基于主动联邦学习的医疗图像分割研究
2022-12-22刘靖宇杨诚奕邓云迪
刘靖宇,杨诚奕,邓云迪
(1.电子科技大学 医学院,四川 成都 611731;2.电子科技大学 信息与通信工程学院,四川 成都 611731)
近年来,科学技术飞速发展,医学诊断所依赖的医疗图像也越来越多,如:脑成像、超声图像、眼底图像等.大量医疗图像诊断需求给医生带来了极大的工作压力.医疗图像分割作为医疗图像处理技术的基础任务,其目的是将图像划分为不同区域,对其中的病例结构进行检测、提取和识别.计算机视觉(Computer Vision,CV)技术的研究在医学图像分割的应用为医生带来了许多便利,极大提升了工作效率.如Wu 等人在2019年提出了Vessel-Net,[1]通过卷积块和多路径监督模块实现了视网膜的血管分割.Ali R 等人[2]提出了一种新的基于模糊广义学习系统的技术,将RGB 图像中兴趣区域提取、数据增强和红绿通道提取聚合到一起,输入到基于模糊广义学习系统的神经网络中,对医疗图像进行分割.类似的研究在肺部和肺结节影像、[3-6]脑肿瘤分割、[7][8]宫颈鳞癌和腺鳞癌筛选等方向均有应用.
由于医疗图像的隐私性,不同医疗机构所存有的图像数据互不相通,这给深度神经网络训练出具有足够泛化能力的模型带来极大的困难.因此研究者们提出了用联邦学习[9]进行训练,即只将子节点的加密信息或训练后网络权重传输到主节点训练合并,再将网络权重分发至各个子节点(不同医疗机构),以此保证各子节点数据的隐私.Chang 等人[10]提出了一种分布式异步鉴别器对抗网络AsynDGAN,同时兼顾数据隐私保护和通信效率高的优点,在隐私敏感的健康实体学习问题上应用验证了所提出的框架.Rieke N 等人[11]在2020年探讨了联邦学习如何为未来的数字健康提供解决方案,并强调了需要解决的挑战和考虑.Sheller M J 等人[12]首次将联邦学习用于多医疗机构协作,在不共享患者数据的情况下实现深度学习建模.此后联邦学习在医疗健康方面也起到了越来越重要的作用.[13][14]
然而目前联邦学习在医疗图像分割上的效果仍然不佳,本文提出结合主动学习策略更加高效地利用子节点数据信息,以提升整体任务的效果.
1 算法描述
1.1 联邦学习
在本文讨论的联邦学习模式中,存在K 个源节点S= {S1,S2,…,SK},在节点Sk中都包含Nk个样本标签对.任务目标是利用来自K个源节点的数据信息训练出模型f,并在目标节点T上进行测试.
在联邦学习的训练阶段,通常设置一个中心节点用于汇总K 个客户端(即源节点)的训练信息.在每一轮训练开始时,每个客户端都会从中心节点复制一份网络模型f的参数W,之后根据各自局部数据Sk继续训练其客户端的模型f k.在一轮训练结束时,中心节点会将各个客户端的参数平均聚合更新中心节点的网络参数,以备下一轮训练时重新分发至其他客户端.
由于联邦学习不允许客户端直接访问其他客户端,为了在各客户端的内部训练中也能利用其他客户端的信息,本文采用FDG(Federated Domain Generalization)联邦学习模型.[15]FDG 提出利用频率空间中固有的信息,将原始图像中的分布信息分离出来,在不泄露隐私的情况下在客户端之间共享.对于尺寸为N的样本图像x,通过傅里叶变换得到其频率空间,其公式表式如式(1).
