基于SVM的变电站母线日净负荷曲线大数据识别方法
2023-01-14刘文飞郝如海
青 灿,行 舟,智 勇,刘文飞,郝如海,马 瑞
(1.长沙理工大学电气与信息工程学院,湖南 长沙 410114;2.国网甘肃省电力公司,甘肃 兰州 730030;3.国网甘肃省电力公司电力科学研究院,甘肃 兰州 730070)
电力负荷建模作为电力系统仿真的重要组成部分,其准确性会对潮流、电压稳定以及暂态稳定计算等产生重要直接影响[1-2]。传统基于统计综合法[3-5]的电力负荷建模关键技术之一是电力负荷曲线分解,但其需要统计各类行业电力负荷中典型用电设备的种类、比例以及各行业负荷占节点负荷的百分比,难以准确统计,且统计困难,统计过程费时、费力。
非侵入式负荷监测与分解(nonintrusive load monitoring and decomposition,NILMD)[6-7]可将低压用户智能电表负荷数据分解为各用电设备的信息,其关键技术为事件探测、特征提取、负荷识别。针对采集的低频信息,如有功功率,近期诸多学者通过机器学习方法对此进行研究。已涉及到的算法包括K近邻(K-nearest neighbor,KNN)[8]、贝叶斯(bayesian)[9]算法,遗传算法(genetic algorithm,GA)[10-11]、隐马尔可夫模型(hidden markob models,HMM)[12-14]、动态时间规整(dynamic time warping, DTW)算法[15-16],人工神经网络(artificial neural network,ANN)[17-19]等方法。上述方法对低频数据分解虽取得了一定进展,但准确度有待提高。文献[20]利用分段线性近似(piecewise linear approximation,PLA),以高斯动态弯曲核(Gaussian dynamic time warping kernel,GDTW)为核函数的支持向量机进行分类识别,有较高的识别率和较快的识别速度。目前,非侵入式负荷监测与分解技术研究大多数集中在家庭用户低电压层面。变电站层母线负荷曲线分解思路与用户层NILMD类似,前提是提取不同行业的典型负荷曲线,其相当于NILMD中的特征信息,通常由聚类分析获得[21-22]。为此,本文提出将非侵入式负荷分解技术拓展到变电站高电压等级层面,即将变电站总负荷功率分解为各典型行业负荷构成功率,进而获取典型行业负荷能耗情况与变电站母线负荷功率变化规律。
