基于自监督学习方法的半监督视频目标分割研究
2023-01-10朱方瑞付彦伟谢伟迪
朱方瑞,张 力,付彦伟,谢伟迪
(1. 复旦大学 大数据学院,上海 200433; 2. 牛津大学 工程科学系,英国 牛津 OX13PJ)
可靠性高、鲁棒性强的智能目标跟踪系统在很多计算机视觉应用中,例如: 车载导航、视频监控、视频活动识别等,都发挥着至关重要的作用。目标跟踪系统的应用问题通常被定义为: 给定视频第1帧或关键帧中的目标边界框或者目标分割掩码(Mask),对视频序列中其他帧中的目标进行定位,提取其边界框或者分割掩码,根据模型输出的不同,分为目标跟踪[1](输出为目标的边界框)和半监督视频目标分割[2](输出为目标分割掩码)。本文研究的问题是利用自监督学习方法进行半监督视频目标分割,也可以称之为密集型目标跟踪(Dense object tracking)。最近自监督方法已经取得了不错的结果,这些方法的主要思路是训练神经网络作为特征编码器提取特征来学习视频帧之间的相似性,利用学习到的相似性矩阵进行分割目标的重建,将分割目标从第1帧或某个关键帧向后传播至全部的视频序列。这种方法主要通过挖掘视频帧之间的时间-空间连续性来实现,网络的优化目标分为两类: 一类是最小化重建的视频帧与原始帧之间的差异[1,3-4];一类是通过循环重建,最大化视频帧间的循环一致性[5-6]。经过训练后的网络用来进行帧与帧之间的匹配,通过网络提取视频帧的特征表示,使目标帧中的像素特征和参考帧中的对应像素的特征尽可能相似,和不对应的像素的特征尽可能不同。当视频序列中出现时间-空间不连续的情况时(比如: 目标遮挡、目标快速运动、运动模糊等),这类方法在进行帧与帧的匹配时会出现错误,并且这些错误在分割后续视频帧中的目标时会不断积累。从这个角度分析,本文研究了如何通过记忆力机制对自监督方法进行改进,通过一个在线自适应模块来修正分割目标结果中的错误,即在测试阶段不断更新重建得到的目标分割掩码,修正其中匹配不当的错误。这个在线自适应模块是针对于每个视频序列进行训练的,网络的权重是随机初始化的,训练数据是重建时得到的目标分割掩码,所以这种方法仍然属于自监督学习的范畴。除此之外,本文进行了数据有效性的探究实验,实验结果表明,当采用少量的图片数据或视频数据进行自监督训练时,测试结果仍能超过部分有监督学习方法,说明有监督学习或者含有语义信息的特征表示对于半监督视频目标分割任务不是必要的,自监督学习在这个任务上是适用的。
