含顺序类别自变量的中位数惩罚回归及应用研究
2022-12-25吉洋莹潘雨辰
吉洋莹,潘雨辰,黄 磊
(西南交通大学 数学学院, 成都 611756)
0 引言
统计研究时,数据往往存在多个变量。近几十年,关于变量选择方法的研究非常多。Akaike[1]提出AIC准则,有助于减少模型过拟合的风险。Schwarz[2]考虑了样本数量,提出了惩罚因子为log(n)的BIC准则。另外,在自变量越来越多的大数据时代下,其维度p甚至大于样本量n。在这种高维情况下,基于AIC、BIC及其扩展的子集选择方法将导致计算的负担和不可靠的结果。因此,统计学家又提出了许多针对高维环境下有用的变量选择方法。例如,Fan等[3]提出了SCAD(smoothly clipped absolute deviation)惩罚,SCAD既能连续地压缩系数,也能在系数较大时取得渐近无偏估计。Tibshirani[4]提出了最小绝对收缩选择算子(least absolute shrinkage and selection operator,LASSO),在最小二乘基础上添加l1惩罚得到稀疏模型。由于LASSO对回归系数使用相同程度的压缩,可能会造成估计不完全有效,模型选择结果不一致的现象。因此,Zou[5]改进LASSO并提出自适应LASSO方法,使回归系数有不同程度的压缩。自适应LASSO能够一致地识别真实模型且所得估计具有oracle性质。 除此以外,对于LASSO统计学家还做了不少拓展,针对具有组特征的数据结构,Yuan等[6]提出可从组角度进行变量选择的group-LASSO方法。Group-LASSO对一组系数向量添加约束,克服了LASSO无法从组水平进行变量选择的缺点。 Wang等[7]将Zou[5]和Yuan等[6]的思想加以结合修订,又提出了针对不同组系数施加不同惩罚的自适应group-LASSO方法。
统计建模中,回归用来量化因变量和自变量之间的关系。其中,最常见的参数估计方法是普通最小二乘法(ordinary least square,OLS)。最小二乘估计是一种基于均值回归的估计方法,在满足正态误差假设时具有良好的性质,如估计量具有无偏性和相合性。然而,当误差不满足高斯-马尔科夫假设条件,就有可能产生有偏的估计结果。若样本数据中存在异常值,模型估计值可能存在较大偏差[8]。另外,有时候不仅希望研究因变量的期望均值,还希望能探索因变量的全局分布。于是,Koenker和Bassett[9]提出分位数回归(quantile regression,QR)。分位数回归应用条件相对宽松,可以描述因变量的全局特征,也可以挖掘更为丰富的信息,另外分位数回归估计采用最小化加权误差绝对值和进行估计,通常不受异常值的影响,结果更为稳健。Yu等[10]总结了一些分位数回归典型的应用领域,分位数回归在医药与生存分析、金融与经济统计、环境分析等诸多领域得到应用。 Engle等[11]在经济中对于计算VaR,提出了一种类似广义自回归条件异方差形式的计算分位数的方法。刘军跃等[12]利用分位数回归法,从碳减排角度实证分析了长江经济带在不同碳排放水平下产业结构升级与碳排放的关系。此外,分位数回归还拓展到各种类型的数据中。例如,具有异方差误差项的数据、时间序列数据、删失数据等。
近年来,建立分位数回归和LASSO类型相结合的分位数惩罚回归的研究越来越广泛。Ciuperca[13]提出了含有组特征变量的分位数自适应group-LASSO。Wang等[14]结合中位数(least absolute deviation,LAD)回归和LASSO构建了LAD-LASSO。 LAD是分位数回归中τ=0.5的回归,LAD不受异常值的影响,结合正则化估计方法对高维数据进行变量选择,可以得到稳健的结果。最近,许多分位数回归方法的相关研究大多都集中在维数超过观测值的高维数据中,如Wu等[15],Wang等[16]研究了l1惩罚分位数回归模型,证明了LASSO惩罚分位数回归估计量的oracle性质。
旨在提出一种含有顺序类别自变量的高维回归方法。教育研究中,受教育水平可以分为小学、中学、大学、研究生教育[17]。患者的身体情况表现为严重损伤、轻微损伤、正常、非常好[18]。 这种具有顺序类别的自变量,通常按照被观测对象特征高低或大小依次赋值,将顺序类别自变量转换为哑变量形式。针对这类含有顺序类别自变量的模型,利用前面提到的分位数惩罚回归模型中的LAD-LASSO对模型进行选择,之后若直接对模型进行拟合,不可保证能消除掉组变量中的伪分类,即组内相邻变量系数相等。 直接进行模型拟合可能会造成过拟合的现象。为了避免发生过拟合, Walter等[19]提出顺序类别变量的编码方案,能够很好地解释系数估计,但依然存在过拟合和估计值不存在等问题。Gertheiss等[20]运用岭回归能够得到稳健的参数估计,但过拟合现象还是没有解决。之后,Tian等[21]提出哑变量线性变换方法(transformed dummies,TD),将TD与BIC方法结合提出TD-BIC方法检测伪分类。 Huang等[22]提出TD-LASSO方法,高维环境下采用LASSO较BIC更为容易。周晓霞等[23]将TD与机器学习相结合识别伪分类。晁越等[24]则是提出一种渐近相合的探测logistic回归模型中顺序多分类解释变量的LTD-BIC伪分类识别方法。又由于LASSO的无差别惩罚,采用自适应LASSO进行改进。因此,将TD与自适应LASSO相结合提出TD-ADLASSO,再与LAD回归相结合提出LAD-TD-ADLASSO识别伪分类。LAD-TD-ADLASSO既可以做参数估计还能识别伪分类,可以有效避免模型的过拟合风险,提高预测精度。
剩余部分安排如下:第1节详细介绍了TD和LAD-TD-ADLASSO伪分类识别与融合技术,并整理出一个系统性的可行算法;第2节通过2个实例,根据所提出的LAD-TD-ADLASSO伪分类识别与融合技术算法展示该方法的实用性和有效性;第3节进行总结和展望。
1 模型与方法
在本节中,介绍了具有顺序类别自变量的高维模型,并提出LAD-TD-ADLASSO算法。为了描述简便,在以下模型推导中仅考虑包含一个顺序类别自变量的回归模型,而实际问题中的模型可能包含多个顺序类别的自变量。考虑含有一个m分类的顺序类别自变量的线性模型:
Yi=α+β2X2,i+…+βmXm,i+
α1Z1,i+…+αkZk,i+εi,
i=1,2,…,N
(1)
式中:εi,i=1,…,N为随机误差。实际研究中,不光有顺序类别自变量,还有连续型变量,用{Z1,…,Zk}表示k个连续型变量。{X2,…,Xm}为相应的哑变量,m类别的顺序类别自变量将生成m-1个哑变量,哑变量定义如下:

(2)
将模型(1)改写成矩阵形式:
Y=Xβ+ε
(3)
式中:X为设计矩阵,X=(1,X2,…,Xm,Z1,…,Zk),并假定列是满秩的,Xj=(Xj,1,…,Xj,N)T,j=2,…,m。 连续型变量Zj=(Zj,1,…,Zj,N)T,j=1,…,k,因变量Y=(Y1,…,YN)T,回归系数β=(α,β2,…,βm,α1,…,αk)T。误差向量ε满足高斯-马尔科夫条件:
(ⅰ)E(ε)=0;
(ⅱ) Var(ε)=δ2I, Var(·)表示一个随机向量的协方差矩阵。
使用最小二乘来估计回归参数向量β,使得误差向量ε=Y-Xβ的平方和达到最小,得到参数向量β的无偏估计:
(4)
当误差项不满足高斯-马尔科夫条件时,使用最小二乘估计可能造成估计有偏。同时,最小二乘极易受异常值的影响,当样本中存在异常值,使用最小二乘的误差平方和可能产生较大偏差。而且,最小二乘确定的是自变量X取值x时,因变量Y的E(y|x),无法给出因变量的一个全局分布。因此,Koenker等[9]提出分位数回归,引入分位数回归替换最小二乘估计,分位数回归不对误差分布做任何假定,可以得到一种稳健性的参数估计方法。分位数回归使用最小化加权误差绝对值和进行参数估计,对异常值的影响较小。同时,分位数回归可以给出自变量X取值x时,因变量Y取值的各种τ分位数Qτ(y|x)下的回归拟合结果,即相应Y取值的各种分位点的估计。
给定X=x,因变量Y的累积条件分布函数为FY(y|X=x)=P(Y≤y|X=x)。因变量Y的τth分位数的分位数回归模型为:
Qτ(Y|X=x)=g(X,β)=xTβ(τ)
(5)

