基于朴素贝叶斯分类的网络谣言识别研究*
2022-12-22李文丽
李文丽
(上海大学管理学院,上海 200444)
1 引言
互联网技术的快速发展带动了网络媒体的进步,网络媒体借助自身传播信息速度快、范围广的特性,为用户带来了及时全面获取信息的便利,但同时也引发了许多失范行为,网络谣言就是其一。谣言的滋生往往会造成民众恐慌,破坏社会秩序,甚至威胁国家安全,具有极大的危害性。比如,2011年日本核泄漏事件,有消息称自然盐将会受到核污染而致使盐量减少,盐商借此哄抬盐价,高于日常几倍价格售卖,引起大众恐慌,破坏社会稳定。因此,制止网络谣言传播尤为必要。目前,许多国家推出了谣言检测、跟踪系统,但绝大部分辟谣工作仍需人工完成,尽管人工辟谣可以保证较高的准确率,但存在费时费事的突出问题,且辟谣措施具有滞后性。因而,亟需自动或半自动的方法识别网络谣言[1],以弥补人工辟谣的关键缺陷。
识别网络谣言的方法主要有2种。第1种是基于分类的识别方法,即将谣言识别看做二分类问题,通过选择合适的特征并结合一种分类算法,以达到识别谣言的目的[1]。研究人员经常使用到的算法有多种,如Qazvinian等[2]使用的贝叶斯分类算法,祖坤琳等[3-5]使用的支持向量机和Sun等[6,7]使用的决策树等。另外,现阶段工作大都在Castillo等[7,8]工作的基础上进行,研究人员将特征分为3种类型,分别是文本内容特征、用户特征和传播特征。由于特征的设计和选择对于谣言识别的影响较大,因而研究者往往会提出新的特征。如贺刚等[9]认为浅层文本特征不利于文本识别,故对微博内容进行深入挖掘,提出了符号、链接、关键词和时间差4种隐式特征。Zhang等[10]提出流行度取向、内外一致性、情感极性和评论观点4个新型隐式特征,结合Yang 等[8]提出的浅层文本特征,通过支持向量机识别方法使得识别精确率有所提升。Sun等[6]发现80%的事件谣言都配有图片,且大部分图文不符,对此提出了4个新的文本特征和1个多媒体特征。
第2种是基于模型的识别方法,相关研究较少,除传染病[11]、神经网络[12,13]和信息传播[14]等几种经典模型外,Liu等[14]开发了一种基于异构用户表示的谣言识别信息传播模型,以实现网络谣言识别,魏阳等[15]提出了基于灰色关联分析的模型识别方法。李明彩等[16]基于最大熵模模型,构建了网络环境中谣言信息的识别机制。
相比于第1种方法,基于模型的分类方法需要大量参数[1],增加了计算过程的复杂性,且谣言识别问题本质上就是一个分类问题,即将信息分类为谣言或者非谣言[16],因而,本文选择基于分类的识别方法进行研究。另外,在贝叶斯、支持向量机和决策树等分类方法中,朴素贝叶斯分类算法理论基础成熟,对于多分类问题具有较低的复杂度,且在分布独立的假设下,分类效果优良。但在以往研究中,较少将其直接用于网络谣言识别,Qazvinian等[2]虽然用到了贝叶斯算法,但只是利用其处理数据特征,Liang等[18]只是利用朴素贝叶斯分类器判别质疑评论,未将其直接应用于谣言分类。
