注意力引导多模态融合的RGB-D图像分割
2022-12-30靳瑜昕杨晓文焦世超文阳晖王爱兵
靳瑜昕,杨晓文,张 元,焦世超,文阳晖,王爱兵
(中北大学 大数据学院,山西 太原 030051)
0 引 言
早期的图像分割方法是从RGB图像中提取特征信息进行分割[1-4]。针对端到端的分割网络在下采样时图像分辨率减少导致部分特征信息丢失的问题,文献[5,6]提出了结合高级语义信息和低级细节特征、聚合不同尺度的上下文信息等方法提高分割性能。RGB图像分割的问题在于图像只提供颜色、纹理、形状等二维视觉信息,而深度信息包含丰富的三维空间特征,通过融合RGB图像和深度图像可以有效提高语义分割性能。Cao等[7]根据深度特征隐含的局部几何形状信息与语义相关性更大,提出形状感知卷积层(ShapeConv)处理深度特征,提高了分割性能。但如何充分利用两种模态之间的互补性和差异性,如何增强编器中信息的交互、传递以及特征提取能力等仍是需要深入研究的问题。针对以上问题,本文提出了一种注意力引导特征交叉融合的室内场景分割网络(attention-guided multi-modal cross fusion network,ACFNet),包含编码器、注意力引导的特征交叉融合模块(attention-guided multi-modal cross fusion module,ACFM)、解码器3部分。针对RGB图像和深度图像的不同特性,分别设计专用的RGB编码器和深度编码器提取特征,并将原始深度图转化为包含更多空间信息的HHA[8](horizontal disparity, height above ground,and the angle the pixel’s local surface normal makes with the inferred gravity direction)图像。ACFM融合模块引入注意力机制[9](convolutional block attention module,CBAM)处理两种模态特征,并将处理后的两种模态以交叉相乘的方式进行融合,充分利用两种模态间的互补性和差异性。通过上述的网络设计,有效地提高了RGB-D语义分割效果。
1 相关工作
1.1 基于多模态融合的语义分割
随着深度传感器的发展,在获得颜色信息的基础上,同时也能较为容易的获得场景的深度信息,越来越多的学者开始了基于RGB-D图像的分割方法研究。文献[10]中指出多模态融合根据融合阶段分为早期融合、晚期融合和混合融合。Chen等[11]提出了空间信息引导卷积网络(spatial information guided convolutional network,SGNet),在不影响参数量和计算成本的情况下,感知几何形状的能力得到了很大程度的提高。