基于多级索引的高维数据近似最近邻搜索
2022-12-24杨凤丽刘仁芬
杨凤丽,李 娜,刘仁芬
(石家庄铁道大学四方学院,河北 石家庄051132)
1 引言
当前网络平台上的文本、视频等多媒体数据量持续上升,例如雅虎网站的日交换信息量高达30亿条,某相簿共享网站包含超过50亿张的图片,且每日仍保持较高的图片上传速率。这些数据包含很多具有科学价值与应用价值的信息。在此背景下,网络海量数据的安全维护极为重要。但是由于此类数据具有高维、异构等特点,使数据的最近邻查询成为难点问题[1,2]。
关于高维数据近似最近邻搜索,很多专家学者已经得到了一些研究成果,例如刘恒等人[3]通过量化编码实现高维数据近似最近邻搜索,该算法搜索性能优越,且时间成本低,但内存消耗较大;刘晨赫等人[4]通过动态网格子空间实现高维数据近似最近邻搜索,该算法复杂度较低,能有效避免有效数据丢失,但数据维数较高时的搜索性能仍不够理想。
哈希搜索的精确、高效性,使其逐步发展为近似最近邻查询问题的有效方法之一,对于高维数据近似最近邻搜索,距离敏感哈希算法运用广泛,为优化该算法存在的搜索稳定性较差问题,引入能将若干索引方法组合使用的多级索引方法,提出基于多级索引的高维数据近似最近邻搜索算法,通过二级距离敏感哈希,实现高维数据近似最近邻搜索。
2 基于多级索引的高维数据近似最近邻搜索算法
2.1 近似最近邻查询
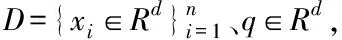
近似最近邻查询在高维数据处理中运用广泛,数据集和查询点定义同上,近似比率用c描述,且c大于1,该查询将向量p∈D作为返回结果,可使dist(p,q)≤c×dist(p*,q)成立,q的最近邻用p*描述。
2.2 LSH算法
距离敏感哈希(Locality-Sensitive Hashing,LSH)算法是高维数据近似最近邻搜索方面极具代表性的算法,若要检测出相似数据点,可通过任意哈希函数值使其以极高的几率出现冲突[5,6]。
哈希函数在该算法中符合式(1)所示条件,它属于单向映射函数
Prh∈H[h(u)=h(v)]=sim(u,v)
(1)
式中,相似度函数用sim(u,v)∈[0,1]描述;哈希函数簇用H描述;哈希函数用h描述,其以均匀方式自H内选择;两个不同数据点用u、v描述;
式(2)描述了利用随机投影法获得的哈希函数表达式
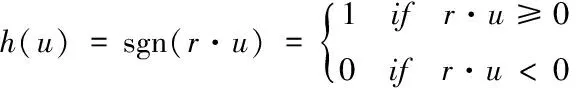
(2)
式内,矢量用r描述,其各元素符合正态分布[7],在超平面内,数据点u的位置决定着哈希函数取值,设定u1、u2表示数据点,两者满足式(3)所示表达式
