基于轮廓似然估计的广义极值分布在地震中长期预测中的应用*
2022-12-21赵宜宾张艳芳王福昌任晴晴
赵宜宾张艳芳王福昌任晴晴
(中国河北三河 065201 防灾科技学院)
引言
极端事件在随机现象的研究过程中出现频率很低,比如大地震、洪水、飓风等,但这些事件一旦发生,将会给生产或生活带来巨大的影响,因此对数据样本中的极端变异性数据信息进行深入研究成为众多学者的共识,在此基础上形成的极值统计分析方法成为灾害损失评估与风险评价的重要工具.
von Bortkiewicz (1922)是近代第一个明确提出极值问题的学者,其在研究正态分布样本的极差时,发现来自正态分布的样本最大值具有新的分布;von Mises (1923)首次对正态样本极值的渐近分布进行了研究;Fréchet (1927)的研究表明,来自不同分布但有某种共同性质的最大值可以有相同的渐近分布;Fisher和Tippett (1928)将次序统计量规范化,按中心极限定理的思想,提出了极值分析渐近原理的基础性定理,完成了极值统计分析基础理论的搭建;Gnedenko (1943)对极值分布的渐近原理给出了严格的证明.在此基础上,众多学者从理论分析(Jenkinson,1955;De Haan,1970,1971)与实际应用(史道济,2006;Bhunyaet al,2012)两个方面开展了对极值理论的大量研究.
最具破坏力的自然灾害之一的地震,尤其是超强震,对社会经济造成的损失是巨大的,因此对特定区域作地震风险估计对于宏观决策和微观管理都是必要的.Nordquist (1945)将极值理论引入到震级预测过程;多名研究人员(Epstein,Lomnitz,1966;陈培善,林邦慧,1973;Yegulalp,Kuo,1974)对最大震级预测模型作了系统的研究;高盂潭和贾素娟(1988)对极值理论在工程抗震中的应用作了详细论述;陈虹和黄忠贤(1995)及钱小仕等(2012,2013)给出了基于统计分析的地震危险性评价指标及其计算方法.
对于广义极值模型,对模型分类和统计规律的表达起主要作用的是形状参数,其数值变化是研究者比较关心的.极值分布主要用极大似然估计和矩估计法确定参数取值,对于参数的区间估计,特别是地震重现水平的区间估计,传统的Delta法(Rao,1965)得到的对称区间,随着震级的提高,与预测结果在大于重现水平取值时有更大的不确定性的实际情况不符.为此,一些科研专家尝试用轮廓似然估计代替极大似然估计,用以确定极值分布的参数值.Murphy和Van der Vaart (2000)证明了在通常情况下轮廓似然估计与极大似然估计是等价的.Tajvidi (2003)、Gilli和 Këllezi (2006)及鲁帆等(2013)对各类实际问题的风险评估,证明了轮廓似然区间估计的不对称性恰是对极值变量的不确定性随取值增加而变大的较好表达.
综上所述,在基于广义极值分布对地震危险性进行评价的过程中,本文拟用轮廓似然函数进行参数估计,以便更合理地表达强震预测的不确定性.
1 极值分布相关理论简述
作为风险管理和安全评价的重要分析工具,极值分析主要针对随机变量中的极端变异性数据进行系统建模,进而对极端事件在未来发生的可能性给出预测评价.为了更清晰地表述基于轮廓似然估计的广义极值分布模型的构建过程,对重要理论和概念概述如下:
1.1 广义极值分布的基本理论
极值分析的基础定理(Fisher,Tippett,1928):若X1,X2,···,Xn,···是分布函数为F(x)的独立同分布的随机变量序列,对于任意n∈Z+,令Yn=max{X1,X2,···,Xn},如果存在常数列{αn>0}和{βn},以及非退化函数Λ(x),使得
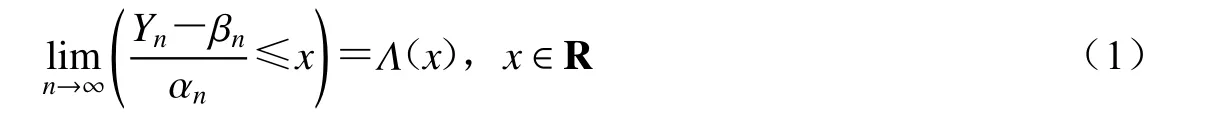
成立,则称Λ(x)为极值分布,并称F(x)属于极值分布Λ(x)的最大值吸引场,记为F(x)∈MDA(Λ).
吸引场的概念说明相互独立且服从相同分布函数F(x)的随机变量序列,在满足一定的条件下,序列的区组最大值近似服从广义极值(generalized extreme value,缩写为GEV)分布.对于验证条件αn和βn难于确定的问题,Fréchet (1927)证明了区组最大值分布规律是稳定的:即使随机变量分布不同,若区组最大值的近似分布存在,则其服从GEV分布,这是极值理论应用的基础.
