非关系型大数据层间并行访问权限控制仿真
2022-12-24王凤领赵方珍
王凤领,王 涵,2,赵方珍,薛 亮
(1.澳门城市大学数据科学研究院,中国 澳门 999078;2.珠海中科先进技术研究院,广东 珠海 519000;3.暨南大学信息科学技术学院,广东 广州 510632)
1 引言
互联网技术的迅速发展和广泛应用以及企业规模的不断扩大,使得信息系统中的数据日益多样化。同时,在用户访问中,存在并行访问请求情况,并行访问请求是一个主体并行发送给一个或多个对象的一组访问请求,当主体请求访问时,访问控制策略决定主体是否被授权访问,如果请求被授权,则对象资源的访问权限向主体开放。并发访问请求是伴随网络应用的界面渲染和数据获取而产生的,并发访问请求被发送到访问控制策略中以获得诸如图片,视频,文本等对象资源信息。在这一背景下,如何对数据资源进行安全有效的管理是一个重要问题,所以数据资源的访问控制对信息系统的发展起着举足轻重的作用。
当前,已经有较多学者开展了关于数据层间并行访问控制的研究,其中,文献[1]中,陈大勇研究了大数据传输中授权访问多层次控制方法,该方法采用可信计算技术,建立了在大数据传输中的多层授权访问控制模型,这种模型具有较强的访问控制粒度,可以有效地支持对角色和服务的多角度访问控制;文献[2]中,李英杰研究了基于大数据分析的舰船通信网络访问权限控制方法,该方法采用大数据分析技术,对用户角色进行精确划分,并根据角色的划分给予相应的访问权限,从而实现船舶信息的安全访问。上述研究成果中能够获得一定的控制效果,但是存在准确性低与效率低的问题,为此设计一个非关系型大数据层间并行访问权限控制方法,从而有效的解决目前存在的问题。实验结果表明,此次研究的非关系型大数据层间并行访问权限控制方法有效解决了目前存在的问题,满足了数据并行访问的控制方法的设计需求。
2 并行访问权限控制协调框架
开放式网络中,对非关系型大数据的控制必须有序进行,才能保证最大程度的网络资源共享和数据资源保护。在访问权限控制设计中,重点依据请求内容对访问控制,以保证控制的准确性与实时性。在访问控制机制中,当主体需要对对象资源进行请求时,需要将请求发送到访问控制策略组件,以便根据访问控制策略要求的格式申请对对象资源的使用授权。对访问请求的内容进行分析后,访问控制策略组件将授权结果返回给主体。在授权主体使用资源时,它会相应地调用对象的资源信息。
图1显示了该框架的组件:
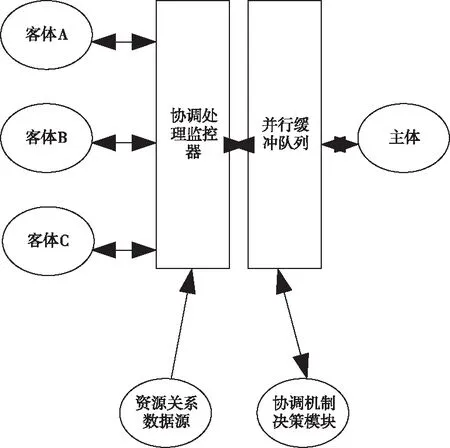
图1 并行访问权限控制协调框架图
图1中,在访问控制协调框架中,主体是具有用户登录身份的终端或应用程序[3],主要包括实体控制请求对象与存取对象。
“客体”为被动实体,主要实行的业务包括咨询、服务以及控制策略等的限制内容。
“并行缓冲队列”是一个缓冲执行并发访问请求的装置,存取控制协调框架规定存取要求所需的内容实体,包括资讯、资源及服务。
