一种基于GAN的轻量级水墨画风格迁移模型
2023-01-04李菲菲
赵 晋,李菲菲
(上海理工大学 上海康复器械工程技术研究中心,上海 200093)
水墨画作为一种传统的中国画,其笔触与墨色复杂多样,绘画技巧灵活丰富,具有独特的艺术魅力和巨大的研究价值,因此得到了越来越多研究者的关注。现有的中国画数字化的研究主要集中于图像检索和图像分类[1-2]。然而创作一幅水墨画通常需要丰富的经验和特定的技巧,因此研究利用相关算法自动生成水墨画作将有利于对中国传统文化的继承和保护。
近年来,随着深度学习[3]技术的发展,风格迁移技术逐渐成为图像处理领域的热点问题,其目的是将给定的图像渲染成不同的艺术风格,同时保证输入图像的内容不发生改变。文献[4]开创性地将CNN(Convolutional Neural Network)用于图像的艺术风格转换,通过利用预训练好的VGG(Visual Geometry Group)网络[5]提取到的特征来重新组合任意给定图片的内容和艺术图片的风格样式,从而完成风格迁移。文献[6]提出了AdaIN(Adaptive Instance Normalization),通过全局特征统计来调整内容图像的均值和方差去匹配样式图像的均值和方差。该方法不仅可以实时地变换任何风格,还可以保证计算效率,减少运行时间。得益于GAN(Generative Adversarial Network)[7]出色的生成能力,它逐渐在风格迁移领域得到了广泛的应用,其生成的结果在视觉上更加逼真。其中较为经典的有监督风格迁移模型Pix2Pix[8]以及无监督模型CycleGAN[9]。然而,现有的风格迁移算法大多适用于西方绘画,直接将这些方法应用于中国水墨画无法取得理想的效果,这是中西方绘画的内在差异所导致的。西方的绘画作品通常十分接近自然图片,整个画面充满多种色彩,而中国水墨画只使用单色墨或渐变的墨色来做画,并且画面中某些区域含有空隙,造成一种留白的效果。为了实现中国水墨画的风格转移,文献[10]首次提出了一个弱监督水墨画风格迁移框架ChipGAN,它从留白、笔触、水墨扩散3个方面来提升水墨画的迁移效果。但是该方法参数量较大,训练时间久,实际的迁移效果并不逼真。因此,本文的目标是构建一种新的算法,在降低参数的同时还能提升水墨风格迁移的质量。
在ChipGAN研究工作基础之上,文中提出了一种新的基于GAN的轻量级风格迁移算法,用于中国水墨画的风格转换,旨在一定程度上针对性地解决水墨画风格迁移质量不佳的问题。该方法首先引入了改进的风格注意力模块来学习内容特征和水墨风格特征之间的相关性,从而将语义上最相近的风格和内容特征进行匹配;然后将其结果和AdaIN的结果进行融合,使得模型更为准确地学习到水墨画所特有的风格特征。为了保证风格注意模块能够正确地学习到内容和风格特征之间的依赖关系,采用了预训练好的VGG网络[5]作为编码器,并对内容图片和风格图片进行统一的编码。另外,本文通过添加循环一致损失来保留图像的主要内容,在重建过程中加入了感知损失来修正图像的细节,生成更高质量的图像。本文通过定性和定量两种实验对新方法进行评估。结果表明该算法具有更少的参数量,更低的训练时间,生成的水墨画风格迁移效果更加真实。
1 生成对抗网络
