改进YOLO的口罩佩戴实时检测方法
2023-01-04程长文陈劲宏
程长文,陈 玮,陈劲宏,尹 钟
(上海理工大学 光电信息与计算机工程学院,上海 200093)
随着全球新冠疫情的爆发,公共场合口罩佩戴检测的效率就显得尤为重要。图像检测任务的核心是特征提取。相较于传统方法,基于深度神经网络方法的特征提取具备更加丰富和完整的信息,因此本文使用深度学习的方法搭配深度学习模型来提高口罩佩戴检测的效率。目前用于目标检测和脸部识别的模型存在一些缺点,例如文献[1]提出的One-stage检测的R-CNN(Region-based Convolutional Neural Network)以及文献[2]提出的Faster R-CNN虽然检测精度良好,但是检测效率不理想,以至于其使用场景有限;文献[3]提出的EfficientDet和文献[4]提出的EfficientNet都是目标检测模型,主要优点在于模型自身具有自适应缩放的功能,但是其模型的精度和效率在识别任务中表现不理想;文献[5]提出的RetinaFace面部识别模型,会捕捉到冗余的脸部特征,造成算力资源的浪费。
针对当下疫情发展的实际需求,本文对于上述模型特点进行了总结:(1)大部分模型都是基于目标检测任务的特点,整体效率和精度受限于机器的性能和检测的目标大小;(2)重叠的目标以及体积小的目标会导致上述分类模型的识别精度下降[6]。基于以上原因,若将上述模型运用到口罩检测任务中,口罩佩戴检测的场所人流密度较大、图像采集点较远、目标重合度和大小较复杂等背景特点会降低模型的效率和精度。
为此,本文提出了一种改进的YOLO[7](You Only Look Once)口罩佩戴实时检测方法。本文模型在文献[8]提出的YOLOv4模型的基础上进行了优化。YOLO模型的特点是采用单个神经网络可以一起完成对物品边界和类别概率的预测,从而实现端到端的物品检测。因此,使用YOLO模型可以在保持合理精度的同时提高检测效率,使其成为真正意义上的实时检测器。本文主要从3个方面优化YOLOv4模型,从而提高模型对人脸口罩佩戴检测的效率和精度:(1)在检测效率上,本文在中间层和隐藏层使用了SiLU激活函数,相较于文献[9]提出的YOLOv3模型中选用的Leaky ReLU激活函数,以及YOLOv4模型中使用的Mish激活函数,SiLU激活函数提升了模型的运算效率。本文模型还添加了Focus结构和自适应图片缩放的策略。其中Focus结构的添加可对3层普通下采样卷积进行参数量的优化,减少参数量,从而达到提速的效果。自适应缩放有助于加快方法的检测效率;(2)在泛化性上,本文采用了自适应锚定框(Auto Learning Bounding Box Anchors)和优化的数据增强(Data Augmentation)[10],自适应锚定框可以基于不同的数据集自动地学习分析,从而为每个数据集计算出适合的预设锚定框。数据增强可对解决模型训练过程中的“小对象问题”有着明显的优化,两者相结合可提升模型的泛化能力;(3)在特征融合能力的提升上,本文方法将现有YOLOv4中Neck部分的CBL(卷积)替换为CSPNet模型中的CSP2。新的Neck部分的添加,提高了模型融合特征能力。
图1为本文所提出的改进YOLO模型的框架。图2为改进YOLO检测方法的训练和检测流程。

图1 改进YOLO检测方法的训练和检测流程Figure 1. Training and detection process of improved-YOLO detection method

图2 改进YOLO模型框架Figure 2. Improved-YOLO model framework
1 YOLO目标检测
1.1 YOLO的发展历程
YOLO系列是从YOLO、YOLOv2 、YOLOv3和YOLOv4不断发展而来的目标检测模型。其与Faster R-CNN单例检测器将目标检测划分为一元回归有所不同。YOLO的框架如图3所示,其主要思想是将输入的图像分割成N×N的网格。该模型对每个网格都进行单独的检测,对每个单元格都进行边界框预测和预测框的置信度计算。置信度可以反映物体存在于网格中的概率,若存在概率高,则相应的置信度就高,反之一样。置信度的计算式为

