融合项目类别信息的非侵入式嵌入序列推荐
2022-12-30孙克雷宁昱霖周华平
孙克雷,宁昱霖,周华平
(安徽理工大学 计算机科学与工程学院,安徽 淮南 232001)
0 引 言
序列推荐模型通过提取用户与项目交互序列中项目之间的关联性捕捉用户偏好特征的动态变化[1]。早期的序列推荐模型采用可以处理序列信息的马尔可夫链模型,随着深度学习在人工智能领域大放异彩,推荐系统领域也受益颇多。基于循环神经网络、卷积神经网络以及自注意力机制的序列推荐模型先后被提出,其中基于自注意力机制的序列推荐模型是当今序列推荐领域研究的热点[2,3]。尽管基于自注意力机制的序列推荐模型已取得了优异的成绩,但仍存在着一定程度的问题,大量的文献证实了在自注意力机制中直接把辅助信息与项目序列的嵌入表征相加会导致信息过载,通常只会带来负面的影响[2,4]。信息过载指的是由辅助信息的嵌入表征与项目序列的嵌入表征直接相加改变了项目序列嵌入表征原有的特征表达,从而引入噪声[4]。由于存在数据稀疏问题,如果自注意力网络的输入只有项目序列的嵌入表征,那么模型会因为数据集提供的信息量过少无法支持网络中大量参数的更新导致推荐精度不佳。因此,本文提出了一种有效缓解网络信息过载的非侵入式嵌入自注意力网络并且在网络中引入了项目的类别信息,以缓解数据稀疏问题。实验结果表明,本文提出的模型可以有效地缓解自注意力网络的信息过载问题以及数据稀疏问题,其评估指标优于近期所提出的基于自注意力机制的序列推荐模型。
1 相关工作
近年来,深度学习受到人工智能各个领域研究人员的青睐,推荐系统领域也不例外。随着DIN[5]、DIEN[6]等基于深度学习的推荐模型接二连三地被提出,推荐系统全面进入深度学习时代。与传统的机器学习模型相比,基于深度学习的推荐模型能够挖掘出数据中更深层次的信息,并且模型结构非常灵活,可以根据不同的数据或不同的应用场景灵活调整模型[7]。
序列推荐早期通常利用马尔可夫链模型从用户与项目的交互历史中捕获用户偏好的转变。进入深度学习时代后,循环神经网络首先被应用到序列推荐模型中,基于循环神经网络的序列推荐模型通过一个隐藏状态总结用户所有的历史行为,然后将这个隐藏状态用于预测下一个行为。Tang等[8]基于卷积神经网络提出了Caser模型,该模型把用户与项目交互序列的嵌入表征看成一张图片矩阵,使用竖直和水平两个方向的卷积核提取序列特征。近年来,自然语言处理领域的序列数据处理技术——自注意力机制在序列推荐领域得到了广泛的应用。Kang等[2]等根据自然语言处理中的Transformer模型[9]提出了SASRec模型,该模型将自注意力机制应用在推荐任务里,成为了当时的SOTA(state of the art)模型。