基于改进CASREL的水稻施肥知识图谱信息抽取研究
2023-01-05郑彭元袁立存戈为溪
周 俊 郑彭元 袁立存 戈为溪 梁 静
(南京农业大学工学院,南京 210031)
0 引言
水稻是世界三大主要粮食作物之一[1],是世界上65%以上人口的主粮,而我国是世界上水稻生产量、消费量最多的国家[2];增加化肥使用量是增加水稻产量最直接的方式之一[3],但会对土壤与环境造成影响,因此水稻的合理施肥对水稻生产至关重要。由于我国各地区土壤种类复杂,相关研究都重点集中在作物本身生长机理而忽略了土壤肥力的表达水平,从而导致已有的水稻施肥信息系统通用性差。
随着智慧农业的兴起,产生了大量的农业信息数据[4]。这些非结构化的数据中包含了农业相关的关键信息,例如水稻等农作物施肥、播种、施药。知识图谱作为人工智能的重要组成部分,广泛应用于各个领域。知识图谱能够将不同类型的实体、概念进行组合进而以可视化的形式展示知识间的结构关系[5-6],极大地提高了信息检索的效率。相关研究者将知识图谱应用到农业领域从而促进农业信息技术的进步,袁培森等[7]提出了一种对水稻的基因、环境、表型等表型组学实体进行关系分类的方法,进而改善水稻表型知识图谱中实体关系抽取问题。于合龙等[8]利用知识图谱对水稻病虫害领域复杂的非结构化数据信息进行结构化存储,为水稻病虫害关联检索及智能诊断提供理论依据。吴赛赛[9]利用知识图谱以结构化的形式描述实体间复杂关系的优势,提出了一种基于深度学习的作物病虫害知识图谱构建方法。但是这些知识图谱的规模化、体系化方面仍存在许多不足,在实现非结构化数据的有效提取、解决文本重叠关系提取等方面仍是当前面临的一大挑战[10]。此外知识图谱在农业领域的应用及研究处于初级阶段,利用知识图谱从分散性、多种类、连贯性差的农业数据中提取关键的、有价值的农业信息是未来研究的重点。