本文利用典型行业负荷曲线特征信息及NILMD相关研究方法,提出一种母线负荷曲线识别方法。首先,提取典型行业负荷曲线的有功突变时间,并对有功曲线波形进行傅里叶级数拟合,实现波形特征提取;然后,基于数据采集与监控(supervisory control and data acquisition,SCADA)系统所得大数据将变电站母线日净负荷功率曲线特征输入到支持向量机模型[23],对行业负荷曲线进行辨识,实现母线日净负荷曲线识别;最后,通过甘肃省网330 kV实际数据验证基于SCADA和SVM的母线日净负荷曲线识别方法的有效性和正确性。
1 母线负荷曲线模型
电力系统中稳态功率、电流和电压波形都能可靠地描述负荷的特性,本文采用稳态有功功率波形作为描述母线负荷内部各行业负荷的依据。
在某一时间区段内,母线负荷总功率按行业负荷组成分解为模型:
(1)
式中PL(t)为t时刻母线负荷的总功率;Ph(t)为t时刻第h类行业负荷的功率;αh(t)为t时刻第h类行业负荷的功率权重系数;e(t)为噪声或误差。
常见4种典型工、农、商和居民行业日负荷有功功率曲线具有如下特征:
1)居民用电时具有很明显的午、晚高峰特征,其中晚高峰负荷更大,晚间负荷比较小且平稳;2)商业用电时白天负荷高且平稳、晚上负荷低,具有很明显的上下班特征;3)工业用电时由于重工业一般为三班作业,轻工业多为单、两班制,相互形成互补,整体负荷大且变化小、平缓;4)农业负荷时全年呈现很强的季节性,灌溉时节用电主要集中在09:00—11:00、15:00—17:00,晚间基本没有负荷。
为了单纯地描述4种典型行业日负荷曲线的变化特征,将其有功分别进行归一化处理,使其为0~100 MW,归一化公式为
(2)
式中Pmin为日负荷波谷值;Pmax为日负荷波峰值;P为未归一化前日负荷;P*为归一化日负荷。由此得到归一化后的典型行业日负荷曲线,如图1所示。
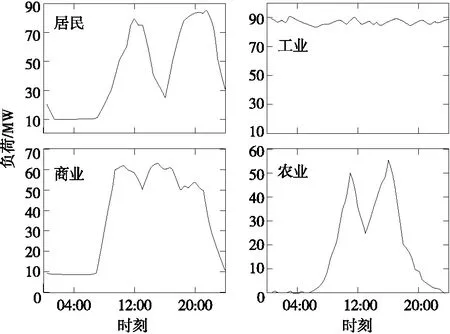
图1 典型行业日负荷曲线Figure 1 Daily load curve of typical industry
2 母线负荷曲线识别原理及方法
在母线负荷识别模型中,利用数据采集与监控(SCADA)系统可以得到变电站高压母线负荷总功率,而负荷内部各行业负荷的组成是未知的所求值。由图1可知,对于某个特定季节,一段时间内不同行业负荷的功率特性会有差异。因此,本文先对典型行业负荷曲线波形特征进行初步提取;然后对母线负荷有功功率进行傅里叶级数分解,得到各级傅里叶函数系数,采用傅里叶变换系数作为行业负荷特征标签;最后利用SVM分类器进行负荷识别。
