融合BiLSTM 和注意力机制的卷烟消费者评价情感分类方法
2022-12-20郑新章宗国浩王永胜冯伟华
王 锐,郑新章,宗国浩,王 迪,王永胜,贾 楠,胡 斌,冯伟华
中国烟草总公司郑州烟草研究院,郑州高新技术产业开发区枫杨街2 号 450001
情感分类是对带有感情色彩的文本进行分析、推理的过程,通过分析人的情感倾向可帮助用户准确定位所需信息。随着互联网和移动通信技术的快速发展,通过获取用户评论数据并对其情感倾向进行挖掘和分析,对于开展经济活动预测、舆情监控等研究具有重要意义。何炎祥等[1]利用深度学习模型研究了中文微博的情感分类。林明明等[2]结合HowNet 方法和Google 相似距离方法对消费数据情感分类进行了分析。刘一伊等[3]提出了基于词嵌入与记忆网络的情感分类算法。刘定一等[4]建立了融合微博热点分析和长短期记忆神经网络的舆情预测方法。近年来烟草行业也开展了较多卷烟消费者评价的情感分类研究,帮助烟草工商企业精准感知消费者的需求,对产品规格进行有效整合。蔡波等[5]将消费者评价中的感官描述词与中式卷烟消费体验感官评价指标词相匹配,验证了中式卷烟消费体验感官评价指标的实用性和适用性,并得到消费者较为关注的感官评价指标;杨春晓等[6]通过人工筛选出卷烟在线评论中的常用情感词汇,构建了卷烟在线评论情感词典,并建立了卷烟评价文本情感分析模型,以考察卷烟在线评论中的情感表达;苏凯等[7]利用统计学方法和关联规则挖掘算法,分析了消费者对斗烟的产品品牌、香味类型、配方类型及配方组成的偏好性。由于缺少带标注的消费者评价数据集,上述研究普遍采用基于词典和规则的无监督学习方法构建模型,难以量化评价情感分析结果的准确性。此外,由于中文语法复杂且表达方法的多样性,依靠人工构建的情感词典进行情感词匹配,存在无法识别领域新词、难以顾及上下文语义关系等问题,特别是在句子结构复杂、无情感词出现等情况下,无法有效识别情感倾向。而采用复杂机器学习或深度学习方法,通过深层次的特征学习可以提高情感分析的准确性。双向长短期记忆神经网络(Bi-directional Long Short-Term Memory,BiLSTM)采用双向门函数解决长距离依赖问题,适用于对包含时序信息的数据建模,在图像识别[8]、新词发现[9]、文本分类[10]等方面应用效果良好。而注意力机制[11]可以使模型更加关注关键特征,已广泛应用于图像分类[11]、机器翻译[12]等领域。为此,通过构建有标注的消费者评价数据集,基于BiLSTM和注意力机制建立卷烟消费者评价情感分类模型,旨在准确分析消费者对卷烟产品的情感倾向,为卷烟产品研发和精准营销提供支持。
1 数据与方法
1.1 数据集构建
使用Python的BeautifulSoup库采集并解析了烟悦网、中国香烟网等平台上2 066 个国内卷烟品牌规格2006—2021 年的消费者评价数据,共114 214条。运用正则表达式匹配、字符串匹配等方法去除广告、重复评论、网页标签以及只包含数字或特殊字符等无效数据,通过大小写转换、简繁体转换、数字归一化等方法完成数据清洗,并按正向、中性、负向3 种情感倾向对评价数据进行人工标注,构建了包含78 226 条数据的卷烟消费者评价数据集,将数据集按4∶1 的比例随机划分为训练集和测试集。各情感类别的样本数量分布见表1。

