基于图像处理的纺织品耐摩擦色牢度评级
2023-01-06安亦锦薛文良张顺连
安亦锦,薛文良,丁 亦,张顺连
(1.东华大学 纺织面料技术教育部重点实验室,上海 201620;2.东华大学 纺织学院,上海 201620;3.广州检验检测认证集团有限公司,广东 广州 511447)
色牢度是纺织品生产质量控制和成品检验中极为重要的指标,是指纺织品的颜色在加工、穿着、使用和洗涤等过程中所能承受外界作用力的大小[1-4]。在评定原样和试样的色差时基本沿用目测法[5],即检验人员利用人眼对模拟实验后的纺织品进行灰度差别转换,再与标准灰色样卡[6-7]对照,判断色差等级。该过程存在极大的主观因素,易受外界环境以及主观因素的影响[8],需要一种能代替人眼判断、提高效率和准确度并降低工作量的评级方式。
目前解决方式是采用仪器测定法来实现色牢度自动评级,所用的测色仪器主要基于光谱分析测色[9-10];但仪器法的测色方法和色差计算等理论研究在应用方面还不成熟,国外进口设备昂贵且在国内实际应用中存在颜色标准不一致性等问题,使得仪器法评级不能作为最终色牢度判断的依据[11-13],且测试时间较长,探测头取样面积固定、单一,有必要探索和研究一种更智能便捷的纺织品色牢度辅助评级方法。实质上,色牢度评级是对图像进行识别的过程,而深度学习可自主、准确地实现这一过程,因此,本文尝试以纺织品耐摩擦色牢度评级为例,利用图像处理技术对采集图像进行增强和分割,规避目前仪器方法存在的颜色空间不足、取样面积单一等问题,且处理准确快速;利用深度学习对训练样本进行客观高效的图像识别,实现过程智能化,取代传统的人眼评级方法,降低检验人员工作和心理压力,提高效率,得出一种基于图像处理和深度学习的色牢度评级新方法,提高准确性、监管性,实现纺织品色牢度评级的便捷化。
1 采 样
1.1 采样对象
色牢度的好坏用色牢度等级来评定,除耐光色牢度和耐气候色牢度等级分为8级外,其余的色牢度等级均分为5级,并在相邻2级之间设有半级[3]。传统的纺织品色牢度色差等级评定是根据试样的变色和贴衬织物的沾色分别评定的[14]。沾色评级在同样尺寸的原色贴衬上进行,拍照过程较易实现,采样评级受制约较少,采样评级相对较容易,而且神经网络的内部逻辑相似,因此首先对摩擦沾色试样进行色牢度评级的探索。
纺织品耐摩擦色牢度是纺织品染色牢度的重要检测内容,是检测纺织品抵抗颜色磨损的能力及对其他材料的沾色情况,通常用沾色评级反映纺织品耐摩擦色牢度。目前,国内采用GB/T 3920—2008《纺织品 色牢度试验 耐摩擦色牢度》,通过评定标准棉布与被测样品摩擦后的被沾色情况,比对标准灰卡,根据5级9等的评级划分,以此判定测试样品的耐摩擦色牢度等级。
1.2 采样方法与仪器
预实验发现,毛织物中的绒类织物(有其他织物也可能存在该类问题)与摩擦头的摩擦阻力相对更大,使得摩擦头边缘与绒类织物间瞬时压强变大,导致染色颗粒更多的沾染在标准摩擦布边缘,该种情况下,评级时不对其边缘沾色情况进行考虑。然而边缘颜色的存在会对目光评级产生混淆;而对于目前采用的仪器方法,边缘较深的颜色极难在采样过程中避免,易造成测色不准或采样偏差,以至于最后纺织品评级过低。
织物花色有特殊纹路或者纹样色彩本身深浅不一致,或者织物本身在染色过程及后处理过程中造成染料在织物上固着度的不一致,均导致摩擦后标准摩擦布上沾色不匀,该种情况下要按照沾色最深处进行评级。然而,较有经验的评级工作人员虽然能够按照最深处的沾色进行评级,但仍然存在一定混淆;对于目前采用的仪器方法,极易在采样过程中漏采深色沾色部分导致评级过高。
