基于深度强化学习的多目标无人机路径规划
2022-12-30陈昱宏高飞飞
陈昱宏,高飞飞
(清华大学 自动化系信息处理研究所,北京 100084)
0 引言
无人驾驶飞机(Unmanned Aerial Vehicle,UAV)简称无人机,是一种无搭载人员的空中飞行器,一般会使用无线遥控设备、自定义程序等手段来实现半自主或自主飞行控制。由于无人机不需要飞行人员随行控制,常被用于在较为危险、恶劣或不适合人类工作的环境中执行特定任务。随着无人机控制技术的发展,越来越多领域开始应用无人机来解决困难任务或提升效率。在农业领域,无人机可以用来监控农作物受到害虫的情况[1],或是协助喷洒农药[2];在航拍领域,无人机航拍可以获得更广阔的全景照片,用于监控巡查或街景拍摄;在通信上,无人机可以作为空中可移动基站提供有效且快速的信息传输[3];在军事上,无人机也可以运用在侦察和定点打击目标等任务。本文主要目标为研究无人机在灾害救援领域的应用场景。
随着5G技术的发展,无人机的技术和性能也随之提高,其相应的应用领域也越来越广泛。自然或人为灾难,例如地震、洪水、火灾、核事故和辐射事故等,可能造成重大生命和财产损失。发生灾难时,可以利用无人机完成灾难现场的侦察任务[4];抑或是作为空中可移动基站来提供救灾通信服务,以保证信息传输的稳定性[5]。
本文考虑的无人机场景是室内火灾救援勘察的任务。由于火灾现场通常保持着高温并且有火焰持续燃烧的现象,搜救人员进入现场进行探查时较为危险,且容易发生搜救人员的伤亡。可以利用无人机不需要人员跟随的特性,先于救灾人员进入灾难现场搜救,一来保护搜救人员的安全,二来无人机小巧的个体也能够更好地进入火灾现场。
在灾害救援方面,无人机可以代替人前往危险的现场进行探勘,有利于避免人员的重大伤亡。传统无人机的路径规划,大部分采用搜索的方式来进行路径规划,在遇到较为复杂的场景时,搜索空间的增大会导致规划效率低下,可以利用强化学习算法更好地指导无人机学习,完成指定任务。
与传统的搜索算法相比,深度强化学习(Deep Reinforcement Learning,DRL)可以处理较大且连续的状态空间和时变环境[6-7],其中一种用来处理连续动作和连续状态的算法为深度确定性策略梯度算法(Deep Deterministic Policy Gradient,DDPG),可以应用于自主导航的无人机[8]。
如今,世界各国对无人机产业更加重视,都开始大力投资和鼓励无人机的创新创业。2016年11月,中国政府网发布了国务院关于“十三五”国家战略性新型产业发展规划的相关文件,国家对于无人机产业更加重视,明确提出加大无人机科研实验和基础设施建设,并大力支持开发市场需求。2019年美国空军发布新版《科技战略:加强2030年及以后的美国空军科技》,计划在未来10年内开发并部署以无人机为代表的技术,并将其融入到美国空军力量中。此外,多个国家和大型科技公司也因5G技术的发展,加大对于无人机技术的投入,不仅是在军事领域上提出相应的战略规划,也在其他民生领域展开相应的技术布局。
可以看出,无论是在未来发展方面或是解决旧有算法问题方面,深度强化学习在无人机技术的发展上都有着不可忽视的潜力,本文主要利用深度强化学习算法解决灾难救援领域的任务。
1 机器学习技术简介
1.1 机器学习发展现状
机器学习,是透过数据和预测模型指导机器学习人类的行为,而在机器学习中,主要分为深度学习和强化学习两个研究方向。
深度学习是一种对数据进行表征学习的方法,目前已经在图像识别、语音辨识、自然语言处理等领域,获得了显著的成果。深度学习的概念来自于人工神经网络,基本思想是透过堆叠多层神经网络,对输入的信息进行分级处理,抽取其低层次的特征,经过样本数据的学习,获得更高层次的特征,学习到数据的特征结构。在多个抽象的特征上,促使机器自动学习将输入的信息数据,映射到输出数据的复杂功能,以获得与输入数据差异最小的输出结果,而不需要仰赖人工制造的功能。在图像识别的领域中一般使用卷积神经网络来完成图像识别、图像分类等任务。例如文献[9]利用深度学习的技术,将输入的图像透过多层神经网络进行语义分析。
