基于深度学习的电网网络攻击检测研究
2022-12-24常英贤孙莉莉张方哲
刘 新,常英贤,孙莉莉,张方哲
(1.国网山东省电力公司电力科学研究院,山东 济南 250003;2.国网山东省电力公司,山东 济南 250001)
0 引言
信息物理系统[1-2](cyber physical system,CPS)致力于将物理世界与网络世界相连,并广泛应用于工业控制系统(industrial control system,ICS)、配电网、交通、能源等领域。CPS基于通信、计算机、网络[3]等技术,使人们能够实时掌握所需的各种信息。结合CPS的智能电网负责电力的传输、分配、监测和控制,可以显著提高电力系统的效率和可靠性。然而,CPS存在一定网络安全威胁。黑客可以释放漏洞,故意造成分支过载跳闸,触发级联故障,从而对智能电网造成重大损害。这些损害轻则影响电力系统正常供电,重则导致重要基础设施的快速崩溃。为此,有必要对智能电网的CPS网络安全进行研究,从而为电力系统的安全运行提供保障。
随着机器学习技术的不断发展,许多学者将其引入电力网络安全领域,充分挖掘其模式识别精度高、学习能力强和鲁棒性强等优势。文献[4]从攻防2个角度对机器学习在电力CPS网络安全领域的应用进行了归纳总结,探讨了机器学习在电力CPS网络安全中的应用。文献[5]针对电力CPS中信息的网络故障,利用潮流传输、故障潮流分布、系统安全影响3个指标提出电力节点辨识模型。文献[6]提出了容忍阶段性故障的协同网络攻击引发电网级联故障预警方法。然而,目前大部分网络安全检查方法仍存在一些缺陷,如电力数据高纬度、数据不均衡等特点使得传统机器学习方法无法直接应用于电力数据检测。此外,现有方法的检测性能仍有巨大提升空间。
本文设计了基于深度学习的电力系统网络攻击检测模型。该模型主要通过学习历史数据和相关日志信息来检测系统中的异常信息。
1 电力系统网络攻击检测模型
电力系统网络攻击检测模型主要包括4个部分,分别为特征选择、数据处理、分类模型搭建和多层集成极限学习机(extreme learning machine,ELM)集成学习。电力系统网络攻击检测模型如图1所示。

1.1 特征选择
特征重构的意义在于通过原始数据获得更灵活的特征信息,从而提高数据的敏感性,并增强模型训练和分类的分析能力。此外,在机器学习问题中,训练如包含太多特征,将会消耗大量计算开销,并且容易过度拟合,从而导致模型性能下降。为了减少高维学习问题带来的影响,本文采用改进的自适应弹性网络的方法来选择特征。
令电力数据表示为(xi,yi),i=1,2,…,N。其中:xi=(xi1,xi2,…,xip)为电力变量信息;yi为类别标签。此时,回归模型可构建如下:
(1)
式中:β0和βj分别为截距系数和回归系数。

(2)

(3)
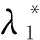
(4)
式中:γ为正实数。
根据上述计算,可从大量特征中提取重要程度相对较高的重要特征。进一步将这些重要特征组成特征向量并代入深度网络学习模型,可以在保证低计算和操作成本前提下,获取更为精确的分类结果。
1.2 数据处理
1.2.1 归一化处理和数据填充
数据在送入深度学习模型之前需要进行预处理操作。数据归一化是数据处理的基本操作。其优点是可以提高迭代的速度和精度,从而获得梯度搜索的最优解。数据归一化方法主要包括min-max和z-score归一化操作。本文主要选取z-score归一化操作,具体描述为:
(5)
式中:X为z-score归一化后数据值;μ为数据均值;σ为数据标准差。
此外,考虑到电力数据中通常存在非数值(non-numerical,NAN)或无穷大(infinity,INF)值,传统方法通常采用平均值或0进行填充。在处理试验中使用的数据集时,本文提出了1种新的逻辑平均值填充方法,以避免数据过于离散。逻辑平均值计算方法为:
(6)
式中:Nki为数据中第k个数据序列的第i个数据;κ为正实数系数;Γ(·)为符号函数。
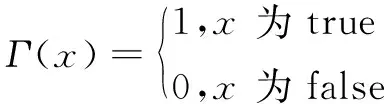
(7)
1.2.2 噪声数据处理
数据集中的噪声问题一直是影响分类或回归精度的重要难题。通常,电力数据中主要存在2种类型的噪声,分别为类别噪声和属性噪声。类别噪声是具有错误类标签的数据。属性噪声是具有错误属性值的数据。
考虑到在实际情况下,与数据空间中密集区域的数据相比,位于数据稀疏分布区域的数据点出现的概率值更低。因此,可将这些噪声数据视为异常值。为此,本文提出了基于粒子群优化(particle swarm optimization,PSO)算法[7]的PSO-K均值(PSO-Kmeans)聚类算法噪声数据处理方法。该方法首先计算每个数据点的离群值分数,从而检测噪声数据。随后,这些噪声数据将在训练集中得到增强,以形成噪声自适应训练集。噪声自适应训练集比原始数据集具有更多的噪声数据。这将增强模型对噪声数据的适应性,并在一定程度上缓解模型的过拟合问题。PSO-Kmeans算法执行流程如图2所示。

