基于语义分割引导的三维目标检测
2023-01-13崔振东李宗民杨树林刘玉杰
崔振东,李宗民,,杨树林,刘玉杰,李 华
基于语义分割引导的三维目标检测
崔振东1,李宗民1,2,杨树林2,刘玉杰1,李 华3,4
(1. 中国石油大学(华东)计算机科学与技术学院,山东 青岛 266580;2. 山东石油化工学院大数据与基础科学学院,山东 东营 257061;3. 中国科学院计算技术研究所智能信息处理重点实验室,北京 100190;4. 中国科学院大学计算机科学与技术学院,北京 100049)
三维目标检测是计算机视觉领域的热门研究内容之一。在自动驾驶系统中,三维目标检测技术通过捕获周围的点云信息与RGB图像信息,对周围物体进行检测,从而为车辆规划下一步的行进路线。因此,通过三维目标检测实现对周边环境的精准检测与感知是十分重要的。针对三维目标检测技术中随机采样算法导致前景点丢失的问题,首先提出了基于语义分割的随机采样算法,通过预测的语义特征指导采样过程,提升了前景点的采样比重,进而提高了三维目标检测精度;其次,针对三维目标检测定位置信度与分类置信度不一致的问题,提出了CL联合损失,使得网络倾向于选择定位置信度与分类置信度都高的3D候选框,避免了传统的NMS仅考虑分类置信度所带来的歧义问题。在KITTI三维目标检测数据集进行了实验,结果表明,该方法能够在简单、中等、困难3个难度下均获得精度的提升,从而验证了其在三维目标检测任务中的有效性。
深度学习;三维目标检测;点云语义分割;采样算法;定位置信度
随着科技的发展,自动驾驶成为了时下最热门的行业之一。自动驾驶技术以其精确、安全、可靠的特点,减少了人类手动驾驶过程中所出现的安全事故。这项技术的影响不只体现在汽车行业,且对社会发展、出行体系都带来了巨大的变革。自动驾驶行业的兴盛,离不开其关键技术之一——三维目标检测技术的发展。三维目标检测技术通过车辆上的雷达传感器和图像传感器捕获周边的环境信息,帮助车辆有效地检测并理解周边的环境,测算出其他车辆、行人等物体的方向、距离,从而帮助自动驾驶系统规划下一步车辆的行进路线。
三维目标检测技术通过雷达传感器扫描获取了三维点云数据。三维点云数据主要包含坐标信息,,和点云的反射强度信息。三维点云与图像的主要区别在于点云数据是无序、不规则、近密远疏的,而且数据量庞大。但对于三维目标检测任务来说,点云数据能提供原始的三维位置信息,使用三维信息能够帮助网络更精确地检测到物体的位置。因此,目前主流的三维目标检测方法[1-3]都是基于原始点云信息来完成的。然而,在室外大场景中,点云的数量十分庞大,约有十万到二十万不等。目前的硬件条件想要实时处理如此大规模的点云是十分困难的,因此,在处理点云之前必须使用采样算法对点云进行下采样,选取有代表性的点作为输入,用以提取特征。目前人们大多使用随机采样(random sampling,RS)来实现下采样的过程,随机采样能够实现在多个点中随机选取出固定数量的点,该方法虽然快,却具有很大的随机性。在三维目标检测任务中,点云根据其位置和语义可以被分为前景点和背景点。前景点包括车辆、自行车、行人等物体表面上的点,其余点如公路、墙面、绿化带等物体表面上的点均为背景点。如果能够采样更
多的前景点作为网络的输入,就能够提取更多的前景信息,从而有效地提升车辆、行人等前景物体的检测精度。然而,随机采样在执行过程中,并未考虑点的位置、上下文等信息,采样结果全凭随机,很难选取到大量前景点作为输入信息送入网络。本文针对这一问题,提出了基于语义分割的随机采样算法,能够在采样过程中考虑点云的分割特征,有效地选择出更多前景点作为输入。同时,针对目标检测存在的分类置信度与定位置信度不一致的问题,还提出了CL联合损失(classification-location joint loss)来帮助网络选择定位置信度与分类置信度都高的3D候选框,避免了传统的NMS仅考虑分类置信度所带来的歧义问题,有效地提升了三维目标检测任务的精度。
