基于多视图融合的3D人体姿态估计
2023-01-05胡士卓周斌胡波
胡士卓,周斌*,胡波
(1中南民族大学 计算机科学学院,武汉 430074;2武汉市东信同邦信息技术有限公司,武汉 430074)
3D人体姿态估计旨在定位场景中人体关键点的3D坐标位置,提供与人体相关的丰富的3D结构信息,因其广泛的应用而受到越来越多的关注,例如在动作识别[1-2]、人机交互[3-4]、AR/VR[5-6]、自动驾驶[7]、计算机动画[8]等领域.
从单目图像的单一视图重建3D人体姿态是一项非常重要的任务,它的完成受到自遮挡、其他对象遮挡、深度模糊和训练数据不足的困扰.这是一个严重的不适定问题,因为不同的3D人体姿态可以投影得到相似的2D姿态.此外,对于建立在2D关节上的方法,2D身体关节的微小定位误差可能会导致3D空间中的姿态失真.上述问题可通过从多个视图估计3D人体姿态来解决,因为一个视图中的被遮挡部分可能在其他视图中可见,为了从多个视图重建3D姿态,需要解决不同相机之间对应位置的关联问题.
近年来,通过多视图匹配的3D人体姿态估计研究主要分为两大类[9]:基于2D到3D的多阶段方法和基于直接回归的方法.基于2D到3D的方法如BRIDGEMAN[10]、DONG等[11]通过估计同一人在每个视图中的2D关键点,然后将匹配的2D单视图姿态提升到3D空间.CHEN等[12]将2D图结构模型[13]扩展到3D图结构模型以编码身体关节位置之间的成对关系.BELAGIANNIS等[14]首先解决多人2D姿态检测并在多个摄像机视图中进行关联,再使用三角测量[15]恢复3D姿态.这些方法在特定的场景下是有效的,但非常依赖2D检测结果,2D姿态估计不准确会很大程度上影响3D姿态的重建质量,特别是存在遮挡的情况.
基于直接回归的方法也称为基于端到端的方法,由于深度神经网络可以拟合复杂的函数,这一方法通常不需要其他算法辅助和中间数据,因此可以直接基于回归的网络结构预测3D姿态坐标.如TU等[16]提出的VoxelPose模型通过多视图特征构建离散化的3D特征体积,没有独立地估计每个视图中的2D姿态,而是直接将得到的2D heatmap投影到3D空间中,但在整个空间中搜索关键点的计算成本随着空间的细致划分呈几何增加,同时还受到空间离散化引起的量化误差影响.
针对以上研究存在的问题,本文对VoxelPose模型进行改进,提出一种基于heatmap的多视图融合网络(Multi-View Fusion Network,MVFNet),该网络在高分辨率网络HRNet[17]的基础上,引入反卷积模块来生成更高分辨率且语义更加丰富的heatmap,并加入对极约束模型匹配融合不同视图的人体中心点的heatmap信息.本文方法优先获取人体中心点的空间位置信息,并结合人体先验性,既减少了其他人体关键点的推理搜索空间,又降低了3D人体姿态估计的误差.
1 3D人体姿态估计模型
本文整体模型如图1所示,主要分为两个阶段:第一阶段采用MVFNet网络生成heatmap(热图),并匹配融合2D视图中不同视角下人体中心点的heatmap信息,该网络包含人体关键点检测和多视图融合两部分;第二阶段投影所有的heatmap到3D空间,通过3D CNN网络由粗到细地构建3D特征体积来估计准确的3D人体姿态.