Jenkinson (1955)将Λ(x)的三种极值分布形式统一为一个表达式,称之为广义极值分布.具有位置参数和尺度参数的广义极值分布的分布函数记为
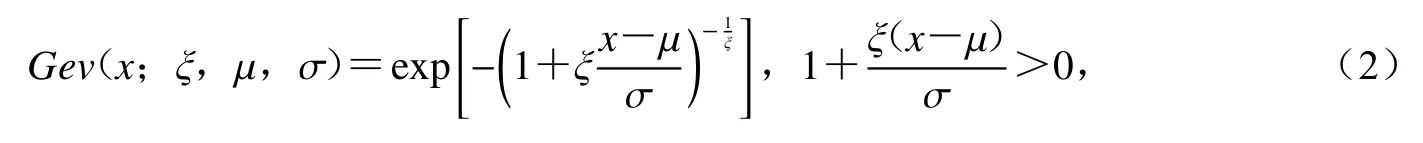
式中,ξ为形状参数,μ为位置参数,σ为尺度参数.
GEV 分布的类型由形状参数ξ的符号决定:当ξ>0时,Gev(x,ξ,μ,σ)表示 Fréchet分布;当ξ=0时,Gev(x,ξ,μ,σ)表示耿贝尔(Gumbel)分布;当ξ<0时,Gev(x,ξ,μ,σ)表示具有有限上端点的威布尔(Weibull)分布.推导过程史道济(2006)一文中有详细描述.
应用极值理论进行安全评价时,常用到分位数概念,定义如下:
设随机变量X∽F(x),若xp满足条件

则称xp为F(x)的p分位数.
从分位数的定义可知:xp=F−1(p),因此,由 GEV 分布函数(式 2)可得

若ξ<0,令p→1可得GEV分布理论的上端点

为了尽可能地满足样本之间相互独立的条件,对时间序列进行区组划分时,应设置足够长的时间间隔,以每个时间段中最大值序列作为GEV建模样本,最大限度地满足样本的渐近独立性.在此基础上,进行模型参数估计和适用性检验,最后利用模型进行安全性评价.
1.2 GEV分布参数的轮廓似然估计
GEV分布的形状参数ξ可以确定模型的分类及密度曲线形状,而分位数是安全评价的重要指标,本节将利用轮廓似然估计给出这两个重要参数的估计.
设随机变量X∽f(x,θ),θ∈Θ,其中概率密度f(x,θ)的形式已知,θ=(θ1,θ2,···,θk)包含k个未知参数,Θ为θ的可能取值范围.X1,X2,···,Xk是样本,x1,x2,···,xk是样本值,则(X1,X2,···,Xk)的联合概率密度在(x1,x2,···,xk)的函数值L(θ)称为样本的似然函数.
取 Θ0⊂Θ,令和分别为θ在Θ0和Θ中的极大似然估计值,称λ为对数似然比值,相应的λ(X)称为对数似然比统计量.史宁中(2008)的研究表明,在一定条件下,当Θ0={θ0} 时 ,有=θ0,此时有),即对数似然比近似服从自由度为k的χ2分布.这是轮廓似然估计法进行参数区间估计的理论基础.
若将θ中的未知参数分成两类, 则似然函数写作L(),其中θi是研究者重点关注的分量,相应的是θ的其它未知分量.则θi的轮廓似然函数定义为即取定θi时,函数值Lp(θi)是L)的最大值.
基于上述理论,在利用GEV分布进行安全评价过程中主要处理ξ≠0的情况,所以下文仅对ξ≠0的情况进行表述,ξ=0的推导过程与之类似.
由GEV的概率密度公式
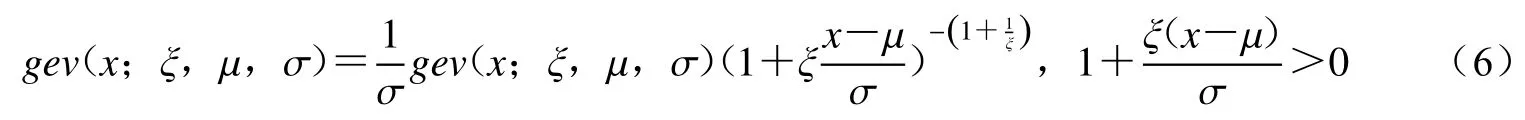
可得,GEV的对数似然函数为
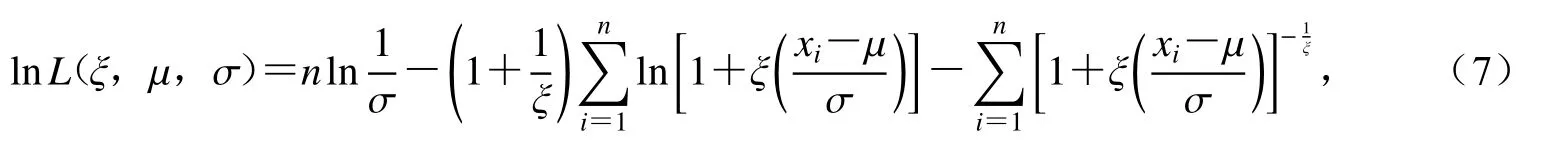
因此GEV关于形状参数ξ的轮廓似然函数可表示为即对于在可能取值范围内ξ的每个值,其函数值Lp(ξ)取在μ和σ定义范围内,使得lnL(ξ,μ,σ)取得最大值,即GEV轮廓似然函数对应的点集为

由此可得ξ的轮廓似然估计值为
