基于蚁群算法的计算引擎均衡部署数学建模
2022-12-24孟小燕赵希武
孟小燕,赵希武
(1.内蒙古师范大学,内蒙古 呼和浩特 010051;2.内蒙古师范大学计算机与信息工程学院,内蒙古 呼和浩特 010051)
1 引言
大数据是云计算发展的产物,不仅数量多,且还具有多样化、复杂化等特性。计算分析大数据可获得更多有用信息,有助于用户更加全方位了解各类业务流程,是促进业务发展的必然要求。大数据的主要特征为规模大,用户获得数据的方式非常简单,且用户在点击和浏览过程中又会生成较多新的数据;种类多,数据更新频率很快,这是与传统数据相比最明显的特征;价值密度低,虽然数据量增长速度飞快,但里面蕴含的有用信息却较少,必须通过计算来获得有用数据。由于数据量巨大,对数据计算分析能力提出更高要求,单一引擎已经不能满足计算需求,为此,分布式计算引擎应运而生,充分使用单个引擎的计算能力实现大规模数据的处理。
但是分布式引擎的应用还不够成熟,常出现计算负载不均衡状况,降低计算能力,影响工作效率。又因开为不同引擎的硬件性能各不相同,进一步加大部署难度。为此,一些学者针对这一问题纷纷展了研究。
文献[1]基于贪心启发式算法建立计算引擎均衡部署框架,定义数据传输机制,利用限定范围的可控参数约束传输过程,结合二次分拆原理,制定分拆计划,通过贪心启发式算法实现分拆结果的均衡部署。文献[2]设计了一种适用于大数据计算的随机样本划分模型。将大数据表示成数据块集合形式,储存在不同节点上;估计大数据的特征,建立回归分析模型,利用Alpha计算架构实现数据清洗,减轻计算量,再通过概率密度函数将计算引擎部署到最佳数据块上。
上述算法虽然能够实现负载均衡,但会出现系统能耗较高、响应时间长等问题。为此,本文设置了均衡部署的约束条件,在多方面约束下,利用蚁群算法建立部署数学模型。蚁群算法是根据蚂蚁觅食设计的,可以不断迭代寻优[3],使方法能够根据约束条件实现动态调节,最终获得全局最优解,即最优部署方案。
2 大数据计算引擎工作模式与流程分析
2.1 计算模式架构
大数据计算模式的选择是数据处理过程中最为关键的环节。在数据产生前期,系统针对已经存在的数据做简单处理,随数据量的增加,处理速度显得尤为重要,此时应增加计算内存,提高系统处理速度。
现阶段,大数据计算模式主要包括流式[4]和批量式[5]两种。其中,流式计算利用Spark平台[6]实现,在计算周期内通过数据库达到信息共享目的。数据计算采用引擎分布式并行处理方案,多个引擎节点采集来自不同数据源的数据,再进行独立计算,并将运算结果保存到数据库中。因此,需最大程度保证引擎部署负载均衡,以满足系统快速、稳定计算的要求。批量式计算利用的是分而治之思想,将待处理的数据划分到多个节点上,减少计算开销,再汇总所用节点处理结果,反复操作上述过程,直至获得理想结果。此种模式的发展时间很长,在处理架构、分析挖掘、可视化等方面均有应用。但是,处理速度较慢,大多应用在对计算时间要求不高的任务中,此外其处理结果精度较高。
