基于Winograd算法的可重构卷积神经网络加速器
2022-12-21袁子昂冉敬楠
袁子昂,倪 伟,冉敬楠
(合肥工业大学 微电子学院,安徽 合肥 230601)
卷积神经网络(Convolutional Neural Networks,CNN)被广泛地应用在图像处理[1-2]、自动驾驶[3-4]等领域。卷积神经网络在人工神经网络的基础上引入了卷积层,使网络计算量激增。为了提高计算效率并提升系统响应速度,利用ASIC(Application Specific Integrated Circuit)、FPGA(Field Programmable Gate Array)等高性能硬件来对CNN网络计算进行加速[5-7]已成为主流趋势。设计高效的卷积计算结构已成为这类硬件加速器的设计重点。
针对上述问题,文献[8]使用Winograd算法加速卷积计算,减少了卷积过程中的乘法数量,该方法的性能相对于传统卷积性能提升了2.25倍。但该方法的卷积过程需要进行连续矩阵乘,增加了中间结果存储带来的访存消耗。文献[9]设计了一种可重构的神经网络硬件加速器,加速器可根据不同的通道数和PE数量去重构PE阵列进行卷积计算,提高了资源利用率和运算效率,其图像分类效率提高了31%。但该加速器在进行其他计算时资源利用效率较低。文献[10]所涉及的可重构加速器可在不同计算任务下,重新配置运算器电路结构,对不同的计算进行加速,提升了资源利用效率。
针对上述问题,本文将Winograd计算划分成多个计算阶段。对于文献[8]中的访存周期损耗,本文将上一计算阶段的结果数据进行转换,使其可以作为下一计算阶段的输入,减少了计算过程中的访存时间,提升了计算效率。本文在各计算阶段中使用多个PE进行联合并行计算,复用已变换的输入特征图和卷积核进行多输出通道并行计算,在减少数据搬移损耗的同时提高了系统的计算效率。相较于文献[9],本文设计了多种计算模式的优化重构计算结构和相应的数据分配和访存策略,提高了不同计算的资源使用效率和单位运算器的计算效率。
1 CNN算法
1.1 CNN推理训练过程
CNN神经网络结构如图1所示,其由卷积层[11]、池化层[12]和全连接层依次级联构成。

图1 CNN网络结构