随后,越来越多的SASRec模型的变体被应用到序列推荐任务中,如Li等[10]提出的TiSASRec模型,该模型在SASRec的基础上融合了序列中项目之间的时间间隔信息,又如Wu等[11]提出的SSE-PT模型,该模型在SASRec的基础上引用了一种新型正则化技术——Stochastic shared embeddings[12]。
尽管上述基于自注意力机制的序列推荐模型已取得良好的效果,但均没有解决自注意力网络存在的信息过载问题。由于它们皆引入了项目的绝对位置信息,而绝对位置信息的嵌入表征作为辅助信息的一种,直接与项目的嵌入表征相加会导致信息过载从而引入噪声。接下来通过公式证明将辅助信息的嵌入表征与项目序列的嵌入表征相加会导致信息过载从而引入噪声。例如在自注意力机制计算项目i与项目j之间的相关性时引入绝对位置信息, (Ei+Pi)(Ej+Pj)T=EiEj+EiPj+PiEj+PiPj,E代表项目的嵌入表征、P代表绝对位置信息的嵌入表征[4]。其中EiPj、PiEj分别是项目i与项目j的位置的点积、项目i的位置与项目j的点积,由于这两部分的结果得不出任何相关性,因此,若辅助信息以直接相加的形式引入自注意力网络中只会增加噪声干扰模型捕捉项目之间的联系,并且以此方式引入辅助信息的种类越多,产生的无关项就越多,引入的噪声也就越多。虽然TiSASRec的作者意识到了数据稀疏问题,在模型中引入了项目之间的时间间隔信息,但他将时间间隔的嵌入表征直接与项目嵌入表征相加导致信息过载,因此,对模型的提升不大。对此,本文提出的NIESR模型通过使用多个自注意力机制提取不同种类的输入信息以解决上述因直接把各种嵌入表征直接相加造成的问题,并引入项目类别信息缓解数据稀疏问题。
2 融合项目类别信息的非侵入式嵌入序列推荐框架
NIESR模型框架如图1所示,模型从项目序列信息、项目的绝对位置信息、项目的类别信息3个角度提取用户与项目交互信息的特征。模型可概括为:①嵌入层:将模型的输入转化成低维稠密的嵌入表征;②多标签类别信息拼接层:在提取项目类别信息的特征前对多标签类别信息的嵌入表征进行拼接处理并使用一个线性层调整拼接后嵌入表征的维度;③非侵入式自注意力机制模块:使用3个多头自注意力机制分别提取3种输入信息的线性特征;④偏好表征拼接层:对3个多头自注意力机制提取的用户偏好表征进行拼接,再通过线性层调整拼接后的用户偏好表征的维度;⑤前馈神经网络:赋予模型非线性处理能力,提取输入信息的非线性特征;⑥预测层:根据输出的用户偏好表征计算用户下一个可能感兴趣的项目。下文将仔细阐述模型各个部分的细节。