1 相关工作
1.1 基于图像的三维目标检测
基于图像的方法根据使用的二维图像输入数量主要分为基于单目图像的方法和基于立体视觉的方法。三维目标检测任务本质上是由二维目标检测任务延伸而来,基于图像的三维目标检测与二维目标检测也是最为相似的。然而,由于缺乏深度信息,只用二维信息来进行三维目标检测是比较困难的。现有的方法主要有2种思路来缓解缺乏深度信息的问题:①利用神经网络提取高级语义表示,求得2D检测框与3D检测框之间的映射;②结合外部深度信息进行深度推理。CHEN等[4]提出了一个简单的穷举搜索算法,生成一组3D候选框,并利用卷积神经网络对候选框进行特征提取和细化。LU等[5]利用几何先验知识将位置预测分解为二维和三维的高度估计。ZHANG等[6]将三维目标检测任务分为长宽高、深度、三维中心坐标、角度4个子任务进行,对于不同截断程度的框均有比较高的召回率。上述方法尽管有效,但还是难以弥补缺乏深度信息的缺点,因此基于图像的方法虽然速度较快,但精度普遍不高。
1.2 基于体素的三维目标检测
三维空间中的体素对应着二维空间中的像素。当三维空间被划分成一个个大小相同的体素块之后,对每个体素块内包含的点云的特征进行求和与取均值的操作,使用体素块内所有点云特征的均值作为其特征信息,如此一来,不规则的点云就被转化为了规则的体素,以便通过三维卷积神经网络有效地提取用于三维目标检测的特征。然而,此种取均值操作是用一个值代表多个点云的特征,不可避免地会造成信息的损失,尤其是那些特征值与均值差距较大的点云,其特征就被严重地“平均”了,因此精度不是很高。如果想尽量保留原始信息,就需要让体素格尽可能的小,但会大大增加体素的总体数量,从而导致计算量大幅增加。ZHOU和TUZEL[7]提出了VoxelNet,引入了VFE编码层聚合体素特征,是基于体素的三维目标检测的开创性工作。然而,由于三维卷积网络的计算量远大于二维卷积网络,因此使用普通的三维卷积会引入巨大的时间开销。后来,YAN等[8]针对VoxelNet效率低的缺点提出了稀疏嵌入卷积检测(sparsely embedded convolutional detection,SECOND),引入了稀疏卷积[9-11]来提升网络的计算速度。DENG等[12]提出了Voxel RoI池化模块,通过聚合体素特征来生成感兴趣区域(region of interest,RoI)特征,同时使用加速的PointNet[13]模块,在保证精度的同时提升了网络的计算速度。然而,由于体素化过程的局限性,基于体素的方法在精度上仍略低于点云的方法。
1.3 基于原始点云的三维目标检测
2017年文献[13]提出PointNet和文献[14]提出PointNet++之后,很多人开始使用这2种骨干网络作为三维目标检测任务的特征提取网络。因为PointNet和PointNet++可以直接从原始点云中进行特征提取,无需对点云进行体素化处理,从而最大程度地保留了物体的原始三维信息。因此,该方法相对于基于体素的方法来说,检测精度得到了提升。文献[1]提出了PointRCNN,将经典的二维目标检测算法Faster RCNN引入了三维目标检测,提出了第一个两阶段的基于原始点云的三维目标检测算法。文献[2]提出了三维单阶段目标检测器(3D single stage object detector,3DSSD),在PointNet++中的特征聚合模块(set abstraction model,SA model)中提出了一种新的融合策略,同时移除了特征传播模块(feature propagation model,FP model),提升了基于原始点云方法的计算速度。文献[3]提出了Lidar-RCNN,为解决尺度模糊问题提出了有效的解决方案。
1.4 基于图像和点云融合的三维目标检测
