人脸识别任务驱动的低光照图像增强算法
2023-01-13范溢华王永振燕雪峰宫丽娜郭延文魏明强
范溢华,王永振,燕雪峰,宫丽娜,郭延文,魏明强
人脸识别任务驱动的低光照图像增强算法
范溢华1,王永振1,燕雪峰1,宫丽娜1,郭延文2,魏明强1
(1. 南京航空航天大学计算机科学与技术学院,江苏 南京 210016;2. 南京大学计算机软件新技术国家重点实验室,江苏 南京 210023)
图像容易受外界照明条件的影响或相机参数条件的限制,导致图像整体偏暗、视觉效果不佳,降低了下游视觉任务的性能,从而引发安全问题。以人脸识别任务为驱动,提出了一种基于对比学习范式的非成对低光照图像增强算法Low-FaceNet。Low-FaceNet主干采用基于U-Net结构的图像增强网络,引入特征保持、语义分割和人脸识别3个子网络辅助图像增强网络的训练。使用对比学习范式可以使得真实世界大量非成对的低光照和正常光照图像作为负/正样本,提高了真实场景的泛化能力;融入高阶语义信息,可以指导低阶图像增强网络更高质量地增强图像;任务驱动可以增强图像的同时提升人脸识别的准确率。在多个公开数据集上进行验证,可视化与量化结果均表明,Low-FaceNet能在增强图像亮度的同时保持图像中各种细节特征,并有效地提升低光照条件下人脸识别的准确率。
低光照图像增强;人脸识别;对比学习;任务驱动;语义分割
视觉信息在人类所接收的各种复杂信息中占据80%以上的比例,由此可见图像信息是一种不可或缺的传播媒介[1]。随着科技水平的不断提升和各种拍摄设备的普及与日益便携化,图像在人类社会中发挥着愈发重要的作用,每个人都在成为图像的创造者与传播者。然而,受外界照明环境影响或技术条件限制,拍摄的图像往往会出现曝光不足、对比度低、细节丢失等问题,此类图像即被称为低光照图像。低光照图像增强技术旨在对低亮度、低对比度、噪声、伪影等问题进行处理,以改善图像质量,并在处理过程中尽可能保持图像的细节特征,以满足特定场景的需求。
低光照图像增强方法可以分为传统基于先验的方法和基于深度学习的方法。
早期传统方法主要包括基于直方图均衡和基于Retinex模型的方法。直方图均衡方法将图像的直方图分布限制在一定范围内,使其趋近于均匀分布,提高原始低光照图像的对比度。PIZER等[2]使用累积分布函数来调整图像的像素值,以使整张图片的像素强度值均匀化。后续进一步衍生出自适应的直方图均衡方法。LAND[3]提出的Retinex理论为低光照图像增强领域奠定了重要的理论基础。Retinex是一个由视网膜(retina)和大脑皮层(cortex)构成的合成词。该理论认为捕获的图像可以分解成光照图和反射图。由于光照图是随着外界环境会发生变化的量,而反射图是物体的本质属性,因此基于Retinex的方法通常是通过求解反射图来获得增强图像。GUO等[4]基于Retinex提出了低光照图像增强(low-light image enhancement,LIME)方法,其利用RGB三通道的最大像素值来估算光照图的像素值,再利用结构先验调节光照图进行图像增强。不同于一般基于Retinex的方法需要同时计算反射分量与光照分量,该方法仅通过预测光照分量,就能达到预期效果,减少了计算成本。
近年来,随着深度学习的飞速发展,利用深度学习方法进行低光照图像增强任务取得了开创性的成功,相较于传统方法,基于深度学习的方法具有更好的准确性、鲁棒性和计算效率。根据算法所使用的学习策略,基于深度学习的低光照图像增强方法又可以分为监督学习、无监督学习与半监督学习等。
在主流的监督学习方法中,低光照网络(low-light network,LLNet)[5]是第一个采用深度学习方法在低光照图像增强任务上的成功尝试。在此模型的基础上,提出了多分支低光照增强网络(multi-branch low-light enhancement network,MBLLEN)[6]和边缘增强多曝光度融合网络(edge-enhanced multi-exposure fusion network,EEMEFN)[7]等方法。WEI等[8]提出的Retinex网络(Retinex network,Retinex-Net)将Retinex理论与深度网络结合起来。FAN等[9]在Retinex模型中融入语义信息,使用语义信息来引导反射分量的重建并估计噪声,进一步提升增强效果。尽管上述方法能够取得较好的增强效果,但由于此类方法只能使用合成的数据进行训练,而真实数据和合成数据间存在的领域鸿沟会导致这类方法在真实数据上泛化性差。为此,一些方法开始探索采集真实数据用于网络训练或生成更加真实的训练数据。CHEN等[10]建立了一套真实的低光照图像数据集,并训练网络寻找从低光照图像到长曝光高质量图像的映射。CAI等[11]建立了一个多曝光度图像数据集,称之为单一图像对比度增强(single image contrast enhancement,SICE),不同曝光的低对比度图片有其对应的高质量参考图片,这些参考图片是通过不同方法增强后择优选出的。
为解决在合成数据集上训练成对数据可能导致的过拟合和泛化性差等问题,JIANG等[12]提出了低光照图像增强领域中第一个基于非成对数据训练的照亮生成对抗网络(enlighten generative adversarial network,EnlightenGAN)。GUO等[13]提出了零参考深度曲线估计(zero-reference deep curve estimation,Zero-DCE)方法,将低光照图像增强重新定义为图像特定曲线的估计问题,而非建立低光照图像到正常图像的映射问题。
为了同时兼具监督学习与无监督学习两者的优点,YANG等[14]设计了一种基于半监督学习框架的深度递归带状网络(deep recursive band network,DRBN)。此方法通过训练成对数据集来恢复图像的细节,并采用对抗学习训练非成对数据集,提高了图像的光照、颜色等视觉感知质量。
本文将低光照图像增强任务与人脸识别任务相结合,设计了非成对的低光照人脸图像增强网络(low-light face image enhancement network,Low-FaceNet),采用对比学习范式提升模型的泛化性,并在其中加入提取出的高阶语义信息,解决了同类型算法可能带来的局部曝光不均匀等问题,同时能够有效提升人脸识别任务的性能。
针对目前监督学习方式存在的难以获取大规模的成对数据集及低光照图像增强过程的不适定性难题,本文提出了一种非成对的低光照图像增强方法Low-FaceNet。
1 算法概述
LEE等[15]指出现有方法通常只将图像增强作为预处理方法,未与下游的高级视觉任务结合起来,从而导致增强后的图像对视觉任务性能的提升并不明显,甚至没有作用。针对上述问题,本文面向人脸识别应用,提出一种以人脸识别任务为驱动的非成对低光照图像增强网络,称为Low-FaceNet,将低阶图像增强任务与高阶人脸识别任务结合起来,以联合学习的方式优化2个任务,使其相互促进。Low-FaceNet主干采用基于U-Net结构的图像增强网络,使用对比学习,融入高阶语义信息,增强图像的同时提升人脸识别的准确率。
图1为本文提出的低光照图像增强方法Low-FaceNet的网络架构图,使用对比学习损失、特征保持损失、语义亮度一致性损失和人脸识别损失函数共同约束网络的训练。
图2为低光照图像增强主干网络的层次结构图,采用基于U-Net的网络架构,其中包含7个卷积、激活模块和8个迭代增强模块,采用端到端的方式训练网络。

