融合BTM和BERT的短文本分类方法
2022-12-30付文杰马红明
付文杰,杨 迪,马红明,吴 迪
(1.国网河北省电力有限公司 营销服务中心,河北 石家庄 050000;2.河北工程大学 信息与电气工程学院,河北 邯郸 056038)
0 引 言
短文本因其内容简短、易于阅读的特性,广泛存在于微博、短信、电力工单等载体中[1]。文本分类作为自然语言处理的基本任务,能够为舆情分析、情感分析、个性化推荐等下游应用服务。因此,如何高效、精确地对短文本进行分类已经成为自然语言处理领域的难点与重点[2]。
针对文本长度长短不一和特征提取困难的问题,文献[3]提出了一种基于LDA和深度学习的文本分类方法,但LDA更加适用于长文本。针对短文本存在高维和特征稀疏的问题,文献[4]在短文本分类方法中,采用BTM挖掘潜在主题信息,充分考虑短文本特征,有效缓解了语义模糊的问题。
为充分提取短文本语义信息,文献[5]提出了融合词向量及BTM的分类方法BTM&Word2Vec,文献[6]提出了一种基于BTM和Doc2Vec的分类方法BTM&Doc2Vec,上述文献均采用主题模型和潜在特征向量模型对语料库进行建模,向量拼接后输入到SVM实现短文本分类。
针对Word2Vec与Doc2Vec模型在进行文本向量表示时,存在无法解决一词多义的问题,文献[7-9]提出了一种基于BERT的短文本分类方法,提高了中文短文本分类精度和鲁棒性。
综上所述,本文结合BTM和BERT模型优势,提出一种融合BTM和BERT的短文本分类方法。分别采用BTM和BERT模型对预处理后的短文本集建模,提取文本主题特征信息和上下文语义信息,构建短文本特征向量,以增强语义表征能力,从而提高短文本分类精度。
1 相关技术
1.1 BTM模型
LDA和PLSA等传统主题模型通过获取词语的共现信息来表示文本级的潜在主题,但在处理短文本时,存在严重的特征稀疏问题。而BTM模型通过对整个语料库的词对建模来提高主题学习的能力,有效克服了短文本特征稀疏的问题,较传统主题模型能够更好地理解短文本主题信息。BTM图模型[4]如图1所示,其符号含义见表1。