如今人工智能已经渗透到各个领域,其中知识图谱表现出了很高的实际应用价值,根据领域构建不同的知识图谱,同时结合不同算法能够极大地提高解决问题的效率。马展等[11]为提高应用程序接口API的检索效率,提出多源信息融合的API知识图谱构建方法。在医学领域,张兴等[12]通过在网络中提取与儿童病护理相关的数据,构建关于儿童病护理的问答数据集,然后利用算法及自然语言处理相关模型实现人工特征转换效率的提高。在航空领域,大数据平台建模也得到飞速发展,但是由于数据不能实现跨专业的贯通导致数据价值不能被全面挖掘。韩吉南等[13]通过构建航天装备数据知识图谱,利用大数据、人工智能知识挖掘航天数据,实现数据的规范化管理。
知识图谱是结构化数据表示中最有效、最简洁、最强大的方法之一。而信息抽取作为构建知识图谱的基础技术,是大规模构建知识图谱的关键一步。面向知识图谱的信息抽取主要是针对关系三元组进行抽取,而重叠三元组问题会极大影响抽取结果。WEI等[14]针对重叠三元组问题提出了CASREL模型,并与ZHENG等[15]提出的NovelTagging,ZENG等[16]提出的CopyR,FU等[17]提出的GraphRel,以及不同编码random-CASREL、LSTM-CASREL、BERT-CASREL进行消融实验,证明了CASREL模型在应对重叠三元组情况的优越性。
本文以水稻施肥信息为研究对象,构建水稻施肥知识结构,根据现有的水稻施肥非结构化数据信息,提出并设计水稻施肥知识图谱实体及关系知识结构,将网络中现存的水稻施肥信息通过该知识结构以结构化数据存储到知识图谱中;为提取大量信息存入知识图谱中,同时针对信息抽取即重叠三元组问题,提出基于RoBERTa-wwm编码+改进CASREL解码的信息抽取模型,进行一系列消融实验,并根据水稻施肥数据特点对模型进行改进,以期实现句子级别的信息抽取,为构建水稻施肥知识图谱以及制作水稻施肥决策系统提供数据基础。
1 水稻施肥信息数据集
目前,有关水稻施肥结构化数据的资源有限,且数据可信度参差不齐。因此,本文有关水稻施肥信息的数据集主要从中国知网和国家水稻数据中心获取,共节选原始数据978句用于数据集标注。