图1 Low-FaceNet网络架构图
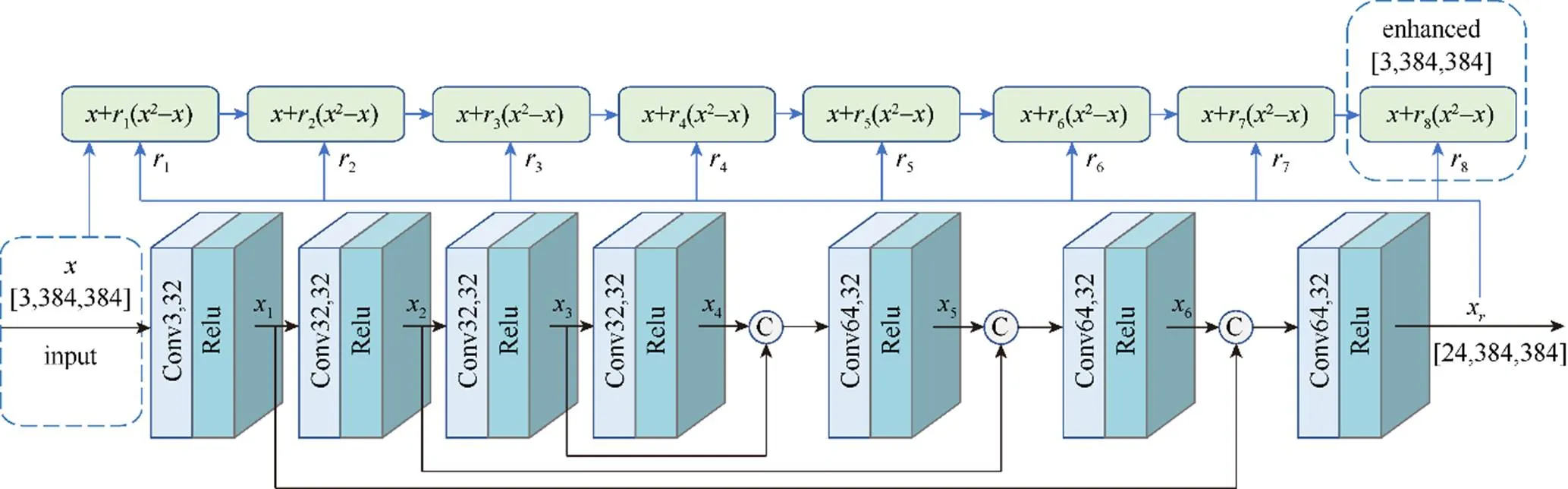
图2 低光照图像增强网络层次图
2 基于对比学习的低光照图像增强网络
现有基于深度学习的低光照图像增强方法大都采用监督学习方式,需要使用带有标签的数据进行训练,即同时需要低光照和其对应的正常光照图像。然而受环境光和相机参数的影响,在同一场景同时获得低光照和正常光照的图像十分困难。因此,本文采用对比学习范式,直接基于真实世界正常光照/低光照图像构建正/负样本,并利用对比学习在特征空间中将增强后的图像与正样本拉进,从而远离负样本。所提出的对比学习框架借助提取的特征信息保留了增强图像中不同尺度的细节信息,并利用高阶语义信息解决了增强图像中可能存在的曝光不均匀问题。最后,将低光照图像增强与人脸识别任务相结合,采用人脸识别损失使增强后的结果能有效提升识别准确率,从而实现了完整的低光照图像增强流程。
2.1 基于对比学习的亮度恢复
对比学习的基本思想是在特征空间中学习一种特征表示,将相关联的特征(正样本)拉近,同时远离不相关的特征(负样本),从而学习到不同样本间的特征表示,更好地服务于目标任务。对于低光照图像增强任务,对比学习可表示为

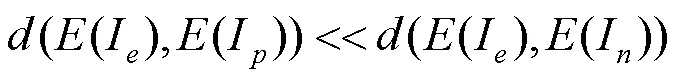
其中,I为增强图像;I为正样本(正常光照图像);I为负样本(低曝光图像);为Gram矩阵;为平均亮度值;为距离。式(1)表示基于对比学习的特征恢复;式(2)表示基于对比学习的亮度恢复。
本文采用预训练好的Vgg-16网络来提取图像特征,使用Gram矩阵定量描述图像的潜在特征