图1 BTM图模型

表1 BTM符号及其含义
假设Multi()表示多项分布,Dir()表示Dirichlet分布,则对于整个语料库中的词对,BTM建模过程如下[10]:
(1)对整个语料库,采样一个主题分布θ~Dir(α);
(2)对每一个主题z∈[1,K], 采样主题-词分布φz~Dir(β);
(3)对每一词对b=(wi,wj), 采样一个主题z~Multi(θ), 从采样到的主题z中随机抽取两个词wi、wj组成词对b=(wi,wj)~Multi(φz)。
1.2 BERT模型
Word2Vec、GloVe作为词嵌入模型只能获得静态的和上下文无关的词向量,不能很好地表示不同上下文中词的语义[11]。而BERT[12]基于双向Transformer 结构生成上下文感知的动态词向量,能够更好地表示上下文语义信息[13]。BERT模型结构[14]如图2所示。

图2 BERT模型结构
图2中,E1、E2、E3、…、En表示短文本中的字符,Trm表示Transformer编码器,T1、T2、T3、…、Tn表示经过双向Transformer编码器后,获得的字向量。
2 BTM&BERT方法
融合BTM和BERT的短文本分类方法BTM&BERT流程如图3所示。首先,对短文本进行预处理;其次,采用BTM对预处理后的短文本集进行建模,获得K维主题向量;再次,采用BERT模型对预处理后的短文本集进行建模,获得句子级别的Q维特征向量;最后,将BTM与BERT建模获得的特征向量进行拼接,获得K+Q维短文本特征向量,输入到Softmax分类器,获得分类结果。
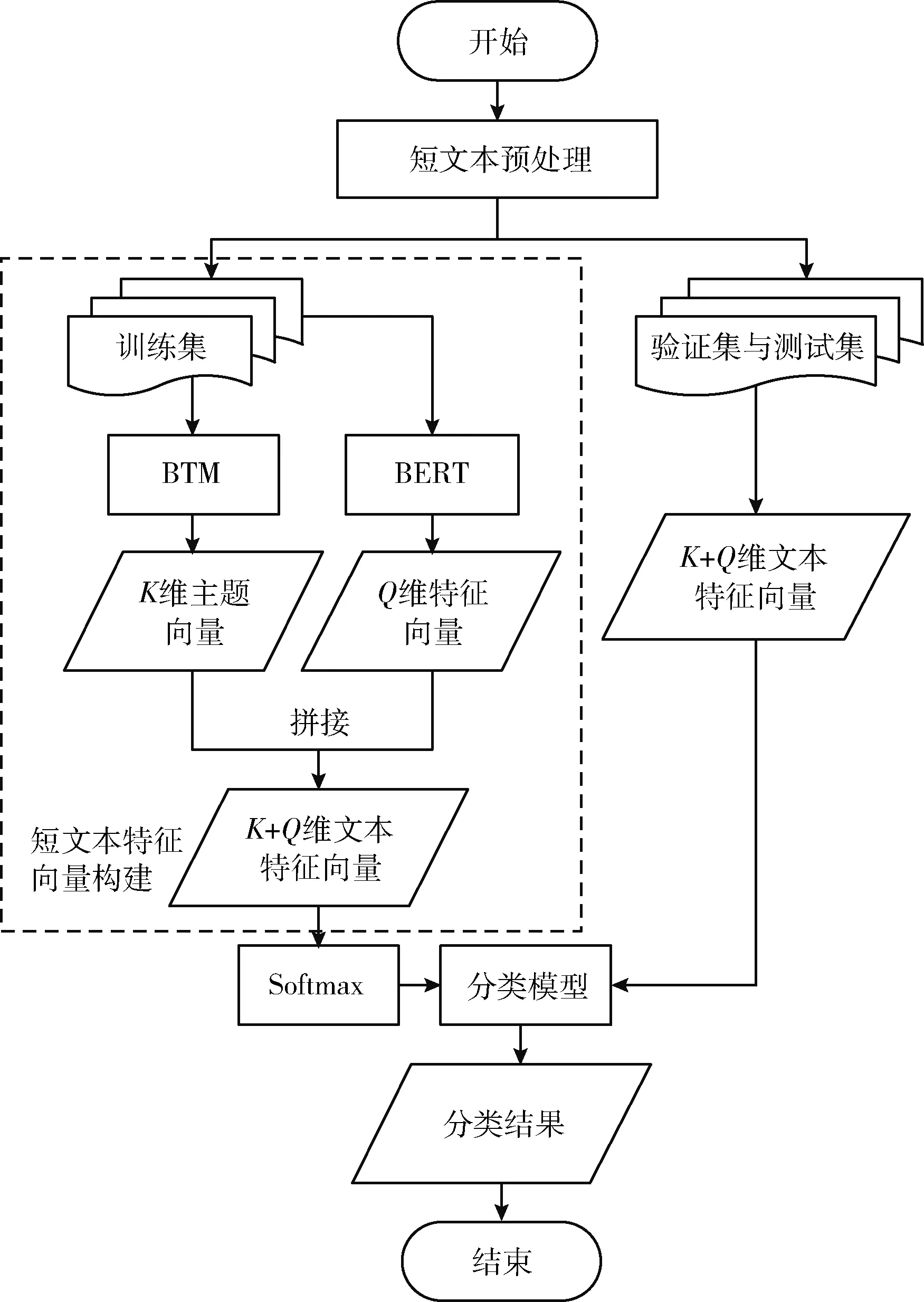
图3 BTM&BERT流程
2.1 短文本预处理