Zhang等[12]提出了NANet(non-local aggregation network),它具有一个精心设计的多模态非局部聚合模块(multi-modality non-local aggregation mo-dule,MNAM),以便在多阶段更好地利用RGB-D特征的非局部上下文。Cao等[13]提出RGB×D,在早期学习阶段以相乘的方式融合RGB信息和深度信息,之后只需要稍微修改就能使用现有的RGB分割网络,简单而有效地将RGB和RGB-D语义分割联系起来。
1.2 注意力机制
注意力机制[14]的基本原理是为特征图中不同的区域分配不同的权重,即提取特征图中所关注的有用信息,同时抑制无用信息,从而实现高效的特征提取,并降低了网络训练难度。其次,注意力机制有助于获取全局上下文信息,促进语义分割精度的提高。Zhou等[15]提出一个共同注意力网络(co-attention network,CANet),设计共注意模块自适应地聚合深度特征和颜色特征。ACNet(attention complementary network)[16]网络利用结合注意力机制的3个并行分支和注意力互补模块(attention complementary modu-les,ACM)有效提取并融合RGB 特征和深度特征,在NYUD V2数据集上的mIou达到48.3%。Zhou等[17]提出一种用于室内语义分割的三流自注意网络(three-stream self-attention network,TSNet),使用带有自注意模块的跨模态蒸馏流融合和过滤两个不对称输入流的语义信息。Yan等[18]提出的RAFNet(RGB-D attention feature fusion network)包含3个互补的注意模块,能够有效的从RGB分支和深度分支中提取重要特征,并且减少语义信息的丢失。
2 本文方法
本文提出的网络模型遵循编码器-解码器架构,其中编码器从输入中提取丰富的语义特征,并执行下采样以减少计算工作量;解码器采用上采样技术恢复输入分辨率,最后为每个输入像素分配一个语义类别。本节首先介绍了所提ACFNet的整体网络架构,然后详细介绍了编码器、ACFM特征融合模块和解码器3部分内容。
2.1 网络模型整体架构
本文提出的用于室内场景分割的ACFNet体系结构如图1所示,其中,7×7、1×1均表示卷积操作,S表示卷积或池化操作的步长(Stride)。以编码器-解码器为基础结构,RGB图像结合HHA图像作为网络输入。编码器部分设计专用的CNN特征提取架构,采用两个独立的非对称网络,分别以ResNet-101和ResNet-50为主干网络提取RGB特征和深度特征。RGB编码器和深度编码器由输入预处理步骤7×7卷积、最大池化操作和Stage m(m=1,…,4) 4个阶段组成,并且在RGB编码器中加入全局特征提取模块。