为了从低光照图像中更好地恢复出正常光照图像,本文采用真实世界非成对的正常光照图像和低光照图像作为正负样本,并通过对比学习范式将增强后的图像的特征与正样本进行拉近,同时远离负样本。其示意图如图3所示。
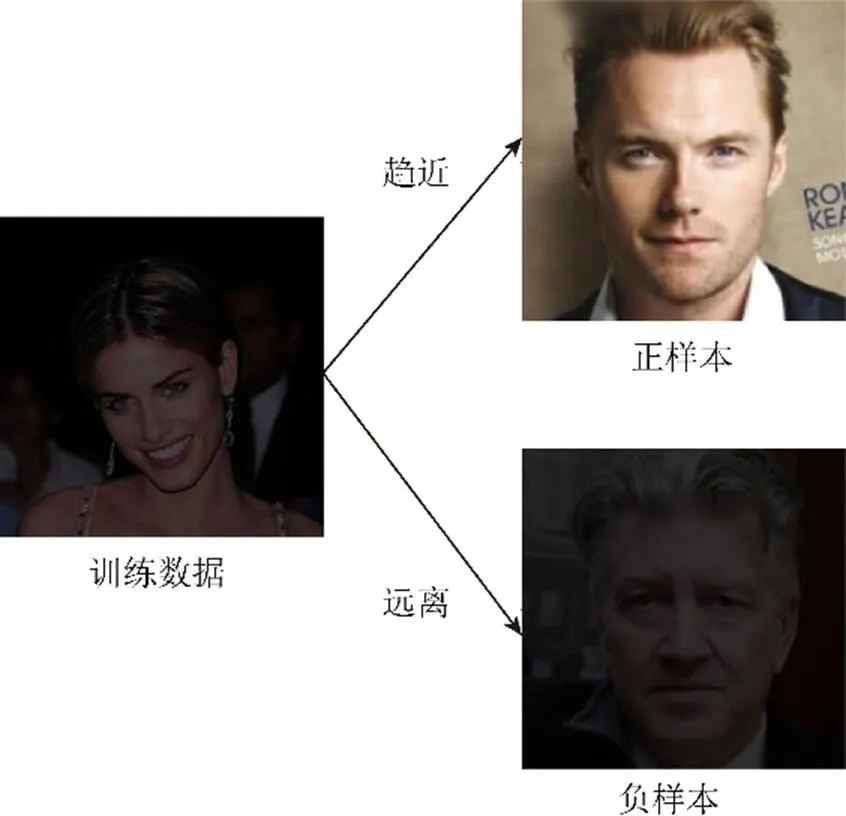
图3 对比学习示意图
因此,对比学习损失可以表示为

其中,α和β为常数,在训练时分别被设置成0.04和0.30,λ和λ分别为相应损失的权重系数,在训练时分别被设置成1.0和1.4。
LI等[16]指出对比学习范式用于视觉任务中,能通过随机性学习到更多信息。为进一步提高模型的鲁棒性,本方法在训练过程中,每次迭代都随机选取正负样本。
2.2 语义亮度一致性约束
为更好地保留增强图像的细节特征,本文考虑利用高阶语义信息来指导网络进行训练,提出了一种语义亮度一致性损失,该约束可以保证增强图像中相同的语义类别亮度保持一致。此外,采用该约束也能在一定程度上解决增强后图像存在的局部曝光不足和曝光过度问题。
在真实场景中,属于同一语义类别下的像素通常分布在相邻的位置,并且应该具有相似的亮度水平,而现有的低光照图像增强方法往往使得增强图像出现局部曝光不均匀的问题。基于此现象,本文定义了每个语义类别中像素的平均亮度为即
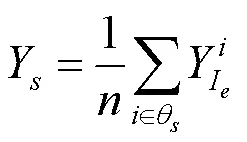
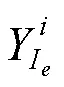
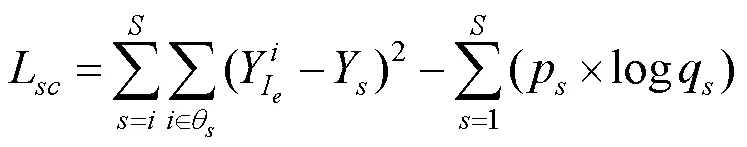
其中,为语义标注真值图片中包含的语义类别数量;p为第个语义类别的类别真值;q为第个语义类别的类别预测值,其权重系数为1.0。
2.3 特征保持约束
鉴于感知损失(perceptual loss)可以使经过处理后的图像与原始图像在感知上保持一致,本文使用感知损失使图像在增强前后的特征保持一致。特征保留损失为

其中,(I)为输入图像第l层的特征映射;(I)为经过网络增强后的图像在第l层的特征映射。
在低光照图像增强领域中,尤其需要关注颜色的自然性。BUCHSBAUM[17]于1980年提出基于灰色世界的颜色恒定假设,即3个通道的像素平均值往往具有相同的数值。本文基于这一假设提出一种颜色一致性损失L,其限制了3个通道像素值的比例,以防止增强图像中出现颜色偏差问题。其表达式为
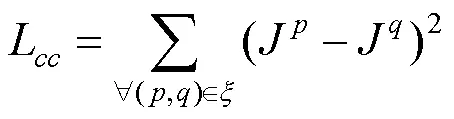
其中,为图片的通道,可取值范围为{R, G, B};(,)为一组通道;为增强图像的通道的像素平均值。
此外,为避免相邻像素之间出现急剧变化,本文还使用总变分损失(TV loss)促进增强图像的空间平滑性。其表达式为
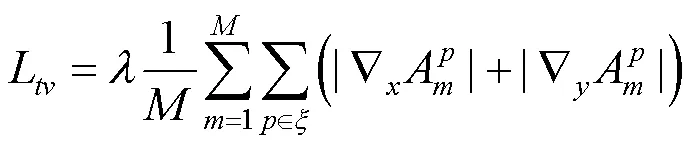
感知损失L、颜色一致性损失L与总变分损失L共同组成了特征保持损失,即

其中,λ,λ,λ为相应损失的权重系数。在实验中,将λ的值设置为1.0,λ的值设置为1.0,λ的值设置为200以达到最佳的实验结果。
2.4 人脸识别约束
为了使低阶的低光照图像增强任务能够更好地服务于高阶人脸识别任务,本文提出了以人脸识别任务为驱动的深度学习框架。首先使用正常光照的人脸数据集预训练识别网络,然后将其引入到低光照图像增强网络中作为一个子模块,并固定其权重,辅助低光照图像增强主干网络的训练。
鉴于交叉熵损失函数已广泛应用于各种分类任务中,而人脸识别任务本质上也属于分类任务,因此本文采用交叉熵损失函数作为人脸识别任务的损失函数。
人脸识别的具体流程如图4所示。首先将训练集中包含的每个人都选一张人脸图像放入人脸数据库中;然后进行编码,编码结果包括人名和人脸特征的2个部分,其中人脸特征的编码需要使用人脸检测网络与人脸识别网络实现;接下来将当前待识别的人脸图像通过人脸识别网络,得到当前待识别人脸图像的特征向量,并将此特征向量与先前数据库中编码得到的人脸特征计算余弦距离,并将余弦距离最大值所对应的索引作为预测结果,其真值为当前人脸的实际身份在人脸数据库中的索引。