原始语料库数据,包含了很多无用信息,如符号、户号等,需要对原始语料库进行预处理来获取比较规范的数据集。短文本预处理主要包括清洗过滤、分词、去停用词三部分。
第一部分:对短文本进行清洗过滤,以电力工单短文本为例,删除“[”、“]”、“客户×××来电反映”、“请尽快核实处理”等无意义的符号和语句,以此来减少数据噪声,另外,过滤少于10个字符的超短文本,以及多于128个字符的长文本;
第二部分:基于jieba采用树结构查找速度较快的优势,以及较好地解决了过多的形容词和副词对计算概率与句子切分的影响[15]。因此,本文采用jieba分词工具对短文本进行分词,在分词模块中加入停用词表和自定义词表,使分词更加的精确;
第三部分:对短文本进行去停用词处理,删除诸如“同时”、“的”、“现在”、“今天”、“一直”等意义不大的词汇,减少文本的冗余度。
2.2 短文本特征向量构建
短文本特征向量构建主要包含3部分内容。首先,采用BTM对预处理后的短文本集进行建模,获得K维主题向量;然后,采用BERT模型对预处理后的短文本集进行建模,获得句子级别的Q维特征向量;最后,将BTM与BERT建模获得的向量进行拼接,获得K+Q维短文本特征向量。
2.2.1 BTM建模
BTM从文本的潜在语义方向建模,能够有效解决TF-IDF、TF-IWF等统计方法忽略语义信息的问题。似于LDA,θ和φ是BTM主题模型中的隐含变量,因此需要从语料库中的观察变量词项来估计参数θ和φ,本文采用吉布斯抽样(Gibbs sampling)方法进行推断,得到每个词对b=(wi,wj) 的条件概率为
(1)
式中:z-b表示除了词b以外的所有其它词对的主题分配,B表示数据集中的词对集,cz表示词对b被分配给主题z的次数,cw|z表示词w被分配给主题z的次数,W为词汇表大小。
根据经验,取α=50/K,β=0.01。 最终估计出主题分布θz、 主题-词分布φw|z和文本-主题概率P(z|d)。θz和φw|z公式请参见文献[16],P(z|d) 公式如下

(2)
式中:cd(b)表示文本d中包含词对b的次数。
