基于混合深度学习框架的气胸图像分类算法*
2023-01-06剑樊
王 剑樊 敏
(1.山西医科大学汾阳学院 汾阳 032200)(2.西北工业大学计算机学院 西安 710129)
1 引言
气胸是常见的胸部疾病之一,如果不及时治疗,可能会危及生命[1]。气胸的发生有多种原因,如胸部受伤或其它一些肺部疾病,最常见的症状包括胸部突然剧痛或呼吸急促。由气胸造成的肺部影像区域往往大小不一,而由此导致肺塌陷的大小又是治疗气胸的关键因素。然而,由于胸腔的复杂重叠结构,以及气胸的位置和大小因患者而异,诊断该疾病是一项极具挑战性的任务[2]。胸部X射线(CXR)是肺部疾病诊断的首选技术手段,然而,由于全世界放射科医生的数量较少,一名放射科医生每年必须分析数千张X光片[2],极容易造成诊断结果的偏差。不仅如此,医疗资源分布不均衡,也给医疗服务带来了巨大的困扰。因此,利用人工智能手段,分析和处理医学图像数据,为医生分析X射线照片提供参考意见,对于减轻放射科医生的负担,平衡医疗资源,具有极其重要的意义。
随着深度学习技术的不断发展,尤其以卷积神经网络为代表的一系列模型在医学图像分类[3]和检测[4]领域取得了不错的成果。但是,这些研究大都使用的是NIH胸部X光数据集,以及未公开的数据集,很少有人使用CheXpert和Mick-CXR-JPG数据集。其次以卷积网络为主的框架,虽然具有一定的空间感知,但是受胸片噪声干扰,以及气胸位置大小等不一的影响,最终使得模型的泛化能力不强,很难推广到临床应用当中。
为更全面地提取胸片的特征信息,提高气胸诊断的准确率,本文提出基于卷积神经网络(CNN)和Visual Transformer(VIT)的混合模型(CNN-VIT)来帮助诊断气胸疾病。将VIT模型的MLP模块进行改进,使其能够达到更好的分类效果,并将其与卷积网络相结合,同时提高全局特征与局部特征的提取效率。经实验比对,本文所提出的方法具有更高的准确率。
2 数据收集
由于现有的气胸实验大都使用的是NIH公开的ChestX-ray14胸部数据集[5],很少有人使用CheXpert[6]和MIMIC-CXR-JPG[7]数据集,因此这些数据集需要被进一步的探索和使用,以便用于气胸任务的检测。
ChestX-ray14数据集中的气胸类数据集可以直接使用,而CheXpert数据集和MIMIC-CXR-JPG数据集中的气胸类数据集需要完成一定的数据清洗工作才可以使用,主要原因是两种数据集中含有侧体位胸片,但是侧体位胸片一般是用来做辅助分析的,而不直接用于疾病诊断。因此我们在做气胸分类时,需要剔除侧体位胸片。为此本文设计了一个基于AlexNet网络的正位侧位分类器。整个网络共计八层,包括五个卷积层和三个全连接层,全连接层神经元个数分别为4096、4096、2。在卷积之后加入BN归一化层,同时将激活函数由ReLU替换为GELU函数,通过实验表明BN层能够加快模型的收敛速度,GELU激活函数在准确率方面优于其它激活函数。
在分类之前首先需要人工进行标注,由于侧体位和正体位的特征比较明显,如在侧体位的图像中直方图分布要明显的偏向低灰度值部分,因此分类任务比较简单,使用小批量的数据集即可达到较为满意的分类结果。经过筛选和标注的数据集如表1所示。
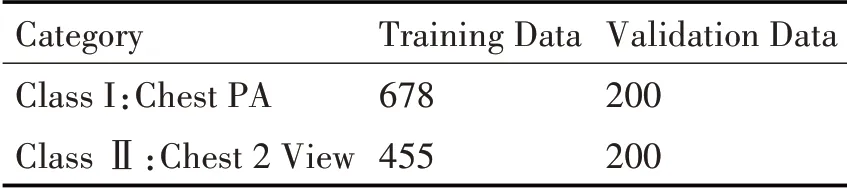
表1 正位与侧位分类数据集
训练过程使用Pytorch框架提供的AlexNet网络的预训练模型,SGD作为优化器,学习率设置为0.001,dropout设置为0.5,训练好的结果如图1所示,验证集准确率达到了0.9848。

