基于关系代数的非连续数据路径挖掘算法
2022-12-24薛欢庆范广玲
薛欢庆,张 玲,范广玲
(1.大庆师范学院数学科学学院,黑龙江 大庆163712;2.东北石油大学数学与统计学院,黑龙江 大庆163311)
1 引言
随着无线网络通信业务量的持续增长,网络通信数量也随之不断上升,按照数据特征将此类数据划分为连续与非连续数据。对于无线网络而言,数据的传输质量与有效利用率是决定其整体通信质量高低的关键[1]。由于连续数据的特点为数据具有较高的连续性、规律性,对其实施归纳较为简单;而非连续数据的特点为信息量庞大、数据间断无明显规律,对其实施归纳较为困难[2]。因此,为提升无线网络的整体通信质量,主要需提高非连续数据的传输质量与有效利用率。在无线网络的数据通信过程中,通过选取不同节点实施数据路由,能够获得各种数据路径,针对非连续数据传输质量与利用率的提升,需由诸多路径内寻求出合适的非连续数据路径实现,而由于非连续数据规律性较差,故而寻求合适路径的前提即为对非连续数据关联规则的挖掘[3,4]。
关系代数属于一类查询语言,可针对关系与其运算实施研究,并通过运算关系对查询实施描述,其也可被看作是研究关系数据语言的一种数学工具,能够通过关系描述各种实体之间的不同关联。它的运算对象与结果均为关系,所运用的基础运算有笛卡尔积、差与交等,运算符主要有逻辑与集合运算符、比较符以及关系符等,常被应用于各类关联规则的挖掘当中[5]。通过运用关系代数挖掘出无线网络数据库内非连续数据的关联规则后,需选取恰当的方法依据此关联规则将无线网络内的非连续数据路径挖掘出来。
分类属于挖掘领域内的关键研究方向,能够实现对所挖掘内容类模型的有效表达,同时对以后的趋势实施有效地预估。以数据集的特点为依据,将一个分类模型生成,通过所生成模型向已给定类别中的任意一种映射未知类别的样本,此即为分类的目标[6,7]。当前主要运用的分类算法之一即为支持向量机(SVM)方法,该方法属于一种机器学习法,是在统计学习的基础上,将最佳分类面建立于空间内,得到分类器后达到分类未知样本的目的[8]。该方法的特点为能够对非线性问题实施有效处理,且泛化能力较高,其关键缺陷为训练与分类速度不够高。粒子群优化算法属于一类智能优化算法,其优点为收敛速度高、运算简单、运算精度高等,是当前较为常用的一种优化算法[9]。
综合以上分析,本文研究一种基于关系代数的非连续数据路径挖掘算法,通过运用关系代数将网络数据库内非连续数据的关联规则获取到,结合粒子群优化算法改进支持向量机,获得改进FSVM,并向改进FSVM内输入所获得的非连续数据关联规则,运用关联规则寻求适合非连续数据传输的路径,实现非连续数据路径的分类挖掘,提升无线网络中非连续数据的传输质量与利用率,为提高无线网络的整体通信质量提供保障。
2 非连续数据路径挖掘算法研究
2.1 基于关系代数的非连续数据关联规则挖掘
挖掘非连续数据传输路径的关键前提是对非连续数据关联规则的挖掘,依据所挖掘的关联规则,获得非连续数据的传输路径。在此选用基于关系代数的关联规则挖掘算法,对无线网络数据库内非连续数据的关联规则实施挖掘。
通常大部分数据库中均包含用户信息、数据项集以及标识符等海量非连续数据,通过相应的数据预处理方法将非关键属性数据删除掉,得到数据样本模式类似的数个特征子集,为令非连续数据关联规则挖掘更高效,可在所获得的各个特征子集上分别实施关联规则挖掘实现[10]。寻得大项集是关联规则挖掘的重点,因此以关系代数理论为基准,通过运用关系矩阵与相应计算提出基于关系代数的非连续数据关联规则挖掘算法(ORAR),获得大项集[11]。ORAR算法仅需对数据库实施单次扫描,运算效率、可伸缩性及并行性较高。
