基于隐私大数据的网络信息防泄漏推荐算法
2022-12-24江官星
黄 卫,江官星
(南昌航空大学科技学院,江西 共青城 332020)
1 引言
网络大数据日益增多,用户在海量数据中很难挖掘出所需数据[1],且由于数据库信息较多,搜索引擎得出的结果也较多,用户无法从中快速提取出所需目标数据,得出的结果仅能根据相关内容信息量完成排序,而不能根据用户真实的兴趣点提供相应内容[2]。同时部分用户在查找信息过程中不知如何描述关键词,无法得出理想数据,因此提出数据推荐算法。根据用户的历史信息以及关键词等信息预测出用户兴趣点并以此搜索相关信息向用户推荐,推荐算法的应用大大提高了工作效率,也进一步发展数据挖掘技术,大数据在网络化以及透明化的同时也对用户的信息产生威胁,即在向用户推荐信息的同时,用户的隐私数据可能暴露给不法分子,即为目前网络数据推荐算法需要优化的问题,现对网络信息防泄漏[3]推荐算法展开研究。
李家华[4]等人利用大数据设计出信息个性化算法,运用Map将推荐目标进行分解,得出结果后利用Reduce进行结合处理,其次在用户偏好获取算法下对用户兴趣点进行挖掘,实现网络信息的推荐。胡敏[5]等人首先获取用户的大量历史数据,并从不同角度收集用户的隐式行为特征,根据特征有效性过滤掉不可用的特征,进而建立出用户的潜在兴趣点模型,最终基于特征相关性原理建立出兴趣点特征函数,实现网络信息的推荐。以上两种算法没有提前对隐私数据进行变换和保护处理,不仅不能保证数据的稳定性,同时提高推荐算法的复杂度,导致其计算效率低下,准确度降低,存在算法性能低的问题。
为解决上述算法中存在的问题,提出基于隐私大数据的网络信息防泄漏推荐算法。
2 网络隐私数据保护算法
基于转换随机化方法实现隐私数据保护时,首先需要任意计算出一个符合大数据环境的隐私数据特征的变换函数,通过变换函数将原始数据进行转换,实现随机化回答[6]。
2.1 数据的变换
假设隐私大数据环境下的隐私数据集为A={a1,a2,…,al},其成分的均值为
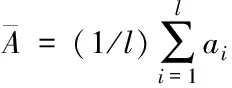
(1)
式中,l代表隐私数据的属性值,i代表数据特征向量,ai代表数据的损失内容。
数据A成分的方差表达式为
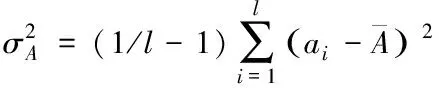
(2)
假设隐私大数据环境下固定存在的隐私数据集为B={b1,b2,…,bm},则B中的成分均值表达式为
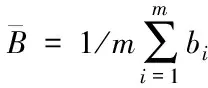
(3)
式中,m代表隐私数据在总样本数据中的比重,bi代表隐私大数据的实验样本。
数据B成分的方差表达式为

(4)
当隐私数据属于数值类别时,此时的数据随机函数表达式为
r(x)=b+ax
(5)
其中,r(x)代表隐私数据x的随机函数,a∈A,b∈B。
则隐私数据的变换处理公式为
y=r(x)
(6)
得出初始隐私数据集D的相应属性计算公式为
Y=R(X)
(7)
其中,R(X)代表与隐私数据较为类似的样本数据。
假设数据集X满足高斯分布原则,则隐私数据的无偏差预测量的表达式为:

(8)
式中,xi代表隐私数据随机化函数的参数值。
在计算过程中将均值设定为0,以此保证计算量最少,进而提高计算效率,此时的初始隐私数据x均值的估计值为

(9)
初始隐私数据x均值的计算公式为

(10)


(11)
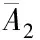


(12)
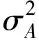

2.2 隐私数据保护算法
隐私数据保护算法[7,8]主要是根据数据特征划分出满足大小要求的簇,并求解出完成划分的簇中的节点个数,在增加边的技术下实现隐私数据的防泄漏。
第一步:计算隐私数据的量化信息丢失量。
随意提取网络中的一个簇,即Clt,该簇的标识符公式如下所示
Q=(n1,n2,…,ns,c1,c2,…,ct)
(13)
则Q在泛化的情况下生成的数据丢失量表达式为

