基于DenseNet结构的轨道暗光环境实时增强算法
2022-12-16王立德
王 银,王立德,邱 霁
(北京交通大学电气工程学院,北京 100044)
随着我国轨道交通技术的不断发展,部分城市轨道列车将会转向采用无人值守的自动驾驶方式运营,而其中车载视觉系统将会是保障列车安全运营的关键技术之一.车载视觉系统主要承担对于列车运行前方环境的感知任务,主要包括轨道识别[1]、场景分割[2]、障碍物检测[3-4]以及行人入侵检测[5]等,而城市轨道交通大多运营在封闭的环境中,光照强度不足或运行在夜间环境的低照度条件下将导致视觉系统效率低下或检测精度下降,主要表现在低照度图像像素光照强度平均值较低,像素之间差异较小导致识别及检测算法无法精确提取图像或物体特征.因此,低照度图像增强算法的研究对于车载视觉系统具有非常重要的意义.
在计算机视觉领域,低照度图像处理一直是研究的热点问题,国内外研究人员提出了多种算法用于处理通用场景下的低照度图像,按照理论分类主要表现为三种:一是基于空间域的算法,典型的如基于直方图均衡化[6-7]的增强方法,该方法针对图像整体来调整直方图分布达到增强图像亮度和对比度的目的;二是基于变换域的算法,该算法需要对图像采用小波变换、离散余弦变换或傅里叶变换等将图像变换到频域空间再做滤波处理,然后进行反变换获得增强的图像,其中最具代表性的算法为基于Retinex理论的方法[8-10];三是基于深度学习的算法,也是目前研究的前沿和热点,原理是采用卷积神经网络对图像进行编解码提取抽象特征并对图像特征进行分解及进行增强操作,网络采用数据驱动的方式训练模型参数,实现低照度图像的增强.
目前,基于深度学习的增强方法相比于传统的基于空间及变换域的方法具有明显优势.这其中又发展为两个分支:基于监督学习的方法和基于无监督学习的方法.大多数基于神经网络的方法均采用具有标签配对数据的有监督训练方式训练网络参数来对图像进行增强,如Lore等[11]提出采用堆叠式稀疏去噪自动编码器对低照度图像进行弱光增强,并验证了采用深度学习对于图像增强的有效性,Wei等[12]提出基于Retinex理论的Retinex-Net进行图像增强,作者在网络中建立了一个用于分解的Decom-Net和一个用于增强光照的Enhance-Net,整个网络采用端到端的方式进行训练.Chen等[13]采用全卷积网络(fully convolutional networks,FCN)来处理低光照图像的原始数据(raw文件)并生成sRGB(standard red green blue)图像,可以对极端弱光照条件下的传感器数据进行增强处理.Cai等[14]训练了SICE (single image contrast enhancement)增强器用于改善曝光不足或曝光过度图像的对比度.这些方法均建立或者采用了成对的弱光和正常光的数据集进行监督训练,对于数据要求较高.而基于无监督或自监督学习的方法则摆脱了有标签数据的限制,其根据损失函数以及对于图像本身的光照判别来进行训练,典型的如基于GAN (generative adversarial network)方法,Jiang等[15]开创性地提出了采用不成对的弱光和正常光图像进行网络训练的EnlightenGAN来增强弱光图像.
在轨道环境下获取高质量成对的低光照/正常光照图像样本并非易事,车载系统也需要实时处理摄像机捕捉到的环境图像,因此,本文提出一种轻量级的自监督学习模型用于对轨道低照度图像进行光照增强,模型采用密集连接网络(DenseNet)作为特征提取网络,用于预测每个像素的光照增强率值,采用多种曝光条件下的非配对图像作为训练数据,以先验知识建立对于图像本身的关键约束来进行自监督学习,先验知识包括正常曝光范围、图像色彩恒定以及输入输出空间一致性等,以此建立损失函数指导网络进行训练.实验结果表明:本文建立的算法能够自适应调整图像每个像素的光照强度值,提高了轨道环境图像在暗光条件下的可视质量且具备实时处理能力,通过实验验证其在轨道分割及轨道障碍物检测任务上能够提高算法在暗光环境下的检测准确率.
1 轨道环境实时增强网络模型
本文提出的模型结构如图1所示,骨干网络由密集连接网络构成,通过级联结构逐层增强图像曝光水平,对密集连接网络每一级输出均采用二次函数改变原始图像各通道的像素强度,网络输入为低照度轨道图像,输出为经过光照增强后的图像,网络层数可自定义调整.图1中:xk为第k层特征集;p(i)和P(i)分别为第i个像素归一化后的和经过二次变换后的像素强度值;Conv (convolution)为卷积;ReLU (rectified linear units)为激活函数;BN (batch normalization)为批量归一化.