在融合模块引入注意力机制,增强有用信息传播的同时抑制无用信息对分割效果的影响,基于CBAM提出注意力引导的特征交叉融合模块(ACFM),并将融合后的特征在编码器阶段多层次传播到两个特征提取分支,以更好地利用融合后的增强特征表示。解码器的基本块 (Decoder m=0,…,4) 简单的使用卷积层+BN层+ReLu堆叠多层以及双线性上采样操作组成,并且将RGB编码器与深度编码器Stage1-3的融合特征通过跳跃连接传输到解码器的Decoder3-1,增加低层细节信息和高层语义信息之间的联系,以此来重用编码器阶段丢失的特征信息。
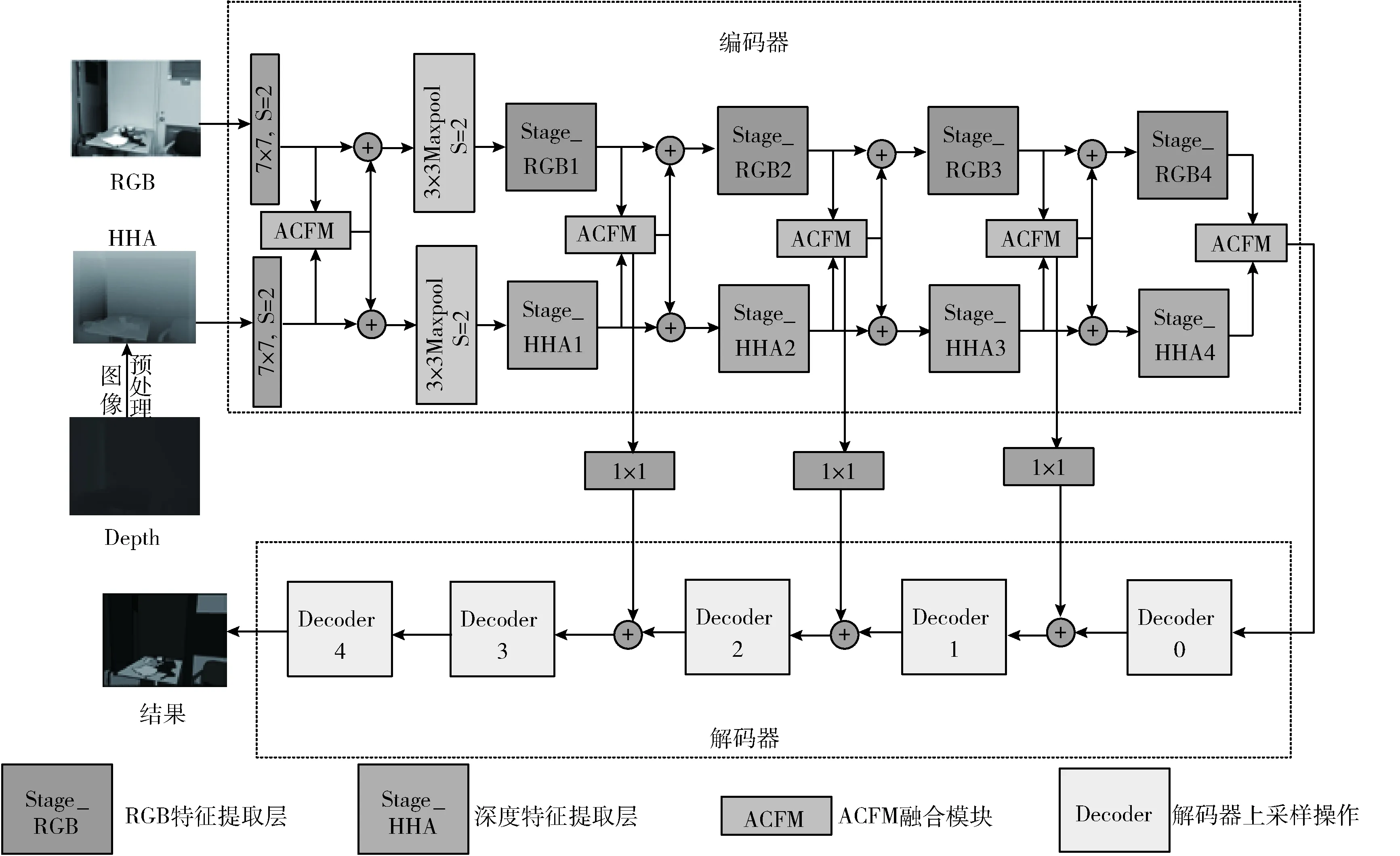
图1 注意力引导多模态交叉融合的语义分割模型ACFNet的体系结构
2.2 编码器
编码器使用非对称双流分支,为RGB和深度编码器设计不同的特征提取网络,对原始深度图像进行数据预处理,将其转换为HHA图像,结合RGB图像作为分割网络的输入数据。分别以ResNet-101和ResNet-50作为RGB编码器和深度编码器的主干网络,并且改进组成主干网络的基本块,即在Bottleneck中加入Maxpool并行模块,如图2(a)所示,记为MP_Bottleneck,通过增加网络宽度的方式提高特征提取性能,如式(1)所示
FE_out=Fin+Conv1×1(Cat(Conv3×3(Conv1×1(Fin)),M_P(Conv1×1(Fin))))
(1)
式中:Fin∈RH×W×C, H、W和C分别表示特征图的高度、宽度和通道数,Conv1×1,Conv3×3分别表示1×1,3×3卷积操作,Cat表示拼接操作,M_P表示最大池化操作,FE_out表示ResNet网络每阶段的输出。为了改进ResNet网络提取图像局部特征的不足,受Cao等[19]提出的GC(global context)的启发,在RGB编码器的4个阶段Stage1-4添加全局特征提取模块(GC),如图2(b)所示,使用GC处理FE_out提取全局特征,并且将最终的全局特征和局部特征通过相加的方式结合起来作为编码器Stage1-4的最终输出,构建全局-局部特征提取模块(global-Local feature extraction module,GL)如图2(c)所示,如式(2)~式(4)所示
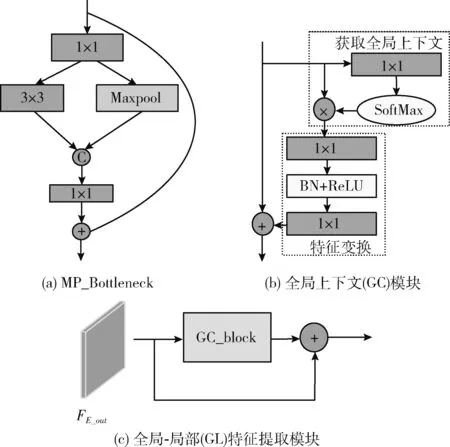
图2 编码器详细设计结构
FGL=FE_out+GC
(2)
GC=FE_out+Conv1×1(ReLu(LN(Conv1×1(y))))
(3)
y=FE_out×SoftMax(Conv1×1(FE_out))
(4)