二维RGB图像能够提供色彩信息,是三维点云数据所无法提供的,因此一部分研究人员开始尝试融合二维信息和三维信息进行三维目标检测任务。2016年,CHEN等[15]提出多视图三维目标检测(multi-view 3D object detection,MV3D),将点云投影到鸟瞰图,使用RoI融合策略,在第二阶段融合图像和点云的特征。KU等[16]针对MV3D检测不到小物体的问题,提出了聚合视图目标检测(aggregate view object detection,AVOD),在MV3D的基础上引入了特征金字塔网络(feature pyramid networks,FPN)[17],融合了多个尺度的特征图,从而对小物体也有了比较高的召回率。VORA等[18]提出了PointPainting,使用图像语义信息来增强点云信息,从而使得点云信息更加丰富。HUANG等[19]在PointRCNN[1]的基础上提出了增强点特征网络(enhancing point features networks,EPNet),引入了图像分支来学习二维特征,并通过LI-Fusion模块对图像特征和点云特征进行融合,从而使用更丰富的特征信息来完成三维目标检测任务。
目前输入数据中包含原始点云信息的方法大都需要使用随机采样来对大量的原始点云进行下采样,以减少输入网络中的点云的数量,提升网络的运算速度。但在室外场景下,传感器扫描到的点大都属于背景点,只有少部分属于前景点。局限于RS算法本身的特性,通过RS采样出来的点中前景点占比很小。为了解决该问题,本文提出了基于语义分割的随机采样算法,改善了普通RS采样结果包含前景点较少的问题。同时,针对目标检测任务存在的定位置信度与分类置信度不一致的问题,提出了CL联合损失来监督网络的训练过程,旨在指导网络筛选出分类置信度与定位置信度都高的三维目标检测框。
2 本文方法
在点云比较稀疏的情况下,或是在雾天、雨天的场景中,仅使用点云信息进行三维目标检测是比较困难的。如图1所示,在上方的RGB图像中,可以观察到远处有一辆白色轿车,而在其对应的点云场景下,相同的位置处却难以观察到轿车的形状。因此,加入图像信息来帮助检测是十分重要的。本文算法使用了点云和图像2种信息作为输入,通过特征学习初步生成候选框,再对候选框进行细化,输出三维目标检测的最终检测结果。

图1 点云稀疏时难以预测的物体
2.1 网络模型
本文的网络结构(图2)以原始点云和RGB图像作为输入数据,输出数据为输入场景中车辆的三维目标检测框的中心点坐标(,,)、三维目标检测框的长宽高(,,)以及车辆的朝向角度。
本文算法为两阶段的算法:第一阶段提取和融合原始点云与图像的特征,通过提取的特征将场景中的点分为前景点和背景点,并且为每个前景点都生成一个初始的3D候选框;第二阶段对第一阶段生成的若干个3D候选框进行微调,删除冗余框,最终对于每一个物体,只保留一个置信度最高的候选框作为输出结果。
在第一阶段中,本文使用PointNet++[14]作为点云信息提取的骨干网络,与普通的PointNet[13]网络相比,PointNet++引入了MSG和MRG模块,能够有效地学习点云的局部多尺度特征。PointNet++中包含4个特征聚合模块和4个特征传播模块,每个特征聚合模块包含采样层、分组层和特征提取层。对于图像信息,本文以摄像机拍摄的RGB图像作为输入,输出包含丰富语义信息的不同大小的特征图。与PointNet++中的4个特征聚合模块对应,本文使用4个简单二维卷积块提取图像特征,每个卷积块包含2个3×3的卷积层、1个批量归一化(batch normalization,BN)层和1个修正线性单元(rectified linear unit,ReLU)激活层组成。并且将第2个卷积层的步长设置为2,从而扩大感受野,并且减少网络模型的计算量。本文的特征映射融合方式与EPNet[19]相同。