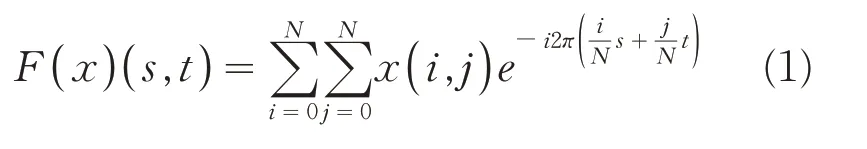
其中频率空间F(x)可以进一步分离出幅值信息Z(x)∈ℝN×N和相位信息P(x)∈ℝN×N.如图2 所示,相位信息相比幅值信息能够提供更高层的语义信息.因此在第k个客户端训练时,从其他K-1 客户端数据中随机选取M 个样本的幅值信息传入其中,再与第k 个客户端数据的相位信息经过插值生成新的训练数据集Skg=

图2 相位信息和幅值信息
1.2 图像分割网络
图像分割网络目标是对图像的所有像素进行分类以划分出前后景.首先将基础分类网络VGG16的全连接层替换为卷积层,得到全卷积网络(Fully Convolutional Networks, FCN)以保持特征的二维形态.转换后得到的FCN 结构为:Input- (64C3-64C3-P2) - (128C3-128C3-P2) -(256C3-256C3-256C3-P2)-(512C3- 512 C3-512C3-P2)*2-4096C7-4096C1-3C1,其中64C3表示卷积核为3×3、通道数为256 的卷积层;P2 表示卷积核为2×2的最大池化层.
经过FCN 的特征提取后,虽然特征保持了图像的二维形态,但相对原图的尺寸缩小了32 倍.要对原图的每一个像素都进行分类,需要通过反卷积对其上采样进行放大.[16]图1展示了FCN-8s的反卷积得到原输入尺寸的示意图.其中最后一个池化层pool5得到的特征图反卷积至32倍得到原图尺寸,记作FCN-32s;pool5 反卷积2 倍与pool4 特征相加得到合并特征,再反卷积16 倍得到原图尺寸,记作FCN-16s;FCN1-16s 的合并特征与pool3 特征相加再反卷积8 倍得到原图尺寸,记作FCN-8s.
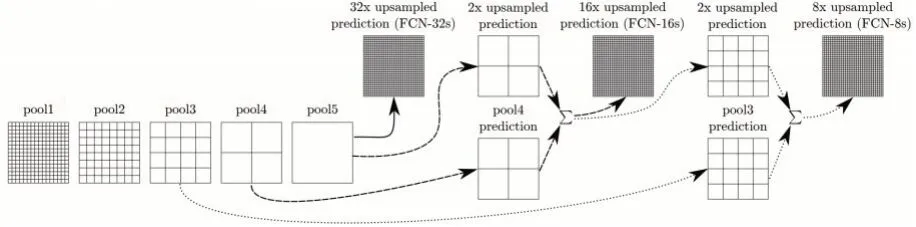
图1 图像分割网络FCN 反卷积示意图[16]
经过反卷积后得到的特征图尺寸为H×W×3,其中H 和W 分别为特征图的高和宽与原图输入尺寸一致,3 为通道数表示三个分类结果,即前景类别1、前景类别2 和背景.沿通道维度进行SoftMax 计算,得到各像素点位置对应分类的概率,即可得到前后景的分割结果以及前景对应类别.同时对每个像素分类结果计算交叉熵损失以训练网络.
1.3 主动学习策略
在FDG方法中,各客户端结合其他客户端数据的相位信息是通过随机挑选生成的,这使得模型训练过程振荡极大难以收敛,若直接选用所有客户端数据则存在数据冗余、训练消耗大的问题.本文通过设计一种主动学习策略,主动从其他客户端中挑选出对当前客户端最有训练价值的样本幅值信息.
在挑选其他客户端幅值信息时,为尽可能保证训练的稳定性,应选取与本地客户端相位信息更为匹配的样本.本文提供设计一个匹配网络来实现这一目标.
本文所设计的匹配网络结构如图3 所示.网络整体由两个全连接层组成,本地客户端的相位信息P(xlocal)和外地客户端的幅值信息Z(xout)分别传入第一层全连接层,被提取出长度为128 的特征信息,其公式表示如式(2).