其中,GC表示全局特征提取模块(GC)的输出,Conv1×1表示1×1卷积操作,LN表示批归一化操作,y表示全局特征提取模块(GC)模块中获取全局上下文部分的输出,FGL表示全局-局部特征,由于高层阶段包含更多的语义信息,会对分割精度产生更大的影响,因此在RGB编码器最后一个阶段的GC_block之前添加全局平均池化(GAP)操作,细化高层语义信息。
2.3 ACFM融合模块
为了更好地利用RGB和深度特征之间的互补性进行特征融合,ACFM融合模块引入注意力机制,首先使用CBAM模块,如图3(a)所示,其中,C表示拼接(Conca-tenate)操作,在通道和空间维度上进行注意力操作,分别对RGB和深度特征重新加权,如式(5)~式(8)所示,学习哪些特征信息需要抑制,哪些特征信息需要重点关注
Fa_rgb=CBAM(FGL)
(5)
Fa_hha=CBAM(FE_out)
(6)
CBAM=ca×σ(Conv7×7(Cat(Avgpool(ca),MaxPool(ca)))
(7)
ca=x×σ(MLP(Avgpool(x)+MLP(Maxpool(x))
(8)
其中,FGL、FE_out分别表示输入融合模块的RGB特征和深度特征,x表示CBAM模块的输入即FGL、FE_out,ca表示CBAM模块中通道注意模块的输出,Fa_rgb、Fa_hha表示经CBAM注意力机制处理后的特征输出,σ表示Sigmoid激活函数,Cat表示拼接操作,Avgpool和Maxpool分别表示平均池化和最大池化操作,MLP表示由两个1×1卷积层组成的多层感知机。ACFM融合模块的具体结构如图3(b)所示,使用交叉相乘的方式,如式(9)和式(10)所示,选择经注意力机制处理后的一种模态特征乘以未经处理的另一种模态特征,从一种模态中选择可区分的信息辅助修正另一种模态
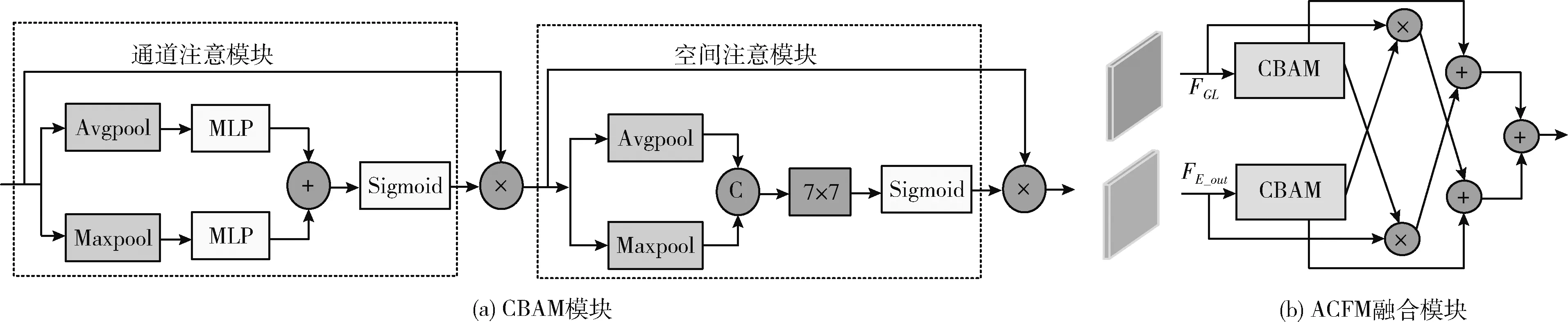
图3 注意力引导多模态交叉融合模块
Fm_rgb=FGL×Fa_hha
(9)
Fm_hha=FE_out×Fa_rgb
(10)
其中,×表示逐元素相乘操作,Fm_rgb、Fm_hha分别表示经相乘操作修正后的特征输出,之后进行交叉残差连接,使用经CBAM模块处理后的特征与经另一模态信息修正后的原始模态信息交叉相加,进一步重用在网络处理过程中丢失的细节信息,增强两种模态之间的互补性,最后将两种模态信息通过相加的方式进行融合,如式(11)所示
Ff_out=(Fa_rgb+Fm_hha)+(Fa_hha+Fm_rgb)
(11)
式中:Ff_out表示ACFM模块的最终输出结果,将融合后的特征传输到编码器阶段以相加的方式多层次传播到两个特征提取分支,该模块充分利用了两种模态之间的互补信息。本文实验结果表明,ACFM模块能够高效融合RGB和深度特征,产生更有利于语义分割的特征表示,进一步改善语义分割性能。
2.4 解码器