第二阶段的任务是对第一阶段生成的多个3D候选框进行细化和微调。第二阶段的细化网络包括3个特征聚合模块,以第一阶段生成的多个3D候选框中随机采样512个点作为细化网络的输入(点云数量不足512的则随机重采样),通过特征聚合模块后分别下采样到128,32和1,最终输出一个一维向量来表征物体的分类置信度和对于(,,,,,,)的微调目标值。
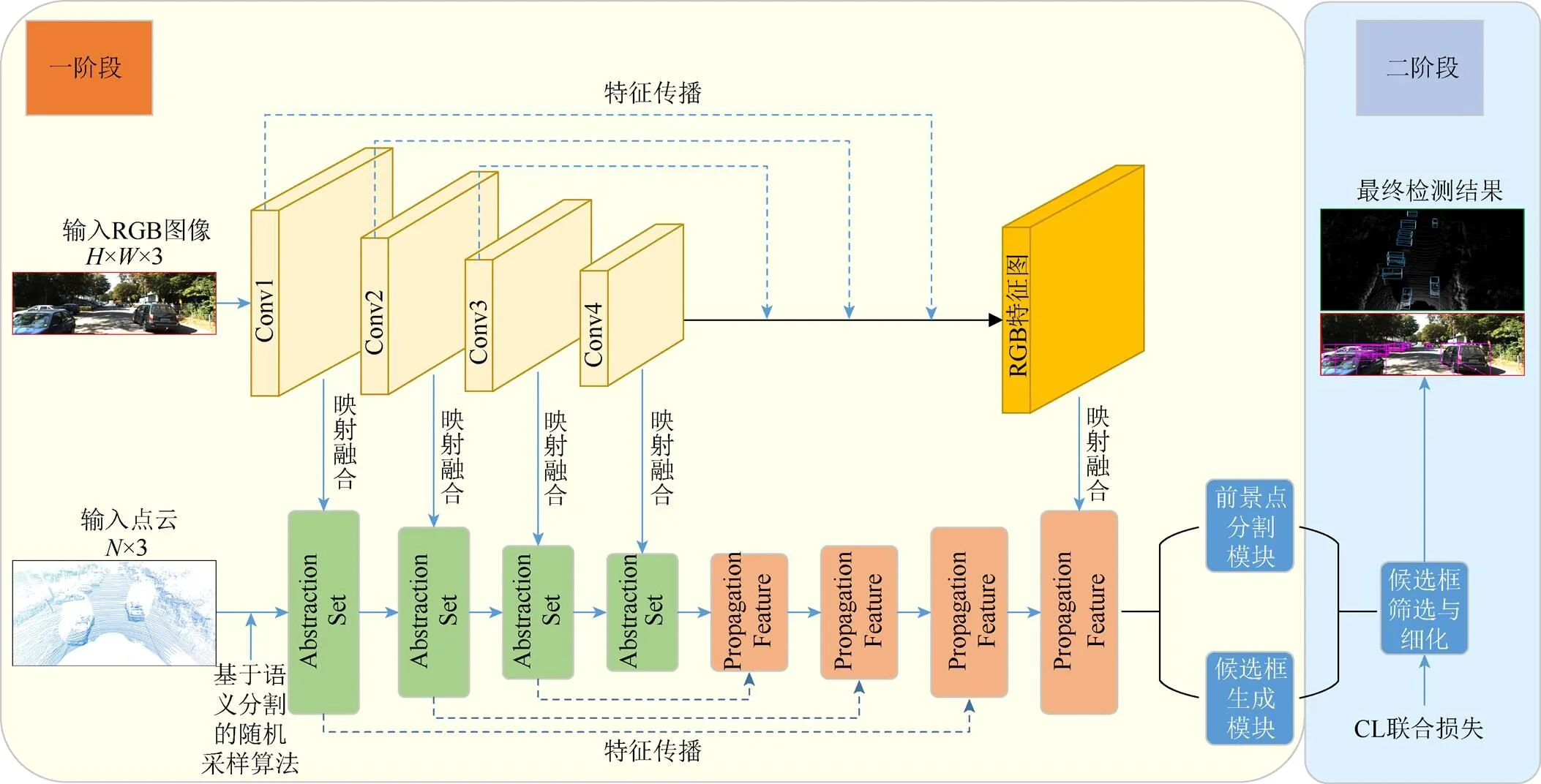
图2 本文网络结构图
2.2 基于语义分割的随机采样络模型
对于室外大型场景而言,点云的总体数量是十分庞大的。以KITTI数据集[20-21]为例,点云是环绕车辆360°采集的,一个场景内的点云数量大都在100 000~200 000之间。RGB图像是面向车辆正前方拍摄的,官方也仅提供了正前方部分的数据标注。因此,在将点云输入网络之前,首先需要将车辆正前方之外的点云删除,仅保留车辆正前方的点云。保留的点云数量大约为16 000~20 000个。然而,其中属于前景点的点云数量大约在100~5 000之间。因此,前景点的数量相对于背景点是比较稀疏的。在以往的三维目标检测方法中,人们大都使用随机采样来选取16 384个点作为网络的输入数据。虽然随机采样的计算速度快,但随机采样在点云密度低的地方采集的点数很少。如果一个物体距离采样位置很远,由于点云的稀疏性,远处物体的点云数量远小于近处物体,此时使用随机采样会导致属于远处物体的点云基本不会被采样或仅采样数量极少的点云,从而导致网络对远处物体的检测难度大大增加。
为了解决随机采样算法采样结果的前背景点数量不平衡问题,本文提出了一种基于语义分割的随机采样方法。首先,通过点云坐标的深度信息,即(,,)中值对点云进行分类,大于等于40的,视为远点;小于40的,视为近点。然后,将远点全部保留,保证原本稀疏的远点不会因为下采样而被剔除。对于近点,本文使用一个语义分割网络对点云进行分割和打分,随机采样模块中的语义分割分数为
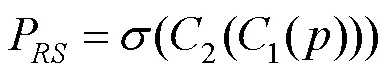
其中,为原始点云的三维坐标信息(,,);为Sigmoid激活函数;1为第一个卷积层,将点云的信息由3维升维到128维;2为第二个卷积层,将点云的信息由128维降维到1维,再通过Sigmoid函数的计算获得每个点的分割分数,前景点与背景点的期望分割分数分别为1和0。之后再对近点的分割分数进行排序,选择得分最高的2 048个近点,最后对剩余的近点进行随机采样,直至总点数达到16 384为止(若该场景没有远点,则直接从近点中选取分割得分最高的2 048个点云,再对剩余点云进行随机采样至16 384个点)。以此作为PointNet++[14]第一个特征聚合层的输入。
当然,分割模块是可以训练的。本文遵循PointRCNN[1]的方法,由于三维的物体在3D空间下是彼此之间自然分离的,因此,在数据集的标注中,3D框内部的点均可被看做是前景点,而3D框之外的点为背景点。综上,可以通过3D真值框的标注获取到物体的分割真值,即框内的点分割真值为1,框外的点为0。对于模块的训练过程,本文使用交叉熵损失来进行监督,损失函数为


通过此种方法,原本稀疏的远处物体的点云不会因为下采样而被剔除,保证了输入数据中远点的数量,进而提升了模型对于远处困难物体的检测能力。同时,近处的点也有更多的前景点送入网络进行特征学习,从而提取出丰富的前景信息,对于网络对前景物体的检测也有着很大的帮助。
2.3 CL联合损失
非极大值抑制(non-maximum suppression,NMS)算法被广泛应用于目标检测算法中,其目的是消除冗余的目标检测框,为每个物体仅保留一个检测框作为最终的检测结果。在传统的NMS算法中,检测框的分类置信度是评价其精确度的主要标准。在获取若干个检测框之后,NMS根据检测框的分类置信度从大到小进行排序,首先选择分类置信度最高的检测框,再计算其余检测框与分类置信度最高的框的交并比(intersection over union,IoU),IoU大于一定阈值的检测框会被抑制和剔除掉。