图1 暗光级联增强网络整体结构Fig.1 Structure of low-light enhancement network
1.1 密集连接网络
DenseNet是由Huang等[16]在2017年提出的深度网络架构,网络主要由多个DenseBlock以及池化层串联组成,每个DenseBlock中都建立前面所有层与后面层的密集连接,实现特征重用并加强了特征的传播,这一特点相比于其他网络极大的减少了网络的参数量和网络计算成本.传统网络第k层输出为

式中:Hk(•)为第k层非线性组合函数.
当采用密集连接时,当前层连接前面所有层作为输入,因此输出变换为

本文利用了DenseNet网络结构中的密集连接用于特征提取并输出预测图像中每个像素点的增强率,因此,舍弃了原始结构中的池化连接,得到一个特征尺寸不变网络.
1.2 像素强度调整非线性映射函数
所提出网络本身不直接预测像素输出强度值,而是通过二次函数变换上一层输出(或原始输入图像)的结果,对输入图像中每一个像素i都根据其亮度值输出相应的增强率 α∈[−1,1].理论上当光照强度大于阈值强度时 α 为负值,降低光照强度;反之 α 为正值,增强光照强度.基于此,建立如下变换函数:

对于每一层变换可表示为

式中:Pn(i)为第n(n= 1,2,…)次变换的输出;Λn(i)为第n次强度变换网络输出的像素i预测增强率.
当n= 1时,Pn−1(i)代表模型原始输入图像,像素亮度变换示意图如图2所示.图中:黄色区域代表增强网络输出的增强率图;数字为像素亮度值.通过二次函数对原始输入进行亮度变换,红色线和蓝色线分别表示对相应的像素亮度进行增强和减弱.

图2 像素亮度变换示意Fig.2 Pixel brightness conversion
1.3 损失函数
为了训练网络参数,本文采用3个损失函数用于表征输出与输入之间的差异,分别为曝光损失、色彩恒定损失以及光照平滑度损失.这3个损失根据对于彩色图像本身的先验知识来衡量增强后的图像与低照度图像之间的损失值,因此,在训练时不需要采用成对的弱光和正常图像进行训练,网络采用输入图像进行自监督训练.
1.3.1 曝光损失
根据人类视觉感受或计算机视觉成像规律,图像曝光值在一定的阈值范围内的为正常曝光,高于这一阈值范围为过度曝光,而低于则为欠曝光.曝光损失函数Le用于度量输入图像中局部曝光强度与正常曝光水平之间的距离,其目的是将图像中局部区域的曝光值调节到一定的范围之内,可表示为

式中:K为采用16 × 16像素尺寸分割出的局部区域的数量,当输入图像设置为256 × 256时,整幅图像被分为16 × 16个局部区域;Ej为第j个区域的平均曝光强度值;ε为正常曝光水平经验值.
1.3.2 色彩恒定损失
人类视觉系统具有颜色恒常性,在外界光源变化的情况下,人类视觉能从变化的光照环境和成像条件下获取物体表面颜色的不变特性,仿照这一原理,Grey-World算法[17]以灰度世界假设为基础,提出对于有着大量色彩变化的图像,R、G、B3个分量的平均值趋于同一灰度值,因此,本文采用一个颜色恒定性损失建立3通道之间的约束关系以校正增强图像中3通道颜色偏差,先计算增强图像的3个通道均值,这样平均灰度值可以表示为

色彩损失函数Lc为3个分量的约束,使3个分量均值趋于一致,可表示为

1.3.3 光照平滑度损失
光照图的一个特点就是局部的一致性和纹理细节的平滑性,而在对图像增强的过程中会引入外部变量干扰图像的光照分布以及引入噪声导致图像局部一致性被破坏,因此,需要对光照增强率添加正则化约束保持光照的平滑性.这种平滑性可以通过降低网络输出的光照增强率图中相邻元素之间的差异来保持,本文采用总变差(total variation,TV)损失Ltv来控制输出每一层增强图的光照平滑度,定义如下:

式中:∇x、∇y表示对水平和垂直方向的梯度运算;为第n层通道c的增强率;N为网络总增强层次.
1.3.4 网络总损失
网络总损失函数如式(9).
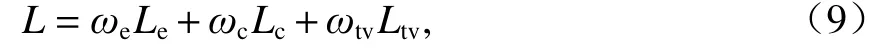
式中:ωe、ωc、ωtv分别为Le、Lc、Ltv的权重.
2 实验设置及结果分析
2.1 训练数据
训练数据来自真实列车运行场景下车载视觉系统拍摄的轨道环境视频,采用将视频每隔一定时间提取一个关键帧并结合人工筛选的方法构建轨道环境原始数据集,数据集由正常曝光图像、隧道环境和夜间环境低光照图像组成,其中,包含1200幅正常曝光图像和200幅低照度图像,为了更好地训练网络,本为采用lightroom软件对数据集进行样本增强,对部分正常曝光图像进行曝光率调节得到不同曝光水平图像组,设置多组过曝光样本和多组欠曝光样本,最终数据集中欠曝光、正常曝光和过曝光样本比例约为2∶2∶1,数据集中包含约4000幅图像用于训练,100幅低照度图像用于测试.
2.2 网络训练细节
将模型部署在Pytorch环境下,GPU采用GTX1080,网络输入图像尺寸设为256 × 256,输入图像全部进行归一化处理,训练时设定mini-batch大小为8,采用Adam优化器训练网络参数,初始学习率设定为 10−4,网络增强层次N设定为8.总的损失函数中默认3个损失分量同等重要,由于损失分量输出值之间数量级存在差异,其权重是为了平衡各损失值在总损失中所占比重,本文实验设定ωe、ωc和ωtv分别为2、1和40.
2.3 网络各层输出评估
所构建的模型为逐层增强级联模型,网络层次可变,将模型中间层结果输出,对比不同层对输入图像的增强效果,结果如图3所示.实验结果显示:网络对低照度输入图像进行逐层增强,通过对不同网络结构的输出对比发现采用8层迭代可以兼顾增强效果和模型计算速度.本文算法对全局暗光环境下的图像可以进行良好的曝光增强,提高轨道环境可视化效果.在列车通过隧道时由于隧道内光线和外界光线强度差异较大,摄像机光圈无法自适应这种光线变化,感光元器件捕捉到的环境画面将会同时出现过曝和欠曝两种极端情况,而根据摄像机成像原理可以知道过度曝光的区域无法通过降低曝光量而获得正常环境细节.本文算法克服了根据图像全局曝光平均值对图像进行曝光调节的缺陷,可以对这种明暗变化强烈的图像进行暗光增强,过曝区域不会影响到算法对其他暗光区域的增强.

图3 增强网络不同层输出结果Fig.3 Enhancement output of different layers
2.4 损失函数作用评估
网络模型训练采用的损失函数具有3个分量,分别为曝光损失分量Le、色彩损失分量Lc和光照平滑损失分量Ltv.本节将通过裁剪对比实验探究3个损失分量各自在网络中的作用,设置以下实验:分别移除总损失函数中3个损失分量其中之一训练网络,实验的目的在于评估各损失函数对输出的影响.实验结果如图4所示.

图4 将损失分量分别移除后的实验结果Fig.4 Experimental results after removing loss components separately
实验结果显示:失去了色彩均衡控制的网络生成的图像虽然在亮度值上增强到了正常的范围,但是产生了严重的色偏;曝光损失函数主要用于将曝光调整到正常范围之内,失去了曝光控制损失函数后网络无法对弱光区域像素进行亮度增强导致输出图像与输入图像无明显差异;移除了光照平滑损失函数的网络所输出的图像虽然曝光正常且未出现明显的色偏,但是图像明显与正常图像相差较大,这主要是由于失去了领域间的相关性产生了伪影导致图像质量下降.
为了探究曝光损失中 ε对实验输出的影响,设定对照实验用以确定该值的大小,实验对照如图5所示,按照经验设定5组对照实验,分别取 ε值为0.4到0.8间隔0.1,分别训练模型,训练样本及其他参数不变,实验结果显示:ε=0.6 或 ε=0.7 得到的图像质量较高,但当图像中存在较大过曝区域时,ε=0.7 时图像整体出现轻微过曝的表现,因此,在本文中设定 ε=0.6,以满足算法对于多数场景的适用性.