(1)
每个网格都能预测目标对象的存在概率C。总共预测6(5+C)个值,即 (x,y,w,h)以及置信度C。其中(x,y)代表网格的中心坐标,(w,h)代表网格的宽度和高度。
受Faster R-CNN的启发,YOLOv2借鉴了先验框的思想进行检测,可以简化问题并简化网络的学习过程。除了先验框外,YOLOv2还引入了批处理的归一化[11]和跳跃连接[12],显著提升了定位和回溯的能力。
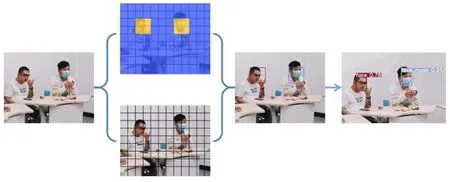
图3 YOLO的模型预测Figure 3. YOLO modelprediction
基于YOLOv2,研究人员又提出了更优的目标检测框架YOLOv3。受文献[13]提出的特征金字塔框架的推动,YOLOv3主要升级了检测的维度。其分别在3个不同的维度检测,有效地解决了检测对象大小变化的问题。与以往的基于区域识别的检测器相比,YOLO模型使用了3个主要的模块,本文将在以下章节逐个说明。
1.2 主干网络部分(Backbone)

CSPDenseNet的前馈传递和权重更新计算式分别如式(2)~式(7)所示
(2)
(3)
(4)
(5)
(6)
(7)
式中,*表示卷积操作;[·]表示堆叠;k表示密集层个数;f表示权重更新的函数。可以发现,Dense Layers的梯度是各自积分的,X″0是独立积分的。
1.3 Neck部分(SPP模块和FPN+PAN模块)
Neck部分主要是为了更好地提取融合特征,从而提高模型性能。其中,Spatial Pyramid Pooling(SPP)[17]模块使用了最大池化,将不同尺度的特征图进行Concat操作,具体实现如式(4)和式(5)所示。另外,Feature Pyramid Network(FPN)[18]特征金字塔网络其实就是不同尺度的特征融合预测。PAN部分主要借鉴了图像分割领域PANet[19]。YOLOv4在PAN部分运用了其拆分的思想,从而进一步提高特征提取的能力。Neck部分的模型结构如图4所示。
(8)
(9)
(11)
(12)
(13)
(14)
(15)
式中,Kh表示核的高度;Sh表示高度方向的步长;Ph表示高度方向的填充数量,需要乘以2;ceil(·)函数表示向上取整,用于核和步长的计算;floor(·)函数表示向下取整,用于Padding的计算。

图4 Neck部分的模型结构Figure 4. Model structure ofthe Neck part
1.4 Head网络输出层
FPN输出的3个分支,通过两层卷积输出预测的Head。锚定框的应用是网络输出层的主要特点。Head层的最终输出向量包含对象得分、类概率和包围框。YOLOv3、YOLOv4与本文模型都是使用一样结构的Head层。不同大小的物体在模型中需要使用不同缩放尺寸的Head来检测,其中每个Head一共使用3×(2个类+1个概率+4个坐标)个锚定框,一共18个Channels。
2 改进YOLO的检测方法
2.1 输入层优化
现有的YOLOv4模型使用了标准的马赛克增强(Mosaic Augmentation)。Mosaic Augmentation参考了CutMix[20]数据增强方式。CutMix数据增强的原理就是将两张图片按照一定比例地混合合成一张新的图片,以此来有效地利用训练像素并保留区域信息来维持正则化效果。Mosaic数据增强的改进在于,一次性读取4张图片,并将4张图片进行相应的翻转、缩放和色域变化之后按照比例混合输出一张图片。这样做的优势在于丰富了检测物体的背景,提高了模型对于不同背景的泛化能力。
本文的方法优化了数据增强模块,添加了图像的视角变换,色域变换方面拆分为色度、饱和度和明度3个方向调整。添加了相应参数的设置文件,可以依据不同数据集手动调整相应变换的概率。表1显示了可以调整的参数清单。

表1 数据增强可以调整的参数
在自适应锚定框的计算方面,对于不同的数据集和检测目标,在YOLO模型中需要初始设定适合训练数据集的锚定框尺寸。在模型进行训练中,模型会在初始的锚定框上输出预测框,从而和数据集中标注的真实框进行对比,计算两者的置信度,再来反向更新预测框,从而优化网络的参数。所以采用多尺度预测目标区域和类别信息[21]对模型的优化尤为重要,图5所示就是针对本文数据集计算得出的锚定框。