基于纺织品色牢度评级场景目前存在的上述问题,本研究将利用图像处理技术提取评级特征并对图片进行筛选,并进行整块标准摩擦布的拍照采集以保证采样完整,规避目前仪器方法采样单一的问题。由于颜色的提取和色彩空间转换本身的缺陷,以及纺织品本身对目光评级和目前的仪器方法造成影响的特点,进行图片拍摄采样和图像处理后作为系统输入,来获取颜色信息,结合后续的神经网络对图像的准确提取特征和分类完成更为准确高效的纺织品色牢度评级的创新研究。
本文研究所用的训练样本实验图像是对已评级后的样品采集的图像,规避对色牢度评级的灰卡比对过程。
选用NIKON D750相机进行图像采集可满足图像对清晰度等条件的要求,设置F4光圈、焦距为35 mm,图像选择最高分辨率4 016像素×6 016像素。使用实验室已有的固定光源箱,光源按照检测要求使用D65标准光源,对已进行人眼评级的沾色试验样本进行拍照采集,照片的分辨率达到300 dpi。
1.3 采样结果
共获取5级9等每个等级250张图像,共计2 250张图片。
2 图像处理
2.1 图像预处理
因为研究是基于小样本量,且最差等级的色牢度评级样本较少出现。为提高神经网络的学习效率和准确性,根据试样采集图片分辨率、特征提取范围清晰度等对采集样本先进行预筛选和处理。由于目光评定受主观影响较大,在半个级别的误差允许范围内仍然存在相差1个级别或1.5个级别的样本会被评为同一个等级的情况,因此与多位专家为每个级别讨论选定上下评级边界样本,用以进行比对和筛选,其中发现评定级别的2~3级与3级的边界模糊性最大。
深度学习模型所能提供的信息来源于训练数据中的信息和模型的形成中专家提供的先验信息。基于小样本量的深度学习,模型从原始数据中所能获取的信息少,需要更多的先验信息[15-17],因此本研究利用图像处理技术对采集后所得的数据集进行了扩展。常用的处理方式,如添加噪声、颜色变换会对后期深度学习的特征提取造成不必要干扰,降低准确率;改变图像亮度等对图像成色会造成一定误差,降低准确率和效率;缩放等不利于图像分割定位,都不适用于该场景,因此选择随机旋转变换对数据集进行扩展,共获取5级9等每个等级350张图像,共计3 150张图片。
2.2 图像分割
将图像划分为若干互不相交的区域,区域是所需条件意义下具有相同属性的像素连通的集合。图像分割一般有3种方法,根据本文研究采集的图像特征,采用最小外接矩形算法提取图像需深度学习的识别区域。
2.2.1 Canny算法边缘检测
边缘检测是对边缘像素的定位过程,是图像分割的基础。Canny边缘检测算子由Canny在1986年开发[18-19],是目前边缘检测最常用的算法,不易受图像噪声干扰,效果理想。在本文研究中该算法模块具体包括以下3部分。
1)先用高斯滤波对图像进行去噪。高斯函数是一个类似正态分布的中间大两边小的函数。设像素点位置为(m,n),其二值图的灰度值为f(m,n)。经过高斯滤波后的灰度值将变为
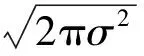
2)计算图像的梯度。基于其定位图像灰度强度变化最强像素点的原理,计算图像的梯度。通过点乘一个sobel算子或其他算子得到不同方向的梯度值gx(m,n),gy(m,n),综合梯度G(m,n)通过下式计算梯度值和梯度方向:
3)确定真实边界。根据梯度抑制非极大值,设置阈值确定边界。高斯滤波可能放大边缘,需要使用规则来过滤非边缘点,在梯度方向上的梯度值最大的像素点属于边缘。设置maxVal和minVal共2个阀值:大于maxVal的像素点都被保留为边缘像素点;低于minVal的都是非边缘像素点;中间的像素点与确定为边缘的像素点邻接则定为边缘像素点。
2.2.2 最小外接矩形分割
利用Canny算子进行边缘检测后确定特征区域,利用最小外接矩形算法对其进行提取、分割。计算得到完全包含所需特征区域的所有的点、线,且四边均与特征区域相切的外接矩形,比较其中面积最小的,即最小外接矩形(MER[5-7],只有1个,从较精确范围上框定特征区域),并采用等间隔旋转的迭代方法计算比较最小外接矩形,在规定范围内以设定角度值进行计算、旋转和拟合边界[20],得到面积最小的外接矩形,以此作为后期深度学习的样本。
2.2.3 算法实现
在Windows Server2012R2服务器上搭建环境,安装程序,利用Pycharm调用OpenCV等文件包进行摩擦沾色区域的提取。
1)边缘提取。输入并读取图片,图片读取内容如图1所示。进行边缘检测。由于边缘像素点的信号变化极大,即灰度值或色彩值急剧变化[21],在梯度方向和反梯度方向各找n个像素点,利用边界寻找函数对图像进行二值图像的轮廓寻找,对梯度变化最大的像素点进行记录,对结果进行阈值二值化的双阈值检测,最后抑制非极大值并进行特征区域边缘连接。

图1 图像的读取
2)框定外接矩形面积最大的轮廓。确定特征区域边缘后,调用应用程序编程接口(API)求取特征区域轮廓的最小外接矩形,各区域最小外接矩形求取结果如图2框定区域所示。计算各最小外接矩形面积,根据采样图像特征调用函数选择所需的面积最大的最小外接矩形,确定特征区域进行提取。
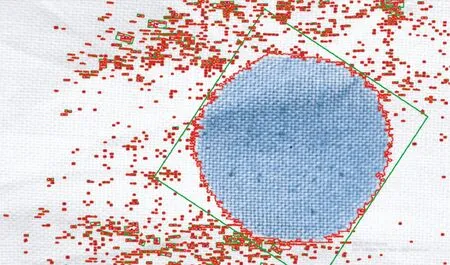
图2 求取结果图
3)对图像进行透视变换。确定所需的面积最大的最小外接矩形,即确定特征区域后,输出像素,用函数构建透视变换的矩阵,对图像进行非尺寸和形状的透视变换,变换结果如图3所示。

图3 填充图像的透视
4)裁剪目标区域。透视变换后对采集图样进行裁剪,保留提取的特征区域,删减干扰特征点,去掉布面纹理和三维特征导致的平面呈现效果对深度学习的干扰,最大限度保留色彩特征以进行后期训练,完成图像分割,如图4所示。

图4 图像分割结果
3 数据库建设与深度学习
3.1 数据库搭建
将处理后图像进行打标整理,搭建数据库,便于后期深度学习的识别与分类,并初步分为学习样本、实验样本、检验样本3部分,其中,检验样本为神经网络测试样本。数据库内部分为两级,首先根据实验样品检测项目的不同,进行一级分类,然后根据色牢度目光评级的9个等级进行二级分类,建立神经网络的学习数据库。
3.2 深度学习
通过预实验和拍照采集之后发现,经过图片对比,无法人工找到图片中沾色区域颜色深浅、色点数量、微观结构与评级之间的联系,导致无法人工提取图像特征,而采用深度模型进行学习,是一种以人工神经网络为架构,对数据进行表征学习的算法[36],可以通过神经网络学习技术自行产生可应用于图像识别的特征。深度学习中常用于图像识别的神经网络是卷积神经网络,其采用原始图像作为输入,具有局部感知和参数共享2个特点[22-23],可有效、全面而高效地从大量样本中学习到相应的特征。