然而,在某些情况下,检测框的分类置信度并不能很好地反映框的定位准确性。如图3所示,相对于绿色的真值框而言,黄色检测框拥有很高的分类置信度,但其定位置信度却比较低,蓝色检测框的定位置信度很高,但分类置信度却低于黄色框。如果将2个框送入NMS,黄色框会被保留,且蓝色框会被判定为黄色框的冗余框从而被删除,这显然不是我们想要的结果。
为了使得定位置信度高的检测框能够被保留,YU等[22]提出了IoU损失,提升了检测框的定位置信度,从而提升了2D目标检测的效果。然而,UnitBox并未考虑分类置信度,而分类置信度是NMS算法所依赖的。针对此问题,本文提出了CL联合损失以使得网络倾向于选择分类置信度与定位置信度都比较高的3D预测框。CL联合损失为

其中,S为预测框的分类得分;为预测框的位置;为真值框的位置;为权重系数。由于S与IoU均是属于[0,1]的数,因此当损失趋近于0时,S与IoU必须均趋近于1,即分类置信度与定位置信度越高时,损失越小。
图3 分类与定位置信度不一致问题
Fig. 3 Classification and localization confidence inconsistency problem
通过使用CL联合损失,使得那些原本定位置信度高而分类置信度低的3D预测框能够在NMS的过程中得到保留,进而提升了网络输出的最终检测框的定位精度。
3 实验结果与分析
3.1 数据集与评价指标
本文使用KITTI-3D数据集[20-21]来验证和评估本文方法。对于三维目标检测任务,KITTI公开数据集包含7 481个样本。在之前的工作中[1,7],7 481个样本被分为3 712个训练样本和3 769个验证样本。因此,为了保证结果的公平性,本文按照文献[1,7]方法进行测试。本文使用KITTI数据集官方所提出的40个召回率下的平均精度均值(mean average precision,mAP)作为评价标准,同时也方便与之前的工作进行公平的比较。
3.2 实验细节
本文的网络架构如图2所示。以图像和点云作为输入数据,对于点云数据,从原始点云中采样了16 384个点作为点云分支的输入数据。对于图像分支,将输入图像裁剪或补充成大小为1280 px×384 px的图像作为输入数据。点云分支的4个SA模块分别将点云下采样到4 096,1 024,256,64个点。再使用4个FP模块恢复到16 384个点,与输入点云数量保持一致,但每个点云的信息被丰富到了128维。在这个过程中,使用三线性插值来补充没有信息或信息维度不足的点的特征。本文提出的CL联合损失的权重系数在训练过程中设置为2。
本文使用的硬件设备为4×GeForce RTX 2080 Ti显卡,每张显卡的显存为11 G。本文的2个子网络采用端到端的训练方式,训练100个epoch,batch size大小为8,优化算法为adam onecycle,初始学习率为0.002,权重衰减为0.001,momentum为0.9。本文采用了与EPNet[19]相同的数据增强方法,对输入点云沿轴随机旋转[−π/18,π/18],沿轴随机翻转,并且对真值框按照[0.95,1.05]的均匀分布进行随机缩放。
3.3 实验分析
为了验证本文方法的有效性,在KITTI val数据集[20-21]上进行了测试,与一部分主流的三维目标检测方法进行了比较,比较结果见表1。通过比较结果可知,本文方法的平均精度均值在简单、中等、困难3个难度的测试上均较之前的方法有所提升,证明了本文基于语义分割的随机采样算法和CL联合损失能够有效地提升三维目标检测任务的mAP。