推理过程从网络输入开始,每层按表1的推理计算式进行计算[13],并将上一层的输出作为下一层的输入,逐层计算直到最后一层。训练过程则相反,将网络实际输出结果和标签值计算得到的网络误差作为最后一层的输出误差[14],从最后一层开始对输出误差进行反向传播[14],每层的传播误差计算方式如表1所示。网络根据每层的传播误差更新对应层的参数。网络通过不断训练来调整各层参数,以使整个网络的输出不断向标签值逼近。

表1 推理训练公式

续表1
表1中,Wl为全连接层l的权值矩阵;Bl为全连接层l的偏置矩阵;α为学习率;Kl为卷积层l的卷积核;Xl为l层的输入,Zl为未经过激活函数的l层输出,Ol为l层经过激活函数的输出;δl为l层的输出误差;Sl为传播到上一层l的反向传播误差;σ为激活函数,σ′为激活函数导函数;⊙代表点乘计算。
1.2 Winograd卷积计算
Winograd是一种快速卷积算法。将输入特征图和卷积核转换到Winograd域进行计算,可以降低乘法复杂度。本文将卷积结果尺度为m,卷积核尺度为n的卷积定义为F(m,n)。在一维卷积下,对于F(2,3),假设输入In=(In0,In1,In2,In3),卷积核W=(W0,W1,W2),卷积结果R=(R0,R1),普通滑窗卷积计算过程如式(1)所示。
(1)
采用Winograd算法先对卷积核和输入进行如下变换
(2)
通过式(2)将式(1)变换成
(3)
将式(3)整理可得式(4)
R=AT[(GW)⊙(BTIn)]
(4)
式(4)可以推广到二维卷积
R=AT[(GWGT)⊙(BTInB)]A
(5)
式(5)为Winograd卷积计算式。其中,In为输入特征图;W是卷积核;⊙代表点乘计算;AT、BT、G都是变换常数矩阵。参数矩阵如下
(6)
式(5)可用于不同卷积核大小和输出规模的卷积,只需调整参数矩阵大小和参数即可。
定义1个二维卷积,卷积的结果尺寸为m×n,卷积核尺寸为r×s。由于式(6)中的变换常数矩阵AT、BT的参数值都为1、0、-1,因此可简单地通过符号位取反和取零操作代替乘法。如图2所示为传统的滑动卷积所需的m×n×r×s次乘法,Winograd算法所需的乘法次数相比传统的滑动卷积下降到了(m+r-1)×(n+s-1)次。对于F(2,3),传统的卷积算法需要36次乘法,而Winograd算法只需要16次乘法,乘法复杂度降低了2.25倍。

图2 滑窗卷积计算过程
1.3 卷积核梯度计算