ACFNet网络的解码器部分由5个相同的单元组成,如图4所示,解码器单元由卷积层+BN层+ReLU激活函数和上采样操作组成,并在其中加入短接连接重用在训练过程中丢失的信息,短接连接使用1×1卷积改变编码器阶段的输出通道数,使其与解码器对应阶段的通道数相同可以进行相加操作。解码器单元中,1×1卷积用于改变通道数,减少模型复杂度,两个3×3卷积用于增加网络的非线性特征,上采样操作采用双线性插值方法,经过5次上采样操作后图像分辨率恢复到输入大小。第一个解码器单元的输入通道数为2048,在图像分辨率增加的过程中通道数逐渐减少,由于最后一个解码器单元用于输出网络预测结果,因此去除其最后一个卷积层之后的批归一化操作,并且设置输出通道数为语义类别个数,即40。
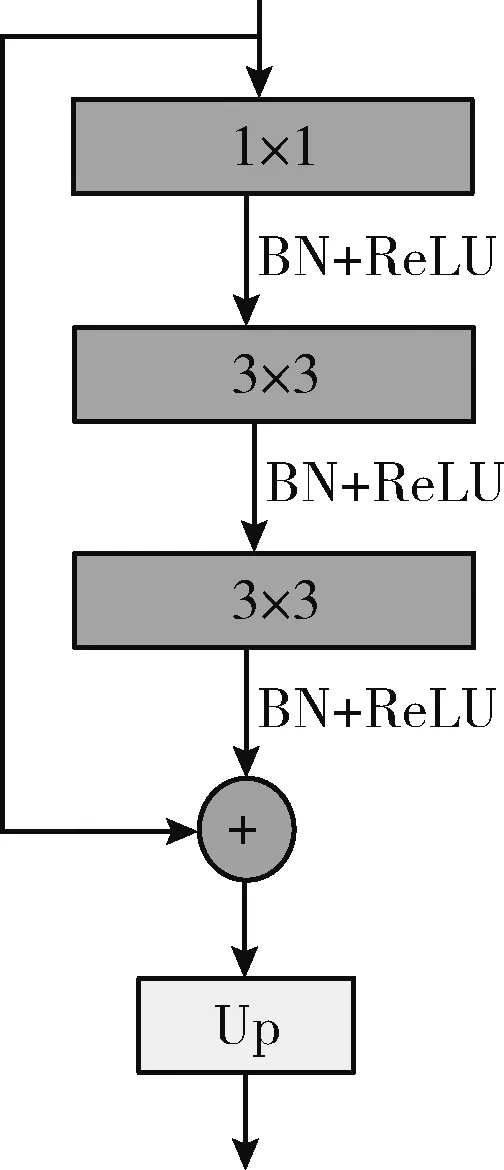
图4 解码器单元
3 实验结果及分析
本节在常用的RGB-D室内数据集上进行了大量实验,评估本文所提出的分割方法,并且对网络的关键模块设置消融实验,验证其有效性。
3.1 数据集与评估标准
3.1.1 NYUD V2数据集
NYU Depth V2数据集[20]是由Microsoft Kinect的RGB和深度相机采集的各种室内场景组成,包含来自3个城市464个不同室内场景的1449张带有标签的RGB-D图像对,其中795张图像对用于训练,654张图像对用于测试环节,使用将894个不同物体分为40个类别的分类方式。
3.1.2 评估标准
本文使用的语义分割性能度量标准为常见的像素精度(pixel accuracy,PixAcc)、平均交并比(mean intersection-over-Union,mIou)、平均像素精度(mean pixel accuracy,MPA),其中PixAcc为表示标记正确的像素占总像素的比例,其计算公式如式(12)所示;mIou即求取所有物体类别交并比(Iou)的平均值,本质为求真实值(Ground Truth)和预测值两个集合的交并比,其计算公式如式(13)所示;MPA为先计算每个类分类正确像素的比例,之后求所有类的平均,其计算公式如式(14)所示
(12)
(13)
(14)
其中,k+1表示类别总数,i表示真实值,j表示预测值,pij表示将真实值为i预测为j的数量,pii表示预测正确的数量,pij和pji分别表示假正(FP)和假负(FN)的数量。
3.2 实现细节
本文采用Pytorch深度学习框架实现网络模型,使用动量为0.9的随机梯度下降(stochastic gradient descent,SGD)优化器训练所提出网络模型,并设置权重衰减为0.001进行正则化,初始学习率设置为0.02,在NYUD V2数据集上训练500个epoch,批量大小设置为5。
