基于贝叶斯网络的老年综合评估过程简化方法
2022-12-24李关东邹函怡王艺桦许杨孙怡宁马祖长高理升
李关东 邹函怡 王艺桦 许杨 孙怡宁 马祖长 高理升
0 引言
当前,我国人口老龄化进程显著加剧。第七次全国人口普查数据显示,我国60岁及以上人口有26 402万人,占总人口的18.70%,与第六次普查数据相比上升5.44%[1]。人口老龄化将增加家庭养老负担,并带来基本公共服务供给的压力。为积极应对老龄化,2019年国务院颁发了《关于推进养老服务发展的意见》,文件中明确指出,通过政府购买服务,统一开展老年人能力综合评估,并将评估结果作为领取补贴、接受养老服务的依据[2]。因此,发展适宜在社区大规模推广开展的老年综合评估方法具有紧迫而重要的实际意义。
老年综合评估(comprehensive geriatric assessment,CGA)是指采用多学科方法评估老年人的躯体情况、功能状态、心理健康和社会环境状况等,并据此制订以维持及改善老年人健康和功能状态为目的的治疗计划,最大程度地提高老年人的生活质量[3]。目前CGA主要分为综合评估测量和单项评估累计测量[4]。综合评估工具内容繁杂,评估耗时耗力,难以普及使用。单项评估工具在单一维度评估中准确便捷,但累计多项工具评估同样丧失其简捷性。评估过程冗长繁琐易引起老人的烦躁情绪,进而影响评估结果的准确性,难以在社区开展大面积筛查评估工作[5]。
为解决上述问题,学者们使用多种方法对问卷内容进行简化。李苗苗等[5]通过文献分析和专家会议法初步设计CGA指标体系框架和快速筛查条目,并采用Delphi专家函询法进一步修订,最终构建CGA快速筛查指标体系,相较传统综合评估量表,问题数明显减少。Tai等[6]首先通过ROC曲线和约登指数确定躯体功能截断值,再使用逐步logistic回归筛选老年综合征的危险因素,最后根据分析结果从常用CGA工具中筛选题项,最终形成简明综合评估工具。这些研究使用专家知识或者统计学方法,通过直接删减部分问题达到了简化量表的目的。然而,删减问题将会影响量表的准确性[7]。评估过程中准确性和便捷性不可兼得的问题难以解决。