如表1中所示,在CNN网络的卷积核梯度计算中,由于反向传播误差δl和卷积层输入特征图Xl通常都是大规模矩阵,而卷积核梯度为两者卷积计算结果,因此梯度计算的计算量和数据搬移量较大。假设训练过程中反馈误差δl为30×30大小的矩阵,输入特征图Xl为32×32大小的矩阵,这两者卷积时,相邻卷积窗中的输入特征图数据重复度可达87%,若采用传统的卷积方式则会使很多重复的数据被反复搬移,复用这些重复数据则可以减轻数据搬移损耗,并提高计算效率。
卷积核梯度计算中的数据关系如图3所示,其中PE_G1~PE_G3代表3组PE,每组含3个PE。利用9个PE分别对输入的误差矩阵数据和相对应的输入特征图数据进行乘累加计算,从而完成卷积核梯度计算。如图3所示,输入PE_G1~PE_G3进行乘累加的误差矩阵数据和输入特征图数据的对应关系,其中XR0代表Xl的第1行行向量,WR0代表δl的第1行行向量,PE_G1对XR0~XR29和对应WR0~WR29进行乘累加;PE_G2中对XR1~XR30和对应的WR0~WR29进行乘累加,灰色方格所代表的的行向量在当前PE分组内为无效计算数据。如图3所示,输入组内PE进行乘累加的δl和Xl行向量内的数据对应关系,以PE_G3组对WR0和XR2的乘累加计算为例,其中W0代表行向量WR0的第1个数据,X0代表行向量XR2的第1个数据。PE_7对X0~X29与相对应的W0~W29进行乘累加计算,灰色方格所代表的X30~X31为无效计算数据。同理,采用PE_8对X1~X30及其对应W0~W29进行乘累加计算。以上PE计算所需的数据,可通过以下数据分配方式得到:
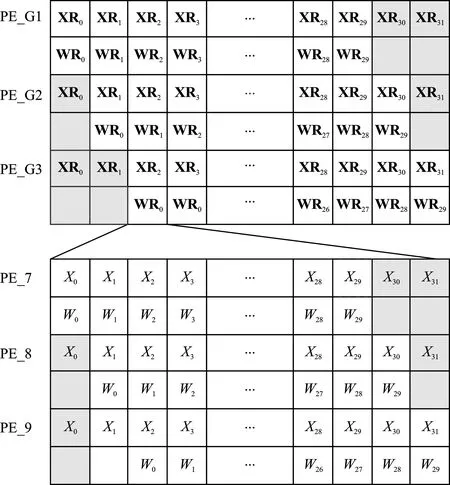
图3 卷积核梯度计算中的数据对应关系

表3 加速器的性能对比
(1)卷积层输入矩阵数据以广播的方式按行同步发送至各个PE;
(2)误差矩阵数据先按行发送到PE_G1中的PE_1,随后通过PE间的脉动传递机制,发送到各个PE中。组间延迟传递中,PE_G1中的PE1会将输入的误差矩阵数据延迟误差矩阵尺寸个周期发送到PE_G2中的PE_4;同理,PE_G2中的PE_4将输入的误差矩阵数据发送到PE_G3中的PE_7。组内延迟传递中,PE_1会将输入的误差矩阵数据延迟一个周期发送到PE_2中,PE_2同理。
通过上述方法可以将输入特征图数据和卷积核数据在PE阵列内尽可能的复用,相对于传统的卷积计算,数据搬移量仅为前者的21.37%。且同时满足多个PE计算的数据需求,使得多个PE得以并行计算,提高了卷积核梯度计算性能。