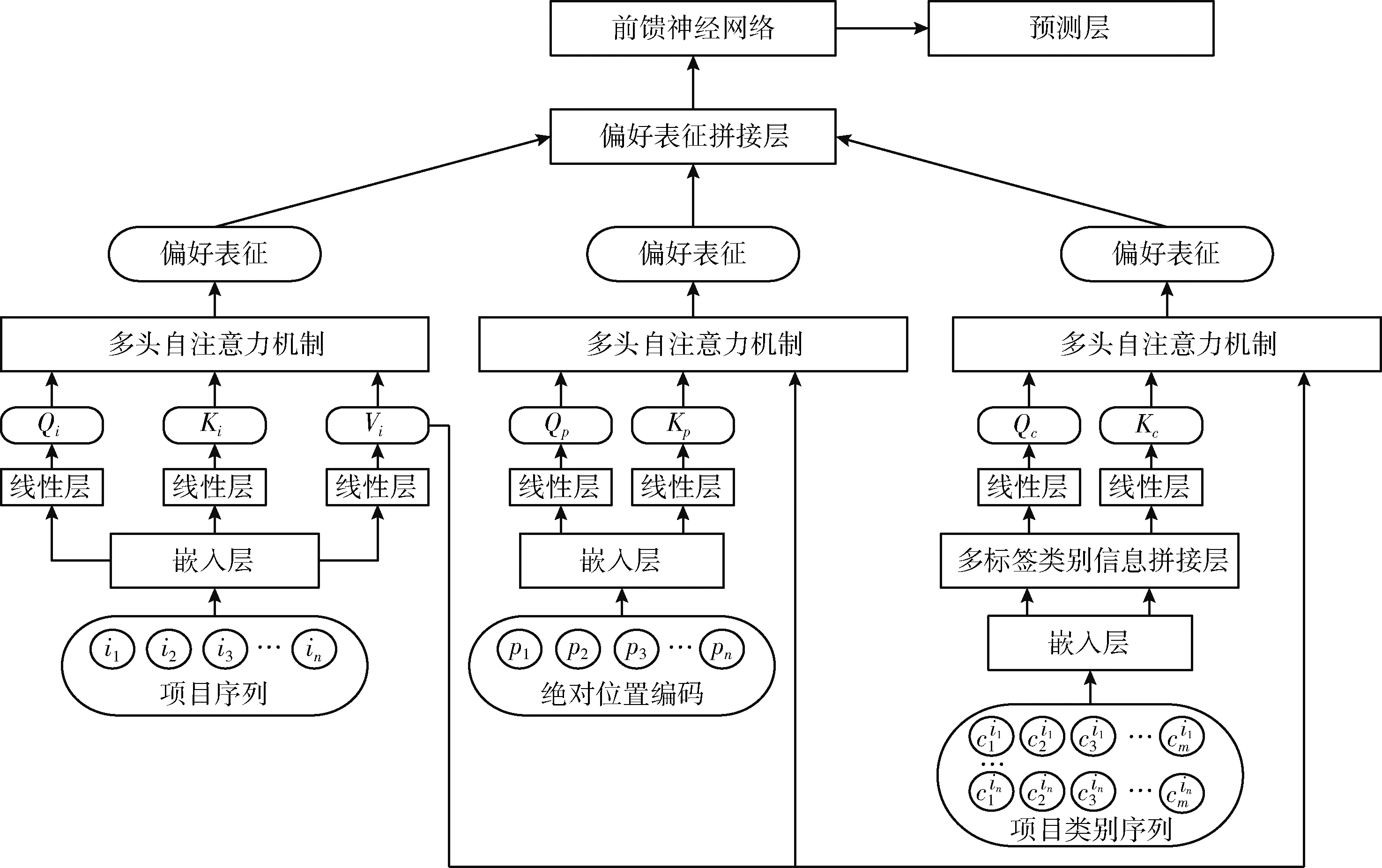
图1 NIESR模型框架
2.1 多标签离散型类别信息的处理
在真实世界中,项目的类别标签通常不是单值,例如电影《泰坦尼克号》的类别标签既是爱情片又是灾难片。爱情片和灾难片就属于多标签离散型类别。在本文提出的NIESR模型中,先把每个项目的类别标签转化成定长序列m,m等于数据集中拥有最多类别标签的项目的标签个数。类别标签长度不足m的项目在类别标签序列后填充0直至长度等于m,将类别标签转化为嵌入表征后,填充项0转化为零向量,对于多标签的处理方法采取拼接法,然后通过一个线性层调整嵌入维度的大小,使拼接后的嵌入表征的维度保持为单个嵌入表征的维度以保持维度的统一,保证模型中的残差连接以及多层自注意力机制的迭代可以顺利执行。而在线性层调整嵌入维度的大小时将高维稀疏的嵌入表征压缩成低维稠密的嵌入表征,相当于提取一次非线性特征。多标签离散型类别信息的嵌入表征拼接处理的实现步骤如图2所示。

图2 多标签离散型类别信息的处理
2.2 问题的定义

2.3 非侵入式自注意力网络
2.3.1 嵌入层
首先为项目字典创建嵌入表征查找表MI∈R|I|×d,d代表嵌入层的维度。将数据集中每个用户的交互序列转换成定长序列,设序列的长度为n,对数据集中长度大于n的序列进行截断操作,即从序列末尾往前取n个项目,对于长度小于n的序列进行填充操作,即在序列的头部添加填充项0,用零向量作为填充项的嵌入表征。通过检索嵌入表征查找表MI将每个用户交互序列转换成嵌入表征EI=[i1,i2,…,in]T,EI∈Rn×d。
由于自注意力机制无法获取项目的位置信息,因此,需要在自注意力网络中加入一个可学习的位置嵌入表征EP=[p1,p2,…,pn]T,EP∈Rn×d。
最后为项目类别字典创建嵌入表征查找表MC∈R|C|×d, 通过检索嵌入表征查找表MC找到每个序列中每个项目的类别嵌入表征,然后通过2.1节的方法进行处理,最终得到类别嵌入表征EC=[c1,c2,…,cn]T,EC∈Rn×d。
2.3.2 非侵入式自注意力机制
非侵入式自注意力机制即使用不同的多头自注意力机制处理不同类别的输入信息。根据嵌入层的3个输入序列EI、EP、EC,计算新的序列ZI=[z1,z2,…,zn]T,ZI∈Rn×d, 每个输出项zj都是由3个输入序列经过非侵入式自注意力机制后进行拼接再通过线性层转换维度后得到,这里使用的拼接法与类别标签的拼接方法及思想一致。
非侵入式自注意力机制(NISA)的输出O表示为

(1)
(2)
(3)
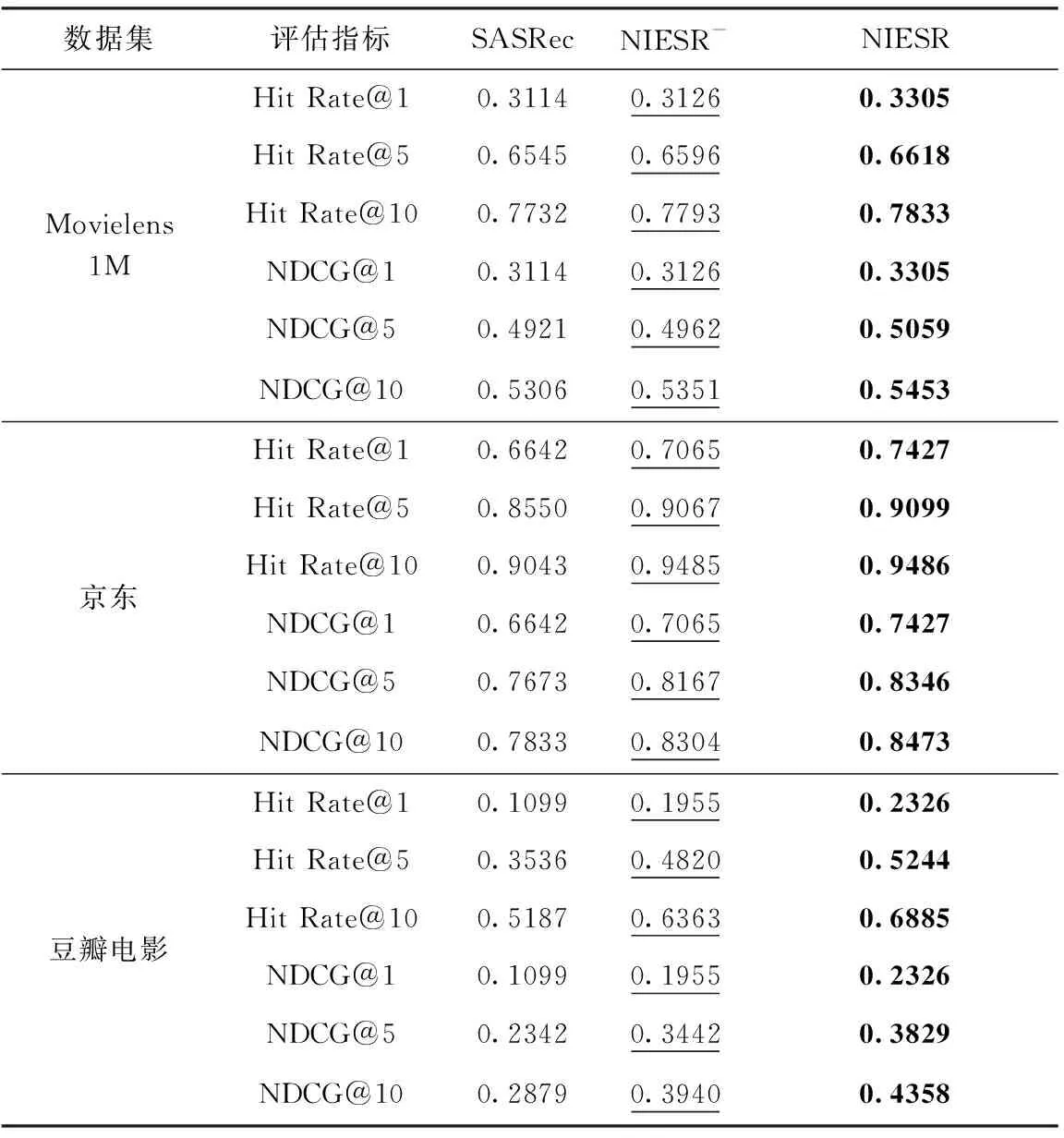