2.1 曲线特征预筛选
考虑到存在4种典型行业负荷,完全利用突变时间和傅里叶级数拟合的系数进行单步遍历会让曲线识别的计算量变大,因此,本文将曲线特征分为曲线预筛选和曲线识别特征两类。首先将负荷突变时间作为曲线预筛选特征进行初步的识别;然后将傅里叶级数拟合的系数作为曲线识别特征;最后利用SVM分类器进行分类识别,从而减小分类识别算法计算量。
2.2 傅里叶级数拟合
以甘肃常见的居民、商业、工业、农业4类行业负荷为例进行研究与分析。通常不同地区各行业负荷组成情况不一样,监测某地区变电站母线处电力负荷的总功率PL(t),对其进行快速傅立叶变换,一般地,4次傅里叶级数足以完整表达日负荷曲线的特征。
(3)
式中ak、bk为母线电力负荷总功率的各次谐波分量的系数;a0为功率基波分量;ω为母线负荷功率基波分量的角频率。
2.3 SVM
支持向量机属于二分类模型,其基本模型是定义在特征空间上间隔最大的线性分类器。
假设给定二维两类训练样本集S={(xi,yi),i=1,2,…,n;yi=(-1,+1)},这里xi表示第i个输入样本,yi表示第i个输入样本对应的类别值。支持向量机是基于训练样本集S求解能够正确地分类训练样本集且几何间隔最大的分离超平面,从而达到分类的目的。
若训练样本集是线性可分的,SVM模型求解最大分割超平面问题可以表示为含有不等式约束的凸二次规划问题,即
(4)
若输入空间的训练样本集是非线性可分的,支持向量机用核函数代替线性分类中目标函数与分类决策函数的内积,通过非线性变换将它转化为高维特征空间中的线性分类问题,然后在此空间内求解出最优分类超平面。
非线性映射为
x→φ(x)=(φ1(x),φ2(x),…,φn(x))T
(5)
则最优分类器为
(6)
目前常用的SVM核函数主要有3种:多项式内积、高斯径向基、Sigmoid核函数,分别为
(7)
(8)
(9)
本文选用高斯径向基核函数的支持向量机划分多类负荷曲线,即多分类问题。在每两类负荷曲线间构造一个二分类器器,若有N类,则组成一个共N(N-1)/2类的多分类器。本文共包含4类典型负荷曲线,组成一个含有6类的多分类器,从而实现4种负荷曲线的分类识别。
2.4 曲线识别流程
本文提出的母线负荷曲线识别方法包括支持向量机分类器训练和母线负荷曲线识别两个部分。