3.2.1 超级深卷积神经网络实验
由于涉及到的识别分类种类多且样本较一般分类所使用的300~500张的体量要多,因此针对实际情况,首先实验了超级深的卷积神经网络,设置的准确性受到网络深度的影响显著,在一般的认知基础之上将神经网络的深度加深到16~19个权重层级,从而实现对现有技术的显著改进,为适应本研究色牢度评级的场景,研究从相对容易进行辨别分类的单纤贴衬沾色评级进行尝试。由于纺织品单纤贴衬沾色色牢度评级数据库有3 150张图片,9个分类,使用超级深的卷积神经网络可利用较小的卷积核解决较多数据量和类别所导致的参数提升与运算效率下降,并尽可能提升其分类结果,有利于其准确分类[24]。
由于首先从单纤贴衬开始研究,因此将所有单纤贴衬处理后的图像导入数据库中,按照70%学习样本、15%校正样本和15%测试样本的比例进行图像分类,搭建数据库,以满足神经网络的自我学习与检测。在本文研究中,基于对超级深的卷积神经网络的适用性[25]的推测,采用19层级的网络架构,分为输入层、卷积叠加池化层、全连接层叠加输出层。池化层套叠5个最大池化层并嵌链在部分卷积层之后,在此之后嵌接3个全连接层,拓宽卷积层的宽度和深度进行模型配置,其中输入层为数据库所录入的图像,输出层为评级结果;将卷积核缩小,根据服务器运算能力和所构建的数据库规模改进设计为3×3卷积核;步长固定为1,padding设置为1。
测试发现,超级深的卷积准确率仅有37%。为改进准确率结果,分析可能导致的原因包括:1)数据库量较小,只是每种分类的训练量不足;2)全部单纤沾色图像全部录入数据库,未先进行等级的分类,可能导致计算机各等级之间分界混乱,且专家评级存在适应性和主观性误差,影响机器学习;3)参数设置需要不断调整磨合;4)模型选择失误。
针对可能的原因进行修正:1)对数据库进行扩充,将3 150张图片扩充至4 950张,每个类别有550张并进行明确标签;2)对数据库中采集图像进行级别评定的确认,确保每张图像所代表的级别等级准确,同时去掉分级混淆、分级错误、分级边界不清的图像,保留4 500张图片,每级别分类有500张;3)调整卷积核的大小为2×2,步长大小设置为1,池化层消减为4个最大池化层,再次进行运行。在对数据进行调整和明确之后,提升其准确率为48%。
通过对其进行多角度、多梯度的参数调整,最终稳定其准确率为51%,该值无法再次提升且不能达到评级需求。分析其根本原因在于该神经网络层级过深,纺织品单纤贴衬沾色场景中获取的图像背景与前景区分明显,过深的神经网络可能导致学习过程中对其纹理特征或其他不相关内容进行了关注训练,导致特征提取混乱,反而降低了学习的准确率,即模型不合适。
3.2.2 创新算法设计
1)空间金字塔池化(SPP)图像输入处理。利用SPP对图像进行卷积操作。将任意尺度图像的卷积的特征转化为相同维度输入到全连接层,方便卷积神经网络处理任意尺度图像而不受数据库内容尺寸影响,避免cropping和warping带来的信息丢失。由于本文研究所采集到的图片尺寸多样,颜色区域所在位置不定,经过图像处理后所得结果的图片尺寸不尽相同,因此利用SPP在输入卷积神经网络前对图像进行统一卷积,使得嵌套后的神经网络能够处理任意尺寸的采集图片,避免颜色信息的丢失,大大提升准确率。
2)卷积神经网络(CNN)特征提取。利用CNN针对所解决问题进行神经网络的架构设计。