图4 人脸识别流程图
通过余弦距离与身份真值即可计算出人脸识别损失,即

其中,为人脸数据库中包含的人脸总数;p为人脸身份真值;q为人脸身份预测值,其权重系数为1.0。
2.5 总损失
本文设计的低光照图像增强网络Low-FaceNet在训练过程中由上文所述的4项损失函数共同约束,分别为对比学习损失L、语义亮度一致性损失L、特征保持损失L以及人脸识别损失face。总损失函数为

其权重系数均为1.0。
3 人脸识别应用
从门禁解锁、电子支付到高铁安检、医院就医等,人脸作为生物特征逐渐成为人们进入万物互联世界的数字身份证。人脸检测与识别具有广阔的发展前景,从2005年左右,人脸检测技术逐渐迈入实际应用阶段,在数码相机与数字监控等应用领域兴起。2014年,随着深度卷积神经网络技术的逐渐发展,人脸识别技术逐渐成熟,并在安全、金融、民生、政务等诸多领域得到了应用[18]。
3.1 人脸检测
人脸检测是在给定图像上定位并标注出人脸所在位置的技术,是后续进行人脸识别、人脸解析等相关任务的必要前提步骤。本文使用由Insightface团队提出的one-stage人脸检测网络RetinaFace[19]进行人脸检测,使用了大规模人脸检测数据集WIDER FACE[20]进行预训练。
为了解决人脸检测中多尺度的问题,RetinaFace算法的特征提取网络使用FPN特征金字塔结构,可以有效改善模型的小尺度检测性能,且几乎不需要增加计算量。图5共使用了从2到6特征金字塔的5个等级。2到5是由相应的残差连接网络的输出特征图(2至6)分别自上而下和横向连接计算得到的,6是5采用步长为2、大小为3×3的卷积核进行卷积采样得到的。1到5使用了预训练于ImageNet-11数据集的ResNet-512网络的残差层,通过Xavieer方法随机初始化6的卷积层[21]。
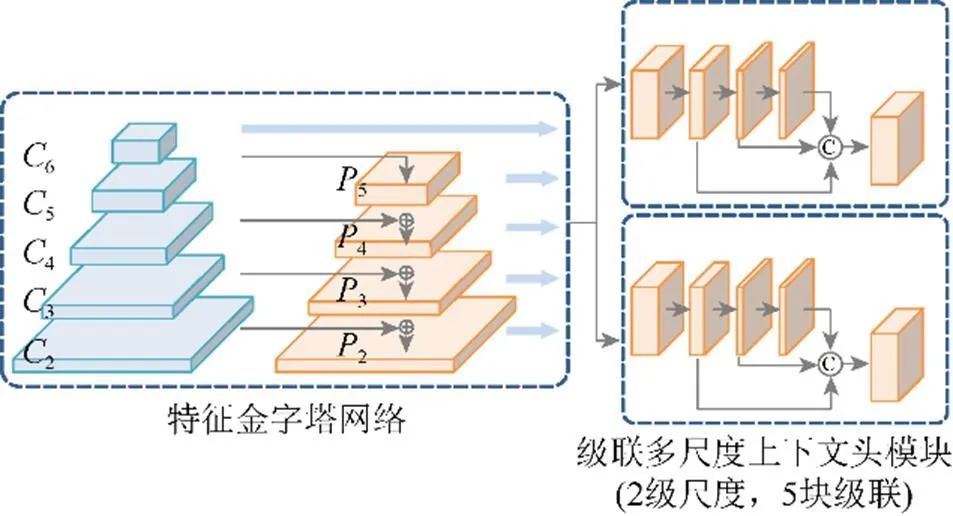
图5 RetinaFace网络结构
3.2 人脸识别
人脸识别使用谷歌团队于2015年提出的FaceNet[22]网络,由于同一人脸在不同的角度或姿态条件下,图像的内聚程度较高,而不同人脸图像之间的耦合程度较低。因此,采用卷积神经网络将人脸映射到欧式空间的特征向量上,训练时基于同一个体的人脸距离总是比不同个体的人脸距离小这一先验知识。图6为FaceNet人脸识别网络的总体流程图。
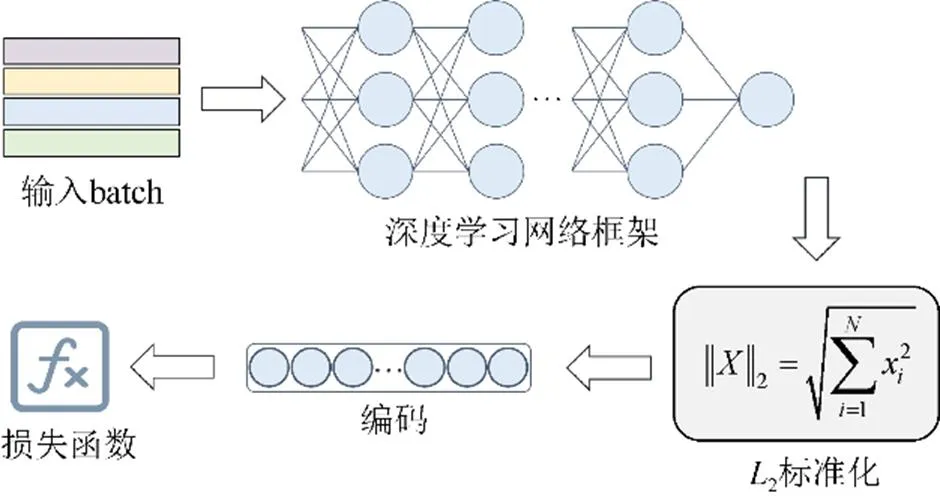
图6 FaceNet人脸识别网络流程图
具体来说,本文使用经过图像剪裁、人脸校正的CASIA-WebFace[23]数据集预训练人脸识别网络FaceNet,其主干网络用于提取特征。原始的FaceNet使用Inception-ResNetV1作为主干特征提取网络,本文使用MobilenetV1网络,该网络是Google提出的一种轻量级深层神经网络,主要应用于手机等嵌入式设备,其核心思想是深度可分离卷积块。深度可分离卷积块包括深度可分离卷积(通常设置为3×3)和1×1普通卷积2个部分,深度可分离卷积相比于普通的3×3卷积使用的参数量更小,主要用于特征提取,通道数的调整则依赖于1×1的普通卷积。
将通过特征提取主干网络得到的特征层进行平均池化、全连接,可以得到一个128维的特征向量。接着进行2标准化,其作用是使得不同个体人脸的特征向量处于同一数量级,便于后续的特征比对。首先需要计算2范数,或称为欧几里得范数,即向量元素绝对值的平方之和再开方