“协调处理监控器”主要对访问对象的装置进行检测,并能够对资源响应以及监控。
“资源关系数据库”主要存储访问主体与客体之间的访问数据关系。
3 非关系型大数据层间并行访问权限控制
3.1 登录认证
通过上面的控制协调框架可知,当用户访问数据时,首先会出现访问请求[4-6]。访问请求的特性可分为两类:本身特性和安全性特性,本身属性是访问请求本身的属性特性,安全属性是由被访问对象所决定。基于上述分析,首先对本身属性进行访问控制,即用户登录认证,登录认证:
通过对用户身份的认证能够检验访问对象的身份是否是合法的,如果审核通过则能够进入下一步骤中,如果身份认证不通过则进行危险警告,不给予认可。
登录认证的流程如下:
步骤一:用户通过 URL请求一个系统页面;
步骤二:检测用户是否成功登陆,如果没有登陆,则进入登陆页面进行登陆;
步骤三:用户在登录页面输入用户名和密码;
步骤四:数据库对用户信息检验,并存取用户信息;
步骤五:对成功登陆的用户进行身份验证,在验证通过后,将信息保存在当前会话框中,如果用户加密口令与数据库存储口令一致,返回用户请求的 URL页面。如果身份验证失败[7-10],则返回登录页并显示错误信息,通过上述用户访问需求,能够获取主体、操作、客体的基本信息,然后根据这些基本信息分被获取主体、客体的全部属性信息并连接成访问控制请求。
3.2 并行访问权限控制
在用户成功登陆后,能够分析用户的访问权限,为了对用户并行访问权限有效控制,建立访问请求图。存取要求存取图中的每个并发存取要求都作为存取图中的一个节点,存取图构造的过程是一种递归方法,将有关联的节点构造成一个存取图,建立存取要求的过程如下:
第二,根据访问请求的属性对其进行分组,将触发访问控制的访问请求节点分成(A)组,未触发访问控制的访问请求节点分成(B)组。
第三,A组根据访问请求节点的访问资源的访问控制安全级别将节点分层,在分层后将关联节点进行创建,创建为一个新的节点,将其记作汇聚节点;
第四,由于层次和层次之间的关系有关,高层节点通过集合节点与低层次节点组合,然后将新建的集合节点连接起来。
不断重复上述步骤以生成访问请求访问图如图2所示。
在上述访问请求图建立完成的基础上,分析访问数据的从属类别,通过对存取数据的依赖分类进行分析,指出一个大的分类可能包含多个子类,也可以对子类进行划分,因为访问数据类之间存在着依赖关系。而在访问控制中,分类特征和属性的相似性被表示为上下级之间的主导关系,为此完整序列集,S={level1,level2,…,leveln∣n∈N+},并定义分类范畴集C={C1,C2,…,Cn},将访问对象标记为三元组,Lo=A1,…,Am,{C1,…,Cn},level,用户标记也是一个三元组,Ls=A1,…,Am′,{C1,…,Cn′},level,其中Am′代表对象数据或用户的普通属性,Cn′代表目标资料或使用者的分类分类属性,即主体和目标所属的分类属性;level代表对象数据或者用户的安全等级。