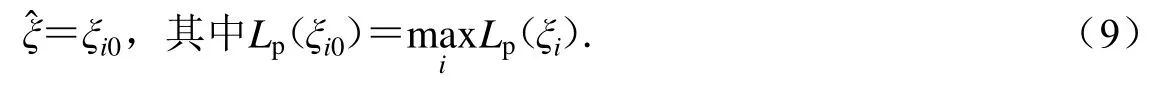

因为对数似然比近似服从χ2分布,所以当ξ=ξi成立时,λ(ξ)=2{Lp-Lp(ξ)}∽χ2(1),进而可得ξ的置信水平为1-α的置信区间为

为了求分位数的置信区间,必须在似然函数中引入参数xp.由分位数的计算(式4)可得µ=xp+σ/ξ[1-(−lnp)−ξ],将μ代入到对数似然表达式(式7)得lnL(ξ,xp,σ).因此,GEV关于xp的轮廓似然函数即对于在可能取值范围内xp的每个值,其函数值Lp(xp)取在ξ,σ定义范围内,使得 lnL(ξ,xp,σ)取得最大值,即轮廓似然函数对应的点集为
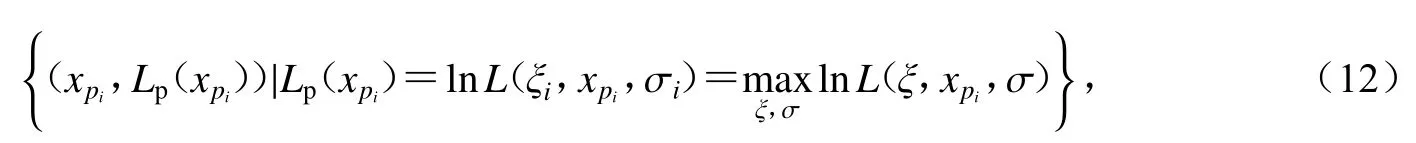
由此可得xp的轮廓似然估计值为

类似于ξ,xp的置信水平为1-α的置信区间为

1.3 地震发生的重现期与重现水平
假设X1,X2,···,Xn为某一特定区域以半年为间隔的地震震级最大值样本,在进行余震删除工作后,鉴于时间间隔比较长,可认为样本满足渐近独立性,且服从GEV分布.设第一次出现超阈值u的时间为τ1=min{k:Xk>u},令P{X>u}=1-Gevξ(u)=q,则有

另由几何分布的性质可得:相邻两次超阈值的时间与第一次出现超阈值的时间理论上是相等的,这是危险事件重现期应具备的基本属性.依上述讨论,重现期定义为给定时间序列X1,X2,···,Xn及阈值u,若序列中变量第一次出现超阈值u的平均时间为T(u),则称u为重现水平,相应的T(u)称为重现期.由上述分析可得重现水平为u的重现期为

相应地,给定重现期T,求重现期的反函数,可得相应的重现最大震级(重现水平)为

实际上重现期为T的重现水平u(T)就是GEV分布的1 -1/T分位数,即u(T)=x1-1/T.重现期与重现水平是进行地震预报分析的两个重要指标,也是进行地震应急预案制定的重要参考因素.下文将以轮廓似然估计法为工具,对东昆仑地震带的地震危险性进行综合分析.
2 基于轮廓似然估计的东昆仑地震带地震危险性分析
2.1 地震数据样本完整性分析
依据对大陆活动地块划定的东昆仑地震带区域边界(张国民等,2005),以从国家地震科学数据共享中心获取的正式地震目录为源数据,提取(82.8°E——104.2°E,33.5°N——37.1°N)自公元前193年至2019年12月的4 385条记录作为研究样本.为了最大程度地满足地震记录样本的相互独立性,采用震级相关时空窗法(陈凌等,1998)对研究样本中的余震进行剔除,得到东昆仑地震带的震例数据3 616条.本文对地震大小的描述采用面波震级MS,如果面波震级缺失,通过公式MS=1.13ML-1.08 (汪素云等,2010)将近震震级ML转换为MS,进行数据填充,进而得到用于地震危险性分析的完整数据样本.
东昆仑地震带的地震空间分布如图1a所示,整个地震带内断裂带密集排布,在高海拔地区大体沿西北向东南展布.地震带内发震点的分布呈现东北部频率高、震级低,中部和西南部频率低、震级高的特点.MS7.0以上强震基本上都发生在断裂带上,而在地壳隆起边缘的断裂带上,地震发生频率较高.