表1 各情感类别的样本数量分布Tab.1 Sample quantity distribution of each emotion category
1.2 烟草领域专有词汇提取
由于中文语境下词与词之间无明显边界,因此如何分词对文本分析的准确性影响较大,通用分词工具应用于特定领域往往因缺少领域未登录词而难以取得理想效果[13-15]。因不同地区、不同消费者群体对同一种卷烟产品有不同的称呼,卷烟消费者评价中存在大量烟草领域约定俗成的短语,如产品名、产品别名、抽吸感受等。本研究中综合考虑了词的内部聚合程度以及所处语境的丰富程度,利用词频、点间互信息(Pointwise Mutual Information,PMI)[16]和左右信息熵提取烟草领域的专有词汇,建立分词补充词典,以提高文本分词的准确性。点间互信息体现了词与词之间的相互依赖程度,PMI值越高,词与词之间的相关性越高,共同组成短语的可能性越大。PMI计算公式为:
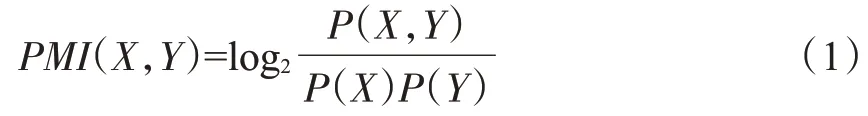
式中:P(X)和P(Y)分别代表词X和词Y出现的概率;P(X,Y)代表词X与词Y共同出现的概率。
信息熵是衡量信息不确定程度的指标,左右信息熵代表了一个词左右可搭配词的多样性,计算公式为:
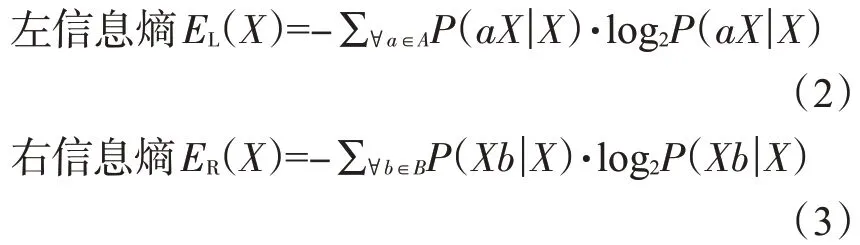
式中:A为词X的左邻字集合;B为词X的右邻字集合。取左右信息熵中的较小值min(EL(X),ER(X))代表词X的自由程度,该值越大,说明该词周围可搭配的词越丰富,独立成词的可能性也越大。
提取语料库中所有长度为7 位及以下的字符串作为候选词,计算各候选词的词频、点间互信息和自由程度,综合考虑提取的时间复杂度和准确性,最终将词频的阈值设为4,点间互信息的阈值设为10,自由程度的阈值设为4。提取能够同时满足各阈值要求的候选词作为领域专有词汇,人工筛选出软云、软玉、黄芙、软蓝楼等词语构建卷烟产品别名表,见表2。将提取出的领域专有词汇作为分词补充词典,采用jieba分词工具对消费者评价数据进行分词。基于构建的卷烟产品别名表,统一评价数据中产品名称的不同表述方式。

表2 部分卷烟产品别名表Tab.2 Aliases of some cigarette products
1.3 模型构建
基于双向长短时记忆神经网络和注意力机制构建BiLSTM-Att情感分类模型。模型由输入层、词嵌入层、BiLSTM 层、注意力层以及输出层构成,架构见图1。
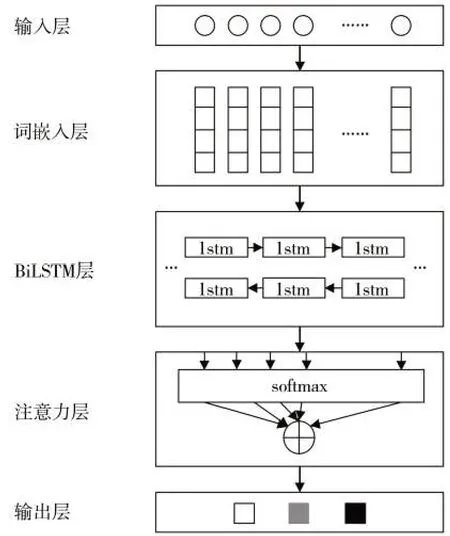
图1 情感分类模型架构图Fig.1 Architecture diagram of emotion classification model
1.3.1 输入层和词嵌入层
因分词后的文本序列长度不一致,需要对序列长度进行统一。假设文本序列最大长度为L,对低于最大长度的序列在其前方用0 补齐,以此统一输入序列长度。根据数据集特征,将L设置为200。对于预处理后的文本序列,采用word2vec[17]的CBOW算法进行词嵌入,将词汇转换成向量形式。
1.3.2 BiLSTM层
