基于数据消冗技术的隐私大数据属性加密仿真
2022-12-24陈小娟贺红艳张慧萍
陈小娟,贺红艳,张慧萍
(湖北工业大学工程技术学院,湖北 武汉430068)
1 引言
近年来,大规模数据的快速发展成为学术界的热门话题环境,由于传统数据加密算法,并不能完全保障数据所有者利益最大化,值得注意的是,基于属性加密可以灵活地实现访问控制,为大数据应用提供了一种新的访问管理方法。大数据主要来自不同的设备,但大多数终端没有嵌入式存储安全模块的密钥,如果在大型数据环境中使用属性加密技术,就会很容易通过显示密钥或者其它秘密远程参数的页面通道进行攻击,造成加密过程中只检查密钥是否泄漏,没有严谨考虑到加密后随机数是否安全。
因为海量数据一直在飞速增加,网络客户端中可以收集到用户数据,并提供一切隐私行为以及状态等敏感信息,所以大数据的开发面临着严峻的挑战。这是因为具有访问信息的大数据不仅包含保护用户数据的信息,还包含其它敏感信息,如用户习惯和偏好。大数据信息销毁后,严重侵犯用户隐私,而对个人财产和安全的数据保护和页面加密的研究是非常重要的。传统的加密模式对于用户来说已经发展了很长一段时间,能够保护涉及个人位置的数据的隐私用户。但是,随着数据量的增加,传统的加密方法已经不能满足现有的数据量需求。数据的采集往往存在严重的错误,数据保护水平不高,这严重限制了用户编码加密技术的进一步发展。文献[1]利用云雾合作的多级聚合模型和同态加密算法,进行多层隐私保护,实时数据在网络端通过加密获得第一层隐私保护,在雾端进行细粒度聚合获得第二层隐私保护,实现了整个网络数据传输与处理的机密性和隐私性。雾级聚合数据在云节点作为系数嵌入符合霍纳规则的一元多项式完成第三层隐私保护,最终电力服务机构将云级粗粒度聚合数据霍纳分解与解密,获得雾级与云级明文聚合数据;文献[2]等人利用角色对称加密将用户角色与密钥相关联,构建角色密钥树,不同角色可根据访问控制策略访问对应权限的文件;同时,提出一种基于角色对称加密的云数据安全去重方案,有效保护个人隐私信息,实现分层结构下的云数据授权去重,并通过群组密钥协商解决角色与密钥映射关系中密钥更新与权限撤销等带来的安全问题。
由于数据网络发展,网络客户端的数据也在海量增加,导致存储空间急剧减少。虽然上述两种文献方法可以有效完成大数据加密,但因不能合理地消除数据的冗余性,产生加密效率不高等问题,基于此本文提出一种基于数据消冗技术的隐私大数据属性加密仿真。
2 基于Bloom filter的大数据消冗算法
目前在数字信息快速增长的同时,还仍然存在着多样性,尽管数据压缩技术可以将文件中不必要数据占用空间降低,但数据增长是飞速的,依旧会占用较多运行内存,因此本文使用冗余数据消除法去除加密过程中不必要信息。
2.1 构造方法
计算过程中,因Bloom filter是一个含有m的多维数据的集合,并且集合中每一组数据都为0,为了能够更好地呈现n个数据元素的集合S={x1,x2,…,xn},利用k个hash函数将数据元素映射到1,…,m的范围区间中[3]。
假设将某一数据段D中,一个有顺序的序列判定为shingle,那么该数据段中,shingle集合就被描述为S(D,w),这样即可构造出Bloom filter:
1)构建出一个m位的大数据bf,并将数据初始化设置,令其取值为0;
2)从数据集合中选取出两个适用于映射函数的hash函数,并将其进行初始化处理,计算后被描述为hash1,hash3;
3)数据集合中抽取出随机的一个shingle,实现hash1,hash3计算大数据的摘要取值,然后将bf设置为1;
4)输出bf,作为大数据文件的特征取值。
2.2 求解误判率
经过Bloom filter计算可以节省大量存储空间,便允许出现少量错误,此外因为经过Bloom filter计算后,冗余数据大量减少,所以整体计算过程误判率也会随之下降,消除的冗余数据越多,精度越高,但相对应的储藏空间使用越多[4]。
当S={x1,x2,…,xn}集合每个数据元素都被映射到对应数据范围区间时,即可进一步获取出某一位仍为0的概率p′,计算公式如下