图1 损失及准确率曲线
CheXpert数据集中的气胸数据经过正侧位分类器后,不仅能剔除侧体位图片,同时还是能剔除一些质量比较差的胸片,如图2所示。
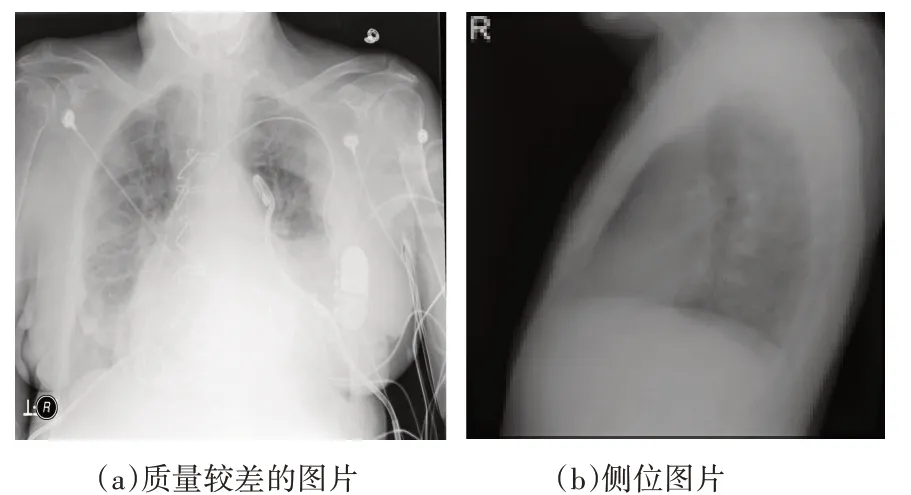
图2 分类器剔除的照片
综上所述,为了使模型能够在更大的数据集上进行训练,得到更好的泛化能力,我们从以上的三个公开数据完成了气胸数据集的收集,具体的经过清洗后,气胸数据集达到了29161张,非气胸数据集(包括正常样例)达到了470284张,该数据集简称CCM-CXR数据集。后期模型的训练将从该数据集内进行抽样选择。作为二分类任务,数据存在着严重的不平衡,因此在实验时我们采用了上采样、数据增强以及下采样等方法以获得新的平衡数据集。
3 模型方法
3.1 EfficientNet模型
EfficientNet模型[8~9]是Google公司于2019年提出的一种分类模型。本文使用的是EfficientNet-B0模型,该模型使用强化学习算法实现MnasNet模型生成基线模型EfficientNet-B0,然后使用复合缩放的方法,在EfficientNet-B0模型预先设定的内存和计算量的范围内,同时对模型的深度、宽度、图片尺寸的三个维度进行搜索改变,最终输出EfficientNet模型。原始的Efficient模型设计输出1000个分类,本文对模型进行改进,重新设计了分类层,并将其最终输出类别改为两个类别。具体的网络结构如图3所示。
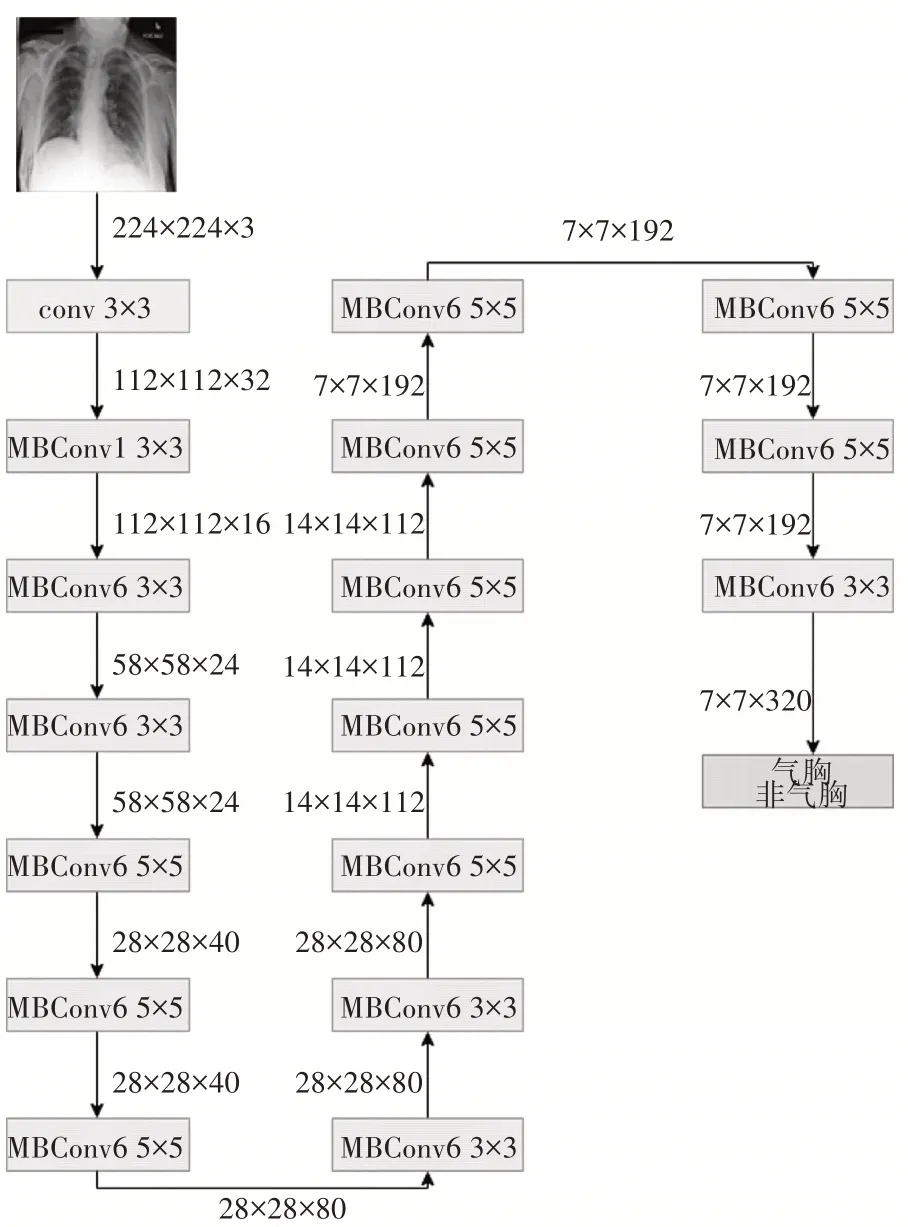
图3 改进的EfficientNet-B0网络结构
3.2 VIT模型
Vision Transformer(VIT)[10]是基于Transformer网络的,Transformer网络[11]在NLP领域已经取得了非常成功的案例。Vision Transformer中只保留了编码器部分,其主要结构如图4所示。其中,Muti-Head Attention模块是基于Self-Attention模块的,多头注意力模块的作用是使网络能够提取更丰富的特征信息。具体公式如下所示:

图4 编码器结构
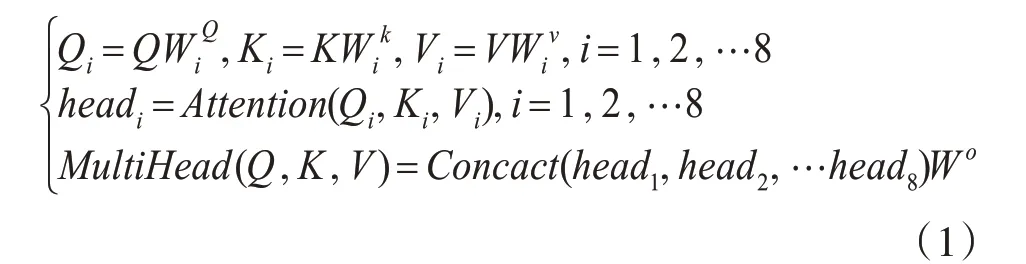
式(1)中Q表示查询向量,K表示被查询的向量,会与每个Q匹配,V表示特征信息,W表示权重矩阵。
VIT整体模型架构如图5所示。首先通过Linear embedding层将图像划分为多个块,然后将其展平,在嵌入位置编码和类编码,经过Transformer Encoder层输出后,输入到MLP Head模块中,该模块由全连接层和激活函数组成,主要用于特征分类,使用的激活函数为GELU,具体公式如下所示:

图5 VIT模型框架

由于本文执行的是二分类任务,因此将最终输出改为二分类。
3.3 方法总体流程
本文提出的方法通过区分X胸片来诊断气胸和非气胸。总体流程如图6所示。数据首先经过预处理,然后使用迁移学习分别训练Efficient-B0和VIT两个模型,最后将两个模型的结果进行加权求和,得到最终的分类结果。