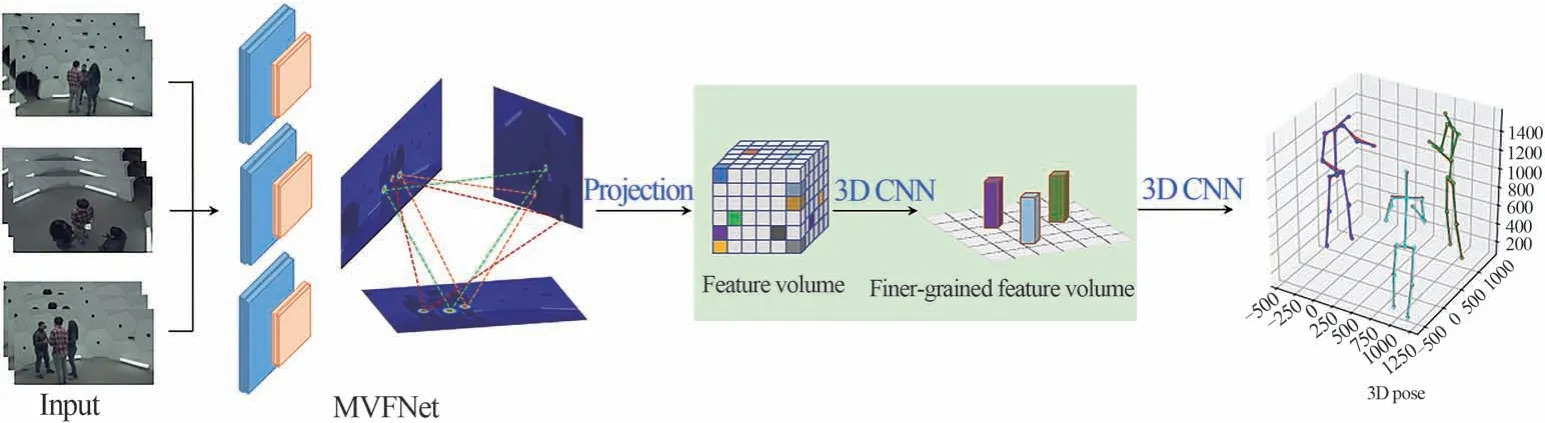
图1 网络结构图Fig.1 Network structure diagram
1.1 MVFNet网络
1.1.1 获取高分辨率heatmap
为获取高分辨率特征信息,HRNet之前的网络采用将高分辨率特征图下采样到低分辨率,再恢复至高分辨率的方法来实现多尺度特征提取,如U-Net[18]、SegNet[19]、Hourglass[20]等.在这类网络结构中,高分辨率特征主要来源于两个部分:第一是原本的高分辨率特征,由于只经过了少量的卷积操作,只能提供低层次的语义表达;第二是下采样再上采样得到的高分辨率特征,然而重复进行上下采样会损失大量有效的特征信息.HRNet通过并行多个高到低分辨率的分支,在始终保持高分辨率特征的同时逐步引入低分辨率卷积,并将不同分辨率的卷积并行连接进行信息交互,使得每一个高分辨率到低分辨率的特征都从其他并行子网络中反复接收信息,达到获取强语义信息和精准位置信息的目的.因此本文提出的MVFNet网络以HRNet为基础框架,加入反卷积模块来获得更高分辨率以及语义信息更加丰富的heatmap,如图2所示.
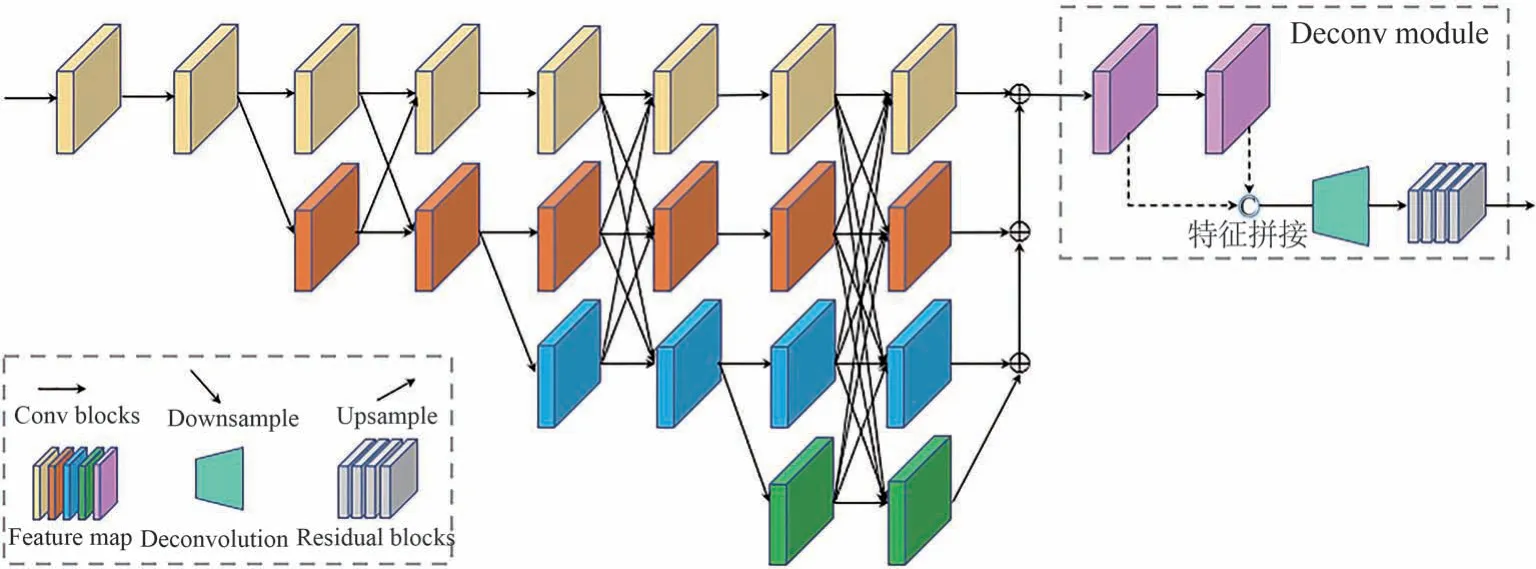
图2 关键点检测网络结构Fig.2 Keypoint detection network structure
网络分为4个阶段,主体为4个并行的子网络.以高分辨率子网为第一阶段,逐步增加高分辨率到低分辨率的子网,并将多分辨率子网并行连接.其中第一阶段包含4个残差单元,每个残差单元都和ResNet-50[21]的相同,由一个通道数为64的bottleneck构成;然后通过一个3×3,步长为2的卷积下采样到第二阶段.第二、三、四阶段分别包含1、4、3个多分辨率块,可使网络保持一定的深度,充分提取特征信息,每个多分辨率块有4个残差单元,采用ResNet的BasicBlock,即两个3×3卷积.