(1)
如果要把集合S完全映射到数组中,那么便需要做kn次hash计算。本文采用e的常用近似计算,如下所示

(2)
根据上式计算结果得知,假设将β表示为集合中数据为0的比例,那么β的期望取值就有E(β)=p′。
为了便于后续计算,令p=e-nk/m,这样即可得知,在已知β值的情况下,错误率的大小
(1-β)k≈(1-p′)k≈(1-p)k
(3)
f=(1-e-nk/m)k
(4)
根据计算结果得知,式中k被设置为2,如果需要通过上式得知数据y是否完全符合该集合的需求条件,即可针对y实现k次函数计算,计算结果显示hi(y)均值为1(1≤i≤k),那么y则属于这个集合,否则便为误判结果。
2.3 确定最优hash函数量
Bloom filter计算过程中使用多个hash函数将集合映射到位数组中,同时存在一定的误判率,因此需要在计算之前,选取出最优扩列函数数量,便于后续数据搜索时,误判率达到最小化。相同,如果计算时同时运用多个hash函数,那么就会产生搜索不属于该集合的数据,来实现误判为0的情况。此外搜索时hash函数量过少,会导致bits表中会有更多的零[5]。
令g=kln(1-e-nk/m),式中当g取最小值时,相对地f将会达到最高取值,这样p=e-nk/m时就可以与g进行转换,便有

(5)
对上式等号两边进行求导运算,结果如下式所示
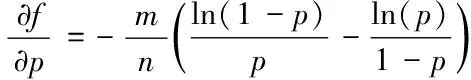
(6)

f=(1/2)k≈(1/2)ln2·(m/n)≈(0.6185)m/n
(7)
根据上述计算,根据Hamming距离和余弦相似公式计算数据对象之间的相似度。如果这两个值相同,则文件将被存储文件的索引替换;如果这两个值不同,则存储文件并更新哈希表以向文件添加新的哈希值[6]。
3 隐私大数据属性加密
由于隐私泄露问题主要出自访问过程中,因此本文讨论通用云访问场景分析数据属性,旨在实现加密数据访问的安全性、可扩展性和精确控制。
3.1 数据共享访问下数据属性分析
充分利用属性加密机制来控制对系统的访问,实现一种有效的对称加密。建立适当的系统和模块模型如图1所示。

图1 数据共享访问场景示意图
大数据访问网络主要是由数据使用者、数据端用户以及网络传输服务器构成,为了能够获取使用者在网络中搜索的访问数据痕迹,就需要采用网络端用户所用的服务器,并且收集数据痕迹以及访问痕迹。Abe选择一组描述信息元素容器的属性。
学生信息网络包括学生类别、培养类别、专业和年级等属性。假设计算机领域的研究人员是一个群体,那么培养类型属性的取值则判定为不定项,因为大数据数据属性取值是以计算机分类为标准的,所以属性取值则是分类与取值的标准,第三类学生和属性值为假期,加密系统中的密钥是由数据所有者根据用户计算出来的,属于用户属性[7]。基于属性加密的云数据结构访问如图2所示。
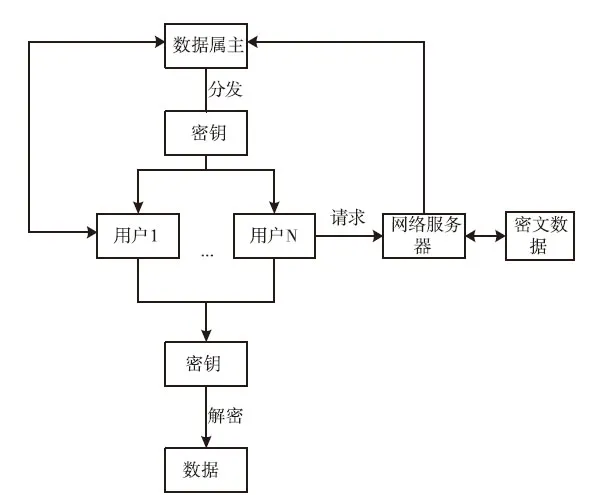
图2 基于属性加密的数据共享访问图
根据系统设计的目的,采用Abe加密系统对数据进行精确的访问控制,Abe属于公共加密系统的密钥。函数算法加密采用大代数结构,加解密运算量很大[8]。因此本文将对称加密与非对称结合,用于解决解密运算量过大的问题。通过设计目标,得出对应的系统功能架构,示意图如图3所示。