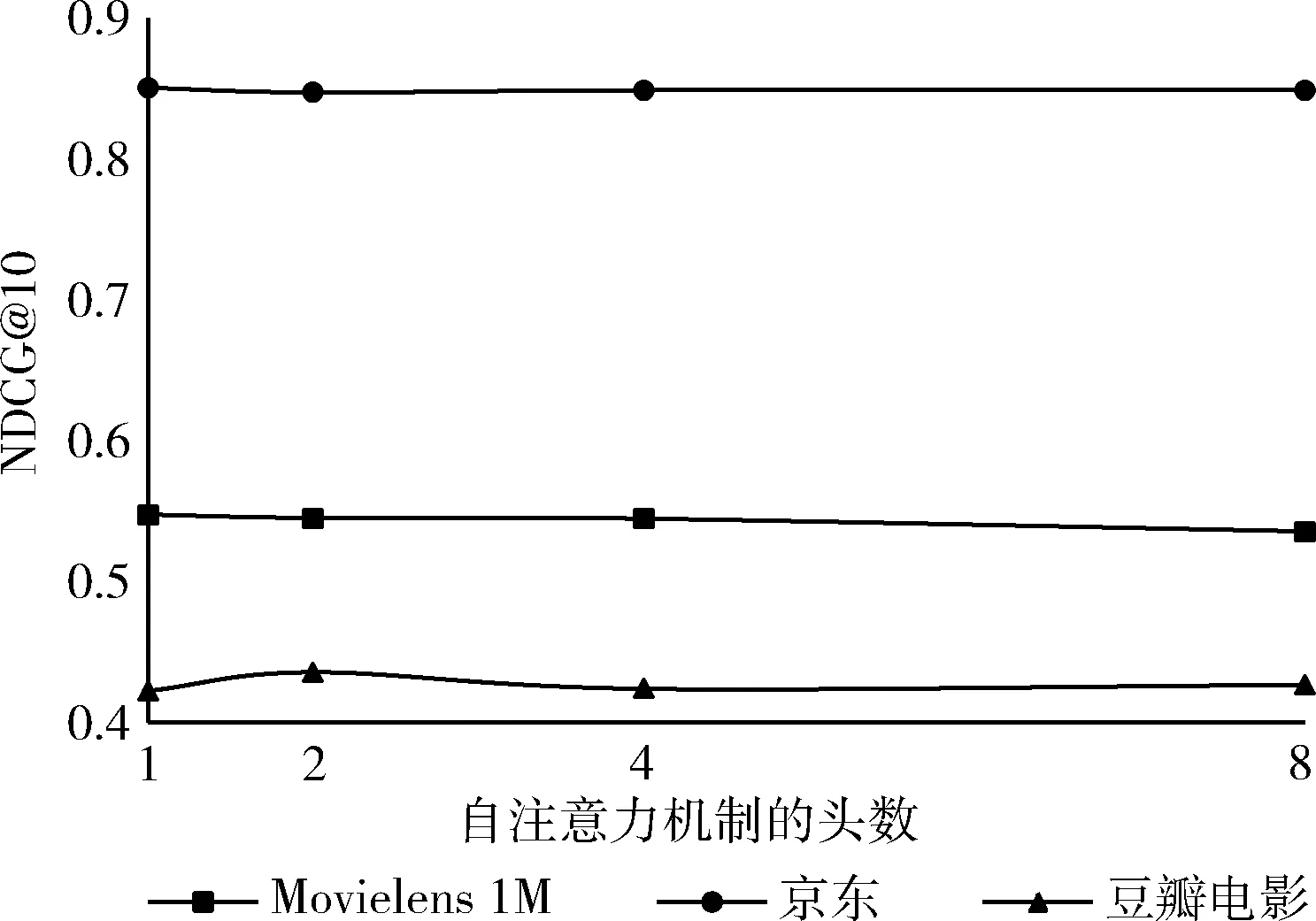
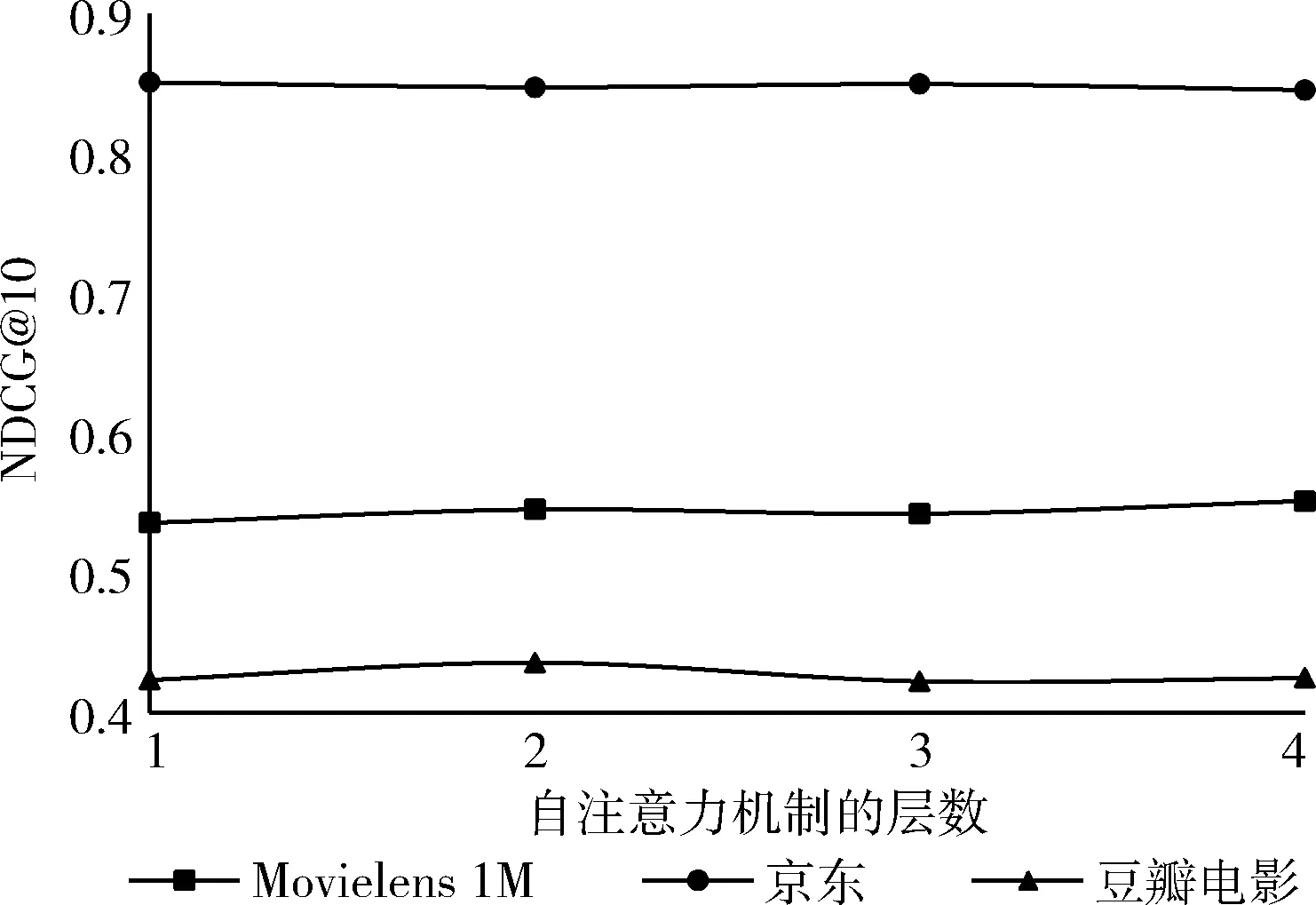
其中,FC代表调节拼接后嵌入层维度的线性层,⊙代表嵌入表征的拼接,h代表多头自注意力机制中头的数量,线性层W∈Rd×d。 为了防止自注意力机制未卜先知,在预测t+1项时,模型应只考虑前t项,因此,需要屏蔽所有Qm与Kn(m 2.3.3 前馈神经网络 非侵入式自注意力机制本质上是个线性模型,为了提取输入信息的非线性特征在非侵入式自注意力机制后添加一个前馈神经网络,为了防止模型过拟合以及训练不稳定,引入了残差连接、Dropout、层规范化来解决,其输出F如下 (4) O′=LayerNorm(QI+QP+QC+Dropout(O)) (5) LeakyReLU激活函数可以在反向传播过程中让输入小于零的部分也可以计算得到梯度,而不是像ReLU激活函数一样将输入小于零的部分置0。前馈神经网络中每层参数W和b互相独立[13]。 2.3.4 多层非侵入式自注意力机制模块 在第一层非侵入式自注意力机制模块输出后,模型可能没有充分挖掘输入信息。为进一步挖掘输入信息,将第一层模块的输出输入到第二层非侵入式自注意力机制模块中,以此类推。第b层(b>1)模块的输出定义如下 ZI=F(b)=FFN(O(b)) (6) O(b)=NISA(F(b-1)) (7) 其中,O(1)=O, 递归传入NISA的张量替换模型的输入EI,EP和EC共享整个多层非侵入式自注意力机制模块。 2.3.5 预测层 在多层非侵入式自注意力机制模块输出之后可以得到项目序列信息、项目绝对位置信息和项目对应的类别信息的组合表示。为了预测第t+1个项目,使用潜因子模型来计算用户对项目i的偏好分数,其定义如下 (8) 模型的目标是提供一个排序后的项目列表。本文采用负采样优化项目的排名,对于每个预期的正输出oi都生成一个负样本o′i∉Su。 损失函数采用二元交叉熵函数 (9) 为了验证本文提出模型的推荐效果,选择3个真实场景中的数据集进行验证: (1)Movielens 1M数据集:广泛用于推荐算法的数据集,包含约6千名用户对约4千部电影的100万条评分数据。 (2)京东数据集:由京东竞赛公开,记录了2016年2月至4月用户的行为信息。本文选取了2016年2月的数据进行实验,包含大约7万名用户对2万个项目的455万条行为信息,行为信息包括浏览、加入购物车、购物车删除、下单、关注、点击。在本文实验中只选取行为信息中用户浏览的部分。 (3)豆瓣影评数据集:本数据集采集于豆瓣电影,包含大约60万个用户对大约7万部电影的400万条评分数据。 以上数据集均包含用户与项目交互的时间戳,在数据预处理后将每个用户的交互序列根据时间戳升序排序。在构建训练集、验证集和测试集时,删除序列长度小于3的序列,以序列倒数第二个项目作为验证集,末尾的项目作为测试集,剩下的数据作为训练集。清洗后数据集的基本信息见表1。 表1 数据集的基本信息 由于模型会给用户提供一个排序后的项目列表,因此,本文选取2个Top-N推荐评估指标,Hit Rate@N以及NDCG@N,以评估模型推荐的质量。Hit Rate@N用于计算推荐成功的用户在所有用户中的占比,用户下一个感兴趣的项目出现在推荐列表的前N项中则代表推荐成功。NDCG@N考虑了用户下一个感兴趣的项目在推荐列表的前N项中的排名,排名越靠前得到的分值越高。对于每个用户模型会随机选取100个未在该用户序列中出现的负样本,根据这101个项目计算Hit Rate@N和NDCG@N。 Hit Rate@N计算如下所示 (10) 式中:UT代表推荐成功用户,U代表所有参与计算的用户。 NDCG@N计算如下所示 (11) 式中:r(i) 代表推荐列表中排在第i位的项目与需要推荐的正样本的相关性分数。若排在第i位的项目为正样本,r(i) 为1;反之,r(i) 为0。 为验证本文提出模型的有效性,将模型与以下基于自注意力机制的序列推荐模型进行对比: (1)SASRec[2]:首个基于自注意力机制的序列推荐模型。 (2)TiSASRec[10]:2020年提出的基于自注意力机制的序列推荐模型,在SASRec模型的基础上融合了序列中项目和项目之间的时间间隔信息。 (3)SSE-PT[11]:2020年提出的基于自注意力机制的序列推荐模型,在SASRec模型的基础上引入了一种新型的正则化技术SSE。 本节将在3个数据集上进行消融实验以测试非侵入式自注意力机制能否解决信息过载问题并测试加入项目类别信息能否缓解数据稀疏问题;分析本文提出的NIESR模型中一些主要超参数对于模型性能的影响;与3个对比模型的性能作比较;分析NIESR模型的时空复杂度。为保持实验公平性,除超参数对比实验外的实验,模型的超参数设置为默认超参数(见表2),在超参数对比实验中对默认超参数采取控制变量法,只改变一个超参数其它超参数不变。实验均在RTX2080Ti显卡上部署。 表2 默认超参数设置 3.4.1 消融实验 为验证本文提出的非侵入式自注意力机制能否解决信息过载问题,将删除NIESR模型输入的项目类别信息部分,并命名为NIESR-。