在网络末端将各阶段不同分辨率的特征图进行融合,融合后的特征图作为反卷积模块的输入,先经过卷积进行通道转换,其结果再与输入特征进行维度上的拼接,然后由一个卷积核为4×4的反卷积使特征图的分辨率提升为原来的2倍,再通过4个残差块进一步提取特征信息,最后由1×1的卷积来预测heatmap.其更高的分辨率有助于获得更丰富的关键点信息,进而实现准确的3D人体姿态估计.
1.1.2 多视图匹配融合
多个视图图像之间存在对极几何关系,描述的是两幅视图之间的内在射影关系,与外部场景无关,只依赖于相机内参数和视图之间的相对姿态.充分利用对极几何关系能够帮助网络获取更多的位置信息,排除训练过程中的无关噪声,提高网络预测的准确度.原理如图3所示.
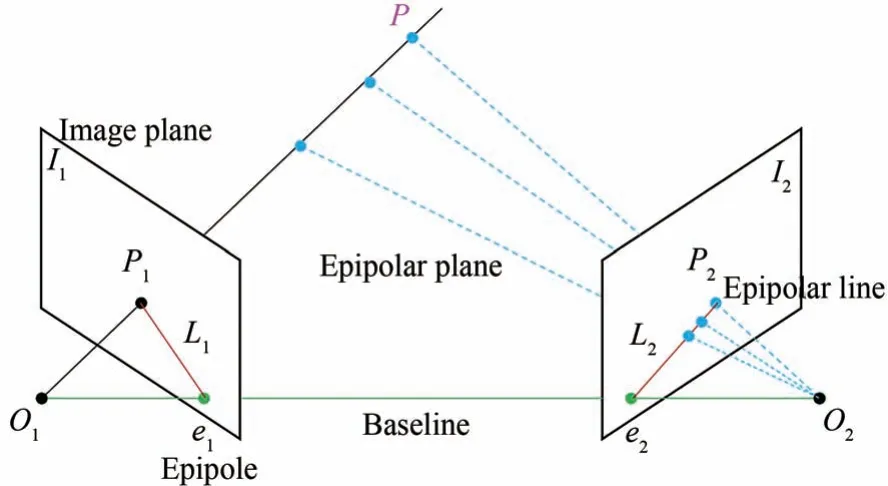
图3 对极几何示意图Fig.3 Epipolar geometry diagram
O1、O2为两个相机的光心,I1、I2为成像平面,e1、e2为相机光心在相对平面上的投影点,称为极点.如果两个相机由于角度问题不能拍摄到彼此,那么极点不会出现在成像平面上.被观察点P在I1、I2上的投影点为P1、P2,由于深度信息未知,P可在射线O1P1上的任意位置,该射线上的不同点投射到右侧图像上形成的线L2称为与点P1对应的极线,则P1在右侧图像的对应点P2必然在极线L2上.匹配点的相对位置受到图像平面空间几何关系的约束,这种约束关系可以用基础矩阵来表达,根据文献[22],对极约束公式为:

其中F为基础矩阵,计算公式如下:

其中M1和M2是两个相机内部参数矩阵,E为本征矩阵,包含相机的外参平移矩阵和旋转矩阵.因此为了充分利用视图间的几何约束关系,本文提出在MVFNet网络中引入多视图对极约束模型.取人体髋关节之间的关键点为中心点,选择同一场景不同视角下的heatmap,并通过多视图对极约束模型获得中心点对应的极线,以此为每个视角的heatmap的中心点,与其所对应的其他视角的heatmap的极线进行特征融合,来纠正和增强当前视角的效果,获得更丰富的语义信息.如图4所示.