图6 混合模型框架
混合模型可以在一定程度上提高模型的准确率[12]。VIT-CNN模型集成了两种不同的特征提取方法,以提取图像的特征,通过实验最终将VIT模型的输出结果乘以系数0.7,EfficientNet-B0模型的输出结果乘以0.3,将两个结果进行相加,可以得到更好的预测结果。
3.4 VIT模型改进
本文选用的VIT模型为VIT-L/16,诸多实验表明,Transformer网络在迁移学习下模型性能会更好,因此我们选用带有ImageNet数据集预训练权重的模型,该模型由23个自编码模块堆叠组成,为了使模型能够更好地完成气胸分类任务,我们删除了原有的MLP模块,并自定义了如图7所示的MLP模块。
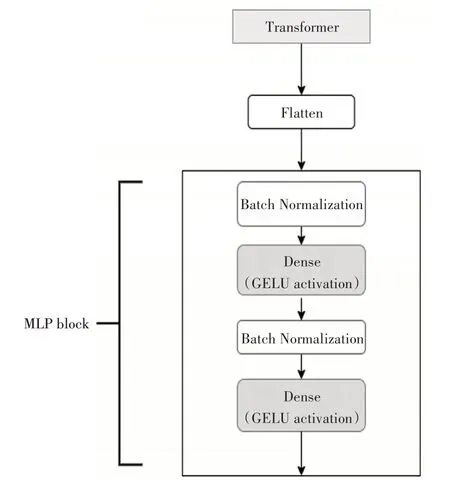
图7 自定义MLP模块
首先将Transformer模块的输出进行展平,然后通过两组由归一化操作和全连接层组成的模块,最后完成分类。使用BN层可以防止模型过渡拟合,并且使模型收敛加快。第一个全连接层由120个神经元组成,并使用GELU激活函数,GELU的非线性变化是一种符合预期的随机正则变换方式,该函数可以为Transformer网络模型的性能带来提升,如GPT-2[13~14]、BERT[15~16]模型。
4 实验及结果
4.1 数据预处理及数据增强
本文选取的数据集来自ChestX-ray14,CheXpert和MIMIC-CXR-JPG三个胸部开源数据集,总计收集499445张数据集,其中气胸数据集为29161张作为正样本,470284张非气胸数据集作为负样本,负样本中包括正常样本和非气胸的其它疾病样本,这样有助于数据的多样性,增强网络的泛化能力。从收集的数据来看,正负样本的比例为0.06:1,数据集存在严重的不均衡问题,数据集不均衡会影响网络的训练效果,以及网络的评估结果。针对以上问题,本文使用了上采样、实时数据扩增、下采样相结合的方法,完成了数据的划分。
对于正样本数据集采用了上采样和实时数据扩增的方法,首先使用上采样方法将正样本数据复制两份,达到扩增数据集的目的,然而单纯的复制并不能保证数据的多样性,因此利用实时数据扩增方法增强数据的多样性,包括随机裁剪、左右上下翻转、随机旋转、90°旋转等方法。对于负样本数据,利用下采样方法,随机抽取58322张图像,使最终的正负样本比例达到1∶1。具体的数据划分情况如表2所示,90%的数据集为训练集,5%的数据集为验证集,5%的数据集为测试集。最后将划分好的数据集的大小统一调整为224×224像素。对于后期实验中的部分网络如inception-V3网络,则调整为299×299像素。
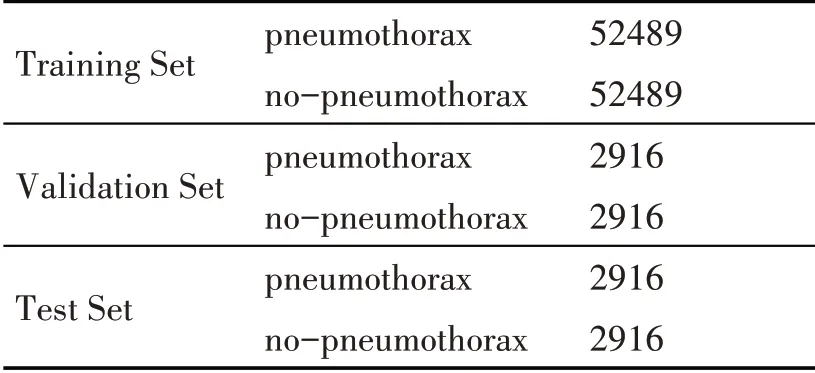
表2 气胸分类数据集划分
4.2 实验细节
本文所用的实验硬件环境是由一个5核Intel(R)Xeon(R)Silver 4210R CPU,两个24G显存的NVIDIA RTX3090显卡和128G内存所组成。该模型使用上述硬件,并采用python3.8虚拟环境及Pytorch框架完成了所有的实验测试项目。在训练时,我们采用交叉熵损失函数,以及NovoGrad优化器[17],它是一种自适应随机梯度下降方法,利用逐层归一化方法使优化器对学习率和权重的初始化更具鲁棒性。通过实验表明,它与SGD优化器具有同等或者更好的性能,与Adam优化器相比,它在内存使用上减少了一半,并且更稳定,虽然模型的训练时间减少了,而性能却没有下降。我们将学习率设置为0.001,批量大小设置为32,模型均训练30个epoch,在训练EfficientNet-B0和Vision Transformer时均使用预训练的ImageNet权重作为初始化权重。
4.3 实验结果与分析
为了验证所提方法的有效性,按照4.2节所述的实验方法,EfficientNet-B0模型、VIT模型以及集成模型CNN-VIT模型在训练集上的损失变化与验证集上得准确率变化如图8所示。集成模型在测试集上的准确率与精确率如表3所示,AUC值如图9所示。