生成对抗网络[7]因其在学习高维且复杂数据分布方面的潜力而成为深度学习领域的热点之一。具体来说,GAN可以不依赖任何关于分布的假设,以一种简单方式从潜在空间生成类似真实数据的样本。这一特性使得GAN在图像处理领域中有着广泛的应用[11-14],尤其在风格迁移[8-10]等问题中,GAN对于改变图像中的某些特征有良好的性能表现。GAN是一种生成模型,由生成器和判别器两个模型组成,这两个模型通常由神经网络来实现。生成器尝试捕获真实示例的分布以生成新的数据样本来欺骗判别器。判别器通常是一个分类器,它将生成样本和真实样本尽可能准确地区分开来。在训练中,两者通过对抗的方式,各自性能均得到了提高。当优化达到了纳什均衡时,可以近似认为生成器已经学习到了真实样本示例的分布,即生成器能够生成足够逼真的样本。GAN的优化问题是一个极小极大问题,其目标函数为
Ez~Pz(z)[log(1-D(G(z)))]
(1)
式中,G和D分别表示生成器和判别器;Pdata表示真实样本的分布;Pz表示随机噪声的分布;E(·)表示计算期望值;D(·)表示计算的概率值;x表示输入的真实图像数据;z表示输入的噪声。
2 基于GAN的轻量级水墨画风格迁移模型
2.1 模型整体框架
模型的整体框架如图1所示,主要包括两个生成器(G和F)和一个判别器D。其中每个生成器的结构是相同的,由VGG-19网络构成的编码器、AdaIN和风格注意力模块以及解码器组成。判别器采用了与PatchGAN[8]相同的网络结构。
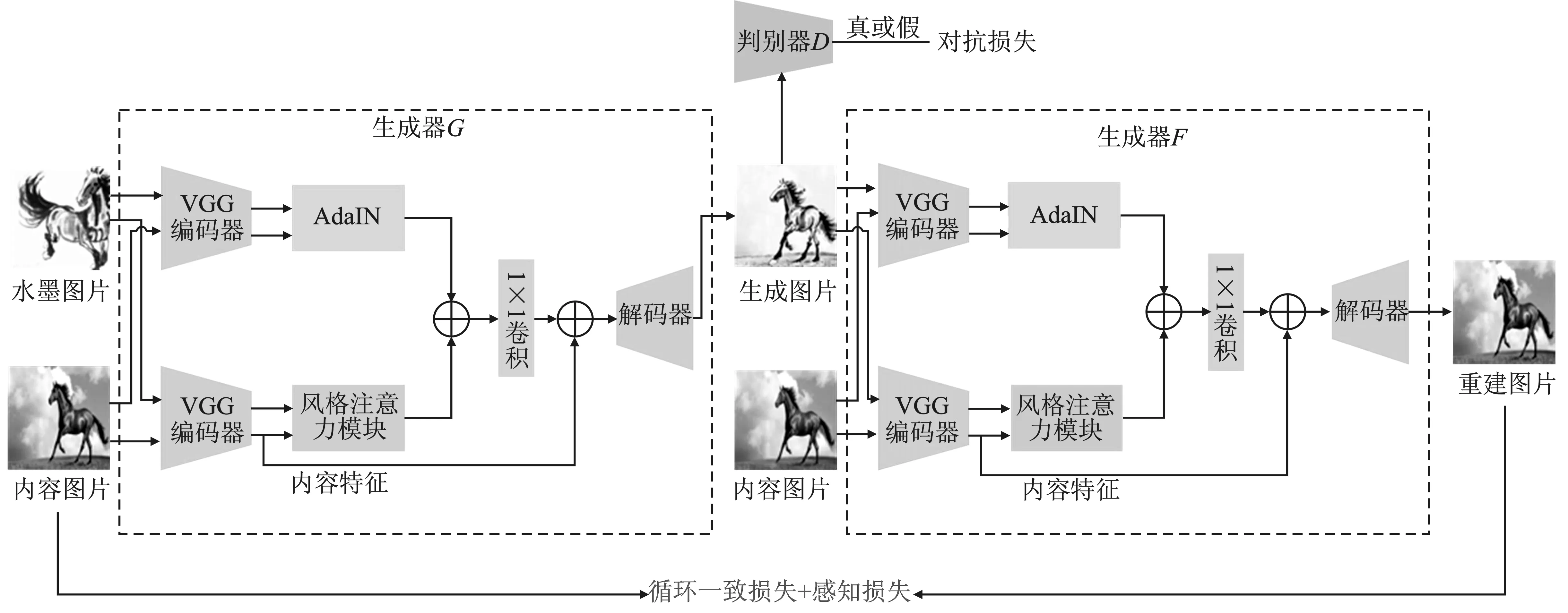
图1 模型整体架构Figure 1. The overall architecture of model
生成器G负责学习一种映射关系,将真实的图片以及水墨风格图片作为输入,生成和水墨风格相类似的图像。生成器F则学习一种反向映射,同样将生成的图片以及真实的图片作为输入,生成重建后的图像,并尽可能使生成的重建图片与输入的真实图片相近。这一重构过程可以让图像在迁移过程中保持图像的主要内容不发生改变。判别器D负责鉴别输入的图像是真实的水墨图像还是生成的虚假图像。在实际中将真实的水墨图像作为正样本,对生成的图像作为负样本对判别器进行训练。另外,本文还引入了对抗损失、循环一致损失以及感知损失来更新生成器网络的参数。
2.2 生成器模型
为了提高水墨风格迁移过程中生成图像的真实性,得到高质量的水墨风格图像,本文引入了一个新的生成器网络架构,主要包括VGG-19网络[5]构成的编码器、AdaIN模块、风格注意力模块以及解码器4个部分。
2.2.1 VGG-19网络编码器
实验表明,采用常规的编码器对真实图像和风格图像进行编码会降低生成图像的质量,这是由于在网络训练过程中,编码器对真实图像和风格图像进行了错误的编码,导致后续风格注意力模块学习到了不正确的风格表示,因此导致迁移的效果不理想。为了解决这一问题,采用预训练好的VGG-19网络作为编码器,并选择其ReLU_3_4层的输出作为后续AdaIN和风格注意力模块的输入。由于预训练好的VGG-19网络的权重是固定的,在训练中参数不会更新,因此对于真实图像和风格图像编码的过程保持一致,风格注意力模块能够更为准确地学习到风格特征和内容特征之间的关系,从而提高风格迁移的质量。
2.2.2 AdaIN模块