微博作为一种全新的社交平台,可为用户提供信息发布与共享的社会服务。研究微博谣言识别的方法,有助于用户判断信息的真假,营造积极的网络环境,使微博在信息传播引导、舆情监控过程中起到积极作用。此外,微博平台中社区管理中心板块主要处理被举报抄袭、冒充和泄露隐私等纠纷事务,可从此模块获取谣言信息,为本文研究提供所需数据。因而,本文从微博中收集若干数据,并从中提取若干个特征,通过假设各个特征之间相互独立,利用朴素贝叶斯分类器,探究其对网络谣言的识别效果。
2 朴素贝叶斯分类识别机制
2.1 朴素贝叶斯分类算法框架
第1步是训练分类器。该过程包含以下步骤:首先是对数据进行预处理,包括分词、去停用词等操作,通过对复杂的消息进行处理,完成对数据的清理、变换,以生成包含内容、用户等各个方面的特征集合,形成训练数据矩阵、类矩阵和测试数据矩阵,为接下来的处理做准备。其次是选择特征。一般来说,特征越发散则越有利于谣言识别,同时也可考虑特征与谣言的相关性,两者为正向关系,相关性越强越有利于谣言识别。在完成前两部分的工作后,接下来就要在Python、R语言或者Matlab等平台上训练朴素贝叶斯分类器。本文选择Matlab数学软件工具训练分类器,由于Matlab的基本数据单位是矩阵,因此经过预处理和特征选择2个步骤生成的特征矩阵,可为训练分类器提供数据。
第2步为测试。在这一阶段也要完成对测试数据的预处理,提取与训练阶段相同的特征,形成测试数据的特征矩阵,利用第1步所训练的分类器进行分类实验。
在经过前2步的训练与测试后,可得到测试数据的分类结果,从而可以对分类结果进行评价。本文提出的谣言识别算法框架图如图1所示。
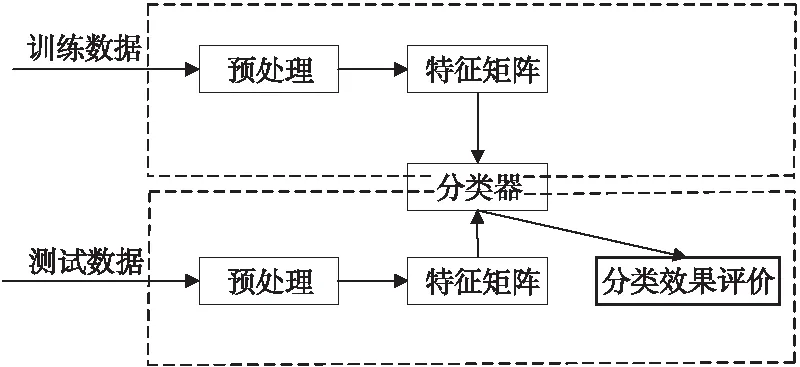
Figure 1 Framework of rumor recognition algorithm
2.2 评价指标
朴素贝叶斯分类器的分类效果受多重因素的影响,例如训练样本数量、特征的选取和特征的数目等,这些影响因素综合作用,导致在分类过程中不可避免地会出现预测出错的情况,比如将谣言预测为非谣言,因此降低出错率尤为必要,可以通过一些评价指标来评判分类效果[3]。
首先建立混淆矩阵,如表1所示。其中,TP(True Positive)代表实际为谣言并被正确预测为谣言的样本数量,FN(False Negative)代表实际为谣言而被预测为非谣言的样本数量,FP(False Positive)代表实际为非谣言而被预测为谣言的样本数量,TN(True Negative)表示实际为非谣言并被正确预测为非谣言的样本数量。

Table 1 Confusion matrix
常用的评价指标及其含义[8,9]如下所示:
(1)准确率(Accuracy):表示被正确预测的数据样本占总研究样本的比率,是最主要的评价指标。计算公式为(TP+TN)/(TP+FP+TN+FN),其值越接近1,说明分类模型的预测效果越优。
(2)精确率(Precision):被正确预测为谣言的样本数目与被预测为谣言的样本数目的比率,主要衡量模型的查准率。计算公式为TP/(TP+FP),其值越大则查准率越高,其值越小说明分类效果越差。
(3)召回率(Recall):被正确预测为谣言的样本数目与样本中谣言的总数目的比率,用来衡量模型对谣言的查全率。计算公式为TP/(TP+FN),一般来说,召回率越接近1,越能识别出所有谣言。