2标准化即将向量中的每个元素除以2范数。
FaceNet使用三重态损失(triplet loss)作为损失函数,即为

其中,为待识别图像通过网络得到的128维人脸特征向量;为与待识别图像属于同一个体的图像通过网络得到的128维人脸特征向量;为与待识别图像属于不同个体的图像通过网络得到的128维人脸特征向量;为欧几里得距离。本文希望网络学习到同一个体不同图像的人脸特征向量之间的欧几里得距离尽可能接近,而不同个体图像的人脸特征向量之间的欧几里得距离尽可能远离。
但是,网络在仅使用三重态损失进行训练的情况下难以收敛,于是本文额外使用了交叉熵损失,表达式见式(11),用于辅助网络收敛。二者共同构成了人脸识别网络训练的损失函数。
4 实验及结果分析
为了从多方面对本文提出的低光照图像增强方法Low-FaceNet进行评价,在选择数据集时考虑了数据的多样性与质量情况。在实验中,首先对语义分割子模块进行性能评价,接着对任务驱动技术的有效性进行验证;之后进行对比实验,从可视化结果和量化指标结果2个方面验证本方法的优越性;最后进行消融实验,验证本文提出的模块、损失函数及所使用的对比学习负样本的有效性,并定量分析各个部件对实验结果的贡献大小。
4.1 数据集与实验设置
4.1.1 数据集
LaPa[24]是京东人工智能发布的数据集,共有22 176张彩色图像,以及与之对应的语义标签图像和关键点信息。其中,训练集、验证集、测试集分别有18 176,2 000和2 000张图像。此数据集用于训练语义分割网络DeepLabV3+[25]。由于LaPa数据集中人名标签存在很多谬误,需要手动挑选改正。原始的训练集经过挑选改正,并划分训练集与测试集。改正后的训练集有4 000张,其中包含2 185组人脸图像,有1 146组包含多张同一个体的图像;测试集有1 789张图像,其中包含1 313组人脸图像,有362组包含多张同一个体的图像。本文将挑选改正后的数据集称为LaPa-Face,暗化处理之后用于训练低光照图像增强主干网络。
CelebA-HQ数据集是高分辨率的人脸图像数据集。从中挑选了360张图像作为对比学习的正样本,并对图像进行暗化处理,得到对应的360张曝光不足的图像作为负样本。此外,在测试阶段另外挑选1 000张图像作为评价增强图像质量的标准图像,经过暗化处理之后作为测试数据集。
WIDER FACE[20]是人脸检测的一个基准数据集,该数据集共计有393 703个带标注的人脸,32 203张图像。其中,训练集有158 989个标注人脸,验证集有39 496个标注人脸,用于训练人脸检测网络RetinaFace[19]。
CASIA-WebFace是当时数据量最大的公开人脸识别数据集,总计10 575个人脸,494 414张图像。本文使用经过剪裁和校正之后的数据集训练人脸识别网络FaceNet,此外,为了验证人脸识别任务驱动方案的有效性,将经过人脸剪裁和校正的数据集暗化处理后再次训练人脸识别网络。
LFW数据集中共有13 000余张人脸图像,其中有1 680组包含2张及以上同一个体的人脸图像,在评价人脸识别算法的性能方面有广阔的应用。在本文中用于评价人脸识别的性能并测试低光照图像增强方法对于人脸识别任务准确率的提升情况。
CASIA-FaceV5是由500个人组成的亚洲人脸数据集,其中每个人包含5张图像,共计2 500张图像。本文仅使用数据集第一部分的100个人,共500张作为测试集。
4.1.2 实验设置
本文在一台配备了Intel(R) Core(TM) i7-4770 CPU (主频3.40 GHz),16.0 GB DDR3内存和NVIDIA GeForce GTX TITAN X的台式计算机上进行实验。将训练集的图像重新调整变换成384×384大小的图片。将训练过程的epoch设置为50,batch size设置为2,学习率固定设置为0.000 1,模型基于PyTorch框架实现,使用Adam优化器。数据集的暗化处理是通过将图像的像素值整体下调一定的比例实现的。
4.2 语义分割网络性能评估
作为本文提出的低光照图像增强网络中的一个子网络,语义分割网络提供的语义高阶信息更好地引导了低光照图像增强网络的训练过程。在本节中,对语义分割模块进行定性和定量的评价。
4.2.1 可视化结果
图7和图8为语义分割网络的可视化结果。由可视化结果可以看出,本文训练的语义分割网络可以正确地进行语义分类。

图7 语义分割预测结果示例1((a)输入;(b)预测;(c)真值)

图8 语义分割预测结果示例2((a)输入;(b)预测;(c)真值)
4.2.2 量化结果
本文使用像素准确率(pixel accuracy,PA)、平均像素准确率(mean pixel accuracy,MPA)、平均交并比(mean intersection over union,MIoU)、加权交并比(frequency weighted intersection over union,FWIoU)等4项准确率评价指标评估所训练的语义分割网络的性能。共训练100个epoch,在每个epoch训练完成后使用4项指标进行评价,根据指标数值选择第96个epoch的结果作为最终结果。表1为语义分割网络epoch 96的准确率评价指标结果。
4.3 以人脸识别任务驱动的有效性验证
为验证本文以人脸识别任务作为驱动的低光照图像增强方法的有效性,特提出了如下验证方案:首先,使用正常光照的原始训练数据集训练人脸识别网络,记为FaceNet1,同样使用正常光照的测试数据集通过此人脸识别网络,计算人脸识别准确率,作为人脸识别准确率上限;然后,使用暗化处理之后的低光照训练数据集训练人脸识别网络,记为FaceNet2,同样使用暗化处理之后的低光照测试数据集通过此人脸识别网络,计算人脸识别准确率,作为人脸识别准确率下限;之后,使用不同的增强方法对低光照数据集进行增强,将增强结果通过FaceNet1(因为此时是接近于正常光照的图像),计算人脸识别准确率。若此时得到的人脸识别准确介于人脸识别准确率上、下限之间,就能够说明本方案的有效性。