随着计算机技术的发展,有学者尝试使用智能化方法辅助简化CGA流程。Daniel等[8]通过推导的分支规则构建了可应用于老年综合评估的数据挖掘算法,但该方法仅适用于二元问题,具有较大局限性。Mo等[7]基于提出的影响力算法构建了快速前向问卷模型(fast preceding questionnaire model,FPQM),该模型对问卷问题进行预测与重排序。该方法在保证问卷结构完整的前提下减少了调查题项。但模型空间占用量巨大,不利于推广使用;此外模型的准确性仍有提升空间。
贝叶斯网络是一种表示不确定性信息的概率图模型,它一方面直观易懂[9],方便学者交流和建模,另一方面又具备严格的数学证明,适合计算机处理[10],被认为是人工智能领域最重要的研究成果之一。Aburai等[11]对富士商业街居民和游客的需求进行问卷调查,利用贝叶斯网络独特的可视化能力和概率推理能力,分析问卷题项之间的因果关系,并对潜在游客进行预测估计,为构建更有效实用的规划建筑提供了参考依据。贝叶斯网络可推理问卷问题的回答,基于此特性便可进一步实现简化评估过程的目的。
本文利用贝叶斯网络发掘问卷题项间的关联,并提出一种用于CGA的问卷调查算法,以解决评估过程中准确性和便捷性不可兼得的问题,并与前文所述的FPQM进行比较分析,探究该方法在简化CGA中的应用价值,为普及社区CGA工作提供一种可行的技术手段。
1 实验数据与预处理
1.1 实验数据
本研究数据来源于北京大学健康老龄与发展研究中心[12]组织的中国老年健康影响因素跟踪调查(Chinese Longitudinal Healthy Longevity Survey,CLHLS),在全国23个省(自治区、直辖市)随机抽取约一半的县市,前后总共进行了8次跟踪调查。该调查数据质量经过评估得到国内外学者普遍认可,已成为学界公认类似调研中数据信息十分丰富和研究潜力巨大的交叉学科研究项目。该调查对象为65岁及以上老人,调查内容包括了老人生理心理健康、认知功能、社会参与、社会经济状况、生活习惯等。
1.2 数据预处理
本研究采用2018年横断面调查数据,该数据包含15 874例数据。以CGA中国专家共识[3]和民政部2013年颁布的老年人能力评估标准[13]为指导,CGA主要包含日常生活活动能力、精神状态、心理健康、感知觉等维度,本研究据此筛选数据集中与CGA内容相关的49项题目,并对回答缺失或无效的样本进行剔除,最后随机抽取其中958例数据用于构建模型和性能测试。认知功能题项中的反应能力、计算能力、记忆力和语言理解中题目有顺序要求,应分别当作整体进行评估,因此分别对相应题目进行计分并作为单变量输入,最终输入属性为38个,详细内容如表1所示。
