能.为了解决由于传统方法计算特征相似度的局限性而在聚类阶段产生伪标签噪声的问题,论文对传统的特征相似度的计算方式进行了改进.具体而言,考虑到不同的特征相似度度量函数对特征之间的相似度评估角度存在差异并由此会形成不同的聚类结果,多度量融合算法在进行特征相似度计算时,通过利用不同的特征相似度度量函数之间的相关性,来进一步优化目标域数据集上的聚类结果.如图3所示,在使用DBSCAN聚类算法计算行人特征之间的相似度获取伪标签时,通过不同的相似度度量函数分别进行特征相似度的计算,最终的特征相似度为不同度量函数计算出来的特征相似度线性加权的结果.一般形式下的多度量融合算法的数学表示如下
(5)
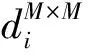
论文预设了4种度量函数,分别是欧式距离(Euclidean distance)、余弦距离(cosine distance)、相关距离(correlation distance)和切比雪夫距离(Chebyshev distance).对于以上特征相似度度量函数的选取,主要是考虑到选取的度量函数对特征之间相似度计算的差异性.对以上4种预设的度量函数数学表示形式如下:给定目标域上的行人样本集合X,X是M维实数特征向量空间M中点的集合,其中,xi,xj∈X,xi=(x1i,x2i,…,xMi)T,xj=(x1j,x2j,…,xMj)T,行人样本xi和xj的欧氏距离定义为
(6)
余弦距离定义为
(7)
相关距离定义为
(8)
切比雪夫距离定义为
(9)

在无监督领域自适应行人重识别任务中,由于无法获得目标域上的任何先验信息,因此认为各个度量函数的重要程度是相同的,即各个度量函数的权重赋值是相同的.此时多度量融合算法中的线性加权转化为平均加权,此时的数学式表示如下
(10)
值得注意的是,论文提出的多度量融合算法与传统的计算特征相似度的方式相比具有以下优势:①在数学形式上具有一般性,使用单一度量函数计算特征相似度可视为是多度量融合算法中其余度量函数的权值置零的特例;②对于不同的行人重识别数据集而言,由于不同的行人重识别数据集上数据分布特点的不同,传统的特征相似性度量方式在聚类时由于只关注到特征之间单一的相似性关系,多度量融合算法通过线性加权的形式综合各个度量函数对聚类结果的影响,可以被用来更全面合理地评估特征之间的相似性关系.
2 实验结果分析
2.1 实验参数设置和实验细节
论文使用的实验环境如下:操作系统为内核基于Linux的Ubuntu20.04,深度学习框架为pytorch1.8.1,编程语言为python3.6,GPU型号为NVIDIA GeForce RTX3090.首先将所有输入图像统一调整为256×128大小,利用随机旋转和随机擦除来进行数据扩充,设置dropout的概率为0.5.对于每一批次训练样本,设置行人身份个数P=8,每个身份的样本个数K=4,每个批次大小为32.使用SGD优化器对网络进行训练,在预训练阶段,使用在ImageNet上经过预训练后的主干网络ResNet50[6].设置:学习率为0.01;添加的全连接层的学习率为0.1;学习率衰减为每8个epoch衰减为原来的10%,总共训练23个epoch.对于微调阶段,共执行5次聚类和微调迭代,各层学习率均设置为预训练阶段的5%,每次微调执行10个epoch.将标签共享和标签异构分支各自提取的512维特征进行拼接,获得1 024维的拼接特征以供聚类和测试阶段使用.DBSCAN聚类的参数中,设置:领域半径为0.8,Duke数据集上最小样本个数为10,Market数据集上最小样本个数为8,标签共享分支损失函数的权重系数α为0.6,标签异构分支损失函数的权重系数β为0.6,三元组损失函数权重γ为0.2.
2.2 数据集和评价指标
该节首先介绍行人重识别常用的两个大型数据集Market-1501和DukeMTMC-reID,之后介绍评价行人重识别算法性能的两种指标Rank-k和mAP.表1显示了Market-1501和DukeMTMC-reID数据集的概况.