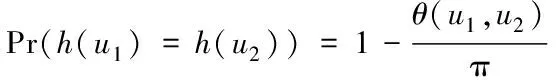
(3)
任意方向矢量用ai描述,以p平稳分布为基础的哈希函数用{h:Rd→Z}描述,关于数据库内矢量点,通过该哈希函数将其投影至ai上,该矢量的各元素符合p平稳分布,其中,若呈现柯西分布,那么p值为1,若呈现标准高斯分布,那么p值为2。对于两个变量,如果其线性组合满足p平稳分布,则是在两者均满足p平稳分布的条件下。{h:Rd→Z}的计算过程用式(4)描述
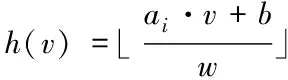
(4)
式内,位于ai上,数据点v的投影用ai·v描述;投影窗口的量化宽度用w描述;参数用b描述,其值符合[0,w]的均匀分布,能极大地提高哈希函数的随机性[8];取整处理用⎣ 」描述。设定v1、v2表示数据点,两者满足式(5)所示表达式
p(c)=Pr(ha,b(v1)=ha,b(v2))
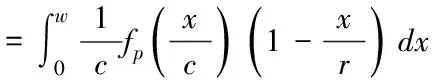
(5)
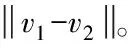
设定hi为单个哈希函数,由于hi不具备较强的区分能力,建立如式(6)描述的第二级哈希函数:
gj(v)={hj,1(v),…,hj,k(v)}j=1,…,l
(6)
式内,对于数据点v,其哈希码为利用k个整数组建的矢量,LSH函数簇用G={g:Rd→Zk}描述。
2.3 基于M2LSH的高维数据近似最近邻搜索算法
处理分布不均匀的高维数据时,易造成索引文件中的哈希桶所存储的数据出现数量不均衡现象,导致返回结果个数过多或过少,从而影响LSH算法的搜索稳定性,因此使用二级距离敏感哈希(M2LSH)实现高维数据近似最近邻搜索,使候选集尽量减少,提升算法的搜索精度和效率。
将索引创建在单个哈希表内的步骤用图1描述。
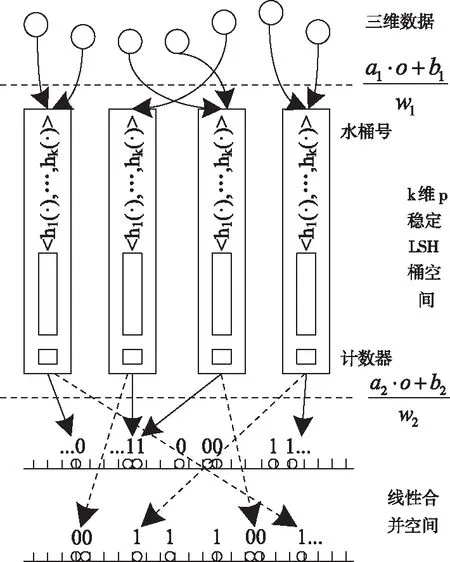
图1 创建索引过程
组合哈希向量代表哈希桶,用于放置原始高维数据,设定对象o,对其实施组合哈希处理,并放进与gi(o)=〈h1(o),h2(o),…,hk1(o)〉匹配的哈希桶内。桶宽用w描述,其值较小,将计数器Counter设定于各组合哈希桶内,能对桶内对象数量进行记录[9,10]。
1)索引创建。
(a)使用哈希桶存储高维数据,以(h1(o),h2(o),…,hk1(o),1)描述各数据对象o完成gi(·)操作的形式,通过AND过程,对象o需放置的组合哈希桶号用o′描述,表示为(h1(o),h1(o),…,hk1(o)),计数器用1描述。