数据集作为模型的输入,用来对模型参数进行训练,模型训练效果部分取决于数据集的质量。由于本文关系种类大部分与水稻施肥信息相关,现存的开源数据集并不适用于本模型训练,因此采用人工标注的方法制作所需数据集。
1.1 水稻施肥关系种类
结合文献中水稻种植所需信息[18-19],设计图1所示的水稻施肥体系数据结构,共27种关系。
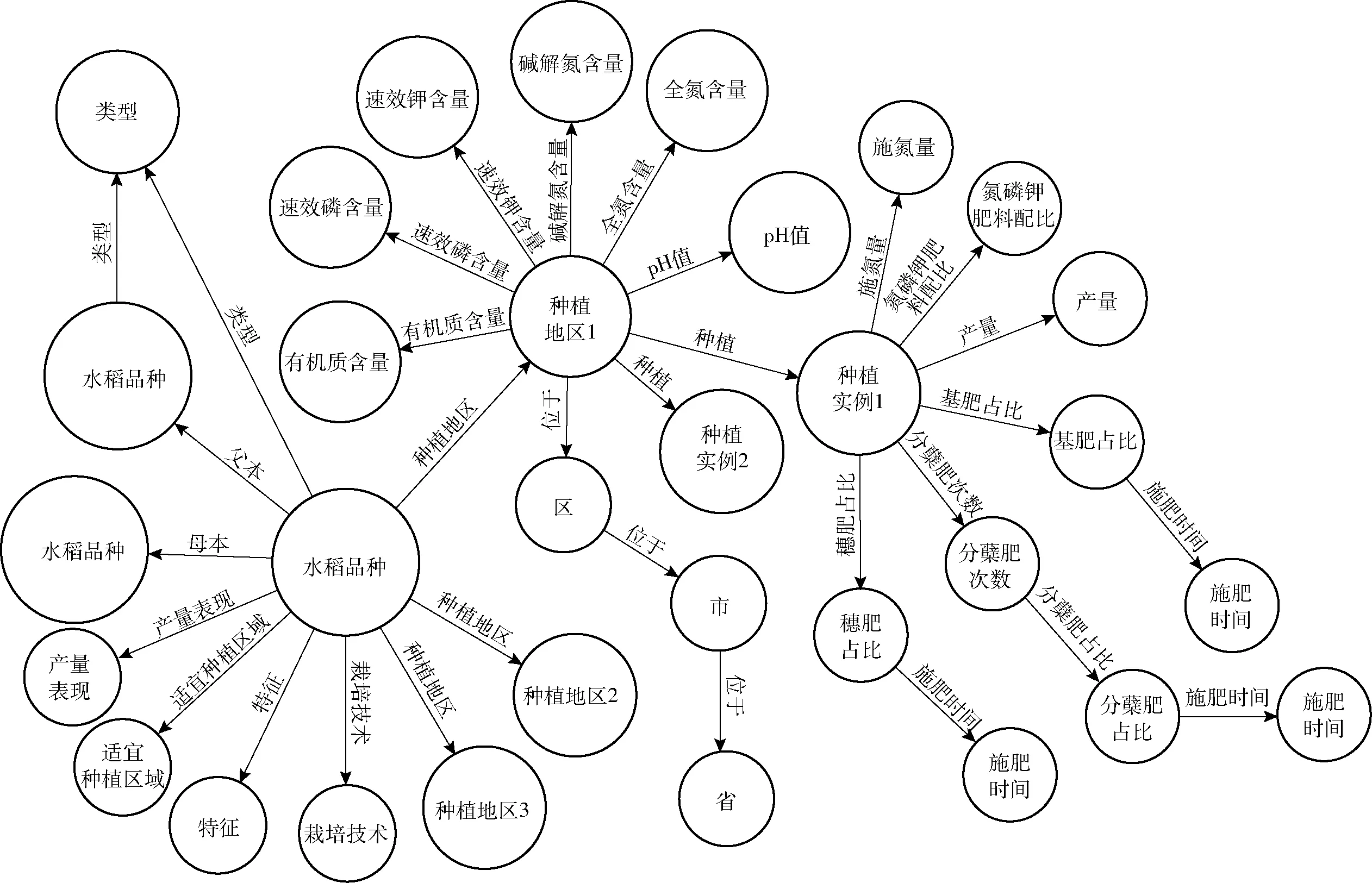
图1 水稻施肥体系数据结构
其中,不同水稻品种之间以父本/母本及水稻类型(粳稻/籼稻)相互连接。对于每个水稻品种,储存其特征、栽培技术、适宜种植区域及产量表现作为其基本信息。同时,将种植实例以地区为单位与水稻品种相连接,储存实验地区的土壤养分情况并与所在省、市、区相连接。最后,将不同种植实例与种植地区相连接,并将施氮量、氮磷钾肥料配比、基蘖穗肥配比及施肥时间、产量与种植实验相连接,形成完整的水稻施肥知识图谱结构。
对原始数据以句子为单位划分,并对数据集进行标注,标注格式为:句子,头实体,关系类型,尾实体。标注完成的数据集示例如表1所示。

表1 水稻施肥信息数据集示例
1.2 水稻施肥信息数据集分配
将标注好的水稻施肥数据集以5∶2∶3的比例随机分配为训练集、验证集和测试集,其中训练集506条数据,验证集189条数据,测试集283条数据。各个数据集关系类型数量如表2所示,其中N表示一个句子中关系三元组的个数。
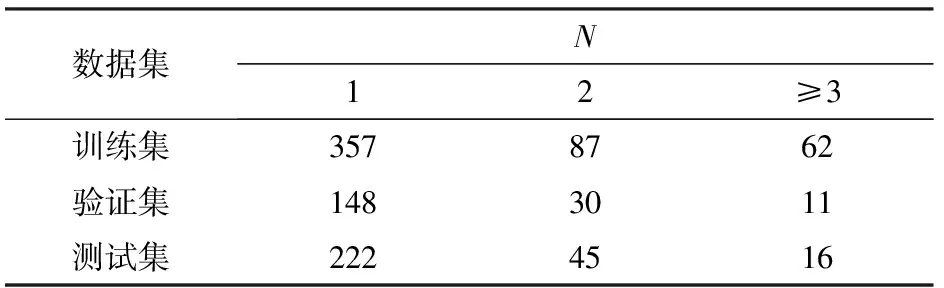
表2 水稻施肥数据集关系类型数量
2 水稻施肥信息抽取模型构建
为了构建抽取效果更好的水稻施肥信息抽取模型,本文采用Encoder-Decoder结构对模型进行构建,模型流程图如图2所示。