3)支持向量机(SVM)调用。在机器学习中。使用分类和回归分析来分析数据,求解SVM[26],进行带约束的优化问题。求解对偶问题的解逼近SVM的最优解,使梯度为零获得极小值,完成目标并得到优化约束下的二次函数,从而进行分类。
4)深度残差网络(ResNext)调用。为提高模型准确率,解决办法基本都是拓宽或深化网络,但是同时会造成超参数数量(通道数、核的大小等)的增加,导致整个网络架构的难度升高,计算内容也会增多导致同样硬件情况下计算效率下降[27]。因此在ResNet基础上将ResNet与Inception网络(又名GoogleNet)相结合,即通过将输入分配到多条分支(相同拓扑结构)后,分组卷积,在每条分支内进行转换,最后再将其融合,从而得到ResNeXt 结构,使得网络可在不增加参数的复杂度的同时提高准确率,减少超参数数量。
3.2.3 算法实现
本文研究针对所解决问题进行相应神经网络的架构调整设计。要保证过多分类和特征识别不造成繁杂的参数计算量和过度拟合,最终使用Res NeXt 101_32×32 d深度残差网络,适应所解决的数据多分类类型的问题,同时减少多参的复杂度并提高准确度。在Ubantu 20.04(配置Nvidia RTX 3090 GPU)环境下利用Pytorch进行算法编写、架构和模型调用、修改。
4 实验验证与结果
将数据库导入算法,设置、选择不同模型和参数进行学习、测试,并进行比较。通过不断调整参数设置和明确数据库分类,目前小样本情况下所得到最稳定高效的训练集的损失率为1.00×10-6、准确率为1;测试集的损失率为0.16%、准确率为87.5%,如图5所示,在小样本量、多分类的制约条件下准确率较高。
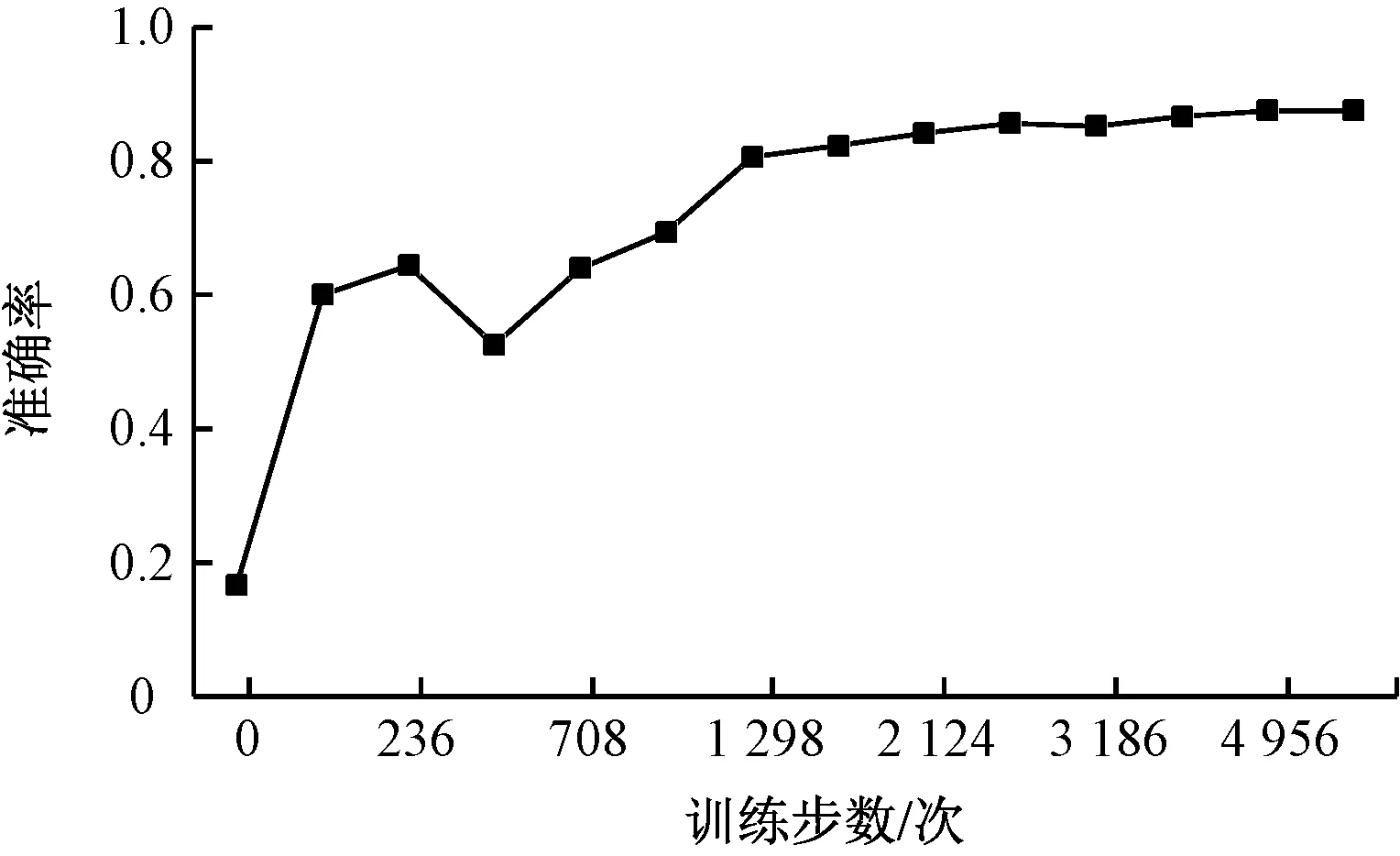
图5 测试集结果图
重新随机抽取未评定等级的100个实验样本进行拍照采集,并将其输入系统算法,记录从拍照采集、输入到最终输出结果的时间;同时分别请3名从事检验检测多年、经验丰富的专家无干扰、独立地在标准光源箱内(日常工作评级一般在各自工位进行)对100个实验样本进行目光评级,记录其评级数和整个评级时间,并在半级允差范围内对结果取平均值,异常样本单独进行讨论评定(未出现异常样本),得到100个样本的最终评级数。
将本文研究的计算机深度学习的评级结果与专家目光评级结果进行比较,在半级允差的范围内,深度学习的评级结果与专家目光评级结果相似度达98%,即准确率达98%,其中误差样本如图6所示。样本A57专家评定2级,系统评定1级;样本A91专家评定2~3级,系统评定1~2级。询问专家和分析样本后发现:由于样本A56颜色较深,给专家造成了视觉暂留,以至于所看到的样本A57较实际颜色更深;样本A91由于专家进行目光评级时已较为疲惫,且受到评级时样品在光源箱内摆放角度对光线、呈色等造成的影响,导致所给级别偏高。

图6 误差样本图
5 结束语
本文根据纺织品色牢度样本特点,应用图像处理技术和深度学习方法,编写并改进了相应算法,结果表明其准确率高、评级速度快,避开测色过程中由于机器的差异带来的系统误差,利用现有仪器,减少对采样操作中的额外要求,实现了对图像特征进行提取识别和对目光评级过程的模拟,操作简单,高效准确。本文研究方法可代替检验人员进行等级评定,减少主观影响,提高监管性且避免人工重复工作。