2 CNN加速器的系统设计
2.1 CNN加速器系统结构
为了适应不同尺寸的计算以及神经网络所涉及的多种运算,本文设计了基于指令配置的CNN加速器。
指令集如图4所示。本文神经网络推理训练过程被分解成逐层计算形式,将每层的数据尺寸等信息和计算模式编写成指令,配置加速器系统,完成神经网络计算。其中Source addr1、Source addr2、Dst addr分别代表源地址和目的地址,I_channel_size、O_channel_size分别代表输入输出通道数,Cal mode代表计算模式,Pad&act代表激活函数和数据Padding的配置信息,W_size为矩阵大小,Pool_size为池化大小,Mat_size代表特征图大小。加速器的框架设计如图5所示。

图4 指令集
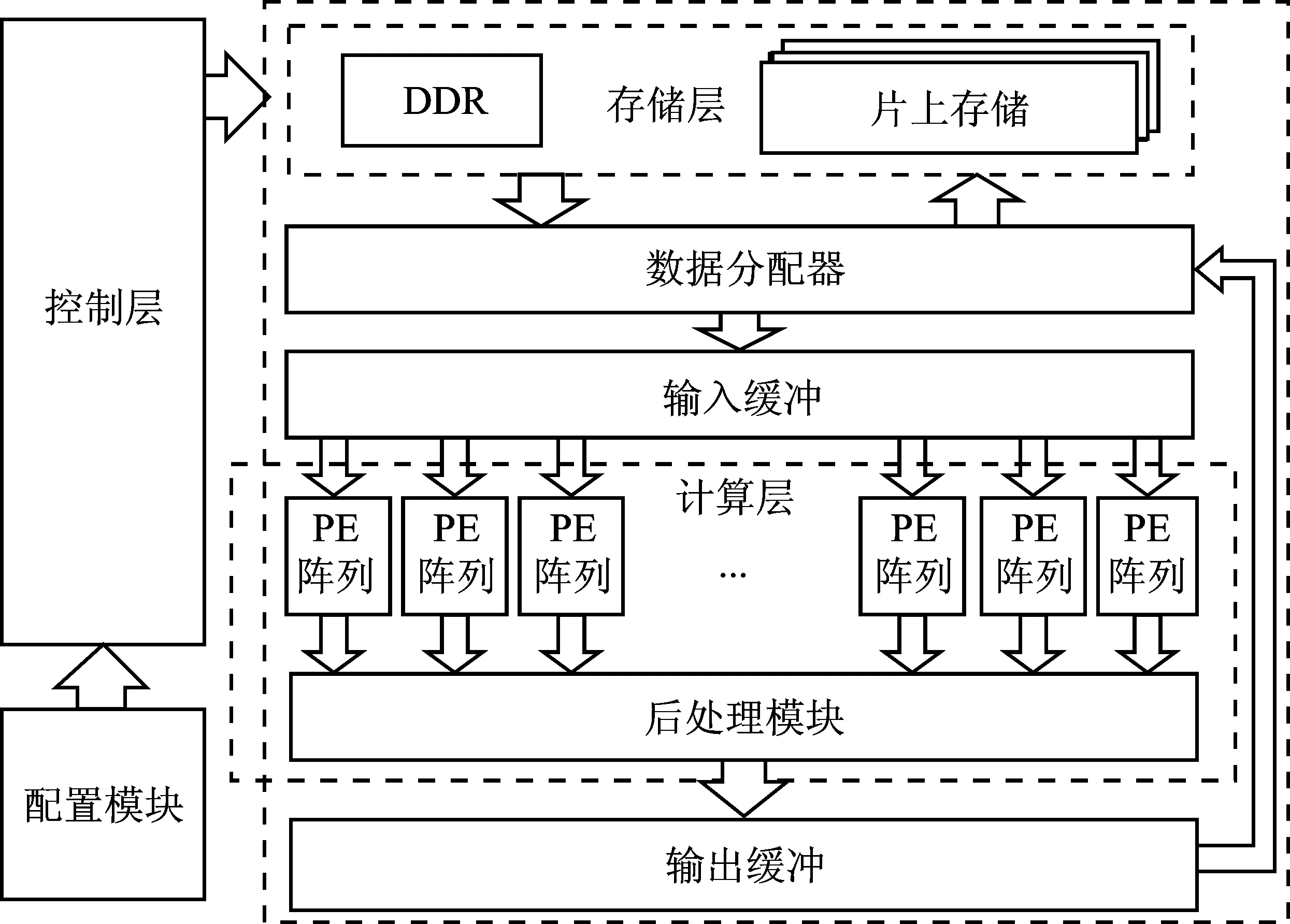
图5 加速器架构
加速器主要由存储层、控制层和计算层组成。存储层主要分为DDR和片上存储,其中DDR存储网络参数、训练集、测试集和训练中所需的中间数据,而片上存储主要存储计算过程中的暂存数据。控制层利用配置模块解析的配置信息去控制整个神经网络的计算过程。计算层主要包括多路PE计算阵列和后处理模块,其中的PE阵列可根据配置信息去重构计算结构以适应不同的计算模式。后处理模块主要用作通道间的累加以及激活函数计算等操作。在执行神经网络计算时,加速器首先通过读取指令获取当前计算任务,数据分配器根据计算模式和地址信息从存储层读取数据并将其分配到输入缓冲中。PE阵列从输入缓冲中获取数据进行计算,PE阵列的计算结果随后被送入后处理模块进行处理。计算完成后,结果数据会被发送到输出缓冲中,输出缓冲将数据整合发送到数据分配器,由数据分配器统一写回到存储层中,整个过程由指令信息配置过的控制层来控制。
2.2 PE阵列配置重构
本文设计了可重构PE单元以提高运算器复用率,并以此为基础设计了可重构的PE计算阵列。PE单元内部可重构成加法、乘法、累加、乘累加、乘加并行计算等计算结构。为了提高不同计算模式的运算效率,加速器通过配置重构PE之间的连接关系和PE的计算功能,形成不同的高效计算结构。由于CNN计算中卷积占据绝大部分的计算量,因此本文以Winograd卷积和卷积核梯度计算为重点,设计了两种高效的重构结构。
