一种基于span的实体和关系联合抽取方法*
2022-12-22吴宏明李莎莎吴庆波
余 杰,纪 斌,吴宏明,任 意,李莎莎,马 俊,吴庆波
(1.国防科技大学计算机学院,湖南 长沙 410073;2.中央军委装备发展部装备项目管理中心,北京 100034;3.陆军项目管理中心,北京 100071)
1 引言
本文研究句内命名实体和关系的联合抽取。与流水线模式的分步抽取方法相比,实体和关系的联合抽取模式可以减轻错误级联传播并促进信息之间的相互使用,因此引起了诸多研究者的关注。
通常,联合抽取模式是通过基于序列标注的方法实现的[1]。
最近大量的研究人员摒弃了基于序列标注的方法,提出了基于span的联合抽取模式。此模式首先将句子的文本处理为文本span,这些span被称为基于span的候选实体;然后计算span语义表示并对其进行分类,以获得预测的实体;接下来组合span,构成基于span的候选关系元组,并计算这些候选元组的语义表示;最后对候选关系元组进行分类,得到关系三元组。该模式进一步提高了联合抽取性能,然而存在以下3个问题:
(1)构成span的不同token对span语义表示的贡献应有所不同,本文称其为span特定特征。但是,现有的方法将span的每个token视为同等重要或仅考虑span头尾token的语义表示,而忽略了这些重要特征。
(2)现有研究方法忽略了关系元组的局部上下文信息或仅通过max pooling的方法对其进行计算,因而不能充分捕获其中包含的信息。而局部上下文中包含的信息,可能在关系预测中起到关键作用。
(3)在span分类和关系分类中均忽略了句子级的上下文信息,而这些信息可能是两者的重要补偿信息。
为了解决上述问题,本文提出了一种基于span的实体关系联合抽取模型,该模型使用attention机制捕获的span特定特征和句子上下文语义表示来增强实体和关系的语义表示。具体来说,(1)使用MLP(Multi Layer Perceptrons)attention[2]计算span特定特征的语义表示;(2)通过将span特定特征的语义表示作为Q(query),将句子token序列的语义表示作为K(key)和V(value),使用Multi-Head attention计算句子的上下文语义表示,用于强化span的语义表示;(3)通过将关系元组语义表示作为query,将相应的token语义序列作为key和value,使用Multi-Head attention分别计算关系的局部和句子级上下文语义表示,用于强化关系的语义表示。
本文使用BERT(Bidirectional Encoder Representation from Transformers)[3]实现基于span的实体和关系联合抽取模型,并研究了上述3个问题,在ACE2005、CoNLL2004和ADE 3个基准数据集上进行了大量的实验。实验结果表明,本文提出的模型超越了以前的最优模型,在3个基准数据集上均达到了当前的最优性能。
2 相关工作
传统上,流水线模式将实体关系抽取分为2个子任务,即实体识别和关系分类。大量的研究工作将神经网络应用于这2个子任务中,例如将RNN(Recurrent Neural Network)[4]、CNN(Convolutional Neural Network)[5]用于实体识别中;将RNN[6]、CNN[7]和Transformer[8]等用于关系分类中。
实体和关系的联合抽取通常被形式化为序列标注任务。研究人员首先提出的方法是表格填充方法[9],该方法用token标签和关系标签分别填充表格的对角线和非对角线。最近,许多研究人员专注于利用深度神经网络来实现这一任务,例如BiLSTM(Bidirectional Long-Short Term Memory)和CNN的结合[10]。
最近,有学者提出了基于span的实体关系联合抽取方法,用于解决序列标注方法中存在的问题,如无法抽取重叠的实体。Dixit等人[2]通过BiLSTM获得span语义表示来实现实体关系联合抽取方法,然后将ELMo(Embeddings from Language Models)、单词和字符嵌入拼接起来,并在span和关系分类中实现了共享。Luan等人[11]获取span语义表示的方法与Lee等人[12]采用的方法相同,但他们通过引入共指消除任务增强了span语义表示。在文献[11]的基础上Luan等人[13]提出了DyGIE(Dynamic Graph Information Extraction),该模型通过动态构造span交互图来捕获span之间的交互。Wadden等人[14]使用BERT替代DyGIE中的BiLSTM,提出了DyGIE++,进一步提高了模型性能。最近,Eberts等人[15]提出了SpERT(Span-based Entity and Relation Transformer),一个简单但有效的基于span的联合抽取模型,该模型将BERT作为编码器,并使用2个多层前馈神经网络FFNN(Feed Forward Neural Network)分别对span和关系进行分类。