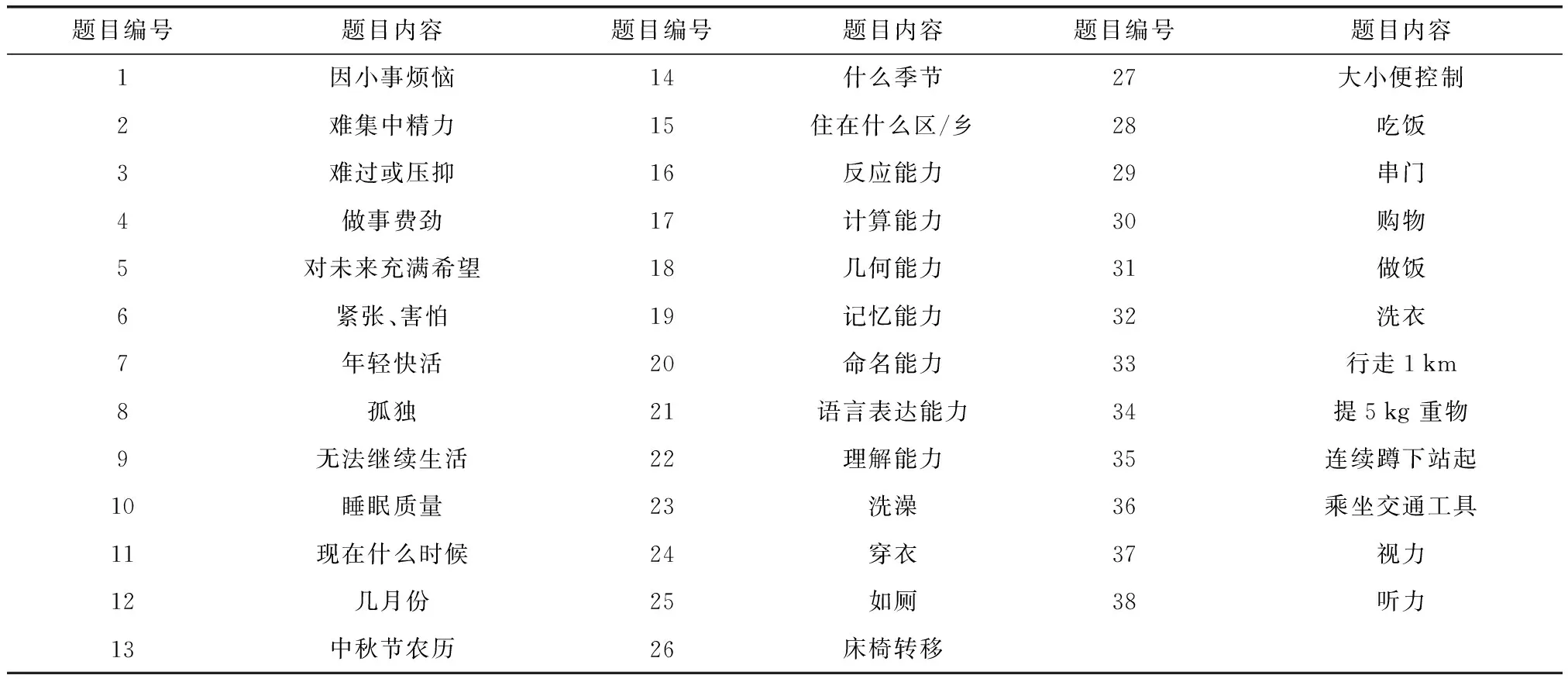
表1 问卷题项内容Table 1 Questionnaire items
2 算法设计及评价方法
2.1 问卷模型构建
本研究首先通过贝叶斯网络发掘并计算问卷题项之间的关系,并以此构建问卷模型。其中度量问卷题项间的关系对应结构学习过程,计算属性间关联强度对应参数学习过程。
基于评分搜索的结构学习[14]将在所有可能存在的结构Gn中寻找一个评分最高的结构G*,评分函数用以度量搜索空间中每个结构与样本数据的拟合程度。以BIC评分函数为例,其评分函数主要基于信息论的最小描述长度(minimum description length,MDL)原理实现,该评分准则将在网络精度与复杂度之间寻找一个平衡点。
基于贝叶斯估计的参数学习[15]先将待估条件概率表参数Θ视为随机变量,并将关于Θ的先验知识表示为先验概率分布,在观测到前l个样本的完整数据后,计算Θ的后验概率分布以及下一个样本Dl+1的概率分布。
2.2 问卷调查算法
本研究提出一种基于贝叶斯网络的问卷调查算法,其可抽象为遍历网络结构G,通过实际问询或者推理计算获取每个属性的取值。算法的流程如图 1所示,主要步骤如下。
(1) 对于贝叶斯网络结构G= (V,E),首先对V按入度从小到大进行排序,优先选择从入度较小的结点开始遍历。
(2) 已遍历结点取值作为证据集,推理当前访问结点的所有取值的概率P,选取其中最大值与输入的超参数阈值σ进行比较,如果P≥σ,则该结点通过推理计算预测取值,否则通过实际问询老人得到回答,同时将取值加入证据集。
(3) 继续遍历剩余结点并执行步骤(2),直到所有结点访问完毕,获得最终调查结果。
由于贝叶斯网络支持多种推理类型,因此结构G的遍历可以选择如下4种方式。
(1) 单向深度优先搜索(DFS):从一个结点V0开始,先访问其中一个子结点V1,再从V1开始访问它的子结点,重复上述过程直到结点全部被访问。
(2) 单向广度优先搜索(BFS):从一个结点V0开始,先访问它所有的子结点{Vchild},之后再依次访问{Vchild}的子结点,重复上述过程,直到结点全部被访问。