强化学习的概念是借由智能体与环境的交互过程,对于不同的行为给予一定的奖励,训练智能体选择做出获得最大奖励函数的行为。如图1所示,环境会给予智能体一个状态,智能体根据自身策略选择一种行为在环境中操作,环境根据不同的行为,返回给相应的奖励函数和新的状态,经过多次的交互过程后,智能体会学习到一个较好的行为策略,从而获得更大的奖励。因此在强化学习中,如何设计奖励函数,显得尤为重要,一些可能影响学习策略的先验知识,都是必须考虑如何在奖励函数的设计中体现[10]。

图1 强化学习基本概念图Fig.1 Basic concept of Reinforcement learning
随着人工智能需要处理的情境越来越复杂,谷歌的人工智能团队DeepMind提出了创新性的概念,将对感知信号处理的深度学习与进行决策处理的强化学习相结合,形成所谓的深度强化学习,利用深度强化学习可以解决以前强化学习难以处理的问题。传统的强化学习算法虽然已经尽可能地模拟了人在学习事情的过程,但是依然会遇到一些无法处理的问题,主要是环境状态的改变与智能体所做的行为有关,二者间可能含有强烈的时间相关性,如果不使用深度学习的算法,容易造成智能体的行为策略难以收敛或是不稳定,此外如果一个行为的后果,需要经过一段时间的过程才会实现,例如信用分配问题,也容易造成智能体在训练过程的不稳定[11]。
1.2 强化学习数学模型
在深度强化学习中,主要的核心还是在于强化学习的基础,透过深度学习抽取特征和函数复杂映射的能力,将强化学习中的一些痛点加以解决。在强化学习中,主要是希望智能体学习一种行为策略,能够根据当前环境信息对应地输出一个行为:
a=π(s),
(1)
式中,a是动作,s则是智能体在环境中的状态。根据不同的环境,动作和状态可能是离散或连续的。
强化学习的问题可以被建模成一个马尔可夫决策过程[12],马尔可夫过程的特点是一个系统中,下一个时刻的状态仅跟当前状态有关,与之前的状态无关;而马尔可夫决策过程则是指下一时刻的状态由当前状态和当前时刻的动作决定。马尔可夫决策过程可以用一个五元组表示:
{S,A,Pa,Ra,γ}。
(2)
在这个五元组中,S代表着状态空间,A代表着动作空间,Pa代表着状态转移的概率,一般用来描述执行一个动作后从当前状态转移到下一个状态的概率,Ra代表着当前状态执行一个动作后的奖励,γ是折现因子,用来将未来获得的奖励折扣到当前时刻的奖励中。
马尔可夫决策过程要解决的核心问题就是选择动作的策略,在数学上使用π函数来表示:
π(a|s0)=p(at=a|st=s0)。
(3)
在奖励上,要考虑的是当前状态下的总回报,从模型上来说,将来奖励的不确定性大,不能够简单地将未来奖励直接加和;从数学上来说,需要满足级数收敛的问题。因此,需要透过一个折现因子将未来每个时刻的期望奖励折现到当前时刻:
(4)
从上面的数学建模上,由于马尔可夫决策过程的核心在于策略,需要将状态转移的概率和状态获得的奖励和策略相结合,后续才能更好地对策略进行评价。利用全概率公式,基于策略的状态转移概率和行动期望回报如下:
(5)
同理可得,基于策略的行动期望回报如下:
(6)
为了评价策略的好坏,根据当前时刻的期望回报定义了行动价值函数Q(s0,a)和状态价值函数Vπ(s0),使用贝尔曼方程来表示行动价值函数和状态价值函数:
Qπ(s0,a)=Ra(s0)+
(7)
(8)
一个好的策略应该要有更高的行动价值,从贝尔曼方程的最优性可以得出,最优策略应该在每个状态中选择行动价值最高的行动来执行,对应地可以得到最优策略的数学描述:
Q*(s0,a)=maxπQπ(s0,a),
(9)
π*(s0)=argmaxaQ*(s0,a)。
(10)
1.3 强化学习的不同方法
强化学习是基于马尔可夫决策模型,可以将不同的强化学习方法归类成几种类型。从依赖环境与否可以分成Model-free和Model-based两种,区别在于智能体是否了解环境。在Model-free的方法中,智能体只根据环境给予的反馈去学习,而不需要去了理解环境或环境对于状态转移的规则;而Model-based的方法需要先让智能体学习环境的相关信息,从而对于自己的状态转移和行为有一定的预判,更好地去采取行动策略。
从行为选择上,可以分为基于概率Policy-based和基于价值Value-based的两种方法。基于概率的强化学习是通过分析得到采取不同的行为的概率,再根据概率采取下一步行动,典型的算法有Policy Gradients;基于价值的强化学习则是根据不同动作的价值,选择一个价值更高的动作进行行动,典型的算法有Q-Learning[13]、Sarsa[14-15]等。两种不同的方法各有其优缺点。经过多年的发展,许多学者也提出了将二者相结合的强化学习方法,例如Actor-Critic[16],Actor采用概率选择动作,Critic根据动作给出相应的动作价值,在原有Policy Gradients的基础上,结合Value-based方法的优点,加速了智能体的学习速度。
从学习的经验来源上,可以分为在线学习On-Policy和离线学习Off-Policy。在线学习方法采用边玩边学的方式,必须由智能体在自己探索的过程学习;离线学习方法可以采用和在线学习一样的方式边玩边学,也可以利用之前探索或他人探索的经验进行学习。典型的在线学习方法如Sarsa、Sarsa lamba等,离线学习方法主要是Q-Learning。
2 系统建模
在室内场景搜救问题上,和传统机器学习领域中的迷宫问题有些许类似,与之不同的是,真实的搜救环境中是连续且大规模的,并且环境中待搜救的目标通常不止一个,衍生出来的是智能体的多目标任务。为了完成在多目标任务上的无人机路径规划问题,首先需要解决传统迷宫问题存在的稀疏奖励问题,再者室内搜救场景中的状态空间较大,需要采用处理连续状态空间和动作空间的深度强化学习算法。
在采用深度强化学习算法进行路径规划前,我们需要先将环境信息建模,将其数字化与离散化,以便进行算法的训练和仿真。
2.1 环境描述与无人机设置
本文选择室内救灾场景(图2)进行实验,在救灾任务中,受困人员的信息是需要重点关注的,该类型信息是带有一定先验知识的,比如:人一般在房间、餐厅、客厅等地活动,并且该类信息不仅仅包含一个目标点,将这一部分的先验信息当作无人机路径的目标,要求无人机以更快的速度飞往目标点。
对于多目标的无人机搜救问题而言,为了更好地进行建模,在无人机上做出了以下几点简化:
① 无人机仅搭载GPS(用于定位)、前方的红外感应器(用于感测前方是否存在障碍)和简易摄像头(用于拍摄场景图片)。
② 无人机的飞行控制理想化,不对其飞行控制系统进行更深入的控制。
③ 无人机接收到的速度指令为一帧的速度,其最大位移距离不超过一个单位格。
基于上述几点的简化,下面将对于状态空间建模和算法设计进行详细的介绍。

图2 实验场景示意图Fig.2 Experimental scene
2.2 状态空间建模
在采用深度强化学习对智能体进行训练前,需要将待执行的问题进行分析,对其状态空间合适地建模。在类似的迷宫问题中,涉及到迷宫地图的建模、智能体的状态和动作描述,需要考虑如何能更好地描述问题并更有效地帮助智能体训练。
在搜救问题上,本质类似于多目标的迷宫问题,本文采用三维矩阵对地图进行离散化建模,将实际场景保存成100×100×10的三维矩阵,对于实际场景中的障碍物透过不同的数值和可飞行区作区分。