表1 行人重识别数据集统计表 个
Rank-k[7]和平均准确率mAP[8](mean average precision)是图像检索领域通用的评测标准,也是行人重识别任务最常用的评价指标.
在单次图像检索中,最后会输出与查询样本相似性降序队列,其中第一张图像即为模型认为最有可能和查询行人是同一个人的样本,rank-k即为从队列中前k张图像中任意一张匹配正确的概率,通常以rank-1,rank-5,rank-10作为评价指标,最终的rank-k结果为查询集中所有的检索结果的平均值.
mAP则是衡量某个查询样本,其在搜索库中所有的正确样本在结果队列中的靠前程度,即mAP先对单个样本查询计算该次AP,再将查询集中的所有样本的AP累加求平均值,即为最后的mAP指标.假设某次查询中搜索库中所有正确匹配样本个数为N,则单次AP计算方法如下
(11)
其中:rN代表第N个正确匹配结果在结果队列中的位数,如第1个正确匹配结果出现在结果队列第1位,则r1=1,第1个正确匹配结果出现在结果队列的第2位,则r1=2,以此类推.
2.3 消融实验
论文设计了多组消融实验验证多度量融合算法的有效性.表2,3分别显示了在Market-1501→DukeMTMC-reID以及DukeMTMC-reID→Market-1501上的消融实验结果.
如表2所示,在Market-1501→DukeMTMC-reID上,首先基线方法中是仅使用欧式距离作为特征相似度度量函数,在多度量融合算法中,使用其他3个单一度量函数作为特征相似度度量函数后,rank1和map较基线方法均有小幅度提升.使用4种度量函数平均加权计算特征相似度使得模型的性能达到最优,rank1和map分别较基线方法上升了0.448 8%,2.106 9%.

表2 Market1501→DukeMTMC-reID的消融实验结果 %
如表3所示,在DukeMTMC-reID→Market-1501上,基线方法中仅使用欧式距离作为特征相似度度量函数.在多度量融合算法中,使用切比雪夫距离计算特征相似度时对模型的增益最大,可视为多度量融合算法中其余3个度量函数的权值置零的特例,此时rank1和map分别较基线上升了0.831 4%,2.163 0%.当使用4种度量函数平均加权计算特征相似度时,rank1和map较基线也分别提升了0.207 8%,1.144 5%.