(3) 双向DFS:从一个结点V0开始,先访问其中一个子结点或父结点V1,再从V1开始访问它的子结点或父结点,重复上述过程直到结点全部被访问。
(4) 双向BFS:从一个结点V0开始,先访问它所有的子结点和父结点{Vchild,Vparent},之后再依次访问{Vchild,Vparent}的父子结点,重复上述过程,直到结点全部被访问。
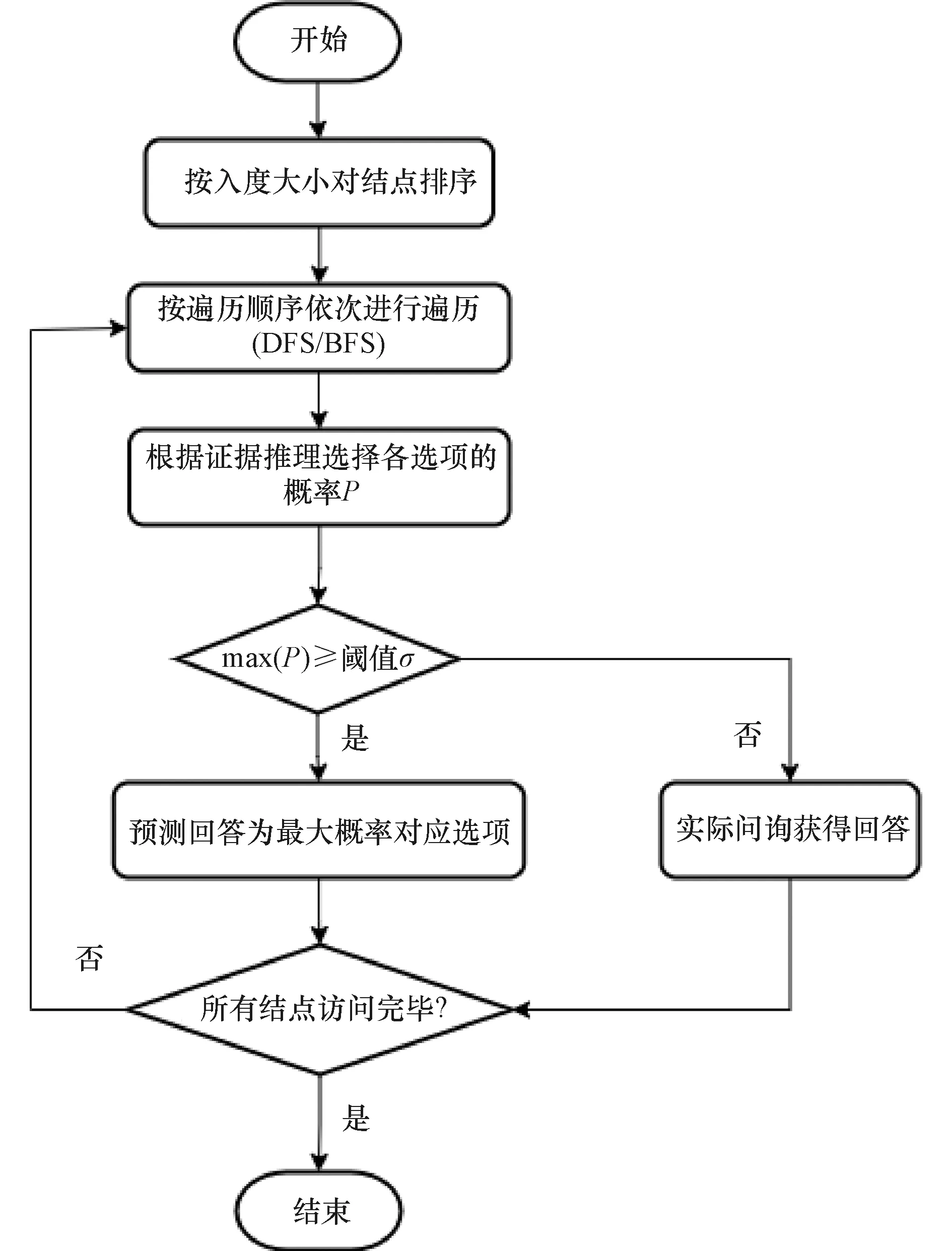
图1 算法流程图Figure 1 Flowchart of the algorithm
2.3 算法评价指标
本算法目的为同时保证评估过程的准确性和简捷性,因此评价指标主要由准确率和简化率构成。涉及的定义如下:个体准确率表示正确预测的问题在所有预测问题中的占比,平均准确率(average accuracy rate,AAR)是数据集中所有个体准确率的算术平均数,评价算法整体准确率。

(1)
式中:m表示测试集样本容量;Cij为第i个个体的第j个问题的预测正误标记,预测正确为1,否则为0;Iij为第i个个体的第j个问题的预测标记,成功预测为1,否则为0。
个体简化率表示预测的问题在问卷中的占比,平均简化率(average reduction rate,ARR)是数据集中所有个体简化率的算术平均数,评价算法整体简化率。
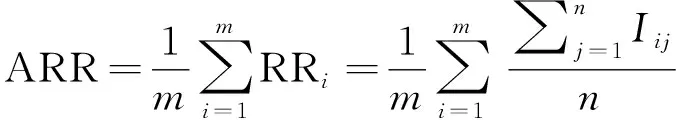
(2)
式中:n表示问卷问题数。
AFβ综合考虑平均准确率和平均简化率两个指标,用于评价算法的性能。
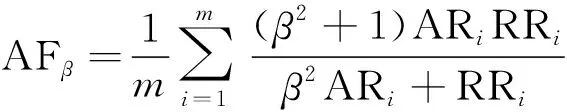
(3)
式中:β为设定参数,可根据实际需要对准确率和简化率的权重进行调整。AFβ越大表示算法的性能越高。当Iij= 0时,ARR=0,AAR=1恒成立;则AFβ=0。当Iij= 1时,ARR=1恒成立;则AFβ和ARR都会很低。因此需要选取合适的Iij使AFβ最大,Iij取决于阈值σ与遍历模式。
2.4 试验流程
将抽取的958例数据按7:3的比例划分训练集和测试集,其中训练集用于构建贝叶斯网络,测试集用于评价算法性能。贝叶斯网络基于Python的pgmpy库实现,pgmpy库完全使用Python语言实现贝叶斯网络,支持多种结构学习、参数学习和推理算法。