图4 多视图对极约束模型Fig.4 Multi-view epipolar constraint model
多视图对极约束模型的输入为高分辨率heatmap,由对极几何约束关系求出各图中心点对应的极线并进行采样,得到对应点的集合.根据heatmap的特性,在相应的坐标处会生成高斯分布的概率区域,只有对应点附近有高的响应,其他地方皆接近于0,因此可用一个全连接层融合对极线上所有点的值,提高中心点检测的准确性.最后使用L2 Loss比较最终融合的中心点坐标和标注的中心点坐标之间的差距来进行训练约束.
1.2 3DCNN网络
1.2.1 粗略定位人体位置
通过逆图像投影方法将得到的所有视图的特征聚合成3D体素体积,初始化体素网格并包含摄像机观察到的整个空间,同时利用相机校准数据使得每个体素中心都被投影到相机视图中,再由3DCNN网络以此为中心由粗到细地构建特征体积来估计所有关键点的位置,网络结构如图5所示.

图5 3DCNN网络结构Fig.5 3DCNNnetwork structure
该网络输入的3D特征体积,是通过将所有相机视图中的2D heatmap投影到共同的3D空间来构建的,由于heatmap编码了中心点的位置信息,因此得到的3D特征体积也带有用于检测3D姿态的丰富信息,根据人体先验信息能减少其他关键点在3D空间中的搜索区域.绿色箭头表示标准3D卷积层,黄色箭头表示两个3D卷积层的残差块.将3D空间离散为X×Y×Z的离散位置{Gx,y,z},每个位置都可以视为检测人的一个anchor.为了减小量化误差,调整X,Y,Z的值缩小相邻anchor之间的距离.在公共数据集上,空间一般为8m×8m×2m,因此将X,Y,Z设置为80,80,20.
融合摄像机视图中每个anchor投影位置的2D heatmap的值,计算每个anchor的特征向量.设将视图a中的2D heatmap表示为Ma∈RK×H×W,其中K是身体关键点的数量.对于每个anchor的位置Gx,y,z,其在视图中的投影位置为,此处的heatmap值表示为然后计算anchor的特征向量作为所有摄像机视图中的平均heatmap值,公式如下:

其中V是摄像机的数量.可以看出Fx,y,z实际上编码了K个关键点在Gx,y,z的可能性.然后用一个3D bounding box表示包含检测到的人体关键点位置,bounding box的大小和方向在实验中是固定的,因为3D空间中人的变化有限,所以这是一个合理的简化.在特征体积F上滑动一个小型网络,以anchor为中心的每个滑动窗口都映射到一个低维特征,该特征被反馈到全连接层以回归置信度作为3D CNN网络的输出,表示人出现在该位置的可能性.根据anchor到GT位置的距离,计算每个anchor的GTheatmap值.即对于每一对GT和anchor,根据二者的距离计算高斯分数,当距离增加时,高斯分数呈指数下降.如果场景中有N个人,一个anchor可能有多个分数,经过非极大值抑制(NMS)保留N个最大的,即代表N个有人的位置.