BERT系列模型相较于RNN、LSTM等模型在编码环节效果更好,且由于数据集为中文,传统BERT模型并不能很好地适应中文语料,因此选择RoBERTa-wwm作为模型的编码器(Encoder)结构;本文数据集中多为重叠三元组(多个关系三元组共享同一个实体),传统信息抽取模型在应对该问题上效果欠佳,而CASREL模型的级联二元标注结构能很好地处理该问题,因此选择CASREL作为模型的解码器(Decoder)结构;为使得通用模型在特定场合能取得更佳效果,结合水稻施肥数据集的特征对该模型进行改进。
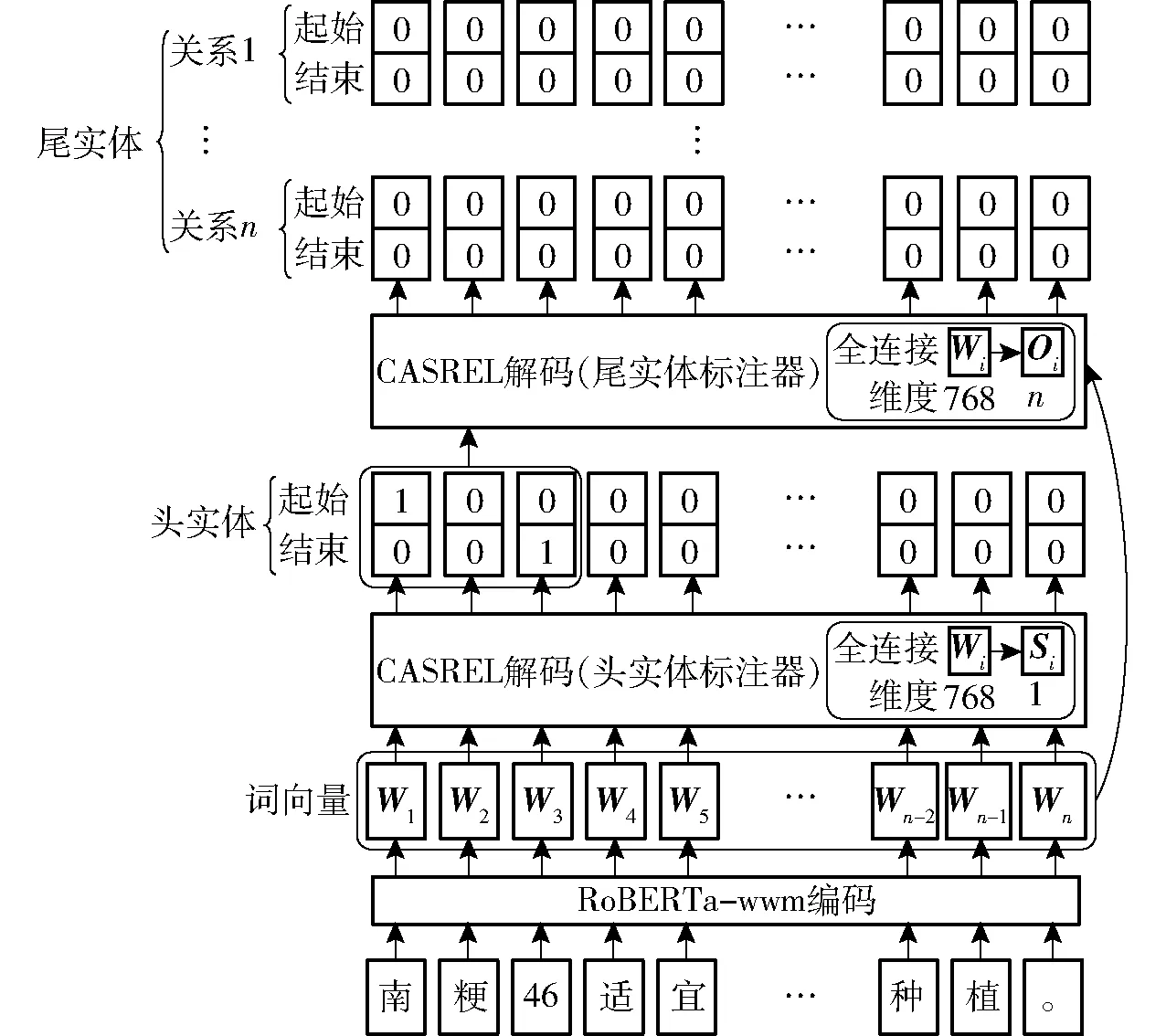
图2 RoBERTa-wwm-CASREL模型流程图
2.1 Encoder-Decoder结构
Encoder-Decoder(编码器-解码器)结构又被叫做Seq2Seq结构,是深度学习中常见的模型框架之一[20]。Encoder由一个编码器将输入序列转化成一个固定维度的稠密向量,Decoder阶段对这个向量进行解读并生成结果[21]。Encoder-Decoder结构将模型分为两部分,这种结构可以有效解决在处理长距离序列化问题时造成的误差累积情况。
2.1.1RoBERTa-wwm编码模型
RoBERTa模型是基于BERT模型的一种优化版本,与BERT模型相同的是,RoBERTa模型的结构也是由多层双向 Transformer 组成的[22-24],并对BERT模型进行了一系列优化[25-26]。
由于BERT的系列模型都是以字为单位进行切分,Mask操作也是以字为单位,这种切分方法在中文语料中效果较差。全词掩码(Whole word masking,WWM)针对这一问题,充分考虑了中文语料的分词操作,以词为单位进行Mask操作。研究表明,使用WWM的BERT系列模型在中文语料中取得了更好的效果[27]。
2.1.2CASREL解码模型
CASREL解码模型主要针对目前既有模型处理重叠关系三元组[28]效果不好的问题,模型是一种级联二元标注框架,基本思想是用两级联步骤提取三元组[14]。首先,从输入句子中检测出头实体。然后,对于每个候选头实体检查所有可能的关系,确定是否有一个关系可以将句子中的尾实体与该头实体联系起来。与这两个步骤相对应,级联解码器由头实体标注器和特定关系的尾实体标注器组成。头实体标注器模块通过直接解码编码器产生的编码词向量来识别输入句子中所有可能的头实体,特定关系的尾实体标注器模块同时识别尾实体以及与头实体标注器获得的头实体的相关关系。