(b)若想为合并上步中获取的组合哈希桶号做准备,可以通过二次哈希对其进行处理并投影至一条线上,利用该操作,能够重新排列桶号,分配邻近的哈希桶号至邻近地点。
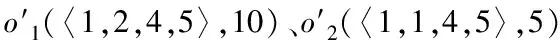
关于索引创建过程,需构建的g(·)数量用i描述,且i=1,2,…,L,各g(·)和索引文件相匹配。
以下为桶合并实现过程:
Input Line (the second hashes)
Compute the AC
Set flag=0
Foreach i=1,…,k2
For j=1,…,length of Sortedlinei
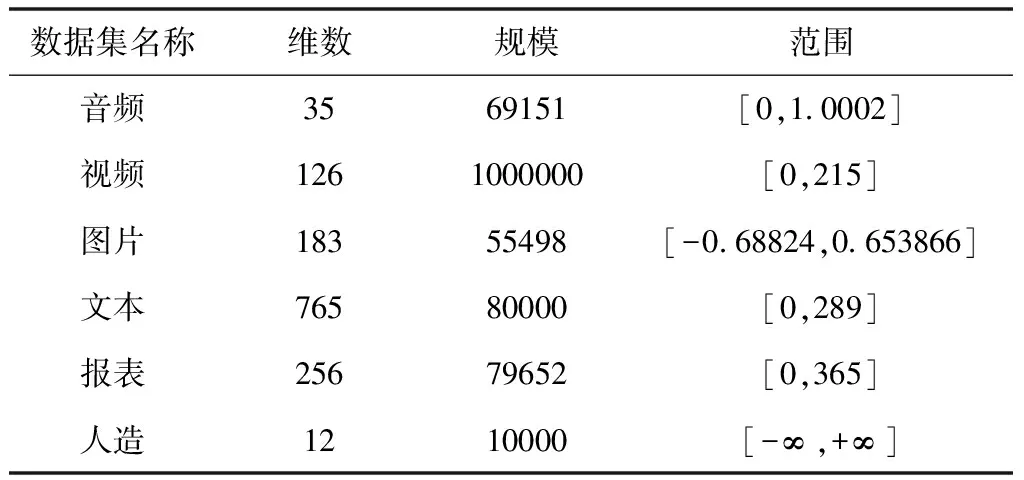
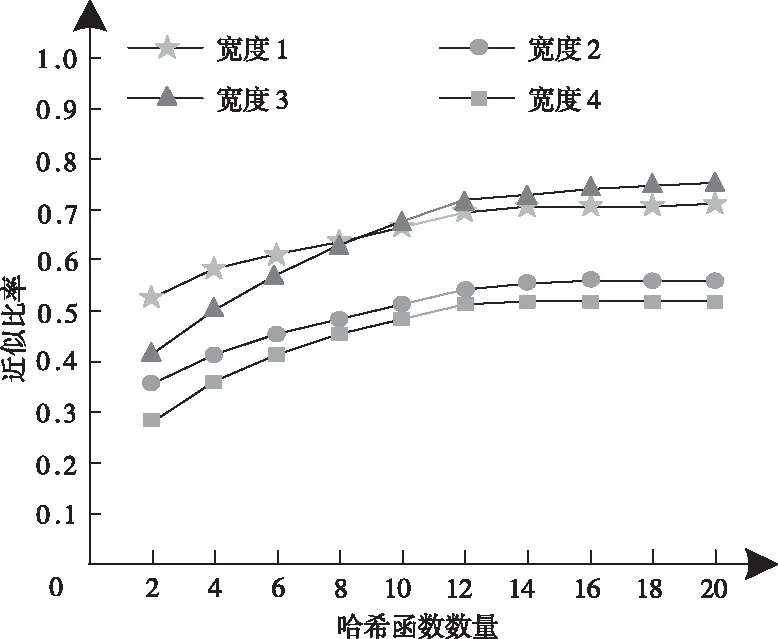
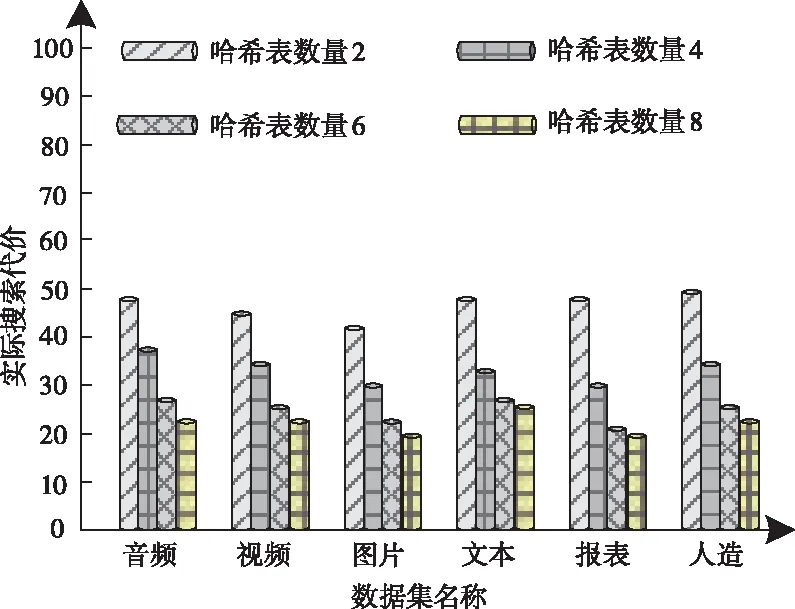
If((count+=getCount(bucketID of linei))/(average count)<ρ&&dist(bucketID of current bucketID) Flagi[bucketID]=flag Else 在上述桶合并过程中,AC为高维数据总数与组合哈希桶数量的比值;待合并桶数量和AC的比值用ρ描述,通常取值为1.5;待合并桶距离限制用cs描述;二级哈希内各线的桶号标记用Flagi描述;在0-1范围中,flag的变动形式用flag描述。 2)搜索阶段。 搜索对象用q描述,组合哈希向量用q′描述,可通过一次哈希形成,q′投影到直线的地点,可在实现二次哈希的基础上获得,查找直线中和q′拥有同样标记的桶号,并将桶内数据当作搜索对象的候选搜索集合[12]。 (b)桶号o′(〈5,7,3,1〉,100),表示通过AND过程后q的所得结果,则无须实现二次哈希,可将该桶内数据直接当作搜索对象的候选集。 (c)如果搜索对象完成一次哈希后,所得桶号内仅存在极少的数据,且实现二次哈希后,未找到拥有同样标记的其余桶,则是哈希函数出现问题,利用OR过程即可弥补。 高维数据一般由视频、图片等非结构化数据生成,选择五个大小与维度均存在差异的实际高维数据集,以及一个人造数据集作为实验对象,使用本文算法实现高维数据近似最近邻搜索,以验证该算法的搜索性能,数据集详情用表1描述。 表1 数据集详情 使用近似比率(Ratio)评价搜索算法的性能,它表示近似和真实最近邻的比值,其值与1越贴近,表明算法的搜索性能越优异。 将合并哈希桶数量设定成5,哈希桶宽设定成1,测试不同相邻桶距离(阈值ρ)下,传统LSH算法和改进的M2LSH算法的高维数据近似最近邻搜索效果,所得Ratio结果用图2描述。 