对非关系大数据的访问控制,通过对数据的属性模式和安全级分类,定义了访问控制结构,并将数据加密后上传到对象服务器。在用户具有满足细粒度访问控制策略的通用属性集和分类类别集的情况下,可以下载和解密数据,由用户的分类类别决定数据的分类属性,由用户安全级别决定数据安全级别。如果不符合则继续下一步,同时,为了进一步保证数据的安全性,对各层数据加密处理[11],其表达式为
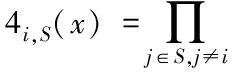
(1)
式(1)中,S代表一个访问元素的集合,x代表访问数据类型,j代表实体属性,∏代表加密参数。
加密处理后,经过如下操作,得到访问信息
纳入标准:(1)年龄≥18岁;(2)患者心衰的症状及体征符合《中国心力衰竭诊断和治疗指南》中慢性失代偿性心力衰竭的诊断标准;(3)NYHA分级Ⅲ~Ⅳ级;(4)LVEF<40%;(5)体质指数<35 kg/m2。排除标准:(1)对托伐普坦过敏者;(2)各种原因所致的对口渴不能做出正常反应及不敏感者;(3)存在脑血管疾病、重度肝肾功能损伤、心源性休克、明显感染及恶性肿瘤等高危因素;(4)低容量性低钠血症;(5)不同意长期随访的患者。
其中信息解密[12]公式为
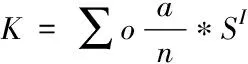
(2)
式(2)中,o代表身份信息,n代表获取信息数量,a代表解密信息判断参数,SI代表第I个信息的解密参数。
在此基础上,分析访问用户的安全等级,其表达式如下所示
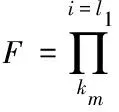
(3)
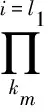
最后对用户访问请求进行排序,其表达式为
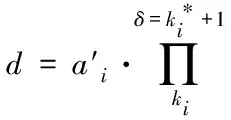
(4)
为了缩短可行性分析算法的计算时间,引入原子谓词,其集合为
B(P)={b1,…,bm}
(5)
数据集合代表通过该端口的数据集合。在这一个步骤中,能够快速识别黑洞信息以及危险信息等。基于上述过程对用户访问情况进行规划,对并发用户处理,解决并发用户带来的问题,以此完成对非关系型大数据层间并行访问权限控制。
4 实验对比
为验证此次研究的非关系型大数据层间并行访问权限控制方法的有效性,进行实验分析。
实验采用的软硬件配置如下所示:处理程序:Inter (R) Core (TM)/i5mr2430 m/CPU@2.40 GHz/处理器;内存安装情况:"6.00 GB";操作系统:Ubuntu14.04" LTS"(主机为 Windows"7"64位操作系统)。
同时,为了保证实验的严谨性,将传统的大数据传输中授权访问多层次控制方法、基于大数据分析的舰船通信网络访问权限控制方法与此次研究的控制方法进行对比,以提高实验的严谨性。