表3 DukeMTMC-reID→Market1501的消融实验结果 %
2.4 对比实验
该节将论文提出的方法同近些年的方法进行了对比,表4,5分别显示了在Market-1501→DukeMTMC-reID,DukeMTMC-reID→Market-1501上的对比实验结果.
从表4,5可以看到,论文提出的方法同早期的相关工作,如SPGAN[11],ATNet等[12]相比,Rank-1和map均有大幅度提升;与近年来基于聚类的伪标签方法,如BUC[14],ACT[17],PAST[24]等相比,在两个评价指标上同样也有非常大的提升.
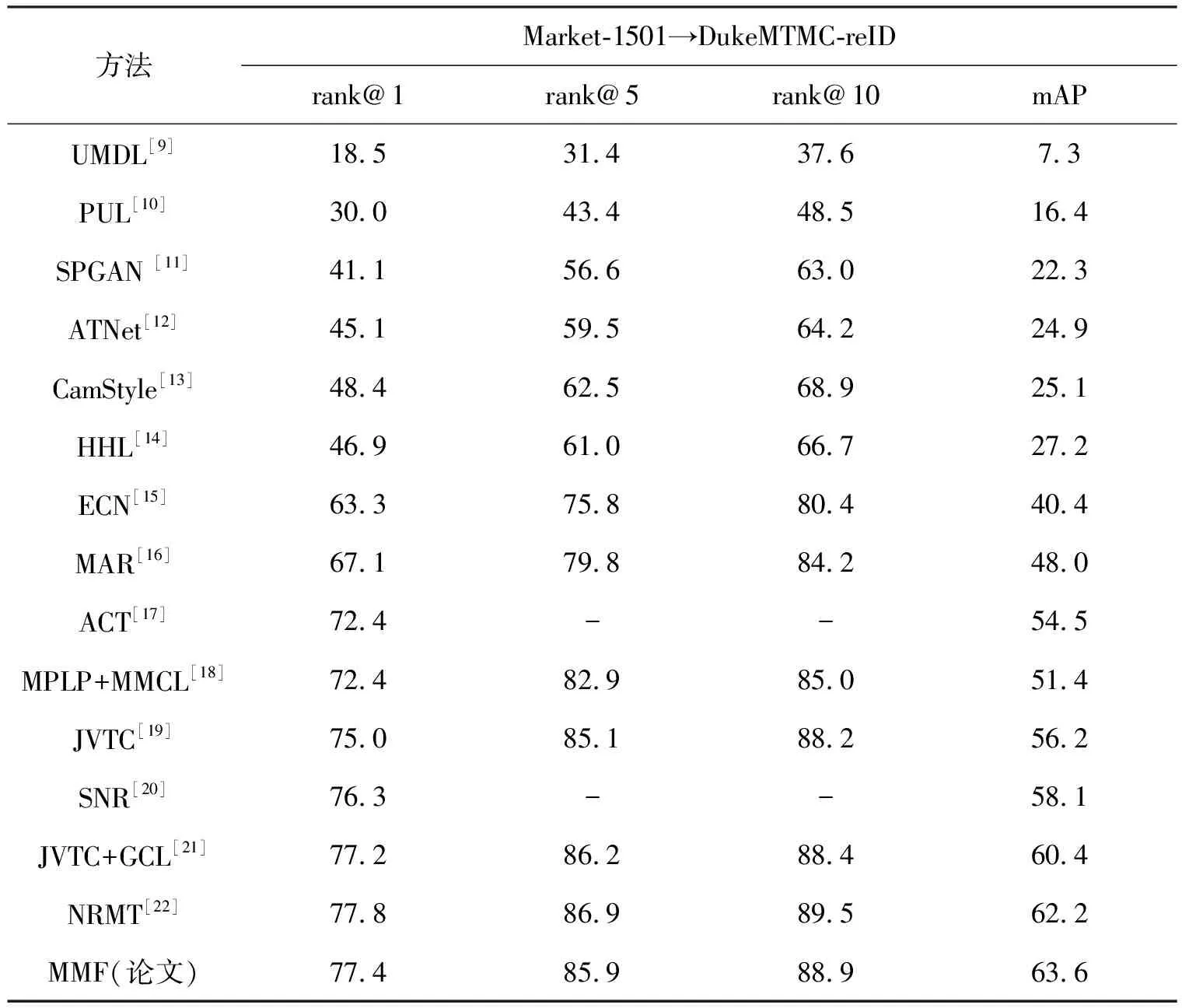
表4 在Market-1501→DukeMTMC-reID上的对比实验结果 %

表5 在DukeMTMC-reID→Market-1501上的对比实验结果 %
3 结束语
论文提出一种基于多度量融合的无监督领域自适应的行人重识别算法,旨在解决在无监督领域自适应行人重识别任务中,由于聚类算法本身存在的局限而难以获得可靠伪标签的问题.该算法在目标域聚类时,在不使用目标域上任何标签信息的情况下,通过多个特征相似度度量函数线性加权的方式计算特征相似度,可以被用来更合理全面地评估聚类时特征之间的相似度,提升了目标域聚类时伪标签的鲁棒性和准确性.在Market1501→DukeMTMC-reID和DukeMTMC-reID→Market-1501上大量的实验结果表明,论文提出的多度量融合算法有效提升了模型在无监督领域自适应行人重识别任务上的检索精度.