首先,本文随机选取K个节点作为聚类的初始中心。对于任意粒子i的编码,可表示为:
Pi={li,vi,fi}
(8)
式中:li、vi和fi分别为粒子i的位置、速度和适应度函数。
(9)

vi=[v1,v2,...,vk]
(10)
式中:v为粒子计算聚类中心时的速度。
(11)
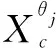
根据适应度函数,计算任意粒子的局部位置最优解lid以及所有粒子的全局位置最优解lgd,并更新粒子i的位置以及速度。
v′i=ζvi-c1r1(lid-li)+c2r2(lgd-li)
(12)
式中:v′i为更新后粒子速度;ζ为速度惯性权重;c1和c2为加速度系数;r1和r2为随机向量,且r1和r2中各元素均在[0,1]之间。
l′i=li+vit
(13)
式中:l′i为更新后粒子位置;t为时间步长。
1.3 分类模型搭建
ELM[8]模型作为1种单隐层前馈神经网络(single-hidden layer feedforward neural network,SLFN),可以在不进行任何调整的情况下随机选择输入权值和隐含偏差。
对于任意电力数据(xi,yi),输入向量xi=(xi1,xi2,…,xip)T∈Rp为具有p维特征的第i个样本。样本标签为Y=[y1,y2,…,yN]。其中,p为输入神经元的数量,即输入特征个数。令:L为隐藏神经元的数量;C为输出神经元的数量,即输出类别个数。同时,令:输入权重矩阵为K=[k1,k2,…,kL];kj=[kj1,kj2,…,kjn]为连接p个输入神经元和第j个隐藏神经元的向量;b=[b1,b2,…,bj,…,kL]为隐藏神经元的偏差;bj为第j个隐藏神经元的偏差。因此,模型中任意输入xi的输出为:
h(xi)=G(Kxi+b)
(14)
式中:G(·)为激活函数。
令H为所有样本的输出,则:
(15)
式中:列表示相对于输入x1到xN的隐藏节点的输出向量;行表示相对于输入xj的隐藏层的输出。
ELM的输出为:
(16)
式中:αi=[αi1,αi2,…,αiC]T为连接第i个隐藏节点与输出节点的权重向量。
1.4 多层集成ELM学习模型
当对ELM模型输出的多组分类器进行组合优化时,传统投票或堆叠方法存在一定缺陷。比如,当某个分类器性能明显低于其他分类器时,将会对整个模型性能产生显著影响。为此,本节提出了1种多层集成学习模型对ELM模型分类器进行组合优化,从而改善“坏值”分类器带来的不利影响。多层集成ELM模型结构如图3所示。
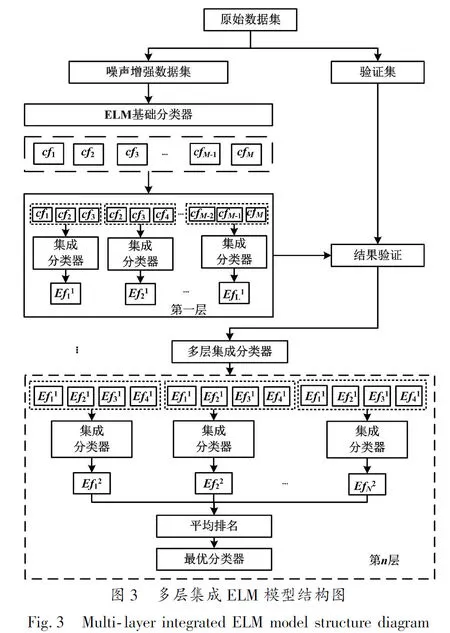
令ELM模型输出的分类器为(Cf1,Cf2,…,CfM)。首先,按顺序将3个分类器利用集成分类器进行训练。3个分类器训练过程可表示为:
(17)
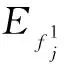
同时,在验证集上对第一层中的所有集成分类器输出结果进行验证,从而比较不同分类器的相对性能。
同理,在下一层集成学习中,按顺序将4个上一层集成分类器输出的结果再利用集成分类器进行训练。4个第一层集成分类器再次集成训练过程可表示为:
(18)