图3 系统功能架构图
3.2 属性加密数学模型

如果令Setup(1k)表示为双线映射的生成元,则至少具有一个安全参数1k,这样便可获取出任意输出的参数集{q,G1,GT,g,e}。
3.2.1 密码学加密
假设在网络数据传输中,算法A用x作为数据输入的参数,那么m即可被描述为x的实际长度,若是在计算中具有一个多项式p,加密计算时便止步于p(m)。
加密计算过程中,具有加密特征的hash函数是一个特殊的扩列函数,根据不同计算取值,可以任意调节符串长度,并将其固定为一个期望的长度。如果h表示hash函数,n为数据输出的实际符串长度,那么即可得知h具有下列特点:
扩散性:是指在加密计算中,根据不同的数据指向,hash函数的取值范围在[0,2m]区间范围内,并且令二进制数据与多项式时间相同;
单向性:如果经计算得知hash函数取值w,想要进一步得出x,这样就必须满足h(x)=w计算式的所有必要条件;
不可有效计算性:寻找出两个不同的大数据进行加密计算,必要前提是x≠y,并且让h(x)=h(y);
实际有效性:在已知加密数据取值前提下,利用h(x)即可获取出实际计算时长。
3.2.2 CP-ABE加密流程
为了实现对云环境数据的安全、可扩展和细粒度的数据访问,应用CP-ABE加密系统,该系统主要用于基于属性加密的云访问控制。换句话说,包含由数据所有者控制的数据的访问结构被添加到加密数据中。只有私钥特性满足加密访问结构的用户才能解密密码Poni是通用cp-abe算法的官方定义[9]。
CP-ABE算法加密流程如下:
数据加密初始化Setup(1k):初始化计算中,首先输入一个安全参数,然后返回加密系统的主公钥MP以及主私钥的计算参数MS。
加密生成算法KeyGen(MS,U):该算法是在计算中,输入与其对应的主私钥MS以及该大数据的属性集合U,并且相对应地生成属性集合中每个数据解密密钥。
大数据属性加密算法Encrypt(MP,S,M):大数据加密算过程中,首先输入MP,大数据消息M以及网络访问结构M,并在此基础上构建只有数据使用者的私钥SK,然后令与私钥有关联的属性集合满足U|=S的必要条件,便于解密的密文C[10]。
大数据属性解密算法Decrypt(MP,C,SKU):在加密后对大数据解密,主要引用主公钥MP、解密密文C以及使用者的私钥SKu。
4 仿真研究
为了能够进一步验证本文加密方法的可行性,在仿真环境为:使用CPU为AMD Athlon(tm) Ⅱ X3,3.l0GHz,2GB内存的PC机,编程语言为C++。在忽略实验环境差异的条件下,采用1TB大小的数据作为实验对象,文件总数为905797,平均大小1105kB。分别针对本文方法与文献[1]、[2]方法在数据消冗、加密过程生成密钥时间开销方面进行对比,对比结果如图4所示。

图4 仿真对比图
从图4可以看出在检测方案的额外存储开销方面,本文方法消冗存储最高,高达60%左右,文献[1]方法次之,最多引入50%左右的额外存储开销,而文献[2]方法检测方案引入的存储开销相对最低。图4(b)则是三种方法的加密误差对比,可清楚看出,本文方法明显优于两种文献方法,因为本文方法的数据消冗效率是最高的,而文献方法没有及时消冗,导致加密过程中,可能会对重复数据加密,因此加密误差高。
在效率对比基础上,对加密和解密时间开销进行对比,图5呈现了三种方法在生成主公钥以及主私钥所用的时间对比。
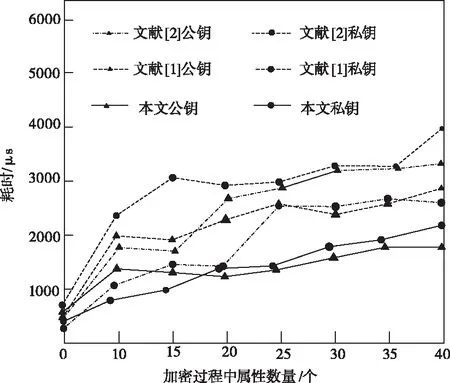
图5 加密公钥私钥生成时间对比
实验结果表明,相对于CP-ABE,文献[1]、[2]方法在生成主公钥以及主私钥时具有较长时间的耗时,导致加密解密效率不高。
5 结论
由于人们对互联网的依赖性越来越高,利用互联网技术进行数据的交互和存储也带来了各个层面的安全问题。因此本文设计了大用户数据的加密保护方法。但是,本研究还存在一些不足,例如,由于因据中会出现一些关于最终加密错误的噪声,但对加密结果影响不大。此外,本文旨在有针对性地研究对大数据进行预处理,以不断减少加密数据保护中的错误和无限解体,保证用户隐私的保护,促进中国互联网技术的进一步发展。