设项集与基础数据库分别以B和J表示,二者集合的笛卡尔乘积以B×J表示,其中,基础数据库中包含大量非连续数据,且J={j1,j2,…,jk};交易集以S表示,且S={s1,s2,…,sz};笛卡尔乘积的随意一个子集均为由B至J的二元关系,则数据库J为最高的此种二元关系。矩阵R可表示成

(1)
式中,由S至J的二元关系矩阵以l=1,2,…,z、i=1,2,…,k表示。通过数据预处理后获得与数据库J有关的特征子集,假设与某个特征子集相对应的集合属于某个关系数据库的子集,该子集以BDj表示,且其构成为元组(TID,itemset)对。子集BDj内的每条记录均与一个样本相对应,该子集内对应属性由样本内的不同分量组成。将子集BDj内的非关联属性TID删掉,仅对与项集相对应的属性予以考量,如果该子集中具备的记录与项数量分别为a个与c个,那么对数据库实施单次扫描后,所获得的关系矩阵R可表示为

(2)
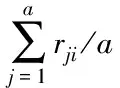
1)1-L-Itemset的确定:以最低支持度阈值t与关系矩阵R作为输入,确定步骤如下:
a.for i=1 to c
b.{mi=0;
c.for i=1 to a
d.mi=mi+rji
e.mi=mi/a}
f.for i=1 to c
g.if mi≥t then 输出1-L-Itemset{i}
2)2-L-Itemset的获取:由于大项集的子集必然属于大项集,故可基于1-L-Itemset{i}将2-L-Itemset得到。假设1-L-Itemset的集合以M表示,则mj内具备对应的1-L-Itemset,j=1,2,…,z,以l表示该集合内第l个属性的标识,也就是集合M内存在z个元素,且z≤c。故以阈值t、关系矩阵R及集合M作为输入,可获得2-L-Itemset{ji}。
3)l-L-Itemset的获取:已知两条引理,其一为若某个项集不属于大项集,那么随意某个存在此项集的集合均不属于大项集;其二为若存在(l-1)-L-Itemset,以{j1,j2,…,jl-1}表示,且该大项集的对应向量以b表示,当项w存在时,令rijl-1与riw(i=1,2,…,a)的支持度比阈值t低,那么{j1,j2,…,jl-1,w}不属于l-Itemset。
假设{j1,j2,…,jl-1}属于(l-1)-L-Itemset,如果{jl-1,w}无法组成2-L-Itemset,那么{j1,j2,…,jl-1,w}项集则无法组成l-Itemset,即该项集不属于l-L-Itemset;如果{jl-1,g}能够组成2-L-Itemset,那么能够将{j1,j2,…,jl-1,g}扩展成l-Itemset,在DWj1∧DWj2∧DWj3…DWjl-1∧DWg时,{j1,j2,…,jl-1,g}即可组成l-L-Itemset。假设存在(l-1)-L-Itemset{j1,j2,…,jl-1},将全部此类大项集与阈值t输入,其中令l>2,生成全部对应的l-Itemset,直到不能继续生成时停止,获得l-L-Itemset。
综合以上过程,实现基于关系代数的非连续数据关联规则挖掘,获得数据库内非连续数据的关联规则,为接下来实施非连续数据传输路径挖掘提供依据。
2.2 基于关联规则的非连续数据路径挖掘
结合基础支持向量机与粒子群优化算法,获得改进的模糊支持向量机模型,将所获得的非连续数据关联规则输入到此模型内,实现对无线网络内非连续数据路径的分类挖掘。
2.2.1 基础支持向量机