4.1 控制时间对比
分别采用传统两种方法与此次研究的非关系型大数据层间并行访问权限控制方法对数据访问权限控制,其控制时间对比结果如图4所示。
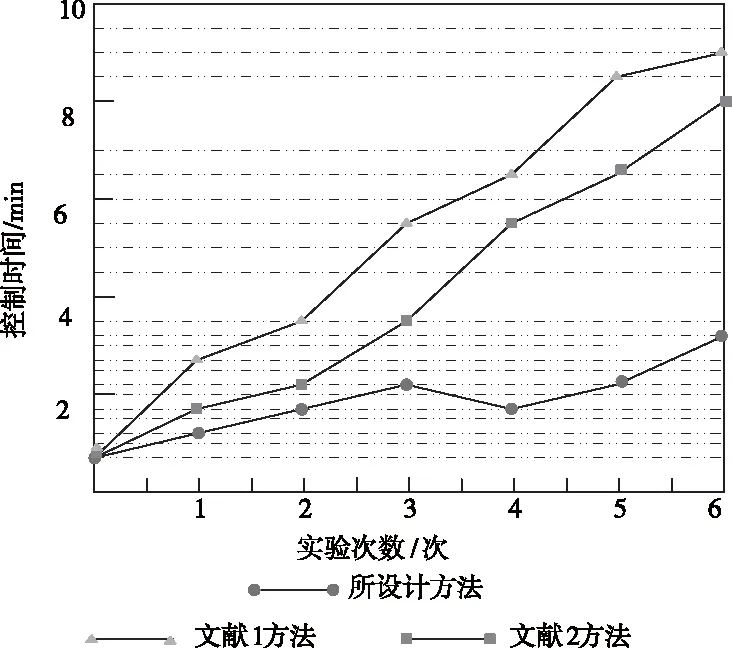
图4 控制时间对比
通过分析上图能够发现,采用此次研究的控制方法控制后,能够在较短时间就能够实现对数据的访问权限控制。而传统的两种数据访问权限控制方法在数据控制上,花费的时间较多。原因是,此次提出的控制方法受到访问文件大小与用户数量的影响较小,所以不仅能够降低控制时间,还能够较好的保证数据的完整性。
4.2 用户访问权限控制准确率对比
下图为传统的大数据传输中授权访问多层次控制方法、基于大数据分析的舰船通信网络访问权限控制方法与此次研究的控制方法的用户访问权限控制准确率。
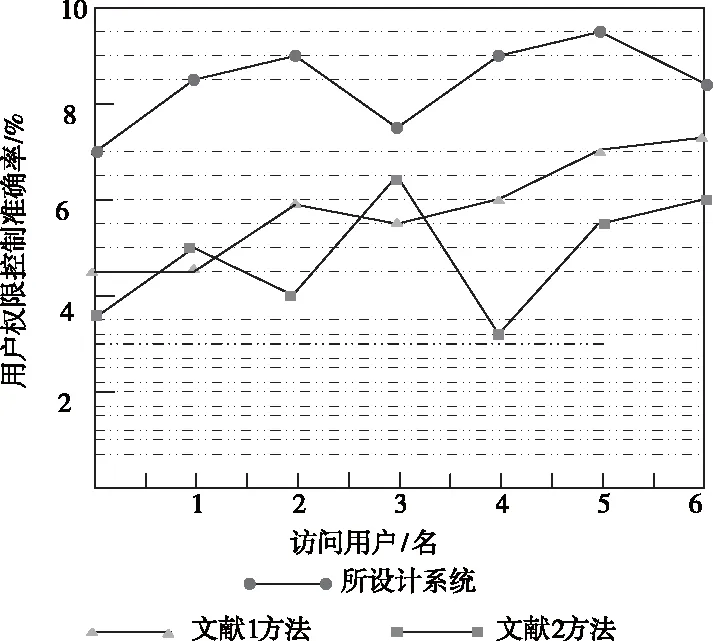
图5 用户访问权限控制准确率
基于上图能够发现,此次研究的控制方法对于用户访问权限控制上的准确性较高,因为此次研究的方法预先就对用户登录情况进行了分析,所以能够合理分析用户访问权限,用户访问权限提高才能提高数据的安全性。而传统的两种控制方法对于用户访问权限的控制上准确率较低,不能够合理分析用户情况,从而会在不同程度上降低数据的安全性。
4.3 数据丢包率对比
数据在并行访问权限控制过程中,会存在数据丢包的情况,为此将数据丢包率作为对比控制方法的一个指标,对比结果如图6所示。
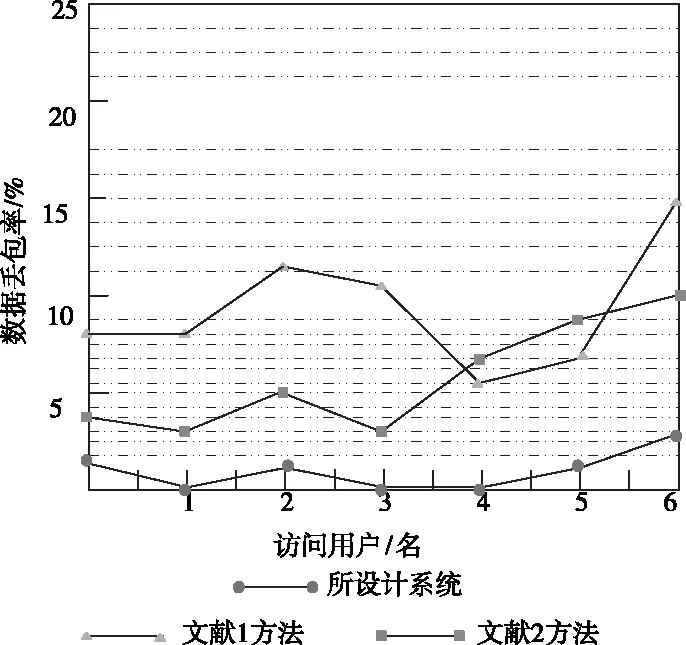
图6 数据丢包率对比
通过分析上图能够发现,此次研究的非关系型大数据层间并行访问控制方法在控制后,数据丢包率明显较低,基本不存在丢包情况。而传统两种控制方法在控制中,数据丢包情况较多,没有此次研究的控制方法的应用效果好。
综上所述,此次研究的非关系型大数据层间并行访问权限控制方法控制时间短,用户访问权限控制准确率高,并且数据丢包率较传统两种方法丢包率低。原因是此次研究的控制方法预先对用户登录认证,并根据用户权限设定了不同的访问内容,对象资源的安全性越高,对象访问请求的安全性越高,对用户访问请求进行了排序,从而提高了访问权限控制效果,具备一定的实际应用意义。
5 结束语
设计了一个非关系型大数据层间并行访问权限控制方法,并通过实验验证了此次研究的控制方法的有效性。通过此次研究的方法有效提高了数据的安全性,并降低了控制开销。但是由于研究时间与研究内容的限制,此次研究的方法还有一定的不足,下一步骤中主要研究的内容如下所示:
1)在存在许多复杂的临时授权操作时,如何协调正常的授权操作是进一步的工作,其最终目标是确保业务流程安全有效地运行。
2)行为与行动之间只有有序的关系,而没有考虑如何处理其它关系,比如说并、或及分支等关系。