图6为重构的Winograd卷积加速结构。如式(5)所示,Winograd计算可被分解为4个步骤:
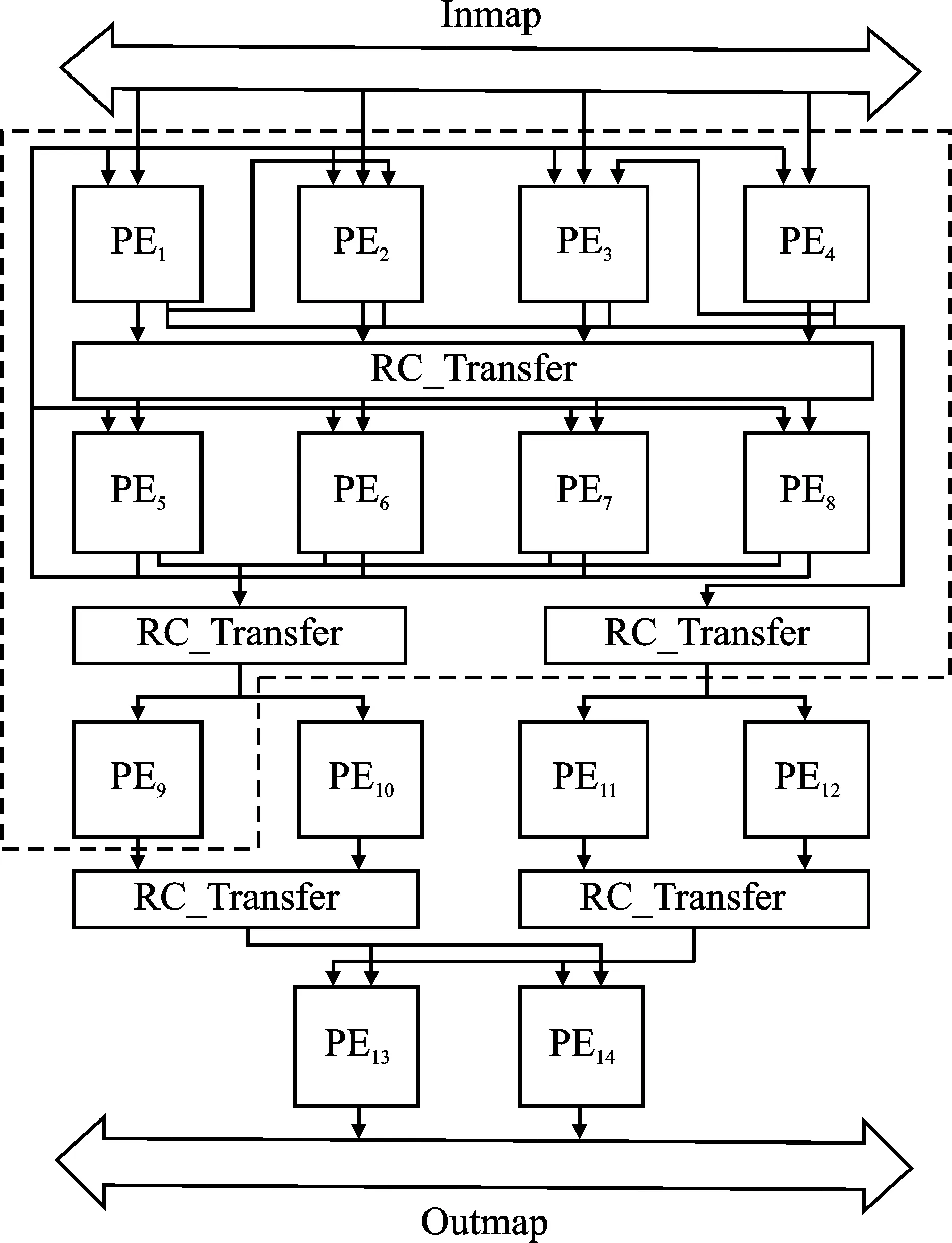
图6 优化的Winograd计算结构
步骤1卷积核变换。如图7所示,卷积核按列将每列的4个数据广播到PE1~PE4。由于式(6)中的参数矩阵G仅包含0、1和±1/2,因此矩阵乘计算过程实际上是根据G矩阵的行参数从卷积核的列向量中选择数据进行取反、相加、乘以参数的过程。每个PE分别负责G矩阵中不同行向量与输入的列向量的计算。如图7所示,RM模块根据配置信息对数据进行选择取反后发给PE,加速器会根据配置信息重构PE内的数据路径,将相应数据发给乘法器和加法器,完成变换计算。由于G矩阵中间的两行参数计算需要两次加法,为了不打断流水,同时提高资源的复用率,PE1和PE4会协助PE2、PE3完成一次加法,并将结果重定向到PE2和PE3完成下一次加法并与参数相乘。与G的变换同理,由PE5~PE8完成GT变换计算。由于G矩阵变换后的结果数据是按列输出的,而GT变换需要矩阵按行输入,如图6所示,因此需要在两者之间插入RC_Transfer模块使得结果数据能够列进行出,满足GT变换需求。在进行步骤2 ~ 步骤4之前,加速器需要通过步骤1将多个输出通道的卷积核变换后存储在PE阵列的存储器中,以便之后的已变换卷积核复用以及输出通道并行计算;
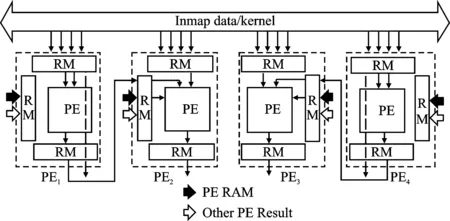
图7 卷积核变换
步骤2输入特征图变换。由于BT矩阵只含±1、0与1,同理可以省去乘法。每个PE分别负责参数矩阵BT中不同列向量与输入的行数据的计算,从而完成输入特征图与矩阵BT的变换计算。PE1~PE4的计算结果会发送到PE5~PE8中,由PE5~PE8完成计算结果与矩阵B的变换计算;
步骤3变换矩阵的点乘。由于步骤2并未使用到乘法,点乘将复用PE1~PE8中的乘法器。如图6所示,PE5~PE8会将已变换的输入特征图发回PE1~PE8进行点乘计算,PE1~PE4和PE5~PE8分别完成不同输出通道的点乘计算。如图8所示,其中PE_RAM为暂存的已变换的多通道卷积核,而Other PE Result为PE5~PE8发回的已变换输入特征图,PE会对两者进行点乘计算;