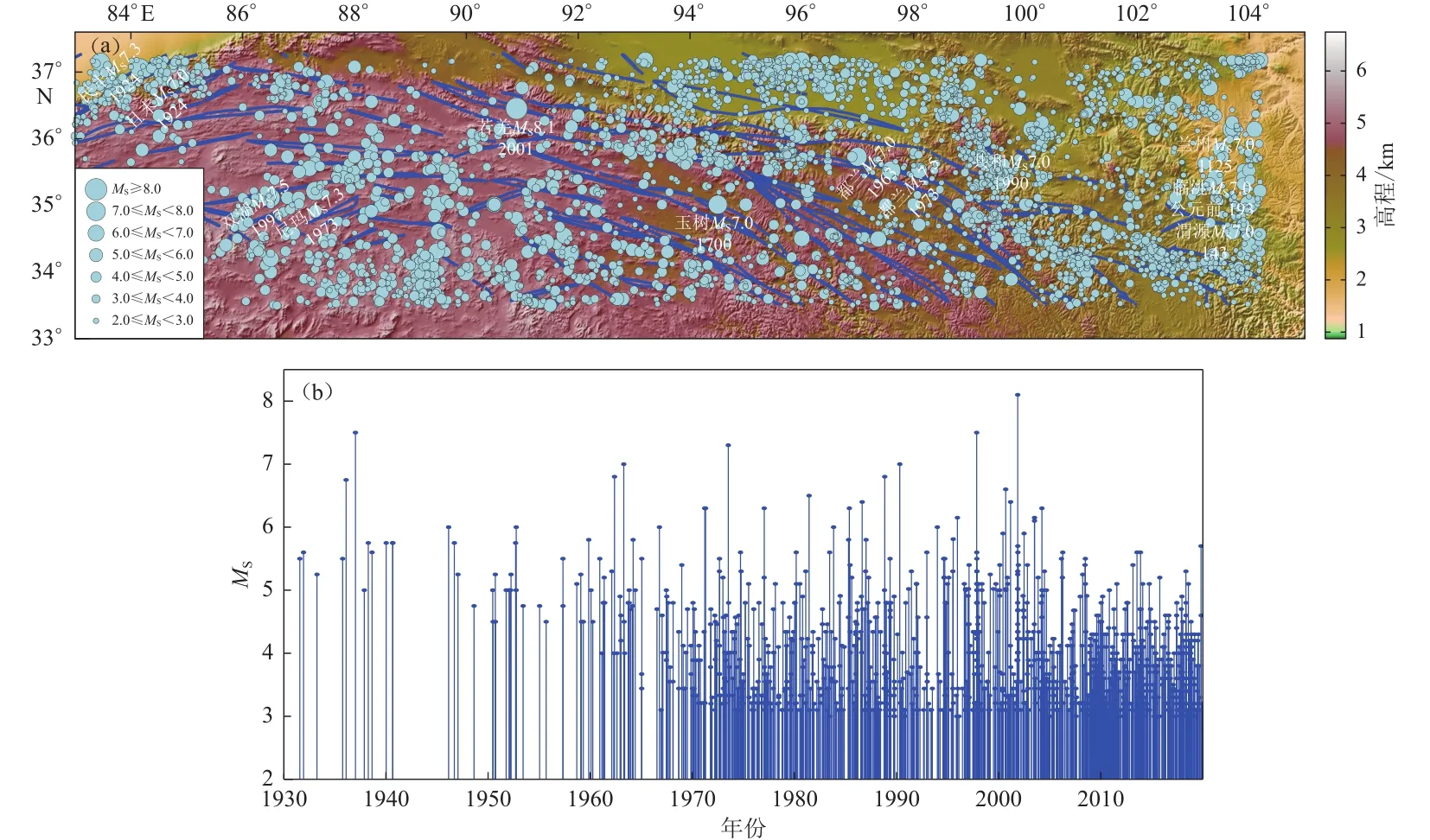
图1 东昆仑地震带的地震分布规律(a) 地震空间分布;(b) M-t图Fig.1 Distribution law of earthquakes in East Kunlun seismic zone(a) Spatial distribution of earthquakes;(b) M-t diagram
东昆仑地震带MS5.0以上地震从1937年开始记录(黄玮琼等,1994),MS6.0上地震从1926年开始记录,1970年中国地震台网建立后,发震情况记录则比较完整.1930——2019年的MS3.0以上震级与时间关系如图1b所示.M-t图表明东昆仑地震带MS4.0和MS3.0以上地震分别从1950年和1965开始才有相对完整的记录.为了尽可能地保留数据信息的同时满足模型分析对数据连续性的要求,本文以半年为区组间隔,提取了1950年后的震级最大值为地震危险性分析样本.
2.2 基于轮廓似然估计的东昆仑地震带GEV分布模型构建
按1.2节GEV分布参数的轮廓似然估计理论,以Matlab软件为计算平台,以遗传算法作为数值计算的主要工具,按如下步骤估计GEV分布的形状参数ξ:首先,设定ξ的可能取值范围为[ξl,ξu] , 对于任意ξi∈ [ξl,ξu] , 依据式(8),搜索μi,σi,使得并将满足条件的点(ξi,μi,σi,Lp(ξi))加入轮廓似然估计点集PLξ;其次,依据式(9)确定i0,由ξ的轮廓似然估计值ξi0和相应的μi0,σi0,确定GEV分布函数GEV(x;ξi0,μi0,σi0);最后,依据式(11)确定ξ的置信水平为1-α的置信区间.
根据上述步骤得到的轮廓似然估计点集PLξ如图2所示.图2表明轮廓似然函数与形状参数ξ存在类似抛物线的关系,在ξ=−0.204 0时轮廓似然函数取得最大值,此时μ=0.847 5,σ=4.834 5.进而可得,GEV 的概率密度函数中参数(ξ,μ,σ)的估计值为(−0.204 0,0.847 5,4.834 5).