在获得文本-主题概率P(z|d) 之后,选取每篇文本的文本-主题概率值P(z|d) 作为文本主题特征,获得主题向量集dBTM={d1_BTM,d2_BTM,…,dn_BTM}, 其中,第n篇短文本主题向量可以表示为dn_BTM={p(z1|dn),p(z2|dn),…,p(zK|dn)}。
2.2.2 BERT建模
采用输出句子级别向量的方式,即BERT模型输出最左边[CLS]特殊符号的向量,该符号对应的输出向量作为整篇文本的语义表示。BERT模型输出[17]如图4所示。

图4 BERT模型输出
如图4所示,[CLS]和[SEP]是BERT模型自动添加的句子开头和结尾的表示符号,假设有某篇短文本s=[申请用电服务查询密码重置], 将其按照字粒度进行分字后可表示为s=[申、请、用、电、服、务、查、询、密、码、重、置], 经Word Embedding之后,得到s对应的字嵌入矩阵A=[a1,a2,a3,…,a12]T, 其中a12是对应“置”的向量表示,假设字向量维度为k, 则A是一个12*k的矩阵。然后,构建Q-Query、K-Key、V-Value这3个矩阵,分别来建立当前字与其它字的关系,并生成特征向量。其中,Q=AWQ、K=AWK、V=AWV。 接着,进行多头自注意力计算,计算公式为
(3)
MultiHead(Q,K,V)=Concat(head1,head2,…,headh)WO
(4)
(5)

最后,将MultiHead与最初输入的文本序列进行残差连接,最终得到句子级别特征向量。
2.2.3 短文本特征向量拼接
将BTM建模获得的文本特征向量集dBTM={d1_BTM,d2_BTM,…,dn_BTM} 与BERT建模获得的句子级别文本特征向量集dBERT={v1,v2,…,vn} 进行对应拼接,获得最终短文本特征向量集dBTM+BERT={d1_BTM+v1,d2_BTM+v2,…,dn_BTM+vn}, 其中第n篇短文本特征向量可以表示为dn_BTM+BERT={p(z1|dn),p(z2|dn),…,p(zK|dn),vn}。
