一种基于随机交叠策略的多突变点在线检测方法
2022-12-21朱俊俊齐金鹏钟金美曹一彤
朱俊俊,齐金鹏,钟金美,任 晴,曹一彤
(东华大学 信息科学与技术学院,上海 201620)
在当今的大数据时代[1-3],在医疗服务、健康保健和卫生管理过程中产生了海量数据集,形成了健康医疗大数据。面对大量的医疗数据,快速分析数据流中的有效信息[4-6]已成为当前的研究热点。突变点检测技术是数据流研究方向的一个重要分支[7-10],受到了越来越多的关注。癫痫病人病理信号是一种典型的大规模时序数据,对其进行分析检测需要较高的准确性和时效性。针对大规模的病理数据进行在线突变点检测分析也逐渐成为当前研究的热点方向。
传统的突变点检测方法以离线为主,无法对大规模的时序数据进行在线检测。国内外学者在突变点检测领域取得了一系列研究成果。文献[7~9]提出了基于距离或相似程度的检测方法,利用迭代方法优化事先设定的目标函数,最终得到了目标函数的最优解,即可将不满足条件的点确定为突变点。单总体T检验(Student′s Test)可判断一个样本平均数与一个已知的总体平均数的差异显著性,适用于样本数据较小的情况,当样本数据属于大规模时序数据时,T检验的检测效果较差[10]。KS检验(Kolmogorov-Smirnov Test)则基于累计分布函数[11]。两样本的KS检验对两样本经验分布函数的位置和形态参数的差异较为敏感,因此成为了比较两样本差异的最常用的非参数方法之一。但是,上述几种方法在进行大规模时序数据检测时,不仅具有时耗较长、精度较低等问题,还没有加入缓冲区,因此无法针对大规模在线时序数据流进行在线分析检测。
针对传统算法无法在线检测、检测精度不高和时耗较长等问题,本文在TSTKS(Ternary Search Tree and KS)[12]算法和滑动窗口模型的基础上,加入缓冲区模型和随机交叠策略,提出了一种基于滑动窗口[13-14]随机交叠策略的检测方法:首先,利用缓冲区接收在线数据流,将数据复制到数据接收器中;然后,在数据接收器中使用基于随机交叠策略的滑动窗口将数据流切分成子数据段;最后,对每个滑动窗口使用TSTKS算法进行多突变点检测[15-17]。该方法集合了TSTKS算法、滑动窗口、缓冲区、随机交叠策略,可在线快速高效检测时序数据多突变点[18-20]。
1 理论基础
1.1 方法概述
相比于传统的离线检测方法,本文提出了一种利用缓冲区模型和随机交叠策略的在线检测方法。步骤如下:(1)先构建缓冲区模型,利用缓冲区模型接收时序数据流;(2)将缓冲区内的数据发送到数据接收器中,在数据接收器中利用TSTKS算法和滑动窗口随机交叠策略,对所接收到的数据流进行多突变点检测;(3)将检测出的突变点放入突变点集合中,并在原始数据集中标注出突变点的位置。时间序列是一个n维的集合,其可被定义为
Zn={x1,x2,x3,…,xi,…}
(1)
式中,xi代表某个数据流在i时刻的一个数据向量。当n=1时,Zn表示单变量时间序列;当n≥2时,Zn表示多变量的时序序列。系统框架图如图1所示。

图1 基于随机交叠策略的多突变点在线检测方法框架图
如图1所示,对于在线时序数据流Z,本文首先利用缓冲区buffer将数据流复制到数据接收器中;然后,在数据接收器中使用基于交叠策略的滑动窗口对数据进行分割;随后,在滑动窗口中使用TSTKS算法进行多突变点检测,并将各个窗口中检测到的突变点信息放置到的突变点集合中;最后,本文根据突变点集合中的位置信息,在原始数据流中对突变点的位置进行标记。
1.2 缓冲区设计
在线检测模型中,数据缓冲区被用于实时接收时序数据,这些被接收的数据将在随后被放置到数据接收器中进行多突变点检测。缓冲区接收时序数据流的示意图如图2所示。
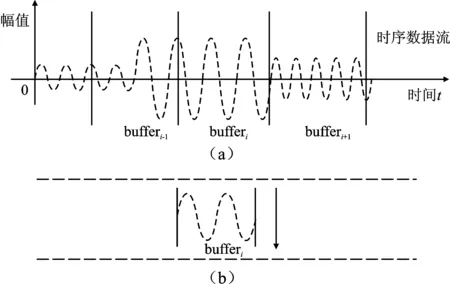