NIESR-模型与基线模型SASRec有着相同的输入,区别在于SASRec模型直接将项目序列的绝对位置信息的嵌入表征与项目序列的嵌入表征直接相加,然后用多头自注意力机制提取特征,而NIESR-模型使用两个多头自注意力机制分别处理这两种输入信息,因此,将NIESR-模型与基线模型SASRec进行对比即可验证本文提出的非侵入式自注意力机制能否解决信息过载问题。NIESR-模型作为NIESR模型删去项目类别信息的版本,将它们的评估指标作对比即可验证在模型中融合项目类别信息能否缓解数据稀疏问题。模型的主要超参数设置为表2提供的默认超参数。实验结果见表3。其中最佳的评估指标将用加粗字体标注,次佳用下划线标注。 从表3可以看出,NIESR-模型的评估指标皆优于SASRec模型,验证了本文提出的非侵入式自注意力机制可以解决信息过载问题;NIESR模型的性能皆优于NIESR-模型,这说明引入项目类别信息的确可以缓解数据稀疏问题。其中对于Top-1指标的提升最大,这更能说明引入项目类别信息的重要性,因为序列推荐模型的任务就是给用户推荐下一个他可能会感兴趣的项目。 表3 消融实验 3.4.2 嵌入层维度对评估指标的影响 为衡量嵌入层维度对评估指标的影响,取嵌入层维度分别为8、16、32、64、128、256时评估指标NDCG@10的结果进行比较,如图3所示。 图3 嵌入层的维度对评估指标的影响 从图3可以看出,Movielens 1M数据集与京东数据集在嵌入层维度为128时趋近饱和,这在一定程度上表明了当本文提出的模型面对稠密数据集时,应分配高维度的嵌入层。相反,豆瓣电影数据集在嵌入层维度为32时达到了饱和,这在一定程度上表明当模型面对稀疏数据集时设置嵌入层维度不宜过大,否则会导致模型过度参数化[4],表现反而会更差。 3.4.3 序列长度对评估指标的影响 为衡量序列长度对评估指标的影响,取序列长度分别为10、25、50、100、200时评估指标NDCG@10的结果进行比较,如图4所示。 图4 序列长度对评估指标的影响 从图4可以看出,随着序列长度的增加本文提出的模型在3个数据集上的表现都是上升趋势,当序列长度低于序列平均长度时随着序列长度的增加评估指标的提高非常明显,当序列长度高于序列平均长度后评估指标的提高开始减缓并趋近于饱和。 3.4.4 自注意力机制的头数对评估指标的影响 为衡量自注意力机制的头数对评估指标的影响,取头数分别为1、2、4、8时评估指标NDCG@10的结果进行比较,如图5所示。 图5 自注意力机制的头数对评估指标的影响 Transformer模型的作者发现使用多头注意力机制可以提高模型性能,它将注意力分布于h个子空间,每个子空间包含d/h维嵌入表征,而在本文提出的模型中多头自注意力机制的头数对于模型的影响很小,可能是因为在Transformer模型中嵌入层维度d=512,而本文所提出的问题中所需的维度过小,不适合分解成更多的子空间。 