(6)
分位数回归不能像最小二乘估计(4)一样得到显式解,通常基于损失函数ρτ(μ),用数值算法对式(6)进行求解:

(7)
主要研究当τ=0.5时的LAD,LAD与分位数回归一样都具有对异常值不敏感,不对误差分布做假设等特点,并且能得到稳健的估计结果,其他τ分位点同理。
主要研究对含有顺序类别自变量的样本进行建模,对于这类样本建模时需要考虑伪分类的情况,避免模型因为存在伪分类发生过拟合现象。对于解决过拟合现象,可以通过正则化进行处理。Gertheiss等[20]曾提出对不含有连续型变量的模型,运用岭回归方法进行伪分类的识别:
(8)
顺序类别自变量为有序类别,设置第一个类别为基准类,定义β1=0,这样可以方便惩罚相邻类别之间的系数差异。 将相邻2类系数之差定义为Δβj=βj-βj-1。该方法实际上是使用l2惩罚的岭回归方法,但岭回归无法消除偏差,不能有效识别出伪分类,且没有考虑连续型变量,因此模型不具有可解释性。
之后,Huang等[22]提出TD-LASSO方法识别顺序类别自变量中的伪分类,主要思想是运用TD对系数进行惩罚。由于TD-LASSO是基于最小二乘基础上进行的,可知最小二乘对异常值敏感,且对模型误差有正态假设条件。因此,根据LAD的不受异常值影响,不对模型误差做假设还能得到稳健性估计结果的特点。用LAD替换最小二乘提出LAD-TD-LASSO。又由于LASSO采用无差别的惩罚系数,会导致部分自变量系数被过度压缩降低估计效率,并影响选择的一致性。因此,采用自适应LASSO对LAD-TD-LASSO方法加以改进提出LAD-TD-ADLASSO方法对伪分类进行识别,具体步骤如算法1所示。
算法1LAD-TD-ADLASSO算法

α1Z1,i+…+αkZk,i+εi
(9)
步骤2将步骤1中的参数进行合并整理:
ΔβmXm,i+α1Z1,i+…+αkZk,i+εi
(10)
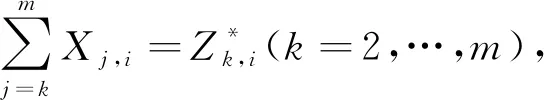
α1Z1,i+…+αkZk,i+εi
(11)
步骤4使用分位数惩罚回归识别伪分类,令φ=(α,Δβ2,…,Δβm,α1,…,αk)T,则
(12)