表1 语义分割准确率评价指标结果
本文分别在3个测试数据集上进行了人脸识别准确率的测试,分别为LaPa-Face数据集的测试部分、CASIA-FaceV5 (仅使用第一部分的500张图像)以及LFW数据集(下同)。为叙述方便,将亮训练、亮测试(上限)的情况标记为up,将暗训练、暗测试(下限)的情况标记为low,得到的人脸识别准确率对比结果见表2。

表2 任务驱动方案有效性验证实验结果(%)
由表2可知,本文方法对输入的低光照图像进行增强后,再通过人脸识别网络FaceNet1计算的人脸识别准确率介于上文所述的准确率上、下限之间,并且与准确率上限之间的差距较小,可说明本文提出的以人脸识别任务驱动方案的有效性。
4.4 对比实验
4.4.1 可视化结果
据本文调研,现有的低光照图像增强方法大都基于自然场景图像的增强,不能直接将这些方法应用于人脸数据集,进行对比实验时,需要将每种方法通过本文提出的人脸数据集LaPa-Face重新训练后再进行比较。本文选取Zero-DCE[13]方法、RUAS[26]方法与本方法进行比较。Zero-DCE方法是基于深度卷积神经网络的方法,与本文方法使用相同的低光照图像增强主干网络;RUAS方法则是将传统的Retinex方法与深度学习相结合的典型方法。图9和图10为对比实验的可视化结果。

图9 对比实验可视化结果对比示例1

图10 对比实验可视化结果对比示例2
由以上可视化结果对比可以看出,Zero-DCE方法丢失了许多细节信息,并且存在曝光过度问题;RUAS方法虽然能较好地保持图像的色彩与细节,但存在局部曝光的问题(如面部),不利于人脸识别系统的面部识别;而本文方法在增强图像的同时能够保持图像中各种尺度的细节信息。
4.4.2 人脸识别准确率对比
表3为对比实验的人脸识别准确率结果。

表3 对比实验人脸识别准确率对比(%)
注:加粗数据为最优值
由表3可知,本文方法在3个测试数据集上的人脸识别准确率基本优于其他方法。其中RUAS在CASIA-FaceV5上的准确率略高于本文方法,经过分析,其原因在于此数据集的平均亮度处于较低的水平,而RUAS方法使得一般的增强图像出现曝光过度问题,导致此数据集的增强结果较为合适,从而人脸识别的准确率较高。
4.4.3 图像质量评价指标对比
除了人脸识别准确率的对比,本文同样关注增强图像的质量。图像质量评价指标有全参考与无参考之分,全参考评价需要使用与待评价图像对应的标准图像作为参考,而无参考意为仅根据待评价图像自身的信息进行评价。本文使用全参考图像质量评价指标峰值信噪比(peak signal to noise ratio,PSNR)与结构相似性(structural similarity index,SSIM),以及无参考图像质量评价指标统一无参考图像质量和不确定性评估器(unified no-reference image quality and uncertainty evaluator,UNIQUE)来评价增强图像的质量。在高分辨率的CelebA-HQ数据集上选取1 000张图像作为测试集进行测试(下同),得到的图像质量指标对比情况见表4。

表4 对比实验图像质量评价指标对比
注:加粗数据为最优值
由表4可知,本文方法在3个图像质量评价指标上的表现均明显优于其他方法。本文提出的低光照图像增强方法能够在增强图像的同时保持图像各种尺度的特征,使得增强图像的质量更佳。
4.4.4 模型泛化性验证实验
为探究本文采用的数据集暗化处理方式是否存在局限性,导致在该数据集下训练的模型泛化能力差,本文重新采用Gamma校正方式对测试集图像进行暗化处理,并使用在原数据集下训练的模型对其进行增强处理,结果如图11和图12所示。

图11 Gamma校正方式可视化结果对比示例1
由图11和图12可见,更换不同的暗化处理方式后,在不重新训练模型的情况下,本文方法仍然可以较好地进行亮度增强,相比于其他方法,更优地保留了图像细节的颜色和结构特性。
此外,为进一步验证本文方法在真实暗光场景下的泛化性,选取了2张真实世界暗光图像并通过不同方法对其进行增强处理。图13和图14为真实暗光图像的增强可视化对比结果,图像均采集于网络。可见,本文方法在处理真实场景图像时依然可以得到高质量的增强图像,色彩和保真度明显优于其他方法。而使用Zero-DCE方法增强后的图像出现了明显的细节模糊问题,RUAS方法出现了局部曝光不均匀问题。本实验充分验证了本文方法可以有效地应对真实世界的暗光场景,具有较好的泛化能力。

图12 Gamma校正方式可视化结果对比示例2

图13 真实暗光场景可视化结果对比示例1

图14 真实暗光场景可视化结果对比示例2
4.5 消融实验
为了验证本文提出任务驱动型低光照图像增强网络框架中各个部件的有效性,还进行对比学习模块(标记为NoM)、语义分割模块(标记为NoM)的模块消融性分析,并进行特征保留损失(标记为NoL)、人脸识别损失(标记为Noface)的损失函数消融性分析,定量分析各个模块与损失函数的贡献大小。此外,为探究对比学习负样本的有效性,采用无负样本训练(标记为NoS)与原始结果对比验证。实验结果从视觉效果与量化分析两个方面进行对比分析。
4.5.1 可视化结果
图15和图16为使用本文方法与去掉模块/损失函数的方法对图像进行增强的可视化结果对比情况。图17为使用本文方法与去掉对比学习负样本的方法进行可视化结果对比示例。