综合上述分析,两种计算模式均有优缺点。因此,本文将两种方式相结合,设计了双模式大数据计算架构[7],如图1所示。
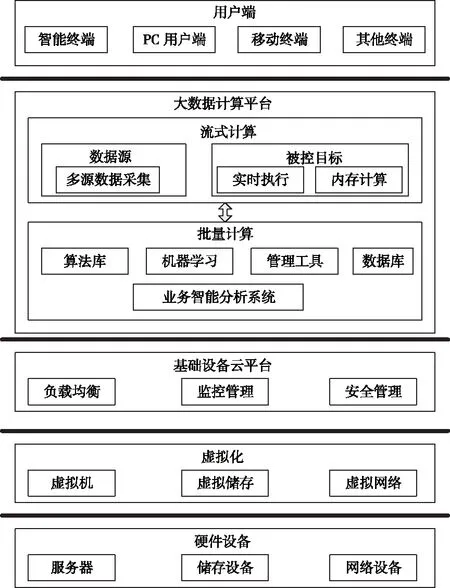
图1 大数据计算模式架构图
2.2 计算流程
根据双模式计算引擎架构特征,设计计算流程,该流程共包括以下阶段:
1)采集阶段:是大数据计算的基础,同时采集多个外部数据源,获取实时数据,并统一数据格式[8];
2)数据预处理:使用批量计算方法分析历史数据,完成大数据基本处理,确定数据之间的关联模型,为流式计算提供数据基础。此阶段数据的主要特征是数量大、多样化且结构复杂。
3)计算阶段:使用分布式引擎实时计算处理后的数据,此阶段数据突发性强且伴随一定无序性特征。
4)操控阶段:根据计算结果给出决策意见。
在双模式计算架构下,按照上述工作流程,即可通过分布式引擎实现大数据计算。但是在计算过程中,由于任务分配不均等导致负载不均衡,为此有必要对引擎部署进行数学建模,平衡任务分配,提高计算效率。
3 大数据计算引擎均衡部署数学建模
3.1 均衡部署约束模型
1)计算任务数量约束
在上述计算环境下,分布式引擎的硬件配置往往存在差异,导致计算任务总量出现不均匀现象。假设引擎节点集合表示为N={n1,n2,…,n|N|},任意一个节点中包含的数据总量是R={rn1,rn2,…,rn|N|},拓扑中存在的计算任务总量记作|T|,因此有

(2)
式中,Tni代表引擎ni上执行的任务总数。为确保数量分配的公平性[9],任务数量应与拥有的资源总数之间呈正比,这对某引擎ni∈N而言,存在
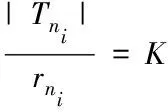
(3)
式中,K属于一个固定常数,根据式(2)和(3)能够得出
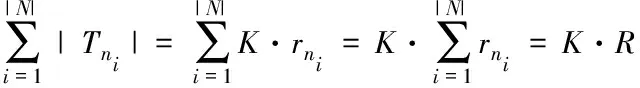
(4)
因此有
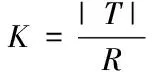
(5)
将分配数量公平性作为约束条件,结合引擎配置情况,通过人工方式设定引擎节点可接收的最大任务数量。针对某引擎ni而言,其计算任务容量表达式如下
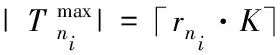
(6)
当每个引擎的配置相同时,没有异构特征[10],则各引擎具备相同数量资源。此时,式(6)可表示为
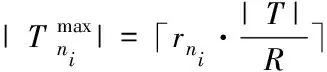
(7)
若t时间点引擎ni已经被部署的计算任务数量是|Tii(t)|,则引擎剩余计算容量表示为
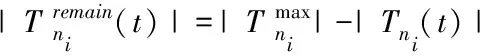
(8)
2)负载均衡约束