1.2.2 构建细粒度特征体积回归人体姿态
第一个3D CNN网络无法准确估计所有关键点的3D位置,因此在第二个3D CNN网络中构建更细粒度的特征体积,大小设置为2000 mm×2000 mm×2000 mm,比8 m×8 m×2 m小得多但足以覆盖人的任何姿势,该体积被划分为X0=Y0=Z0=64个离散网格,其网络主体结构与第一个3D CNN相同.基于构造的特征体积,估计每个关键点K的3D heatmapHK,最后回归准确的3D人体姿态,HK∈RX0×Y0×Z0.根据公式(4)计算HK的质心,即可得到各关键点的3D位置DK:
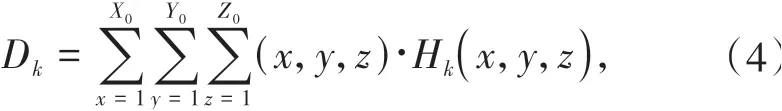
将估计的关节位置与真实位置D*进行比较以训练网络,损失函数L1的公式为:
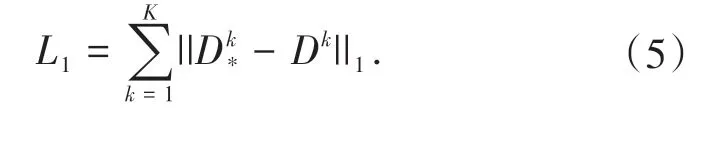
2 实验结果与分析
2.1 实验数据集
本文采用3个公共数据集Campus、Shelf、CMUPanoptic进行实验,其中Campus数据集通过3个摄像机捕获了3个人在室外环境中的互动情况,共1.2万张图片.Shelf数据集由5个摄像机拍摄4个人拆卸货架的活动,共1.6万张图片.CMU-Panoptic数据集是目前用于多人3D姿态估计的最大数据集,包含30多个高清摄像机拍摄的65个日常活动视频序列和150万个人体骨骼关节注释,选取3、6、12、13、23视频序列得到73万张图片.按照标准[23]把视频序列中的160422_ultimatum1,160224_haggling1,160226_haggling1,161202_haggling1,160906_ian1,160906_ian2,160906_ian3,160906_band1,160906_band2,160906_band3作为训练集;160906_pizza1,160422_haggling1,160906_ian5,160906_band4作为测试集.
2.2 评价指标
使用正确估计关节位置的百分比PCP3D(Percentageof Correct Part 3D)来评估Campus和Shelf数据集3D姿态的准确性,如果预测的关节位置和真实关节位置之间的距离小于肢体长度的一半,则认为检测正确[14].对于CMU-Panoptic数据集,采用每个关节位置的误差的平均值MPJPE(Mean Per Joint Positon Error)作为重要评价指标,以毫米为单位评估3D关节的定位精度,表示GT和预测关节位置之间的距离.对于每帧f和人体骨架S,MPJPE的计算公式如下:

其中NS是骨架S中的关节数,对于一组帧,误差是所有帧的MPJPE的平均值;同时在MPJPE的阈值(从25 mm到150 mm,步长为25 mm)上取平均精度(Average Precision)和召回率(Recall)作为综合评估3D人体中心检测和人体姿态估计的性能指标.AP是由横坐标Recall、纵坐标精确率(Precision)两个维度围成的PR曲线下面积,AP的值越大说明检测模型的综合性能越好.
2.3 实验结果及分析
实验基于Linux搭配Pytorch深度学习框架实现,具体实验环境如表1所示.

表1 实验环境配置单Tab.1 Experimental environment configuration sheet
2.3.1 Shelf和Campus数据集的实验结果分析
在Shelf、Campus数据集训练过程中,输入图像的尺寸设置为800×640,batch_size、缩放因子、最大迭代轮次、学习率的初始值、人体关键点数目分别设置为2,0.35,30,0.0001和17.采用Adam优化器自动调整学习率,初始3D空间网格划分为80×80×20,构建细粒度特征体积时,空间网格划分为64×64×64.实验结果与VoxelPose进行比较,PCP3D数据如表2所示.