图5 不同ε值对输出的影响Fig.5 Effect of ε on output
2.5 低照度图像不同区域增强效果评估
本节实验验证网络对于曝光不足像素点的增强效果,根据多层增强网络中输出的3通道增强率图计算平均增强率,并进行可视化输出, 如图6所示.图中,红色为主要增强区域,颜色越深增强率越大.由增强率图与原始输入图的对比可发现主要增强区域集中在暗光区,对于颜色偏白的过曝或反光区则增强率明显较低,甚至增强率为负.

图6 网络中对于低照度图像中每个像素增强率的可视化结果Fig.6 Visualization results for each pixel enhancement rate in network for low-light images
图7为对某一个通道的8次迭代增强率统计信息,其中,横坐标为增强率大小,取值范围为(−1,1),纵坐标为统计像素数量,输入轨道环境图像大小为512 × 288.从图中不难看出:增强率的范围随着层数的升高而扩大,并且较高的层具有对高亮度区域逐步降低曝光量的作用.这验证了本文的轨道增强算法具有光照自适应性,能够对输入图像根据弱光区域曝光强度自动调节曝光增强率,而对过曝区域降低曝光率,从而将图像曝光调节到正常范围之内,有效地改善低照度图像的视觉效果.
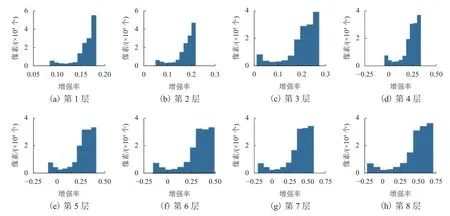
图7 增强网络中某一通道1 ~ 8层各像素增强率统计结果Fig.7 Statistical results of the enhancement rate of each pixel in layers 1 to layer 8
2.6 暗光环境下的轨道分割实验
本节采用多种分割算法对轨道场景下的原始暗光图像以及经过本文算法增强的图像进行轨道分割实验,对比不同分割算法在暗光增强前、后的分割效果,采用轨道分割网络RailNet[2]中定义的像素准确度(pixel accuracy)、平均交并比(mean IoU)、精确度(precision)及F值(F-measure)3个指标评估分割结果,实验结果如表1所示,图8为采用RailNet轨道分割网络进行的测试对比图,图8(a)为原始暗光环境下的检测结果,图8(b)为经过本文算法增强后的检测结果,红色区域为检测出的轨道区域.

图8 暗光环境下轨道检测对比实验Fig.8 Comparative experiment of railroad detection under low-light environment

表1 不同分割算法在暗光增强前、后的性能对比Tab.1 Performance comparison of different segmentation algorithms before and after low-light enhancement
2.7 暗光环境下行人入侵检测实验
行人入侵是轨道交通中严重影响行车安全的行为,本节采用目前目标检测中常用的YOLO算法作为基准来进行轨道环境下的行人检测,通过暗光增强前、后检测器的性能对比实验证明本文所提出的轨道低照度增强算法的有效性.部分实验结果如图9所示,图9(a)为原始暗光环境下的检测结果,图9(b)为经过本文算法增强后的检测结果,图中红色实线框为检测结果,黄色虚线框为误检,绿色虚线框为漏检.实验显示:暗光环境下的行人检测存在较多误检或漏检情况,而经过本文算法增强的图像在进行行人检测时准确率更高,误检率较低.图10展示了部分轨道场景下弱光增强效果.

图9 轨道暗光环境下行人检测对比实验Fig.9 Comparative experiment of pedestrian detection in low-light railroad environment

图10 低照度轨道环境下图像增强结果Fig.10 Image enhancement results in low-light railroad environment
3 结束语
本文提出了一种采用DenseNet结构的自监督学习轻量级深度学习模型用于解决铁路弱光环境中车载视觉的弱光检测问题,模型通过逐级提高弱光区域曝光率的方式改善弱光场景下的图像成像质量,并采用图像本身的先验知识对网络进行端到端训练,缓解了铁路环境下难以获取大量成对训练样本(正常曝光/欠曝光图像组)的问题.在实验中解释了模型原理及参数设置依据,通过设置多组对比实验及轨道场景下的轨道分割实验和行人检测实验证明了模型的有效性,处理速度为160帧/s满足实时处理的要求.本文所提出的算法对低照度场景下的弱光增强效果较好,但目前还无法解决过度曝光场景下的成像质量问题,未来将研究过度曝光图像及过度曝光区域的处理问题.