(4)F1值:由于精确率与召回率有时会冲突,因此引入F1值。F1值为精确率和召回率的调和平均值,是实现精确率和召回率综合表现的评价指标。计算公式为F1=2*精确率*召回率/(精确率+召回率)。F1与分类效果成正向关系,其值越大说明谣言的识别效果越好。
3 数据收集与实验
3.1 数据收集
本文以新浪微博为基础,从其中摘录数据,为了更有效地测试朴素贝叶斯分类器的有效性,共收集3套数据集。第1套数据集摘录于微博用户“谣言档案馆”所汇总的谣言档案,该数据集的特点是谣言大多集中在2014年之前,涉及到各个类别的谣言,大多数配有图片,本文从中共摘录出60条谣言,此套数据集称为训练集1。第2套数据集来自于新浪微博社区管理中心,该中心主要处理被举报抄袭、冒充和泄露隐私等纠纷事务,力求维护微博社区秩序,构建安全的网络环境,本文在管理中心不实信息模块共过滤摘录了78条谣言,时间点集中在近年,此套数据集称为训练集2。第3套数据集是非谣言集合,随机从微博热门、热搜榜和同城榜等模块摘取,共120条,称为训练集3。
3.2 特征选取
由于特征的选择关系到谣言识别的准确度,属性在谣言与非谣言数据中出现的频率相差越大,越有利于谣言的识别。因而,在进行谣言识别时,选择合适的特征尤为重要。基于此,本文选用了以下特征:
特征1媒体特征。本文将收集到的数据样本分为3类,分别是配图片、视频和无多媒体。其中,在配有图片的数据集中,根据水印个数进一步细分。
特征2其他字符特征。为了增加信息的可靠性,很多谣言会配有图片,而这些图片中往往会有水印或者其他文字字符。本文依据是否配有图片、图片特征对数据样本进行编码分类。
特征3符号特征。本文对这类特征的处理方式为计算?、!…等符号个数总和。
特征4~特征6情感词数目特征。本文以大连理工大学信息检索研究室编写的中文情感词汇本体库为基础,进行适当扩展,例如根据语境可认为“遭”“遭遇”等于“遭受”,以判断每个情感词的情感强度和情感极性,并统计数据样本中正、负、中性情感词的数目,依据分类不破坏原则对其进行编码。
特征7摹因符号特征。本特征针对训练集1,依据数据样本是否含有#、@、URL等符号进行分类。
特征8评论特征。通过观察评论,可发现在谣言的评论中存在大量的“谣言”“辟谣”“假的”等词汇,本文通过过滤前10条评论,将含有这些词语的样本编码为2,否则编码为1。
3.3 实验结果分析
由于人工收集的实验数据,样本容量与多样性均有限,在计算过程中无法避免零概率问题,将造成实验结果具有一定的不合理性,故本文以是否进行平滑处理操作为基准,进行2组实验。第1组实验未进行平滑处理,以训练样本为变量,旨在探究朴素贝叶斯分类器对网络谣言识别的可行性,及不同训练条件下的朴素贝叶斯分类器对谣言与非谣言的识别情况和所含规律。第2组实验中引入拉普拉斯平滑,消除零概率事件的影响,旨在与第1组实验结果进行对比,判断是否依然满足第1组实验的结论,且比较拉普拉斯平滑修正前后的朴素贝叶斯分类器的结果,探索规律。
3.3.1 训练样本数量不同对识别结果的影响