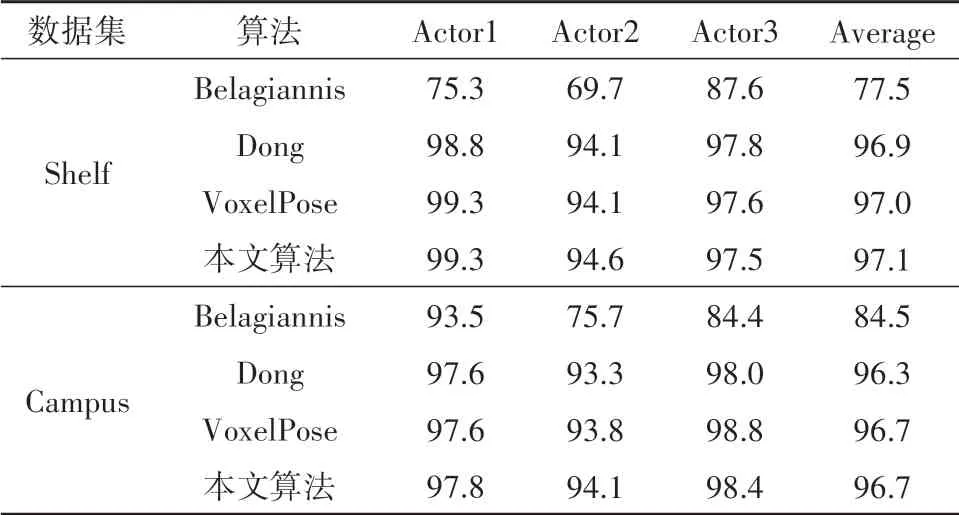
表2 Shelf和Campus的PCP3D对比Tab.2 Comparison of PCP3Din Shelf and Campusdatasets /%
对比两个数据集的实验结果可以看出,PCP3D在Shelf中的平均值提升了0.1%,在Campus的Actor1、Actor2均略有提升,说明综合考虑2D人体中心点的多视图匹配融合有助于提高3D人体姿态估计的准确率.由于这两个数据集的GT姿态注释不完整,因此没有进行AP和Recall的对比.通过可视化的结果发现:只要关键点在至少两个视图中可见,通常可以得到准确的人体姿态估计,可视化结果如图6所示.
由图6可发现在Shelf数据集中,由于缺少一部分红圈中人的GT注释,所以存在无法检测到该人关键点的情况,输出的301帧中只有66帧正确检测到关键点,但仍可以恢复其3D姿态.Campus数据集的注释比较准确,即使在3号相机中存在严重的遮挡的情况下,两人几乎重合,本文算法通过融合2D人体中心点的特征信息可更精准地定位其在3D空间中的位置,进而由3D CNN网络构建由粗到细的特征体积来估计其他关键点的位置,得到更加准确的人体姿态,因而通过另外两个相机检测到Actor1和Actor2关键点的准确度有所提升.3D人体姿态估计结果如图6右所示.

图6 Shelf(上)和Campus(下)数据集3D姿态估计Fig.6 Shelf(up)and Campus(down)datasets3Dposeestimation
2.3.2 CMU-Panoptic数据集的实验结果分析
不同的数据集所采集的图像参数和人体关键点注释不同,因此设置输入图像的尺寸为960×512,epoch和人体关键点数目分别为10,15,其他超参数与前两个数据集一致.本文模型的AP、Recall与VoxelPose的对比如表3所示.

表3 CMU-Panoptic的评估指标对比Tab.3 Comparison of evaluation indicators in CMU-Panoptic dataset/%
在AP25上相较于VoxelPose提升了4.6%,Recall提高了2.17%.重要指标MPJPE方面,VoxelPose为17.82 mm,本文算法为16.80 mm,降低了1.02 mm.说明在2D关键点检测网络中,生成的高分辨率heatmap带有更丰富的特征信息,融合不同视图的人体中心点heatmap能够带来准确的3D空间位置信息,并结合人体先验性有效缩小了其他关键点的推理范围,从而降低了误差,实现了更高精度的3D人体姿态估计.可视化效果见图7,在吃披萨和弹乐器的活动中,即使有人体和桌椅遮挡,仍然能检测到腿部关键点,但对小孩的姿态估计存在一定的误差,因为小孩关键点间距较小,且只有少量的GT注释和样本数据,所以导致估计的效果不佳.综合表2和表3的实验数据可验证在确定2D人体中心点位置的基础上进行3D空间推理从而恢复人体姿态的方法是有效的,在不同程度上提高了检测各个关键点的精确度,降低了每个关节位置的误差的平均值.

图7 CMU-Panoptic数据集3D姿态估计Fig.7 CMU-Panoptic dataset 3D pose estimation
3 结论
本文针对自然环境下遮挡和检测不准确等问题,提出了一种基于heatmap的多视图融合网络MVFNet来估计3D人体姿态.网络以HRNet为基础加入反卷积模块生成更高分辨率的heatmap,获得更加丰富的语义信息;然后通过对极约束模型匹配融合中心点特征,可优先确定中心点在3D空间中的位置,缩小其他关键点的推理范围;再经过3D CNN网络构建特征体积得到各关键点的空间位置;最后回归出准确的3D人体姿态.实验结果表明:本文的改进模型相较于VoxelPose具有良好的性能和效果,有一定的工程应用价值.