图4为本文方法在KITTI val数据集上测试结果的3组可视化效果。其中,第一行为原始图像,第二行为本文方法检测结果在图像上的可视化结果,第三行为官方标注文件中的真实值的可视化效果,第四行为本文方法检测结果在点云上的可视化结果。绿色3D框为真值框,紫色框和蓝色框为预测框,3D场景中框的浅色面朝向表示物体的朝向,黄色圈中的物体是官方数据集中标注为DontCare的物体,标注为DontCare意味着该物体距离扫描设备过远导致点云十分稀疏。值得注意的是,本文算法检测出了部分被官方标记为DontCare的物体,说明本文基于语义分割的随机采样算法能够有效保留更多本身点云较为稀疏的物体的前景点。在第三列中,红色圈中的物体是本文方法预测方向错误的案例,左上方车辆检测错误的原因可能是该车辆车头与车尾形状十分相似,同时距离点云采集设备较远,点云稀疏,并且该车辆处于阴影中,RGB信息不够丰富;右侧车辆方向预测错误的原因可能是该车辆被遮挡严重,仅凭车辆顶部的点云很难预测正确该车辆的朝向。
3.4 消融实验
本文在KITTI val数据集[20-21]上进行了大量的消融实验,以验证本文方法的有效性。实验结果见表2。可以看出,在使用基于语义分割的随机采样算法之后,3D mAP指标相较于不使用提升了1.17%。说明基于语义分割的随机采样算法可以有效地选择更多的前景点作为网络的输入,从而使得网络能够学习到更加丰富的前景特征,提升网络对于前景物体的检测性能,同时最大程度地保留了远点,使得原本稀疏的远点不会因为下采样而导致丢失,提升了对远处物体的检测性能。在使用了CL联合损失之后,3D mAP指标得到了1.46%的提升。说明本文提出的CL联合损失能够帮助网络选择出定位置信度与分类置信度都比较高的3D检测框,有效减少了部分拥有很高定位置信度的3D检测框由于分类置信度较低而被NMS算法所抑制的情况。将两者一起使用时,3D mAP指标提升了1.68%,证明了本文方法的有效性。
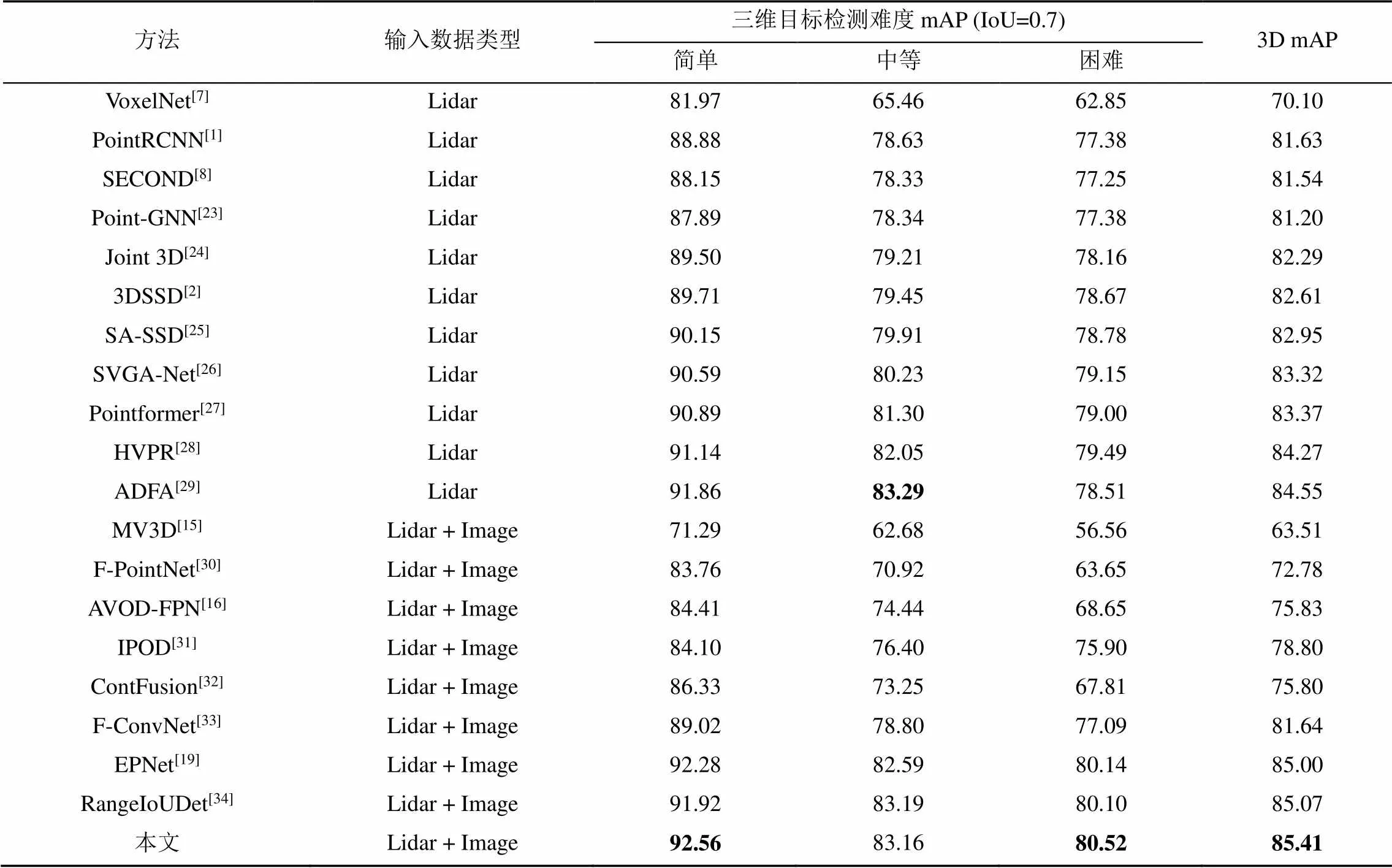
表1 KITTI val数据集三维目标检测结果对比
注:加粗数据为同等难度下的三维目标检测mAP最优值

图4 本文算法三维目标检测可视化结果((a)原图;(b)图像可视化结果;(c)真值;(d)点云可视化结果)

表2 KITTI val数据集上的消融实验
注:加粗数据为同等难度下的三维目标检测mAP最优值
针对本文提出的CL联合损失的权重系数,本文做了对应的消融实验,实验结果见表3。通过实验结果可以看出,当设为2时,可以取得最高的3D mAP值85.41%。因此本文在训练过程中将设为2。实验结果表明,在选择预测框时适当考虑定位置信度是有意义的。本文方法能够有效地选择出定位置信度与分类置信度都比较高的检测框,从而提升了三维目标检测的性能。
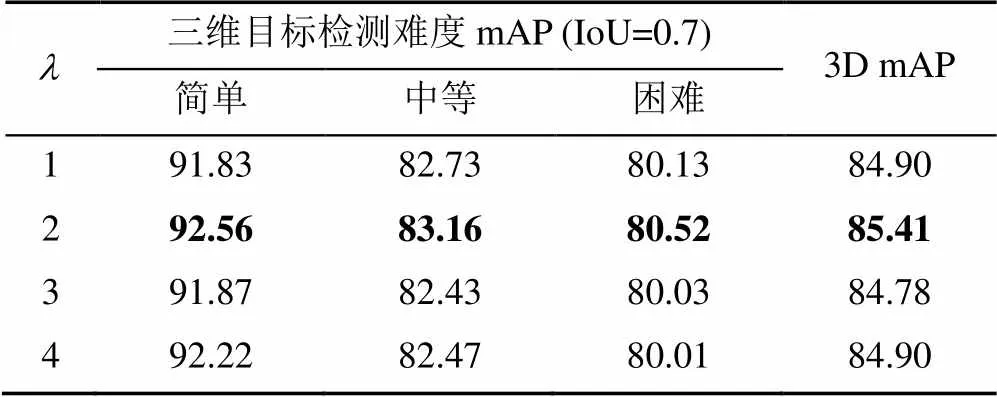
表3 CL联合损失中参数l不同值的比较
注:加粗数据为同等难度下的三维目标检测mAP最优值
4 结束语
本文针对三维目标检测中随机采样具有不确定性的问题,提出了基于语义分割的随机采样算法,得以充分利用点云的原始信息,使输入网络的点云具有更强的代表性,同时针对目标检测的定位置信度与分类置信度存在歧义的问题,提出了CL联合损失,使得网络能够选择出那些分类置信度与定位置信度都比较高的候选框,减少了拥有很高定位置信度的3D检测框由于分类置信度较低而被NMS算法所抑制的情况。本文在KITTI val数据集[20-21]上进行了大量三维目标检测的相关实验,结果表明,本文方法的三维目标检测精度高于一部分主流的三维目标检测方法,证明了其有效性。本文存在的问题是对于图像信息的利用还不足,下一步的工作重点是探究如何更好地使用图像信息,以及信息融合的新方式。
[1] SHI S S, WANG X G, LI H S. PointRCNN: 3D object proposal generation and detection from point cloud[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2019: 770-779.
