商业银行信用风险度量及评估方法研究
2023-01-10侯景花
侯景花
(晋中学院计划财务部,山西晋中 030619)
随着市场经济的发展,商业银行正朝着多元化方向发展,同时也面临着更多的金融风险,而信用风险便是其中之一,且发生的频率非常高[1,2]。所谓的信用风险指的是信贷资金安全有着不同程度的不稳定性,主要体现在贷款方因为客观或主观原因无力偿还或是不愿偿还贷款,导致银行方面不能如期收回资金,造成经济损失[3,4]。据世界银行统计,目前信用风险已成为银行倒闭的重要原因之一,所以对商业银行信用风险进行度量及评估,准确分析其在信贷业务中可能出现风险的几率非常有必要,精准的评估结果将会为商业银行的信贷决策提供有利的依据[5]。
近年来,国内外诸多学者对银行信用风险评估问题进行了大量研究,并取得了一定的成果。如夏冰[6]等人通过 “剪裁法” 从供应链的角度运用稀疏最小二乘支持向量机模型对企业的信用风险进行了评估;杜永强[7]等人通过平滑扩充理论对样本数据进行生成并扩充,得到大样本数据,并以此为基础对银行信用风险级别进行划分,进而实现信用风险的评估。上述两种方法虽然对银行信用风险的评估有一定预测作用,但是前者评估切入角度较为片面,后者受样本数量影响较大,导致二者在评估的有效性和准确度上表现得略有逊色。
信用风险是较为复杂的风险类型,不易被精准度量及评估,为此本文提出的商业银行信用风险度量及评估方法,分别运用层次分析法和信息熵方法赋权于信用风险度量及评估体系中的各个指标,得到主、客观权重,并将二者融合得出综合指标权重,并通过自适应调整学习速率的方法优化BPNN网络,实现合理、有效、准确地对商业银行信用风险进行度量及评估,为商业银行的信贷决策提供有利的依据。
一、商业银行信用风险度量及评估
(一)构建商业银行信用风险度量与评估指标体系
1.指标体系构建原则
第一,指标选择的全面性与重要性。因为导致商业银行出现信用风险的因素很多,如宏观因素、借款企业自身因素等[8,9],这就要求在选择度量及评估指标时考虑要全面,且目的性要强。
第二,定性与定量指标结合。定量指标可以直观、明确地获取实际数据,还可以定义出具体的评估标准,并通过量化的方式描述出来[10,11]。但是信用风险度量及评估是较为复杂的系统,不可能将每一个影响商业银行信用风险的因素都用量化的方式表示出来,这样那些不能被量化的指标只能通过定性的方式进行描述。
第三,指标的可预见性。构建指标体系的目的就是为了更深入地挖掘借款企业与商业银行自身的潜在风险因素,要求所选择的度量及评估指标要能表现将来的发展走势。
2.信用风险评价指标体系的建立
依据上述原则并结合我国信用风险的现状,选取以下指标构建商业银行信用风险度量及评估指标体系,详见表1。

表1 商业银行信用风险度量及评估指标体系
上述指标是对信用风险进行管理、控制、监督和检查的重要工具。利用上述指标,可以查明与挖掘信用风险评价潜力,降低商业银行信贷风险,提高经济效益。
(二)商业银行信用风险评估指标权重
指标权重的获取可以分成主观与客观两种方法,这两种方法本身均有不足之处。主观方法主要是从指标本身蕴含的意思制定权重,但是在客观性方面,则表现较差,容易被评估人员的主观想法所影响;而客观方法则是以实际数据为度量及评估的标准,可以不受评估人员主观的影响,但是不能反映出评估人员对各个指标的关注程度,甚至会产生客观方法求得的权重不符合实际情况的现象。所以,在对指标权重进行赋权时,应将主观方法与客观方法进行结合,充分展现其自身的优点。目前,层次分析法(AHP)比较适应于指标权重主观方面的确定,且应用也较为广泛;信息熵方法则更适应于指标权重客观方面的确定。
1.基于层次分析法确定指标主观权重
层次分析法是依据心理学研究原理,把较为复杂的系统划分为多个因素作为分析对象,按照这些分析对象的性质展现出具有层次化的决策过程,构建出结构分明的指标评估体系的方法[12]。该方法在应用时,通常会把分析对象分成不同的层级,相同层级的指标以上一层级的指标为基准,进行一对一的比较,建立两两对比判断矩阵,另外对其获取的结果实行一致性的检测。
(1)构建判断矩阵
根据银行信用风险度量及评估指标体系构建所有层次元素间的联系,也就是建立各个评估指标之间的关系,并进行成对比较,从而构建出信用风险评估指标成对判断矩阵,用Z=(Zij)mn表示,判断矩阵描述为:

有关专家对评估指标重要程度进行评估赋分,根据的评分标准是1~9标度法,如表2所示。
建立对比矩阵C,判断一级指标准基层的重要程度,采用专家打分的方式,评定各特征的比较分值,如表3所示。

表3 准基层比较分值
(2)权重系数计算
第一,依据建立的判断矩阵中评估人员给出的各指标元素取值,对各行的元素值进行求积操作,求得的乘积用Qi描述,公式表示为:

表21 ~9标度法

式中,判断矩阵Z中,行的序号用i描述,列的序号用 j描述,且 i,j=1,2,3,…,n。指标的个数用 n 描述,∏表示求积符号。
第二,求得Qi的n次方根Gi,描述为Gi=Wi,描述为:

第三,因为通常情况下邀请的都是由多人组成的专家组对评估指标赋分,所以就需要对评估专家组给出的权重进行集结处理,用公式描述为:

式中,专家e对指标i赋予的总权重值用ωei描述,专家组人数用r描述。
第四,检验结果的一致性。为了确保AHP获取的结果合理,取得指标权重之后,还需对其一致性进行检验。首先要获得矩阵的最大特征值,描述为:

式中,判断矩阵和指标权重的积用(ZW)i描述,进而获取一致性指标与比率分别描述为CI=通过CR可以检测矩阵的一致性,即如果CR≤0.1,说明矩阵Z满足一致性检测的条件,反之则不满足。
满足一致性检测的要求矩阵Z,其最大特征值λmax 对应的特征向量用 S=(S1,S2,…,Sn)描述,归一化后得到指标权向量 W=(W1,W2,…,Wn)。
2.基于信息熵确定指标客观权重
信息熵(Information Entropy)可以用于信息的量度,表示的是几率和信息冗余度之间的关系,是系统无序程度的度量,描述成信息量的几率加权统计均值[13,14],表达式为:

式中,状态值出现的几率用pi描述,D表示pi的函数,代表了平均不确定性,自然对数函数用ln描述。把信息熵运用在评估系统里,可以最大限度地减少每个指标权重的主观性。
熵权值具体运算过程如下:
第一,评估对象样本数量用m描述,每一个评价对象包含的指标个数用n描述,建立判断矩阵,表示为:

第二,获取第j个评价指标下第i个评估对象的指标比率,描述为:

第三,对评估指标的熵进行定义,描述为:

式中设定当pij=0时,则pijlnpij=0,目的是使lnpij有意义。
第四,求得评估指标的熵值,第j个指标的熵值表示成:
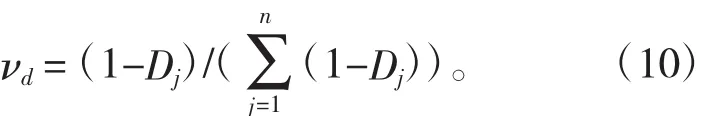
第五,获取指标权向量,描述为:

3.综合权重的确定
层次分析法是通过评估人员的经验和认识获取指标权重,侧重于体现指标对于商业银行信用风险的重要程度,因此有时就会出现这样的情形,即虽然某一指标较为重要,但是该指标却没有较强的针对性,这种情况下就不需要对其赋予较大权重;信息熵则是通过客观数据来度量指标的重要程度,能较好地反映出指标的针对性,但是如果只是单纯地根据客观数据进行判断,那么就会使有着较强针对性的指标对商业银行信用风险的重要程度不能突显出来,特别是有异常数据产生时,就要减小虽然重要但针对性较差的指标所占的权重,同时提升针对性较强指标的权重。总之,就是把较为重要但针对性不强的指标转移给针对性强但重要程度略低的指标一部分权重。这样将通过主、客观方法获取的权重进行综合就可以使两者得到互补,并且以重要程度为前提增强整个模型的代表性。商业银行信用风险度量及评估指标的综合权重是通过客观权重调整主观权重的方式获取,详细描述是:将主观权重作为前提,然后根据客观权重体现出来的针对性,调整主观权重的比例。通过该方法获取到商业银行信用风险度量及评估指标的综合权重向量C=(c1,c2,…,cn),其中 ci描述为:
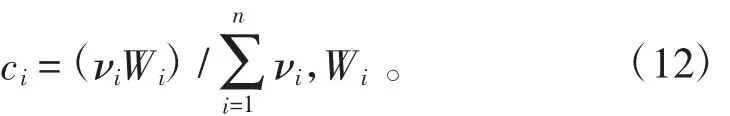
(三)BPNN网络模型
BPNN属于前馈型阶层网络,一般由三个层次组成,第一层为输入层,第二层为隐藏层,第三层为输出层[15]。
为了提升BPNN网络的性能对其进行了优化。优化的方式就是自适应调整其学习速率,即如果经过K次迭代总误差R变小,则判断其学习速率提升,反之则判断为降低,具体描述为:

式中,学习速率用g描述,训练次数用K描述,误差函数用R描述。
学习速率初始值的选取有两种方式,即随机选取和经验赋值。当选取较大速率时,若误差加大,那么学习速率变小;当选取较小速率时,若误差变小,那么学习速率增加,以此进行迭代,直到误差为预期值,结束迭代,或是迭代达最大次数,则迭代结束。通过多次实验对相关参数进行改进,以促进BPNN网络实现最佳形态,完成BPNN网络模型的构建。
经过优化的BPNN网络模型,以自适应调节的方式促进BPNN进行最大学习速率的训练,能够极大地提升BPNN模型的收敛速度,增加整体性能。
优化后的BPNN网络模型关于商业银行信用风险度量及评估的学习过程具体如下:
(1)输入层神经元的数量的设置。依据确定的商业银行信用风险度量及评估指标体系,将通过AHP与信息熵的方法确定的指标权重中占比较小的指标去除,从而可以降低BPNN模型输入的维度。
(2)输出层神经元的数量的设置。最终输出层提出的结论应与借款方的信用风险等级相对应。
(3)隐藏层的数量以及神经元数量的设置。通过Komogrov原理可知,具有3个层级的BPNN网络能够贴近随机的非线性函数,所以本文关于商业银行信用风险度量及评估设置1个输出神经元。对BPNN网络性能影响最大的就是位于隐藏层神经元数量。如果神经元数量过多,那么网络学习的时间也会过长,而且误差也不一定能实现最佳;如果神经元的数量过少,会出现容错性差的问题,影响度量与评估的准确性,因此,通过以下公式对隐藏层神经元最佳数量进行确定,描述为:

式中,位于输入层、隐藏层以及输出层中神经元的数量分别用b、q和o描述,a是常数,且其取值范围是1至10之间。
(四)商业银行信用风险度量及评估步骤及模型
运用层次分析法-信息熵-BPNN综合模型对商业银行信用风险度量与评估步骤如下:
第一,建立商业银行信用风险度量与评估指标体系,指标体系建立之前需了解该行业的特点,选取的指标要对借款方信用等级有足够的影响力。
第二,通过层次分析法-信息熵确定最具影响力的指标变量,并在对度量及评估结论没有影响的前提下进行简化,进而简化BPNN网络的结构。
第三,设置BPNN网络输出神经元数量,因为每个借款方仅对应一个信用风险等级,因此本文设置1个输出神经元。
第四,对BPNN网络所有参数进行初始化操作,如学习参数和精度、动量项的因数、设置的迭代次数等。
第五,无量纲化信用风险度量与评估每项指标,归一化样本参数为0至1之间的数值。
第六,将随机生成的-1至1之间的数,赋予BPNN初始权值矩阵中。
第七,训练BPNN模型,依据附加动量法进行操作。
第八,将训练得到的学习精度与设置的精度做对比,判断其是否符合要求,或迭代次数是否达到设置的最大迭代次数,若有一项符合要求,那么网络训练结束,留存结果。反之,重新返回第六步,直至满足条件。
在信用风险进行度量及评估时也可以将其看作模式识别的问题。设定影响银行信用风险度量及评估结果指标用x1,x2,…,xn描述,信用风险级别用y1,y2,…,ym′描述,那么得出商业银行信用风险评估模型,描述为:

二、实验分析
以某地方性商业银行为实验对象,该银行的组织形式为股份制,在当地设有多家分行。
为了验证本方法的有效性,将本方法对该商业银行信用风险度量及评估进行度量及评估,分值评估公式表示为:

再根据分值将评估等级划分为四级,即优秀(86~100)、良好(71~85)、合格(61~70)、较差(60 以下),经过实验最终获得信用风险度量及评估结果,如表4所示。

表4 信用风险度量及评估结果
由表4可知,本文方法能够有效地获取该商业银行一级指标与二级指标的权重,以此得出该银行信用风险度量及评估的分值为83,评定该商业银行评估等级为 “良好” 。由此说明,利用本文方法可以有效地对商业银行信用风险进行度量及评估,该方法具有较强的适用性。
为了验证本文方法对于商业银行信用风险度量及评估的优越性,将文献[6]中基于SLS-SVM的供应链视角下中小企业信用风险评估、文献[7]中基于平滑扩充原理的商业银行信用风险评级模型和文中所提方法与实际结果相比。实验利用该商业银行130组历史数据作为样本集,其中121组数据用于训练,9组数据用于检测,从而得到的实验结果如图1所示。

图1 采取本文方法评估的结果与实际结果对比图
由图1可知,利用本文方法得出的评估结果曲线与实际结果曲线重合度极高,由此说明本文方法拟合程度高,对于商业银行信用风险的度量及评估具有较好的精度。
通过评估指标的熵值验证本文方法的商业银行信用风险度量及评估指标选取的效果。
实验选取该商业银行的80组数据进行测试,将信用风险度量及评估的各个指标分别用1~21的数字表示,利用本文方法分别测试每个指标的熵值,得出的结果如图2所示。
由图2可知,每个指标熵值均接近实际熵值,表明本文方法的商业银行信用风险度量及评估指标选取的效果较为优秀,各指标具有很强的代表性,构建的风险度量及评估指标体系科学、合理。

图2 指标熵值结果
为了验证本文方法设置1个隐藏层的BPNN网络模型的合理性,实验分别设置隐藏层层数为2层和3层的BPNN网络模型与本文方法进行了对比分析,得出的结果如图3所示。

图3 不同隐藏层层数下BPNN识别性能精度结果
由图3所示,利用本文方法设置的BPNN结构,当迭代次数为200次时,BPNN网络的识别精度已达90%以上,当迭代次数为600次时,识别精度已趋于100%,且呈收敛态势,而两种结构的BPNN当迭代次数为800次和1 000次时,识别精度才达到90%。由此说明,本文方法设置1层隐藏层的BPNN结构较为合理,有着较强的识别能力和较快的收敛速度。
三、结论
随着经济一体化的日益明显,商业银行的信贷合作面临的风险越来越大,为此本文提出了一种对商业银行信用风险进行度量及评估的方法。该方法通过AHP和信息熵对已构建的商业银行信用风险评估指标权重进行获取,选取的银行信用风险度量及评估指标的熵值与实际熵值接近,具有较好的评估效果,将其导入至优化后的BPNN网络中进行训练,以得到风险度量及评估模型,使得商业银行风险的度量及评估具有较好的精度,当迭代次数为600次时,BPNN网络识别精度已趋于100%。这表明本文方法能有效地监管与防范信贷问题带来的风险,具有较强的应用性。
