基于上下文注意力机制的实时语义分割
2022-12-21于润润姜晓燕朱凯赢蒋光好
于润润,姜晓燕,朱凯赢,蒋光好
(上海工程技术大学 电子电气工程学院,上海 201620)
为提高神经网络的分割质量,现有语义分割研究方法[1]使用了较深的卷积网络和复杂的网络结构,虽然取得了更高精度,但也增加了网络的参数数量。大部分语义分割算法需要耗费大量计算和显存资源,限制了该技术在移动设备上的应用。因此,实时语义分割概念被提出,并成为了分割算法的重要研究方向。针对网络参数量大和推理速度慢的问题,目前的解决方法有两种:(1)轻量化特征提取层结构;(2)多分支结构。两种结构从减少网络卷积参数和解耦网络任务两个角度来达到实时预测的目的。CAP (Context Aware Pruning for Semantic Segmentation)[2]网络通过模型剪枝,对网络特征通道数目进行轻量化处理,提升了网络预测速度,但该方法精度较低。ICNet(ICNet for Real-time Semantic Segmentation on High Resolution Images)[3]设计了三分支网络,输入图像以低、中、高3种分辨率输入到不同深度的网络中,经过多层次信息融合获得最终特征信息,在实时的前提下,获得了较高的分割精度。基于ICNet[3]网络,本文提出了更加轻量的双分支级联网络来解耦语义分割任务,获得了更快的网络推理速度。
实时分割网络由于其网络的轻量性,导致特征抽象能力较弱,缺少上下文信息。语义分割是像素级分类任务,同类物体像素点预测相对独立,特征上下文信息缺失将导致分割结果类内一致性较差。如图1(a)[4]所示,由于像素点的预测过程互相独立,特征缺少上下文信息,导致牛身体的一部分被预测成为了马。同类物体处于图像中的不同位置,因此特征表征不同,网络需要上下文信息,以便向同类物体的所有像素分配同类标签。特征缺少上下文信息还会导致类间不可区分性。不同类别的物体在图像中具有相似的颜色和纹理信息,网络提取的特征表征相似,网络需要利用上下文信息,加强两种类别之间的区分能力。如图1(b)[4]所示,电脑机箱和电脑显示器两个类别具有相似的颜色和纹理信息,机箱中的部分像素点被误分类成为显示器。为了解决这个问题,DFN(Discriminative Feature Network)[5]网络从一个更加宏观的角度重新思考语义分割,将一致的语义标签分配给一类物体而不是每个单一像素。该方法采用Smooth Network抓取不同尺度的语境信息,并通过全局平均池化抓取全局语境,学习一个鲁棒特征表征。Border Network负责区分外观相似但标签不同的相邻图像块,明确地使用语义边界指导特征的学习,并在训练时增加了语义边界监督,增大了类间差距。但是该方法的网络参数量较大,因此不适用于实时语义分割。

(a)