3 实验结果
3.1 实验环境及参数设计
本实验在PyCharm 2021.2.1中编写程序并运行。试验硬件配置:CPU为AMD Ryzen 5 3500U @ 2.10 GHz,内存为20.0 GB,操作系统为Windows 10。
本实验使用爬山法对贝叶斯网络结构进行搜索,并通过BIC评分函数筛选最优网络结构。采用贝叶斯估计进行模型参数学习,使用变量消元法对属性进行精确推理。在评价指标中,设置AFβ的β=0.5,表示准确率重要程度为简化率的2倍。调查算法中的超参数阈值σ从0.95开始以0.05为单位依次减小进行试验,每种阈值条件下分别进行4次不同遍历模式的试验,最终选取AFβ最高的参数组合作为最优参数。
3.2 贝叶斯网络结构
通过训练集学习得到的贝叶斯网络结构,使用Netica软件对其进行可视化展示,由于网络结构复杂,本文仅以部分结点为示例,如图 2所示。每个结点即一个问题,网络同时存储每个选项出现的概率,结点之间通过有向边连接,表示存在依赖关系。调查开始时,算法从上到下依次执行搜索策略,当任意一个问题的回答确定后,网络将及时自动更新其他问题选项的概率。在积累足够信息后,算法便可推断一些问题的回答,否则继续直接问询获取回答。
3.3 算法验证分析
在958例数据中随机选取30%的数据即288例构建测试集,对设计的算法进行验证分析。对比输入不同的阈值σ和遍历模式下的评价指标,分别选取单项指标最高的参数组合进行展示,如表 2所示。结果显示,当阈值σ≤0.2时,无论何种遍历模式,都能获得最高的平均简化率,可达0.92,但准确性较差;当阈值σ取最高的0.95时,单双向BFS遍历模式都能获得最高的平均准确率,可达0.98,但简化率很低。这符合认知,当阈值过低时,即使出现概率较低也会被直接预测,因此大部分问题都不会被问询,但这样的预测结果并不可信;当阈值很高时,预测的问题可信度很高,但大部分问题都不会被预测。因此,考虑算法的综合性能,应该在这两个数值之间寻找平衡,本试验的结果是σ= 0.7时,无论何种遍历模式,都能获得最高的AFβ,可达0.85,此时综合性能最佳。遍历模式在相同阈值的条件下对试验结果影响不大,说明无论模型采用何种推理方式,均能得到较一致的结果。