若引擎nk被部署到执行计算任务tij的节点范围内,记作f(tij)=nk,其另一种形式为f-1(nk)=tij;若引擎nk被部署到执行任务集合Tnk={t11,t12,…,tij}的节点上,此时记作f(Tnk)=nk或f-1(nk)=Tnk。上述的f即为部署法则[11]。
假设某带权拓扑[12]内计算任务集合是T,nx表示众多引擎中随机一个,引擎nk被部署到f-1(nk)任务中,引擎nl(l≠k)则被部署在f-1(nl)任务集合中,因此有

(9)
并且
f-1(nk)∩f-1(nl)=∅(k≠l)
(10)
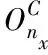
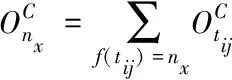
(11)
利用OC表示所有引擎的负载总和,在同构情况下,各引擎的负载会随任务数量的变化而改变,但OC保持不变
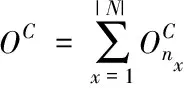
(12)
若将负载总和平均分配到各引擎上,则每个引擎需要承担的负载表示为
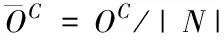
(13)
3)最优部署开销约束
部署开销与数据流大小相关,数据流越大,部署时间就越长,系统能耗就越高。假设任务tij和tkl二者的数据流大小表示为vij,kl或vkl,ij,若要保证最优部署开销,需最大程度减少待计算的数据流总量[13],即
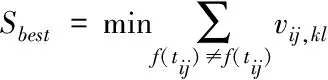
(14)
还可表示为
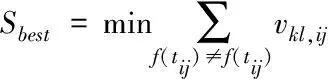
(15)
3.2 基于蚁群算法的均衡部署数学建模
在计算任务数量、负载均衡和最优开销约束下,利用蚁群算法完成引擎均衡部署数学建模。
蚁群算法需先对信息素函数τij(t)做初始化处理,该函数代表引擎nx针对某任务Ti表现出的信息素浓度,结合引擎计算能力[14]MIPSj、通信带宽Bandwidthj完成初始化操作
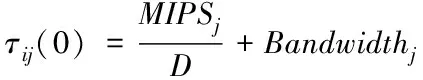
(16)
式中,D为常数。
实现函数初始化后,利用下述表达式得出引擎nx被部署到任务Ti处的几率
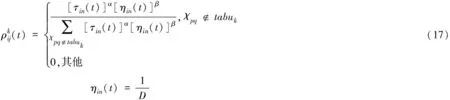
(18)
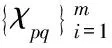
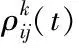
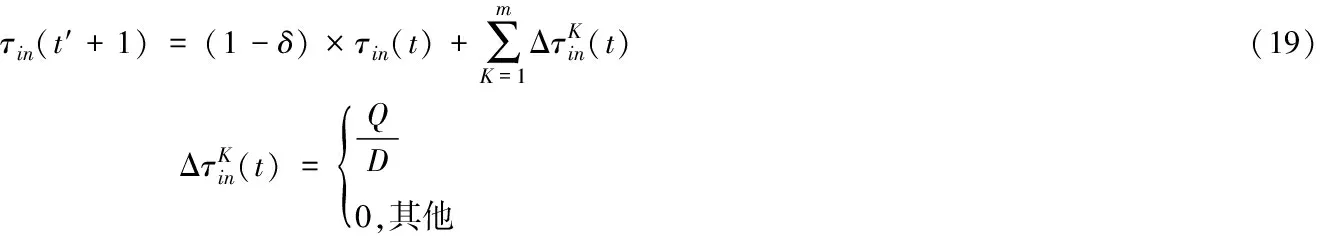
(20)
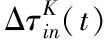
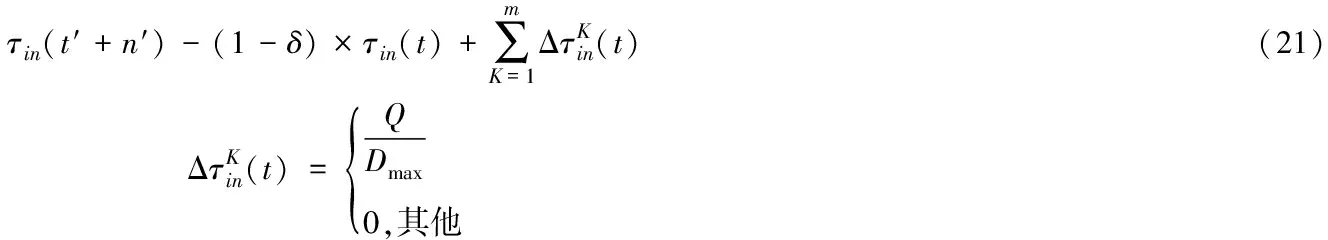
(22)
式中,Dmax代表经过多次迭代后得到的最优解。