本文提出了一种基于span的实体和关系联合抽取模型,与已有研究方法不同的是,本文使用attention机制捕获span特定特征和上下文语义表示,进一步强化span和关系的语义表示。通过计算目标序列语义表示与源序列语义表示之间的匹配程度,attention机制可得到源序列上的注意力得分,即权重得分。因此,信息越重要,其权重得分就越高。根据权重得分的计算方式进行分类,attention机制具有多种变体,例如Additive attention[16]、Dot-Product attention[17]和Multi-Head attention[18]等。

Figure 1 Architecture of the proposed joint entity and relation extraction model
3 基于span的实体和关系联合抽取模型
图1所示为本文提出的模型架构。本文提出的模型使用BERT作为编码器,即使用Transformer[18]模块将单词嵌入映射到BERT嵌入。根据这些嵌入表示,计算span语义表示并执行span分类和过滤(3.1节);然后,组织关系元组,计算关系元组语义表示并执行关系分类和过滤(3.2节);最后,介绍模型的损失函数(3.3节)。
首先定义一个句子和该句子的一个span:
句子:S=(t1,t2,t3,…,tn)
span:s=(ti,ti+1,ti+2,…,ti+j)
其中,t表示token,一个token指代文本中的一个单词或一个符号,如标点符号、特殊符号等;下标(例如1,2,3,…)表示token在文本中的位置索引。在span中,下标j表示span的长度阈值。
3.1 span分类和过滤
首先,将NoneEntity类型添加到预定义的实体类型集合(表示为η)中。若span的类型不属于任何预定义的实体类型,那么它的类型为NoneEntity。
如图1所示,用于分类的span语义表示由4部分组成,即:(1)span头尾token语义表示的拼接;(2)span特定特征的语义表示;(3)span的句子级上下文语义表示(span width embeddings);(4)span宽度语义表示。本文用Xi表示tokenti的BERT嵌入,则S和s的BERT嵌入序列表示分别如式(1)和式(2)所示:
BS=(X0,X1,X2,…,Xn)
(1)
Bs=(Xi,Xi+1,Xi+2,…,Xi+j)
(2)
其中X0表示特定字符[CLS]的BERT嵌入。
(1)span头尾token语义表示的拼接:如果span包含多个token,则将span头token和尾token的BERT嵌入拼接。否则,复制单个token的BERT嵌入并将其拼接起来。以s为例,其拼接结果为:
Hs=[Xi;Xi+j]
(2)span特定特征的语义表示:本文使用MLP attention[2]计算span特定特征的语义表示,以s为例,其特定特征计算的形式化表示如式(3)所示:
Vk=MLPk(Xk)
s.t.k∈[i,i+j]
(3)
(4)
(5)
其中,Vk是标量;αk是Xk的attention权重,由Softmax函数计算得出;Fs是根据attention权重和Bs计算得到的span特定特征的语义表示。通过这种方式可以评估span包含的每个token的重要性,并且token越重要,它持有的attention权重就越大。通过将Fs作为Q(query),BS作为K(key)和V(value),使用Multi-Head attention计算span的句子级的上下文语义表示。以s为例,上述计算可形式化如式(6)所示:
Ts=Attention(Fs,BS,BS)
(6)
(3)span宽度嵌入:在模型训练过程中为每个span宽度(1,2,…)训练一个宽度嵌入表示[3],因此可以从宽度嵌入矩阵中为s查找宽度为j+1的嵌入表示Wj+1。
(4)span分类:用于分类的span语义表示由4部分拼接而成,其形式化表示如式(7)所示:
Rs=(Ts,Fs,Hs,Wj+1)
(7)
Rs首先输入到一个多层FFNN,然后将输出结果输入到一个Softmax分类器,输出结果为s在实体类型空间(包括NoneEntity)上的后验概率分布值,如式(8)所示:
ys=Softmax(FFNN(Rs))
(8)
(5)span过滤:通过搜索得分最高的类别,ys预测得到s的实体类型。本文保留未分类为NoneEntity的span,并构成一个预测的实体集ε。
3.2 关系过滤和筛选
首先,将NoneRelation类型添加到预定义的关系类型集合(表示为γ)中。设s1和s2是2个span,用于关系分类的关系元组定义如式(9)所示:
〈s1,s2〉∈{ε⊗ε}
s.t.s1≠s2
(9)
如图1所示,用于分类的关系语义表示由3部分组成,即:(1)构成关系的2个预测的实体的语义表示拼接;(2)关系的局部上下文语义表示;(3)关系的句子级上下文语义表示。
(1)关系元组语义表示的拼接:将s1和s2的语义表示分别形式化为Rs1和Rs2(本质为span的语义表示)。在拼接Rs1和Rs2之前,本文首先使用2个不同的多层前馈神经网络FFNN分别减小其维度,拼接结果如式(10)所示:
Hr=[FFNN(Rs1);FFNN(Rs2)]
(10)
(2)关系的局部上下文语义表示:令Bc表示s1和s2之间的局部上下文的BERT嵌入序列,其形式化表示如式(11)所示:
Bc=(Xm,Xm+1,Xm+2,…,Xm+n)
(11)
通过将Hr作为Q(query),Bc作为K(key)和V(value),使用Multi-Head attention计算关系的局部上下文语义表示,如式(12)所示:
Fr=Attention(Hr,Bc,Bc)
(12)
(3)关系的句子级的上下文语义表示:通过将Hr作为Q,Bs作为K和V,使用Multi-Head attention计算关系的句子级上下文语义表示,其形式化表示如式(13)所示:
Tr=Attention(Hr,Bs,Bs)
(13)
(4)关系分类:在将Fr和Tr融合到关系语义表示之前,本文首先将2个不同的多层FFNN应用到Fr和Tr,以控制其维度,目的是使它们在关系的语义表示中保持适当的比例,用于分类的关系语义表示可形式化为:
Rr=[Hr;FFNN(Fr);FFNN(Tr)]
(14)
类似于span分类,Rr首先输入到一个多层FFNN,然后将输出结果输入到一个Softmax分类器,产生〈s1,s2〉在关系类型空间(包括NoneRelation)上的后验概率分布,如式(15)所示:
yr=Softmax(FFNN(Rr))
(15)
(5)关系过滤:通过搜索得分最高的类别,yr可以预测出〈s1,s2〉的关系类型。本文保留预测为非NoneRelation的关系元组并构成关系三元组。
3.3 损失函数
本文将联合抽取模型的损失函数定义如式(16)所示:
L=0.4Ls+0.6Lr
(16)
其中,Ls表示span分类的交叉熵损失,Lr表示关系分类的二元交叉熵损失。由于关系分类的性能通常比实体识别性能差,因此本文对Lr赋予更大的权重,旨在让模型更多地关注关系分类。
4 实验
4.1 数据集
本文模型在ACE2005[19]、CoNLL2004[20]和ADE(Adverse-Effect-Drug)[21]3个基准数据集上进行实验,以下将3个数据集简称为ACE05、CoNLL04和ADE。
(1)ACE05英文数据集由多领域的新闻报道组成,例如广播、新闻专线等。该数据集预定义了7个实体类型和6个关系类型。本文遵循当前已有研究工作中提出的training/dev/test数据集划分标准。其中包括351份训练数据,80份验证数据和80份测试数据,这其中又有437份包含重叠实体。
(2)CoNLL04数据集包括来自华尔街日报和AP的新闻语料,本文遵循当前已有研究工作中提出的training/dev/test数据集划分标准。其中包括910份训练数据,243份验证数据和288份测试数据。
(3)ADE旨在从医学文献中抽取药物相关的不良反应,预定义了2个实体类型(即Adverse-Effect和Drug)和1个关系类型,即Adverse-Effect。该数据集由4 272个句子组成,其中1 695个包含重叠实体。本文在该数据集上进行10重交叉验证实验。
4.2 实验设置
本文使用English BERT-base-cased model作为嵌入生成器。在本文模型训练期间训练FFNN和attention的模型参数并且对BERT模型参数进行微调。本文将模型训练的batch大小设置为8,dropout设置为0.2,宽度嵌入的维度设置为50。Multi-Head attention头数设置为8。学习率设置为5e-5,weight decay设置为0.01,梯度裁剪阈值设置为1,对不同数据集,本文设置了不同的epoch。对于所有数据集,span宽度阈值均初始化为10。本文采用动态负采样策略来提高模型性能和鲁棒性,其中实体和关系的负例采样数量都是每个句子中正例的30倍。
4.3 基准模型
在3个基准数据集上,本文模型与以下模型进行比较。
(1)DyGIE++[14]是当前在ACE05数据集上基于span联合抽取模式的最优模型,它通过引入共指消除任务来强化span和关系的语义表示。
(2)Multi-turn QA(Multi-turn Question & Answer)[22]是当前在ACE05和CoNLL04 2个数据集上基于序列标注的最优模型。它将实体和关系的联合抽取形式化为一个多轮问答问题,但仍是基于序列标注的抽取模式。