步骤4结果变换。如图6所示,将步骤3点乘完的结果发送到PE9~PE10和PE11~PE12,两者分别完成不同输出通道计算结果的变换。如图8所示,每个PE的RM模块会根据矩阵AT的参数选择数据送入PE进行相加计算,从而完成结果与矩阵AT的变换计算,PE9~PE12的计算结果会被发送到PE13~PE14,PE13~PE14随后完成结果与矩阵A的变换计算。

图8 其它计算过程的PE重构
本文将式(5)展开,重组成步骤1~步骤4所示的计算过程,并利用不同计算阶段的PE之间的互联和RC_Transfer的数据转换,避免了原算法中的计算数据访存,减少了数据搬移。此外,各计算过程内多PE并行计算变换,各过程间流水进行,提升了PE阵列的计算吞吐量。步骤3和步骤4通过将多个不同输出通道的已变换卷积核与已变换的输入特征图并行进行点乘、变换计算,不仅增加了计算阵列在输出通道上的计算并行度,还复用了已变换的输入特征图,减少了输入特征图的重复变换,提升了数据的利用率。在阵列结构上每增加一份PE9~PE14计算结构和相应的乘法器,便可在输出通道上提升一倍的并行度。多个PE阵列并行计算不同输入通道的卷积,并在后处理模块对输出特征图进行多通道累加,又提升了整个计算系统在输入通道上的并行度。
图9为重构的卷积核梯度优化结构。该计算结构重构了图6中的PE1~PE9。如章节1.4所述,输入特征图,按行广播进入所有的PE中,反向误差矩阵通过PE之间的数据传递通路发送到各个PE中。PE每3个分为一组,通过9个PE并行完成卷积核梯度计算。同一组相邻的PE之间的误差矩阵数据传递要经过Delay模块来获得一个时钟周期的时延,不同组的PE之间的误差矩阵数据传递要经过FIFO来获得输入特征图列数个时钟周期的时延,以上的数据传输结构使得每个PE的输入数据形成如图3所示的对应关系。在卷积过程中会出现如图3中灰色方格所示的无效数据,这些无效数据会打断乘累加计算过程,因此需要将部分和及时锁存并及时弹出到加法器输入继续进行累加。该计算结构在复用重复数据并减少数据搬移的同时,满足了多个PE的并行计算需求,提升了卷积核梯度计算的效率。
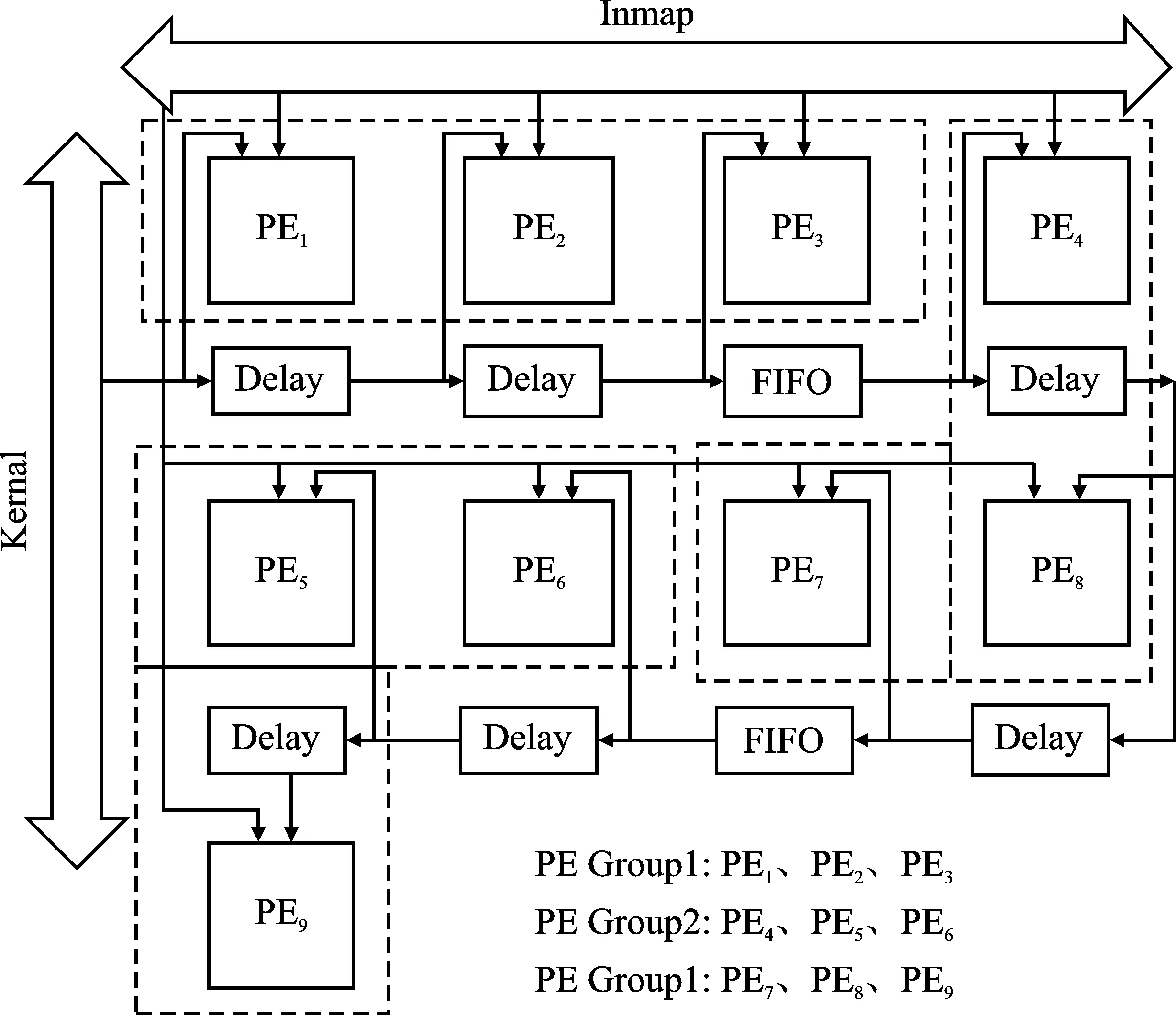
图9 卷积核梯度优化计算结构
2.3 数据分配器