图15 模块/损失函数消融实验可视化结果对比示例1

图16 模块/损失函数消融实验可视化结果对比示例2

图17 负样本消融实验可视化结果对比示例
由图15和图16中可视化结果对比可以看出:NoM去掉对比学习模块之后增强结果仍然很暗,说明基于对比学习进行亮度恢复的有效性;NoM去掉语义分割模块之后增强图像中出现了局部区域曝光过度的现象,说明引入语义信息对于保证图像中相同语义类别下的亮度一致的有效性;NoL去掉特征保持损失之后增强图像中丢失部分细节信息,部分区域呈现蓝色,说明特征保持损失对于保留图像细节特征的有效性;Noface去掉人脸识别损失与Ours的方法对图像进行增强的结果相差不大,但其能够有效地提升人脸识别的准确率,且对于人脸图像的增强质量有一定程度的促进作用。由图17(b)与(c)可视化结果对比可以看出:去除对比学习负样本之后的训练结果难以正确恢复图像亮度,增强图像的整体亮度仍处于较低的水平。
4.5.2 人脸识别准确率对比
表5为消融实验的人脸识别准确率对比情况。

表5 消融实验人脸识别准确率对比(%)
注:加粗数据为最优值
由表5可知,本文提出的2个模块、2项损失函数与采用的对比学习负样本对于人脸识别准确率的提升起到了不同程度的促进作用。其中M,M,L和S用于亮度增强、曝光度控制与细节的保持和恢复,通过增强图像来提升人脸识别的性能,而face是通过任务驱动技术,直观地从网络中学习提升人脸识别准确率的信息,从而进一步提高了准确率。
4.5.3 增强图像质量评价指标对比
表6为消融实验的增强图像质量评价指标对比情况。
由表6可知,本文方法在全参考图像质量评价指标PSNR与SSIM均优于其他方法,框架中的各个模块与损失函数都对结果起到了不同程度的促进作用。本方法的UNIQUE指标略逊于不加入人脸识别损失的增强方法,但需要注意的是本文更关注人脸识别应用的性能,图像质量评价只是辅助评价方法。
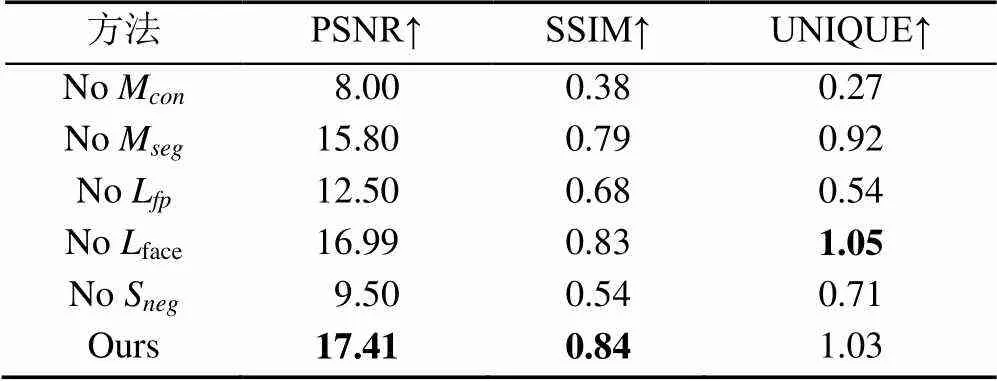
表6 消融实验图像质量评价指标对比
注:加粗数据为最优值
5 结束语
本文针对低光照图像增强与人脸识别应用提出了一个新颖的非成对低光照图像增强算法,设计了以人脸识别任务为驱动的低光照图像增强网络Low-FaceNet。Low-FaceNet由4个子网络构成,其中主干网络是图像增强网络,3个子网络分别为特征提取网络、语义分割网络和人脸识别网络。为解决低光照图像增强领域中难以获取大规模的低光照图像与其对应的正常光照图像,本文采用了对比学习技术直接从真实世界的正常光照/低正常图像构建正/负样本,为网络训练提供额外的监督信息。此外,通过特征保持损失、语义亮度一致性损失和人脸识别损失来共同约束图像增强网络的训练。为了让子网络能有效地服务于图像增强网络的训练,本文先采用预训练的方式分别训练人脸识别网络和语义分割网络,然后固定其权重以端到端的方式训练图像增强网络,训练过程中仅更新主干网络的参数。
视觉和定量结果均表明,本文方法相较于其他图像增强方法,得到的增强图像质量更好,能够保留图像中不同尺度的细节特征。此外,本文以人脸识别任务为驱动的方案能够有效地提升低光照条件下人脸识别的准确率。
本文方法的局限性主要表现在:当使用小规模数据集对网络训练时,通常不能取得较好的增强效果,这是因为对比学习范式通常需要大量的样本对才能获得良好的性能。此外,当前训练所使用的数据集图像质量欠佳,可能会对模型的性能产生一定的影响。在后续工作中,考虑构建一套真实场景下的高质量人脸识别数据集来解决这一问题,并进一步探索本文所提出的学习方案在其他无监督低阶视觉任务中的潜力。
[1] 王坤. 基于卷积神经网络的低光照图像增强算法研究[D]. 赣州: 江西理工大学, 2020.
WANG K. Research on low light image enhancement algorithm based on convolutional neural network[D]. Ganzhou: Jiangxi University of Science and Technology, 2020 (in Chinese).
[2] PIZER S M, JOHNSTON R E, ERICKSEN J P, et al. Contrast-limited adaptive histogram equalization: speed and effectiveness[C]//The 1st Conference on Visualization in Biomedical Computing. New York: IEEE Press, 1990: 337-345.
[3] LAND E H. The retinex theory of color vision[J]. Scientific American, 1977, 237(6): 108-128.
[4] GUO X J, LI Y, LING H B. LIME: low-light image enhancement via illumination map estimation[J]. IEEE Transactions on Image Processing, 2017, 26(2): 982-993.
[5] LORE K G, AKINTAYO A, SARKAR S. LLNet: a deep autoencoder approach to natural low-light image enhancement[J]. Pattern Recognition, 2017, 61: 650-662.
[6] LV F F, LU F, WU J H, et al. MBLLEN: low-light image/video enhancement using CNNs[C]//The 29th British Machine Vision Conference. Durham: The British Machine Vision Association and Society for Pattern Recognition Press, 2018: 4.
[7] ZHU M F, PAN P B, CHEN W, et al. EEMEFN: low-light image enhancement via edge-enhanced multi-exposure fusion network[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34(7): 13106-13113.
[8] WEI C, WANG W J, YANG W H, et al. Deep retinex decomposition for low-light enhancement[EB/OL]. (2018-06-08) [2022-05-07]. https://arxiv.org/abs/1808.04560.
[9] FAN M H, WANG W J, YANG W H, et al. Integrating semantic segmentation and retinex model for low-light image enhancement[C]//The 28th ACM International Conference on Multimedia. New York: ACM Press, 2020: 2317-2325.
[10] CHEN C, CHEN Q F, XU J, et al. Learning to see in the dark[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 3291-3300.
[11] CAI J R, GU S H, ZHANG L. Learning a deep single image contrast enhancer from multi-exposure images[J]. IEEE Transactions on Image Processing, 2018, 27(4): 2049-2062.
[12] JIANG Y F, GONG X Y, LIU D, et al. EnlightenGAN: deep light enhancement without paired supervision[J]. IEEE Transactions on Image Processing, 2021, 30: 2340-2349.
[13] GUO C L, LI C Y, GUO J C, et al. Zero-reference deep curve estimation for low-light image enhancement[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2020: 1777-1786.
[14] YANG W H, WANG S Q, FANG Y M, et al. From fidelity to perceptual quality: a semi-supervised approach for low-light image enhancement[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2020: 3060-3069.
[15] LEE Y, JEON J, KO Y, et al. Task-driven deep image enhancement network for autonomous driving in bad weather[C]//2021 IEEE International Conference on Robotics and Automation. New York: IEEE Press, 2021: 13746-13753.
[16] LI W B, YANG X S, KONG M H, et al. Triplet is All You Need with Random Mappings for Unsupervised Visual Representation Learning[EB/OL]. (2021-06-08) [2022-04-20]. https://arxiv.org/abs/2107.10419.