为了更真实地模拟实际的飞行过程,对于无人机飞行过程中的状态和动作采用连续值进行描述,任意时刻的状态st采用无人机在环境中的x、y、z坐标表示,任意时刻的动作at则采用无人机在x、y、z三个方向上的速度值进行表示。
st=[xt,yt,zt],
(11)
at=[vxt,vyt,vzt]。
(12)
无人机的状态本质上是无人机在环境地图中的坐标,而本文使用的是连续值(无人机的状态)来对离散空间(环境地图)进行描述,这二者之间将进行如下的处理:
对于飞行到新状态st+1=[xt+1,yt+1,zt+1],对该状态向下取整,判断环境地图坐标为[⎣xt+1」,⎣yt+1」,⎣zt+1」]的位置是否是障碍物,若是障碍物,则代表无人机的飞行路径会撞到障碍物,视为不合法飞行;若不是障碍物,则该飞行路径视为合法路径,并转移无人机状态到新状态st+1。
3 基于多目标任务的MADDPG算法
在搜救任务中,主要面临两个难点:稀疏奖励和搜索空间过大的问题。为了有效解决这两个难点,MTDDPG算法在基础的深度强化学习算法DDPG[17-18]上,采用类似于分层学习[19]的框架,加入一定的奖励重塑[20],将问题分区简化,从而达到更好的训练效果和路径。
3.1 基于环境分区的改进
在真实的搜救环境中,一般会提前获取到待搜救环境的一个大体空间分区,比如在室内环境中,搜救人员可以事先了解室内的隔间信息。在此基础上,可以事先对整个大的搜索空间进行分区,把原本100×100×10甚至更大的空间简化,分成若干个小区,在每个小区内训练一个神经网络进行决策,一是可以更快地收敛训练结果,二是不同区的网络可以同步训练,缩短整体训练时间,从而更快地把握黄金救援时间。
为了模拟方便,在本问题中将空间划分成矩形空间,有利于在训练过程中更容易判断所在区域。如图3所示,本文将环境简单地划分为10个区域,每个区域内有1个或n个网络负责决策,这些子网络主要考虑该区域是否有目标点以及如何前往相邻区域的连接处。

图3 室内空间分区示意图Fig.3 Schematic diagram of indoor space partitions
经过环境分区后,除了有效地缩小各个网络的搜索空间外,根据不同区域间的邻接关系,可以将环境空间抽象成图结构(如图4所示)。基于图结构,可以利用图算法来决定遍历各区的路径,也可以在实际飞行过程中,根据实时环境(如温度、湿度等信息)动态选择不同区域的访问顺序,有利于在部署上更加泛用。

图4 室内空间分区图结构Fig.4 Graph structure of indoor space partitions
3.2 基于奖励重塑的改进
透过环境分区将问题从“多目标”问题化简为“多个单目标”问题,然而在单目标迷宫问题中存在的稀疏奖励问题依然存在,如果只采用式(13)全局奖励形式进行训练,训练结果难以快速地收敛。
(13)
考虑到场景的特殊性,待搜救的目标属于先验信息的一部分,而各个区域的连接点在环境划分后可以事先指定,因此每个子网络的目标点皆属于已知信息,可以利用这些先验信息对奖励进行密集化重塑,在奖励中加入当前位置和目标距离的负数进行重塑,可以得到新奖励:
(14)
式中,ɡt代表每个子网络的目标点,d(st+1,ɡt)则代表下一时刻位置与目标点的距离。
3.3 基于多目标任务的MTDDPG算法
多目标任务的两个重要难点通过环境分区和奖励重塑后,可以得到有效的改进,因此在搜救任务中,基于处理连续空间的深度强化学习算法——DDPG,在多目标任务的基础上,透过分层强化学习和奖励重塑的结合,对整个搜索空间化简,加速单一区域内收敛速度;同时由于各个区域间的决策互不干扰,分区训练的架构适合并行训练,加快整体训练速度,提出基于多目标任务的深度强化学习算法——MTDDPG。