1 通过自监督学习进行半监督视频目标分割的方法
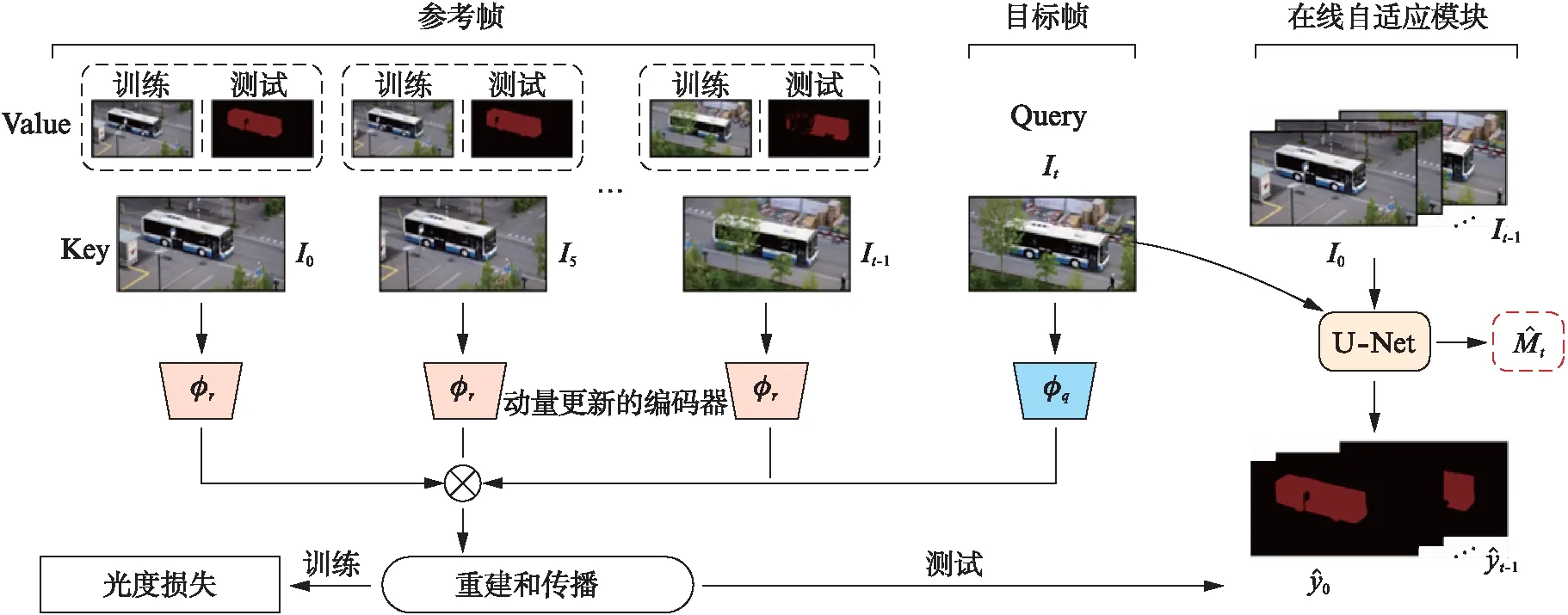
在本节中,首先介绍通过挖掘两个视频帧的相似性,重建视频帧的自监督学习方式来进行视频目标分割;然后在此基础之上,本文通过引入记忆力机制进行改进,在不增加额外计算开销的情况下,解决了目标遮挡的问题;最后,通过设计自监督的在线自适应模块,修正了一些通过重建方式得到的目标分割掩码中的错误,提升了模型的准确性。
1.1 通过重建视频帧学习帧与帧之间的相似性
本节首先介绍通过神经网络提取视频帧的特征表示来学习帧与帧之间的相似性,这种方法不需要有标注的数据,通过原始视频数据直接进行网络建模。通过设计自监督学习中的瓶颈(Bottleneck),使网络学习找到参考帧中能最佳匹配当前像素特征的像素集合,对当前像素特征进行重建。
具体来说,给定某个视频序列中的两个视频帧,记为{It-1,It}∈H×W×3,其中H,W表示原始帧的长度和宽度;待训练的神经网络(特征编码器)记为Φ(·;θ);经过特征编码器提取输入视频帧的特征表示,记为ft=Φ(g(It);θ),提取的特征ft∈h×w×d,其中h,w,d分别表示特征图的长度、宽度和通道数;g(It)表示自监督学习中的瓶颈,即人为地减少一些信息,防止网络学习到平凡解(Trivial solution)。在这里,我们采用随机舍弃输入视频帧在“Lab”颜色空间内的一个或两个通道的方式,得到的数据作为瓶颈信息。
通过软注意力机制来计算某个特定视频帧It与参考帧It-1的特征之间的相似性,得到相似度矩阵A。考虑到视频序列中视频帧之间时间-空间的连续性,当前帧It中的某个像素i的特征被表示为参考帧It-1中像素特征的加权和。这里用(i,j)表示特征图上的空间位置坐标,在参考帧中,我们只考虑像素i的邻域内的像素特征,用来重建当前帧中像素i的特征,即N={∀n∈It-1,|n-i| (1) (2) 式中:c表示像素i的邻域半径;相似度矩阵At∈hw×4c2;·表示数量积运算,即内积。