长短期记忆神经网络(Long Short-Term Memory,LSTM)[18]是在循环神经网络的基础上,通过设置遗忘门、输入门和输出门,选择性地遗忘过去无意义的信息,保留新的有用信息。相较于循环神经网络,LSTM 可以更好地捕捉较长距离的依赖关系。LSTM的网络更新规则[18]见公式(4)~(9),根据输入数据xt和t-1 时刻记忆单元的输出ht-1,遗忘门ft控制要丢弃的状态信息,输入门it控制要保留的输入信息,通过tanh层得到候选记忆单元t;在遗忘门、输入门的共同作用下,得到当前单元的状态Ct;最后由输出门ot和单元状态Ct得到当前记忆单元的输出ht。
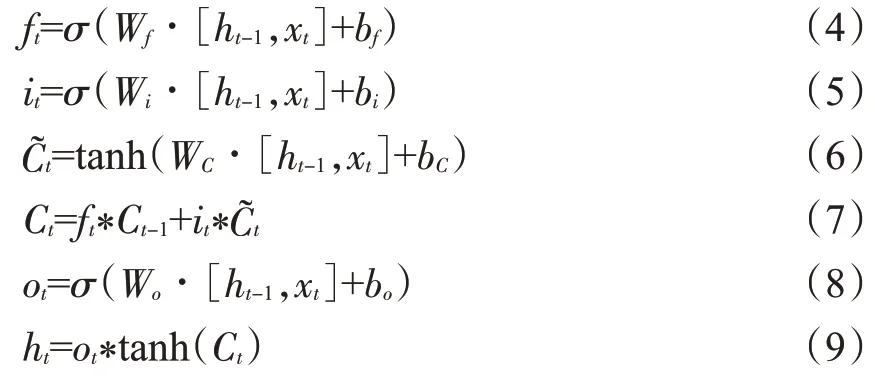
式中:Wf、Wi、WC、Wo分别为遗忘门、输入门、控制门和输出门的权重矩阵;bf、bi、bC、bo分别为对应的偏置矩阵;σ(·)为sigmoid 激活函数;tanh 为双曲正切函数;*为哈达玛乘积。
LSTM可以根据之前时刻的信息预测下一时刻的输出,但在文本数据中一个词通常由上下文环境共同决定,特别是卷烟评价数据中存在情感词、程度副词、否定词之间的交互。例如,“有苏烟的味道。香得很!!”中“很”用于修饰情感词“香”的程度;“之前的口粮,劲道还是可以的,现在感觉抽完嘴干得不行”中“不行”用于表达情感词“干”的程度。BiLSTM 由正向LSTM 与反向LSTM 组合而成,可以较好地捕捉这种双向语义。BiLSTM 的网络结构如图2 所示,将词嵌入向量分别传入正向LSTM和反向LSTM,通过拼接正向LSTM产生的隐向量与反向LSTM 产生的隐向量htR,得到句子的编码向量ht=]。
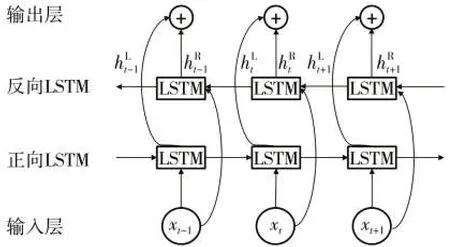
图2 BiLSTM网络结构图Fig.2 Structure of BiLSTM network
1.3.3 注意力层和输出层
由于句子中的每个词对评论情感的判断贡献不同,在BiLSTM模块中引入注意力机制,以减少或忽略无关信息,突出评论中与情绪相关的特征,进一步提升情感分类的准确性。将BiLSTM的编码结果h=(h1,h2,……,hn)作为注意力层的输入,根据公式(10)和(11)计算不同特征的权重系数和注意力值[11],对输入信息加权求和,得到目标词的上下文特征。输出层的激活函数采用softmax,针对三分类问题,输出层设置3个神经元。

1.4 模型训练
采用Python 语言编程,使用Tensorflow GPU
2.5.0 和keras 2.5.0 构建神经网络模型,显卡采用NVIDIA GeForce RTX 3090。使 用Gensim 中 的word2vec 训练词向量,训练窗口大小为5,词向量维度为300。通过网格搜索确定优化器Adam 的学习率为0.000 2。批样本大小为64,采用Dropout在训练过程中随机忽略20%的特征检测器,提高模型泛化性能,防止模型过拟合,损失函数为交叉熵损失函数。
1.5 模型评估
将BiLSTM-Att模型与基于情感词典方法[19]、传统机器学习方法(使用tfidf 构造特征的SVM[20]和使用词向量构造特征的SVM[21])、通用文本情感分析工具(调用百度AI 开放平台中的情感倾向分析接口)、LSTM[18]、BiLSTM 进行对比,通过优化参数使各方法达到最佳效果,并采用精确率(Precision)、召回率(Recall)和F1值评价分类结果的准确性。