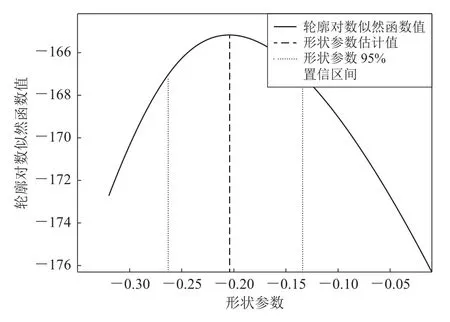
图2 形状参数与轮廓对数似然函数之间的关系Fig.2 Relationship between shape parameters and profile log likelihood function
基于轮廓似然估计构建的GEV分布模型对样本数据分析的适用性检验如图3所示.直方图轮廓趋势线与概率密度曲线基本吻合;P-P图的散点在56°线附近小幅波动,表明样本与理论分布的分位数特征基本是一致的;且ξˆ<0表示震级的重现水平有理论上限.上述检验表明,本文构建的GEV分布模型适用于对昆仑山地震带作地震危险性分析.
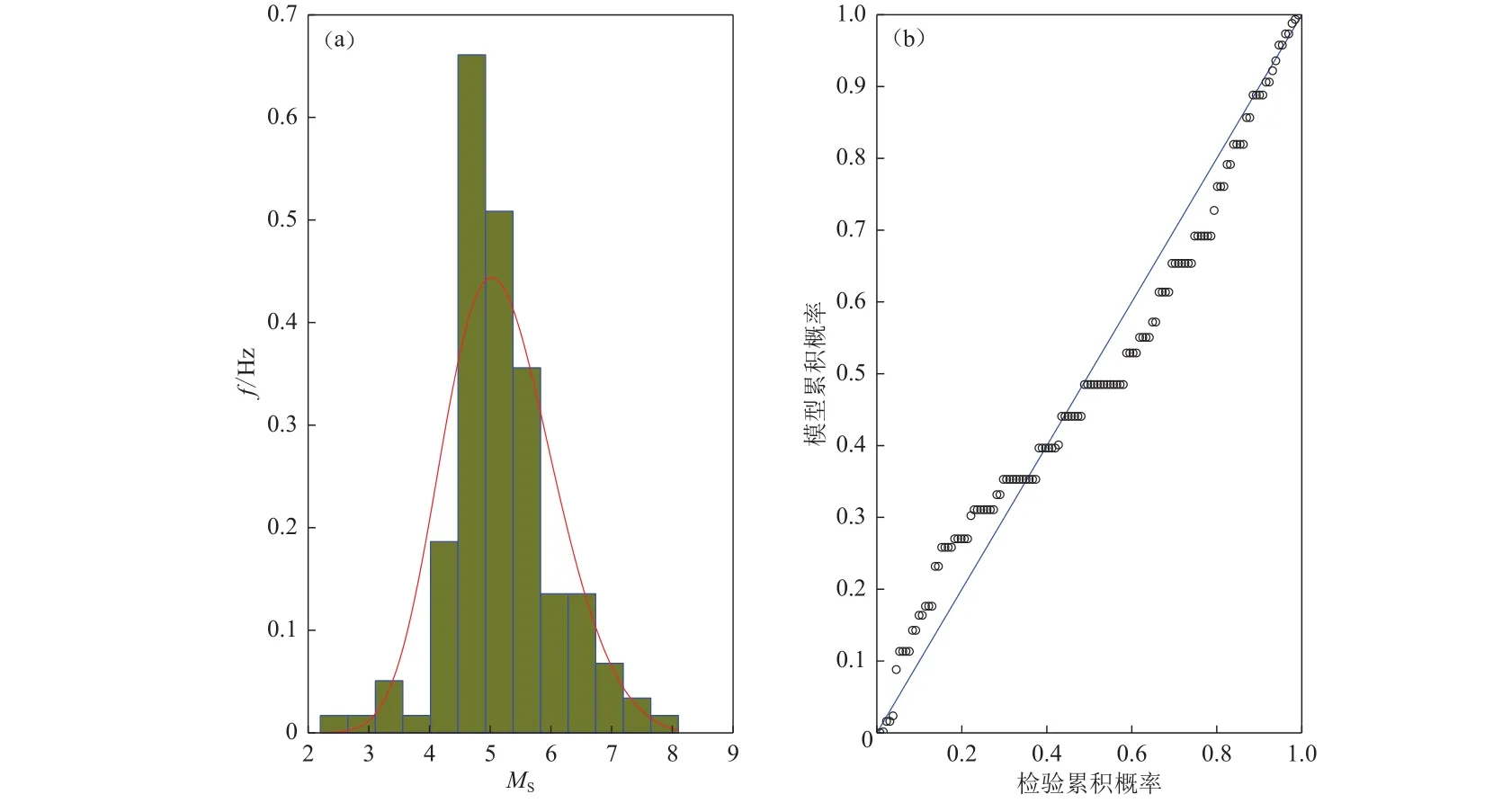
图3 GEV 分布模型适应性检验图(a) 密度曲线与直方图;(b) P-P 检验Fig.3 Adaptability test of GEV distribution model(a) Density curves and histograms;(b) P-P test
由于ξ的轮廓置信上限小于0,则依据式(10)可求震级的理论上限.同时,在区组震级X∽GEV (x;ξi0,μi0,σi0)的条件下,利用E(X)=µi0-σi[01-Γ(1-ξi0)]/ξi0,ξi0<1,可求得最大震级理论平均值,其中Γ(x)是伽马函数.