[2] YANG Z T, SUN Y N, LIU S, et al. 3DSSD: point-based 3D single stage object detector[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2020: 11037-11045.
[3] LI Z C, WANG F, WANG N Y. LiDAR R-CNN: an efficient and universal 3D object detector[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2021: 7542-7551.
[4] CHEN X Z, KUNDU K, ZHANG Z Y, et al. Monocular 3D object detection for autonomous driving[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2016: 2147-2156.
[5] LU Y, MA X Z, YANG L, et al. Geometry uncertainty projection network for monocular 3D object detection[C]// 2021 IEEE/CVF International Conference on Computer Vision. New York: IEEE Press, 2021: 3091-3101.
[6] ZHANG Y P, LU J W, ZHOU J. Objects are different: flexible monocular 3D object detection[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2021: 3288-3297.
[7] ZHOU Y, TUZEL O. VoxelNet: end-to-end learning for point cloud based 3D object detection[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 4490-4499.
[8] YAN Y, MAO Y X, LI B. SECOND: sparsely embedded convolutional detection[J]. Sensors: Basel, Switzerland, 2018, 18(10): 3337.
[9] GRAHAM B. Spatially-sparse convolutional neural networks[EB/OL]. (2014-02-03) [2022-05-09]. https://arxiv. org/abs/1409.6070.
[10] GRAHAM B. Sparse 3D convolutional neural networks[EB/OL]. (2015-08-13) [2022-06-10]. https://arxiv. org/abs/1505.02890.
[11] GRAHAM B, ENGELCKE M, MAATEN L V D. 3D semantic segmentation with submanifold sparse convolutional networks[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 9224-9232.
[12] DENG J J, SHI S S, LI P W, et al. Voxel R-CNN: towards high performance voxel-based 3D object detection[EB/OL]. (2020-07-15) [2022-05-11]. https://arxiv.org/abs/2012.15712.
[13] CHARLES R Q, HAO S, MO K C, et al. PointNet: deep learning on point sets for 3D classification and segmentation[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2017: 77-85.
[14] QI C R, YI L, SU H, et al. PointNet++: deep hierarchical feature learning on point sets in a metric space[C]//The 31st International Conference on Neural Information Processing Systems. New York: ACM Press, 2017: 5105-5114.
[15] CHEN X Z, MA H M, WAN J, et al. Multi-view 3D object detection network for autonomous driving[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2017: 6526-6534.
[16] KU J, MOZIFIAN M, LEE J, et al. Joint 3D proposal generation and object detection from view aggregation[C]// 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems. New York: IEEE Press, 2018: 1-8.
[17] LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2017: 936-944.
[18] VORA S, LANG A H, HELOU B, et al. PointPainting: sequential fusion for 3D object detection[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2020: 4603-4611.
[19] HUANG T T, LIU Z, CHEN X W, et al. EPNet: enhancing point features with image semantics for 3D object detection[M]//Computer Vision - ECCV 2020. Cham: Springer International Publishing, 2020: 35-52.
[20] GEIGER A, LENZ P, URTASUN R. Are we ready for autonomous driving? The KITTI vision benchmark suite[C]//2012 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2012: 3354-3361.
[21] GEIGER A, LENZ P, STILLER C, et al. Vision meets robotics: the KITTI dataset[J]. The International Journal of Robotics Research, 2013, 32(11): 1231-1237.
[22] YU J H, JIANG Y N, WANG Z Y, et al. UnitBox: an advanced object detection network[C]//The 24th ACM International Conference on Multimedia. New York: ACM Press, 2016: 516-520.
[23] SHI W J, RAJKUMAR R. Point-GNN: graph neural network for 3D object detection in a point cloud[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2020: 1708-1716.