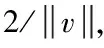
yi(v·x+e)-1≥0,i=1,2,…,n
(3)
式中,偏移量以e表示;与超平面垂直的向量以v表示。经由支持向量机对输入空间实施非线性变换后,获得高维空间,在此空间内对最佳线性分类面实施求解。变换中应用的核函数为RBF,表达式为
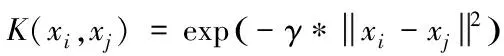
(4)
式中,核参数以γ表示,同时γ>0。
2.2.2 改进的模糊支持向量机
1)有效的待选支持向量预选取
在此将训练样本集划分成正、负两类,由该样本集内预选取出有效的待选支持向量。主要分为以下两种情形:
①线性可分:设已知样本向量组以{x1,x2,…,xn}表示,那么中心o即为此类样本的平均特征,可表示为

(5)
②非线性可分:通过非线性函数将两个已知向量x与y向特征空间内映射,那么在此空间内二者的欧氏间距可表示成

(6)
式中,核函数以K(·)表示。则此空间样本的中心向量0θ可表示成
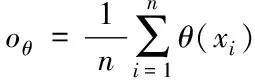
(7)
以式(5)或者式(7)为依据,将正类与负类中心0+、0-运算出来,同时对二者的间距实施运算,即
d′=|o+-o-|
(8)
对两类样本集内全部样本与异类中心o之间的间距依次实施运算,并选取出比d′小的样本,以此类样本作为待选支持向量,所运用的运算公式为
d″=|xi-o|
(9)
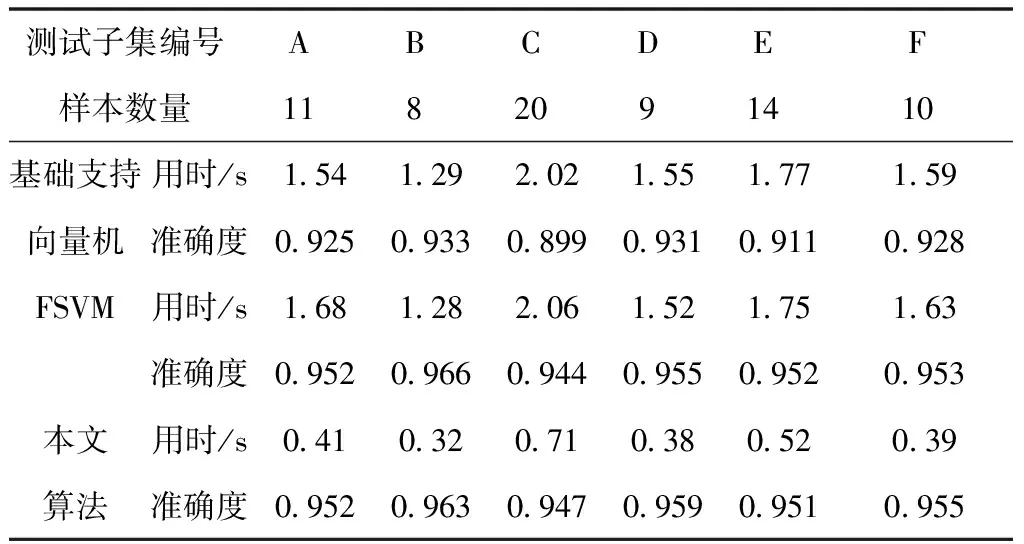
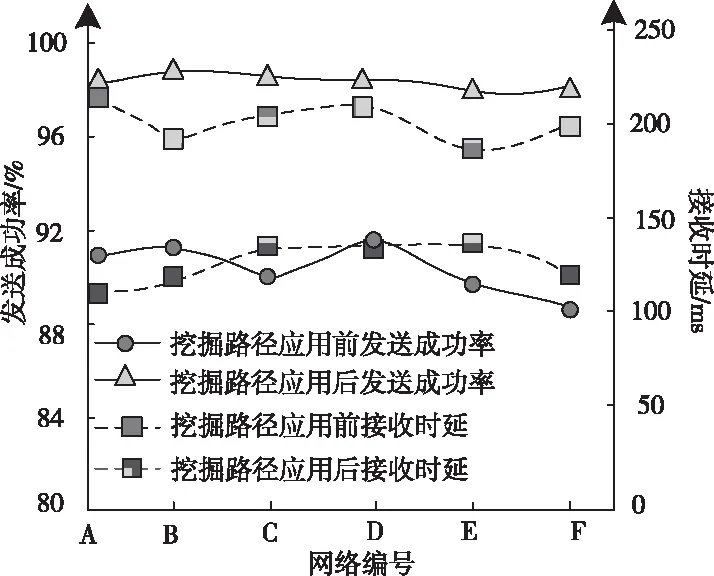
也就是将d″ 2)全新模糊隶属度函数 由于改进的模糊支持向量机(FSVM)是通过与超平面间距最小的点获得最佳分类面,也就是通过支持向量获得的,但一般情况下,支持向量所处位置为与类中心相距较远处,故而所得到的隶属度较小,易造成分类超平面与最佳分类面的偏离[13]。为解决此问题,提出一种全新的隶属度函数,令样本的隶属度与类中心间距成正比。通过式(5)或者式(7)能够获得0+与0-,则各正类样本与正类中心、各负类样本与负类中心的间距分别表示为 (10) 设预选取支持向量之后的正类与负类样本分别以X+和X-表示,那么全新的隶属度函数可表示为 (11) 式中,足够小的正数以Ф表示,防止ui=0的状况产生。 3)快速FSVM分类挖掘算法 经由以上过程对FSVM实施训练,在训练时发现部分训练样本并未起到作用,因此,为有效降低运算量,提升实际分类挖掘效率,需对支持向量实施有效地缩减。以保证FSVM分类挖掘精度为前提,选用粒子群优化算法缩减支持向量,提升分类挖掘速度[14]。通过对FSVM实施训练后,获取到支持向量集的模糊隶属度向量,选用此向量当作粒子群优化算法的粒子,适应度函数选取为测试集的平均分类挖掘误差,挑选出最佳支持向量子集对支持向量实施有效缩减,实现分类挖掘速度的有效提升。具体过程如下: ①粒子群优化算法:粒子的移动间距与方向由粒子的速度决定,粒子速度的调整与其本身及其余粒子的移动经验保持同步,以此达到可解空间内的个体寻优[15]。