针对类内不一致和类间不可区分的问题,本文设计了两种轻量级的注意力机制来解决实时语义分割任务中特征缺少上下文信息的问题。为加强分割结果的类内一致性,本文通过轻量级的通道注意力机制,在通道层面进行全局上下文信息的加强,使得同类别的像素点特征向量最大响应都处于同一层,即加强通道上特征凝聚程度。为加强特征可区分性,本文通过使用轻量级的空间注意力模型,加强空间特征点之间上下文信息的流动,增强了同类别特征响应,减弱了其它类别的特征响应,从而加强了不同类别之间的特征区分能力。
本文设计了一种轻量自适应通道注意力机制和空间注意力机制,加强了实时语义分割结果的类内一致性和实时语义分割结果的类间可区分性。为了使网络轻量化,本文设计了双路径级联特征提取网络,采用高级特征分支获取抽象的语义信息,通过低级特征分支获取丰富的空间细节信息。将双分支特征融合后,可以用较低的计算量获得良好的分割结果。最后,本文在语义分割数据集CamVid和Cityscapes上进行了大量实验以证明本文提出方法的有效性。
1 注意力模型
近年来,基于注意力模型[6]的分割网络取得了较大的研究进展。注意力机制源于人类视觉研究。人类大脑每时每刻都在接收海量的数据信息,大脑选择性地关注部分信息,忽略其它冗余信息。在语义分割领域,最典型的注意力机制为文献[7]提出的双注意力网络模型DANet(Dual Attention Network)。双注意力网络包含通道注意力和空间注意力两个模型,两者并行来处理输入特征,通过融合通道空间信息增强的特征,可获得较精确的分割结果。空间注意力模块(Position Attention Module)进行所有位置特征点的互相关联,选择性地聚合加权不同位置的特征。特征图A(C×H×W)经过3个卷积操作,获得3个特征图B、C、D,进而重组(reshape)为C×N,其中N=H×W,C为特征通道数。注意力图计算式为
S=Softmax (BT×C)
(1)
式中,S表示特征中任意两点之间的依赖关系矩阵。
空间注意力模块特征计算式为
F=Reshape(α×D×BT)
(2)
式中,重组后大小为C×H×W;α为尺度因子,是可学习的参数,训练时被初始化为0。将依赖关系图加权到每个特征点进行空间注意力关系加强。
DANet[7]的通道注意力模块(Channel Attention Module)负责进行所有通道信息整合,选择性地强调互相依赖的通道映射关系。将特征图A(C×H×W)进行重组和转置操作后得到特征G(C×N)和K(N×C),其中N=H×W。将两个特征图相乘获得注意力图计算式
X=Softmax(G×K)
(3)
式中,X表示特征中任意两个通道之间的依赖关系矩阵。通道注意力模块特征计算式如下
X=Reshape(β×XT×A′)+A
(4)
式中,重组后大小为C×H×W;β为尺度因子,是可学习的参数,训练时初始化为0;A′为A重组结果,大小为C×N。