经过训练,得到可以最小化重建的视频帧与原始的视频帧It间的光度损失(Huber损失)的特征编码器(Φ(·;θ)),也就是通过此编码器提取的特征可以使视频帧It中的像素特征和与其匹配的参考帧It-1中的像素特征的距离尽可能近,和其他不相关的像素特征的距离尽可能远,网络的优化目标表示为 (3) 在测试时,同样根据视频帧的特征图计算相似度矩阵,根据得到的相似度矩阵重建目标分割掩码,得到视频目标分割结果,记为 (4) 其中:yt表示第t帧的目标分割掩码。 从一对视频帧It,It+1中学习相似性会遇到的问题是,无法应对分割目标在视频序列中“出现—消失—再出现”的情形。例如,某个待分割的目标在视频帧It中是被遮挡的,而在视频帧It+1中又重新出现,那么在It,It+1两帧进行匹配时,It+1中目标所在区域的像素特征将无法在It中找到可以匹配的像素特征。在心理学中,这种现象被称作物体持久性,是一种能够感知物体持续存在的能力,即使在此段时间内无法通过视觉、触觉、听觉、嗅觉感知到这个物体。 为了使网络模型拥有这种能力,最直观的做法是采用一个外部的记忆模块,来储存更多的参考帧用来重建目标视频帧。在本文中,我们提出一个基于动量更新的外部记忆模块(Momentum memory),它大大简化了增强记忆力的目标跟踪器(Memory-Augmented Self-supervised Tracker, MAST)[3]中的复杂计算操作,在不增加额外GPU显存和计算量的情况下,引入了多个参考帧用于对目标视频帧进行更好地重建。 具体来说,给定一个目标视频帧Iq和记忆模块中储存的K个参考帧,记作Ir={I1,I2,…,IK}∈K×H×W×3。我们训练两个基于神经网络结构的特征编码器,即目标帧特征编码器Φq(·;θq)和参考帧特征编码器Φr(·;θr),用来提取目标视频帧Iq和参考帧Ir的特征图: fq=Φq(Iq;θq),fr=Φr(Ir;θr)。 (5) 式中:fq,fr分别为目标帧和参考帧的特征表示;θq,θr为编码器参数。此时,重建目标视频帧Iq中的像素i的过程表示为 (6) (7) 式中: 相似度矩阵Aq∈hw×K4c2;N={∀n∈Ir,|n-i| 在训练过程中,θq采用正常的反向传播方法进行参数更新,为了节省计算开销,θr采用动量更新的方式[7]进行参数更新,更新方式如下: θr←mθr+(1-m)θq。 (8) 这里,m∈[0,1)是动量系数,在实验中,我们采用m=0.999。至此,我们通过自监督的视频帧重建任务训练了完整的特征编码器,包括Φq(·;θq)和Φr(·;θr)两部分。在测试过程中,对通过特征编码器得到的特征图进行相似度计算,重建目标分割掩码,从第1帧起,逐渐得到整个视频序列的目标分割掩码。 尽管记忆力机制可以解决一部分物体遮挡的问题,但是模型仍然受到视频序列的时间-空间不连续的影响,比如: 某些区域在初始的视频帧中都是被遮挡的,但是在某个视频帧中开始出现,此时,对于新出现的区域,将无法从参考帧中找到和它们匹配的区域。在这种情况下,利用光度损失(Huber损失)训练的特征编码器将无法对这些区域准确地重建,积累的错误会随着视频序列的长度增加而增加。为了解决这一问题,我们提出一个在线的自适应模块,来修正这些区域在匹配时出现的错误。 利用特征编码器重建得到的目标分割掩码,我们针对每一个视频序列训练一个在线自适应模块,即一个图像分割网络Ψ(·;θ),它是从头进行训练的,网络权重随机初始化。网络的优化目标为: (9) (10) 图1 本文方法的视频目标分割的总体结构图Fig.1 Schematic illustration of the proposed method for video object segmentation 在本节中,首先介绍实验数据集和模型实现细节,然后分析模型各个组成部分的影响,展示模型的定性和定量结果,并进行分析。最后,进行模型的数据有效性实验研究,并分析结果。 本文在两个标准的视频目标分割数据集上进行实验,分别是DAVIS-2017[2]和YouTube-VOS[10]。DAVIS-2017数据集中包含150个高分辨率视频序列,含有30 000以上的目标分割掩码标注;YouTube-VOS数据集包含4 000个高分辨率视频序列,90个目标类别,190 000以上的目标分割掩码标注。自监督训练时,我们只采用YouTube-VOS中的原始视频帧数据。测试时,采用半监督视频目标分割的模式,利用视频序列的第1帧的目标分割掩码,去分割后续视频帧中的目标。利用标准的评价准则[2,10]: 区域相似性(J)和边界准确性(F),对模型进行评价。 