数据分配器根据配置信息采用不同的地址映射方式对DDR存储器或片上存储器进行数据存取。由于DDR存储器带宽较高,数据分配器将读取多路计算所需的数据分配到输入缓冲中,多个PE阵列得以并行计算,提升了系统计算效率。由于权值区域占据较大的存储字段,在读取权值矩阵的转置时,会涉及到DDR存储器的跨行读取,影响DDR存储器的读取速率。加速器通过在行方向上读取多个Burst,再跳行,减少了DDR存储器的跨行次数,提高了DDR存储器的访存效率,每次读取的数据会通过多路PE阵列并行计算和PE的多列乘累加计算吞吐掉。
3 实验性能评估
本文使用Xilinx Virtex-6 XC6VLX240T FPGA对加速器进行实现,工作频率为130 MHz,资源使用率如表2所示。CNN加速器通过以太网口从上位机获得初始化的权值和训练集和测试集,指令通过ROM存储在FPGA内部。FPGA上电复位后,通过读取指令配置计算系统进行计算,从而完成网络的推理训练过程。
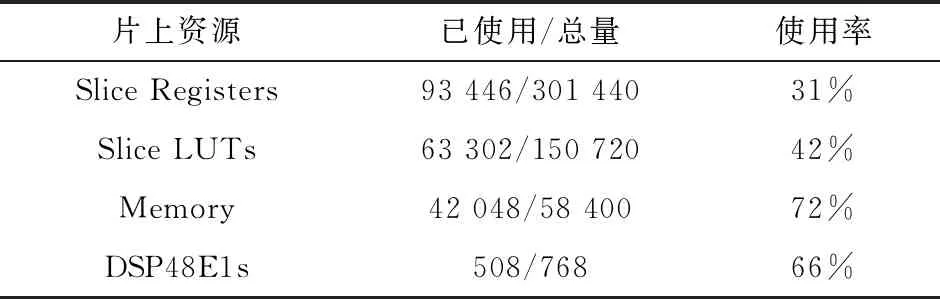
表2 片上资源使用率
加速器采用VGG-9网络模型和CIFAR-10数据集进行推理训练计算以测试加速器的性能[15]。VGG-9网络结构如图10所示,包含6层卷积层、3层全连接层以及3层池化层。每层卷积均采用4D的卷积核,同时拥有多重输入通道和输出通道。
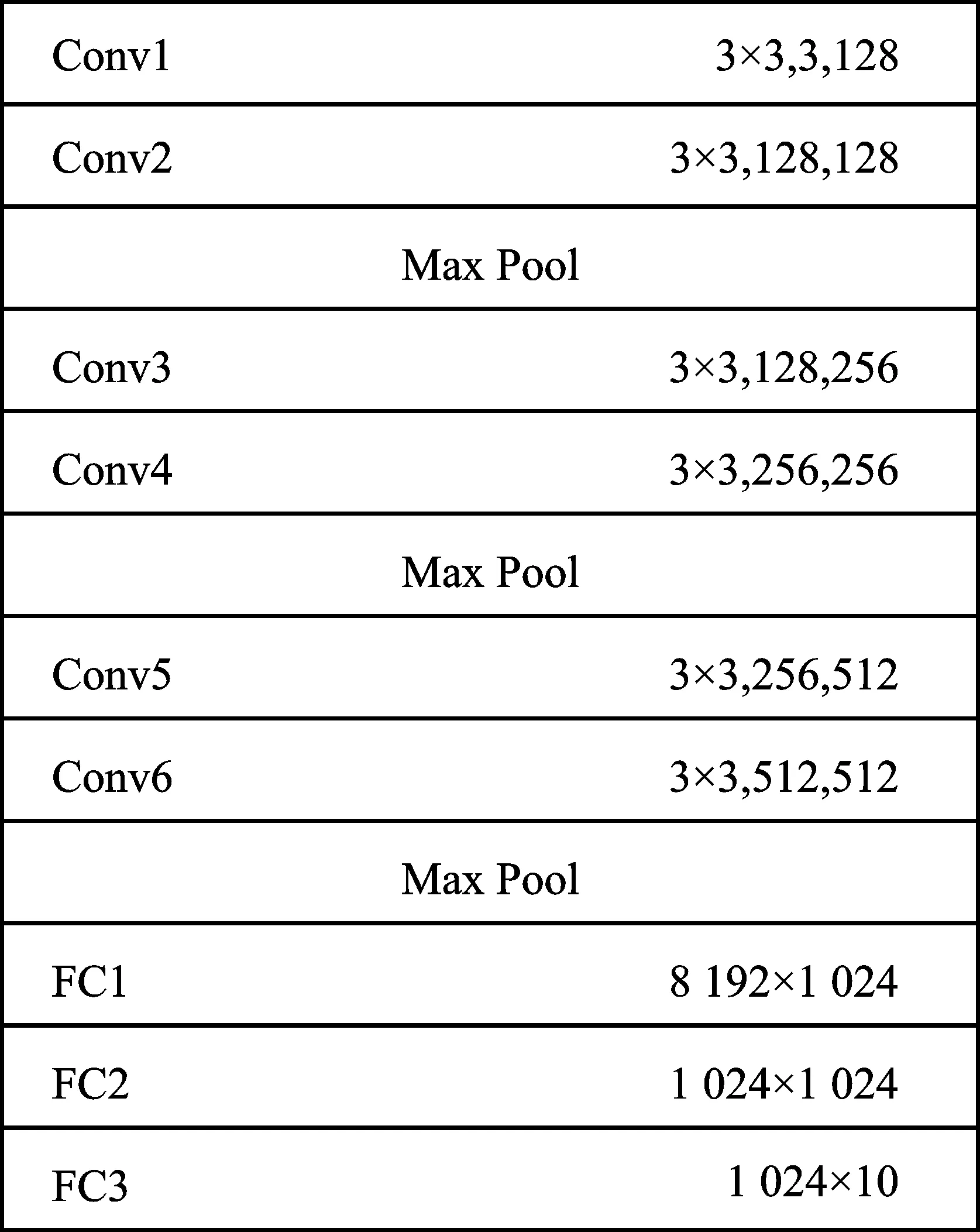
图10 网络模型
本文中,加速器采用小批量随机梯度下降法(Mini-Batch SGD)对网络进行训练,Batch为128,整个训练集被重复训练30次。
图11为对训练过程中网络对训练集的识别率曲线。FPGA在训练过程中会将每个训练集图片的推理结果通过以太网口发送到PC,PC将推理结果与训练集标签进行对比,计算出每个Batch的识别率,Iteration则代表了当前的Batch序号。在8 000 Iteration后,整个网络对训练集的识别率不再有明显变化。在训练结束后,FPGA以测试集对训练好的网络进行推理计算,并将分类结果发送到PC对正确结果进行统计,识别率可达76.54%。

图11 批量训练识别率曲线