2.3 Softmax分类
在获得短文本特征向量集之后,采用Softmax回归模型对短文本进行分类。假设有训练样本集 {(x1,y1),(x2,y2),(x3,y3),…,(xn,yn)}, 其中xn表示第n个训练样本对应的短文本特征向量,共n个训练样本,yn∈{1,2,…,m} 表示第n个训练样本对应的类别,m为类别个数,本文中m=4。
给定测试短文本特征向量x,通过Softmax回归模型的判别函数hθ(x) 计算给定样本x属于第j个类别的概率,输出一个m维向量,每一维表示当前样本属于当前类别的概率,出现概率最大的类别即为当前样本x所属的类别。Softmax 回归模型的判别函数hθ(x) 为
(6)

(7)
通过判别函数hθ(x), 即可以实现短文本数据预测分类。
融合BTM和BERT的短文本分类方法(BTM&BERT)如算法1所示。
算法1: BTM&BERT
输入:D={(d1,y1),(d2,y2),…,(dn,yn)}、Niter=1000、K、α=50/K、β=0.01
输出: 短文本分类模型BB_model
(1) 对短文本集D进行预处理
(2) 为所有词对随机分配初始主题
(3) foriter=1 toNiterdo
(4) forbi∈Bdo
(5) 为每一个词对分配主题zb
(6) 更新cz、cwi|z、cwj|z
(7) End for
(8) End for
(9) 计算主题分布θz和主题-词分布φw|z
(10) 根据式(2)计算文本-主题概率P(z|d), 获得主题向量集dBTM={d1_BTM,d2_BTM,…,dn_BTM}
(11) 采用BERT预训练模型对预处理后的短文本集进行建模, 获得句子级别的特征向量集dBERT={v1,v2,…,vn}
(12) 对文本向量集dBTM和dBERT进行拼接, 获得短文本特征向量集dBTM+BERT