[24] ZHOU D F, FANG J, SONG X B, et al. Joint 3D instance segmentation and object detection for autonomous driving[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2020: 1836-1846.
[25] HE C H, ZENG H, HUANG J Q, et al. Structure aware single-stage 3D object detection from point cloud[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2020: 11870-11879.
[26] HE Q D, WANG Z N, ZENG H, et al. SVGA-net: sparse voxel-graph attention network for 3D object detection from point clouds[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2022, 36(1): 870-878.
[27] PAN X R, XIA Z F, SONG S J, et al. 3D object detection with pointformer[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2021: 7459-7468.
[28] NOH J, LEE S, HAM B. HVPR: hybrid voxel-point representation for single-stage 3D object detection[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2021: 14600-14609.
[29] LI J L, DAI H, SHAO L, et al. Anchor-free 3D single stage detector with mask-guided attention for point cloud[C]//The 29th ACM International Conference on Multimedia. New York: ACM Press, 2021: 553-562.
[30] CAO P, CHEN H, ZHANG Y, et al. Multi-view frustum pointnet for object detection in autonomous driving[C]//2019 IEEE International Conference on Image Processing. New York: IEEE Press: 3896-3899.
[31] YANG Z T, SUN Y N, LIU S, et al. IPOD: intensive point-based object detector for point cloud[EB/OL]. (2018-01-25) [2022-04-28]. https://arxiv.org/abs/1812.05276.
[32] LIANG M, YANG B, WANG S L, et al. Deep continuous fusion for multi-sensor 3D object detection[M]//Computer Vision - ECCV 2018. Cham: Springer International Publishing, 2018: 663-678.
[33] WANG Z X, JIA K. Frustum ConvNet: sliding Frustums to aggregate local point-wise features for amodal 3D object detection[C]//2019 IEEE/RSJ International Conference on Intelligent Robots and Systems. New York: IEEE Press, 2019: 1742-1749.
[34] LIANG Z D, ZHANG Z H, ZHANG M, et al. RangeIoUDet: range image based real-time 3D object detector optimized by intersection over union[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2021: 7136-7145.
3D object detection based on semantic segmentation guidance
CUI Zhen-dong1, LI Zong-min1,2, YANG Shu-lin2, LIU Yu-jie1, LI Hua3,4
(1. College of Computer Science and Technology, China University of Petroleum, Qingdao Shandong 266580, China; 2. College of Big Data and Basic Science, Shandong Institute of Petroleum and Chemical Technology, Dongying Shandong 257061, China; 3. Key Laboratory of Intelligent Information Processing, Institute of Computing Technology, Chinese Academy of Sciences, Beijing 100190, China; 4. School of Computer Science and Technology, University of Chinese Academy of Sciences, Beijing 100049, China)
3D object detection is one of the most popular research fields in computer vision. In the self-driving system, the 3D object detection technology detects the surrounding objects by capturing the surrounding point cloud information and RGB image information, thereby planning the upcoming route for the vehicle. Therefore, it is of great importance to attain the accurate detection and perception of the surrounding environment. To address the loss of foreground points incurred by random sampling in the field of 3D object detection, a random sampling algorithm based on semantic segmentation was proposed, which guided the sampling process through the predicted semantic features, so as to increase the sampling proportion of foreground points and heighten the precision of 3D object detection. Secondly, to address the inconsistency between the location confidence of 3D object detection and the classification confidence, the CL joint loss was proposed, leading the network to select the 3D bounding box with high location confidence and classification confidence, so as to prevent the ambiguity caused by the traditional NMS only considering the classification confidence. Experiments on KITTI 3D object detection datasets show that the proposed method can improve the precision at the three levels of difficulties: easy, moderate, and hard, which verifies the effectiveness of the method in 3D object detection task.
deep learning; 3D object detection; point cloud semantic segmentation; sampling algorithm; location confidence
TP 391
10.11996/JG.j.2095-302X.2022061134
A
2095-302X(2022)06-1134-09
2022-07-21;
:2022-09-30
国家重点研发计划项目(2019YFF0301800);国家自然科学基金青年基金项目(61806199);国家自然科学基金项目(61379106);山东省自然科学基金项目(ZR2013FM036,ZR2015FM011);中国石油大学(华东)研究生创新基金项目(22CX04037A)
崔振东(1997-),男,硕士研究生。主要研究方向为三维目标检测与深度学习。E-mail:z20070047@s.upc.edu.cn
李宗民(1965-),男,教授,博士。主要研究方向为计算机图形学、数字图像处理与模式识别。E-mail:lizongmin@upc.edu.cn
21 July,2022;
30 September,2022
National Key Research and Development Program of China (2019YFF0301800); Youth Fund of National Natural Science Foundation of China (61806199); National Natural Science Foundation of China (61379106); Natural Science Foundation of Shandong Province (ZR2013FM036, ZR2015FM011); Innovation Fund Project for Graduate Student of China University of Petroleum (East China) (22CX04037A)
CUI Zhen-dong (1997-), master student. His main research interests cover 3D object detection and deep learning. E-mail:z20070047@s.upc.edu.cn
LI Zong-min (1965-), professor, Ph.D. His main research interests cover computer graphics, digital image processing and pattern recognition. E-mail:lizongmin@upc.edu.cn