2.2 模型改进
在水稻施肥数据集中,与施肥决策相关的数据大部分都在尾实体,而尾实体多由数字加单位组成,因此,为了使模型的提取效果更好,提高对包含上述尾实体的三元组的抽取能力,本文在尾实体标注器的输入中加入了单位标注器模块。单位标注器模块在对句子进行编码的同时,使用正则方法对句子中的单位符号进行匹配,对匹配到的符号作为结束标注位并向前通过判断是否为中文字符的方法找到起始标注位,将起始标注位到结束标注位标注为1,其余位标注为0,形成句子标注信息,并在尾实体标注器解码时,将标注信息与编码词向量和头实体标注器的结果相加,使得该位置有更大的可能作为尾实体被抽取出来。
同时,由于原CASREL模型头实体标注器和尾实体标注器均采用直接解码的方式,三元组提取效果较差,如果在原模型基础上加入一层隐藏层[29],考虑使用更多的参数来提高模型对水稻施肥信息抽取的效果,但随着抽取到的信息增多,也会造成模型精度下降。由于原模型训练结果精度较高,因此加入维度为1 024的隐藏层,在略降低精度的情况下,提高模型对水稻施肥信息抽取的效果,改进后的模型流程图如图3所示。
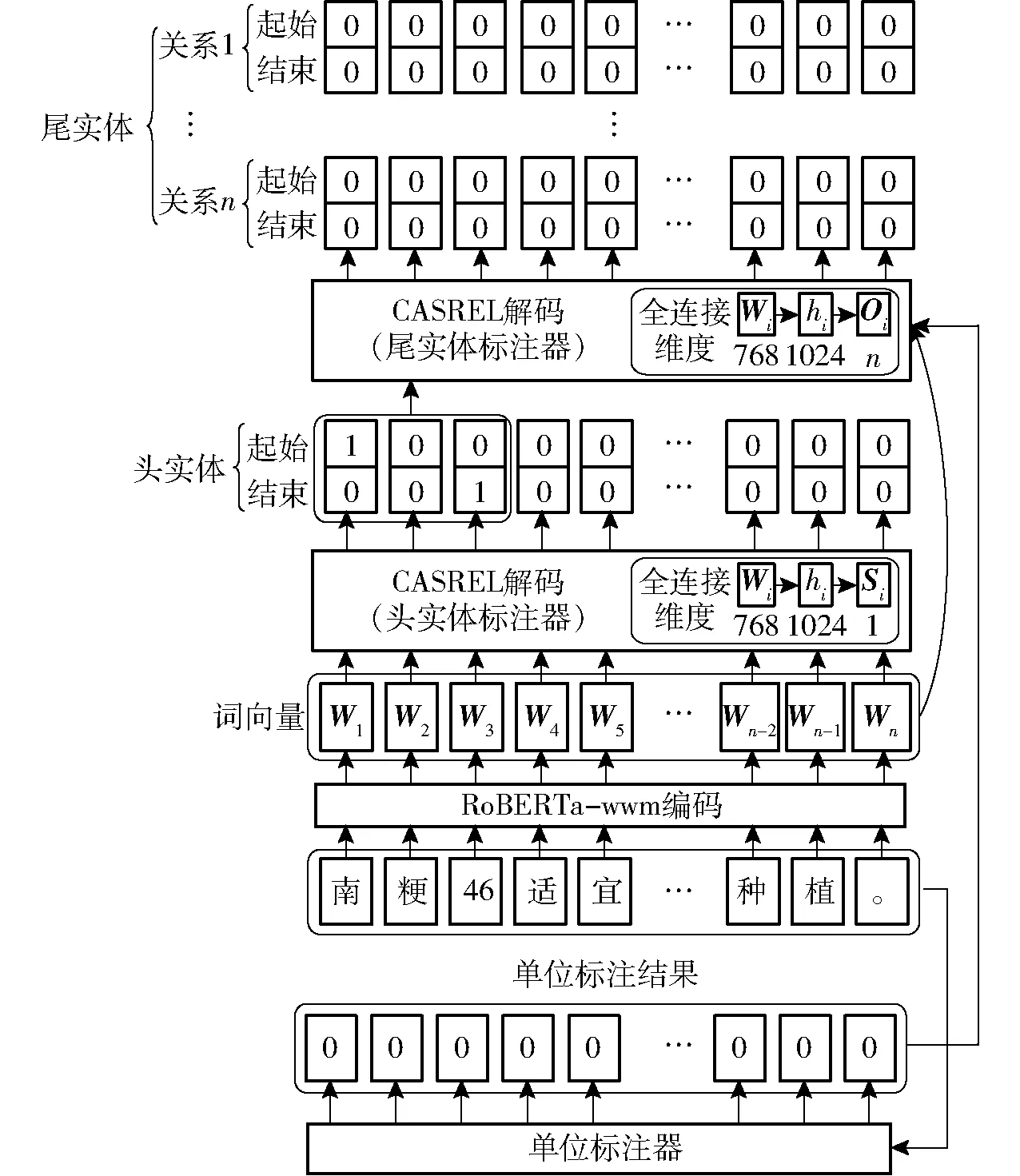
图3 改进后RoBERTa-wwm-CASREL模型流程图
3 模型训练结果与分析
3.1 训练环境
选择Intel(R)Core(TM)i7-10700K CPU @ 3.80 GHz,GPU为NVIDIA GeForce RTX 3060 Ti,16 GB内存,Windows 10操作系统,运行环境为Pytorch 1.9.0+cuda 11.1。
3.2 参数设置
水稻施肥模型参数设置如下:学习率1×10-5,批量大小6,迭代次数100,梯度下降算法ADAM。