设某个搜寻空间的维度为F,此空间内第i个粒子的速度与位置属性分别以Vi与Yi表示,且Vi=(v1,v2,…,viF)、Yi=(yi1,yi2,…,yiF);该粒子的全局与个体极值分别以Qh与Qi表示,且Qh=(qh1,qh2,…,qhF)、Qi=(qi1,qi2,…,qiF),则粒子的速度更新公式可表示成 (12) (13) ②编码方式:粒子群优化算法的各个粒子均代表一个解,运用该算法简化FSVM的支持向量,对FSVM实施训练后所获取的m个支持向量即为粒子维数;支持向量集的每个子集对应一个粒子,以式(11)为依据,运算此类样本的隶属度;设所得隶属度在umin~umax区间内,将初始化粒子的位置区间选定为此区间,初始化粒子群空间内的某个粒子为运算所得的m个样本权重向量,各粒子均具备自身的速度与位置;其中,样本的隶属度通过位置表示,通过速度调整;预先给定阈值,当粒子向外输出时,若隶属度比此阈值高,则此隶属度值不实施调整,选定此样本,反之则将隶属度调整成0,不选取此样本。 ③适应度函数:由初始训练样本内任意选取40%样本当作测试集,在待选支持向量预选取、全新隶属度函数设定及粒子群优化算法缩减FSVM训练后支持向量的基础上,以所选取测试集的平均分类挖掘误差为粒子的适应值,故适应度函数可表示成 (14) 式中,真实值与预估值分别以pi和pi′表示;测试集的总样本数以M′表示。 2.2.3 基于改进FSVM的快速分类挖掘过程 基于改进FSVM的快速非连续数据路径分类挖掘算法过程为: 1)将非连续数据关联规则、训练样本集S′={(x1,y1),(x2,y2),…,(xn,yn)}输入到改进FSVM内,依据式(5)或者式(7)将正、负类中心得出,同时运用式(8)运算出二者的间距; 2)通过式(9)依次对正、负两类样本与各自类中心的间距实施运算,同时由其中挑选出间距比正、负类中心间距低的样本,将此类样本当作待选支持向量,构成有效待选支持向量集合; 3)通过式(10)求得样本的隶属度,将模糊化的待选支持向量集合获取到,对此集合实施FSVM训练后获取支持向量集合; 4)对粒子群实施初始化,并将运算所得的m个支持向量的权重向量当作初始化后该粒子群的某个粒子; 5)将其中全部粒子的位置留存下来; 6)分别对留存的粒子位置实施判别,若此位置比设定阈值高,那么不对此位置实施更改,反之则将此位置变成0,由此选出支持向量子集; 7)对通过各粒子选出的各个支持向量子集依次实施FSVM训练,将判别函数获取到,以此函数为依据,测试所选取测试集,同时通过式(14)对粒子的适应度值实施运算,以运算所得结果为依据,对粒子的个体与全局最佳位置分别实施调节; 8)运用式(12)、(13)对粒子群实施更新,对能够达到循环终止条件实施判别,若适应度值不发生改变,即可终止并将最终结果输出,反之则跳回至第5)步; 9)通过所得输出结果对FSVM实施训练后,将缩减支持向量之后的决策函数获取到,运用此函数结合非连续数据关联规则实现非连续数据路径的分类挖掘。 实验采用MATLAB仿真工具箱进行仿真分析,随机选取15种网络构成复杂网络,整体复杂网络共具备350个节点,1250Byte数据流,其中非连续数据流为570Byte,整体复杂网络共包含168条数据路径。运用本文算法对实验网络实施非连续数据路径挖掘,检验挖掘过程中本文算法的挖掘性能,以及实验网络应用本文算法所挖掘路径实施非连续数据传输后的实际效果,以此分析本文算法的综合性能。 由15种网络内随机选取9个网络的数据路径作为训练样本实施训练,其余6个网络的数据路径作为测试样本实施测试,其中,训练样本内的样本数为96,测试样本内的样本数为72。检验本文算法引入粒子群优化算法改进FSVM过程中,各阶段对训练样本实施正、负类样本分类的效果,分析本文算法的改进效果。主要包含基础支持向量机阶段、FSVM阶段及粒子群优化阶段的分类结果,所得结果如图1所示。 图1 本文算法各阶段的正、负类样本分类结果 通过图1可看出,FSVM阶段与基础支持向量机阶段分类所得的正、负类样本数量几乎相同,而粒子群优化阶段分类所得的正、负类样本数量均低于前两个阶段,原因是此阶段在FSVM的基础上引入了粒子群优化算法实施改进,有效约简了支持向量,减少了样本数量。 