AdaIN[6]是一种用于快速风格迁移的方法,通过转移全局特征统计数据来调整内容图像的均值和方差,使之与风格图像相匹配,在特征空间中完成风格迁移。AdaIN是基于IN(Instance Normalization)的改进,不同之处在于AdaIN没有可学习的仿射参数,它会根据输入的风格图像自适应生成仿射参数。假定x和y分别表示输入的内容图像和风格图像经过VGG-19网络编码器得到的特征张量,则AdaIN 层的计算为
(2)
式中,σ(·)表示计算方差;μ(·)表示计算均值。但是由于其实现方式过于简单,实验表明其单独来实现水墨风格迁移任务效果并不理想,因此需通过融合AdaIN和风格注意力模块的结果来提升风格迁移的质量。

图2 风格注意力模块结构Figure 2. The structure of style-attention module
2.2.3 风格注意力模块
风格注意力模块是基于传统的非局部模块[15]的改进,不同之处在于该模块计算的是两种不同特征(内容特征和风格特征)之间的依赖关系,具体如图2所示。该模块可以根据内容图像特征空间的分布,自适应地学习到相匹配的局部风格模式。在训练过程中,该模块通过学习内容和风格特征之间的关系,在内容特征图中不同的位置渲染相对合适的风格样式,例如水墨画中特有的留白空隙特征出现在物体上的概率是比较大的,如果图像的其他背景部分出现留白空隙则看起来很不协调,因此通过引入该模块能够学习到更特定的水墨特征。
同样假定输入内容图像和风格图像分别经过VGG-19网络编码器得到内容特征xj和风格特征yi,{xj,yi}∈C×H×W。其中,C表示特征的通道数,H和W分别表示特征图的高和宽。张量xj和yi分别被变换成C×N的形式作为该模块的输入,其中N=H×W。然后使用两个卷积核大小为1×1,通道数为C′=C/8的卷积网络分别获取特征fi和gj,则有
(3)
式中,{Wf,Wg}∈C′×N。然后对fi进行转置,并通过张量矩阵相乘的方法和gj相乘得到两个特征相对位置之间的影响关系pi,j,并使用Softmax函数对其进行归一化处理
(4)
式中,μi,j表示对计算xj中j位置的值时yi中i位置的值所占的权重,接着通过相似的方法得到h(xj), 最终注意力值得输出为
(5)
式中,h(xj)=Whxj,Wh∈C×N。
2.2.4 解码器
解码器采用了和编码器相对等的网络结构对输入特征进行解码。为了减少伪影,选择了上采样加卷积的方式来替代传统的转置卷积。
为了保留输入的真实图像的内容结构信息,避免部分特征信息的丢失,在编码器真实图像的输出和解码器之前增加了跳跃连接来提高图像迁移的质量,如图1所示。
3 损失函数
3.1 对抗损失
为了使生成的图像和目标域水墨风格的图像相类似,引入对抗损失来使得生成图像的分布和真实的水墨图像分布相匹配。传统的交叉熵损失[7]通常导致模型训练不够充分,从而降低了生成样本的质量。因此,本文选择最小二乘损失[16]替代交叉熵损失来进一步优化生成图像的质量。最小二乘法可以基于离边界的距离对生成的虚假样本进行惩罚,在一定程度上避免了梯度消失的问题,从而提高生成图像的质量。 给定来自真实图片数据集的样本x和真实水墨数据集的样本y,经过生成器G后得到生成图像,此时生成器和判别器的对抗性损失表示如下
Ey~pdata(y)[(D(y))2]
(6)
式中,pdata(·)表示对应数据集的分布;G(x,y)表示生成的图片;D表示判别器。