图2 贝叶斯网络结构示意图Figure 2 Structure diagram of Bayesian network structure

表2 不同参数组合的性能Table 2 Performance of different parameter combinations
进一步,算法性能随阈值σ的变化如图 3所示,平均简化率从阈值σ= 0.4开始,随阈值σ的增加快速下降,相反,平均准确率从阈值σ= 0.4开始,随阈值σ的增加快速上升,而AFβ从σ= 0.4开始先是不断上升,在σ= 0.7达到最高点,之后开始下降,整体波动幅度较小。因此,权衡准确率和简化率后,σ= 0.7可作为本实验的最优参数。
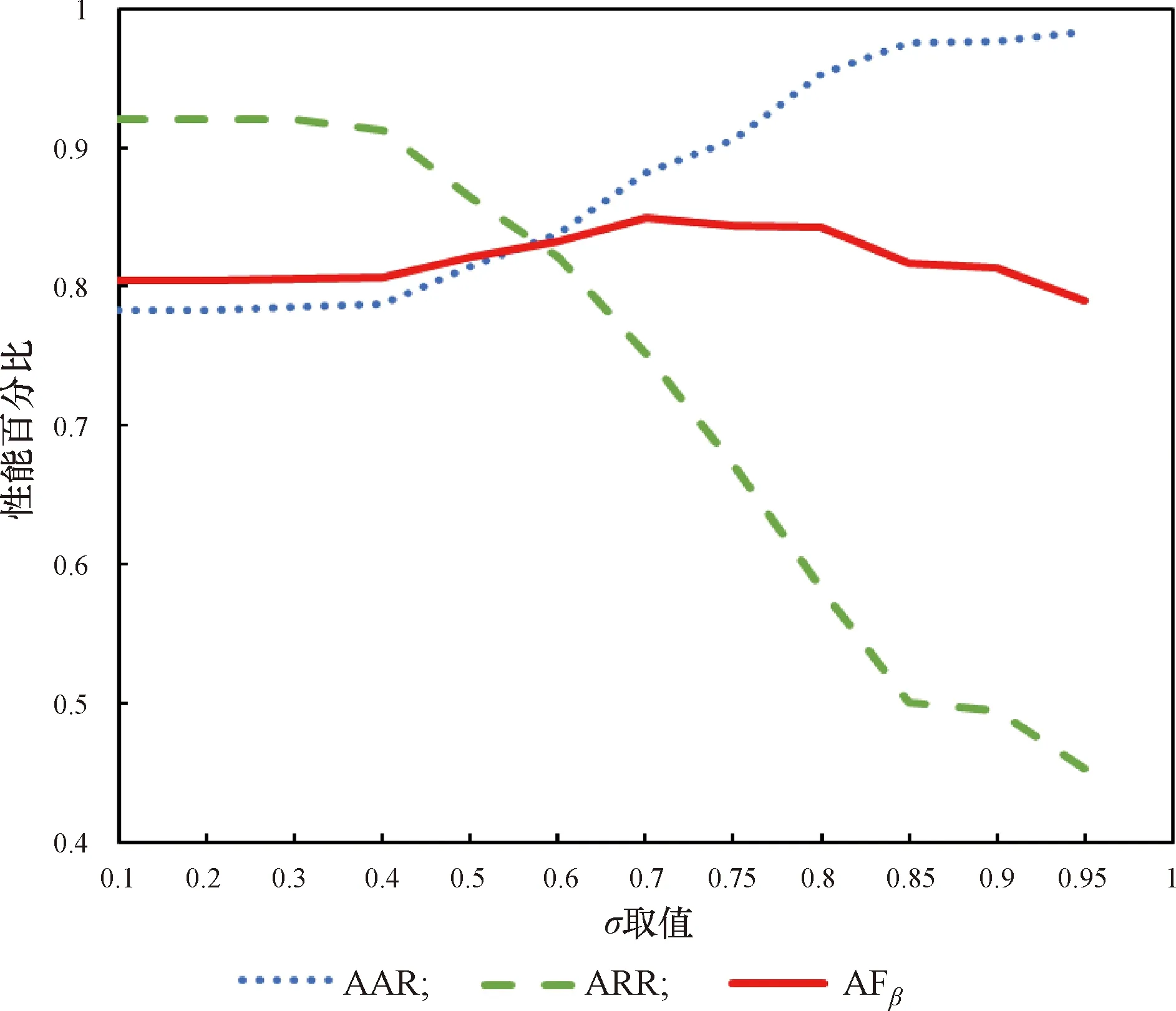
图3 算法性能随阈值σ增加的变化Figure 3 Performance with increasing threshold σ
3.4 算法性能比较
为进一步验证本研究算法的性能,将与其他算法进行对比。调研发现,现有公开报道中有关老年综合能力评估的智能算法较少,本文采用其中较有代表性的FPQM[7]作为对比。与本研究算法类似,FPQM同样需要输入一个阈值参数σ对性能进行调试,因此对阈值σ从0.95开始以0.05为单位依次减小进行实验。各项指标峰值及模型存储大小对比结果如表3所示。结果表明,本研究算法在最高准确率和综合性能上明显高于FPQM,同时在空间占用上大幅减小,在最高简化率上虽低于FPQM但差距不大。
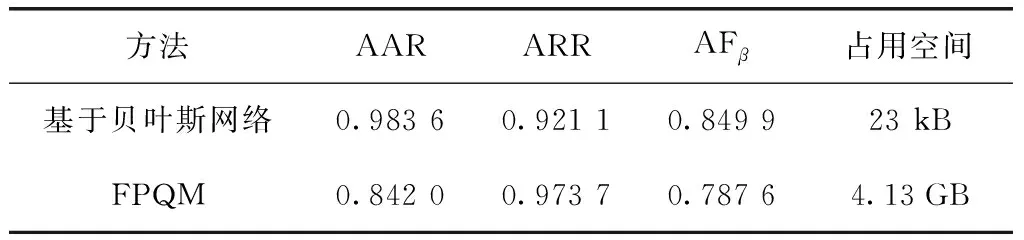
表3 不同算法的性能比较Table 3 Performance comparison of different algorithms
4 讨论
本研究表明,基于贝叶斯网络的老年综合评估过程简化方法相较先前的FPQM综合性能更好,准确率更高,同时节省数万倍的存储空间,在运行时能更加高效地加载训练好的模型到内存中,适合大面积综合评估的应用场景。
目前CGA普遍采用量表、问卷调查的方式进行评估[4],量表题项都是经过复杂流程挑选得到的,题项之间既存在关联,也存在独立的情况[16]。因此,通过删减题项的方式将会降低评估的准确性。量表的题项以单选题为主[17],少部分多选题可以通过计分方式转化为单选题,这些题项均可作为离散属性变量输入计算机处理。通过部分问题回答去预测其他问题回答,属于多维分类问题,与传统分类问题不同,这是一个前沿课题[18]。