MTDDPG算法的整体框架类似于分层学习,不同的是,在子控制器中,对于不同区域间的决策分为多个子网络,不仅仅靠唯一的网络训练。如图5所示,结合分区后的图结构选择合适的图算法决定不同区域的访问顺序,Goal Generator根据图算法决定访问顺序,结合整体地图给出n个子目标G={ɡ1,ɡ2,…,ɡn}。

图5 MTDDPG算法结构图Fig.5 MTDDPG algorithm structure diagram
Goal Generator给出下一个目标后,智能体透过当前区域和目标点决定适用的子网络Neti,每个子网络都是一个DDPG算法。每个DDPG网络中包含Actor网络和Critic网络,Actor网络设计成一层隐层,隐层结构为1 024×256,输入层和隐层的激活函数选择ReLU函数,由于无人机在3个方向的速度限制在[-1,1],采用更为合适的tanh函数作为输出层的激活函数(图6(a));Critic网络选择和Actor网络类似的结构,区别在于Critic网络的输出层不添加任何激活函数(图6(b))。
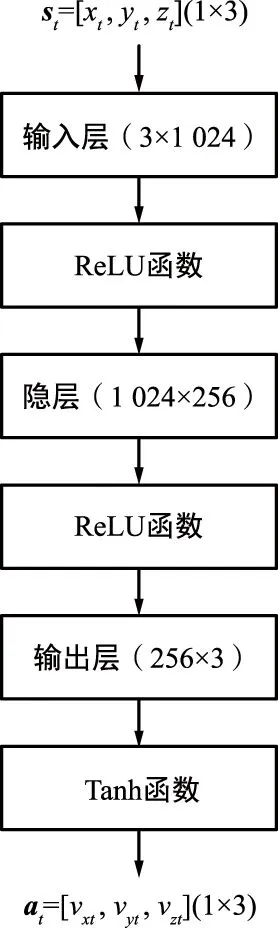
(a) Actor网络结构
子网络的更新类似于传统DDPG算法,在参数更新上采用软更新。此外,对于每一个子网络,利用并行训练的方式同步训练,进而缩短整体的训练时间,详细的伪代码如算法1所示。

算法1 MTDDPG算法Require:·numofsub-networkn·Areaset … {}· - ɡ · ɡ θ μ θμ θ θμ ′ μ′ θ ′ ←θ θμ′ ←θμ ,… ▷ - ɢ ,… μ θμ ɢ - ▷ ɢ γ ′ μ′ θμ′ θ ′ ɢ ɢ∑ θ ∇θμ ≈ ɢ∑ ∇ θ μ ∇θμ μ θμ θ ′ ←τθ τ θ ′ θμ′ ←τθμ τ θμ′
3.4 MTDDPG算法的优势
DDPG算法基于深度学习的基础上,改进了连续状态空间下的强化学习问题,在具有足够资源和时间训练的情况下,透过神经网络的前向传播过程进行决策,同时借由反向传播过程进行参数更新,综合了深度学习和强化学习的优势。但是在一些特定问题上,DDPG算法仍有很大的局限性,一般要对问题有深入的认识和了解,在建模上存在一定的难点。对于稀疏奖励问题而言,需要靠奖励重塑、分层学习等机制改进;复杂空间搜索问题则需要花费更多的时间和资源进行训练和部署;多目标问题在不同目标间的决策容易冲突甚至陷入局部最优点。
在本文考虑的室内搜救场景中,室内环境复杂并且搜救任务的时效性强,需要尽可能地缩短训练时间和部署的复杂性。此外,搜救任务中存在多个目标点的问题也难以用DDPG算法直接解决。相比于DDPG算法,本文提出的MTDDPG算法充分利用搜救任务中的先验信息,简化训练过程并提高了任务的完成度。与DDPG算法比较而言,MTDDPG算法具有以下几点优势:
① 环境分区方法利用基础的室内隔间信息,简化网络训练时的搜索空间,并且将多目标问题化简为单目标问题。
② 利用目标点的先验信息,对环境奖励进行重塑,更好地指导智能体完成搜索任务。
③ 多个区域网络的并行训练,极大地缩短了整体的训练时间。
为了进一步分析MTDDPG算法的优势,设计了3个实验来体现MTDDPG的训练效果,并对比与传统深度强化学习算法的差异。
4 仿真实验与MTDDPG算法实验验证
为了验证在搜救场景中MTDDPG算法的有效性,本文利用代码模拟一个室内搜救环境,作为算法验证的平台。本文,设计了3个不同的实验,用于对比DDPG和MTDDPG的差异,并根据实际救灾场景,模拟训练并部署MTDDPG算法,测试其路径规划的结果。
4.1 实验环境搭建与设计
整体室内环境如图3所示,其中包含3个卧室、客厅、厨房、餐厅和阳台,同时在各个房间内,安置了对应的家具,包括床、衣柜、电视柜、沙发等家具。图7是室内环境的可视化建模,用于展示规划后路径在室内环境飞行情况。可以看出和图3中的各个房间和家具一一对应,并且根据不同家具尺寸进行了坐标化,用于存储在三维离散矩阵中。