图5 本文数据集计算得出的初始化锚定框Figure 5. Boundingbox anchors from the data set in this study
现有的YOLOv3和YOLOv4初始化锚定框的设定需要通过单独的kmeans_for_anchors.py程序单独计算。本文将锚定框的计算放置到训练代码中,从而实现每次训练时能够自适应地计算不同数据集的最优锚定框。
在常见的目标检测模型中,自适应图片缩放对输入模型的图片尺寸有着长宽的要求。为了能够尽可能地利用不同尺寸的数据集,模型需要对数据集中不同图片的尺寸进行调整以适应模型的输入要求。在YOLO模型中,常用的检测尺寸有416×416和608×608。本文模型训练的是608×608。如图6所示为对800×600长宽的图像进行缩放的过程。然而,现有的YOLO模型无论训练还是检测都是将图片强制缩放到指定的尺寸。本文对此进行了优化,在训练时对数据集全部缩放到预定的尺寸,但在方法检测时采用np.mod(X,32)的计算方式缩减黑边,从而提高模型检测的效率。

图6 自适应图片缩放的过程Figure 6. The process of adaptive image scaling
本文方法在检测图像中使用自适应缩放的具体实现如图7所示。

图7 自适应图片缩放优化步骤Figure 7. Adaptiveimage scaling optimization steps
自适应缩放的优化主要分为3步:(1)计算得出最小的缩放系数;(2)由最小的缩放系数确定图像缩放的比例;(3)通过函数np.mod(X,32)确定填充的高度,从而得到变换后的图片。本文方法的网络经历了5次下采样,故将函数的第2个参数设置为32,即25=32,所以用32进行取余操作。
2.2 Neck部分优化
在YOLOv4的Neck部分中,使用的是CBL。本文为了加强模型的特征融合能力,参考了CSPNet模型中的CSP2结构,将Neck部分的CBL部分替换为CSP2。具体的模型框架如图8所示。
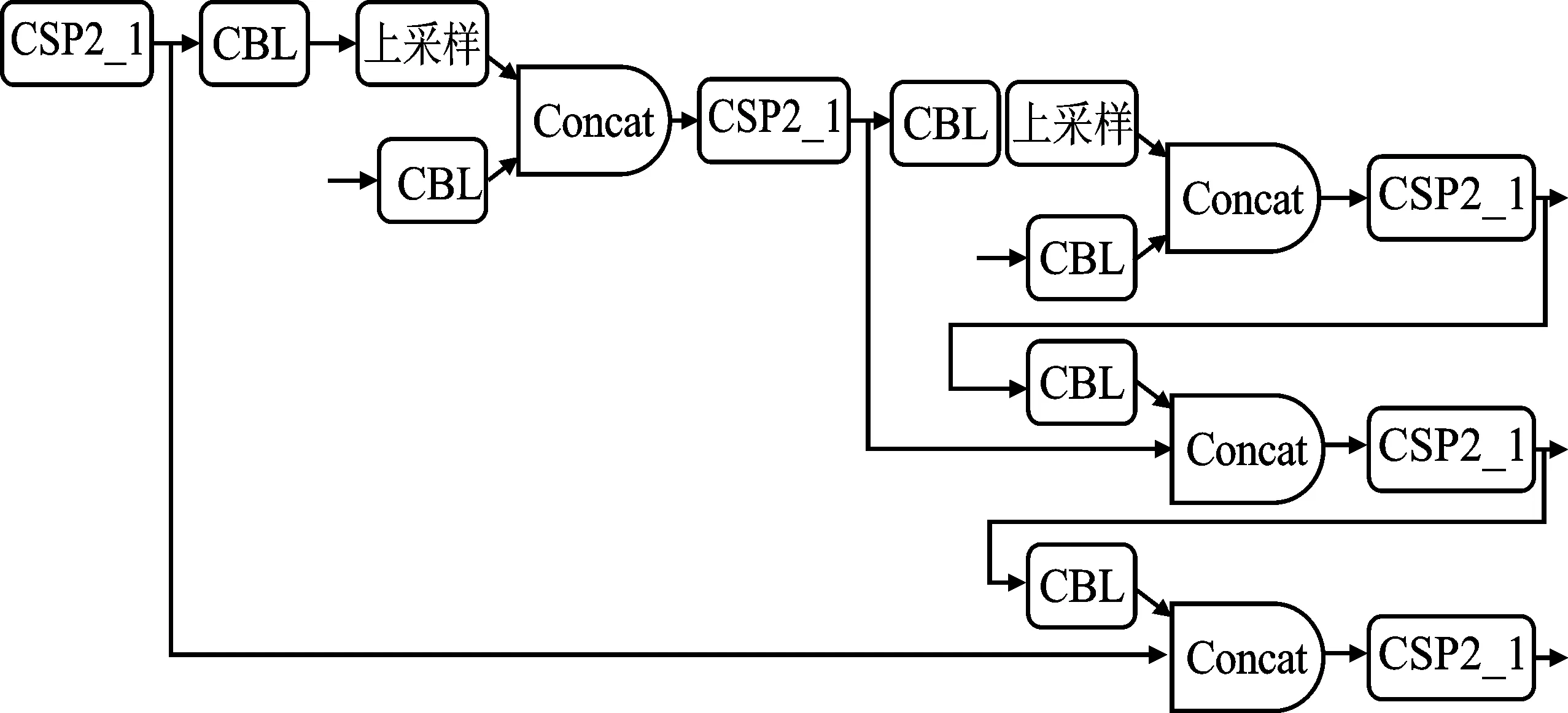
图8 Neck部分优化结构Figure 8. Neck partially optimized structure
2.3 激活函数优化
本文使用SiLU(Sigmoid-Weighted Liner Unit, SiLU)激活函数替换YOLOv4现有的Mish激活函数。Mish函数的数学表达式如式(16)所示。SiLU也称为Swish激活函数,最初是由Google Brain所提出的,实际上是Sigmoid函数的改进版本。SiLU的表达式及其导数表达式如式(17)和式(18)。
(16)
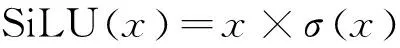
(17)