如图12所示为本文中优化后的Winograd卷积与普通滑窗卷积的计算周期对比。其中,滑窗卷积已归一到相同并行度。随着卷积尺寸变大,卷积核变换和后处理所占的周期比例减少,加速效果更明显。加速器复用已变换的输入特征图进行多个输出通道并行计算,在减少数据重复搬移的同时提升了PE阵列在输出通道的计算并行度,多个PE阵列会并行进行多个输入通道卷积,增加了加速器在输入通道的计算并行度。相对于普通滑窗卷积,本文优化的Winograd卷积计算效率提升了4.352倍。

图12 计算周期对比
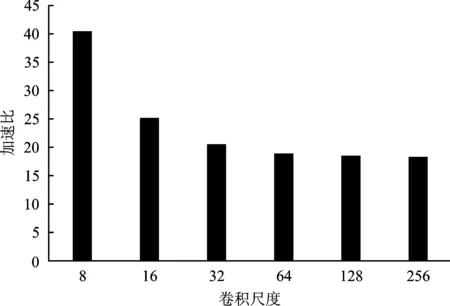
图13 加速器与CPU的卷积核梯度计算性能对比
本文所设计的优化卷积梯度计算中对重复数据采取了复用,提高了加速器对输入特征图数据重复度高的小尺寸卷积核梯度计算的效率,加速比更高。通过优化的数据分配方式和相应的计算结构,单个数据通道的卷积核梯度计算提升了9倍并行度,而数据搬移量仅为普通划窗卷积的23.19%,减少了数据搬移损耗。加速器相对于CPU平均性能提升为23倍。
在推理阶段,由于卷积层的输入特征图尺寸变小,加速比逐渐变小。在训练阶段,由于数据的复用率随着尺度变小而逐渐变大,使得加速比逐渐变大。加速器在推理和训练阶段各层相对CPU有着18~36倍的性能提升。加速器在VGG-9的网络架构下的卷积层平均吞吐率可达192.55 GFLOPS(Giga Floating-point Operations Per Second)。
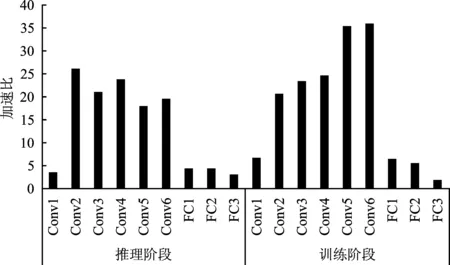
图14 加速器与CPU在推理和训练阶段不同层的加速比
本文所提出的加速器与其他几种加速器的性能对比如表3所示。本文的加速器在不同计算模式下将计算阵列重构成不同的高效计算结构,提高了资源利用率,单位资源计算效率高于其他几种加速器。本文优化的Winograd计算结构设计和多层次并行计算机制,使加速器在卷积计算上有着较高的效率,在卷积层吞吐率上相对于其他加速器有显著的优势。
4 结束语
本文实现了一种CNN硬件加速器,该加速器通过指令配置进行神经网络的推理和训练计算。本文通过配置PE阵列重构了不同的高效计算结构,并在多个层次进行并行计算,提升了加速器在推理和训练过程中的计算性能。相对于传统的滑窗卷积,该加速器的计算效率提高了近4.352倍。在卷积核梯度计算中,优化的数据分配方式满足了多PE并行计算的数据需求,同时使数据搬移量降至原先的23.19%,提高了数据的复用率,减少了数据搬移。加速器在VGG-9的网络架构下的卷积层平均吞吐可达192.55 GFLOPS。