(13) 将短文本向量集dBTM+BERT输入到Softmax 回归模型进行训练
(14) 输出短文本分类模型BB_model
3 实验结果与分析
3.1 实验环境及数据
本实验的环境为:操作系统为64位Win10家庭版,处理器为Intel Core(TM) i5-9300H,RAM为16 GB,语言环境为Python3.6,BTM建模环境为Ubuntu 16.04,BERT建模环境为tensorflow 1.14。

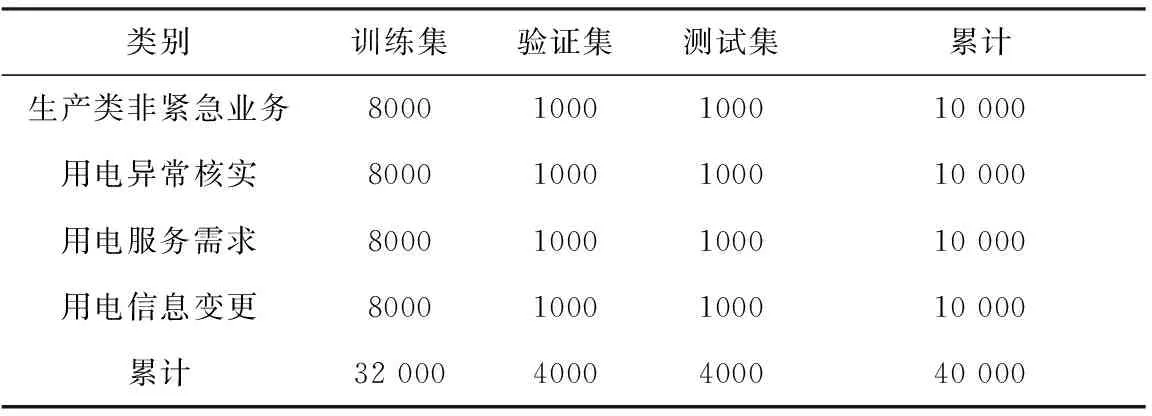
表2 实验数据具体分布情况
实验数据(部分)见表3。

表3 实验数据(部分)
3.2 评价指标
本文采用Precision(精确率)、Recall(召回率)和F1-measure(F1值)3个指标对提出的BTM&BERT方法进行有效性分析。对应的混淆矩阵见表4,3个指标的计算公式如下所示

表4 分类结果的混淆矩阵
(8)
(9)
(10)
3.3 与其它短文本分类方法的比较
采用Google提供的BERT-Base模型进行训练,BERT模型的网络结构为12层,隐藏层为768维,注意力机制采用12头模式,采用Adam优化器,学习率为0.001,dro-pout 为0.1。由于主题数目K值的选取会直接影响BTM的性能,所以本文在主题数目K值上进行了实验,在BTM建模时,根据语料库类别数,设置K=4,9,14 (以5为间隔),分析在不同K值下,对本文所提出的方法的影响。在不同K值下,本文提出的BTM&BERT方法在生产类非紧急业务、用电服务需求、用电异常核实、用电信息变更4个类别下的Precision、Recall和F1-measure结果见表5~表7。

表5 BTM&BERT在各个类别下的分类结果(K=4)

表6 BTM&BERT在各个类别下的分类结果(K=9)
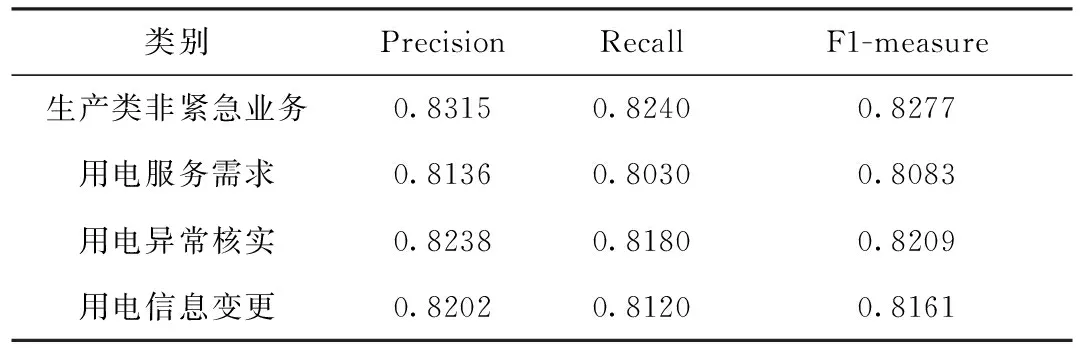