(18)
2.4 添加Focus结构
在YOLOv3和YOLOv4模型中并没有Focus结构。本文在输入层之后添加Focus结构,主要是进行切片操作,对3层普通下采样卷积进行改进。改进后参数量减少,可以达到提速的效果。图9展示的是Focus结构中的切片示意图,4×4×3的特征图像经过切片之后转变为32×12的特征图像。

图9 Focus切片示意图Figure 9. Schematic diagram of Focus slice
本文方法输入的尺寸为608×608×3,将其输入到Focus结构中,对其进行切片操作,先变换为304×304×12的特征图像,随后输入到模型经过72个卷积核的卷积操作,最终变换为304×304×72的特征图像。
3 实验与分析
3.1 数据集的获取
本文数据集主要来源于MAFA(Masked Faces)[22]data set(基本都是戴口罩的图片)和WIDER FACE data set(基本都是不戴口罩的图片)。数据集总共7 859张,其中包含6 120张训练集和1 839张验证集。训练集包含来自MAFA的3 006张图片以及WIDER Face的3 114张图片,验证集包含MAFA的1 059张图片以及WIDER Face的780张图片。图10显示了不同数据集不同场景的数据图片。

图10 数据集图片类别 (a)室外口罩佩戴 (b)多人未佩戴口罩 (c)室内佩戴口罩 (d)白色口罩佩戴 (e)充足光线未佩戴口罩Figure 10. Data set image category(a)Wearing mask outdoors (b)Many people without masks (c)Wearing mask indoors (d)Wearing a white mask (e)Sufficient light and mask is not wearing
本文数据集的图片由不同尺寸的图片组成,由训练机器的显存大小决定经过Letterbox处理成416×416或者608×608。本文数据集标注采用了LabelImg软件,数据集的Label分布如图11所示。