图2 缓冲区模型设计示意图
图2(a)中,箭头为数据流的流向,bufferi表示当前时刻第i个缓冲区。本文所提方法使用bufferi接收在线数据流,当缓冲区满载后,将数据输入到如图2(c)所示的数据接收器中,以便进行多突变点检测。操作时,不断循环此过程,直至数据流结束。
本文中,缓冲区的大小仅依赖于当前的时序数据的流速。针对不同的数据流,缓冲区的大小需要灵活设置。本文将缓冲区的长度设为BS(Buffer Size),则缓冲区长度的计算式为
BS=t×ω
(2)
式中,t为时间系数;ω表示在线数据流的流速。
1.3 滑动窗口随机交叠策略
为了避免当突变点处于滑动窗口边缘时的易漏检问题,本文提出了一种基于滑动窗口的随机交叠策略。当缓冲区接收到数据流后,先在数据接收器中新开辟一段与缓冲区大小相同的数据空间,再将缓冲区内的数据流复制到数据接收器中,并使用基于滑动窗口的随机交叠策略和TSTKS算法进行多突变点检测。滑动窗口随机交叠策略示意图如图3所示。

图3 基于滑动窗口随机交叠策略示意图
图3中,以bufferi为例,虚线框为滑动窗口,Wi表示第i个滑动窗口的长度。在bufferi中使用多个滑动窗口,并将待检测的数据流划分到多个滑动窗口中,然后在每个滑动窗口中使用TSTKS算法进行多突变点检测。黑色阴影部分为滑动窗口随机交叠部分,Si为第i个滑动窗口和第i+1个滑动窗口随机交叠部分的长度。随机交叠策略中,随机交叠参数为
Ti={ti|0 (3) 式中,Ti是随机选取的一个数值。设当前滑动窗口的长度为Wi,则随机交叠部分的长度Si为 Si=Ti×Wi (4) 对于下一个滑动窗口Wi+1,定义其左边界为WLj,右边界为WRj,根据式(4)中得到的Si可以得到 WLj=Wi-Si (5) 式中,i,j∈N,j=i+1 。下一个滑动窗口的长度为Wj, 则可以确定其右边界为 WRj=WLj+Wj (6) 至此,完成了一次交叠窗口的更替。 为了更加直观地突出算法的有效性,本文提出了3条性能评价指标,分别是时耗Tim、命中率Hit和平均绝对误差(Mean Absolute Error,MAE)。时耗表示算法对整段数据完成突变点检测耗用的时间。命中率表示正确检测的突变点个数占预先设置的突变点个数的百分比,可以表示为 (7) 式中,cp为检测到的正确突变点个数;N为预先设置的总的突变点个数。对于多突变点检测算法而言,平均绝对误差表示算法检测出的每个滑动窗口内突变点与实际突变点位置距离绝对值的和与N的百分比,可以表示为 (8) 式中,i、j为正整数;Test表示检测出的突变点集合;Rel表示实际突变点集合。 实验中,首先选取不同的buffer长度,并验证buffer长度对实验结果有影响;随后,对比分析滑动窗口算法与滑动窗口随机交叠算法的多突变点检测实验结果,以验证随机交叠策略的有效性;然后,分析TSTKS算法和HWKS(Haar Wavelet and KS)算法、KS检验、T检验在加入缓冲区和随机交叠策略后对多突变点检测效果的影响;最后,选取癫痫病人发病状态的部分肌电数据进行实验分析,以验证算法对真实数据的影响。 2.1.1 缓冲区长度对比实验 本实验中,仅根据时序数据的流速来决定buffer的长度,针对不同的数据流速,需要灵活调整buffer的长度。本文对比分析了不同buffer长度对多突变点检测结果的影响,结果如图4所示。 (a) 图4中,仿真数据长度为215,设置了10个突变点位置,粗方框L表示缓冲区。图4(a)~图4(d)分别对应不同的buffer长度,分别是29、210、211、215。从对比实验图中可以看出,随着缓冲区长度逐渐增大,突变点检测效果也逐渐变好。这是由于当缓冲区长度较小时,对于相同长度的仿真数据,需要切分的子段会增多,此时突变点位于缓冲区边缘的概率增加,导致突变点漏检。从该实验结果可知,buffer长度影响多突变点检测效果。 2.1.2 滑动窗口随机交叠策略对比实验 在数据接收器内,用滑动窗口选中一段数据,随后将时序数据切分为几个数据子段,并将子段放置到滑动窗口中进行突变点检测。本文对比了在滑动窗口交叠与不交叠两种策略下的检测结果,如图5所示。 (a) 图5中,仿真数据长度约为16 500,设置了10个突变点。利用缓冲区接收时序数据,在数据接收器中对数据进行多突变点检测。粗方框内的矮形细框为滑动窗口,在图5(a)中滑动窗口交叠,图5(b)中滑动窗口未交叠。从实验结果可以看出,滑动窗口交叠策略检测出突变点的效果明显优于不交叠策略检。 2.1.3 与其他算法对比实验 将TSTKS算法与HWKS算法、KS检验、T检验进行对比,在4种算法中均加入缓冲区模型和滑动窗口随机交叠策略,并对仿真数据进行多突变点检测。通过分析4种算法的时耗、命中率和相对误差来验证算法的有效性。各算法检测突变点效果图如图6所示。 (a) 图6中,仿真数据长度为16 500,设置了10个数据突变点,buffer的长度设置为211,滑动窗口长度设为29。如图6所示,各算法加入缓冲区模型和随机交叠策略后, TSTKS算法和HWKS算法可基本确定突变点的位置,而KS检验和T检验法的误判较多,算法精度较差。在进行1 000次试验后,得到如表1所示的实验数据。 表1 4种算法性能指标对比表 由表1可得,加入缓冲区模型和随机交叠策略后,TSTKS算法和HWKS算法的命中率较高,HWKS算法时耗最小,TSTKS算法次之,KS检验和T检验时耗较长,准确率较低。 2.2.1 缓冲区长度对比实验 由于模拟数据具有一定的局限性,因此本实验基于癫痫病人的肌电数据对在线算法和离线算法进行对比测试。肌电数据来自PhysioBank数据库,实验中选取了癫痫病人发病初至发病结束的部分肌电 (Electromyogram,EMG)数据,数据长度为214。本实验对真实肌电数据进行缓冲区对比实验,缓冲区长度分别选取29、210、211、214。由于真实数据不同于模拟数据,故在本实验中选用SF和DF来衡量算法的准确性,其中SF表示检测到的突变点前后两段的统计波动,DF表示检测到的突变点前后两段的细节波动,Tim表示时耗。突变点的位置往往出现在两段数据统计波动和细节波动最大处,距离突变点越近,数值越大。实验对比图如图7所示,实验结果如表2所示。 (a) 表2 肌电数据缓冲区长度对比 由图7和表2可知,算法基本能够检测出发病开始和发病结束位置的突变点,基本没有误检的突变点。但对于不同的缓冲区长度,表2中的数据有较明显的不同。随着缓冲区长度不断增大,时耗相对较低,但统计波动、细节波动有较明显的变化,统计波动先增大后减小,细节波动先减小后增大。由此可知,面对真实数据时,缓冲区长度的选取将影响算法检测多突变点的准确性。 2.2.2 与其他算法对比 本实验中,使用真实病理数据癫痫病人的部分肌电数据作为研究对象,将TSTKS算法和HWKS算法、KS检验、T检验进行对比。本文在4种算法中均加入缓冲区模型和滑动窗口随机交叠策略,对真实肌电数据进行多突变点检测。通过分析各算法的时耗、统计波动和差值波动来验证算法的有效性。实验对比图如图8所示,实验结果如表3所示。 (a) 表3 不种算法性能指标对比表 本实验中将buffer长度设置为211,滑动窗口长度设为26。分析图8和表3可知,TSTKS算法和HWKS算法基本可以检测到肌电数据中突变点的起始位置和结束位置,KS检验和T检验对肌电数据突变点的检测比较集中,无法较准确地检测出突变点的起始和结束位置,说明TSTKS算法和HWKS算法对肌电真实数据的多突变点检测效果比KS检验、T检验好。从表3可以看出,TSTKS算法检测出的突变点位置的VF和DF相对较大且时耗较小,说明算法的整体效果较好。 本文将时序数据作为研究对象,在TSTKS算法基础上引入缓冲区模型和滑动窗口随机交叠理论,提出了一种基于随机策略的在线突变点检测算法。该方法利用缓冲区接收在线时序数据流,在数据接收器中使用基于随机策略的滑动窗口切分数据,并在滑动窗口内使用TSTKS算法进行多突变点检测,以此来提升算法的精度。本文利用模拟数据和真实脑电数据进行仿真实验,证明了与滑动窗口算法相比较,本文所提出的算法时耗较短,命中率较高,能够解决面对大规模时序数据在线检测所面临的时耗长、精度差等问题,可作为大规模病理数据快速分析的备用方法。1.4 性能指标
2 实验对比与分析
2.1 仿真实验分析




2.2 病变数据流实验分析




3 结束语