在自监督训练时,特征编码器采用ResNet-18结构,通过改变卷积操作步长使输出的特征图大小为输入图片的1/4。对于数据预处理,采用随机裁剪,缩放至384×384大小作为网络输入,将图像由“RGB”转化为“Lab”通道图像,并随机(p=0.5)舍弃一个或两个通道。首先,采用一对视频帧预训练特征编码器,进行120 000次迭代,批大小为48,采用Adam优化器;然后,加入记忆力机制微调特征编码器,进行10 000次迭代,在特征图间进行匹配时的邻域大小为25×25。预训练学习率为1×10-3,微调时学习率为1×10-4。在测试阶段,通过两个特征编码器计算当前帧和参考帧之间的相似度矩阵,用此矩阵重建目标分割掩码,与此同时,利用得到的分割结果,开始进行在线自适应模块的训练。为了简化模型,我们采用以ResNet-18为骨干网络的U-Net结构,输入图片大小为480×480,数据增强方式包括随机颜色扰动、水平翻转。网络采用Adam优化器,初始学习率为2×10-4,以步长50衰减。模型以训练200次迭代左右的网络输出作为最后的分割结果。 为了验证模型各个组成部分的有效性,我们逐一加入各个模块进行训练,即记忆力机制、在线自适应模块,并在DAVIS-2017验证集上进行测试,所有的模型都只在YouTube-VOS训练集上训练。通过表1(见第192页)可以看出,每个模块的加入都能提升模型性能,尤其是加入记忆力机制后,模型能解决视频序列中大比例存在的目标遮挡问题。 表1 模型不同组成部分对模型性能的影响(在DAVIS-2017验证集上的结果) 通过图2中的定性结果,可以看出当只通过网络学习两帧间的相似性进行重建时,会由于物体被遮挡的原因,出现很多错误(将背景区域作为分割目标)。当加入记忆力机制后,网络可以利用更多的参考帧进行重建,但是对于新出现的图像区域仍会出现分割错误,在线自适应模块的提出可以缓解这方面的问题。 图2 模型加入不同组成部分后的目标分割定性结果Fig.2 Qualitative results of target segmentation after adding different components to the model 此外,本文分析了参考帧数量对模型性能的影响,因为参考帧数量的大小会对模型的运行效率产生影响,表2的结果表明,采用5个参考帧能获得相对较好的性能,故在所有实验中均采用5个参考帧。