以DANet[7]为代表的注意力机制取得了良好的分割效果,但其需要计算像素点之间的关系矩阵,计算量较大,无法在实时语义分割网络使用。文献[8]提出了SENet(Squeeze-and-Excitation Network),其轻量通道注意力模块通过全局平均池化获取每个通道的特征响应,进而获取全局感受野。其计算式为
(5)
式中,u(i,j)为输入特征;H、W为特征的高和宽。使用两个全连接层来增加非线性,调整通道层面的权重,通道特征注意力计算式为
S=Sigmoid(Fex(ReLU(Fex(U)))
(6)
式中,Fex(·)为全连接操作;Sigmoid(·)获得[0,1]区间的权重结果。在通道层面增强特征之间的互相依赖关系,可获得更精确的分割结果。
2 提出的网络模型
2.1 轻量级自适应通道注意力模块
实时语义分割网络中,特征缺少上下文信息,导致预测结果中类内存在一致性较差的问题,因此本文基于SENet[8]中的轻量通道注意力网络,提出了一种轻量的自适应通道注意力模块,结构如图2所示。
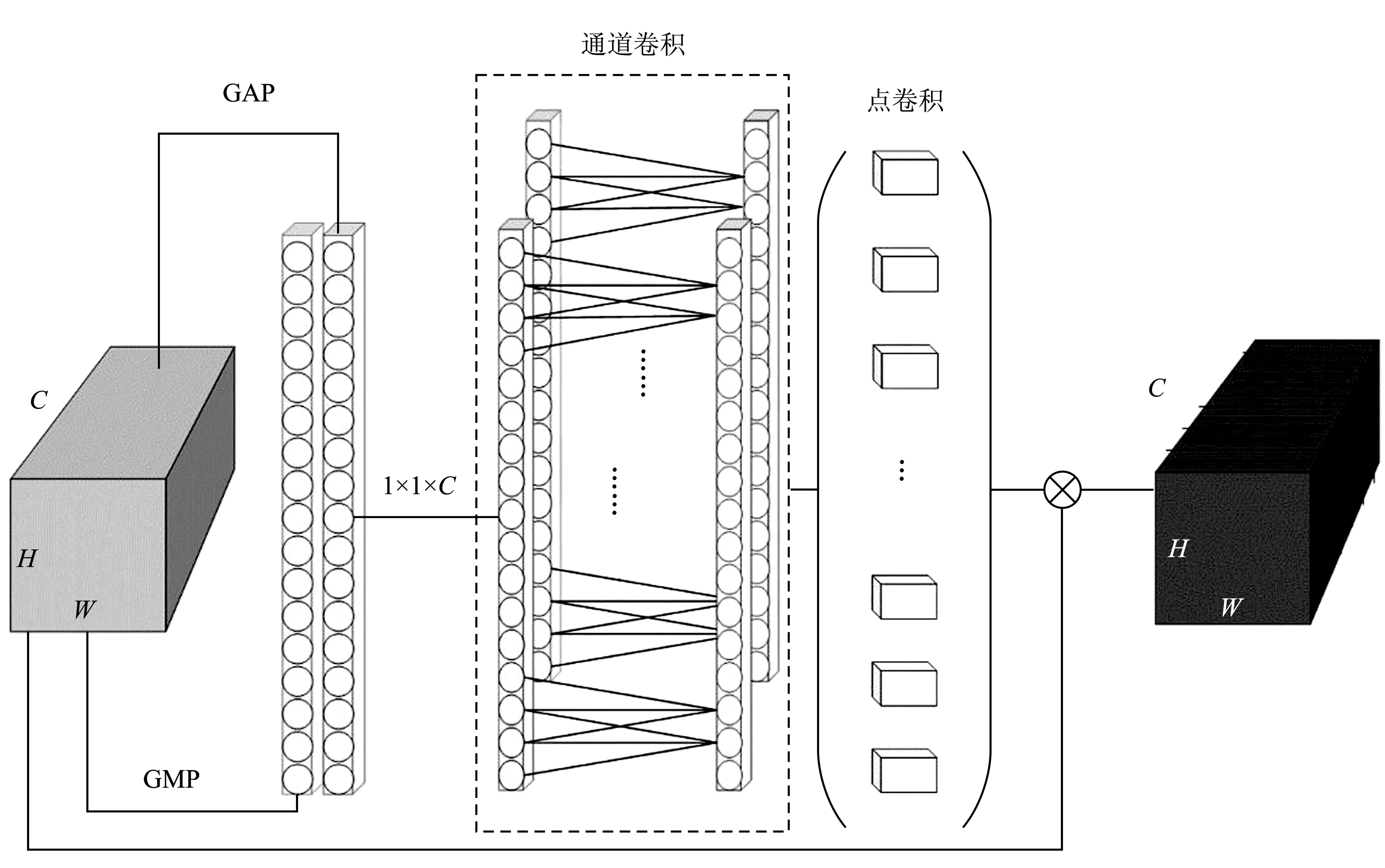
图2 自适应通道注意力结构图
将输入特征A(C×H×W)送入全局平均池化(Global Average Pooling,GAP)和全局最大池化(Global Max Pooling,GMP)用以获取全局特征信息。全局平均池化用于获取特征全局分布,每个全局平均池化的结果都具有特征全局感受野。全局最大池化用于获取每个特征通道上最大的特征响应。将上述两个特征信息向量拼接(Concate)在一起,形成特征在通道上的表征信号。本文利用深度分离卷积学习特征通道信息之间的依赖关系,依据文献[9],在深度分离卷积中的通道卷积部分,设计了自适应卷积核大小的一维卷积核,通道卷积的参数k决定原始特征提取出的通道特征的相互交互关系,k越大,交互的范围越大。将注意力机制安插在网络的不同位置时,输入特征的通道数是不同的。k应该和输入特征通道数C有关,即k=δ(C)。依据传统算法中高斯核函数被应用于处理未知的映射关系,将k和C之间关系定义为
(7)
式中,γ、b为超参数,分别设置为2和1;|t|odd表示最接近t的奇数,主要原因是通道数C通常被设置为2的整数次幂,一维卷积核共享参数。
通道表征信号经过自适应的通道卷积和标准点卷积特征融合后可获得C×1×1特征;经过Sigmoid(·)获得[0,1]区间的注意力图。该权重作用在输入特征上,在通道层面增强特征之间的互相依赖关系,并增强了特征在通道层面的上下文关系。
2.2 轻量级空间注意力模块
为了在空间层面加强特征的上下文联系,增强特征在空间域特征点的互相依赖关系,获得实时语义分割结果中更好的类间可区分性,本文设计了轻量的空间注意力模块,结构图如图3所示。