图8 模型训练曲线

表3 三种模型在测试集上的准确率、精确率及AUC值
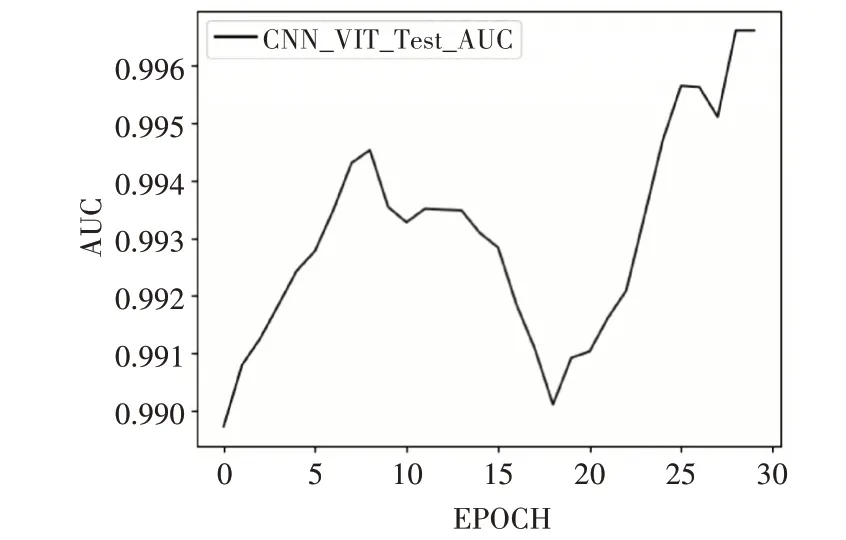
图9 集成模型测试集AUC值
从图8中可以看出改进的VIT模型准确率要高于EfficientNet模型,由于使用了迁移学习初始化权重,因此模型在训练集上的开始损失即是一个比较小的初始值。在验证集上的开始准确率也是比较高的一个初始值,这有助于模型的快速收敛。从表3可以看出改进的VIT模型在测试集上的准确率比EfficientNet模型的准确率高3.6%,精确率高1.4。这表明改进的VIT模型要优于EfficientNet模型。集成到CNN-VIT模型后,准确率达到了99.00%,精确率达到了99.24%,AUC值达到了0.99,性能得到了进一步的提升。
为了更好地说明本文所提方法的分类能力,图10为模型进行预测分类时的混淆矩阵。从混淆矩阵中可以看出,改进的VIT模型识别能力比较均衡,对于气胸与非气胸的识别精度相同。Efficient-Net模型在识别气胸和非气胸能力上存在差异,并且识别气胸的能力更强。CNN-VIT集成模型,对非气胸的识别精度与改进的VIT模型相同,但是对气胸的识别能力更强,这使得集成模型在临床诊断中可以更好地检测气胸任务,是符合实际应用的。