FPQM基于一阶依赖的假设,解释了部分属性间的真实关系。一阶依赖假设过于理想,本研究考虑基于高阶依赖的思想可以更完整地解释属性间关系,进一步提升算法的泛化性能[19]。真实问卷中题项间会呈现网状关系,以图结构表示题项之间的关系更加贴近实际。贝叶斯网络以图为基础结构表达属性间的关联,并通过概率计算具体量化属性间的关联强度。表 4列出了贝叶斯网络与FPQM原理的比较。基于贝叶斯网络的问卷调查算法通过预测部分回答的方式在不删减题项的前提下减少了问询问题数,达到了简化评估过程的目的。
CGA主要通过问卷得分划分老人能力等级,因此只要最终得分在同一等级范围内,即使该算法不能达到100%的准确率,个别问题的失真对最后分级结果的影响也在可控范围内,因此本研究提出的算法能够在保证结果准确的同时实现简化评估的效果。CGA分级结果的验证将在后续研究中进一步实现。在本研究结果中,最优参数组合的平均简化率达0.75以上,这表示问卷调查的工作量可以节省到原先的25%,具有显著的简化效果。

表4 不同模型的原理比较Table 4 Comparison of principles between different models
本研究通过训练数据集得到的贝叶斯网络,提出了一种老年综合评估过程简化方法,经测试集验证该方法优于其他类似应用的算法。该方法同样可应用于任何不同的问卷评估流程,解决调查过程中全面准确和简捷不可兼得的问题。此外,也可基于该方法设计老人自助评估流程;数据分析者也可利用该方法对缺失数据进行补全。本研究后续将考虑纳入个人基本信息、各项客观指标等更多元的属性变量,并尝试更多的建模方法对性能进行测试,对算法综合性能进行进一步优化。同时,以本算法为核心开发的智能化老年综合评估系统终端设备目前正在研制过程中。
5 结论
本研究针对CGA准确性与便捷性不可兼得的问题,基于贝叶斯网络提出了一种老年综合评估过程简化方法,通过测试数据集初步验证,平均准确率为0.983 6,AFβ为0.849 9,占用空间23 kB,均明显优于已报道的简化算法。在当前老龄化日益严峻背景下,该方法对于基层社区和养老机构提升CGA工作效率具有重要应用价值。