表7 BTM&BERT在各个类别下的分类结果(K=14)
从表5~表7可以看出,在不同K值下,本文提出的BTM&BERT方法在各个类别下的Precision、Recall和F1-measure虽然有小幅度变化,但其分值均能达到0.8,表明主题数目K值对分类效果有一定地影响,但还是能够对电力工单短文本进行较高精度的分类,在以后的工作中,可以考虑利用困惑度(Perplexity)[18]或者主题连贯性(Topic Coherence)[19]等方法优先确定最优主题数目K值,进一步提高短文本分类效果。
为了验证BTM&BERT方法在分类精度上的优势,本文将BTM&BERT方法与基于BTM的分类方法(BTM)、基于BERT的分类方法(BERT)、融合词向量及BTM模型的分类方法(BTM&Word2Vec)以及基于BTM和Doc2Vec的分类方法(BTM&Doc2Vec)进行对比实验。5种方法对应的Precision、Recall和F1-measure见表8~表10。

表8 5种方法对比实验结果(K=4)
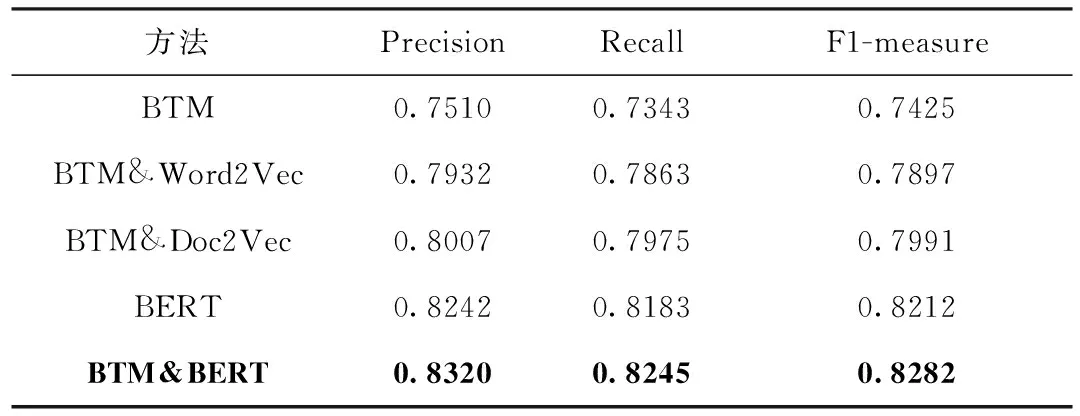
表9 5种方法对比实验结果(K=9)
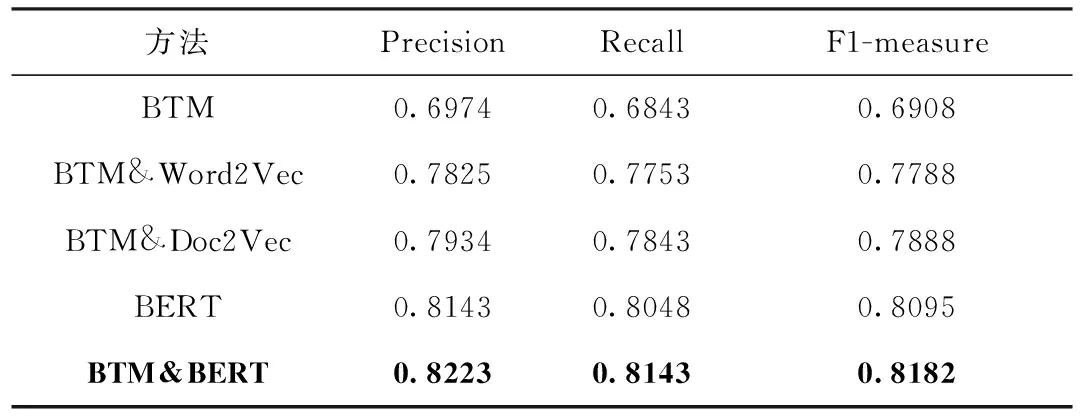
表10 5种方法对比实验结果(K=14)
在不同K值下,各个类别下对应的F1-measure比较结果如图5~图7所示。
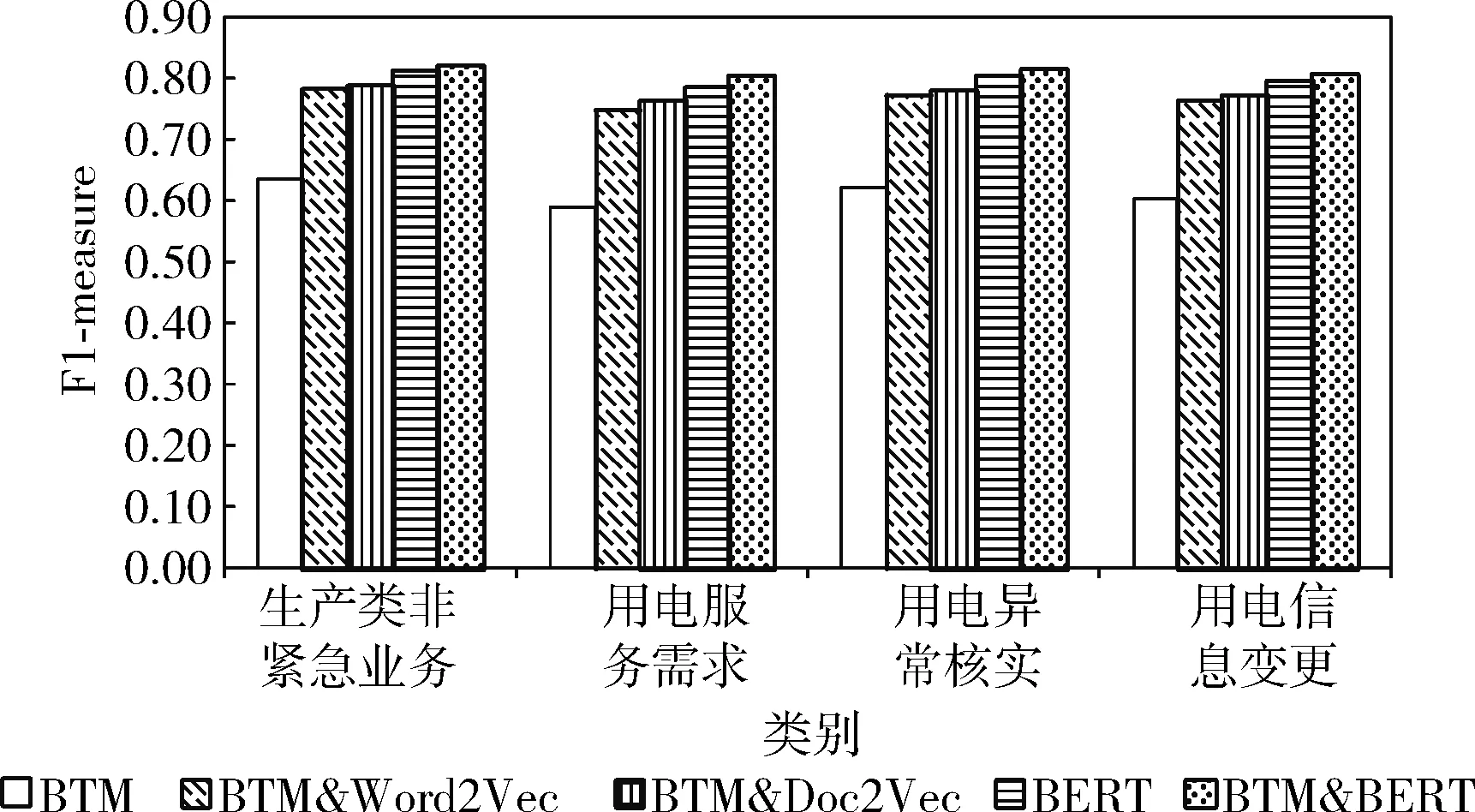
图5 各个类别下对应的F1-measure比较(K=4)

图6 各个类别下对应的F1-measure比较(K=9)
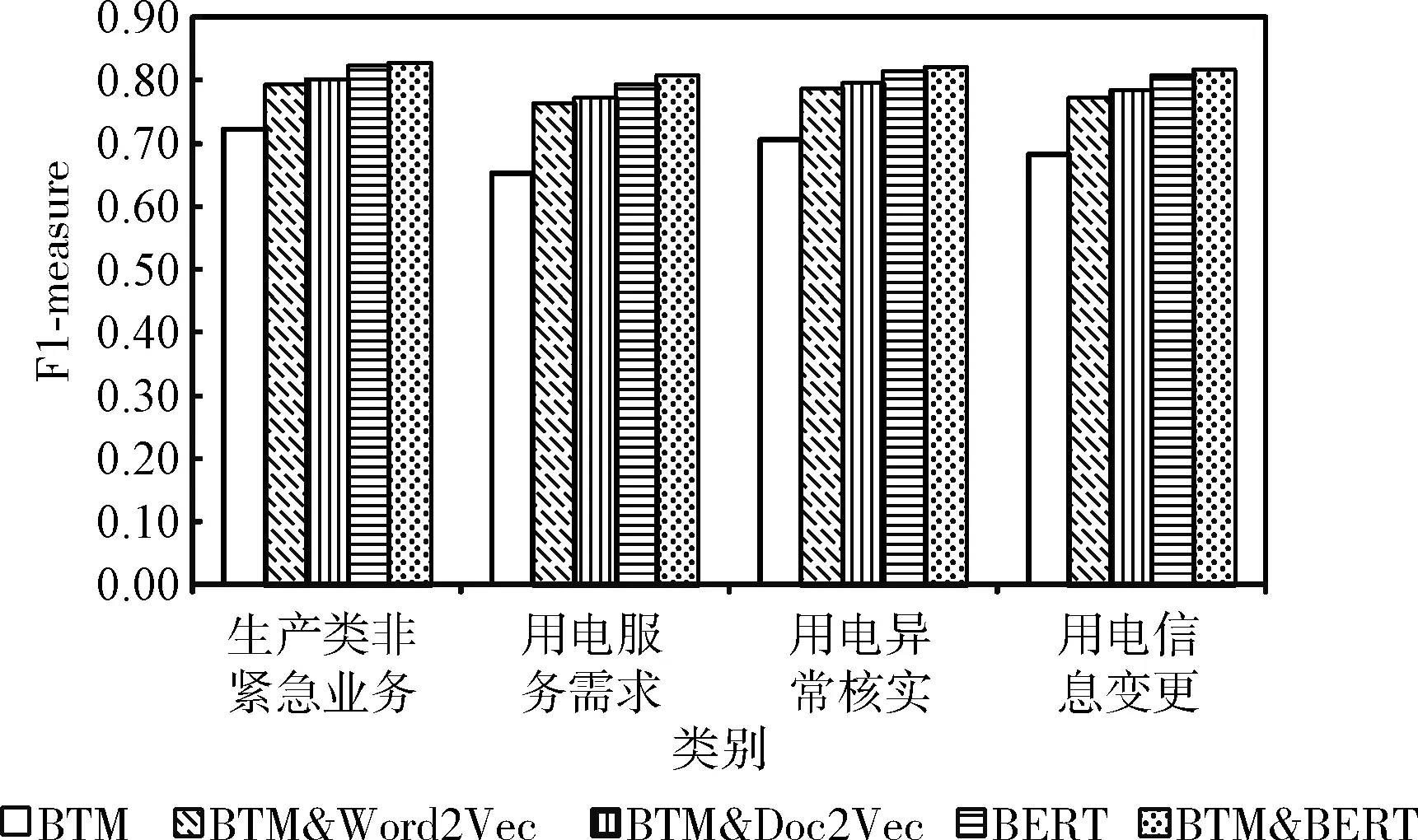
图7 各个类别下对应的F1-measure比较(K=14)