图11 本文数据集Label
3.2 实验环境
为验证本文改进YOLO方法的准确性和有效性,在表2所示参数的环境平台下进行实验。
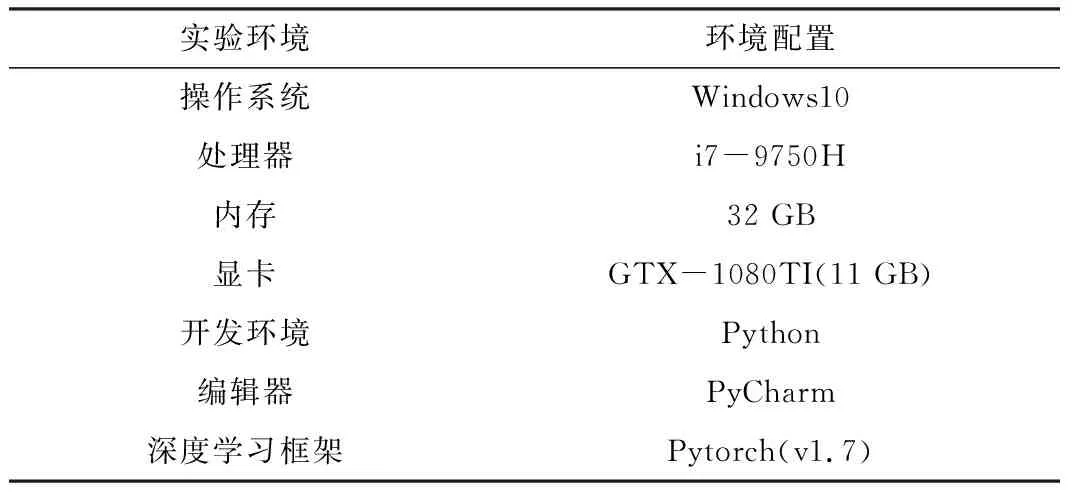
表2 本文实验环境及配置
3.3 实验参数和评价指标
本文实验优化后的模型配置参数如表3所示。在主要参数相同的情况下验证不同模型的检测效果,用以验证本文方法的有效性和准确性。
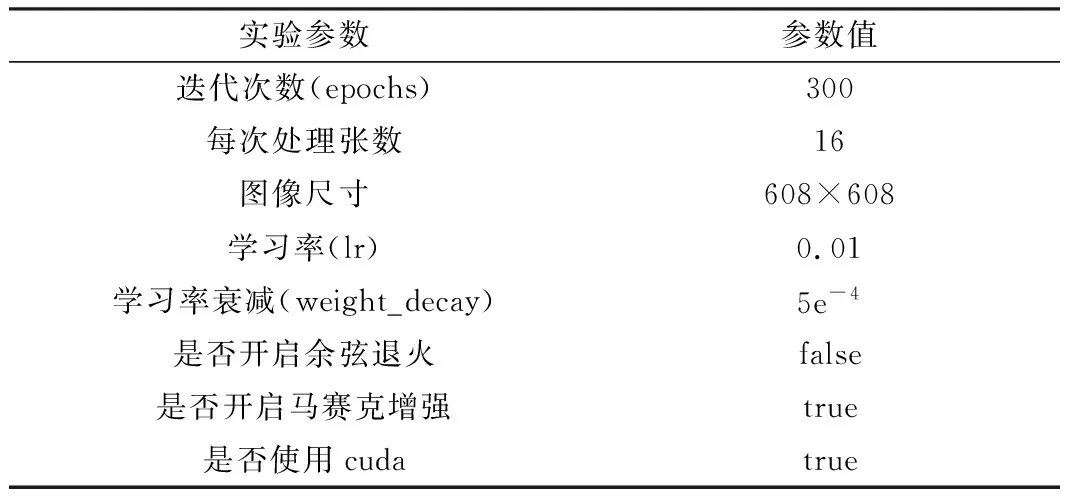
表3 模型的参数设置
本文实验属于二分类模型,主要的评价指标分为召回率(Recall)、精确率(Precision)、F1-Score、平均精度(mean Average Precision,mAP)和帧率(Frames Per Second,FPS)。二分类评价M指标的计算依赖于混淆矩阵,具体放入结构如表4所示。