(3)SpERT[15]是当前在ADE和CoNLL04 2个数据集上基于span联合抽取模式的最优模型。
(4)Relation-Metric[23]是一种基于序列标注的联合抽取模型,并且采用了多任务联合学习模式。该模型在ADE数据集上取得了当前的最优性能。
4.4 实验结果
本文提出的模型和当前性能最优的联合抽取模型的比较结果如表1所示。本文提出的模型表示为SPANMulti-Head,表示使用Multi-Head attention计算上下文语义表示。在ACE05和CoNLL04 2个数据集上,本文采用准确率P(Precision)、召回率R(Recall)和微平均F1(micro-averageF1)评估指标。在ADE数据集上,本文采用准确率P(Precision)、召回率R(Recall)和宏平均F1(macro-averageF1)评估指标。这些指标均参照当前已发表的研究工作。对于ACE05和ADE 2个数据集,表1列出的所有结果均已将重叠实体考虑在内。

Table 1 Performance comparisons of different models on ACE05,CoNLL04 and ADE datesets
从表1可以看出,SPANMulti-Head在3个基准数据集上的性能均超过了当前已有的最优模型。具体来说,与SpERT相比,SPANMulti-Head在实体识别方面获得了1.29(CoNLL04)和1.31(ADE)的绝对F1值提升,而在关系抽取方面则获得了更佳的绝对F1值提升,分别为2.86(CoNLL04)和1.89(ADE)。本文将这些性能提高归结于span特定特征和上下文表示。此外,与DyGIE++相比,在ACE05数据集上,SPANMulti-Head在实体识别和关系抽取上相比DyGIE++获得了0.99和1.84的绝对F1值提升。但是,值得注意的是DyGIE++采用了多任务联合学习的方式,通过引入共指消除任务进一步增强了span的语义表示,而本文方法并未引入共指消除。
4.5 消融实验
本节在ACE05测试集上进行消融实验,以分析不同模型组件的影响。
(1)span特定特征和span的句子级上下文语义表示的影响。
表2给出了span特定特征和span的句子级上下文语义表示对本文提出模型的影响。其中,-SpanSpecific表示使用Bs的max pooling替换Rs中的[Fs,Hs];-SentenceLevel表示使用[CLS]的BERT嵌入替换Rs中的Ts;base表示执行以上2种消融操作。在ACE05测试集上,可观察到span特定特征语义表示和span的句子级上下文语义表示均有益于实体识别和关系抽取,这是因为 span的语义表示在2个子任务中共享。

Table 2 Ablation results of span-specific and span sentence-level contextual representations
(2)关系的局部和句子级上下文语义表示的影响。
表3给出了关系的局部和句子级上下文语义表示对本文提出模型的影响,其中,-local表示使用Bc的max pooling替换Rr中的FFNN(Fr);-SentenceLevel表示去除Rr中FFNN(Tr);base是执行以上2种消融操作。
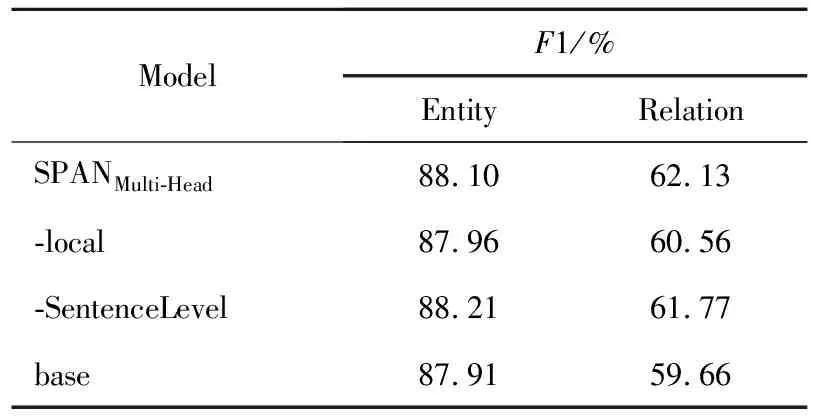
Table 3 Ablation results of relation local and sentence-level contextual representations
在ACE05验证数据集上,可观察到关系的局部和句子级的上下文语义表示明显地有益于关系提取,然而对实体识别的影响却可以忽略不计。一个可能的原因是,这些上下文语义表示直接构成关系的语义表示,然而仅通过梯度反向传播影响span的语义表示。
值得注意的是,与关系的句子级上下文语义相比,关系的局部上下文语义对关系抽取的影响更大。原因之一是决定关系类型的信息主要存在于关系元组和局部上下文中。另一个原因是作为补偿信息,关系的句子级上下文语义表示在关系语义表示中所占的比例相对较小,目的在于避免将噪声引入关系的语义表示中。
5 结束语
本文提出了一种基于span的实体关系联合抽取模型,该模型使用attention机制强化span和关系的语义表示。具体来说,使用MLP attention捕获span特定特征,丰富了span的语义表示;使用Multi-Head attention捕获句子局部和全局特征,进一步强化了span和关系的语义表示。本文提出的模型在3个基准数据集上的性能均超过了当前最优模型,创造了当前最优的联合抽取性能。将来将研究通过减少span分类错误来进一步提高关系分类性能,还计划探索更有效的方法用于编码语义更为丰富的span和关系语义表示。