(14)
其中,|Clt|代表网络隐私数据中簇内节点的总数,ni代表簇的节点度。
假设网络隐私数据共生成m个簇,此时数据的总丢失量表达式为
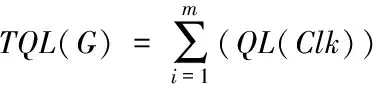
(15)
式中,G代表网络节点
第二步:计算隐私数据结构信息丢失量。
假设隐私大数据中网络节点G的表达式为
G=(V,E)
(16)
式中,V代表簇中某节点的集合,且V={v1,v2,…,vn},E代表节点连接的边。
则节点间可形成边的最大数量为

(17)
其中,vi代表簇内节点,k(vi)代表节点度,k代表隐私数据参数。
假设已知节点间的真实成边总数,则节点vi的聚集数量为
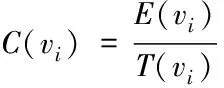
(18)
式中,E(vi)代表节点之间形成边的总数。
因此隐私大数据环境下G以及网络簇Clt的聚类系数之和的表达式分别为

(19)
其中,|CL|代表数据的限定阈值。
综上所述总结出数据丢失量的求解公式为
NTQL=FQL-EQL
(20)
若网络隐私数据簇中实际有N个节点,m个簇,则各个簇的中的实际使用用户计算公式为
Ni=N·(ni/(n1+n2+…+nm))
(21)
其中,ni代表簇的顺序为i的节点个数,且m≥i≥1。
最终确保所有节点连接稳定的情况下,筛选出节点个数最少的节点,将其与新节点进行连接,完成隐私大数据网络信息的防泄漏。
3 网络信息的推荐算法
大多的网络信息推荐算法[9,10]都是根据权重定制出用户专属的推荐内容,但这种推荐算法极易泄露用户的隐私信息。由于该算法需要收集十分详细的用户信息以此分析出用户可能存在的兴趣点,随着人们隐私信息保护意识增强,在不影响网络信息推荐的同时还需防止用户信息被泄露是现阶段的研究目标。
经研究发现,基于协同滤过的推荐算法是不影响推荐性能且不泄露用户隐私的最佳推荐算法,该算法主要将每种项目的特征分类到相应的群组内,根据每种群组的评价估计出用户对此项目的感兴趣程度,将这种行为称为群组的交互行为,根据交互行为可很好的显示出用户对项目的感兴趣程度,因此在推荐过程中需要提取项目特征并进行划分群组,当用户评价出群组中某个项目,根据同一群组内评价结果相似的特性进行推荐,且推荐的过程仅仅收集项目本身的特征,直接从根源上切断用户的隐私信息。
经总结,协同过滤推荐算法就是依据用户对相似特征项目的评价结果进行推荐,在计算过程中可根据项目属性特征向量建立出项目的特征近似矩阵,并将其与用户的评价矩阵进行融合,生成邻近项目群组,并充分估计填充矩阵,最终预测出项目感兴趣程度分数,进而完成信息推荐,具体计算过程如下所示。
首先构建出项目特征相似性模型完成近似项目的划分,构建此模型需要对项目特征数据进行量化处理,计算其相似性以及相似项目集合。
1)数据的量化处理
假设某项目被分成n个互不依赖的特征,此项目的n维向量表达式为
(ci1,ci2,…,cin)
(22)
式中,cin表示项目i的第n个属性的特征值。
2)项目相似度计算
项目相似度计算的表达式如下所示

(23)

项目特征的相似度计算是构建该模型的关键步骤,完成此步骤即代表完成了模型的构建。
为防止用户的项目评分矩阵过少,需要提前筛选出至少评价过其中一种项目的用户,则评价过项目的用户集合为
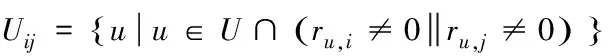
(24)
式中,u代表用户,ru,i代表用户对项目i的评价结果,ru,j代表用户对项目j的评价结果。
利用相似特征群组的评价对未进行评价的项目的评分进行估计,最终生成目标项目的最近邻居。
则用户集对项目i的评分表达式为