表4 二分类混淆矩阵
不同评价指标的计算式如式(19)~式(21)所示。
(19)
(20)
(21)
mAP的计算方式为所有分类的AP进行平均所得。AP的计算方式为Recall和Precision的曲线(RP曲线)与坐标轴构成图形的面积。FPS为每秒传输帧数,主要用来衡量方法的检测效率。
3.4 对比实验
目前已有多种口罩佩戴检测的方法,而过去主要尝试的检测模型为RetinaFace[23],该模型仅在少量的数据集上进行了实验,数据集仅有3 000张,并且模型也进行了更多的无用面部特征点的检测,消耗算力且降低效率。DFS[24]模型实现的核心在于人脸检测。该方法运用了特征融合、语义分割和注意力学习,在口罩佩戴的检测中主要依赖模型结构。此外,该模型训练费时,检测效果对图像质量依赖度较大,所以效果不太理想。RetinaNet[25]模型的实验受限于数据集和模型的特点,检测精度和检测效率都不高,检测精度低于90%且单张图片的检测检测时间超过200 ms。本文改进YOLO方法在本文数据集中的检测精度和效率上都有所提高。本文数据集场景较多,能够使训练出来的模型适应不同的环境。单张图片的检测使用本文方法在NVIDIA GTX1080Ti(11 GB)上的检测耗时低于30 ms,FPS大于25就可以归为实时检测。本文模型检测的FPS一般维持在30,且检测分类的判别数值也相对较高,对于一些复杂场景和目标重叠的情况也有较好的识别精度。
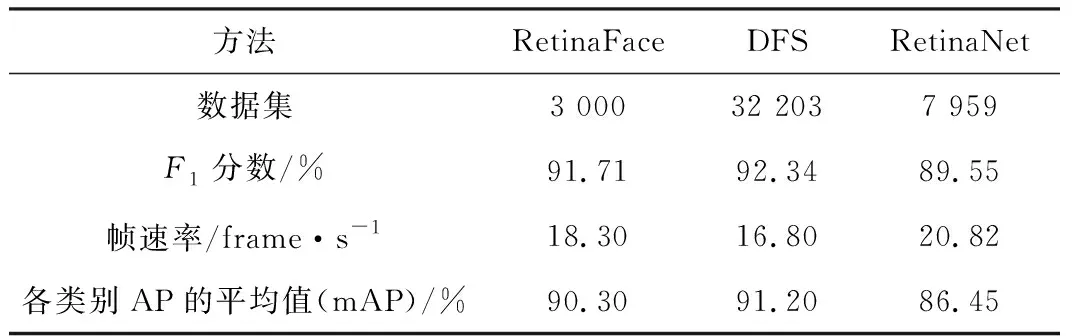
表5 不同方法和不同数据集检测效果对比
3.5 消融实验
消融实验主要用来分析不同网络模型对整个方法的影响,该实验方法常用于深度学习领域。
本文研究了YOLOv4、YOLOv4-tiny和改进YOLO的消融效果。实验的数据集包含7 959张图片,训练和检测的比例为9∶1。图12显示了改进YOLO模型的消融实验检测效果。对所有人脸进行检测,戴口罩和未佩戴口罩检测出的标签不同,其中face_mask是佩戴口罩的标签,face是未佩戴口罩的标签。表6显示了实验的一些数据,这些数据表示当置信阈值等于0.5时获得的一些数据值。从表中可以看出,新的数据增强方案、CSP2结构的引入和Focus结构的添加以及新的激活函数等优化显著提高了方法的查全率和查准率,从而使F1的分数从97.02%提高到97.35%。另外,自适应图片缩放在于保证准确率的情况下提高了检测效率,这对于使用工程化建设有一定的帮助。表6的参数证明了本文一些优化的有效性,它提供了口罩以及小目标检测的解决方案。图13显示了3种不同模型的查准率和召回率曲线,曲线已进行归一化操作,可以看出本文模型具有一定的优势。