本文提出的网络结构分别将改进后的ResNet-101和ResNet-50网络在ImageNet数据集上进行预训练后作为编码器的主干网络,将深度图像编码为HHA图像,输入的RGB-D图像分辨率大小统一裁剪为640×480,为了增加图片的多样性,对输入图片应用随机水平翻转、缩放和裁剪等操作进行数据增强,使用交叉熵作为损失函数并采用监督学习的方式,在NVIDIA GeForce RTX 3090 GPU上训练所提出的网络模型参数,训练过程中的损失曲线如图5所示。

图5 损失曲线
3.3 实验结果分析
3.3.1 与其它方法的对比实验
本节在NYUD V2数据集上将本文提出的ACFNet与其它现有的方法进行比较,NYUD V2数据集划分为40个语义类别,结果见表1,列出了本文方法与其它方法在像素精度(PixAcc)、平均交并比(mIou)、平均像素精度(MPA)上的分割性能。
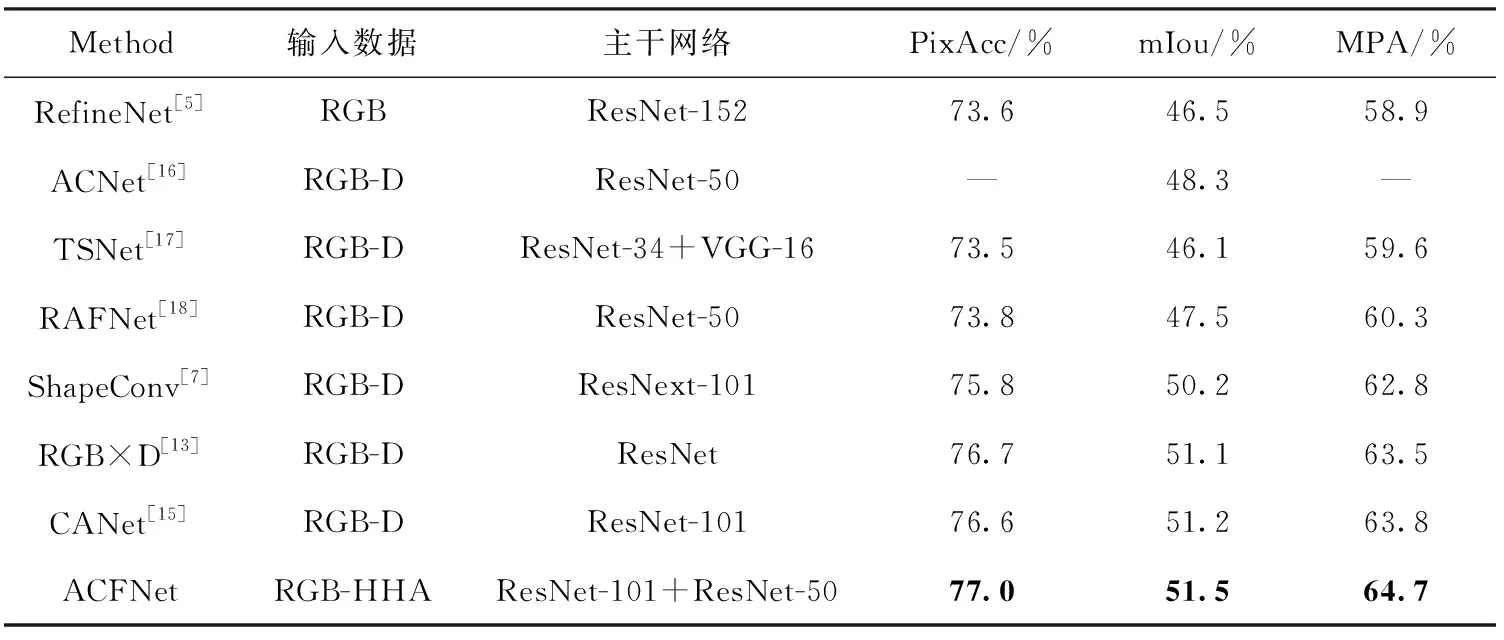
表1 在NYUD V2数据集上与其它方法的比较
具体而言,本文方法以ResNet-101+ResNet-50为主干网络,在40个语义类别的NYUD V2数据集上进行实验,两个评估指标像素精度、平均交并比和平均像素精度分别为77.0%、51.5%和64.7%。与仅使用RGB图像作为输入的RefineNet相比,像素精度、平均交并比和平均像素精度分别提高了3.4%、5.0%和5.8%,实验结果表明加入深度特征对于分割性能有一定的提高;与同样使用注意力机制的ACNet和CANet相比,平均交并比分别提高了3.2%和0.3%;与融合特征同样使用双向多级传播策略的RAFNet相比,像素精度、平均交并比和平均像素精度分别提高了3.2%、4.0%和4.4%;与较新的分割算法TSNet和RGB×D相比较,虽然网络层数相对较多,但平均交并比也有很大提高,分别提高了5.4%和0.4%。综上所述,本文所提出的ACFNet优于现有的大多数方法,在NYUD V2数据集上表现出具有竞争力的分割性能,能够较好地适应室内场景的复杂性和多样性。
3.3.2 语义分类结果分析
为了更直观地分析本文方法在不同类别上的语义分割结果,本节进一步分析ACFNet在NYUD V2数据集的40个语义类别上的交并比,并将其与室内语义分割算法RAFNet和CANet在不同类别上的交并比进行比较,以更清楚验证本文方法在室内语义分割方面的有效性。结果见表2,每个类别的最高结果用黑色加粗标记。

表2 在NYUD V2数据集上40个类别的交并比(Iou)比较结果/%