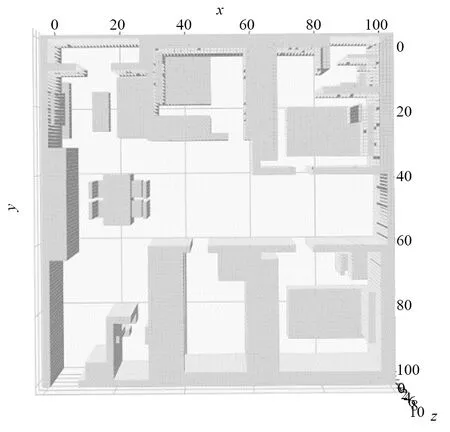
图7 可视化环境图Fig.7 Visualize the environment map

基于室内搜救的背景下,在传统深度强化学习算法的基础上,提出适合完成多目标任务的MTDDPG算法。为了验证MTDDPG算法的优势,本文设计了3个实验,分别是:
① 空旷场景实验:该场景不包含任何障碍物,仅有四面墙体和待搜索的4个目标(图8)。
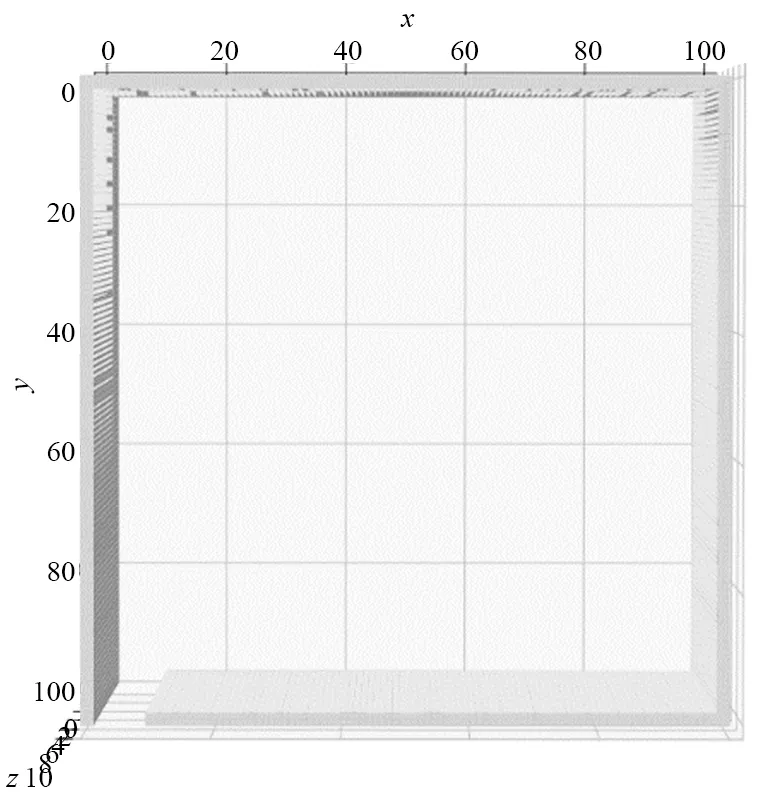
图8 空旷场景实验地图Fig.8 Experimental map of an empty scene
② 无家具场景实验:该场景仅有室内各个房间的隔间信息和待搜集的4个目标,不包含详细的家具信息(图9)。
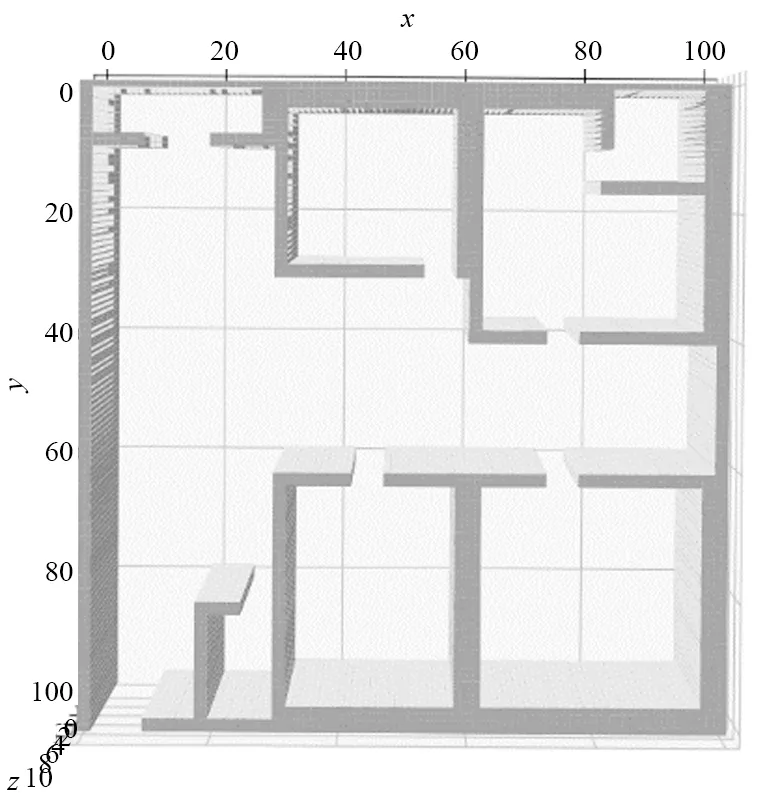
图9 无家具场景实验地图Fig.9 Experimental map of unfurnished scene
③ 完整家具场景实验:该场景具备完整的室内信息,包含墙体、家具和待搜救目标(图7)。
透过上面3个实验设置,验证MTDDPG算法和传统深度强化学习算法的差异和优势,并且在搜救场景中,部署训练好的MTDDPG算法,观察其在场景中规划的无人机飞行路径。此外,还会对比不完整先验信息场景和完整先验信息场景中的路径差异,并对结果进行分析。
4.2 MTDDPG算法实验验证
4.2.1 空旷场景实验
空旷场景实验的环境如图8所示,在环境中包含4个目标点,分别位于[x,y]=[18,68]、[40,20]、[75,29]、[67,82]4个坐标上,由于无人机是在三维空间飞行,无论z坐标为多少,只要满足x、y坐标位于目标点的方格内即算达到目标。
主要验证DDPG、DDPG+Reward Shaping(下面简称DDPG+RS)和MTDDPG三个算法的优劣,因此在除去各个算法本身差异的部分,其余训练上的参数均保持一致,如表1所示。在训练参数上,除表1的参数之外,每个episode中还需要指定训练次数(steps),在MTDDPG算法中,每个子网络在一个episode中训练1 000次,由于共有7个子网络,因此对应的DDPG算法和DDPG+RS算法则在一个episode中训练7 000次,以此来平衡不同算法总的训练次数。
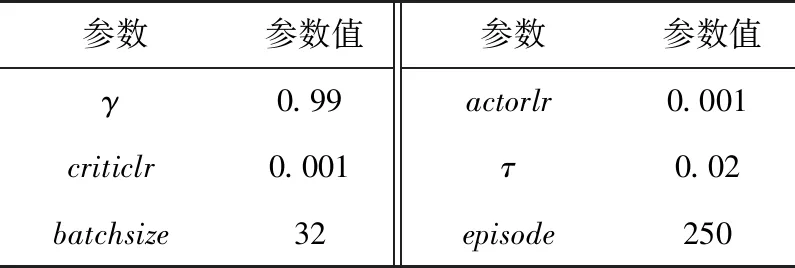
表1 空旷场景实验网络参数Tab.1 Network parameters for empty experiment
MTDDPG算法需要事先对环境进行分区,由于本实验场景较为空旷且只有4个目标点,为了仿真上的便利性,对环境简单分为4个区域(如图10所示),并从左下角开始顺时针访问4个目标。根据预设的目标访问顺序,加上决策如何在各个区域转换的子网络,本实验的MTDDPG算法需要训练7个子网络,分别是4个子网络控制前往目标点和3个子网络控制4个区域间的转换。
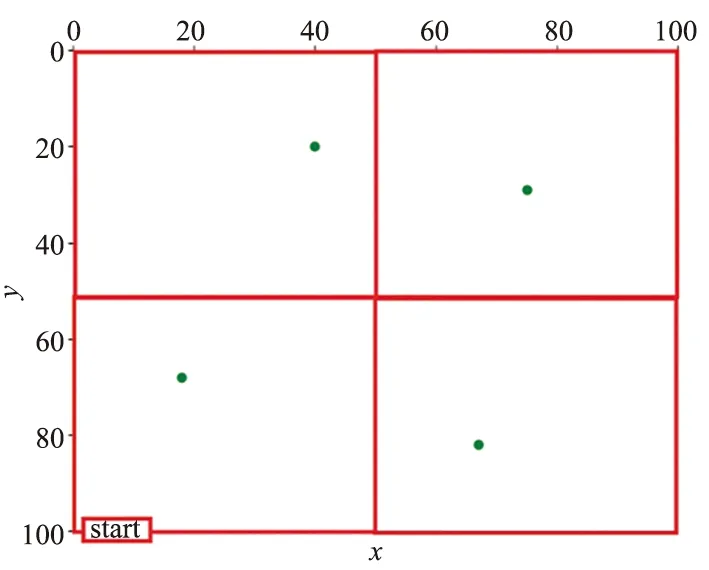
图10 MTDDPG在空旷场景实验下的环境分区示意图Fig.10 Schematic diagram of the environment partitioning of MTDDPG in an empty scene experiment
对于MTDDPG算法而言,透过并行训练各个子网络,平均一个子网络在5 min左右能够训练完成,总的训练时间因为并行训练的原因,相当于只需要一个子网络的训练时间即可。