为探究不同数量训练样本条件下分类器对谣言与非谣言的识别情况,本文首先进行实验1:从数据集1中选取数量相当的谣言与非谣言来训练分类器,训练样本数目分别是60,70,80,90,100,受到该数据集条件的限制,本文共计从上述特征中选取了特征1~特征7共7个特征,同时用同一检测样本集(10条谣言和10条非谣言)来检测以上5组训练数据,实验结果如图2所示。

Figure 2 Comparison of experimental results of different training samples in experiment 1-dataset 1
再次,考虑到数据集1的局限性,利用数据集2进行实验2:在该实验中,选取特征1~特征6和特征8共7个特征,实验过程与实验1相类似,分别选取了60,70,80,90,100个样本训练分类器,同时使用另一套测试集(10条谣言和10条非谣言)来检测以上5组数据,实验结果如图3所示。

Figure 3 Comparison of experimental results of different training samples in experiment 2-dataset 2
为了探讨使用不同训练集生成的分类器对同一测试集的测试效果,本文进行了实验3: 从数据集2中选取2组互不交叉的训练集,每组训练集中样本数目为70(35条谣言+35条非谣言),随后利用2个训练集分别训练分类器,使用所得到的分类器检测包含有14条数据的测试集(8谣言和6非谣言)。实验结果如表2所示。

Table 2 Comparison of recognition effect
结论1将朴素贝叶斯分类器用于网络谣言识别,能获得良好的识别效果。观察实验1和实验2的结果,识别准确率均达到了0.6以上,且F1值也较高,说明识别效果良好。
结论2训练样本数目与识别效果并非正比关系。观察图2和图3可发现,准确率、精确率、召回率和F1等4个评价指标都会随着样本数目的变化上下波动,且图2呈现凸字形曲线,当训练样本数目为80或90时,各评价指标均达到最大值0.8。另外观察图3曲线,当训练样本数目为70和80时,准确率相同,曲线水平说明结论2成立。
结论3利用过多或过少的样本训练的分类器识别准确率可能会下降。当训练样本数目为60时,实验1和实验2的准确率分别为0.7和0.67,均低于各自对应的最高值。此外,在实验1中,当训练样本为100时,准确率也低于最大值0.8,由此可以说明结论3成立。
结论4根据实验3可知,使用不同训练集生成的分类器对同一组测试样本的识别结果有可能不同。
3.3.2 拉普拉斯修正对识别结果的影响
拉普拉斯修正的本质是为每个计数均加上一个较小的数,该值通常为1,既保证了每个属性概率非零又保证了概率和为1。本文用N表示训练集中总共的分类数;属性ai可能的取值数用Ni表示;Db表示样本中事件b发生的次数,在本文中事件b有2种可能性,即谣言和非谣言;Db,ai表示属于事件b,且属性为ai的样本个数;D表示样本总数,则修正规则如式(1)~式(4)所示:
先验概率P(b)计算公式为:
(1)
经拉普拉斯修正后为:
(2)
条件概率P(x|b)计算公式为:
(3)
经拉普拉斯修正后为:
(4)
实验4:在保证实验1和实验2训练集、测试集和特征不变的前提下,在谣言识别的过程中进行拉普拉斯修正,得出修正后的判别结果,并对比实验1和实验2的准确率,实验结果如图4和图5所示。
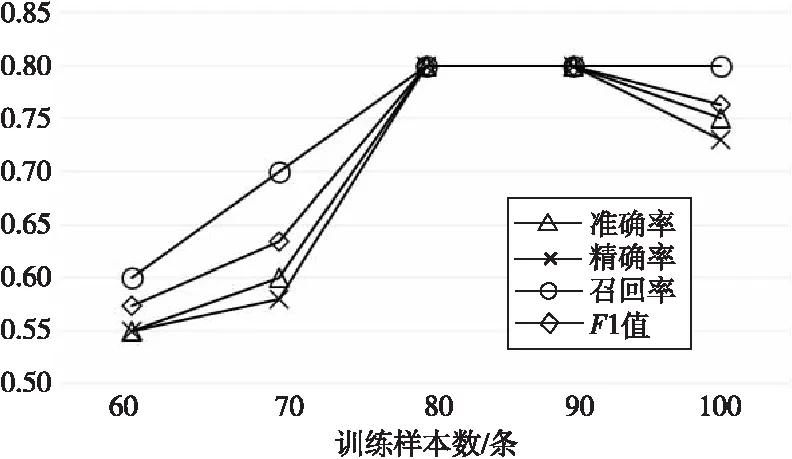
Figure 4 Experiment 4-experiment 1 Laplace modification
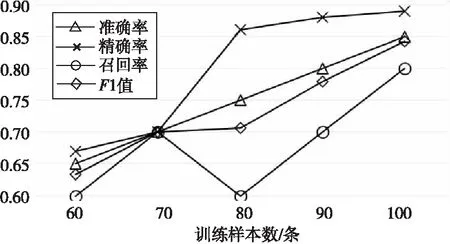
Figure 5 Experiment 4-experiment 2 Laplace modification
实验5:以实验3数据为基础,采用与实验4的方法进行拉普拉斯修正,计算修正后的准确率,并对比实验3修正前后的结果,如表3和表4所示。

Table 3 Experiment 5-comparison 1 before and after modification
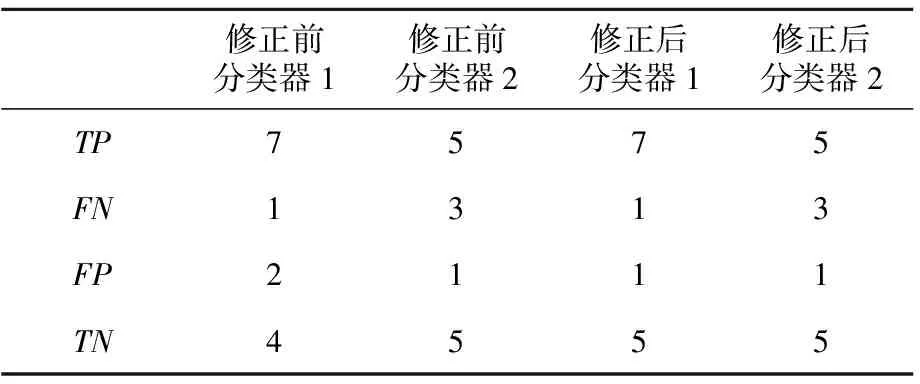
Table 4 Experiment 5-comparison 2 before and after modification
结论5经拉普拉斯修正以后,结论1~结论4依然成立。观察以上修正前后的图表可以发现,虽然谣言识别结果有所变化,但是依然符合上述结论。
结论6训练条件一定的情况下,对朴素贝叶斯分类器进行拉普拉斯修正会影响对谣言与非谣言的识别结果,且修正后的分类器识别准确率不一定会增加。首先,观察表4和表5可发现,修正前后的分类器2的识别结果是相同的。其次,分类器1的识别结果在修正前后均发生了变化,说明训练集不同会影响识别结果;但分类器2的2次识别效果均相同,说明识别结果在修正前后也存在不变的可能性。此外,观察对比图6和图7可看出,修正后的分类器识别准确率并没有完全高于修正前的,说明拉普拉斯修正不会提高识别准确率。
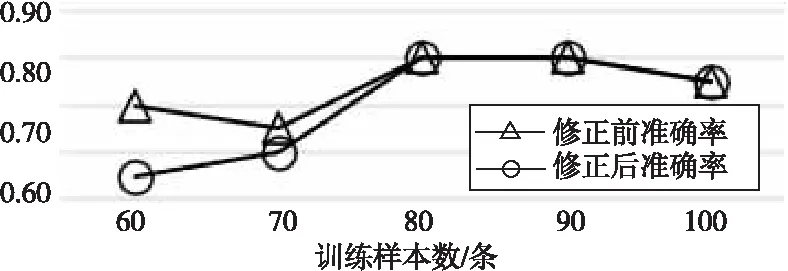
Figure 6 Experiment 5-experiment 1 accuracy comparison before and after modification
4 结束语
本文将网络谣言识别与朴素贝叶斯理论结合,通过对数据进行预处理、分词、编码和统计分析等操作,提取8个特征,分别是媒体特征、其他字符特征、符号特征、正、负、中性情感词数目特征、摹因符号特征和评论特征,利用Matlab构建朴素贝叶斯分类器实现对谣言与非谣言的分类。实验结果发现:朴素贝叶斯分类器具有良好的分类效果;通过控制训练条件发现,训练集的选取与控制对识别结果的影响较大,在训练样本数目变动时识别准确率会发生波动,其中,受先验概率的影响是一个重要原因。
本文还存在以下不足之处:(1)由于数据来源有限且通过人工收集,数据量较少,所获取的实验数据集具有一定的局限性,在未来的研究中将扩大谣言的收集范围,及时收录更多谣言。(2)朴素贝叶斯假设各个特征之间相互独立,而现实中各个因素之间往往相互联系,理论要求与现实情况存在一定的误差,在未来研究中将考虑特征之间的联系,利用贝叶斯网络分类谣言。