3.4.5 自注意力机制的层数对评估指标的影响 为衡量自注意力机制的层数对评估指标的影响,取层数分别为1、2、3、4时评估指标NDCG@10的结果进行比较,如图6所示。 图6 自注意力机制的层数对评估指标的影响 多层堆叠的自注意力机制可以捕获数据集中更深层次的信息,如图6所示,自注意力机制的层数对于模型的影响很小,是因为一层自注意力机制已经可以捕获数据集中绝大多数的信息。 3.4.6 不同模型的实验结果对比 对比模型均以原文作者给出的原代码运行,在模型对比实验中所有模型的主要超参数都设置为表2的参数,表中未提及的超参数保持原代码的默认设置,实验结果对比见表4。 表4列出了NIESR模型与其它对比模型在Top-N=1、Top-N=5以及Top-N=10时的评估指标,其中最佳表现与次佳表现分别用粗体和下划线表示,提升率为次佳表现至最佳表现的提升。 从表4中可以看出NIESR模型在评估指标NDCG以及Hit Rate上均达到了最好的结果。NIESR在评估指标上的提升得益于模型在不造成信息过载的前提下融合了项目的类别信息,项目类别信息缓解了数据稀疏问题可以辅助模型更精确地捕捉项目之间的关联性。SASRec相比于NIESR推荐效果不佳的原因是SASRec不但存在着数据稀疏问题,而且在融入项目绝对位置信息时造成了信息过载。TiSASRec相比于NIESR推荐效果不佳的原因是TiSASRec虽然在SASRec模型的基础上融入了项目之间的时间间隔信息尝试解决数据稀疏问题,但是使用直接相加的形式造成了模型输入信息过载,导致模型对于SASRec的提升很小。SSE-PT相比于NIESR推荐效果不佳的原因是SSE-PT仅仅在正则化技术方面改善了SASRec,但是没有改善数据稀疏问题,因此,对于SASRec模型的提高不是很明显。通过表4还可以看出本文模型在数据集Movielens 1M和京东上的评估指标提升不够明显,因为在这两个数据集中用户与项目的平均交互长度较长,序列信息较为充分,导致增加项目类别信息对于模型捕捉项目之间的关联性的作用不明显,而本文模型在用户与项目的平均交互长度较短的豆瓣电影上的评估指标提高比较明显,因为序列较短,模型可以学习到的信息有限,增加项目类别信息缓解了数据稀疏问题。因此,评估指标的提升较为明显。 表4 3个数据集上不同模型的实验结果比较 3.4.7 时空复杂度分析 由于本文提出的NIESR模型是基于SASRec模型进行改进的,因此,在本节将NIESR模型与SASRec模型在时空复杂度的层面进行对比。 