当参考帧数量为t-1时,即将当前帧t之前的所有帧均加入到记忆力模块中进行编码,这样做的结果并不是最优的,说明网络仍需要有选择地从参考帧中进行匹配。 表2 参考帧的数量对模型性能的影响(在DAVIS-2017验证集上的结果) 在两个标准的视频目标分割数据集YouTube-VOS和DAVIS-2017上,将本文的方法和前人的方法进行比较。从表3和表4的结果可以看出,本文提出的自监督方法可以超越先前的自监督方法,缩小有监督方法和自监督方法的性能差距;本文提出的方法可以在较少训练数据集上进行训练,并达到不错的效果,模型更加高效;自监督学习方法有更好的泛化性能,在训练中未出现的类别上的测试结果没有和训练中出现的类别的测试结果有很大的差距。 表3 模型在YouTube-VOS验证集上的定量结果 表4 模型在DAVIS-2017验证集上的定量结果 此外,我们对模型进行视频目标分割的结果进行可视化,结果如图3(见第194页)所示。对于DAVIS-2017数据集,图3中第1行展示了物体的尺度变化以及被遮挡区域逐渐出现的情形,第2行展示了分割目标的外观和姿势的变化,第3行展示了相机抖动和物体运动的情形。对于YouTube-VOS数据集,图3中第1行展示了物体的外观颜色和背景十分接近,第2行展示了遮挡和被遮挡后出现的情况,第3行展示了目标运动以及尺度发生变化的情况。本文提出的分割模型均能对其有良好的分割效果。 图3 模型在DAVIS-2017和YouTube-VOS数据集上的定性结果Fig.3 Qualitative results of the proposed module on DAVIS-2017 and YouTube-VOS datasets 本文还针对提出的分割模型进行数据有效性的实验探究,也就是只采用少量训练数据,来探究模型的性能。具体来说,实验分为两种情形: 一是只采用少量视频数据作为训练集;另一种是采用少量图像数据作为训练集。对于基于图像的训练数据,我们采用单应变换对单张图片进行连续的数据增强操作,生成一系列视频序列,将这些视频序列用作训练数据。