从表8~表10以及图5~图7可以看出,与其它4种分类方法相比,本文提出的BTM&BERT方法在分类精度上取得了更好的效果。其中,对于BTM方法,提取文本主题特征来表示整体文本信息,无法准确全面地表示文本,分类精度最低;对于BTM&Word2Vec方法,利用BTM扩充Word2Vec文本向量,有效解决文本稀疏性问题,分类精度高于BTM方法,但利用Word2Vec表示文本向量无法解决一词多义和文本语序的问题;对于BTM&Doc2Vec方法,有效解决了文本语序的问题,分类精度高于BTM&Word2Vec方法,但仍没有解决一词多义的问题;对于BERT方法,融合了字向量、文本向量和位置向量,该方法具有较强的文本表征能力,分类精度高于BTM、BTM&Word2Vec和BTM&Doc2Vec方法;对于本文提出的BTM&BERT方法,结合BTM和BERT的优势,充分考虑文本上下文语义信息,并融合文本主题特征信息来丰富文本语义信息,分类精度高于BTM、BTM&Word2Vec、BTM&Doc2Vec和BERT这4种方法。
4 结束语
针对短文本特性,在BTM能够有效解决短文本特征稀疏以及较高精度提取主题特征信息的基础上,结合BERT预训练语言模型强大表义能力的优势,提出了一种融合BTM和BERT的短文本分类方法,并应用到电力工单短文本中。首先,对电力工单短文本集进行清洗过滤、分词和去停用词预处理操作;其次,采用BTM对预处理后的电力工单短文本集建模,获得K维主题向量;再次,采用BERT对预处理后的电力工单短文本集建模,获得句子级别的Q维特征向量;最后,将BTM与BERT获得的特征向量进行拼接,获得K+Q维文本特征向量,输入到Softmax分类器,获得电力工单短文本分类结果。实验结果表明,BTM&BERT方法与BTM、BTM&Word2Vec、BTM&Doc2Vec以及BERT方法相比,在精确率、召回率以及F1值3个指标上,对电力工单短文本分类任务表现出更优效果,有效提高了电力工单短文本分类精度。在今后工作中,将对BTM进行优化,提高短文本主题特征信息提取精度,以进一步提高短文本分类性能。