3.3 算法性能评估指标
使用精确率(Precision)、召回率(Recall)、F1值作为评价指标[30],其中,精确率是指预测正确的三元组数与预测三元组总数的比值,召回率是指预测正确的三元组数与实际三元组总数的比值[31]。编码部分将RoBERTa-wwm与BERT-base-chinese和BERT-wwm进行对比,解码部分将原CASREL模型与改进后模型进行对比。
3.4 模型信息抽取结果分析
3.4.1不同梯度下降算法对比分析
本文对RoBERTa-wwm-CASREL模型进行了不同梯度下降算法[32]的对比,随机梯度下降算法(SGD)学习率选择1×10-3,F1值训练过程如图4所示,最终训练结果如图5所示。
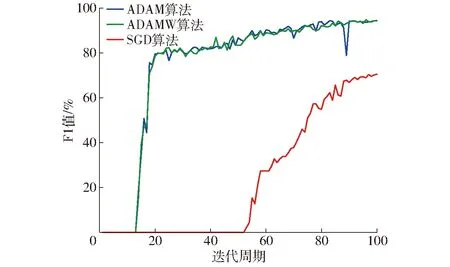
图4 不同梯度下降算法F1值训练过程
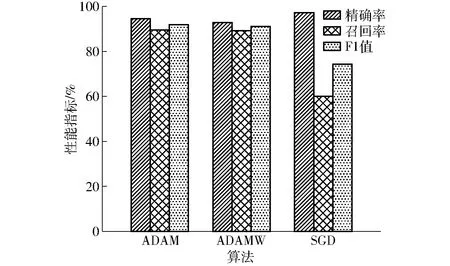
图5 不同梯度下降算法训练结果
由图4可以看出,相同迭代次数下,ADAM算法和ADAMW算法的F1值高于SGD算法,ADAM算法和ADAMW算法的优化速度始终高于SGD算法;ADAM算法在训练过程中存在一定的波动,第90轮迭代时,ADAM算法波动较明显,而ADAMW算法在整个训练过程中较为稳定。由图5可得,ADAM算法的最终F1值为91.86%,略高于ADAMW算法,而SGD算法F1值仅为74.25%,相对于另外两种算法结果较差;但就精确率而言,SGD算法的精度达到97.11%,而另外两种算法的精度均低于95%。
3.4.2不同批量大小对比分析
选择批量大小为6、12、24进行水稻施肥信息抽取试验,梯度下降算法选用ADAM算法,在RoBERTa-wwm-CASREL模型上的结果如表3所示。

表3 本文模型不同批量大小时性能对比结果