(25)
式中,rui=0代表用户未评价过项目i,pui代表预测评分,rui代表实际评分。
若用户已评价过项目i,此时的评分为rui,反之,可利用实际评分rui进行pui的预测,其公式为
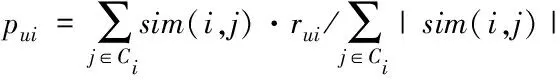
(26)
式中,Ci代表项目i的特征。
最终根据项目实际评分rui和预测pui筛选出用户的兴趣点,并将其推荐给用户,完成网络数据的推荐,同时防止隐私数据的泄露。
4 实验与结果
为了验证基于隐私大数据的网络信息防泄漏推荐算法的整体有效性,分别采用所提算法、文献[4]算法和文献[5]算法进行推荐算法性能的测试,测试结果如下:
4.1 推荐算法准确性能
仅仅计算算法准确率不足以证明推荐算法的准确性,为精确算法的推荐性能,对比三种的平均绝对误差,其公式为
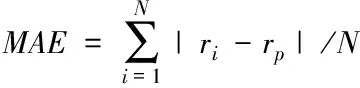
(27)
式中,rp代表项目i的预测评分,ri代表项目i的实际评分,MAE代表平均绝对误差。
由于MAE更能准确反映算法的准确性能,在同一环境下进行五组实验,比较三种算法的MAE值,MAE越低说明算法的准确率越高。
选取五组样本数据进行实验,每组数据种类以及类型均不相同,结果如图1所示,所提算法得出的平均绝对误差最小,其次是文献[4]算法,误差最大的是文献[5]算法。该实验结果验证了所提算法具有理想的准确性,这是因为所提算法提前对隐私数据进行转换和保护,从而简化数据,同时保证数据的稳定,加强了数据的推荐性能,进而降低推荐算法的平均绝对误差。

图1 三种算法的平均绝对误差
4.2 兴趣点覆盖率
推荐算法的目的是将所有用户感兴趣点的项目推荐给用户,推荐结果是否全面也是测试算法性能优劣的一大指标,即计算算法的覆盖率大小,其表达式为

(28)
式中,M代表项目预测分数的个数,|Ω|代表隐私数据的评分总数,RC代表项目评分覆盖率。
比较三种算法的RC值,RC值越高,说明评分的项目数量越多,即越全面,进而证明算法的性能优。

图2 不同算法的覆盖率
根据结果可知,每组实验中覆盖率最高的均是所提算法,其余两种算法的覆盖率均远低于所提算法,说明文献[4]算法和文献[5]算法项目评分不完整,导致推荐结果不完善,极可能遗落很多可推荐的兴趣点,降低推荐算法的性能,从而验证所提算法的有效性。
4.3 F1值
F1值是统计学中评价算法性能的一大优良指标,是精确率和召回率的调和平均,因此该指标可直接反映算法的优劣。
F1值的公式如下所示
F1=(2×precision×RC)/(precision+RC)
(29)
式中,precision代表推荐算法的精确度,其公式为
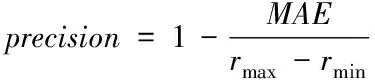
(30)
式中,rmax表示计算过程中项目的最高评分,rmin表示计算过程中项目的最低评分。
根据式(29)可知,F1值越大说明算法的精确度等性能均较优。根据图3可知,在每组实验中最高的F1值都是所提算法,因此证明网络数据推荐最精确的为所提算法,其余两种算法均不可取,证明了所提算法的优越性。

图3 三种算法的F1值
5 结束语
在大数据环境下,为保证不降低用户推荐兴趣点性能的前提下还可保护用户隐私,提出基于隐私大数据的网络信息防泄漏推荐算法,该算法首先对隐私数据进行转换和保护处理,其次利用协同滤过原则得出兴趣点的评分,完成兴趣点的推荐,实现网络信息防泄漏推荐,解决了推荐算法性能差的问题,保证用户的用网安全,也确保用户获取完整的兴趣点。