根据这些训练好的子网络,基于MTDDPG的框架部署后,便可用于对完整路径的决策,图11(a)为路径的三维图,图11(b)为路径的上视图,在两个图中,均用蓝点代表起点,绿点代表4个待搜救的目标点,红线则代表MTDDPG算法规划的路径。
除了验证MTDDPG在简单环境中的训练效果,本实验对于3个不同算法进行了效果对比。图12可以看出,红线和紫线分别代表MTDDPG算法的全局奖励和局部奖励,横坐标为训练次数(episode),纵坐标为奖励(reward),对比于其他算法来说,MTDDPG算法在reward上的收敛速度和效果都较好。从橙线、绿线和蓝线的对比来说,简单的奖励重塑效果并不会比原始DDPG更好。图13对比了3个不同算法的任务完成率,蓝、橙、绿三线分别代表MTDDPG、DDPG、DDPG+RS算法,明显可以看到MTDDPG在任务完成率上取得了更好的效果。
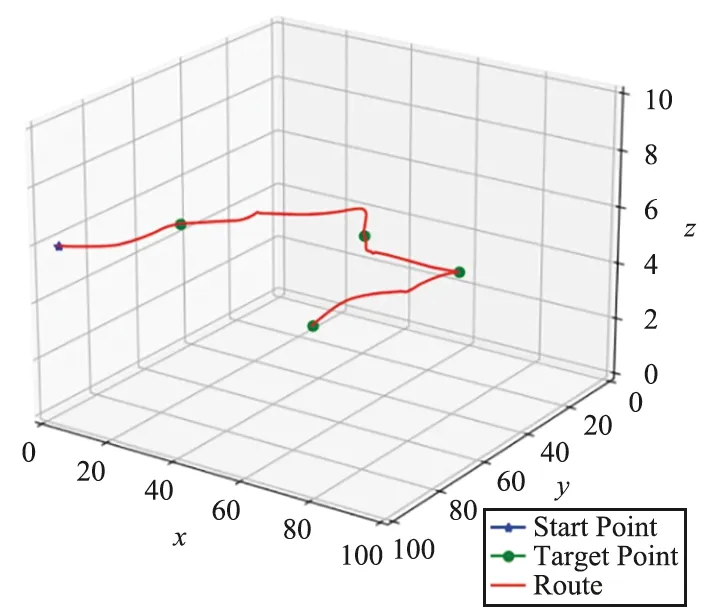
(a) 三维图
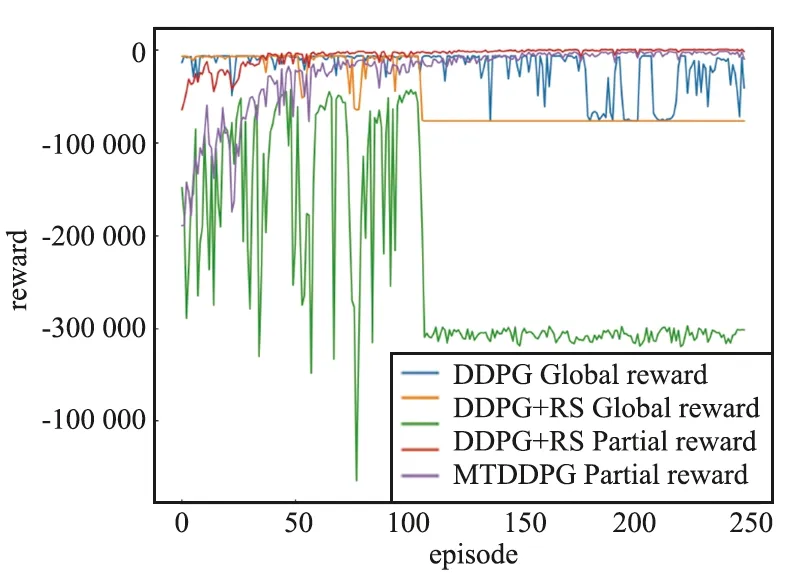
图12 3种算法的训练奖励对比Fig.12 Training reward comparison of three algorithms
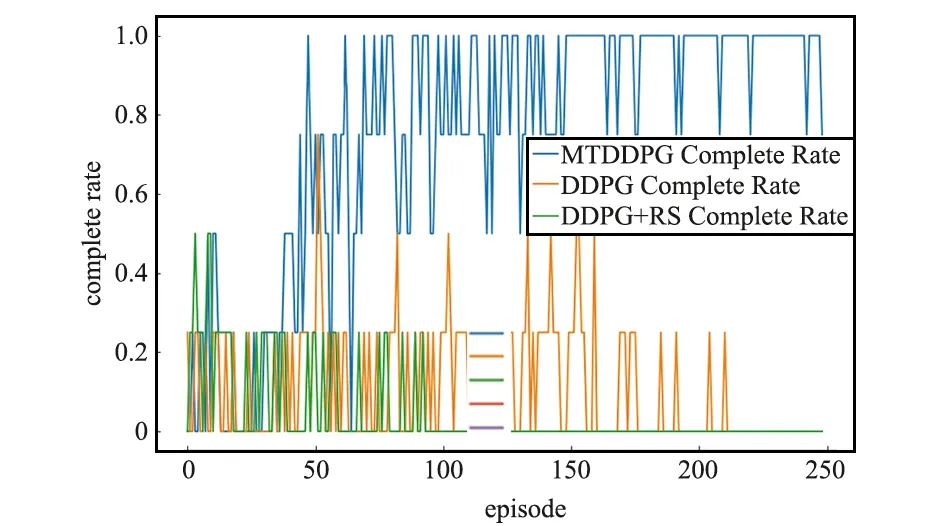
图13 3种算法的任务完成率对比Fig.13 Comparison of task completion rates of the three algorithms,the horizontal axis represents the number of training sessions
4.2.2 无家具场景实验
无家具场景实验的环境如图9所示,实验场景中,模拟真实救灾中先验信息缺失的情况,比如家具信息。在此基础上,对于MTDDPG算法的训练和部署需要进行一定的处理,确保无人机在飞行过程中不会撞到未知的家具。在训练过程中,环境分区按照室内隔间矩形分割,和有家具的场景类似,如图3划分;而训练参数上,和空旷场景类似,采用表2的参数进行训练。

表2 无家具场景实验网络参数Tab.2 Network parameters for unfurnished scene
本实验环境中包含4个目标点,分别位于[x,y]=[18,68]、[14,5]、[48,79]、[83,29]4个坐标上,并且按照这个顺序访问各个目标点。根据环境分区可以知道,总共需要14个子网络进行联合决策,其中包含4个目标点决策子网络和10个区域转换决策子网络。
对于MTDDPG算法,我们关注于各个子网络训练的reward以及任务完成率。图14显示14个子网络的训练reward,可以看到,所有子网络在全局奖励(蓝线)上训练后都收敛到一个稳定值,而对于多数的子网络而言,局部奖励(橙线)也收敛到稳定值。
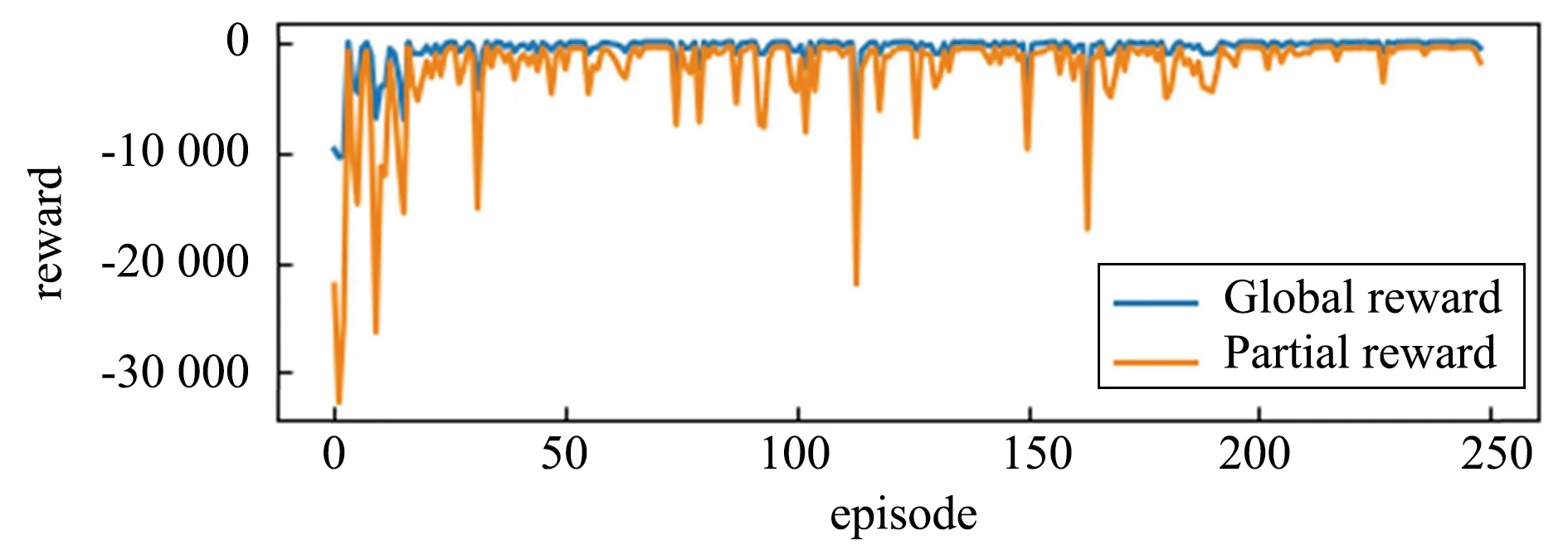
(a) Agent0 Reward
虽然训练时采用的是无家具场景,但是在实际应用中,应该要部署在具有完整家具信息的场景。由于训练过程中缺乏家具信息,会导致训练好的MTDDPG算法在实际飞行中,规划的路径有撞到家具的风险。为了解决这一问题,在部署上,智能体每选择一个动作时,需要对于下一个状态进行判断,如果是障碍物,则根据随机策略重新选择动作,确保不会撞到;如果不是障碍物,则无人机按照MTDDPG算法给出的动作行动。图15显示了通过MTDDPG算法在无家具场景中训练后实际的飞行轨迹(黑线)可以看到,经过特殊处理后的轨迹,很好地完成目标点(绿点)搜索任务,并且避开了可能存在的家具。
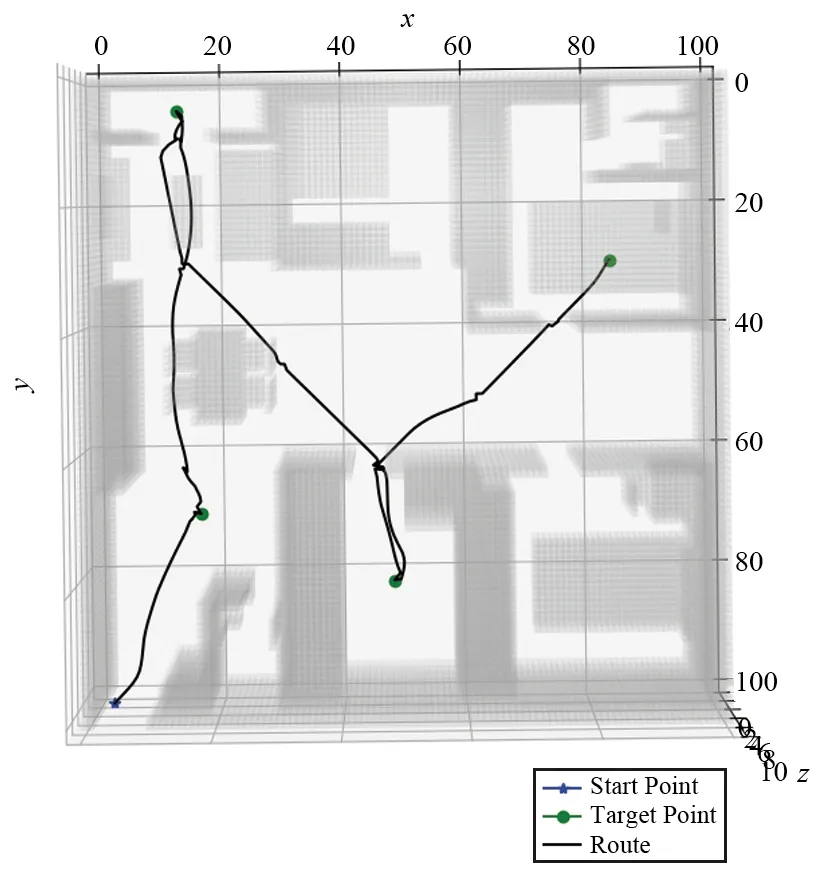
图15 无家具场景下训练的无人机实际飞行轨迹Fig.15 Flight trajectory of the UAV trained in the unfurnished scene
