云计算技术在计算机大数据分析中的应用
2023-01-06王光肇刘国鹏
王光肇,刘国鹏
(1.中国煤炭科工集团太原研究院有限公司,山西 太原 030006;2.煤矿采掘机械装备国家工程实验室,山西 太原 030006)
0 引 言
在计算机技术高速发展的进程中,云计算技术以其可拓展性、超大规模、高可靠性以及虚拟化等优势得到了广泛应用。特别是在计算机大数据分析过程中,利用云计算技术可以动态优化计算机大数据处理性能,实现计算机大数据的高效率分析。因此,探究计算机大数据分析中的云计算技术应用措施具有非常重要的意义。
1 云计算技术
云计算是一种利用网络关联计算机硬件、软件资源的技术,可以集中处理数据、存储资源,并根据需要将资源分配到其他计算机设备中[1]。现今形势下,云计算服务与部署模式如图1所示。
图1中,基础设施即服务(Infrastructure as a Service,IaaS)本质上是为用户提供可租用的场外服务器、网络硬件、存储硬件以及虚拟机资源;平台即服务(Platform as a Service,PaaS)本质上是运行用户在操作系统、服务器、存储等云基础设施上部署资源;软件即服务(Software as a Service,SaaS)本质上是以Internet为载体,支撑接连网络的用户浏览云端应用[2]。
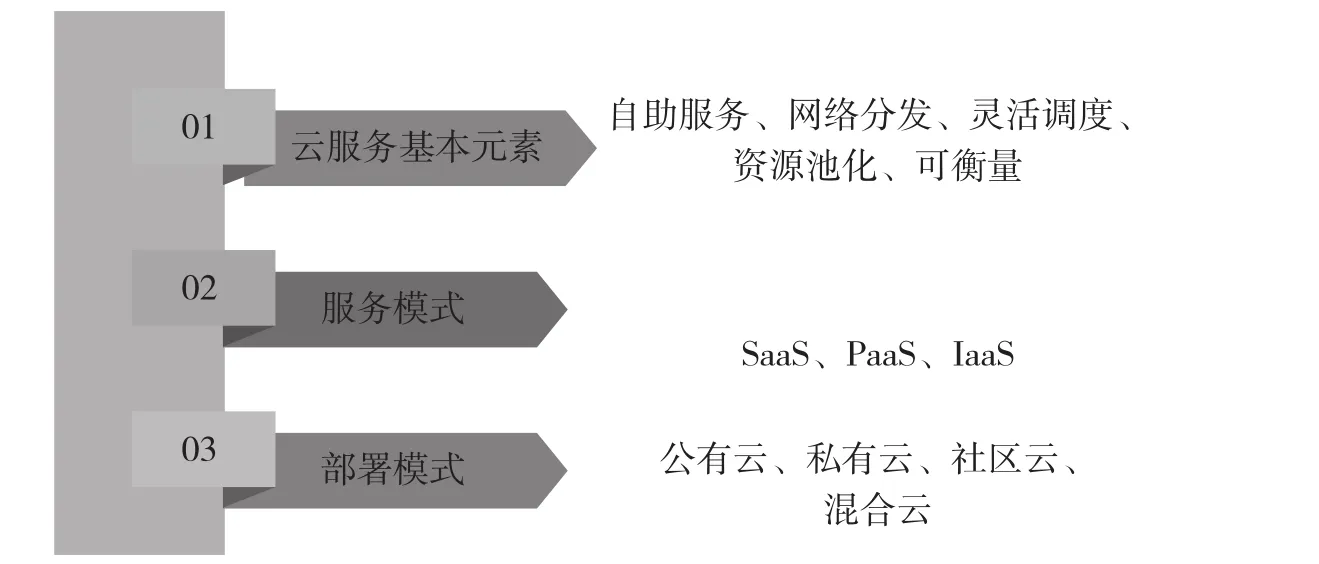
图1 云计算技术服务与部署模式
2 云计算技术在计算机大数据分析中的应用优势
2.1 降低成本
传统的计算机大数据分析主要包括计算机辅助分析、数学统计、社会学分析以及图情分析等,均依托本地资源架构,需专门配备硬件设施、文件系统,成本较高。而云计算技术使用廉价商用机器,可以由分布式文件系统完成计算机大数据分析,在确保计算机大数据分析可靠性的同时,降低分析成果存储成本。
2.2 提高容错
传统计算机大数据分析架构的容错率较低,一旦本地化数据分析资源容量达到TB级,就无法有效处理。而云计算技术可利用软件的方法解决海量数据分析问题,文件系统负责容错任务,容错率较高,可以满足海量数据高容错分析的处理要求[3]。
2.3 实时分析
传统基于本地资源架构的计算机大数据分析数据量为GB级,分析方式为交互性和批处理,需多次写入更新,整体结构为静态,资源结构伸缩性为非线性,无法满足海量数据实时分析的要求。而云计算技术的计算机大数据分析数据量为PB级,分析方式为批处理,可一次写入多次读取更新,整体结构为动态,资源结构伸缩性为线性,可满足海量数据实时分析要求[4]。
3 云计算技术在计算机大数据分析中的应用措施
3.1 构建云计算体系
云计算技术应用到计算机大数据分析中的前提是完善的云计算体系。根据云计算技术采样工具网络爬虫的特点,可综合利用虚拟资源构架技术、数据处理技术、数据挖掘技术,构建虚拟多元信息处理模型体系[5]。依托虚拟多元信息处理模型体系,研究多种应用资源,整理、分配到若干设备,促使计算数据处理速度达到较高的水平。特别是在数据吞吐量达到最大水平时,在模型内整合数据资源,重新构建数据包,预先推动数据包进入传输控制协议管道,满足数据快速传输要求。数据资源整合后,借助云计算自身任务调度功能,依据实际目标,灵活调度任务资源,进而在控制器、内部指示灯之间构建信息交互通道,将数据分析信号传递给控制器,经控制器读取模块内部数据进行量化客观分析,了解不同类别硬件实际占用率与虚拟化资源配置数据差异,为数据运用提供依据。
3.2 规划云计算方案
私有云、公有云是云计算主要使用的对象类别,具有不同优势。为融合二者优势,可以规划混合云计算方案,优化云计算在计算机大数据分析中的应用流程,为服务对象提供舒适的体验。在混合云计算方案规划时,应对接服务对象心理需求,从最大程度减小服务开支着手,允许每一位服务对象按需选择服务类型,提前预知下一周期消费明细,自由选择服务类型。在服务类型确定后,合理分配个人账户内部、公共计算阶段的工作负载[6]。
为了尽可能多地从私有、公共环境中获取有价值数据(含结构化、半结构化、非结构化数据),可以借助Google云计算技术特有的海量数据分析、存储、访问、管理组织与并行处理功能进行组织框架改进(见图2)。