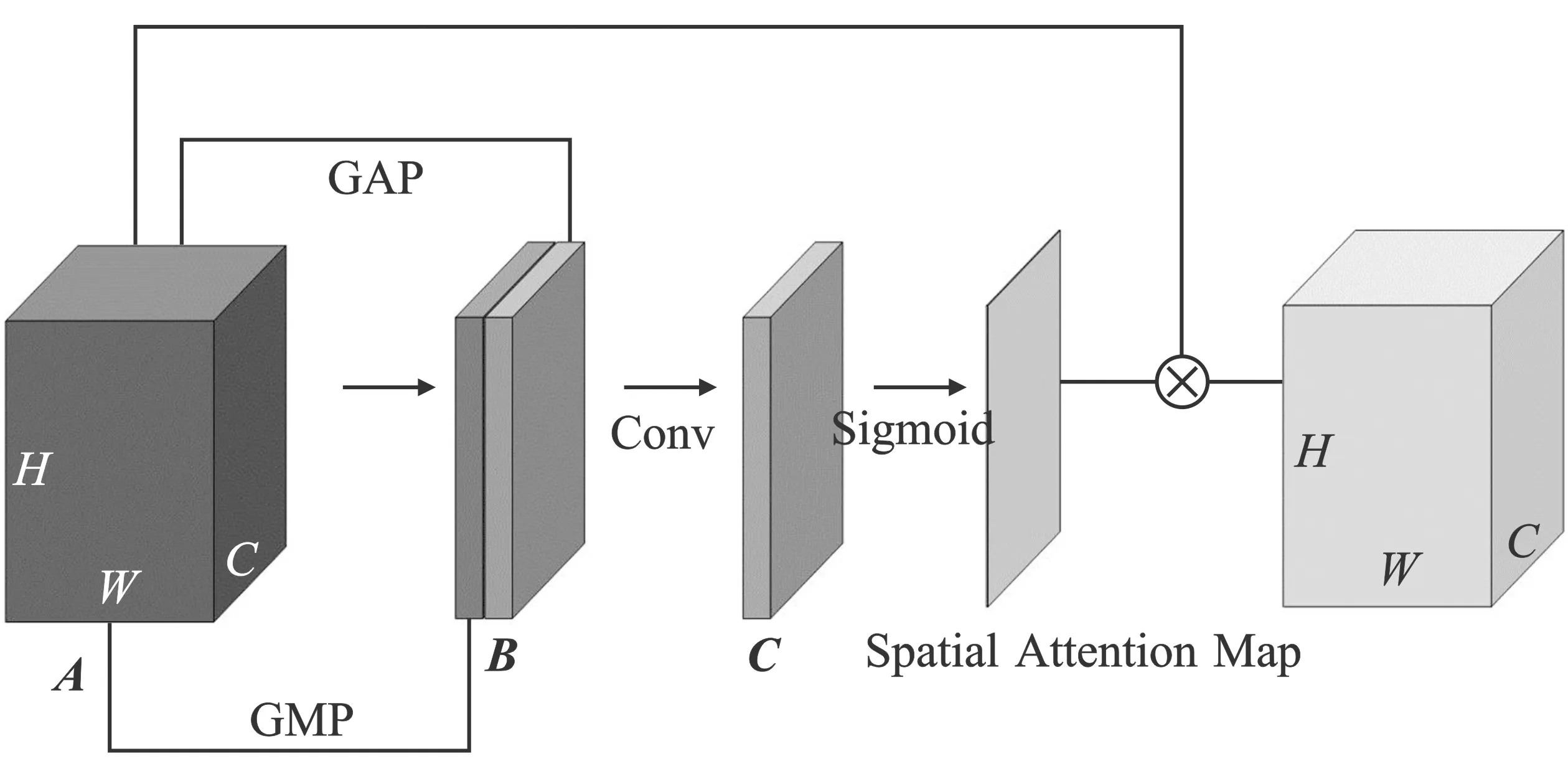
图3 空间注意力结构图
图中输入特征A(C×H×W)在每个特征点通道上使用GAP和GMP,所获得的特征经过拼接操作得到2×H×W的特征B,即输入特征的空间关系表征。为使特征信息在空间域进行特征交互,需使用较大的卷积核。为了减少计算量,本文使用分组卷积,获得了特征C,即特征点上下文依赖关系的特征。分组卷积使用沿着x和y方向的一维卷积核,维度为k×1和1×k。本文将k×k的卷积核进行拆分,从而减少了参数数量。特征C经过Sigmoid(·)获得[0,1]区间的空间注意力权重结果, 使用分组卷积,卷积核大小为7。注意力图和输入特征相乘后,即可获得空间上下文信息加强的特征信息。
2.3 双路径级联特征提取网络
文献[2]中,三分支级联结构过度分解了分割任务,中分辨率分支虽然增加了网络的参数量,但不能有效提升网络结果。基于此,本文设计了一种双路径级联特征提取网络,网络结构如图4所示。

图4 双路径级联特征提取网络结构图
本文级联网络为两个分支:低分辨率分支和高分辨分支。低分辨率分支输入图片为原图的1/4,虽然空间细节缺失,但是经过网络特征映射后可以获得较好的高级语义信息。低分辨率分支网络为PSPNet(Pyramid Scene Parsing Network)[10],在网络最高层特征输出添加轻量的自适应通道注意力,增加了高层语义信息的上下文信息,提高了分割结果的类内一致性。高分辨率路径输入图片为原图,下采样网络是3个简单的卷积层和池化层的堆叠,最大程度上保留了图像的空间细节信息。下采样网络最高层特征使用文献[3]中的特征融合模块 (Cascade Feature Fusion,CFF),通过融合低分辨率分支的特征图,使特征图中包含高级语义信息和空间细节信息。与此同时,连接轻量的空间注意力模块,增强空间域中特征点上下文信息,促进了信息流动,提高了分割结果中的类间可区分性。本文在低分辨率分支和高分辨率分支使用交叉熵损失函数来监督学习。
3 实验验证
3.1 标准数据集
CamVid[11]数据集是自动驾驶领域常用数据集,由车载摄像头拍摄的视频构成,图片分辨率为720×960,共标注了11个语义类别,将全部标注好的图片分为376张训练集、101张验证集和233张测试集。针对CamVid数据集中存在的类别不平衡的问题,本文为每个语义类别分配一个权重
(8)
式中,r为超参数,实验中设置为1.02;c1表示类别信息;Pcl表示c1类出现的概率。为扩增数据集的数据量,将数据集中所有图片进行图像缩小操作。
Cityscapes[12]数据集是高分辨率的街景数据集,图片分辨率为1 024×2 048,共标注了19个语义类别。数据集分为精细标注和粗糙标注两部分:第1部分为5 000张精准标注的图片,其中2 975张图片为训练集,500张图片为验证集,1 525张图片为测试集;第2部分为19 998张粗糙标注的图片,可以用来扩充训练集。数据集涵盖了50个城市不同场景、不同天气下的图片,是一个多变的街景数据集。本文实验不使用Cityscapes数据集中粗糙标注的训练集。