时间复杂度:本文提出的NIESR模型的时间复杂度主要受多标签类别信息拼接层、多头自注意力机制、偏好表征拼接层以及前馈神经网络的影响,因此,模型的时间复杂度可表示为O(nmd2+n2d+nld2+nd2), 其中m代表项目拥有的类别标签的最大个数,n代表序列的长度,l代表偏好表征拼接层拼接的偏好表征个数,d代表嵌入表征的维度。SASRec模型的时间复杂度可表示为O(n2d+nd2)。 接下来将对比这两个模型在3个数据集上训练的时间开销(1个epoch的训练时间)及测试的时间开销。实验结果见表5。 表5 时间开销对比 由表5可以看出,本文提出的NIESR模型训练所需的时间约为SASRec模型的1.5倍,测试时间约为SASRec模型的2倍,NIESR模型在时间开销上高于SASRec模型的部分主要在于两个调节嵌入表征拼接后大小的线性层,由于项目拥有的类别标签的最大个数m为常数且偏好表征拼接层拼接的偏好表征的个数l为常数3,通常情况下,m与l是小于n和d的,因此,NIESR模型的时间复杂度与SASRec模型的时间复杂度是同一个量级的。由于NIESR模型的评估指标相对于SASRec模型的提升是可观的,因此,NIESR模型的时间开销高于SASRec模型的部分是适度的。 空间复杂度:空间复杂度代表了在模型训练过程中需要学习的参数量。本文提出的NIESR模型需要学习的参数来自于嵌入表征以及嵌入表征拼接使用的线性层、多头自注意力机制、前馈神经网络和层规范化中的相关参数。NIESR模型与SASRec模型的参数量对比见表6。 表6 参数量对比 项目嵌入表征的参数量占整个模型训练过程中需要学习的参数量的主导地位,因此,在相同的数据集中,NIESR模型的参数量高于SASRec模型的部分仅在于类别信息的嵌入表征以及两个调节嵌入表征拼接后大小的线性层。因此参数量高于SASRec模型的部分可以忽略不计。 本文提出的融合项目类别信息的非侵入式嵌入序列推荐模型通过使用多个多头自注意力机制分别处理不同种类的输入信息,解决了在基于自注意力机制的推荐模型中融合辅助信息会造成信息过载的问题,并通过融合项目类别信息缓解了数据稀疏问题。经上述实验验证,在3个真实数据集上的评估指标相比几个近期提出的模型均得到了提升,但忽略了数据集中的用户画像信息,用户画像信息可以进一步改善数据稀疏问题。下一步工作将着手研究如何将用户画像信息与模型相融合,进一步缓解数据稀疏问题,提高模型的推荐性能。

2.4 损失函数

3 实 验
3.1 数据集概况

3.2 评估指标
3.3 对比模型
3.4 实验结果对比与分析






4 结束语