由图2可知,云计算技术环境下,大数据分析主要借助并行处理方法。较之传统网格计算等并行方法,云计算技术中的并行处理流程进一步简化。例如,在MapReduce模型中,先借助map函数、reduce函数计算处理输入的<key,value>对集,再生成1个新的输出对集<key,value>。在新的输出对集生成后,由map函数将输入处理为中间对集<key,value>,集中汇聚具有相同key对应的全部value,进而借助reduce操作归并处理,最终获得(key,final-value)的结果集。整个过程中,数据分析逻辑为将大型分析任务切分为若干数据块,经处理节点分布计算后汇总结果[7]。

图2 云计算技术的大数据分析框架
在并行处理逻辑下,传统固定式的资源配置无法满足大数据分析要求。因此,根据计算机海量数据在云计算环境中呈现出的数据内容与模式、处理方法未知的特性,可以构建集群资源与配置参数等动态资源配置计划,测量不合理资源,诊断瓶颈,针对性优化,确保云计算在大数据分析中的有效应用。
底层存储和访问主要依托Google分布式文件系统,是云计算技术正常运用于大数据分析的保证。系统包括客户端、数据块服务器、主控服务器几个节点,其中客户端为专用访问接口,以库文件形式存在;数据块服务器以文件形式存储数据,是文件系统集群规模的决定依据。在存储文件分块标准默认为64 MB时,数据块数量也为64;在逻辑视角主控服务器与文件集群一一对应。根据整个系统的元数据保存要求,主控服务器可先向客户端提供数据块服务器信息,再经客户端直接访问数据块服务器,完成数据存取、读写,顺利分离控制流、数据流,确保客户端与主控服务器、客户端与数据块服务器之间分别存在且仅存在控制流、数据流,降低服务器负载。在面对海量计算机数据分析操作时,数据流和控制流分离的存储与访问模块可长期跟踪特定数据对象属性状态,根据实时分析人物、数据量负载进行数据块服务器的动态扩展与伸缩,满足数据密集型文件分析要求,容错能力较强,并可将高集成度执行结果发送给数据分析模块。
云计算技术环境下,不缓存数据的操作机制较之传统文件系统缓存性能提升作用更加突出[8]。特别是在客户端多数应用流式读写、少量重复读写的操作状况下,可以实时分析海量历史数据、监测已有资料文献。对于部分需频繁读写的数据,则引入合作缓存技术,由数据块服务器本地文件系统负责缓存,配合数据块服务器的动态加载,规避缓存容量局限性对计算机海量数据分析的干扰。
计算机数据分析中的数据吞吐量较高,需要以批处理的形式保持低延时。基于此,需要摒弃大量依靠关系数据架构的本地资源平台,而是对标海量多类型数据处理和复杂信息查询需求,整合传统关系数据库,动态控制数据部署、格式,确保用户顺利推断底层存储数据的局部属性[9]。
在组织结构设计改进的基础上,需要进行管理结构优化。即依据分布式多维映射表,借助1个行关键字、1个时间戳、1个列关键字进行索引。同时依据行关键字字母倒排数据,确保同一行关键字下数据不间断,提高数据分析效率。例如将Data.analysis.com倒排为com.analysis.Data;对于列,则可以列关键字组成的列族为基本单元,压缩类型相同的同一列族,避免列关键字过多对海量数据分析的干扰;对于时间戳,则加入64位整数,由系统分配赋值,也可用户自定义,将事务时间特性融入关系型数据库内,满足云计算技术实时分析海量数据的要求。
3.3 保障云计算安全
信息数据分析安全是阻碍云计算技术在计算机大数据分析中应用的首要瓶颈。为保障云计算技术的应用安全,可应用物理+数学方式控制访问权限。根据原密码分配密钥,设置双重加密认证,规避不法入侵者盗取信息,保护服务对象隐私安全[10]。同时定期升级云计算密钥系统,自动备份虚拟化的基层系统中间产物镜像,以便在系统出现灾难性状况时自动将存储于计算机服务器的镜像转化为数据,降低云计算数据丢失风险。在这个基础上,从源头着手,启动云计算技术的数据处理函数,辅助隐藏用户登录信息,规避网络内部其他人员获知用户实际位置信息,确保用户信息安全。
4 结 论
云计算技术的应用为计算机大数据分析带来了翻天覆地的变化,不仅可以降低计算机大数据分析成本,而且可以满足计算机大数据按需灵活分析的要求。因此,应构建云计算体系,规划云计算技术应用方案,综合应用双重加密认证与自动备份镜像,保障云计算技术应用安全,为云计算技术在计算机大数据分析中的应用提供支持。