3.2 评价指标
本文对数据集测试结果使用平均交并比mIoU(Mean of Inetersection over Union),即所有类别的交并比(IoU)结果的平均值来对结果进行评价。平均交并比为图像语义分割中重要的评价指标,其计算式为
(9)
式中,数据集共K个类;Rii表示正确预测的像素数量;Rij表示i类被预测成为j类的错误像素个数;Rji表示表示j类被预测成为i类的错误像素个数。mIoU范围为[0,1],值越大代表分割出的结果越准确。
3.3 实验评估
3.3.1 实验设置
本文训练过程中,使用Adam优化器,设置CamVid和Cityscapes数据集的初始学习率为0.001,batch size分别为4和2。在训练过程中,学习率按照poly策略进行动态设置
(10)
式中,lr表示学习率;lr_init表示初始学习率;iter表示当前迭代次数;iter_max表示最大迭代次数;power为0.9。模型在CamVid和Cityscapes数据集上总共迭代训练180次和200次。所有实验均在GPU为GTX 1080Ti且操作系统为Ubuntu18.04的机器上运行。
3.3.2 CamVid数据集上实验结果
本文在来源于CamVid数据集的测试集上将本文方法与主流分割算法进行了对比,结果如表1所示。相较于基线ICNet[2],本文方法的mIoU和FPS(Frames Per Second)分别提升了1.1%和0.8。虽然本文方法的精度低于PSPNet50[10],但运行速度提升了5.3倍。本文特征提取网络为ResNet50,而DFANet(Deep Feature Aggregation Network)[15]使用轻量型的骨干网络,因此DFANet的预测时间更短。图5为本文方法在CamVid数据集上的分割结果图,其中Image为输入图像,GT(Ground Truth)为图像分割真值图。该结果表明本文提出的轻量通道和空间注意力模块获得了更精确的分割结果。

表1 在CamVid数据集上的结果
3.3.3 Cityscapes数据集上的实验结果
本文方法与当前分割算法在Cityscapes数据集的测试集上的实验结果比较如表2所示,其中DR表示是否使用了粗糙标注的图像。本文方法的性能在Cityscapes数据集上的提升比较大,与基线网络ICNet[3]相比,本文方法的mIOU提升了2.0%,验证了其有效性。虽然FRRN(Full-Resolution Residual Networks)[13]的精度高于本算法精度,但在预测时间上,本文算法比其快了14.6倍。本文方法与其它算法的精度和实时性对比图如图6所示。