从表2中可以总结得出,在40个语义类别中,本文方法在22个类别上的交并比表现都优于其它两种方法。一方面,与CANet相比,本文方法在常见的易区分物体“柜子”、“床”、“椅子”上,交并比分别提高了1.4%、3.0%、3.5%;同时在大面积背景区域的分割精度上也有一定提高,与RAFNet相比,ACFNet在“墙壁”、“地面”和“天花板”的交并比分别提高了6.0%、1.5%和2.8%,这得益于本文提出的融合模块能够充分利用RGB和深度两种特征之间的差异性和互补性,有效利用了深度特征所提供的三维空间信息,其中注意力机制抑制无用信息、放大有用信息的能力是融合模块表现较好的主要原因之一。另一方面,本文方法在出现频率较低的小物体上也表现出了较好的分割性能,比如在“图片”、“灯”、“包”等物体上,ACFNet的交并比分别比RAFNet和CANet提高了8.2%、2.2%、10.6%和3.2%、4.2%、3.4%;同时在一些形状不规则物体上的交并比也有一定程度的提高,比如ACFNet在“百叶窗”、“淋浴器”上的交并比分别比RAFNet和CANet提高了9.0%、4.1%和3.9%、19.1%,这得益于本文提出的全局-局部特征提取模块,增加了更多可区分的细节信息,在一定程度上能够改进分割性能。
3.3.3 消融实验
为了验证在相同超参数下本文所提网络结构的有效性,本节在NYUD V2数据集上进行了大量的消融实验。以编码器的主干网络为ResNet-101和ResNet-50、RGB和深度特征通过简单相加融合并进行双向多级传播、编码器和解码器对应阶段设计短接连接的配置作为基线网络(Baseline),ACFM表示融合模块,GL表示全局-局部特征提取模块,见表3,与基线网络相比,单独添加两个模块的平均交并比分别提高了2.4%、1.5%,而集成两个模块的本文方法平均交并比提高了3.1%,这表明同时使用比单独使用任一模块效果更好。
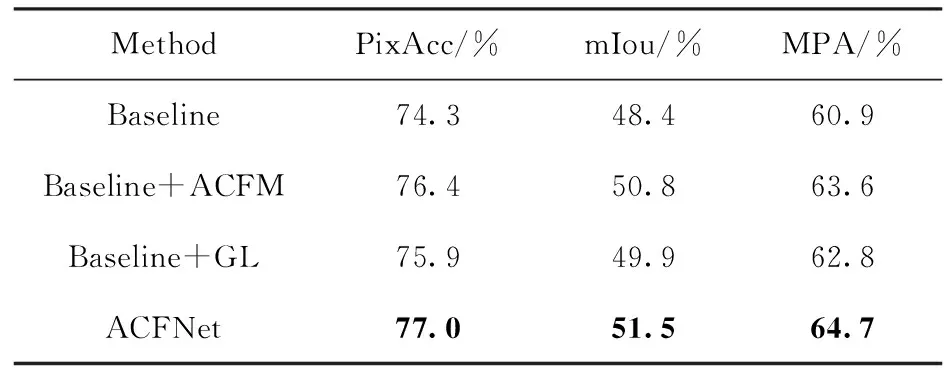
表3 在NYUD V2数据集上ACFM和GL模块的消融实验
为了进一步验证本文所设计的ACFM融合模块是最优组合结果,消融实验在ACFNet仅去除GL模块的基础上进行。首先设置不同的特征融合方式进行实验,表明ACFM模块融合方式的有效性,见表4,CBAM表示在融合之前对两种特征进行的注意力操作,相加表示逐元素相加,本文方法指ACFM模块中使用的交叉相乘再相加的融合方式,从表4中可以看出仅选择相加的融合方式效果最差,像素精度、平均交并比和平均像素精度分别为74.3%、48.4%和60.9%;加入CBAM模块处理特征之后再进行相加融合分割性能有一定的提高,而本文的融合方式是3种方式中融合效果最好的,像素精度、平均交并比和平均像素精度可以达到76.4%、50.8%和63.9%。这是因为ACFM模块的融合方式增加了更多的交互操作,增强了两种特征间的相关性,有效地利用了RGB和深度特征携带的信息。
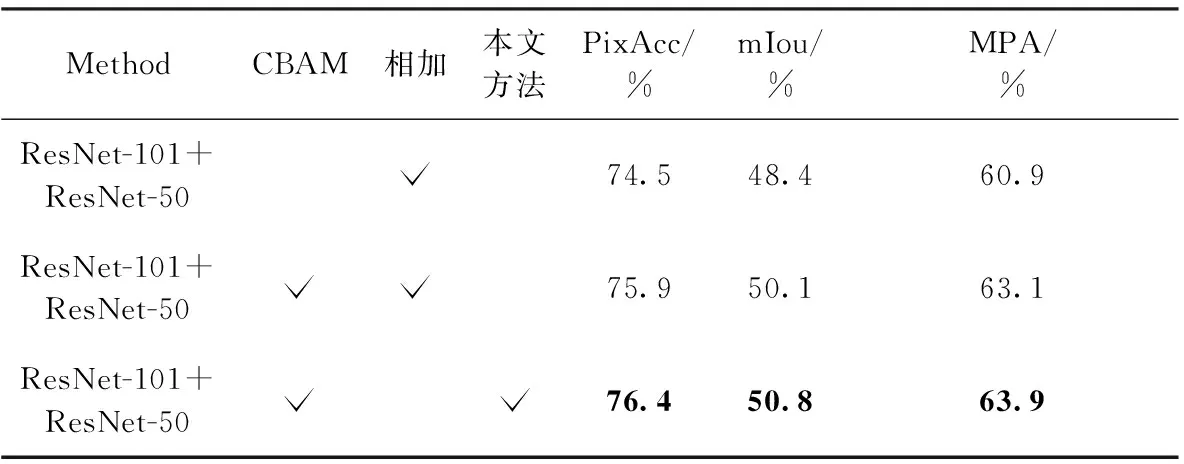
表4 在NYUD V2数据集上ACFM模块不同融合方式的消融实验