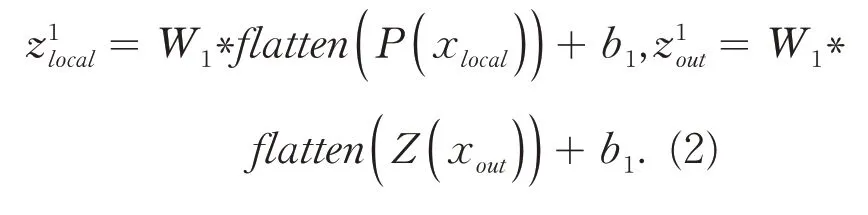

图3 匹配网络结构图
其中,flatten(·)函数是将矩阵形式的相位信息和幅值信息展开成一维向量,即

其中W2∈ℝ64×128和b2∈ℝ64×1分别为第二层的参数矩阵和偏置值.
最后,通过欧式距离计算与的相似度,再将所有其他客户端幅值信息按相似度从高到低排序,选取M 个最相似的样本幅值信息加入本地客户端生成新的训练数据.
2 实验与结果分析
2.1 数据集介绍
本文使用的数据集为MESSIDOR 视网膜数据集,[18]由法国国防研究部在2004年资助的TECHNO-VISION 项目收集建立,是目前世界上最大的眼底视网膜图像数据库,包含1200张图片.任务的目标是将眼底图像中的视杯(Optic Cup)和视盘(Optic Disc)分割出来,如图4所示.
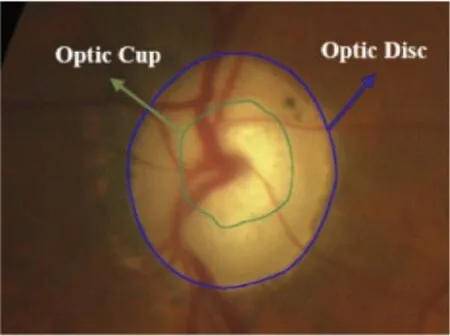
图4 眼底图像数据
原始图像包含1440×960、2240×1488 和2304×1536 三种大小,本文将所有样本统一裁剪至包含目标区域的800×800 图片,再缩小为384×384,如图5所示.

图5 图片预处理
2.2 实验设置
本文将所有样本数据划分至4个不同的客户端,各客户端的数据按3:1 分为训练集和测试集.在训练阶段,所有客户端都采用相同的超参数,采用的图像分割网络为FCN-8s,使用Adam 优化器,以0.001 的学习率更新模型参数.总共联邦训练轮次为100,每个客户端内部训练轮次为1.实验通过深度学习开源框架PyTorch 实现,所用实验环境配置如表1所示.

表1 实验环境配置
2.3 结果分析
2.3.1 主动学习与随机挑选对比
表2展示了本文所提出的主动挑选策略与随机挑选在实验中的对比结果,其中由于Dice 指标越高越好,而HD指标是越低越好,因此用Total=Dice-HD 作为整体评价指标.本文实验设置从其他客户端分别用随机和主动各选取20%和30%样本的幅值信息.结果显示,在20%的情况下,主动方法在Dice 指标上比随机高2.51%,总指标高3.75%;在选取30%幅值信息的情况下,主动方法Total 指标比随机高出3.02%.这充分说明了本文所提出的主动联邦学习方法在眼底图像分割任务上的优势.