2 真实数据
在本节中,使用提出的LAD-TD-ADLASSO方法对2个实际数据例子进行分析研究,比较模型结果,观察并分析该方法是否具有实用性和有效性。
2.1 实证分析1
分析一个来自医学研究的真实数据集。数据来自新加坡眼科研究所眼科流行病学研究小组,见网站blog.uus.edu.sg/SEED。重点研究眼病、糖尿病、视网膜病变、青光眼、屈光不正和白内障等。选择其中一个糖尿病数据集来展示所提出的LAD-TD-ADLASSO方法对具有顺序类别自变量的模型的性能。一共3 280个数据,7个变量。数据存在缺失值,利用删除法对数据进行处理,剩余3 242个数据。其中因变量为血压,有4个顺序类别自变量,分别是性别、受教育水平、家庭经济状况、糖尿病诊断。连续变量为年龄和BMI指标(身高与体重平方的比值),根据以往的医学研究可将年龄和BMI进行分类。年龄以10年为一分段将其划分为一个5分类的顺序类别自变量。BMI根据世界卫生组织(WHO)的划分标准将其划分成偏瘦、正常、肥胖前状态、一级肥胖、二级肥胖、三级肥胖。整个糖尿病数据集有6个顺序类别自变量。医学研究中通常绘制table one向读者展示研究人群的基本特征变量,见表1。特征变量中用(*)表示顺序类别自变量。对顺序类别自变量的分类情况做相应的统计描述,得到相应的频数和频率。连续型变量描述其均值、标准差、中位数和最大最小值。

表1 糖尿病数据集的统计描述
判断顺序类别自变量中是否存在伪分类,以受教育水平为例。绘制受教育水平影响血压的阶梯图,如图1所示。受教育水平中2、3分类对于血压影响相似, 猜测受教育水平中2、3分类之间没有显著差异,可能存在伪分类。同样,受教育水平中4、5分类对于血压影响非常接近,猜测受教育水平中4、5分类可能存在伪分类。但不能单凭图1就猜测哪些类别存在伪分类,需要通过提出的LAD-TD-ADLASSO方法进行伪分类的识别。

图1 受教育水平影响血压的阶梯图
首先,构造线性模型(模型1)为:


然后,通过LAD-TD-ADLASSO方法识别出顺序类别自变量中隐藏的伪分类,检测出受教育水平中3、4分类为伪分类,5、6分类为伪分类,将6分类的受教育水平进行伪分类识别与融合得到一个4分类的顺序类别自变量。 家庭经济状况中2、3、4分类为伪分类,将其合并为一个2分类顺序类别的自变量。BMI分类中4、5、6分类为伪分类,融合成一个4分类变量。建立模型2:
为了评价未做TD-ADLASSO伪分类识别的模型1和做过TD-ADLASSO伪分类识别的模型2的差异性。 同时,检验做LAD与做最小二乘下的模型的性能。 采用交叉验证进行评价,交叉验证可以用于评估模型的预测性能。比较平均绝对误差(mean absolute error,MAE)和均方误差(mean square error,MSE)指标,MAE和MSE越小,则表示模型效果越好:

表2 添加干扰后交叉验证的MAE和MSE结果
将未做TD-ADLASSO伪分类识别的模型1基于最小二乘得到的结果记做OLS,模型1基于LAD得到的结果记做LAD。 将做过TD-ADLASSO伪分类识别的模型2基于最小二乘得到的结果记做TD+OLS,模型2基于LAD得到的结果记做TD+LAD。
根据表2可知,TD+OLS得到的MAE和MSE均小于OLS的MAE和MSE,TD+LAD下的MAE和MSE结果也均小于LAD的结果。说明经过TD-ADLASSO伪分类识别下的模型较未经过TD-ADLASSO伪分类识别的模型更具稳健性。同时,比较模型1和模型2内部的OLS和LAD结果,经过伪分类识别的模型2中,基于LAD得到的MAE和MSE均小于基于OLS得到的MAE和MSE。同样,未经过TD-ADLASSO伪分类识别的模型1中,基于LAD得到的MAE和MSE均小于基于OLS得到的MAE和MSE。表明LAD较最小二乘更具稳健性。通过TD+LAD得到的MAE和MSE结果发现,使用了TD的模型MAE、MSE不仅更小,而且哑变量个数变少,模型更精简,这符合解释型建模的要求。而且使用了LAD的模型,在随机干扰下表现更稳健。因此,提出的LAD-TD-ADLASSO方法在实际数据处理上具有可行性。
2.2 实证分析2
数据来自于成都市某中学不同年级学生的若干项目指标,该组数据包含了2 550位同学的大样本数据,主要统计了2类指标:一类是身体素质,包括性别、身高、体重;另一类是体测成绩,此类指标包括肺活量、50米跑、坐位体前屈、一分钟跳绳。将50米跑作为因变量,考虑其他因素的影响,其中有6个顺序类别的自变量,分别是年级、性别、体重、肺活量、坐位体前屈、一分钟跳绳。 性别变量是二分类变量,1代表男性,2代表女性; 体重中的类别分为4个等级,等级1~4分别代表“正常”,“低体重”,“超重”,“肥胖”; 肺活量中的类别分为4个等级,等级1~4分别代表“不及格”,“及格”,“良好”,“优秀”; 坐位体前屈和一分钟跳绳中的类别也分为4个等级,等级1~4代表的分类情况同上。变量及其变量解释具体见表3。特征变量中用(*)表示顺序类别自变量,其余的为连续型变量。对顺序类别自变量的分类情况做相应的统计描述,连续型变量描述其均值、标准差、中位数和最大最小值。