为了进行公平的比较,这里我们采用时长约为10 min的100个原始视频序列进行对比实验。 实验结果如表5所示,尽管只采用少量的视频或图像数据进行训练,模型仍能达到不错的分割效果,比如可以超过CorrFlow方法[4]。这个结果表明,对于这类密集型目标跟踪任务(半监督视频目标分割),有监督学习或者含有语义信息的特征表示不是必要的,因为仅有少量训练数据存在时,模型是无法学习到丰富的语义信息的。 表5 分割模型的数据有效性实验探究(在DAVIS-2017验证集上的结果) 本文对用自监督学习方法进行半监督视频目标分割的任务展开研究。首先,利用神经网络构造特征编码器学习视频帧之间的相似性,用来重建目标分割掩码;然后,提出了记忆力机制用于解决视频序列中的目标遮挡问题,以便更好地进行匹配和重建,设计动量更新的特征编码器以提高模型的计算效率;最后,设计自监督的在线自适应模块来修正重建分割目标掩码中出现的错误。实验结果表明,本文提出的方法可以超越前人的方法,并且在只采用少量训练数据的情况下,模型仍能获得不错的分割性能,表明含丰富语义信息的特征表示在密集型目标跟踪任务中不是必要的。 在未来的研究中,可以将重点放在以下几点: 首先,可以引入光流信息来自监督地捕获目标运动信息,对复杂的运动情形进行更好地分割;其次,可以考虑结合RGB信息和光流信息,使其提供的自监督信号互补,以完善目标分割模型。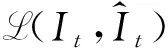
1.2 带有记忆力机制的分割目标重建
1.3 自监督的在线自适应模块
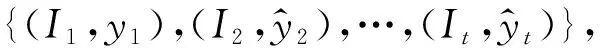
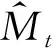
2 实验设计与结果讨论
2.1 实验数据集和实现细节
2.2 模型各个组成部分和参考帧的数量对分割模型的影响



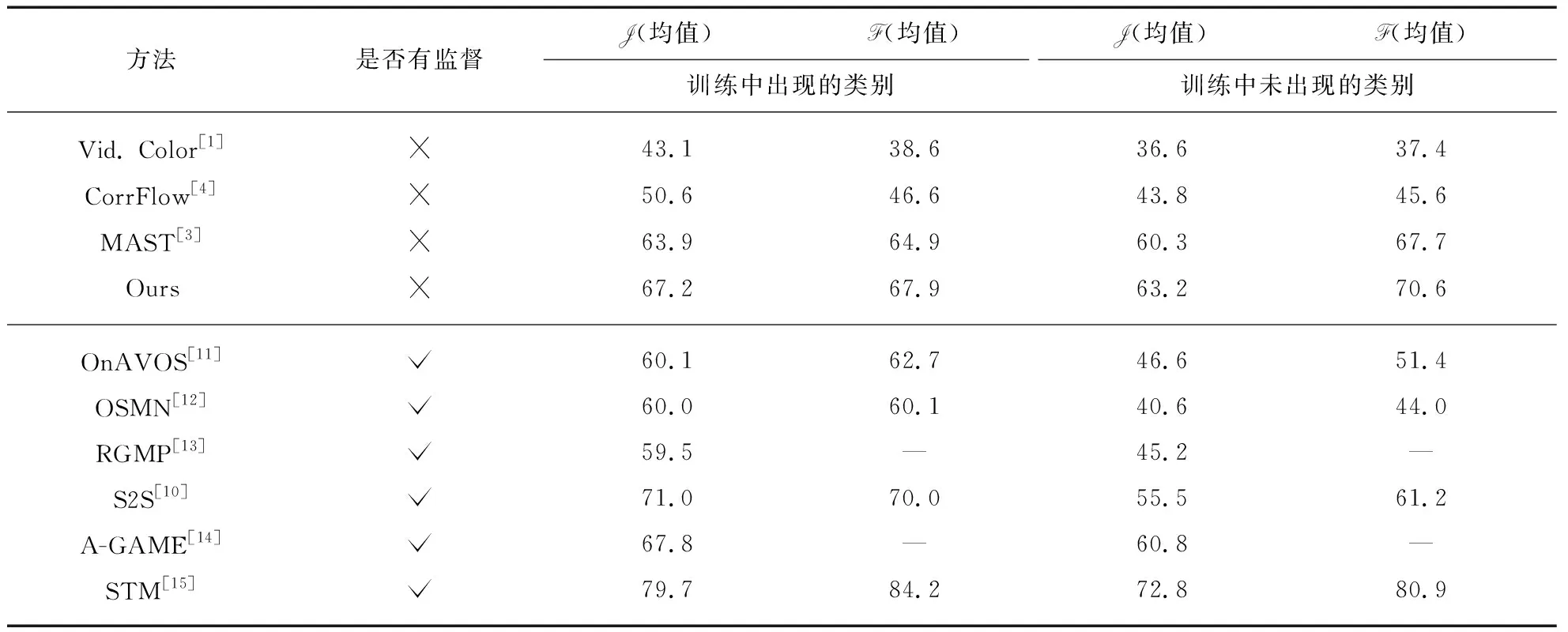
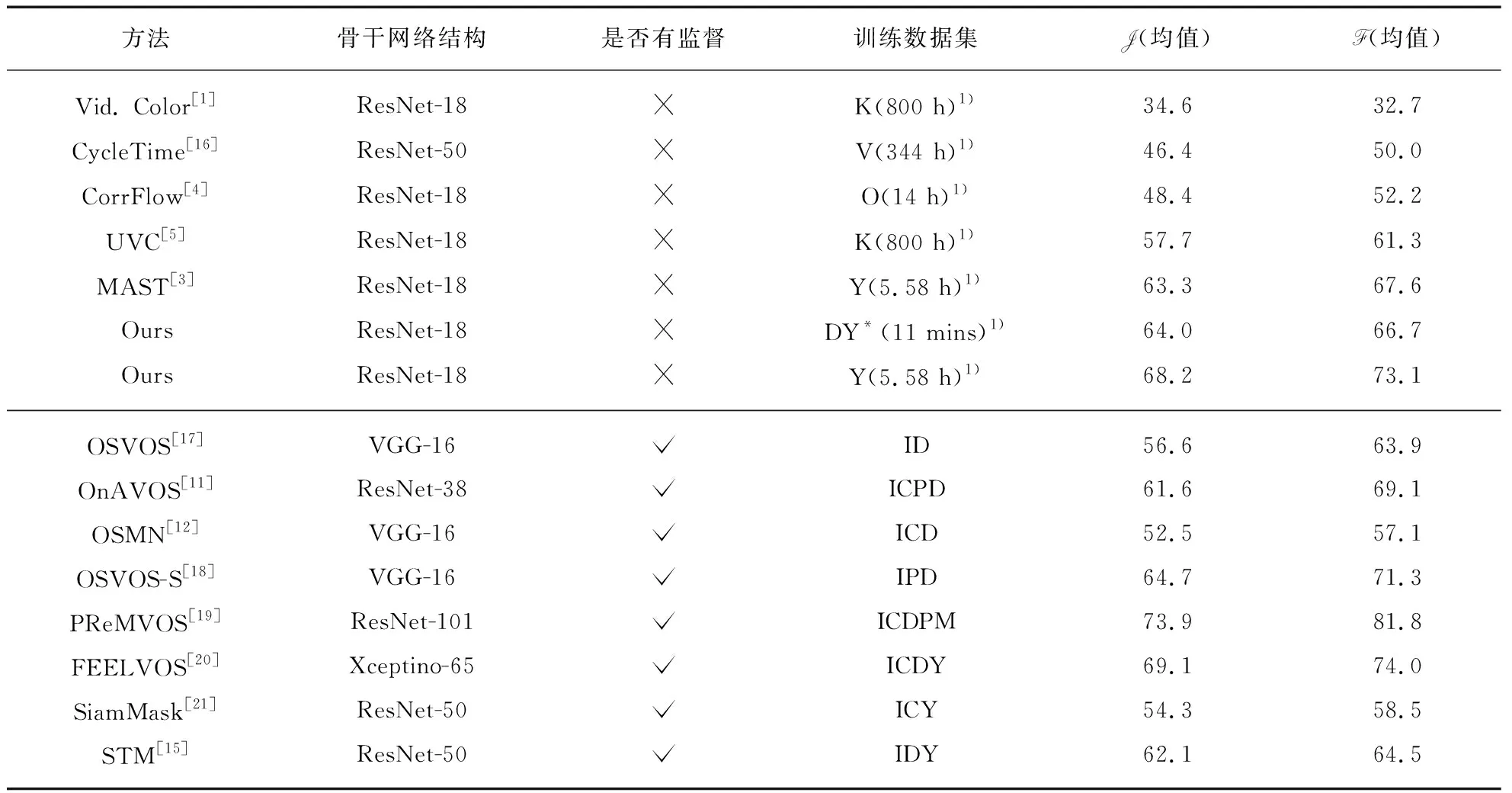
2.3 模型在标准视频分割数据上的实验结果

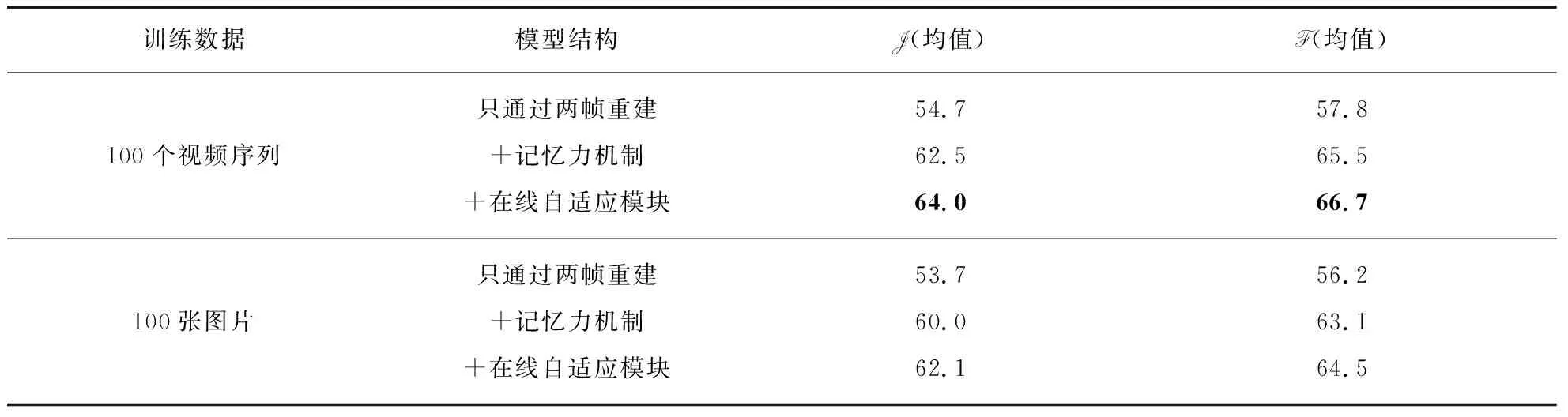
2.4 模型的数据有效性研究
3 结 语