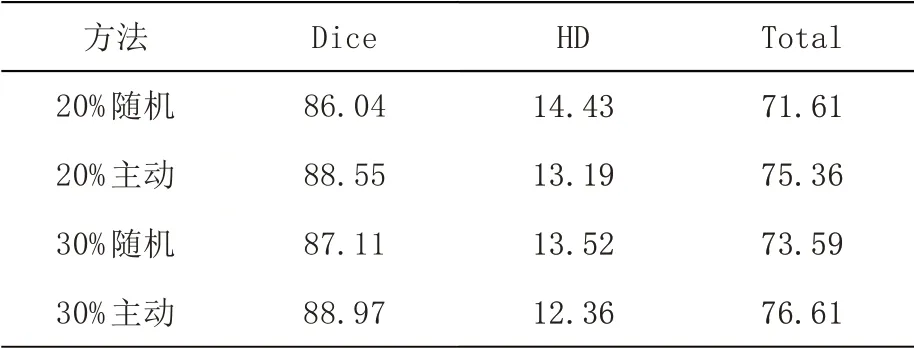
表2 随机挑选与主动方法在FCN-8s网络中的对比结果
此外,对比20%随机与30%随机的结果发现,后者的Total 指标比前者高出1.98%.30%主动比20%主动的Total指标只高出1.25%.这说明了增加选取其他客户端的幅值信息量,能够有效提升模型的性能,同样显然会带来额外的运算量.在主动学习中增加数据量带来的效果提升小于随机挑选,这是因为随机挑选的幅值信息具有不确定性,在不同比例的选择条件下实验结果波动较大.另一方面,随着数据量选择比例的增大,主动选择与随机选择的差距会逐渐缩小,因为大部分数据都被选择加入了训练.
2.3.2 不同分割网络应用的对比
为验证所提主动挑选策略在不同图像分割网络的适用性,本节实验对比了在FCN-32s、FCN-16s、FCN-8s 以及U-Net[17]四种分割网络上,主动挑选与随机挑选20%数据进行联邦学习的效果.
表3展示了本文所提主动方法应用在不同图像分割网络中的结果.结果显示在所有测试的四个分割网络上,主动挑选的方法均优于随机挑选.FCN-32s 与FCN-16s 的Total 指标低于FCN-8s,这是因为FCN-32s 与FCN-16s 反卷积所使用的特征图仅包含最后两层池化层的高阶特征,FCN-8s 融合了前两者的信息达到了最佳的效果.U-Net 作为经典图像分割网络,达到了与FCN-8s接近的效果.
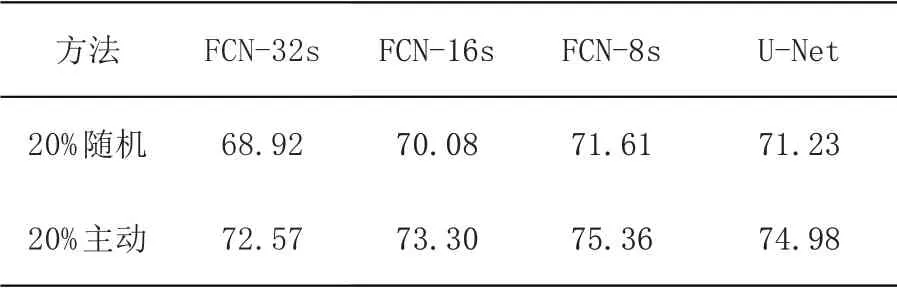
表3 随机挑选与主动方法在不同网络中的Total 结果
结 语
本文提出了一种主动联邦学习方法,在训练过程中同时保证隐私性和数据的高效利用.通过在眼底图像分割任务中的实验表明,本文所提出的主动联邦学习方法相比传统联邦学习中的随机挑选幅值信息,可以更有效的提取出对本地客户端训练最有价值的数据样本.经过在不同图像分割网络上的测试,进一步验证了本文所提方法的广泛适用性.在训练过程中,本文所提方法能够在计算量与模型效果间达到良好的平衡,仅使用有限的其他客户端样本幅值,就能达到较为理想的分割效果.但是在实际应用中,所提方法仍有一定的局限性.主动学习需要对所有客户端数据计算相似性,所消耗的计算资源较多,对比方法仍有较大的改进空间.下一步将对此难题进行深入研究,进一步提高模型的运算效率,提升模型在实际应用中的效果.
猜你喜欢
——稳就业、惠民生,“数”读十年成绩单