由表3可以看出,当批量大小为6时,精确率达到94.34%,F1值达到91.86%,召回率为89.51%;随着批量大小的增加,模型F1值不断下降,所需时间减少。批量大小从6增加到24,F1值降低9.72个百分点,所需时间减少372.96 s。
3.4.3解码模型对比分析
本文将改进后CASREL模型与原模型进行对比,梯度下降算法选用ADAM算法,批量大小为6,在本文数据集上进行训练并对结果进行对比分析,模型训练过程如图6所示,最终训练结果如表4所示。
由图6可以看出,改进后模型的优化速度比原模型有一定的提升,且F1值、精确率、召回率的训练过程均优于原模型,且相对稳定。优化速度变快是由于在原模型中加入了单位标注器模块,从而实现模型在训练过程中可以更简单、更快速地找到被标注的实体。
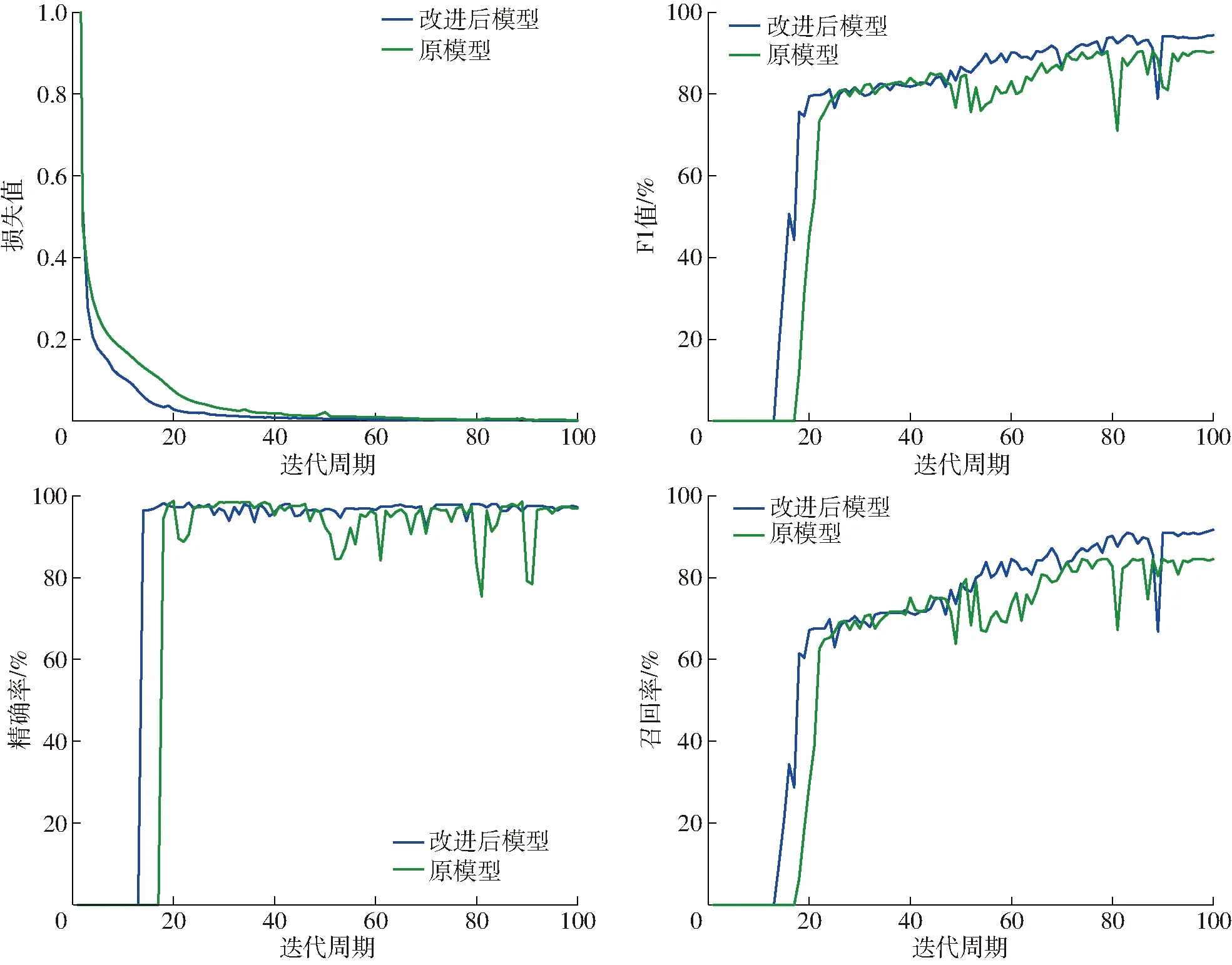
图6 模型训练结果
由表4可看出,改进后模型精确率为94.34%,召回率为89.51%,F1值为91.86%;相比于原模型,召回率提高4.6个百分点,F1值提高1.77个百分点,但精度降低1.61个百分点。而且改进后模型较原模型多预测25个三元组,预测正确的三元组多18个。这是由于在原模型中加入了单位标注器模块的同时,在解码过程中加入了隐藏层,使模型效果更好。

表4 解码模型对比结果
3.4.4不同预训练模型编码对比分析
将BERT-base-chinese、BERT-wwm-ext、RoBERTa-wwm-ext模型分别作为水稻施肥信息模型的编码模型进行对比。BERT-base-chinese是Google提供的基础中文预训练模型,BERT-wwm-ext和RoBERTa-wwm-ext是Google基于WWM在2019年5月31日发布的一项BERT的升级版本,语料为EXT数据。EXT数据包括中文维基百科、其他百科新闻、问答等数据,总词数达54亿。梯度下降算法选用ADAM算法,批量大小为6,最终训练结果如表5所示。

表5 不同编码模型对比结果