1)分类器训练。首先分析典型行业日负荷曲线的负荷突变时间,得到预筛选特征库;然后对行业日负荷曲线进行傅里叶级数拟合,得到傅里叶级数拟合的相关系数,即曲线识别标签库;最后利用高斯核支持向量机模型对曲线识别特征标签训练,得到含有6类的二值分类器库。
2)负荷曲线识别。首先根据母线日净负荷曲线的负荷突变时间从之前训练过的二值分类器库中筛选出对应的二值分类器;然后基于SCADA系统获取变电站母线日净负荷曲线,通过傅里叶级数拟合得到拟合相关系数,将其作为曲线识别特征输入到二值分类器,得票最多的二值分类器对应的负荷即母线负荷曲线识别结果。
具体的母线负荷曲线识别流程如图2所示。

图2 母线负荷曲线识别流程Figure 2 Flow chart of bus load curve identification
3 算例分析
本文对甘肃省某330 kV变电站下110 kV母线日净负荷曲线进行识别,由SCADA系统采集得到该变电站母线负荷以及该母线区域新能源出力数据。该地区4月15日的母线日负荷、风电日出力曲线分别如图3、4所示。
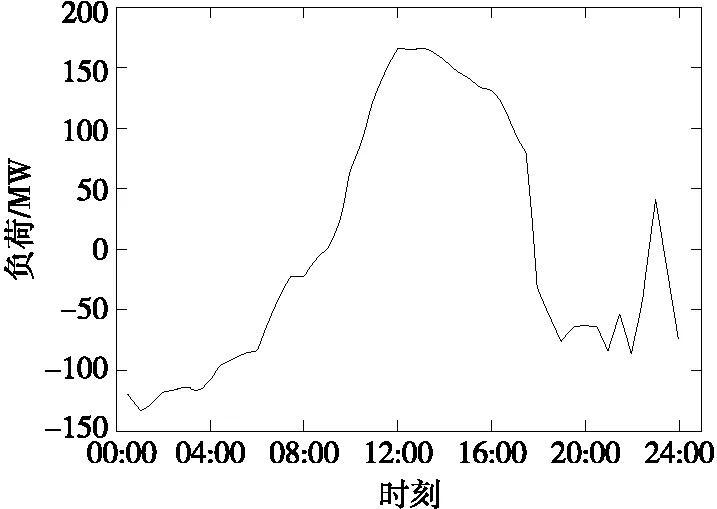
图3 母线日负荷曲线Figure 3 Bus daily load curve
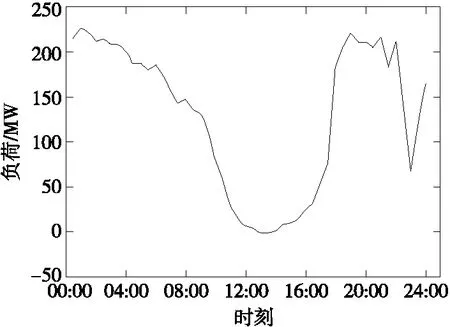
图4 风电日出力曲线Figure 4 Wind power daily generation curve
变电站母线日净负荷为母线日负荷与接入风电日出力的叠加,即
P′bus=Pbus+Pwind
(10)
式中P′bus为某时刻母线净负荷;Pbus为相应时刻母线负荷;Pwind为相应时刻母线接入风电出力。由此可以得到母线日净负荷曲线,如图5所示。
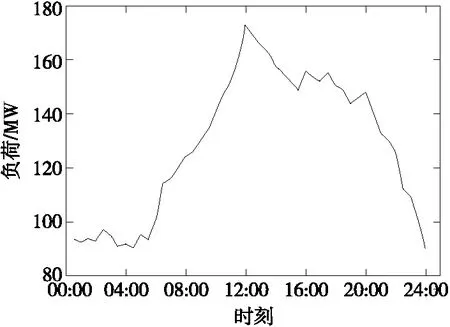
图5 母线日净负荷曲线Figure 5 Bus net daily load curve
3.1 曲线预筛选特征
由图1、5得到各典型行业日负荷及母线日净负荷曲线突变时间,如表1所示,若变电站母线日净负荷波形在21:00—21:30左右出现突变,则只需在此处辨识居民、商业负荷;若变电站母线日净负荷波形在16:00左右出现突变,则只需在此处辨识居民、农业负荷,无需对所有行业负荷进行识别,如此可以缩减识别范围,提高识别效率。

表1 日负荷突变时间Table 1 Daily load mutation time
3.2 曲线识别特征标签