3.2 循环一致损失
循环一致损失[9]可以保证每一个输入图像都能映射到一个期望的输出,并且能够保留图像的固有特征,保证训练的稳定。具体来说,给定任一真实内容图像x和水墨风格图像y,首先经过生成器G得到生成图像G(x,y),该结果再经过生成器F得到重构图像F(G(x,y),x),此时重构的图像应尽可能和原来输入的内容图像保持一致,即F(G(x,y),x)≈x。循环一致性损失的定义如式(7)所示。
cyc(G,F)=Ex~pdata(x)[‖F(G(x,y),x)-x‖1]
(7)
3.3 感知损失
最近的研究[17]表明, 基于预训练网络的感知距离更符合人类对图像相似度的感知,而传统的距离度量通常会导致生成图像产生模糊的效果。为了能够更好地保留输入图像的视觉特征,这里仍然使用预训练好的VGG-19[5]网络作为特征提取器。分别计算重构后的图像和输入的内容图像经过网络产生的特征图之间的差异性,衡量两者高级语义特征的相似性
per(G,F)=
(8)
式中,V指预训练好的VGG-19网络;wi表示不同层计算出的差值所赋予的权重。通过多次实验,最终选择“ReLU_1_2”, “ReLU_2_2”,“ReLU_3_3”以及“ReLU_4_3”4层的输出来计算感知损失,并且将w1、w2、w3和w4分别设置为1.0/32、1.0/16、1.0/8和1.0/4,得到了较好的结果。
综上所述,最终生成器的损失函数为
(G,F)=GAN+αcyc+βper
(9)
判别器的损失函数为
(D)=-GAN
(10)
式中,α和β是超参数,表示循环一致损失和感知损失在整个损失中的权重占比。
4 实验结果与分析
4.1 实验设置
本实验基于NVIDIA Tesla T4 GPU,网络使用Pytorch框架进行搭建,利用Python进行编程。实验采用的数据集为ChipGAN所提出的中国斑马水墨画数据集ChipPhi,其中训练集包含1 478张真实照片以及822张水墨风格图片,测试照片为160张。由于数据集图片的尺寸不一致,在实验中所有图片被统一处理成256×256大小。模型的训练次数为200个epoch,批处理大小batch size设置为1,初始学习率设置为0.000 2。 采用Adam优化算法进行参数更新,其中判别器和生成器交替优化,权重参数α和β分别设置为10和5。
4.2 定量结果对比
为了比较不同方法迁移结果的质量,本文采用了FID[18](Fréchet Inception Distance)和KID[19](Kernel Inception Distance)两个测试指标来对生成的图像进行评估。
FID用于衡量真实图片和生成图片在特征层次分布的差异。在评估生成样本的真实性和多样性方面,FID与人类的主观评价相符合。FID的值越低表示生成的图像质量越高。具体来说,通过使用预训练好的InceptionV3网络为输入的待测图像生成一个2 048维的特征向量,然后分别计算出所有真实图像和生成图像的特征之后,最后由以下计算式获得两者之间分布的距离
FID=
‖μx-μy‖2+Tr(∑x+∑y-2(∑x∑y)1/2)
(11)
式中,μx和μy分别表示真实图像和生成图像的均值;∑x和∑y分别表示真实图像和生成图像的协方差;Tr表示矩阵的迹。