为了比较参数估计方法的差异,表1分别列出了轮廓似然法和极大似然法(钱小仕等,2012)的估计结果,在进行模型主要参数估计时,两种估计方法的效果基本相同.

表1 轮廓似然估计与极大似然估计GEV的分布结果对比Table 1 Comparation of the profile likelihood estimation and maximum likelihood estimationof GEV distribution
通过上述分析可知,东昆仑地震带每半年的最大震级平均约为MS5.2,理论上的最大震级约为MS9.0,属于巨震级别,说明这一区域的地质条件很不稳定,属于大地震发生危险性极高的地区.
2.3 东昆仑地震带重现水平及置信区间的轮廓似然估计
上文估计的半年最大震级理论均值和上限,是对地区发震情况的简要概述,对应急预案制定参考意义不是很大.重现期和重现水平是评估地震危险性的两个核心指标,在估计了GEV分布重要参数后,给定重现期T,按式(17)可以确定理论重现水平u(T).为了满足决策需要,有时需要求出重现水平的置信区间.利用信息矩阵获得的置信区间(Rao,1965)是关于置信水平对称的,但实际上随着预测震级的提高,在高于置信水平的时候,震级选择会更加离散,也就是说置信区间关于置信水平对称是不合理的.为此,下文将利用轮廓似然法来估计重现水平的置信区间.
在给定重现期的情况下,确定重现水平及置信区间可按如下步骤进行:首先,对于给定重现期T,按式(17)可以确定理论重现水平u(T),根据u(T)值设定一个相对保守的重现水平取值范围[XPl,XPu].对于 任 意xpi∈[XPl,XPu] , 依据 式 (12),搜索ξi,σi, 使得L(pxpi)=并将满足条件的点(ξi,xpi,σi,Lp(xpi))加入轮廓估计点集PLxp;其次,依据式(13)确定i0,得到xp的轮廓似然估计值xpi0;最后,依据式(14)确定xp的置信水平为1-α的轮廓置信区间.
根据上述步骤得到的重现期分别为20年、50年、100年、500年的重现水平和置信区间如图4所示.