在确定融合模块的具体结构之后,本文对在网络的不同位置加入融合模块也进行了消融实验。如表5所示,在每个阶段单独加入ACFM的分割性能差强人意,尤其是网络结构的早期比如7×7卷积、Stage1之后,从表5中可以看出,这样对网络性能的提升微乎其微,这是由于前期的特征还未经过太多处理,获得的有用信息较少。而在每个阶段单独加入融合模块对于整体的分割性能都有一定的改善,因此本文选择在所有阶段加入融合模块,表5中第6行的显示结果表明了本文网络结构设计的有效性,这种方式下的分割性能是最优的,与效果最差的7×7卷积阶段加入融合模块相比,像素精度、平均交并比和平均像素精度分别提高了1.2%、2.1%和2.0%。

表5 在NYUD V2数据集上ACFM模块位于ResNet-101+ResNet-50不同阶段的消融实验
为了验证本文提出的修改ResNet网络基础块的设计,在其它结构均不改变的情况下,仅替换MP_Bottleneck为Bottleneck进行消融实验,结果见表6,实验结果表明MP_Bottleneck使像素精度、平均交并比和平均像素精度分别有了0.5%、0.3%和0.5%的提高。

表6 在NYUD V2数据集上ResNet-101+ResNet-50不同基础块的消融实验
3.3.4 分割结果可视化
为了更直观地展示本文网络模型的结果,本节在图6中显示了ACFNet在公共数据集NYUD V2上的部分可视化结果,其中第一、第二、第三列依次表示RGB图像、HHA图像和语义标签,第四、第五列分别表示基线网络和ACFNet的语义分割结果。图6中使用方框标记了语义分割结果的对比区域,结果显示ACFNet对于易区分的大面积物体的分割精度有所提高,如第1行的“墙壁”和第6行的“窗帘”;本文模型在不规则物体上的分割表现也较好,如第2行的“盆栽”和第3行的“灯”,相比基线网络,ACFNet在轮廓细节方面的分割结果有所改善;对于颜色相近的难以区分的物体,如第4行的“架子”和第5行的“水池”,本文模型也能获得更多分割正确的区域。

图6 本文网络在NYUD V2数据集上的分割结果可视化对比
4 结束语
为改善室内语义分割算法性能,本文提出一种注意力引导多模态交叉融合的室内语义分割网络ACFNet。在数据预处理阶段将深度图转化为包含更多空间信息的HHA图像,ACFM融合模块引入注意力机制,从通道和空间两方面处理RGB和深度特征并设计专用的融合连接方式。同时引用全局上下文模块提取全局特征,将全局、局部特征通过相加结合起来,增强网络传播过程中的特征表示。在室内RGB-D数据集NYUD V2上进行了大量对比实验结果表明本文方法的有效性,相比近几年其它的语义分割算法,像素精度和平均交并比均有所提高。如何进一步简化本文的网络模型,降低模型复杂度,融合多尺度特征以提高小物体的分割准确率是未来需要解决的问题。