执行完上述过程后,对下一层输出的所有分类器进行排名统计,即将每个分类器从获得最佳性能到获得最差性能进行排名,从而确定每个分类器在不同评估度量中的性能指标。进一步根据每个分类器在多个评估度量中的平均排名,在测试集上对平均排名最高的集成模型进行测试,从而获得最佳分类结果。因此,集成模型能够消除性能持续性较差的分类器,从而改善模型训练效果。
2 仿真与分析
2.1 数据集与试验环境
2.1.1 数据集
本文研究所用数据集为中国某变电站通过电源管理单位(power managment unit,PMU)、Snort、控制面板和继电器等记录系统记录运行产生的数据,统计时间为2019年1月至2020年12月,采样频率为30 min/次。首先,对原始数据集进行数据清洗,删除不正确(缺失值超过80%)的数据。数据清洗后,有效样本共计51 809个,可分为正常、单相接地(single-line-to-ground,SLG)故障、线路维护、数据注入攻击、远程跳闸命令注入攻击、中继设置更改攻击6类。其中,SLG指系统电压、电流和频率异常时导致的故障。电力系统中的SLG故障大部分是线对地和线对线(line-to-line,LL)产生的故障。线路维护指系统维护时1条特定线路上的1个或多个继电器被禁用,从而引起的电力数据异常。数据注入攻击是1种与电力系统状态估计过程相结合的重要网络攻击类型。攻击者通过改变相位角来产生虚假的传感器信号。这种类型的攻击可能对电力系统造成物理或经济影响。远程跳闸命令注入攻击是在从通信网络上的攻击计算机向传输线末端的继电器发送继电器跳闸命令时引起的电力系统故障。中继设置更改攻击会改变中继运行状态,导致继电器对有效故障的响应不及时,使得电力系统造成无法挽回的经济损失或安全威胁。
各类数据统计结果如下:正常数据43 472个、SLG故障4 966个、线路维护792个、注入攻击891个、远程跳闸命令注入攻击890个、中继设置更改攻击798个。由此可知,该数据集具有严重的样本不均衡性,异常与正常的电力数据比约为1∶6.21。
试验环境设置如下:硬件为64 GB内存和英特尔至强(R)E5-2620 CPU的Ubuntu系统。算法仿真环境主要基于Python进行开发。
2.2 试验设置
首先,基于PSO-Kmeans算法生成噪声自适应训练集,增强模型对噪声数据的适应性,从而在一定程度上缓解模型的过拟合问题。接着,将噪声自适应训练集代入ELM分类器完成基础分类器训练,从而消除数据不均衡造成的影响。最后,基于多层学习机制,根据每个分类器在多个评估度量中的平均排名,在测试集中对平均排名最高的集成模型进行测试,从而获得最佳的分类结果。需注意,为了增强试验的稳健性和减少偶然性,对每组试验重复执行30次,并取所有试验结果的平均值用于评估模型的性能。
此外,为综合分析模型性能,研究选取准确率、Brier分数、接收者操作特征(receiver operating characterisic,ROC)、曲线下面积(area under curve,AUC)等指标对K最近邻(K-nearest neighbor,KNN)、随机森林(random forest,RF)、支持向量机(support vector machine,SVM)、卷积神经网络(convolutional neural network,CNN)、ELM模型进行对比。
2.3 性能与分析
2.3.1 特征选择性能分析
本小节综合对比特征选择对模型性能的影响。表1所示为特征提取前后不同模型性能综合对比结果。

表1 特征提取前后不同模型性能综合对比结果
由表1可知,经特征提取后,KNN、RF、SVM、CNN、ELM等模型准确率均有所提升。因此,本文所提的改进自适应弹性网络特征提取方法有助于提高分类器的分类效果。分析原因可知,特征选择能有效剔除冗余变量以及不相关的变量,从而有助于提高模型训练效率。
2.3.2 数据处理前后对比分析
本小节分别对比、分析了应用数据处理方法(归一化和PSO-Kmeans)前后不同模型的性能。噪声数据处理前后不同模型性能对比结果如表2所示。

表2 噪声数据处理前后不同模型性能对比结果
由表2可知,经数据处理后,除RF模型准确率降低外,其余模型准确率均有所提升。
分析原因可知,RF在严重不平衡数据集中获取有效信息和识别正样本的能力相对较弱,故模型性能无明显提升。因此,数据处理有助于提高分类模型的性能并减少其随机性。
2.3.3 多层集成学习性能分析
本小节采用所提方法分别执行改进自适应弹性网络特征提取和数据处理,并基于多层集成学习模型进行分类。多层分类器性能统计结果如表3所示。与表1和表2相比,多层集成分类器在性能指标上均具有明显优势,最优分类器准确率达到88.91%。由表3可知,分类器准确率、Brier分数、AUC等性能指标并不是随着分类器层数的增加而更优。分析原因可知:分类器层数增多将扩大模型规模,使得需要训练的参数量呈几何倍数增加,从而导致模型调参困难,使模型容易陷入局部最优。

表3 多层分类器性能统计结果
3 结论
本文建立了1种基于深度学习的电网网络攻击检测模型。该模型可基于改进自适应弹性网络特征提取、归一化、PSO-Kmeans数据处理方法和基于ELM的多层集成学习模型有效分类电力数据,从而提高电力系统网络攻击检测能力。首先,本文基于改进的自适应弹性网络模型,从大量电力数据中提取重要特征。其次,本文提出了归一化和PSO-Kmeans噪声数据处理方法,从而增强模型对噪声数据的适应性,并在一定程度上缓解模型过拟合问题。最后,本文基于多层集成模型对ELM模型分类器进行组合优化,从而改善“坏值”分类器带来的不利影响,提高模型分类性能。该模型为电力系统安全管理及稳定运行提供了一定的借鉴。
未来研究方向包括电力用户隐私保护、配电网网络安全等方面,从而进一步提升配电网数据安全与服务管理水平。