由表5可以看出,RoBERTa-wwm-ext模型的精确率为94.34%,召回率为89.51%,F1值为91.86%,相对于BERT-base-chinese模型,精确率提高15.47个百分点,相较于BERT-wwm-ext编码,精确率降低0.15个百分点;而相较于BERT-base-chinese编码与BERT-wwm-ext编码,F1值分别提高16.79、0.88个百分点;由此可见,基于WWM的BERT-wwm-ext编码,在中文任务上取得的效果远超于BERT-base-chinese编码,而RoBERTa-wwm-ext编码相对于BERT-wwm-ext编码应用了更多的参数,效果有一些提升。
3.5 模型应用
将《不同施氮量对水稻南粳46产量及品质的影响》[33]一文以及国家水稻数据中心中关于该品种的信息作为输入在原模型与改进后模型中进行试验,得到的水稻施肥三元组抽取结果如表6所示。
从表6中可以看出,模型对输入数据的抽取效果较好,水稻施肥决策所需信息基本抽取正确,改进后模型针对包含单位尾实体抽取效果有较大提升。同时发现模型对特定地点抽取效果较差,这是由于数据集的数量有限,若实体未在数据集中出现,会导致模型结果较差,针对这种情况,选择通过大量农业相关中文语料对编码模型进行预训练,可能会提高模型在该情况中的效果。

表6 水稻施肥三元组抽取结果
综上所述,改进后的RoBERTa-wwm-CASREL模型在进行水稻施肥信息抽取任务时,能有效提高信息抽取率,同时,选择最优的编码模型在一定程度上也使得模型效果更佳。
4 结束语
提出了基于改进RoBERTa-wwm-CASREL模型的水稻施肥信息抽取方法。根据水稻施肥所需信息,定义了水稻施肥体系数据结构并制作了水稻施肥数据集。结合水稻施肥数据特点,通过添加单位标注器和在CASREL解码中添加隐藏层来对模型进行改进。对比试验结果表明,改进后模型精确率、召回率与 F1值分别达到94.34%、89.51%和91.86%,优于原模型。改进模型可以对水稻施肥数据进行有效的信息抽取,为构建水稻施肥知识图谱提供了数据基础。