2 结果与分析
2.1 统一产品名称表述对模型的影响
统一产品名称和未统一产品名称的情感倾向三分类结果见表3。可见,统一产品名称后模型的精确率、召回率和F1 值分别提高1.88、1.70、1.78 百分点,分类准确性显著提升。

表3 统一产品名称对模型的影响Tab.3 Influence of product alias unifying (%)
2.2 情感分类结果对比
情感倾向二分类(正向、负向)和三分类(正向、中性、负向)结果见表4。可见,与其他方法相比,BiLSTM-Att 的分类准确性均有一定提升。在二分类中,BiLSTM-Att的F1值比LSTM和BiLSTM分别提高3.20 和1.51 百分点;在三分类中,BiLSTM-Att的F1 值比LSTM 和BiLSTM 分别提高2.22 和0.71百分点,表明本研究中建立的方法具有有效性。对于较易区分的二分类问题,基于词典方法的F1值为89.08%,优于传统机器学习方法,接近百度AI 和LSTM,说明在有明显区别特征情况下,通过足够多的规则匹配可以取得较好分类效果。由于中性情感的文本处于两极分类的边缘地带,区分难度大,因此在三分类问题中各方法的准确性均有下降。基于词典方法和百度AI 的准确性下降明显,F1 值分别为72.46%和64.08%,说明这两种方法无法有效识别烟草领域评论的复杂情感。两种SVM 方法中,使用tfidf提取文本特征的SVM分类准确性较高。
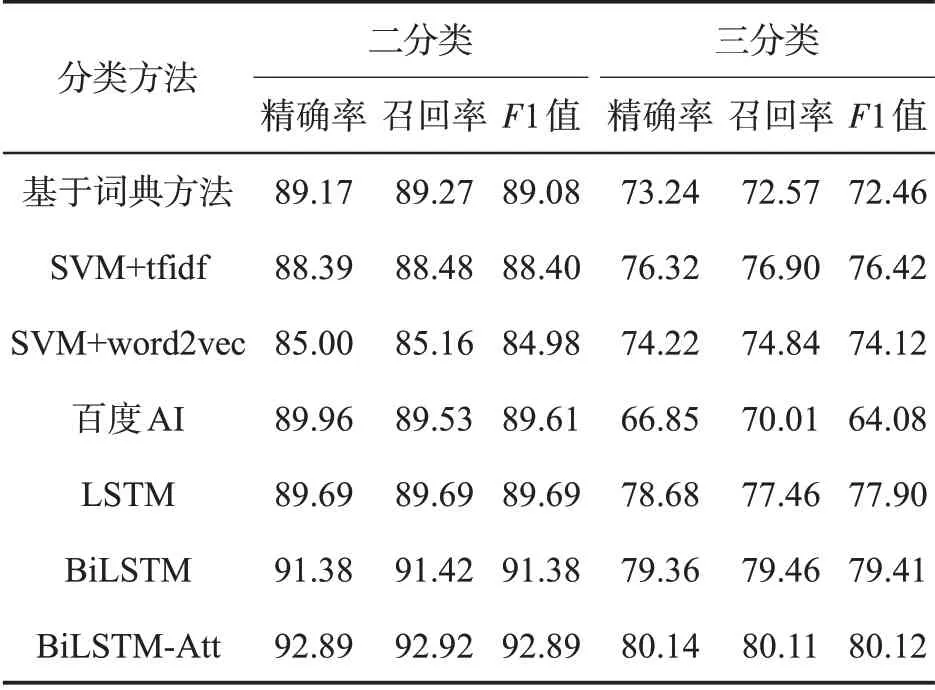
表4 情感倾向二分类和三分类结果对比Tab.4 Comparison of results of binary and ternary emotion classification (%)
根据情感分类结果分别绘制正向、中性、负向评价的词云图,见图3。可见,卷烟消费者的关注重点是产品的口味、价格和包装。正向评价中“喜欢”“口粮”“适合”“值得”“好看”“饱满”等关键词的出现频率较高,负向评价中“不值”“假烟”“恶心”“不行”“垃圾”“炒作”等关键词的出现频率较高,中性评价中的情感词相对较少。不同类别评价的关键词与所表达的情感一致,再次验证了本研究方法的有效性。

图3 不同情感类别评价词云图Fig.3 Word cloud map of comments in different emotion categories
3 结论
基于2006—2021 年2 066 个卷烟品牌规格消费者评价数据,建立了融合双向长短时记忆网络和注意力机制的BiLSTM-Att 情感分类模型,并与基于词典方法、传统机器学习方法、通用文本情感分析工具、LSTM、BiLSTM 进行分类效果对比,结果表明:①BiLSTM-Att在卷烟消费者评价情感分类中具有较高准确性。二分类中,F1 值达到92.89%,比BiLSTM、LSTM和基于词典方法分别提高1.51、3.20和3.81 百分点;三分类中,F1 值达到80.12%,比BiLSTM、LSTM和基于词典方法分别提高0.71、2.22和7.66百分点。②在三分类中统一产品名称可使模型的F1 值提高1.78 百分点。未来将进一步开展细粒度的情感分析研究,以更好地掌握消费者对卷烟产品口味、价格、包装等方面的需求。