对图1所示4种典型行业日负荷曲线及图5母线日净负荷曲线进行傅里叶级数拟合,得到负荷特征标签,如表2所示。
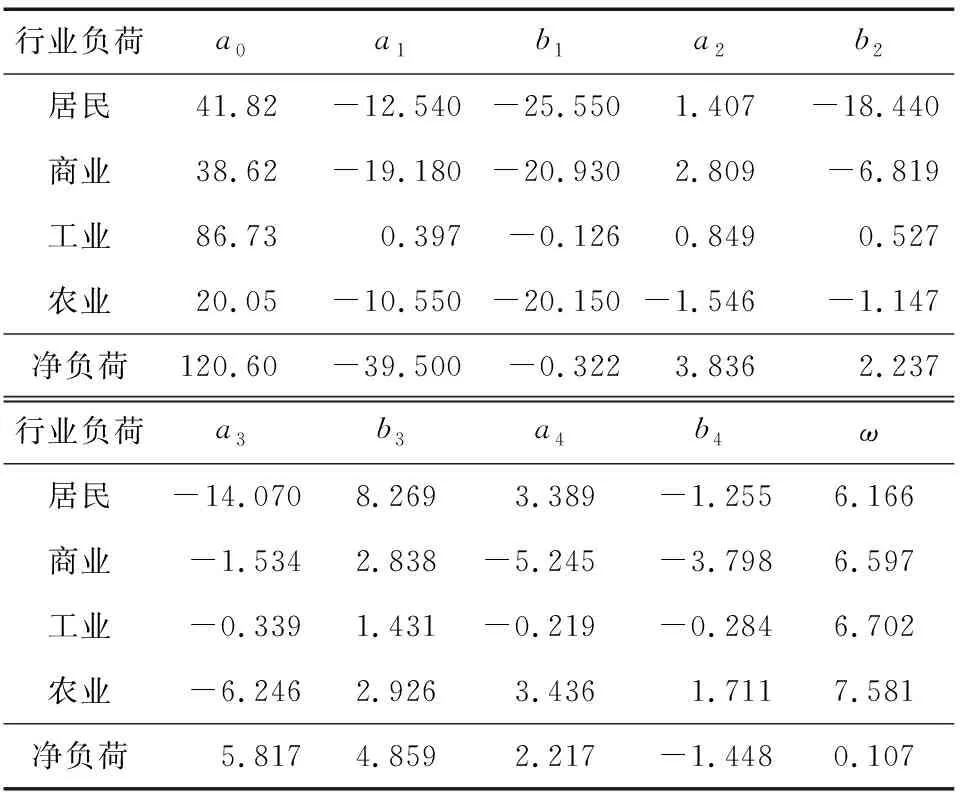
表2 负荷特征标签Table 2 Load characteristic tags
3.3 母线负荷曲线识别
对图5所示母线日净负荷曲线进行识别,具体识别过程如下:
1)基于两两负荷训练分类器,对行业负荷有功波形特征库(包括有功突变时间和傅里叶级数拟合系数)进行分类器训练,得到高斯核支持向量机二值分类器库;2)分析母线日净负荷曲线变化过程,提取负荷突变时间,进行预筛选,得到相应的高斯核支持向量机二值分类器;由图5可以确定该类母线负荷突变时间为05:00、11:30、16:30、20:00;3)将傅里叶级数拟合后曲线特征识别标签向量输入到二值分类器,对二值 SVM 分类器进行测试,所有二值分类器中得票数最多的负荷即为识别结果,曲线识别结果如图6所示,可以看出,分解出的4条典型行业负荷曲线与图1对应,分别呈现明显相似的的曲线特征。
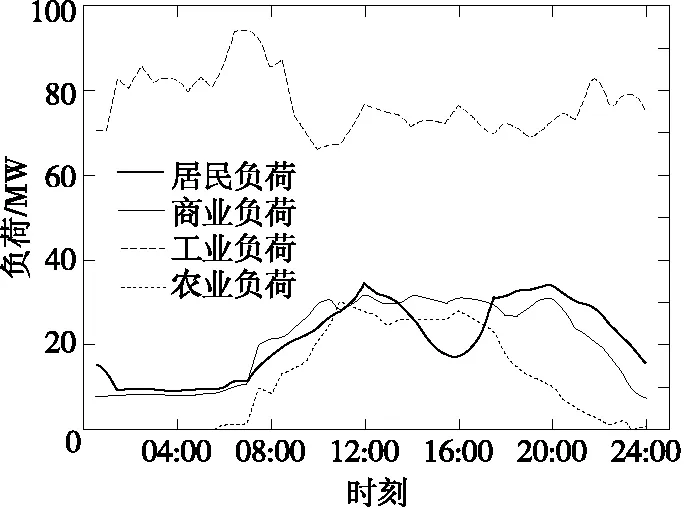
图6 4月15日曲线分解结果Figure 6 Curve decomposition results on April 15
为验证该方法的有效性和适应性,对该地区同一110 kV母线下5月15日、6月15日的母线日净负荷曲线进行辨识,曲线识别结果分别如图7、8所示。将图7、8与图1比较,可以看出,曲线识别结果与典型行业负荷曲线具有明显的相似性,故本文所提方法能有效识别变电站母线负荷曲线。
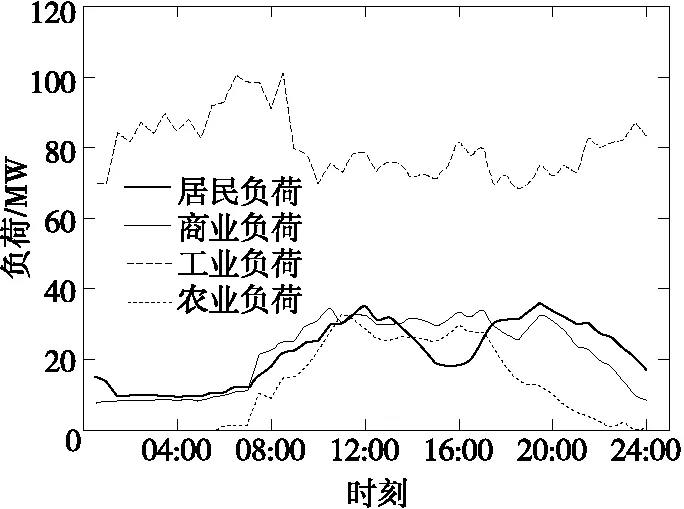
图7 5月15日曲线分解结果Figure 7 Curve decomposition results on May 15
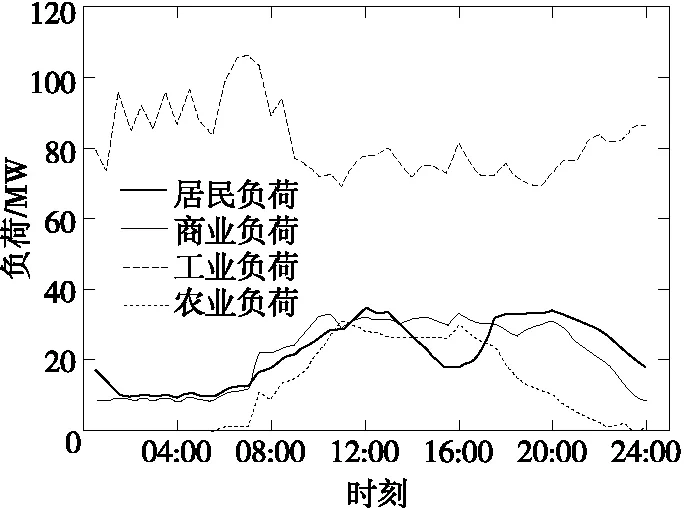
图8 6月15日曲线分解结果Figure 8 Curve decomposition results on June 15
4 结语
本文提出了一种基于数据驱动和支持向量机的母线负荷曲线识别方法,得到如下结论:
1)利用SCADA变电站母线负荷历史大数据挖掘可有效获取其负荷曲线特征,为统计负荷建模提供新的思路;2)在母线有功负荷功率暂态突变时间及其傅里叶变换系数标签负荷特征提取基础上,通过构建高斯径向基核函数支持向量机模型,可有效实现变电站母线负荷内部行业负荷种类及组成进行分类。