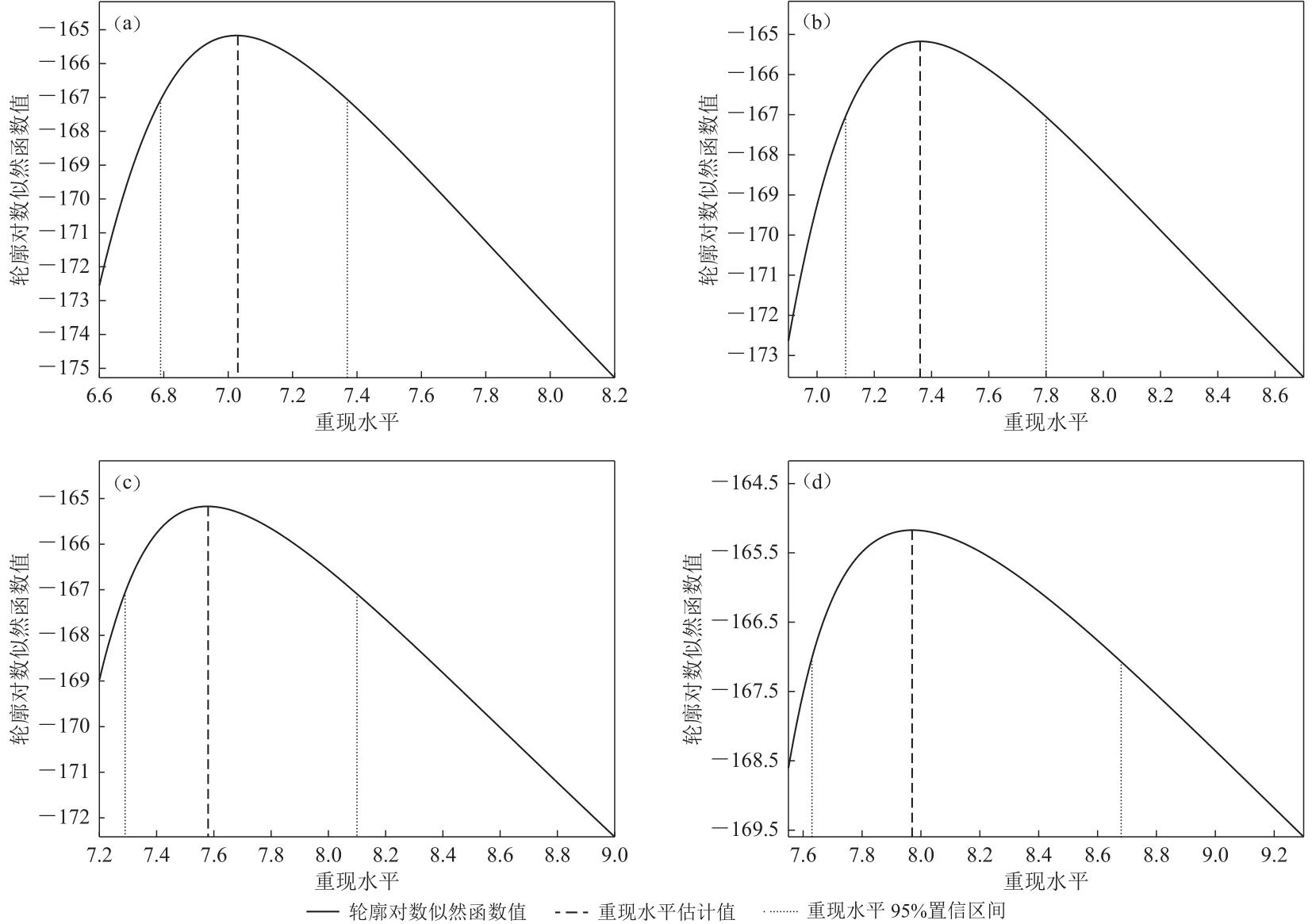
图4 重现水平及置信区间的轮廓似然估计(a) 20 年重现期;(b) 50 年重现期;(c) 100 年重现期;(d) 500 年重现期Fig.4 The reappearance level and confidence interval of the profile likelihood estimation(a) 20-year return period;(b) 50-year return period;(c)100-year return period;(d) 500-year return period
用Delta法和轮廓似然估计得到的估计结果对比分析详见表2.估计结果从数值计算的角度佐证了对于重现水平的估计,轮廓似然法与极大似然法是等效的(Murphy,Vander Vaart,2000).
表2的对比结果说明,对于重现期10年以下的重现水平置信区间的估计,轮廓似然法与极大似然法的估计结果基本相同,即针对短期地震危险性评估,两种方法是等效的.但在进行中长期地震危险性分析时,轮廓似然估计得到的估计区间整体向右偏移,即置信下限和上限比相应的极大似然估计要高,而且重现水平右侧的宽度随着重现期的提高,与左侧区间宽度之比越来越大,说明随着重现期的变长,重现水平随之提高,而且发生超重现水平的震级取值更分散,是对震级区间更为保守的预测,也是与实际情况相吻合的.两种方法估计结果的直观差异如图5所示.
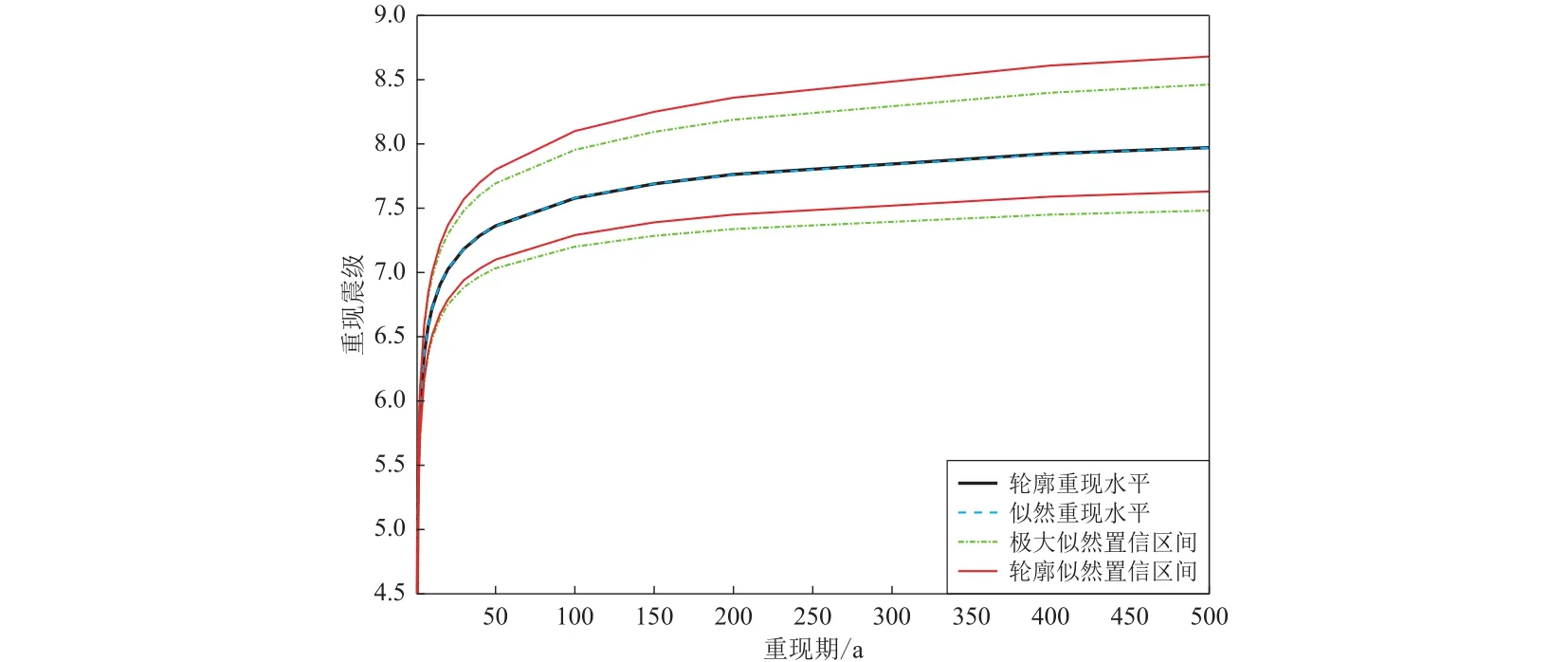
图5 重现水平的轮廓似然估计与极大似然估计对比Fig.5 Comparation of the reproduction level between profile likelihood estimation and maximum likelihood estimation
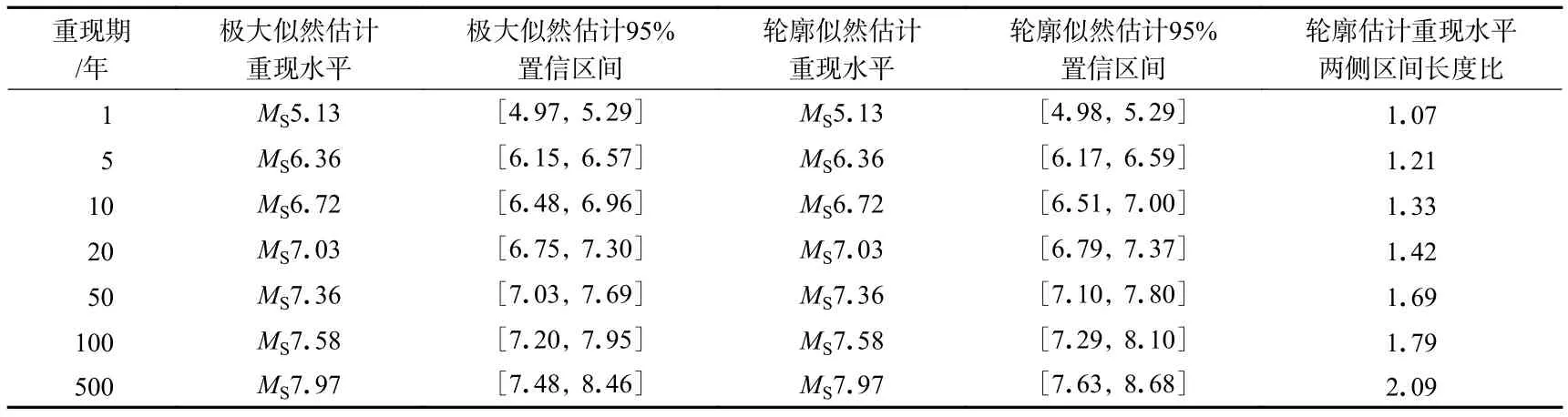