分析图2可以看出,LSH算法和M2LSH算法的近似比率均随着相邻桶距离增加而降低;LSH算法的近似比率下降趋势明显,最大近似比率约为0.75,当相邻桶距离增加至20时,近似比率已降低至0.21;当相邻桶距离小于等于16时,M2LSH算法的近似比率保持在1左右,当相邻桶距离增加至20时,其最小近似比率与LSH算法的最大近似比率较为接近。对比以上结果可得,相邻桶距离对算法的搜索性能影响较大,本文算法优化后的高维数据近似最近邻搜索效果大幅度提升,且稳定性较好。 选取报表数据集完成搜索测试,将其规模设定为100,哈希桶宽度设置为1、2、3、4,分析不同哈希函数数量下,各哈希桶宽度对数据集搜索近似比率的影响,结果如图3。 图3 哈希函数数量和哈希桶宽度对搜索近似比率的影响 分析图3可以看出,随着哈希函数数量增加,不同哈希桶宽度对应的近似比率均呈上升趋势;在哈希函数数量小于12的情况下,近似比率上升速率较快,在超过12后逐渐趋于固定值;当哈希函数数量为2时,不同哈希桶宽度的近似比率较为接近,当哈希函数数量小于8时,哈希桶宽度为1的近似比率始终保持最高,当哈希函数数量大于8时,哈希桶宽度为3的近似比率处于最高数值,且仍有上升迹象。对比这些数据表明,哈希函数数量和哈希桶宽度对高维数据近似最近邻搜索具有较大影响,将两参数分别设置为12、3,不仅能获得更优异的搜索效果,还能极大地节省时间开销,无需持续增加哈希函数数量。 引入实际搜索代价评价本文算法的搜索能力,其值越低,表明算法的搜索效果越理想。将哈希表数量分别设定成2、4、6、8,测试本文算法搜索表1中不同数据集获得的实际搜索代价,结果用图4描述。 图4 不同数据集的实际搜索代价 分析图4可以发现,在哈希表数量不断增长的情况下,使用本文算法搜索不同数据集获得的实际搜索代价均随之降低,表明增加哈希表数量能够提升高维数据近似最近邻搜索效果;当哈希表数量从2增长至6时,各数据集对应的实际搜索代价下降幅度较大,当哈希表数量从6增长至8时,实际搜索代价下降速率显著减缓,表明在哈希表数量增长至一定程度后,对本文算法搜索效果的促进作用会逐步减小。 研究基于多级索引的高维数据近似最近邻搜索算法,在原有距离敏感哈希算法的基础上,提出二级距离敏感哈希算法,实现高维数据近似最近邻精确、稳定搜索。 为验证所提算法的有效性,设计仿真验证其应用有效性。通过不同参数的设定,验证该算法的搜索效果,以便采取针对性方案优化算法整体性能。根据所得的实验结果可知,该算法优化后的搜索效果大幅度提升,且稳定性较高。且该算法适用性极强,可为各类检测、辨识、预警等技术领域提供借鉴。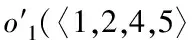
3 结果分析
4 结论