[17] BUCHSBAUM G. A spatial processor model for object colour perception[J]. Journal of the Franklin Institute, 1980, 310(1): 1-26.
[18] 孙哲南, 赫然, 王亮, 等. 生物特征识别学科发展报告[J]. 中国图象图形学报, 2021, 26(6): 1254-1329.
SUN Z N, HE R, WANG L, et al. Overview of biometrics research[J]. Journal of Image and Graphics, 2021, 26(6): 1254-1329 (in Chinese).
[19] DENG J K, GUO J, VERVERAS E, et al. RetinaFace: single-shot multi-level face localisation in the wild[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2020: 5202-5211.
[20] YANG S, LUO P, LOY C C, et al. WIDER FACE: a face detection benchmark[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press,2016: 5525-5533.
[21] 牛作东, 覃涛, 李捍东, 等. 改进RetinaFace的自然场景口罩佩戴检测算法[J]. 计算机工程与应用, 2020, 56(12): 1-7.
NIU Z D, QIN T, LI H D, et al. Improved algorithm of RetinaFace for natural scene mask wear detection[J]. Computer Engineering and Applications, 2020, 56(12): 1-7 (in Chinese).
[22] SCHROFF F, KALENICHENKO D, PHILBIN J. FaceNet: a unified embedding for face recognition and clustering[C]// 2015 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2015: 815-823.
[23] YI D, LEI Z, LIAO S C, et al. Learning face representation from scratch[EB/OL]. (2014-06-08) [2022-06-19]. https://arxiv. org/abs/1411.7923.
[24] LIU Y L, SHI H L, SHEN H, et al. A new dataset and boundary-attention semantic segmentation for face parsing[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34(7): 11637-11644.
[25] CHEN L C, ZHU Y K, PAPANDREOU G, et al. Encoder- decoder with atrous separable convolution for semantic image segmentation[EB/OL]. (2018-06-08) [2022-05-19]. https:// arxiv.org/abs/1802.02611.
[26] LIU R S, MA L, ZHANG J A, et al. Retinex-inspired unrolling with cooperative prior architecture search for low-light image enhancement[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2021: 10556-10565.
Face recognition-driven low-light image enhancement
FAN Yi-hua1, WANG Yong-zhen1, YAN Xue-feng1, GONG Li-na1, GUO Yan-wen2, WEI Ming-qiang1
(1. Institute of Computer Science and Technology, Nanjing University of Aeronautics and Astronautics, Nanjing Jiangsu 210016, China; 2. State Key Laboratory of New Computer Software Technology, Nanjing University, Nanjing Jiangsu 210023, China)
Images are susceptible to external lighting conditions or camera parameters, resulting in overall darkness and poor visualization, which can degrade the performance of downstream vision tasks and thus lead to security issues. In this paper, a contrastive learning-based unpaired low-light image enhancement method termed Low-FaceNet was proposed for face recognition tasks. The backbone of Low-FaceNet was in the form of an image enhancement network based on the U-Net structure, introducing three sub-networks, i.e., feature retention network, semantic segmentation network, and face recognition network, thereby assisting the training of the image enhancement network. The contrastive learning paradigm enabled a large number of real-world unpaired low-light and normal-light images to be used as negative/positive samples, improving the generalization ability of the proposed model in the wild scenarios. The incorporation of high-level semantic information could guide the low-level image enhancement network to enhance images with higher quality. In addition, the task-driven approach made it possible to enhance images and improve the accuracy of face recognition simultaneously. Validated on several publicly available datasets, both visualization and quantification results show that Low-FaceNet can effectively improve the accuracy of face recognition under low-light conditions by enhancing the brightness of images while maintaining various detailed features of the images.
low-light image enhancement; face recognition; contrastive learning; task-driven; semantic segmentation
TP 391
10.11996/JG.j.2095-302X.2022061170
A
2095-302X(2022)06-1170-12
2022-07-29;
:2022-10-10
国家自然科学基金项目(62172218,62032011)
范溢华(2000-),女,硕士研究生。主要研究方向为自然图像处理。E-mail:fanyihua@nuaa.edu.cn
魏明强(1985-),男,教授,博士。主要研究方向为计算机图形学、计算机视觉等。E-mail:mingqiang.wei@gmail.com
29 July,2022;
10 October,2022
National Natural Science Foundation of China (62172218, 62032011)
FAN Yi-hua (2000-), master student. Her main research interest covers natural image processing. E-mail:fanyihua@nuaa.edu.cn
WEI Ming-qiang (1985-), professor, Ph.D. His main research interests cover computer graphics, computer vision. E-mail:mingqiang.wei@gmail.com