图12 改进YOLO的消融实验检测效果Figure 12.Improved-YOLO ablation experiment detection effect

表6 YOLOv4、YOLOv4-tiny和改进YOLO的消融实验
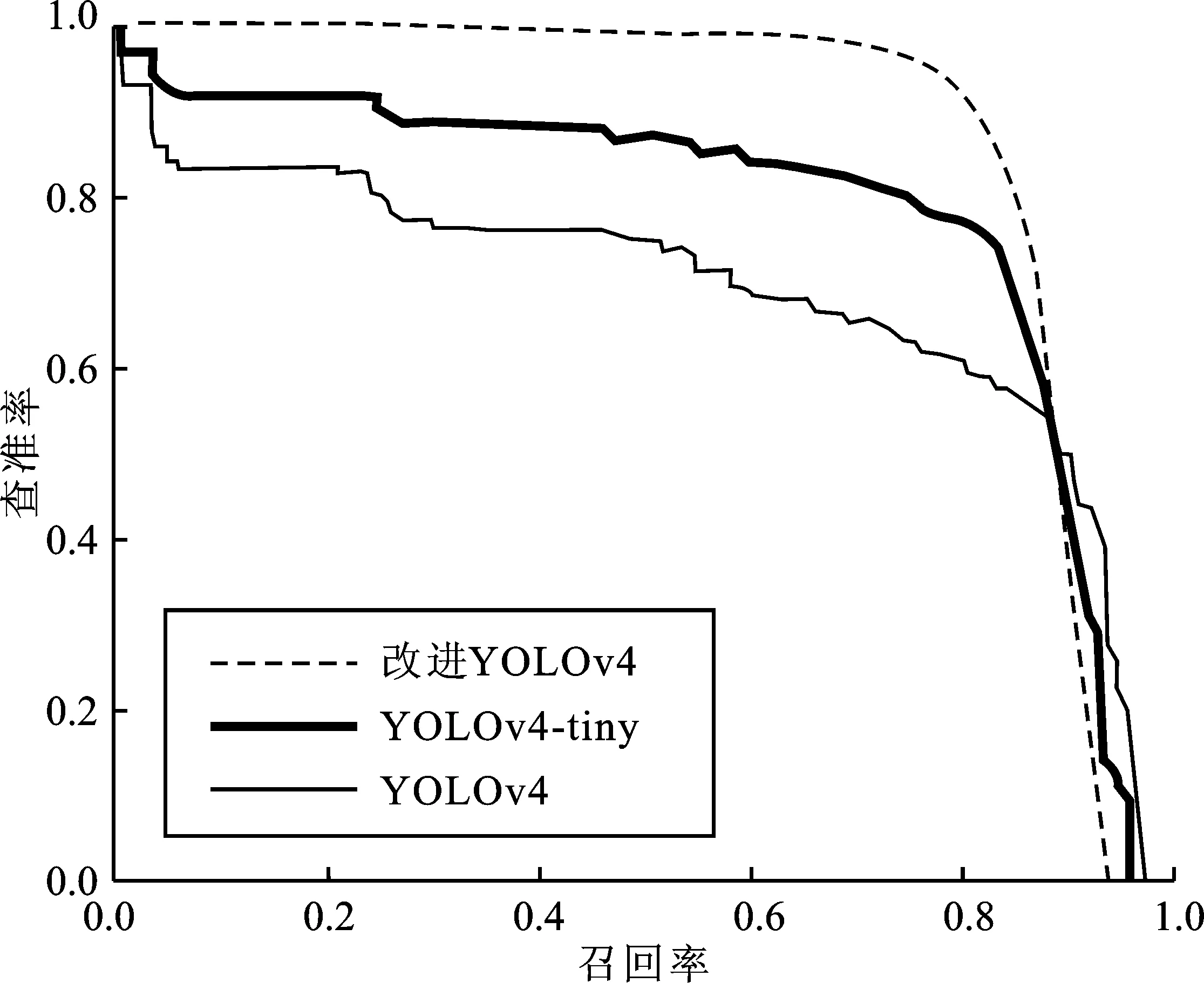
图13 YOLOv4、YOLOv4-tiny和改进YOLO的查准率和召回率曲线Figure 13. Precision andrecall curves of YOLOv4, YOLOv4-tiny and improved-YOLO
4 结束语
本文提出了一种基于YOLOv4分割模型的人脸口罩佩戴实时检测模型的实现方法。该方法可以在性能较低的设备上保证视频流的实时检测,并且检测精度具有优势。优化之后的方法在LabelImg工具手工标注的数据集进行了离线训练。此外,方法的自适应图片缩放提高了工程化的能力。该方法可以扩展到多种检测场景,例如信号灯[26]、安全帽、护目镜、工牌等。本文方法还拥有进一步优化的空间,例如继续优化数据集的增强方法,优化模型层级适应不同检测需求,优化小样本的方法效果等,从而提高检测精度和效率。