将测试集分成6个子集,每个子集对应一个网络(A~F),子集内的样本数对应网络内的数据路径数量,运用本文算法对各个子集分别实施数次分类挖掘实验,将各个子集内的非连续数据路径挖掘出来,统计本文算法数次挖掘的分类挖掘用时与精度,以数次实验的平均值为实验验证结果,并将所得结果与基础支持向量机、FSVM的结果实施对比,检验本文算法的挖掘性能。所得检验结果如表1所示。 表1 本文算法的挖掘性能检验结果 分析表1能够得出,本文算法对6个测试子集的平均分类挖掘用时为0.455s,平均准确度值为0.955,而基础支持向量机对6个测试子集的平均分类挖掘用时与平均准确度分别为1.627s和0.921,FSVM对6个测试子集的平均分类挖掘用时与平均准确度分别为1.653s和0.954,综合可见,本文算法的平均准确度与FSVM十分接近,但平均分类挖掘用时较基础支持向量机与FSVM而言,分别降低了72.03%和72.47%,原因是本文算法运用粒子群优化算法改进FSVM,实现对支持向量的有效约简,显著减少样本数量,降低分类挖掘用时,保障分类挖掘精度的同时,提高最终的分类挖掘速度。 以测试集内的6个实验网络为例,检验各网络应用本文算法所挖掘路径前后,非连续数据传输的实际效果,选取非连续数据发送成功率与接收时延作为检验指标,统计所得检验结果如图2所示。 图2 本文算法挖掘路径应用前后各网络数据传输效果 由图2能够得出,未应用本文算法挖掘路径时,各实验网络的非连续数据发送成功率介于88.6%~91.8%之间,非连续数据接收时延位于180ms~220ms之间,而应用本文算法所挖掘路径后,各实验网络的非连续数据发送成功率达到97.5%~98.8%区间,接收时延位于115ms~135ms之间,由此说明,应用本文算法所挖掘的非连续数据路径后,能够显著提升网络的非连续数据发送成功率,并降低非连续数据接收时延,提升网络的非连续数据传输效果与数据利用率,有效改善网络的非连续数据通信质量。 网络通信中非连续数据的传输质量与利用率高低,直接影响着网络通信的整体质量,同时也影响用户的使用感受,为提升网络的整体通信质量,提高用户的满意度,本文针对一种基于关系代数的非连续数据路径挖掘算法展开研究,通过基于关系代数的关联规则挖掘算法,获取到网络数据库内非连续数据的关联规则,在基础支持向量机的基础上,通过预选取待选支持向量、设定全新隶属度函数及粒子群优化算法约简支持向量后,获得改进的FSVM,将所获取的非连续数据关联规则输入改进的FSVM,实现对非连续数据路径的分类挖掘,实际应用结果表明,本文算法可在保障挖掘精度的前提下,通过有效约简支持向量,减少正、负类样本的分类数量,显著降低挖掘用时,提升整体挖掘效率;将本文算法所挖掘路径应用到实验网络中,能够有效改善实验网络对非连续数据的发送与接收效果,提高网络的非连续数据利用率与通信质量。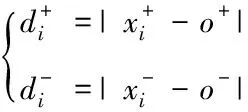
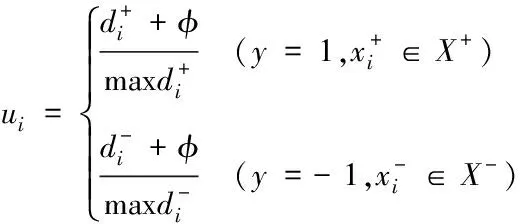
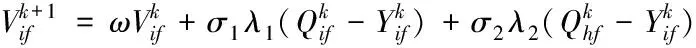
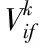
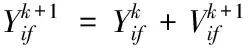
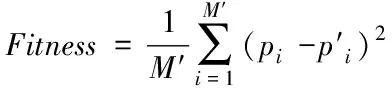
3 实验结果分析

4 结论