表2 极大似然估计与轮廓似然估计的重现水平对比Table 2 Comparation of the recurrence level between profile likelihood estimation and maximum likelihood estimation
本文所用源数据是东昆仑地震带截止到2019年12月的数据,为了对比两种方法的分析效果,首先截取1920年后100年的震例数据,其中大于极大似然估计下限(MS7.20)和轮廓估计下限(MS7.29)的样本数都是5个,分别为1924年和1973年的MS7.3、1937年和1997年的MS7.5以及2001年的MS8.1,其中MS8.1地震已经超过极大似然估计上限MS7.95,但在轮廓似然估计上限之内.如果估计精度为MS0.1,则大于轮廓似然估计下限的样本为3个,从数量来说,优于极大似然估计.如果截取1420年后的500年的地震数据,大于极大似然估计下限(MS7.48)的样本数为3个,分别是1937年和1997年的MS7.5,以及2001年的MS8.1,而超过轮廓似然估计下限(MS7.63)的样本只有1个MS8.1震例,重现数量上优于极大似然估计.以上实例分析表明,轮廓似然估计作为震级重现水平区间估计的理论工具,比以信息矩阵为基础的Delta法更加合理和适用.
3 讨论与结论
本文对轮廓似然估计法在广义极值(GEV)分布模型的参数估计中的应用从理论分析到数值计算进行了详细地阐述,并将构建的极值分布模型应用于东昆仑地震带的地震预报.在对参数的点估计过程中,轮廓似然估计与极大似然估计效果相当;在进行重现水平置信区间估计过程中,如果重现期比较短,两种方法估计效果几乎无差异,但在进行中长期地震预报时,轮廓似然估计法得到的重现水平置信区间对于不确定性的表达更加充分,较基于信息矩阵的Delta法得到的对称置信区间更为合理.
基于轮廓似然估计的GEV分布模型能够对地震危险性作出相对比较客观的评价,但该模型所用数据为区组最大值信息,在模型构建过程中对观测信息利用不够充分,使得由模型得到的预测结果与实际情况存在偏差,作者后续将主要从历史信息挖掘和模型调整与优化两个方向入手,以构建更加有效的地震预报预测模型.