4.2.3 完整家具场景实验
完整家具场景也称为完整先验信息场景,本实验中的环境具有完整的家具信息,如图7所示。在该场景下,网络能得到充分的训练,并且训练和实际飞行的地图是更接近的。在这个实验环境中,共有4个目标点,分别位于[x,y]=[18,68]、[14,5]、[48,79]、[83,29]4个坐标上,并且按照上述的顺序依次访问。训练参数的部分,为了和无家具场景实验进行对比,训练参数和无家具场景实验保持一致,如表2所示。
和无家具场景实验类似,根据环境分区的结果,一共需要14个子网络进行训练和决策。对这14个子网络同样用训练reward和任务完成率进行评价,图16分别显示了14个子网络的训练reward。可以看到,大部分子网络在全局奖励(蓝线)和局部奖励(橙线)上,经过训练后收敛到稳定值。
经过训练后的网络,将该网络部署在一样的场景中进行搜索任务,根据MTDDPG算法的框架,利用14个训练好的子网络对无人机飞行路径进行规划,图17(a)和图17(b)分别展示了MTDDPG算法所规划路径的三维图和上视图,可以看见,无人机飞行的轨迹(上视图中的黑线)避开了障碍物并完成4个目标点(绿点)的搜索任务。
本实验和无家具场景实验的对比中,两个实验所规划的路径如图18所示,可以看出,无家具场景下的路径轨迹(红线)更加大胆,比如在厨房中的轨迹,正常飞行高度下,无家具场景的轨迹更加靠近冰箱(障碍物),完整家具场景的轨迹(黑线)则会远离冰箱而靠近飞行高度下更为空旷的灶台。此外,从二者的轨迹对比来说,无家具场景和完整家具场景实验所规划的轨迹大体上没有太大的差异。因此,MTDDPG算法在先验信息是否充分的两种场景下,都能较好地完成多目标的搜索任务。

(a) Agent0 Reward

(a) 三维图
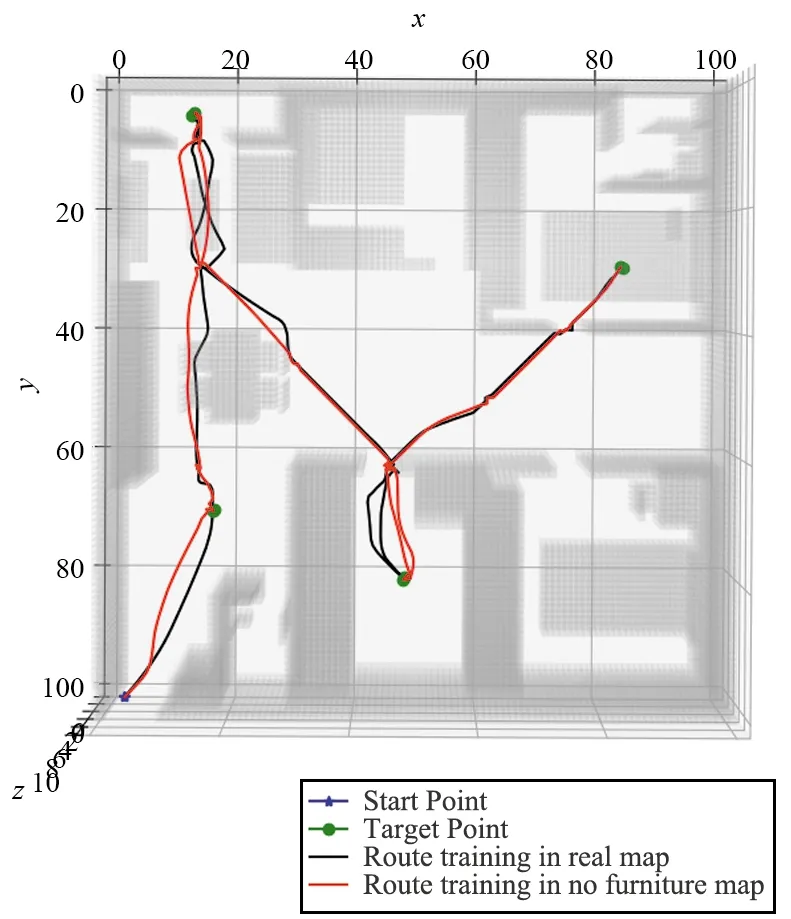
图18 无家具场景和完整家具场景的轨迹对比Fig.18 Trajectory comparison between an unfurnished scene and a complete furniture scene
5 结束语
本文主要研究深度强化学习算法,在多目标搜索任务中规划无人机的飞行轨迹,基于稀疏奖励的场景中,对旧有算法分析并改进,提出基于多目标任务的深度强化学习算法——MTDDPG。
对旧有的深度强化学习算法,本文基于环境分区和奖励重塑进行了两个方面的改进。利用环境分区可以将多目标问题化简为多个单目标问题,并且经过分区后的各个区域搜索空间变小了,而负责各个区域决策的子网路不互相干扰,可以同步训练减少整体训练时间。在分秒必争的搜救任务中,训练时间减少意味着可以更快地部署,对于场景探勘和搜救有着极大的帮助。
基于奖励重塑的改进上,环境分区化简问题后,每一段的决策可以建模成单目标的迷宫问题。这类型的问题经过许多学者的研究后,有比较好的奖励重塑形式,可以有效地解决训练结果收敛速度慢的问题。本文在全局稀疏奖励上,加入当前状态和目标点距离的负数作为新奖励形式,结合环境分区,有效地改善了多目标任务中存在稀疏奖励和搜索空间大的两个难点。
实验验证中,本文设计了3个实验对算法进行验证,其中在空旷场景实验中对DDPG、DDPG+RS和MTDDPG算法进行分析对比,可以看出MTDDPG算法在该任务中的优势。无家具场景实验和完整家具场景实验中,二者分别对于不完整先验信息和完整先验信息的场景进行了建模,利用MTDDPG算法在两个场景中训练,最终部署在完整家具场景中进行轨迹规划。本文对比两个实验规划的轨迹,并对于结果进行了分析解释。
综合理论分析和实验验证结果,本文提出的MTDDPG算法在多目标的搜救任务上,相比于传统的深度强化学习算法,取得了较好的成果。