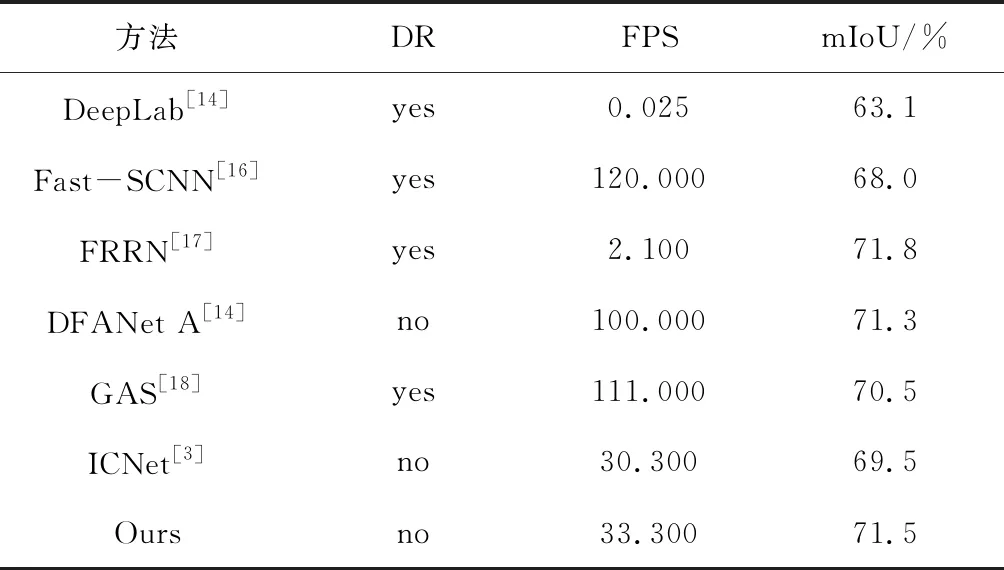
表2 在Cityscapes数据集上的结果

图6 实时性和精度对比可视化图
可视化的分割结果如图7所示,其中Image为输入图像,GT为图像分割真值图。基于上下文注意力机制的方法能够有效分割图像中的物体,分割结果图中类内不一致和类间不可分情况出现较少,证明了所提出的轻量自适应通道注意力模块可有效加强高层语义特征在通道层面的上下文信息,并增强特征的类内一致性,也验证了本文提出的轻量空间注意力机制可增强高分辨率通道在空间层面的上下文信息,促进特征信息在相邻特征点上的流动,减少类间不可分的情况。从结果中可知,本文方法精度略高于DFANet A[15]、Fast-SCNN(Fast Semantic Segmentation Network)[16]和GAS (Graph- guided Architecture Search Network)[18],且预测时间大幅下降。

图7 Cityscapes数据集分割结果图
3.3.4 消融实验
为了验证本文提出的轻量级自适应通道注意力模块和轻量级空间注意力模块的有效性,在Cityscapes数据集上进行了消融实验,实验分组为:(1)不使用轻量级自适应通道注意力模块LACAM (Lightweight Adaptive Channel Attention Module)和轻量级空间注意力模块LSAM(Lightweight Spatial Attention Module)且只使用双路径级联特征提取网络(DCFE-Net);(2)使用轻量级自适应通道注意力模块(DCFE-Net + LACAM);(3)使用轻量级空间注意力模块(DCFE-Net + LSAM);(4)轻量级自适应通道注意力模块和轻量级空间注意力联合使用(DCFE-Net + LACAM + LSAM)。实验结果如表3所示,图8展示了分割结果对比图,其中GT为图像分割真值图。

图8 消融实验结果图

表3 在Cityscapes数据集上的对比结果
4 结束语
本文提出了一种上下文信息增强的实时语义分割网络,在更加轻量化实时语义分割网络的前提下解决了分割结果中出现类内不一致和类间不可分问题。本文利用双路径级联特征提取网络,解耦语义分割任务分为低分辨率分支和高分辨率分支,网络可以实时预测。利用深度分离卷积对通道层面特征依赖关系建模,自适应通道卷积核大小,调整各通道特征响应值,强化高层特征上下文表征能力,加强实时语义分割结果类内一致性。此外,本文还利用分组卷积,以较小的计算量获得了较大的特征信息流动区域,在空间层面加强特征上下文联系,增强了特征空间细节信息,加强了实时语义分割结果类别间可区分性。实验验证结果表明,本文所提出方法在权威数据集CamVid和Cityscapes上取得了较好的性能。