表3 成都市某中学不同年级学生的若干项目指标的统计描述
判别顺序类别自变量中是否存在伪分类,以体重水平为例,绘制体重的核密度估计图,如图2所示。由图2可知,体重的第2、3、4分类非常近似,猜测体重的2、3、4分类存在伪分类。为了判断是否确实存在伪分类,通过提出的LAD-TD-ADLASSO判别伪分类。

图2 体重的核密度估计图
首先,构造线性模型(模型3)为:


然后,通过LAD-TD-ADLASSO方法识别出顺序类别自变量中隐藏的伪分类,如体重水平中的2、3、4分类为伪分类,将其合并为同一类,建立模型4:
为了评价未做TD-ADLASSO伪分类识别的模型3和做过TD-ADLASSO伪分类识别的模型4的差异性,以及检验做最小二乘和做LAD的模型的性能。同样,在交叉验证过程中,选择训练集残差最大的前5%的数据,将其因变量Y添加总体因变量的2倍标准误差得到其MAE和MSE结果,见表4。

表4 添加干扰后交叉验证的MAE和MSE结果
根据表4可知,TD+LAD的MAE和MSE小于LAD的结果,且TD+OLS的MAE和MSE小于OLS的结果,表明通过TD-ADLASSO伪分类识别后的模型较未经过TD-ADLASSO伪分类识别模型更具稳健性,模型效果更好。比较模型3和模型4内部的OLS和LAD结果,经过TD-ADLASSO伪分类识别的模型4中,基于LAD得到的MAE和MSE均小于基于OLS得到的MAE和MSE。同样,未经过TD-ADLASSO伪分类识别的模型3中,基于LAD得到的MAE和MSE均小于基于OLS得到的MAE和MSE,表明LAD较最小二乘更具稳健性。通过TD+LAD得到的MAE和MSE结果发现,使用了TD的模型MAE、MSE不仅更小,而且哑变量个数变少,模型更精简,这符合解释型建模的要求。而且使用了LAD的模型,在随机干扰下表现更稳健。因此,提出的LAD-TD-ADLASSO方法在实际数据处理上具有可行性。
3 结论
针对含顺序类别自变量的线性回归模型,研究LAD和一种新型的顺序类别自变量的伪分类识别及融合技术。对提出的伪分类识别技术TD-LASSO加以改进,利用自适应LASSO代替LASSO对不同参数进行不同压缩提出TD-ADLASSO方法。之后,介绍了LAD的性质并与最小二乘作比较得出LAD的优势,用LAD替换最小二乘做参数估计。对TD-ADLASSO伪分类识别技术加以改进得到LAD-TD-ADLASSO方法,该方法能有效地进行变量选择与参数估计,得到稳健性结果。最后通过糖尿病数据集和成都市某中学不同年级学生的若干项目指标2个真实数据集,分别展示所提出的LAD-TD-ADLASSO方法识别伪分类的实用性,通过模型比较、交叉验证得到的结果证实提出的LAD-TD-ADLASSO方法具有可行性。 然而,本文中仅考虑τ=0.5的LAD,当τ取任意分位数时,也是值得研究的内容。