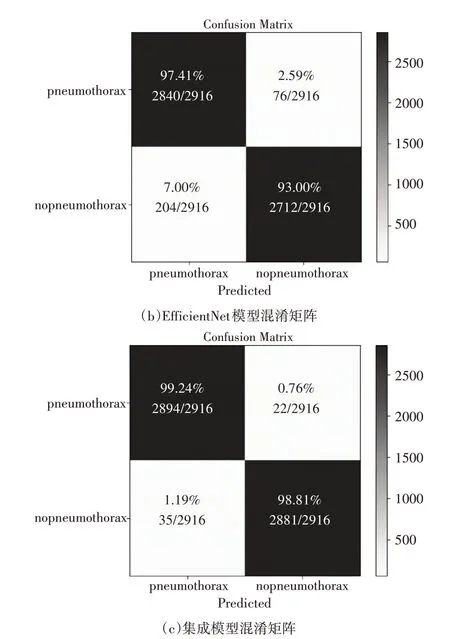
图10 分类混淆矩阵
4.4 消融实验
1)改进VIT模型实验
为了验证改进的VIT中每个模块的有效性,在CCM-CXR数据集上进行了消融实验,如表4所示。从表4的实验1可以看出,当使用BN+1个全连接层+ReLU激活函数时,测试集的准确率下降了2.35%。实验2可以看出,当减少了BN层时,测试集准确率下降到了95.37%。实验3可以看出,当把激活函数替换为GeLU函数时,准确率相比于实验2有所提高,达到了96.59%。实验3可以看出,当把激活函数替换为GeLU函数时,准确率相比于实验2有所提高,达到了96.59%。从实验4可以看出,当使用BN+1个全连接层+GeLU激活函数时,测试集准确率又有了进一步的提高,准确率达到了97.21%,当使用两个BN+1个全连接层+GeLU激活函数模块堆叠时,准确率达到了98.81%,而去掉BN层时,准确率下降了1.7%。当我们继续增加堆叠的层数时,模型在测试集上的准确率开始下降,这表明模型出现了过渡拟合的情形,因此我们最终决定使用两个模块堆叠的MLP结构。

表4 改进VIT-L/16模型消融实验(二分类任务)
2)数据预处理实验
本文的数据集CCM-CXR,来源于三个开源的胸部数据集,为了加快模型的收敛速度,提高模型的准确率,让模型更好地符合临床辅助诊断的实际需求,本文对数据集进行了数据清洗,具体的方法如第2节所述。在实际诊断中,当医生遇到侧位胸片以及质量较差的胸片时,医生都会使用软件进行相应的窗位调节,以便更好地识别气胸。因此本文首先通过网络清洗,剔除一些脏数据以及质量较差的数据,从表5中也可以看出,利用清洗过的数据集对模型进行训练,其准确率的提升是显著的,提高了3.84%,由此我们可以看到模型的改进固然重要,但是相比于前期的数据预处理也很重要,高质量的数据集可以加快模型的收敛,提高模型的准确率,增强模型的泛化能力。

表5 基于改进模型VIT-L/16的数据预处理消融实验
4.5 其它模型的比较
为了进一步证明本文所提方法的有效性,本文将该模型与一些经典的分类模型进行了比较,在实验中为了保证实验条件的一致性,除个别网络如Inception-V3需要调整图像为299×299外,其余数据预处理方法均相同。具体表现如表6所示。从表中可以看出Inception-V3网络的准确率较高,其可能的原因是Inception-V3网络的图像输入分辨率高于其它模型输入图像的分辨率。整体来看本文所提方法的准确率高于其它模型,表现最佳,可以更好地帮助诊断气胸疾病。

表6 与其它模型的比较
5 结语
针对目前卷积网络在医学分类任务中其有限的局部感受野限制它们获取全局信息的能力,本文提出了基于CNN和Transformer的混合深度学习框架,解决了传统CNN忽略图像内部长距离依赖关系,无法准确描述医学图像全局特征信息的问题。同时为了提高模型的泛化能力,依托三个开源的胸部数据集收集了包含50万张胸片的数据集,从而提高了气胸分类任务的准确率。将所提出的模型与其它模型进行比较,实验结果表明所提模型能够更好地识别气胸任务,为临床气胸诊断提供了更加可靠的方法。但本文仍然存在一定的局限性,在实际的临床诊断中,胸片作为诊断胸部疾病的方法,主要包括肺结节、肺炎、肺水肿、肺不张、新冠肺炎等,后续的工作将考虑胸部图像的多分类任务,目前胸部图像的多分类任务的准确率为90%,尚不能达到临床诊断的实际需求,因此下一阶段将利用深度学习混合框架进一步研究多分类任务,提高胸片图像分类的准确率,为临床的诊断提供更加可靠的方法。