计算时分别选取ChiGAN和文中模型生成的结果与对应测试集真实水墨风格图片之间的FID值,结果如表1所示。从中可以看出,所提出的模型FID指标要低于ChipGAN,说明该模型生成的图片更类似于真实的水墨风格图片,并且生成图片的分布更接近于测试图片的分布。

表1 FID和KID×100指标数值
KID指标用来计算真实图像和生成图像的特征之间的最大均值差异(Maximum Mean Discrepancy,MMD)。不同于FID,KID是一个无偏估计量,当测试图像的数量比特征的维数更少时,FID是一个更可靠的指标。KID的值越低表示真实图像和生成图像之间的视觉相似度越大。同样采取和FID相同的计算方式,从表1可以看出,该模型的KID值仍然低于ChipGAN,这表明所提出的模型生成的水墨图片具有更高的视觉质量。
4.3 模型分析
为了表明文中模型轻量级的特性,现将提出的模型生成器的参数量以及完整的训练时间同ChipGAN作了对比,结果如表2所示。从表中可以直观地看出该模型在参数量以及训练时间相较于ChipGAN都有了较大优化,其中参数量减少了大约55%,训练时间降低了60%左右。
本文模型参数量减少的原因在于所引入的VGG网络编码器、AdaIN以及风格注意力模块。其中VGG网络编码器和AdaIN没有可学习的参数,且风格注意力模块只包含1×1大小的卷积,参数量也相对较少,因此该模型主要的参数量集中在解码器部分。而ChipGAN采用了常规的编码器、残差模块以及解码器3个部分,这些都包含了可学习的参数,尤其是多个残差模块的堆叠参数量较大,因此参数量比文中模型更多。另外ChipGAN在训练中还加入了其他预训练网络分支来辅助模型更好地完成水墨风格迁移任务,因此训练时间相较于文中模型也更长。

表2 生成模型的参数量以及模型的训练时间
4.4 定性结果对比
图3展示了ChipGAN模型和本文基于GAN的轻量级水墨风格迁移模型生成的结果对比。为了更加直观地对比,本文使用矩形框体对一些特别区域进行了标记。从中可以清晰地看出,相比于ChipGAN,本文模型生成的结果内容更加完整,细节更加逼真,例如第1行本文所提出的模型生成马的头部更加完整。另外该模型生成的结果具有更好的水墨笔触效果以及自然的留白空隙,如图3的第2行和第4行所示。综上所述,定性结果的评估表明本文所提出的模型生成了令人更加满意的结果。

(a) (b) (c)图3 ChipGAN模型和本文模型的定性结果对比(a)原图 (b)ChipGAN (c)本文模型Figure 3. Comparison of qualitative results between the ChipGAN and our model(a)The original image (b)ChipGAN (c)The proposed model
5 结束语
本文提出了一种基于GAN的轻量级风格迁移模型,在一定程度上解决了中国水墨画风格迁移质量不佳的问题。该方法通过使用预训练的VGG网络对内容图片和风格图片进行统一编码,对AdaIN和改进的风格注意力模块的结果进行融合,使得模型可以更准确地学习到水墨风格特征。另外,引入的感知损失可以修正图像的细节特征,提高了视觉质量。从定性和定量结果来看,本文方法有效地提高了水墨风格迁移的质量。当然,在图像生成的质量方面还有待提升,在未来的工作中将继续研究和改进该算法。