4 仿真设计与分析
为评估所建数学模型性能,设置仿真。仿真基于分布式服务器系统,该平台可靠性高、具有较强的容错能力。为突出本文方法优势,利用贪心启发式算法、随机样本划分模型与所提方法的仿真结果进行对比,实验结果如下。
1)响应时长性能分析
部署响应时间影响着大数据计算效率,与用户满意度密切相关。随着用户并发请求的增加,三种算法的平均响应时间仿真结果如图2所示。
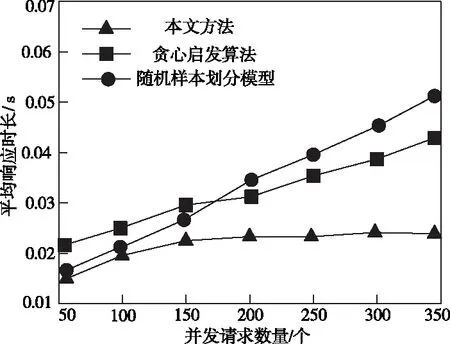
图2 不同算法部署响应时长对比图
分析图2得出:随着用户并发数量不断增加,所提方法的响应时长稍有上升趋势,待并发请求量达到200个时,响应时间不再上升,达到平稳趋势,而随机样本划分模型起初的响应时长与所提方法接近,但后续上升速度较快。整体而言本文方法能够快速部署计算引擎,减少用户等待时长,这是因为蚁群算法具有较强的寻优能力,可以快速找到部署最优解。
2)引擎负载均衡评价
计算引擎部署最重要的就是负载均衡,本文利用下述评价函数判断负载均衡情况。
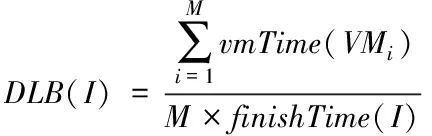
(23)
式中,finishTime(I)表示使用某种部署方案完成全部计算任务所需时间,即max(VMTime(VMi)),M为计算引擎数量。能够看出DLB(I)值越高,引擎利用效率也越高,表明负载更加均衡。三种算法的负载均衡对比结果如图3所示。
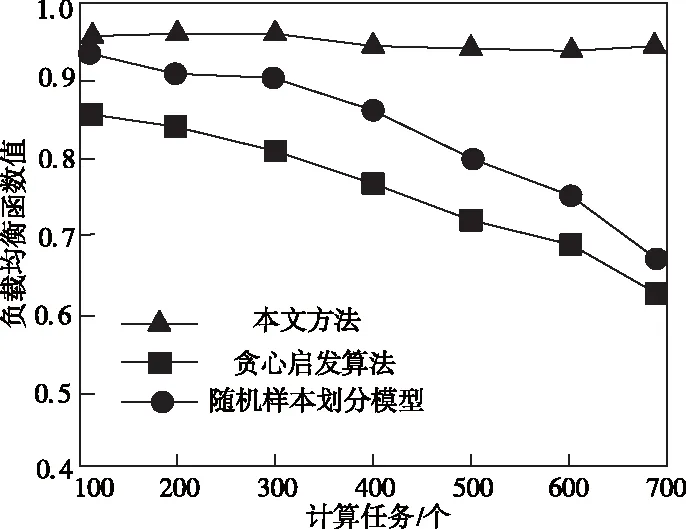
图3 不同方法负载均衡对比图
图3显示,随着大数据计算任务的增多,在引擎数量相同条件下,本文算法的负载均衡函数值始终处于较高水平,没有显著变化趋势。表明该部署方法的负载均衡情况不会受到计算任务量的影响,而其它两种方法受其影响较大,当计算任务过多时,无法保证部署均衡。
3)部署能耗分析
计算能耗是引擎部署方案实用性的体现,若能耗低,系统能承载的计算任务量就可以加大,本次实验分别从系统整体能耗和单位计算量能耗两方面比较三种算法性能,仿真结果分别如图4所示。
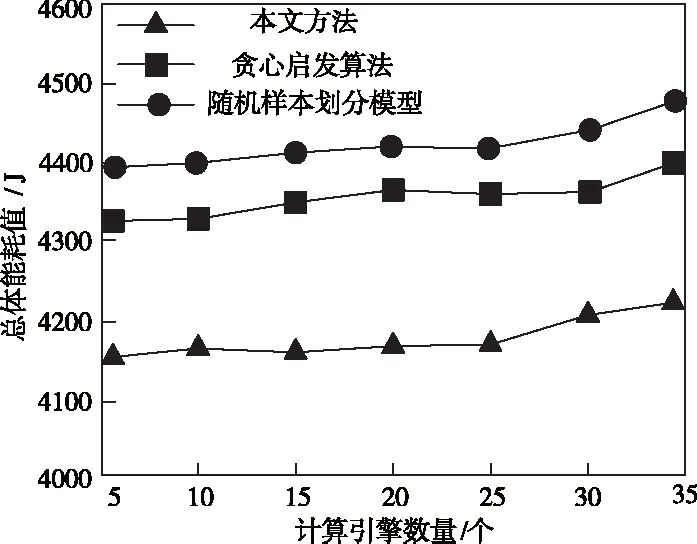
图4 不同方法下系统整体能耗图
由图4看出,三种部署方法消耗的系统能量变化趋势基本相同,其中本文模型消耗的能量最低,可保证系统稳定运行。这是因为当计算任务量相等时,引擎数量增加会减少单位计算量,因此单个引擎的所需能耗会下降。
5 结论
现阶段,分布式系统广泛应用在大数据处理领域,但计算引擎均衡部署影响着其应用效果。为此,本文利用蚁群算法建立均衡部署模型。仿真结果表明,所建模型在实现负载均衡的同时还能减少计算时间,有助于提高用户满意度。但该模型的研究还有进一步优化的空间,例如增加负荷约束向量,验证此模型下的大数据计算质量。此外,考虑到大数据的动态性与灵活性,还需优化蚁群算法,避免因历史信息累计而无法构建新路径的问题。
